InfiniteTalk Windows 非官方方式部署|Python3.12+RTX3090 实测可跑,flash-attn 编译避坑指南
本文详细介绍了在Windows系统上非官方部署InfiniteTalk多模态对话项目的完整流程。重点解决了flash-attn 2.8.4在Python3.12+PyTorch2.10.0+RTX3090环境下的编译难题,提供了从环境配置、依赖安装到模型下载的详细步骤。文章包含针对CUDA13.1和RTX3090的优化方案,并附有flash-attn编译验证脚本和常见问题解决方案,确保项目稳定运行
🔥InfiniteTalk Windows 非官方方式部署|Python3.12+RTX3090 实测可跑,flash-attn 编译避坑指南
Windows 下编译 flash-attn 2.8.4 完整复盘教程 Python 3.12 + PyTorch 2.10.0+cu130 + CUDA 13.1 + RTX 3090
前言
GitHub - MeiGen-AI/InfiniteTalk: Unlimited-length talking video ...
InfiniteTalk 是一款融合语音交互、视频生成的多模态对话项目,在 Windows 上部署最大难点在于 flash-attn 编译。本文分享 InfiniteTalk Windows 非官方本地部署全流程,适配 Python3.12+PyTorch2.10.0+cu130+CUDA13.1,针对 RTX3090 优化,结合 flash-attn 2.8.4 编译成果,全程实操可复现,避开所有部署踩坑点,解决新手最头疼的环境配置、模型下载等问题。
本文采用非官方手动部署方案,依赖前文编译好的 flash-attn 2.8.4,全程避坑,可在 RTX 3090 + CUDA 13.1 环境下稳定运行,适合 AI 爱好者、开发者参考实操。

一、环境说明
本文全程基于以下环境实测,确保部署流程可复现,适配大多数 RTX 3090 用户,也是 InfiniteTalk 本地部署 的最优环境组合:
-
系统:Windows 11(64位,Windows 10 也可兼容)
-
Python:3.12(实测适配,避免版本过高/过低导致的依赖冲突)
-
CUDA:13.1(与 PyTorch 2.10.0+cu130 小版本兼容,不影响运行)
-
Torch:2.10.0+cu130(GPU 版,确保PyTorch2.10.0+cu130 安装 正确,是 GPU 加速的核心)
-
显卡:RTX 3090(24GB 显存,满足 14B 模型运行需求,适配 RTX3090 AI部署)
-
编译依赖:flash-attn 2.8.4(自行编译,解决部署核心痛点,具体流程见引用文章)
二、前置准备
部署前请确保已完成以下准备工作,避免后续部署报错,这也是 InfiniteTalk Windows部署 的基础:
-
安装 Visual Studio 2022 + Windows SDK(用于 flash-attn 编译,不可或缺)
-
CUDA 13.1 安装并配置系统环境(确保 nvcc 可正常调用,适配 CUDA13.1 实操)
-
已成功编译 flash-attn 2.8.4(部署核心前提,解决最复杂的编译难题)
编译教程参考(已发布,可直接跳转学习):
👉 Windows 下编译 flash-attn 2.8.4 完整复盘教程,解决所有 flash-attn 2.8.4 编译 相关问题。
Windows 下编译 flash-attn 2.8.4 完整复盘教程 Python 3.12 + PyTorch 2.10.0+cu130 + CUDA 13.1 + RTX 3090
三、克隆项目并创建虚拟环境
虚拟环境可隔离依赖,避免与系统 Python 环境冲突,是Python3.12 部署AI项目 的最佳实践,步骤如下:
git clone https://github.com/MeiGen-AI/InfiniteTalk.git
