基于 Kafka + ELK + Ollama + OpenClaw 的日志收集与智能告警平台
操作系统:CentOS Stream 10
核心组件:Kafka 3.6.1 (KRaft)、Nginx 1.26.3、Filebeat 9.3.2、Mysql 8.4.8、Elasticsearch 7.17.18、Kibana 7.17.18、Ollama (Qwen3.5:2b)、OpenClaw
服务器规模:10 台
一、项目整体架构
共 10 台 CentOS Stream 10 服务器,IP 与角色规划如下:
| IP 地址 | 主机名 | 部署组件 | 核心功能 |
| 192.168.117.135 | app1 | Flask (app.py) | 后端业务服务 |
| 192.168.117.136 | app2 | Flask (app.py) | 后端业务服务 |
| 192.168.117.137 | nginx | Nginx + Filebeat | 反向代理 + 日志采集 |
| 192.168.117.138 | kafka1 | Kafka | Kafka 节点 1 |
| 192.168.117.139 | kafka2 | Kafka | Kafka 节点 2 |
| 192.168.117.140 | kafka3 | Kafka | Kafka 节点 3 |
| 192.168.117.141 | mysql | MySQL 8.4.8 | 持久化存储 |
| 192.168.117.142 | elk | Elasticsearch + Kibana | 实时分析 + 可视化 |
| 192.168.117.143 | ollama | Ollama + monitor.py | AI 判断 + 日志监控 |
| 192.168.117.158 | openclaw | OpenClaw | 自动化运维诊断 |
二、环境准备(所有节点执行)
2.1 基础软件安装
dnf install wget vim java-21-openjdk.x86_64 -y2.2 静态 IP 配置(按各自机器修改)
编辑 /etc/NetworkManager/system-connections/ens33.nmconnection
示例(以 kafka1 为例):
[ipv4]
method=manual
addresses1=192.168.117.137/24,192.168.117.2
dns=114.114.114.114重启网络:
nmcli connection reload
nmcli device up ens332.3 配置主机名
# 各节点分别执行
hostnamectl set-hostname app1 # 135节点
hostnamectl set-hostname app2 # 136节点
hostnamectl set-hostname nginx # 137节点
hostnamectl set-hostname kafka1 # 138节点
hostnamectl set-hostname kafka2 # 139节点
hostnamectl set-hostname kafka3 # 140节点
hostnamectl set-hostname mysql # 141节点
hostnamectl set-hostname elk # 142节点
hostnamectl set-hostname ollama # 143节点
hostnamectl set-hostname openclaw # 158节点2.4 Hosts 映射
编辑 /etc/hosts :
192.168.117.135 app1
192.168.117.136 app2
192.168.117.137 nginx
192.168.117.138 kafka1
192.168.117.139 kafka2
192.168.117.140 kafka3
192.168.117.141 mysql
192.168.117.142 elk
192.168.117.143 ollama
192.168.117.158 openclaw2.5 关闭防火墙与 SELinux
# 关闭防火墙
iptables -F
systemctl stop firewalld
systemctl disable firewalld
# 禁用 SELinux
vim /etc/selinux/config
SELINUX=disabled
# 重启生效
reboot三、Kafka 3.6.1 集群部署(KRaft 模式)
部署节点:kafka1(138)、kafka2(139)、kafka3(140)
3.1 下载解压
cd /opt
wget https://archive.apache.org/dist/kafka/3.6.1/kafka_2.13-3.6.1.tgz
tar xf kafka_2.13-3.6.1.tgz
cd kafka_2.13-3.6.13.2 配置文件修改
编辑 /opt/kafka_2.13-3.6.1/config/kraft/server.properties
关键配置(按节点修改):
| 配置项 | kafka1 (138) | kafka2 (139) | kafka3 (140) |
| node.id | 1 | 2 | 3 |
