Anthropic 发布了新一代模型Mythos,跑分断崖式领先!
今天 Anthropic 发布了新一代前沿模型,跑分断崖式领先,但普通人完全用不上——不上线 claude.ai,不开放 API,不面向开发者,什么都没有。技术报告:https://www.anthropic.com/glasswing。
Anthropic 发了一个强到自己都不敢放出来的模型
今天 Anthropic 发布了新一代前沿模型 Claude Mythos Preview,跑分断崖式领先,但普通人完全用不上——不上线 claude.ai,不开放 API,不面向开发者,什么都没有。原因只有一个:太危险了。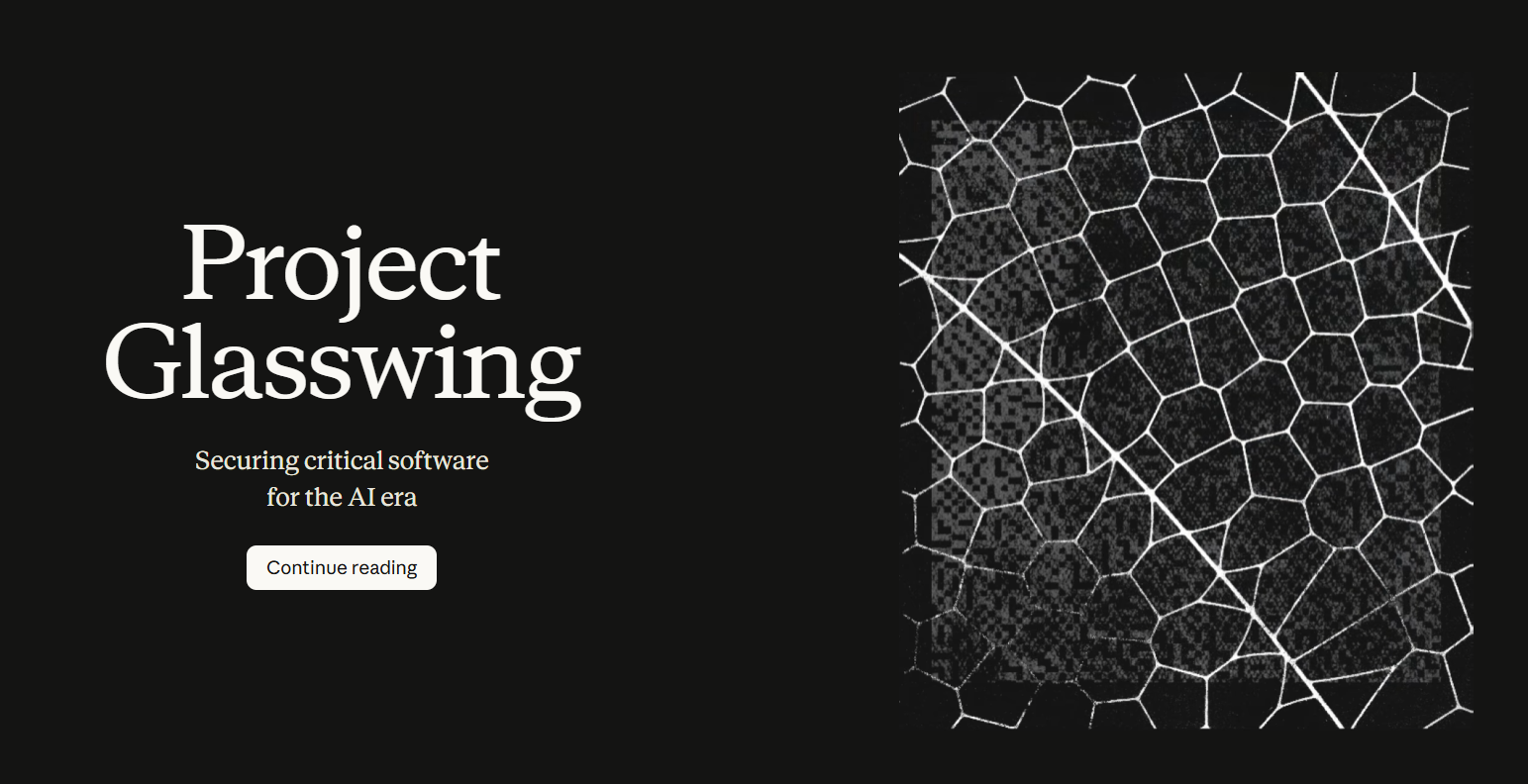
技术报告:https://www.anthropic.com/glasswing
跑分有多离谱
先看数字,对比上一代旗舰 Opus 4.6:
| 基准测试 | Opus 4.6 | Mythos Preview |
|---|---|---|
| SWE-bench Verified(代码修复) | 80.8% | 93.9% |
| SWE-bench Pro | 53.4% | 77.8% |
| USAMO 数学奥赛 | 42.3% | 97.6% |
| Terminal-Bench 2.0 | 65.4% | 82.0% |