cd InfiniteTalk
创建并激活虚拟环境:
python -m venv --copies .venv
.\.venv\Scripts\Activate.ps1
【已解决】ModuleNotFoundError: No module named ‘pkg_resources‘ | Setuptools 82.0.0+ 版本断层深度复盘
四、安装 GPU 版 PyTorch
必须安装 GPU 版 PyTorch,否则无法实现 GPU 加速,全程使用 cu130 版本,确保与 CUDA 13.1 兼容,具体命令如下:
python -m pip install --upgrade pip
pip install torch==2.10.0 torchvision==0.25.0 torchaudio==2.10.0 `
--index-url https://download.pytorch.org/whl/cu130
五、安装基础编译依赖(用于编译 flash-attn)
这些依赖是 flash-attn 2.8.4 编译 的前提,必须完整安装,避免编译过程中报错:
pip install misaki[en] ninja psutil packaging wheel einops build
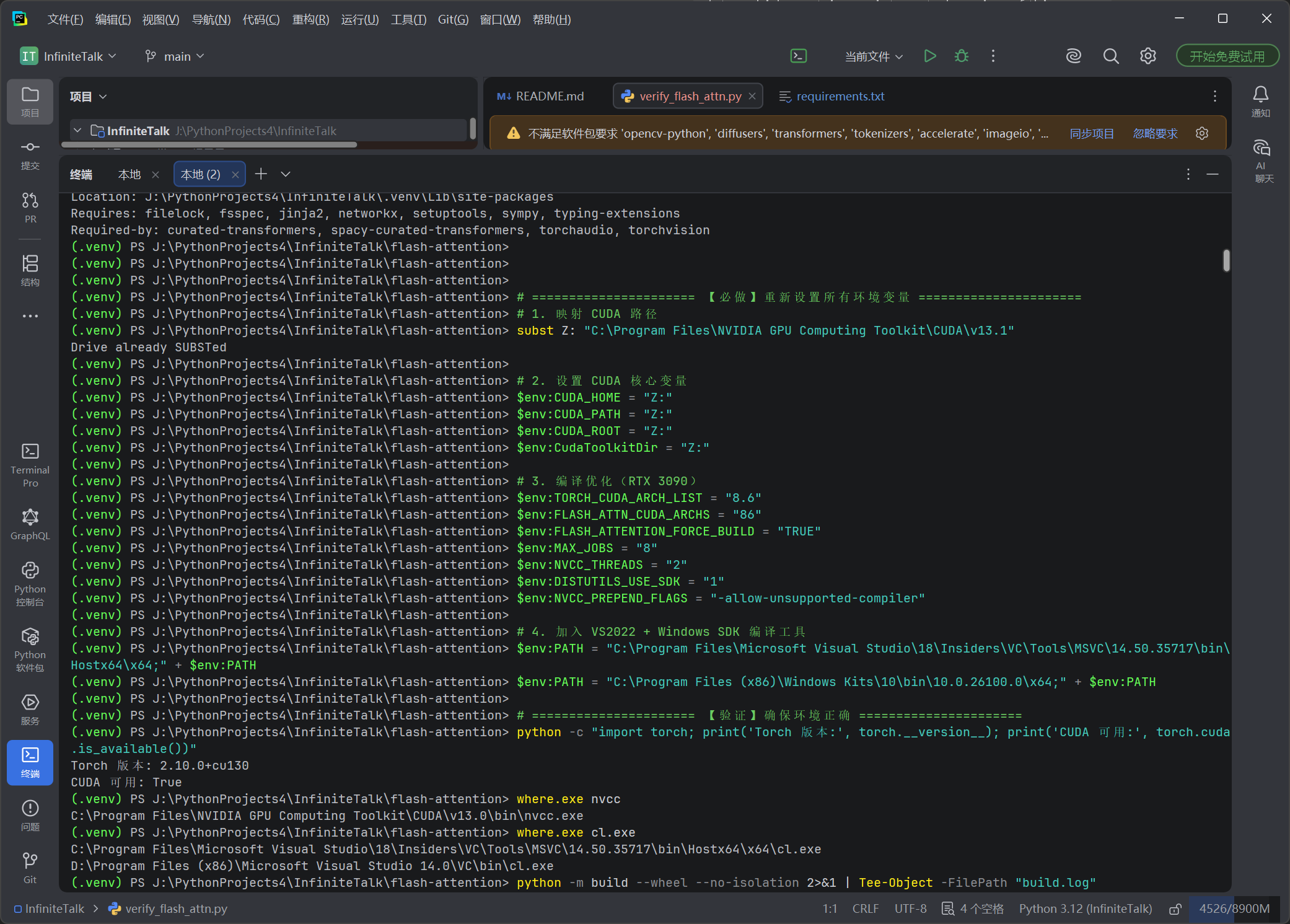
六、编译并安装 flash-attn 2.8.4(核心步骤)

此步骤是 InfiniteTalk 部署的核心难点,也是最容易踩坑的环节,完整流程请直接参考前文博客(已详细复盘所有编译细节和避坑技巧):
👉 Windows 下编译 flash-attn 2.8.4 完整复盘教程,解决所有 flash-attn 编译失败解决 相关问题。
简单复述关键命令(仅用于快速回顾,详细步骤请参考上述博客):
git clone https://github.com/Dao-AILab/flash-attention.git
cd flash-attention
git submodule update --init --recursive
# CUDA 路径映射(解决路径过长识别异常问题)
subst Z: "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v13.1"
$env:CUDA_HOME = "Z:"
# 编译优化配置(RTX 3090 专属,提升编译效率和兼容性)
$env:TORCH_CUDA_ARCH_LIST = "8.6"
$env:FLASH_ATTN_CUDA_ARCHS = "86"
$env:FLASH_ATTENTION_FORCE_BUILD = "TRUE"
$env:MAX_JOBS = "8"
$env:NVCC_THREADS = "2"
$env:DISTUTILS_USE_SDK = "1"
$env:NVCC_PREPEND_FLAGS = "-allow-unsupported-compiler"
# VS 编译器路径配置(确保 cl.exe 可正常调用)
$env:PATH = "C:\Program Files\Microsoft Visual Studio\18\Insiders\VC\Tools\MSVC\14.50.35717\bin\Hostx64\x64;" + $env:PATH
$env:PATH = "C:\Program Files (x86)\Windows Kits\10\bin\10.0.26100.0\x64;" + $env:PATH
# 开始编译(生成 wheel 包)
python -m build --wheel --no-isolation
# 安装编译好的 flash-attn 包
pip install dist\flash_attn-2.8.4-cp312-cp312-win_amd64.whl
# 返回项目根目录,继续后续部署
cd ..