| listeners | PLAINTEXT://kafka1:9092,CONTROLLER://kafka1:9093 | PLAINTEXT://kafka2:9092,CONTROLLER://kafka2:9093 | PLAINTEXT://kafka3:9092,CONTROLLER://kafka3:9093 |
| advertised.listeners | PLAINTEXT://kafka1:9092 | PLAINTEXT://kafka2:9092 | PLAINTEXT://kafka3:9092 |
| listeners | PLAINTEXT://0.0.0.0:9092,CONTROLLER://0.0.0.0:9093 | PLAINTEXT://0.0.0.0:9092,CONTROLLER://0.0.0.0:9093 | PLAINTEXT://0.0.0.0:9092,CONTROLLER://0.0.0.0:9093 |
其余配置不动
3.3 集群初始化
仅在 kafka1 执行,生成集群 UUID:
cd /opt/kafka_2.13-3.6.1
bin/kafka-storage.sh random-uuid > tmp_random
cat tmp_random所有节点执行,格式化存储:
bin/kafka-storage.sh format -t 集群UUID -c /opt/kafka_2.13-3.6.1/config/kraft/server.properties3.4 配置 Systemd 服务
vim /usr/lib/systemd/system/kafka.service[Unit]
Description=Apache Kafka server (KRaft mode)
Documentation=http://kafka.apache.org/documentation.html
After=network.target
[Service]
Type=forking
User=root
Group=root
Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/usr/lib/jvm/java-21-openjdk/bin/"
ExecStart=/opt/kafka_2.13-3.6.1/bin/kafka-server-start.sh -daemon /opt/kafka_2.13-3.6.1/config/kraft/server.properties
ExecStop=/opt/kafka_2.13-3.6.1/bin/kafka-server-stop.sh
Restart=on-failure
[Install]
WantedBy=multi-user.targetsystemctl daemon-reload
systemctl start kafka
systemctl enable kafka3.5 集群验证
# 创建 Topic(3 副本 3 分区)
bin/kafka-topics.sh --create --bootstrap-server kafka3:9092 --replication-factor 3 --partitions 3 --topic nginxlog
# 查看 Topic
bin/kafka-topics.sh --list --bootstrap-server kafka3:9092
# 测试生产消费
bin/kafka-console-producer.sh --broker-list kafka3:9092 --topic nginxlog
bin/kafka-console-consumer.sh --bootstrap-server kafka1:9092 --topic nginxlog --from-beginning四、后端 Flask 服务部署
部署节点:app1(135)、app2(136)
4.1 环境安装
dnf install epel-release -y
dnf install python3 python3-pip -y
python3 -m pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple
python3 -m pip install flask -i https://pypi.tuna.tsinghua.edu.cn/simple4.2 应用部署
/root/app.pyfrom flask import Flask
app = Flask(__name__)
@app.route("/")
def index():
return "this is flask web kafka2"
app.run(host = "0.0.0.0")
4.3 配置 Systemd 服务
vim /etc/systemd/system/app.service[Unit]
Description=Flask App Service
After=network.target
[Service]
User=root
WorkingDirectory=/root
ExecStart=/usr/bin/python3 /root/app.py
Restart=always
RestartSec=5
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl start app
systemctl enable app五、Nginx 1.26.3 + Filebeat 9.3.2 部署
部署节点:nginx (137)
5.1安装 Nginx
yum install epel-release -y