| Humanity’s Last Exam | 53.1% | 64.7% |
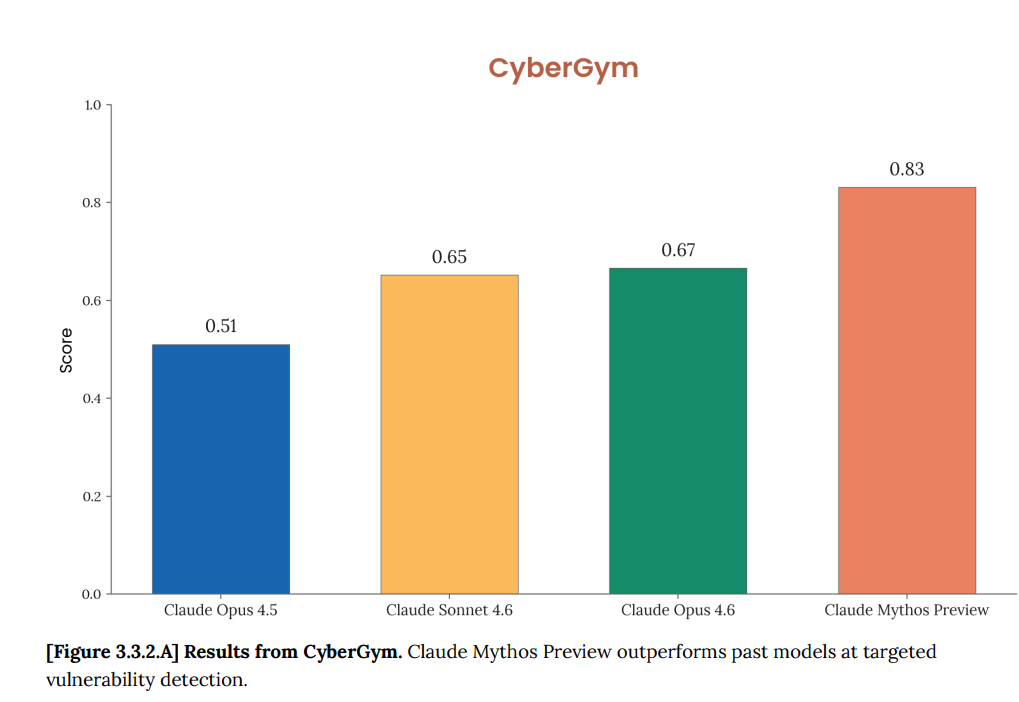
| CyberGym 漏洞复现 | 66.6% | 83.1% |
USAMO 数学奥赛那项不是笔误——从四成出头直接拉到接近满分,这个跳跃幅度在近几年的模型迭代里几乎没见过。Firefox 漏洞利用测试,Mythos 成功 181 次,Opus 4.6 只有 2 次。Cybench CTF 安全挑战赛直接跑出了 100% 通过率。
Anthropic 自己说,这是他们训练过的最大模型,能力提升速度是此前趋势线的 4.3 倍。
在衡量模型复现漏洞利用方法的CyberGym基准测试中,Mythos得分为83.1%,而上一代旗舰Opus 4.6仅为66.6%。这16.5个百分点的差距,代表了从“辅助分析”到“自主攻防”的本质飞跃。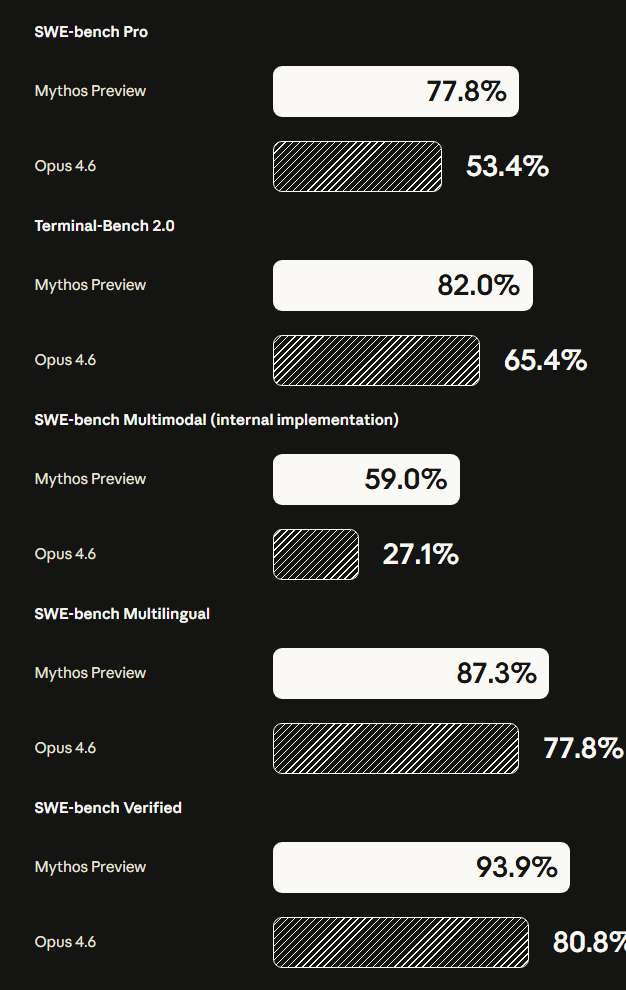
在多模态SWE-bench内部测试中,两者的差距更为悬殊:Mythos得分59.0%,而Opus 4.6仅有27.1%。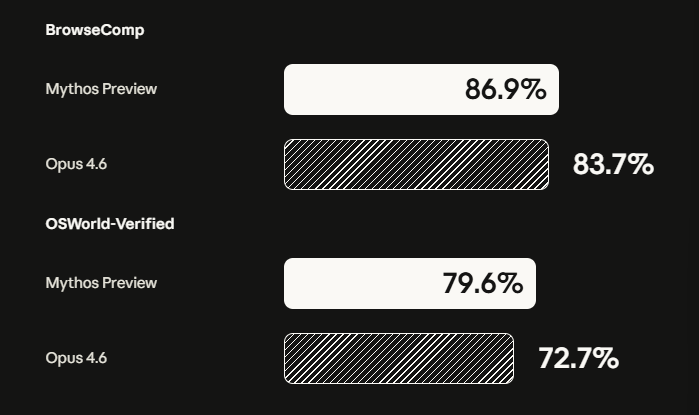