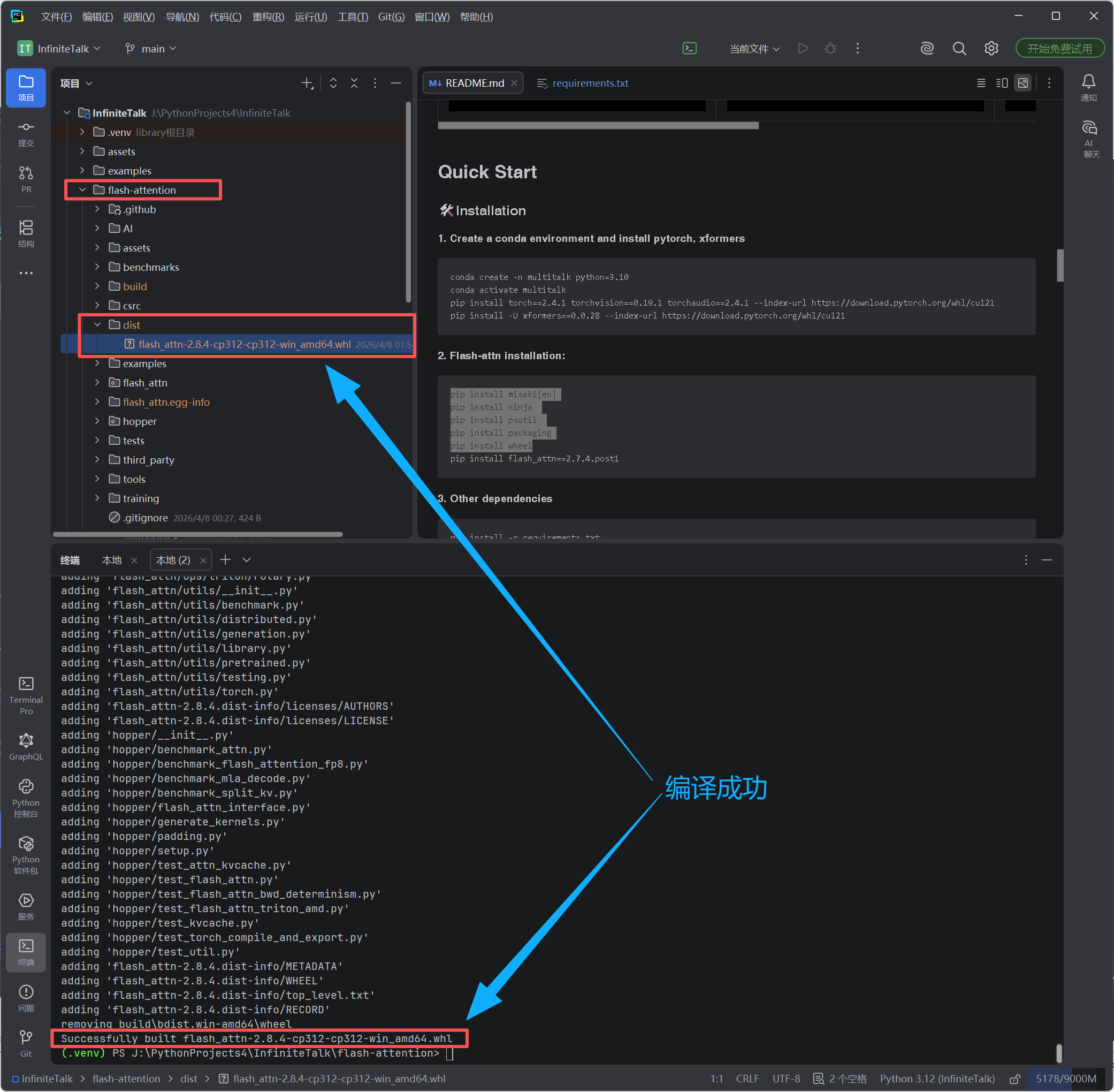
七、安装项目依赖
安装 InfiniteTalk 项目所需的所有依赖,确保项目可正常启动,避免 InfiniteTalk 启动失败:
安装前,排查 requirements.txt 文件的内容,把“==”“<=”这两种指定一律修改为“>=”,避免版本锁死循环冲突报错!