yum install nginx -y5.2 配置反向代理(代理后端两台 Flask)
vim /etc/nginx/conf.d/app.confupstream app {
server 192.168.117.135:5000;
server 192.168.117.136:5000;
}
server {
listen 80;
location / {
proxy_pass http://app;
proxy_set_header Host $host;
}
}systemctl start nginx
systemctl enable nginx5.3 安装 Filebeat
cd /opt
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-9.3.2-linux-x86_64.tar.gz
tar -zxf filebeat-9.3.2-linux-x86_64.tar.gz5.4 配置 Filebeat
vim /opt/filebeat-9.3.2-linux-x86_64/filebeat.yml# ============================== Filebeat inputs ===============================
filebeat.inputs:
- type: filestream
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/nginx/access.log
- /var/log/nginx/error.log
# 关闭文件句柄自动关闭
close_inactive: 1s
# 强制每次写入立即读取
scan_frequency: 1s
#句柄超时重连
close_timeout: 1s
#强制从文件尾部读取
tail_files: true
#==========------------------------------kafka-----------------------------------
output.kafka:
hosts: ["192.168.117.138:9092","192.168.117.139:9092","192.168.117.140:9092"]
topic: nginxlog
keep_alive: 10s
# 1. 禁用压缩,减少延迟
compression: none
# 2. 强制100ms内必须发送
flush_interval: 100ms
bulk_max_size: 1
# ============================== Filebeat modules ==============================
filebeat.config.modules:
# Glob pattern for configuration loading
path: ${path.config}/modules.d/*.yml
# Set to true to enable config reloading
reload.enabled: false
# Period on which files under path should be checked for changes
#reload.period: 10s
# ================================= Processors =================================
processors:
- add_host_metadata:
when.not.contains.tags: forwarded
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
5.5 配置 Systemd 服务
vim /etc/systemd/system/filebeat.service[Unit]
Description=Filebeat
After=syslog.target network.target
[Service]
Type=simple
User=root
ExecStart=/opt/filebeat-9.3.2-linux-x86_64/filebeat -e -c /opt/filebeat-9.3.2-linux-x86_64/filebeat.yml
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl start filebeat
systemctl enable filebeat六、MySQL 8.4.8 部署
部署节点:mysql (141)
6.1 安装
dnf install mysql8.4-server -y6.2 配置
vim /etc/my.cnf.d/mysql-server.cnf#添加
bind-address=0.0.0.0
port=3306systemctl start mysqld
systemctl enable mysqld6.3 创建远程账号
-- 创建 root 用户,允许任意 IP 登录
CREATE USER 'root'@'%' IDENTIFIED BY '123456';
-- 授予所有权限
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION;
-- 刷新权限
FLUSH PRIVILEGES;七、ELK 栈部署
部署节点:elk (142)
7.1 系统调优