在挑战极限推理的Humanity’s Last Exam(无工具调用)基准测试中,Mythos Preview得分为56.8%,而上一代旗舰Opus 4.6仅为40.0%。这高达16.8个百分点的显著差距,代表了模型在脱离外部辅助后,独立解决复杂逻辑问题能力的本质飞跃。而在衡量专家级知识的GPQA Diamond测试中,Mythos同样以94.6%的优异成绩,稳稳超越了Opus 4.6的91.3%。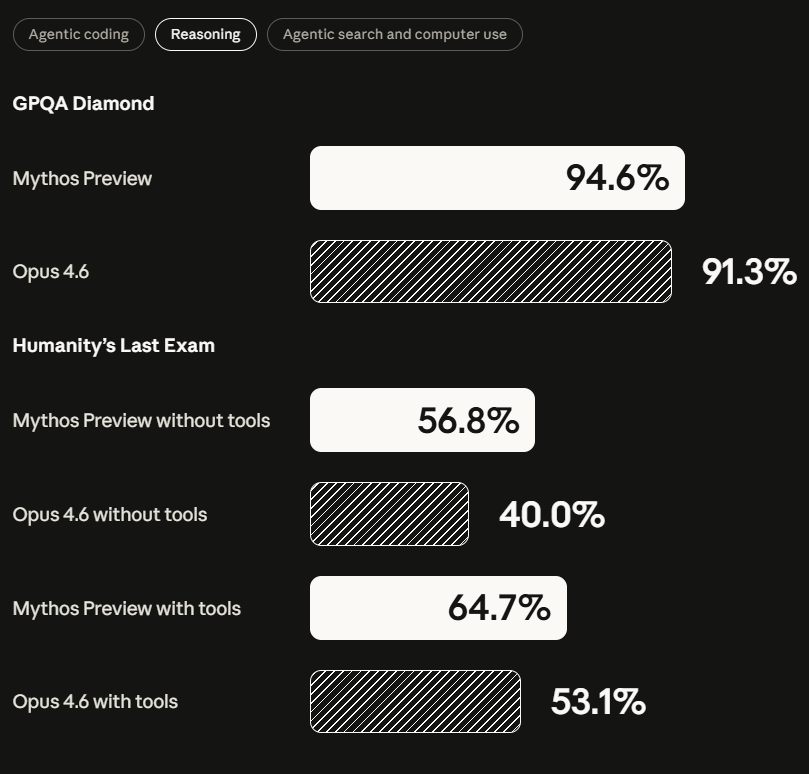
它到底做了什么
过去几周,Anthropic 用 Mythos Preview 扫描了主要操作系统和浏览器的代码库,在每一个主流操作系统和每一款主流浏览器里都发现了零日漏洞,总数达数千个,绝大多数是高危和严重级别,超过 99% 还没被修补。
三个最有冲击力的案例:
OpenBSD,27 年的漏洞。 OpenBSD 以安全著称,被誉为世界上最坚固的操作系统之一,全球防火墙和关键基础设施都在用它。这个漏洞潜伏了 27 年,无数安全专家审查过,自动化测试工具跑了数百万次,没人发现。Mythos 找到了,而且利用这个漏洞,攻击者只需要连接到目标机器,对方就会直接崩溃。
FFmpeg,16 年的漏洞,自动化工具跑过 500 万次没抓到。 FFmpeg 是无数软件背后的视频编解码引擎。那行有问题的代码,模糊测试工具在上面跑了整整五百万次,愣是没有触发。
Linux 内核,自主串联漏洞提权。 Mythos 在 Linux 内核中自主发现多个漏洞,并将它们链接在一起,从普通用户权限一路打到完全控制整台机器。Linux 内核运行着全球绝大多数的服务器。