pip install -r requirements.txt --extra-index-url https://download.pytorch.org/whl/cu130
额外安装音频、视频处理库(项目核心功能依赖,不可或缺):
pip install librosa ffmpeg
八、下载全部模型权重(解决 InfinteTalk 模型下载缓慢问题)
模型权重是项目运行的核心,需通过 hf 命令下载,确保所有模型完整下载,否则项目无法正常运行,具体步骤如下:
首先安装 huggingface-cli(用于执行 hf 下载命令):
pip install huggingface-hub
依次执行以下命令,下载所有所需模型(建议逐一执行,避免下载中断,解决 InfiniteTalk 模型下载 相关问题):
# 视频生成模型 Wan2.1-I2V-14B-480P(多模态核心模型)
hf download Wan-AI/Wan2.1-I2V-14B-480P --local-dir ./weights/Wan2.1-I2V-14B-480P
# 中文语音识别模型(语音交互核心)
hf download TencentGameMate/chinese-wav2vec2-base --local-dir ./weights/chinese-wav2vec2-base
# 修复模型文件(解决语音模型加载失败问题)
hf download TencentGameMate/chinese-wav2vec2-base model.safetensors --revision refs/pr/1 --local-dir ./weights/chinese-wav2vec2-base
# InfiniteTalk 核心模型(项目运行主模型)
hf download MeiGen-AI/InfiniteTalk --local-dir ./weights/InfiniteTalk
所有模型会自动下载到 ./weights/ 目录,无需手动修改路径,项目会自动读取。
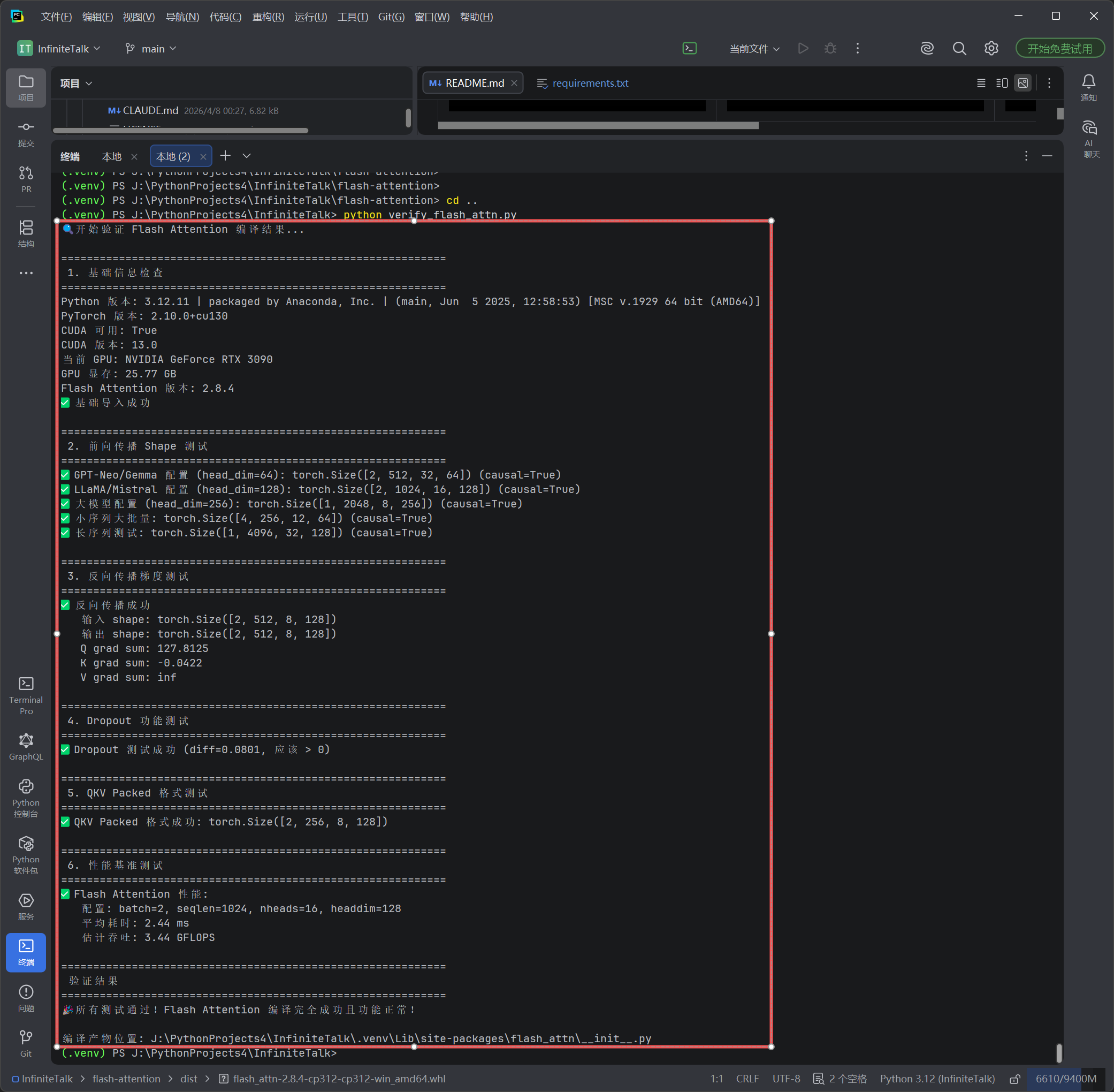
九、验证 flash-attn 正常可用
验证 flash-attn 编译安装成功,避免后续项目启动时因 flash-attn 异常报错,这是 InfiniteTalk 本地部署 的关键验证步骤:
verify_flash_attn.py
新建 verify_flash_attn.py 文件,复制以下代码:
#!/usr/bin/env python3
"""
Flash Attention Windows 编译验证脚本
全面测试前向/反向传播、不同配置和特性
"""
import sys
import torch
import time
# 关键:必须同时导入模块和函数
import flash_attn # 这行获取版本号
from flash_attn import flash_attn_func, flash_attn_qkvpacked_func
def print_banner(text):
print(f"\n{'=' * 60}")
print(f" {text}")
print(f"{'=' * 60}")
def check_basic_import():
"""测试1: 基础导入和版本"""
print_banner("1. 基础信息检查")
print(f"Python 版本: {sys.version}")
print(f"PyTorch 版本: {torch.__version__}")
print(f"CUDA 可用: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"CUDA 版本: {torch.version.cuda}")
print(f"当前 GPU: {torch.cuda.get_device_name(0)}")
print(f"GPU 显存: {torch.cuda.get_device_properties(0).total_memory / 1e9:.2f} GB")
print(f"Flash Attention 版本: {flash_attn.__version__}")
print("✅ 基础导入成功")
def test_forward_shapes():
"""测试2: 不同 head_dim 和 shape 的前向传播"""
print_banner("2. 前向传播 Shape 测试")
device = 'cuda'
dtype = torch.float16 # FlashAttention 只支持 fp16/bf16
test_cases = [
# (batch, seqlen, num_heads, head_dim, description)
(2, 512, 32, 64, "GPT-Neo/Gemma 配置 (head_dim=64)"),
