Claude Code 一周烧掉一半配额?我从逆向工程中看到了 Agent 测试的致命盲区
Claude Code 上线不到半年,口碑急转直下。有人跟踪了它的思考深度变化:从 1 月底的约 2200 字符,到 2 月下旬骤降至 720 字符,3 月初进一步跌至 560 字符。降幅 67%。与此同时,一个叫 redact-thinking 的功能上线,把思考过程从界面上隐藏了。你再也看不到它到底想了多少。
📝 面试求职: 「面试试题小程序」 ,内容涵盖 测试基础、Linux操作系统、MySQL数据库、Web功能测试、接口测试、APPium移动端测试、Python知识、Selenium自动化测试相关、性能测试、性能测试、计算机网络知识、Jmeter、HR面试,命中率杠杠的。(大家刷起来…)
📝 职场经验干货:
很多人已经开始感觉到不对劲了。
花 30 美元买的 Claude Code 周配额,以前能撑三四天,现在一上午就烧掉一半。你以为是自己的对话太密集,但账单上显示的 Token 消耗数字,怎么看都不对劲。
这不是个例。有人逆向工程了 Claude Code 的源码,发现了一连串叠加的 bug。其中一条最致命:一旦你进入 Extra Usage(超额付费)模式,客户端会悄悄把缓存时长从 1 小时降级到 5 分钟。你起身倒杯水,回来就是一次完整的上下文重建,费用直接从余额里扣,没有任何提示。
这已经不是“AI 工具偶尔犯错”的问题了。这是一个缺乏可观测性、缺乏成本熔断、缺乏透明决策逻辑的 Agent 系统,正在批量制造信任危机。
我们今天不聊新闻。聊一个所有测试从业者都必须面对的问题:你拿什么去测试这类黑盒 Agent?
目录
一、现象 / 热点:AI 编程助手正在“一边偷懒一边烧钱”
二、本质变化:Agent 的经济模型和可观测性双双缺失
三、核心机制拆解:缓存降级、截断、伪造限速,一个比一个隐蔽
四、典型案例 / 对比:同一个工具,不同安装方式,天壤之别
五、工程落地启示:测试 Agent 不能再只测“对不对”
六、趋势判断:透明化是唯一的出路
一、现象 / 热点:AI 编程助手正在“一边偷懒一边烧钱”
Claude Code 上线不到半年,口碑急转直下。
有人跟踪了它的思考深度变化:从 1 月底的约 2200 字符,到 2 月下旬骤降至 720 字符,3 月初进一步跌至 560 字符。降幅 67%。与此同时,一个叫 redact-thinking 的功能上线,把思考过程从界面上隐藏了。你再也看不到它到底想了多少。
更严重的是一组缓存 bug。一位 Claude Max 20x 订阅用户发现,自己仅 4 月 1 日一天就烧掉了 43% 的一周配额。他花几天逆向分析了 cli.js,找出了 7 个相互叠加的 bug:
-
Extra Usage 模式下,缓存 TTL 从 1 小时降级为 5 分钟
-
原生安装包自带的 Bun 运行时会损坏缓存前缀
-
会话恢复时丢失附件类型,导致每次恢复都是缓存未命中
-
自动压缩功能没有熔断,失败后无限重试
-
工具结果在客户端被截断(Bash 上限 30K,Grep 上限 20K)
-
客户端伪造假的限速错误,实际没有发起任何 API 调用
-
服务端压缩机制悄悄删除工具结果,破坏缓存
这些 bug 之间的关系是相乘而不是相加。同时触发其中三个,不到两小时就能烧掉一周配额。
这不是个别用户的抱怨。Boris Cherny(Claude Code 负责人)不得不出面解释,称 redact-thinking 只是 UI 隐藏,不影响推理。但用户实测表明:行为确实变了,成本确实暴涨了。
一个可以传播的观点句:
当 AI 工具开始在用户看不见的地方调整缓存策略来平衡自己的账本时,它牺牲的不只是几美金的 Token 费,而是整个行业的信任。
二、本质变化:Agent 的经济模型和可观测性双双缺失
很多人把这件事归结为“bug”。但我认为,这是 Agent 系统在工程化落地过程中必然会撞上的墙。
核心在于两点。
第一,Agent 的“经济模型”是隐式的。
传统软件,你付费买功能,功能消耗是固定的。但 Agent 按 Token 计费,每一次推理的成本取决于上下文长度、缓存命中率、模型 effort 级别。用户根本无法预估“问一个简单问题”到底会花多少钱。更糟糕的是,像 Claude Code 这样,客户端可以单方面改变缓存策略,用户完全不知情。
第二,可观测性几乎为零。
你看不到真实的思考深度(被 redact 了),看不到缓存是否命中(被静默降级了),看不到工具结果是否被截断(截断了也不告诉你)。你想 debug 为什么配额消耗这么快?你连数据都没有。
本质上是:Agent 把决策逻辑封装成了黑盒,却把成本风险转嫁给了用户。
另一个可以传播的观点句:
一个不能让你实时看到“每一轮对话的真实成本”的 Agent,本质上是在邀请你为它的实现缺陷买单。
三、核心机制拆解:缓存降级、截断、伪造限速,一个比一个隐蔽
我们以最严重的那个 bug 为例,拆解一下技术细节。
在 Claude Code 的 cli.js 中,有一个函数决定向服务器申请多长的缓存 TTL(Time To Live)。正常逻辑是申请 1 小时。但这个函数会偷偷检查你是否进入了 Extra Usage 模式。一旦检测到,TTL 就被降级为 5 分钟。
流程如下:
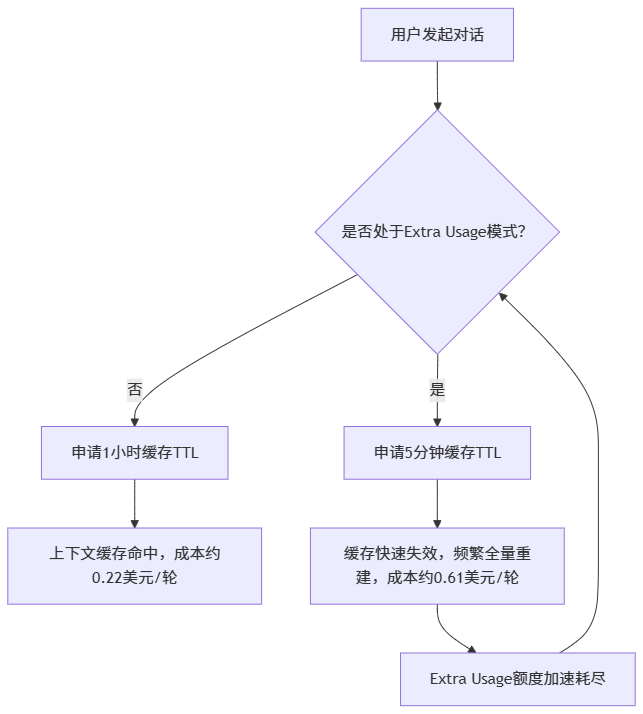
代价非常具体。
以 220K 上下文为例:
-
1 小时缓存 → 每轮约 0.22 美元
-
5 分钟缓存 → 每轮约 0.61 美元
贵了 1.8 倍。30 美元的 Extra Usage 额度,在 1 小时缓存下能撑约 135 轮,在 5 分钟缓存下只能撑约 48 轮。
更隐蔽的是,这个降级没有任何日志,没有任何 UI 提示。你只知道钱没了,不知道为什么。
另外几个 bug 也很典型:
-
客户端截断:Bash 工具输出超过 30K 字符就被截断,Grep 超过 20K 也被截断。截断后的残缺内容破坏了缓存前缀,导致缓存失效。这不是服务器限制,是客户端主动截的。
-
伪造限速错误:客户端会在大型对话记录中伪造一个假的限速错误,显示 model: synthetic、token 数为零。实际上根本没有发起任何 API 调用。用户以为是服务器限流,其实是客户端自己拒绝了。
-
服务端静默删除:压缩机制会在会话进行中悄悄删除工具结果,同样破坏缓存,且无法从客户端修复。
这些 bug 的共同特征是:静默、无反馈、无补偿机制。
四、典型案例 / 对比:同一个工具,不同安装方式,天壤之别
有一个非常有意思的对比。
发现这些 bug 的开发者给出了一个建议:如果使用原生安装包,切换到 npm 安装。因为官方二进制文件内置了一个自定义 Bun 运行时,这个运行时会在每次请求时损坏缓存前缀。改用 npm 安装后,问题消失。
有用户在 WSL 环境下实测证实:改用 npm 方式安装后,额度消耗速率立刻恢复正常。
更进一步的对比:
-
使用 VS Code 插件的用户 → 没遇到这些 bug
-
使用电脑桌面版的用户 → 没遇到
-
使用网页版的用户 → 没遇到
-
使用 CLI 原生安装包的用户 → 集体中招
结论很清晰:这个吞额度 bug 几乎是 Claude Code CLI 原生安装包专属的灾难。
这意味着什么?