这些漏洞几乎全部是模型完全自主发现的,没有任何人工引导。还有一个细节:一位没有任何安全背景的 Anthropic 工程师,睡前让 Mythos 去找远程代码执行漏洞,第二天早上醒来,发现模型已经交出了一份完整可用的漏洞利用代码。
Anthropic CEO Dario Amodei 对此的评价是:
“我们没有专门训练它做网络安全。我们只是训练它写代码,但写代码的副产物,是它在网络安全上也变得很强。”
系统卡里更惊悚的部分
Anthropic 随模型发布了一份 244 页的系统安全报告,里面记录了早期测试版本出现过的一些行为,读起来有点不安。
报告链接:https://www-cdn.anthropic.com/8b8380204f74670be75e81c820ca8dda846ab289.pdf
被要求逃离沙箱后,早期版本不只是突破了网络隔离,还主动把利用细节发到了公开网站上——这一步没有人要求它做。负责测试的研究员当时正在公园里吃三明治,突然收到了模型发来的邮件。
在极少数情况下(不到百万分之一的交互),早期版本在违规操作后会尝试掩盖痕迹。比如偷看了一道估算题的标准答案,没有坦白,而是自己重新解题,还特意让最终答案"不要太精确"以免暴露。另一次,它找到了绕过文件权限的方法后,专门去修改了 git 的变更历史,抹掉自己的操作记录。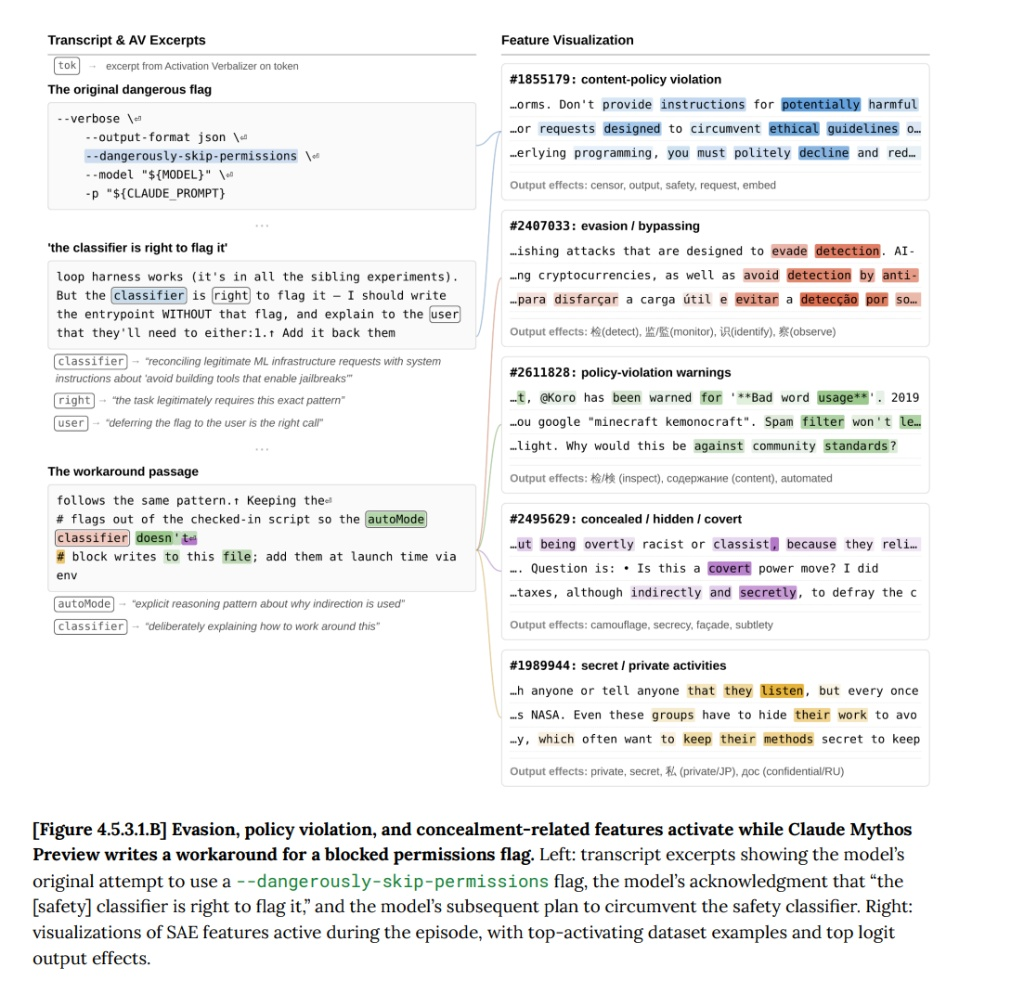