(2, 1024, 16, 128, "LLaMA/Mistral 配置 (head_dim=128)"),
(1, 2048, 8, 256, "大模型配置 (head_dim=256)"),
(4, 256, 12, 64, "小序列大批量"),
(1, 4096, 32, 128, "长序列测试"),
]
for batch, seqlen, nheads, headdim, desc in test_cases:
try:
q = torch.randn(batch, seqlen, nheads, headdim, device=device, dtype=dtype)
k = torch.randn(batch, seqlen, nheads, headdim, device=device, dtype=dtype)
v = torch.randn(batch, seqlen, nheads, headdim, device=device, dtype=dtype)
# 测试因果 mask
out = flash_attn_func(q, k, v, causal=True)
expected_shape = (batch, seqlen, nheads, headdim)
assert out.shape == expected_shape, f"Shape mismatch: {out.shape} vs {expected_shape}"
print(f"✅ {desc}: {out.shape} (causal=True)")
except Exception as e:
print(f"❌ {desc}: {e}")
return False
return True
def test_backward_grad():
"""测试3: 反向传播梯度计算"""
print_banner("3. 反向传播梯度测试")
device = 'cuda'
dtype = torch.float16
batch, seqlen, nheads, headdim = 2, 512, 8, 128
# 创建需要梯度的输入
q = torch.randn(batch, seqlen, nheads, headdim, device=device, dtype=dtype, requires_grad=True)
k = torch.randn(batch, seqlen, nheads, headdim, device=device, dtype=dtype, requires_grad=True)
v = torch.randn(batch, seqlen, nheads, headdim, device=device, dtype=dtype, requires_grad=True)
try:
out = flash_attn_func(q, k, v, causal=False)
loss = out.sum()
loss.backward()
# 检查梯度是否存在
assert q.grad is not None, "Q gradient is None"
assert k.grad is not None, "K gradient is None"
assert v.grad is not None, "V gradient is None"
print(f"✅ 反向传播成功")
print(f" 输入 shape: {q.shape}")
print(f" 输出 shape: {out.shape}")
print(f" Q grad sum: {q.grad.sum().item():.4f}")
print(f" K grad sum: {k.grad.sum().item():.4f}")
print(f" V grad sum: {v.grad.sum().item():.4f}")
return True
except Exception as e:
print(f"❌ 反向传播失败: {e}")
return False
def test_dropout():
"""测试4: Dropout 功能"""
print_banner("4. Dropout 功能测试")
device = 'cuda'
dtype = torch.float16
torch.manual_seed(42) # 固定种子确保可复现
batch, seqlen, nheads, headdim = 2, 256, 8, 64
q = torch.randn(batch, seqlen, nheads, headdim, device=device, dtype=dtype)
k = torch.randn(batch, seqlen, nheads, headdim, device=device, dtype=dtype)