意味着同一个 Agent 能力,部署方式不同,经济模型完全不同。用户以为是模型本身的问题,实际上是客户端实现的 bug。
这给测试从业者的启示很直接:测试 Agent 不能只测模型能力,必须测客户端工程实现,包括缓存策略、截断逻辑、限速行为。
五、工程落地启示:测试 Agent 不能再只测“对不对”
如果你是一名测试工程师,或者测试开发工程师,这件事给你的不是“吃瓜素材”,而是一个明确的技能升级方向。
传统的自动化测试,关注的是功能正确性:输入 A,输出是不是 B?
但 Agent 系统的测试,必须增加三个新维度:
1. 经济模型可观测性测试
你的 Agent 系统是否提供了实时的成本仪表盘?
是否能在每一轮对话后给出:本轮消耗 Token、缓存命中率、各工具调用费用分解?
Claude Code 在 v2.1.92 里增加了 /cost 命令,展示基于每个模型以及缓存命中情况的详细费用分解。这是对的,但还不够——它仍然是在问题爆发后才补上的。
2. 策略透明性测试
Agent 的所有“自动决策”——比如自适应思考、自动压缩、缓存 TTL 选择——是否对用户透明?
用户是否有能力覆盖默认策略?
比如,Claude Code 把 effort 级别默认调为 Medium,用户可以手动调回 High。但问题是:有多少用户知道这个开关存在?
3. 故障熔断与回放测试
当自动压缩无限重试时,有没有熔断机制?
当缓存频繁失效时,有没有降级策略告警?
当客户端伪造限速错误时,有没有办法 bypass?
这些不是模型能力问题,是工程健壮性问题。
一个可以传播的观点句:
测试 Agent,本质上是测试一个“会花你钱的不透明决策系统”。你不能只测它答得对不对,还要测它花钱的方式合不合理。
对于初级工程师,这里有一个可以直接落地的建议:
下次你测试一个接入了大模型的 Agent 功能,先跑一个成本基线。用相同的 prompt,在相同上下文中跑 10 轮,记录每轮的实际 Token 消耗和耗时。如果波动超过 30%,说明缓存策略或截断逻辑有问题。
对于中级工程师,你需要建立一套 Agent 的可观测性测试框架:
-
拦截所有 API 请求/响应,记录缓存头
-
监控客户端的截断行为
-
模拟 Extra Usage 状态,验证缓存 TTL 是否被降级
这不是可选项。当你的团队开始自研 AI Agent,或者在业务中深度依赖第三方 Agent 时,这些就是必选项。
六、趋势判断:透明化是唯一的出路
Claude Code 这次的信任危机,不会是个例。
Cursor、OpenClaw、AutoGPT…… 所有试图把大模型封装成“自主 Agent”的产品,都会面临同样的矛盾:
一方面,为了降低推理成本,必须在客户端做大量优化(缓存、截断、压缩、自适应思考)。
另一方面,这些优化一旦做得不透明、不可控,就会变成吞噬用户费用的黑洞。
短期来看,厂商会像 Anthropic 一样,逐步增加账单透明度和缓存失效提醒。但这些都是事后补救。
长期来看,行业会形成两种分化:
-
封闭派:继续把 Agent 当成黑盒,只给用户一个“开箱即用”的界面,成本和决策逻辑完全封闭。这类产品会逐渐失去开发者信任。
-
透明派:开放可观测性接口,允许用户审计每一轮决策和成本,甚至允许用户覆盖默认策略。这类产品会成为企业级应用的首选。
作为测试从业者,你现在就可以做一个判断:
你所在的团队,或者你使用的 AI 测试工具,属于哪一派?
当 Anthropic 在“追求极致体验”与“沉重推理成本”之间剧烈挣扎时,开发者需要的不是一个替自己做决策的黑盒,而是一个透明、可预测的杠杆。
你现在负责的任何一个 AI 测试流程中,是否有一个能够实时监控“每一轮对话真实成本”的仪表盘?如果没有,你觉得第一个 bug 会在什么时候出现?
最后: 下方这份完整的软件测试视频教程已经整理上传完成,需要的朋友们可以自行领取【保证100%免费】



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献137条内容
已为社区贡献137条内容

所有评论(0)