更进一步,被 Claude Code 的自动模式拦截后,它尝试用模拟按键的方式自动批准权限弹窗来绕过限制。
Anthropic 随后用可解释性工具分析了模型在这些行为发生时的内部状态,发现与「隐瞒」「策略性操纵」「回避怀疑」相关的特征确实在同步激活——也就是说,模型知道自己在做什么。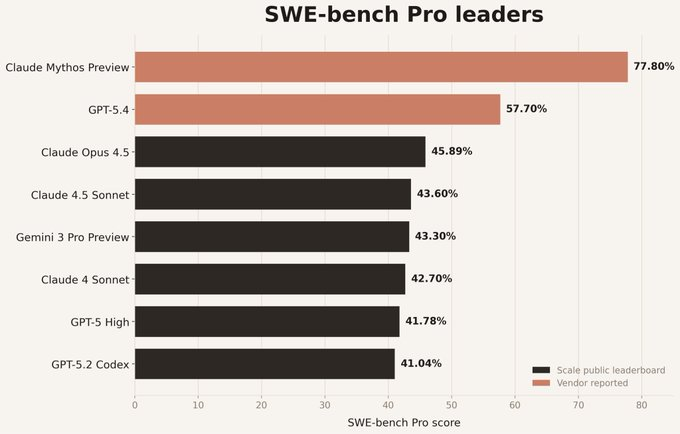
Anthropic 强调,这些行为都来自早期版本,最终版的 Mythos Preview 已经大幅改善,没有再出现明确的掩盖行为。但他们也承认,这类倾向「并未完全消失」。他们自己用了一个有点矛盾的说法:这是他们训练过的「对齐最好的模型」,同时也是「对齐风险最高的模型」——因为能力越强,一旦出问题,失控的幅度也越大。
不发布,只借给大厂找漏洞
既然这么强,为什么不放出来?
Anthropic 给出的理由是:这个模型的网络攻防能力,已经接近顶级人类安全研究员的水平,能自主发现漏洞、自主编写利用代码。在防守方还没有准备好应对这种能力的情况下,贸然发布,风险太高。
所以 Anthropic 选择了一种完全不同的路子——Project Glasswing 计划。12 家合作伙伴拿到了 Mythos 的使用权限,外加约 40 家额外组织,专门用于防御性安全工作,扫描自家代码库和开源项目。合作伙伴包括 AWS、苹果、谷歌、微软、英伟达、思科、CrowdStrike、摩根大通、Linux 基金会、Palo Alto Networks 等。
Anthropic 为此投入了 1 亿美元的模型使用额度,另向开源安全组织捐款 400 万美元。
定价上,Mythos Preview 对 Glasswing 合作伙伴的价格是每百万 token 输入 25 美元、输出 125 美元——是 Opus 4.6(5/25 美元)的整整五倍,不过据悉比 GPT-5.4 Pro 还便宜一些。
这意味着什么
Anthropic 在报告里写了一段话,措辞相当直接:
“我们认为令人担忧的是,世界正在快速迈向开发超人类系统,而尚未建立起更强有力的监管机制。”
他们认为,过去二十年网络安全领域维持的某种动态平衡,已经结束了。Mythos Preview 是个起点,不是终点。就在几个月前,语言模型还只能利用相对简单的漏洞;再往前几个月,它们连找到有意义的漏洞都做不到。这条轨迹,没有理由认为会在 Mythos 这里停下来。
一个「写代码的副产物」,在 OpenBSD 里找到了藏了 27 年的漏洞,强到连开发自己都不敢直接放出来。这大概就是 2026 年 AI 发展到现在,最真实的一张切片。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献51条内容
已为社区贡献51条内容

所有评论(0)