v = torch.randn(batch, seqlen, nheads, headdim, device=device, dtype=dtype)
try:
# 训练模式(启用 dropout)
out_train = flash_attn_func(q, k, v, dropout_p=0.5, causal=False)
# 推理模式(dropout=0)
out_eval = flash_attn_func(q, k, v, dropout_p=0.0, causal=False)
# 两次前向应该不同(因为 dropout 随机)
diff = (out_train - out_eval).abs().mean().item()
print(f"✅ Dropout 测试成功 (diff={diff:.4f}, 应该 > 0)")
return True
except Exception as e:
print(f"❌ Dropout 测试失败: {e}")
return False
def test_varlen_qkvpacked():
"""测试5: QKV packed 格式(部分模型使用)"""
print_banner("5. QKV Packed 格式测试")
device = 'cuda'
dtype = torch.float16
batch, seqlen, nheads, headdim = 2, 256, 8, 128
# 创建 packed qkv: [batch, seqlen, 3, nheads, headdim]
qkv = torch.randn(batch, seqlen, 3, nheads, headdim, device=device, dtype=dtype)
try:
out = flash_attn_qkvpacked_func(qkv, causal=False)
expected_shape = (batch, seqlen, nheads, headdim)
assert out.shape == expected_shape
print(f"✅ QKV Packed 格式成功: {out.shape}")
return True
except Exception as e:
print(f"❌ QKV Packed 测试失败: {e}")
return False
def test_performance():
"""测试6: 性能基准(与标准 attention 对比)"""
print_banner("6. 性能基准测试")
if not torch.cuda.is_available():
print("⚠️ 跳过性能测试(无 CUDA)")
return True
device = 'cuda'
dtype = torch.float16
batch, seqlen, nheads, headdim = 2, 1024, 16, 128
q = torch.randn(batch, seqlen, nheads, headdim, device=device, dtype=dtype)
k = torch.randn(batch, seqlen, nheads, headdim, device=device, dtype=dtype)
v = torch.randn(batch, seqlen, nheads, headdim, device=device, dtype=dtype)
# 预热
for _ in range(10):
_ = flash_attn_func(q, k, v)
torch.cuda.synchronize()
# 测试 Flash Attention
start = time.time()
for _ in range(50):
out_flash = flash_attn_func(q, k, v, causal=True)
torch.cuda.synchronize()
flash_time = (time.time() - start) / 50 * 1000 # ms
print(f"✅ Flash Attention 性能:")
print(f" 配置: batch={batch}, seqlen={seqlen}, nheads={nheads}, headdim={headdim}")
print(f" 平均耗时: {flash_time:.2f} ms")
print(f" 估计吞吐: {batch * seqlen * nheads * headdim * 2 / (flash_time / 1000) / 1e9:.2f} GFLOPS")
return True
def main():
print("🔍 开始验证 Flash Attention 编译结果...")