vim /etc/security/limits.conf
* soft nofile 65535
* hard nofile 65535
* soft nproc 4096
* hard nproc 4096
vim /etc/sysctl.conf
vm.max_map_count=655300
fs.file-max=655350
sysctl -p7.2 创建专用用户
groupadd es
useradd -g es es7.3 Elasticsearch 7.17.18 部署
7.3.1 安装 Elasticsearch
cd /usr/local/src
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.18-linux-x86_64.tar.gz
tar -zxvf elasticsearch-7.17.18-linux-x86_64.tar.gz
mv elasticsearch-7.17.18 /usr/local/elasticsearch
chown -R es:es /usr/local/elasticsearch7.3.2 修改配置
vim /usr/local/elasticsearch/config/elasticsearch.yml# 集群名称(单机版默认即可,集群版所有节点必须一致)
cluster.name: my-elasticsearch
# 节点名称(单机版默认即可,集群版每个节点唯一)
node.name: node-1
# 允许所有IP访问(核心!开启远程连接)
network.host: 0.0.0.0
# ES默认端口
http.port: 9200
# 集群发现(单机版设置为单机模式)
discovery.type: single-node
# 关闭跨域限制,对接Kibana/Head插件必配
http.cors.enabled: true
http.cors.allow-origin: "*"7.3.3 IK 分词器安装
# 切换到es用户
su es
# 进入ES的插件目录
cd /usr/local/elasticsearch/plugins
# 创建ik目录
mkdir ik
cd ik
# 下载对应版本的IK分词器
wget https://release.infinilabs.com/analysis-ik/stable/elasticsearch-analysis-ik-7.17.18.zip
# 解压(如果没有unzip,执行 yum install unzip -y 安装)
unzip elasticsearch-analysis-ik-7.17.18.zip
# 删除压缩包
rm -rf elasticsearch-analysis-ik-7.17.18.zip
# 重启ES生效
ps -ef | grep elasticsearch | grep -v grep | awk '{print $2}' | xargs kill -9
/usr/local/elasticsearch/bin/elasticsearch -d7.3.4 配置Systemd 服务
vim /etc/systemd/system/elasticsearch.service[Unit]
Description=Elasticsearch
Documentation=https://www.elastic.co
Wants=network-online.target
After=network-online.target
[Service]
Type=forking
User=es
Group=es
# 你的安装目录(必须和你实际路径一致)
Environment=ES_HOME=/usr/local/elasticsearch
Environment=ES_PATH_CONF=/usr/local/elasticsearch/config
Environment=ES_PID_DIR=/usr/local/elasticsearch
Environment=ES_START_SCRIPT=/usr/local/elasticsearch/bin/elasticsearch
ExecStart=/usr/local/elasticsearch/bin/elasticsearch -d
ExecStop=/usr/local/elasticsearch/bin/elasticsearch-stop
Restart=on-failure
RestartSec=5s
# 标准限制
LimitNOFILE=65535
LimitNPROC=4096
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl start elasticsearch
systemctl enable elasticsearch7.3.5 验证
curl http://192.168.117.142:92007.4 Kibana 7.17.18 部署
7.4.1 安装
cd /usr/local/src
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.17.18-linux-x86_64.tar.gz
tar -zxvf kibana-7.17.18-linux-x86_64.tar.gz
mv kibana-7.17.18-linux-x86_64 /usr/local/kibana
chown -R es:es /usr/local/kibana7.4.2 修改配置