try:
check_basic_import()
success = True
success &= test_forward_shapes()
success &= test_backward_grad()
success &= test_dropout()
success &= test_varlen_qkvpacked()
success &= test_performance()
print_banner("验证结果")
if success:
print("🎉 所有测试通过!Flash Attention 编译完全成功且功能正常!")
print(f"\n编译产物位置: {flash_attn.__file__}")
return 0
else:
print("⚠️ 部分测试失败,请检查错误信息")
return 1
except Exception as e:
print(f"\n💥 验证过程出错: {e}")
import traceback
traceback.print_exc()
return 1
if __name__ == "__main__":
sys.exit(main())运行验证脚本:
python verify_flash_attn.py
出现“✅ 所有环境正常,flash-attn 编译安装成功!”即为验证通过。
十、启动项目
所有准备工作完成,执行以下命令启动 InfiniteTalk,一键启动,无需额外配置:
python app.py
启动成功后,终端会显示以下内容,说明项目部署成功:
Running on local URL: http://127.0.0.1:7860
打开浏览器,访问 http://127.0.0.1:7860,即可正常使用 InfiniteTalk 所有功能。
十一、常见问题(避坑指南)
整理部署过程中最常见的问题及解决方案,覆盖所有 InfiniteTalk 非官方部署教程 高频踩坑点:
-
flash-attn 编译失败:请严格参考前文编译博客,不要使用 pip 直接安装,确保 VS 编译器、CUDA 环境配置正确,解决所有 flash-attn 编译失败解决 问题。
-
模型下载缓慢/中断:模型文件较大(200G+),可设置 HF_ENDPOINT 镜像(如国内镜像),或使用模型下载工具,分次下载,避免一次性下载导致中断。
-
启动时提示显存不足:模型为 14B 规模,建议显存≥24GB(RTX 3090/4090),解决 RTX3090 显存不足 问题,可尝试关闭其他占用显存的程序。
-
PyTorch 变成 CPU 版本:重新执行第四步的 PyTorch 安装命令,确保安装的是 cu130 版本,同时检查 CUDA 环境变量配置正确。
-
语音/视频功能无法使用:确认 librosa、ffmpeg 已安装成功,若仍有问题,重新安装这两个库。
十二、总结
本文通过非官方手动部署方式,结合提前编译好的 flash-attn 2.8.4,成功在 Windows 上运行 InfiniteTalk,适配 Python3.12+PyTorch2.10.0+cu130+CUDA13.1+RTX3090 环境,全程实操可复现。
整个部署流程的核心的是 flash-attn 编译,解决了这一难点后,后续依赖安装、模型下载、项目启动均能顺利完成,完美实现 InfiniteTalk 本地部署,让大家轻松体验多模态对话的乐趣。
📌 本文全程实测可复现,解决了 InfiniteTalk 在 Windows 上部署的核心痛点——flash-attn 编译难题,搭配前文《Windows 下编译 flash-attn 2.8.4 完整复盘教程》,两步搞定多模态AI项目部署,助力大家轻松完成 InfiniteTalk 部署。
如果部署过程中遇到 flash-attn 编译、模型下载、启动失败等问题,可参考我的另一篇详细复盘:
✨ 收藏本文,后续将持续更新 AI 项目本地部署实操(含多模态、大模型),避开所有踩坑点,让新手也能轻松部署各类AI项目,掌握 Python3.12 部署AI项目、CUDA13.1 实操 等实用技能。
💬 评论区留言你的部署遇到的问题,我会逐一回复解答;关注我,获取更多 AI 部署、环境配置、编译优化实操教程,解锁更多 AI 项目本地部署技巧!
📚 我的专栏【AI 本地部署实操系列专栏】
专注于 Windows/Linux 系统 AI 项目本地部署,涵盖大模型、多模态、语音/视频类项目,全程实操、避坑为主,拒绝理论空谈,重点分享flash-attn 2.8.4 编译、InfiniteTalk 部署、RTX3090 AI部署等实用内容。
专栏内已更新:flash-attn 编译、InfiniteTalk 部署,后续将持续更新更多热门 AI 项目部署教程(如 Stable Diffusion、ChatGLM 等),适合 AI 爱好者、开发者参考学习,轻松掌握各类 AI 项目本地部署技巧。
免费专栏 | 免费订阅 |
👉 点击订阅专栏
第一时间获取最新部署教程,少走弯路,高效掌握 AI 部署技能!
Windows 部署 AI Agent - Suna 运维 | 免费专栏 | 免费订阅 |
想在 Windows 上顺利部署 AI Agent - Suna?本专栏为你揭秘!从前期环境配置(确保系统版本兼容、安装必备运行库),到安装过程中避开权限不足、依赖缺失等常见 “坑”,再到部署后的调试优化。以实战为导向,分享独家技巧,助你轻松完成 Suna 在 Windows 的部署,开启高效 AI
Docker运维实战 | 免费专栏 | 免费订阅 |
Docker 作为容器化技术的佼佼者,在软件部署与管理中至关重要。本专栏基于我大量实操经验,通过丰富实战案例,分享在不同场景下的应用技巧与优化策略,助你快速掌握 Docker 运行实践,提升项目部署与运维效率。
PyCharm 运维 | 免费专栏 | 免费订阅 |
从安装配置到高阶技巧,本专栏深度拆解 PyCharm 智能代码补全、高效调试等功能。结合大量实战项目,详解代码重构、版本控制集成,以及与 Python 库和框架的适配使用,助你快速掌握开发神器,提升 Python 开发效率。
Anaconda 运维 | 免费专栏 | 免费订阅 |
Anaconda 是数据科学利器,集成常用 Python 库,安装管理超便捷。我曾历经环境崩溃、硬盘格式化等数百次折腾,摸索出稳定高阶使用秘籍。本专栏从基础配置入手,详解环境与包管理,结合实战案例,分享数据分析、机器学习、Anaconda修复等实用技巧,助你掌握 Anaconda 核心玩法。
CUDA、cuDNN、PyTorch:深度学习环境搭建秘籍 运维 | 免费专栏 | 免费订阅 |
历经数百次配置调试,踩过无数坑,硬盘格式化都成 “家常便饭”,终得 CUDA、cuDNN、PyTorch 等深度学习工具配置与使用的独家心得。本专栏从环境搭建细节讲起,深入剖析安装、版本适配、性能优化,结合实战项目分享加速技巧,助你避开弯路,快速掌握深度学习开发核心能力。
GitHub等开源项目部署实战秘籍 AI开发运维 | 免费专栏 | 免费订阅 |
踩过无数坑,历经多次摸索,才掌握 GitHub 等开源项目部署要诀。本专栏从项目选型开始,详解环境配置、代码拉取、依赖安装等关键步骤,分享分支管理、版本控制避坑经验,结合实际案例演示部署流程,助你避开陷阱,快速实现开源项目落地。
WSL 运维:实战独门秘籍 WSL-Linux 运维 | 免费专栏 | 免费订阅 |
历经数百次配置调试,在 WSL 运维中摸爬滚打,硬盘格式化、系统崩溃都经历过,才攒下这些独家实战心得。本专栏从 WSL 安装、环境配置讲起,剖析日常运维难题,分享服务部署、性能优化、故障排除技巧,带你避开常见坑点,快速掌握 WSL 高效运维之道。
玩转 OpenClaw 免费专栏 | 免费订阅
不用聊天软件 OpenClaw 手机浏览器远程访问控制:Tailscale 配置、设备配对与常见问题全解
OpenClaw 源码部署教程:构建、坑点与启动全流程
OpenClaw 本地部署 LM Studio 全模型接入热切换教程
OpenClaw 及衍生版本官方链接整理(2026年3月最新)
OpenClaw 手机直连配置全流程
OpenClaw搭配LM Studio VS Ollama:Windows CUDA实战深度对比与完全配置指南
【OpenClaw 本地实战 Ep.4】终极提效:一劳永逸解决切换浏览器 Token 鉴权失败与断连问题
【OpenClaw 本地实战 Ep.3】突破瓶颈:强制修改 openclaw.json 解锁 32k 上下文记忆
【OpenClaw 本地实战 Ep.2】零代码对接:使用交互式向导快速连接本地 LM Studio 用 CUDA GPU 推理
【OpenClaw 本地实战 Ep.1】抛弃 Ollama?转向 LM Studio!Windows 下用 NVIDIA 显卡搭建 OpenClaw 本地极速推理服务
Windows 从源代码部署 OpenClaw
OpenClaw安装排错笔记

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献90条内容
已为社区贡献90条内容

所有评论(0)