vim /usr/local/kibana/kibana-7.17.18-linux-x86_64/config/kibana.ymlserver.host: "0.0.0.0"
server.port: 5601
elasticsearch.hosts: ["http://192.168.117.142:9200"]
elasticsearch.username: "es"
i18n.locale: "zh-CN"
7.4.3 配置Systemd 服务
vim /etc/systemd/system/kibana.service [Unit]
Description=Kibana
Documentation=https://www.elastic.co/
After=elasticsearch.service
[Service]
User=es
Group=es
WorkingDirectory=/usr/local/kibana/kibana-7.17.18-linux-x86_64
ExecStart=/usr/local/kibana/kibana-7.17.18-linux-x86_64/bin/kibana
Restart=always
RestartSec=10
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl start kibana
systemctl enable kibana7.4.4 验证
访问:http://192.168.117.142:5601
八、Python 数据处理层
8.1 日志清洗脚本
部署位置:kafka1/kafka2/kafka3
功能描述:
-
作为 Kafka Consumer 订阅
nginxlogTopic,消费原始 Nginx 日志 -
解析日志格式,提取结构化字段:客户端 IP、请求时间、请求方法、URL、HTTP 状态码、省份地区、运营商等
-
数据清洗:标准化时间格式、过滤无效记录、字段类型转换
-
分流输出:将清洗后的数据同时发送至 Elasticsearch(192.168.117.142,实时索引)和 MySQL(192.168.117.141,持久化存储)
运行方式:后台持续运行,建议 Systemd 托管
9.2 数据入库脚本
部署位置:与日志清洗脚本同节点
功能描述:
-
接收日志清洗脚本的输出数据,建立 MySQL(192.168.117.141)连接池
-
执行批量 INSERT 操作,将结构化日志写入指定数据表
九、智能监控与 AIOps 闭环层
9.1 Ollama 部署
部署节点:ollama(143)
9.1.1 安装ollama
curl -fsSL https://ollama.com/install.sh | sh9.1.2 拉取模型
ollama pull qwen3.5:2b9.2 日志监控脚本(monitor.py)
部署节点:ollama (143)
功能描述:
-
定时巡检:每一分钟查询 Elasticsearch(192.168.117.142)一分钟内日志数据
-
数据聚合:统计时间窗口内的 HTTP 状态码分布(4xx 错误数、5xx 错误数)、请求量 QPS、平均响应时间、错误率百分比
-
AI 决策:将聚合指标通过本地 API 发送至 Ollama (qwen3.5:2b),Prompt 要求模型判断是否存在异常,返回布尔值
-
分支处理:
-
返回
false:系统正常,记录巡检日志,进入下一轮循环 -
返回
true:触发异常处理流程,构造异常上下文(异常类型、时间范围、关键指标)
-
-
联动诊断:HTTP 调用 OpenClaw 服务(192.168.117.158),传递异常上下文
-
告警闭环:接收 OpenClaw 返回的诊断结果,整合后通过 SMTP 发送 QQ 邮件告警
9.3 OpenClaw 自动化运维
部署位置:openclaw (158)
部署过程:参考OpenClaw源码安装-CSDN博客
功能描述:
-
服务监听:暴露 HTTP/gRPC 接口,接收 monitor.py 的异常通知
-
诊断执行:根据异常类型自动执行预定义诊断命令集:
-
检查后端 Flask 服务状态(
systemctl status或ps查询) -
查看 Nginx(192.168.117.137)最近错误日志(
tail -n 100) -
检测后端服务器端口连通性(
nc或curl探测 5000 端口) -
验证服务进程存活状态
-
-
结果返回:将诊断输出格式化 JSON 返回给 monitor.py
十、项目结构总结
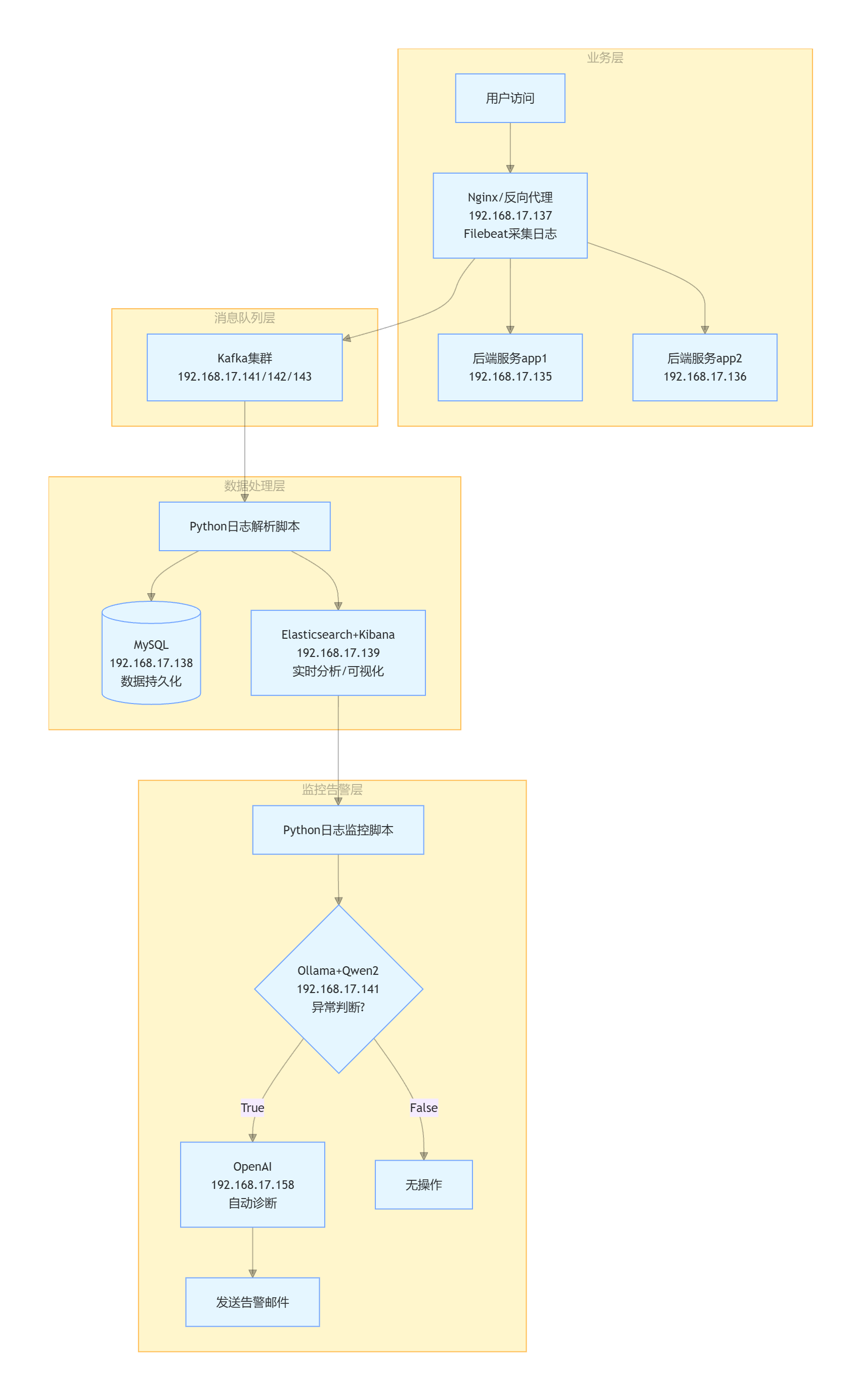
十一、项目总结
本文完整搭建了一套企业级日志收集、存储、分析、监控、智能告警平台,包含:
-
日志采集:Filebeat 实时监控 Nginx 日志,低资源占用
-
削峰解耦:Kafka KRaft 3节点集群,无需 ZooKeeper
-
存储双写:Elasticsearch 实时分析 + MySQL 持久化归档
-
可视化:Kibana 日志检索与图表展示
-
智能监控:Ollama 本地大模型(Qwen3.5:2b)异常判断
-
自动化排障:OpenClaw 诊断服务状态、端口、日志,邮件告警闭环
整套架构采用 10 台 CentOS Stream 10 服务器,组件版本经过兼容性验证,全流程可复现,适合作为企业级运维平台实践项目。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)