谷歌Gemma 4 MoE实测
在Gemma 4 31B Dense版本之后,我们继续对Gemma 4系列的另一款模型——gemma-4-26b-a4b-it进行了全面评测。在当前主流大模型竞争格局中,gemma-4-26b-a4b-it作为一款MoE开源模型,其核心竞争力不在于与大参数旗舰模型比拼准确率,而在于以极低的推理成本提供可用的智能水平。需要说明的是,本次评测侧重中文场景下的综合能力考察。*数据来源:非线智能ReLE评
在Gemma 4 31B Dense版本之后,我们继续对Gemma 4系列的另一款模型——gemma-4-26b-a4b-it进行了全面评测。这是一款采用混合专家架构(MoE)的模型,总参数量260亿,但每次推理仅激活38亿参数,在保持较高智能水平的同时大幅降低推理开销。官方将其定位为"专注低延迟"的版本,与31B Dense版本形成"质量优先 vs 速度优先"的互补矩阵。
需要说明的是,本次评测侧重中文场景下的综合能力考察。与31B版本类似,Gemma 4 26B MoE的核心优势——本地部署的极速推理、原生Agent工作流、跨模态处理以及140+语言支持。
gemma-4-26b-a4b-it版本表现:
- 测试题数:约1.5万
- 总分(准确率):50.3%
- 平均耗时(每次调用):47s
- 平均token(每次调用消耗的token):799
- 平均花费(每千次调用的人民币花费):1.7
1、新旧对决
对比上一代版本(gemma-3-27b-it),gemma-4-26b-a4b-it在所有评测维度上均实现了提升,数据如下:


*数据来源:非线智能ReLE评测https://github.com/jeinlee1991/chinese-llm-benchmark
*输出价格单位: 元/百万token
- 整体性能显著提升:新版本准确率从39.0%提升至50.3%,提升了11.3个百分点,排名从第146位升至第130位。
- 法律与行政公务领域提升最为突出:从39.7%提升至62.0%(+22.3%),与31B Dense版本的表现趋势一致,表明Gemma 4系列在法规理解方面的中文能力有了整体性的改善。
- Agent与工具调用接近翻倍:从17.6%提升至33.3%(+15.7%),增幅在所有维度中排名第二。这与Gemma 4系列主打的原生Agent工作流定位高度吻合,MoE版本在该维度上甚至略高于31B Dense版本(33.3% vs 32.7%)。
- 推理与数学计算稳步提升:从43.4%提升至57.5%(+14.1%),逻辑推理能力有较为扎实的进步。
- 医疗与心理健康领域进步明显:从50.6%提升至62.1%(+11.5%),提升幅度较为可观。
- 金融领域同步提升:从56.4%提升至64.0%(+7.6%),保持了稳步改善。
- 教育领域有所改善:从29.6%提升至37.8%(+8.2%),虽然绝对值仍处于较低水平,但进步方向明确。
- 语言与指令遵从提升相对有限:从49.1%提升至52.1%(+3.0%),在所有维度中属于提升幅度最小的领域,中文复杂指令的精准理解仍是MoE版本需要优化的方向。
- 速度与成本优势:gemma-4-26b-a4b-it的平均耗时为47s,平均Token消耗为799,每千次调用花费仅1.7元。对比同系列的31B Dense版本(82s,687 token,1.4元),MoE版本在响应速度上快了约43%,但Token消耗略高(799 vs 687),实际花费略高(1.7元 vs 1.4元)。
2、横向对比
在当前主流大模型竞争格局中,gemma-4-26b-a4b-it作为一款MoE开源模型,其核心竞争力不在于与大参数旗舰模型比拼准确率,而在于以极低的推理成本提供可用的智能水平。我们从三个维度进行横向对比分析:
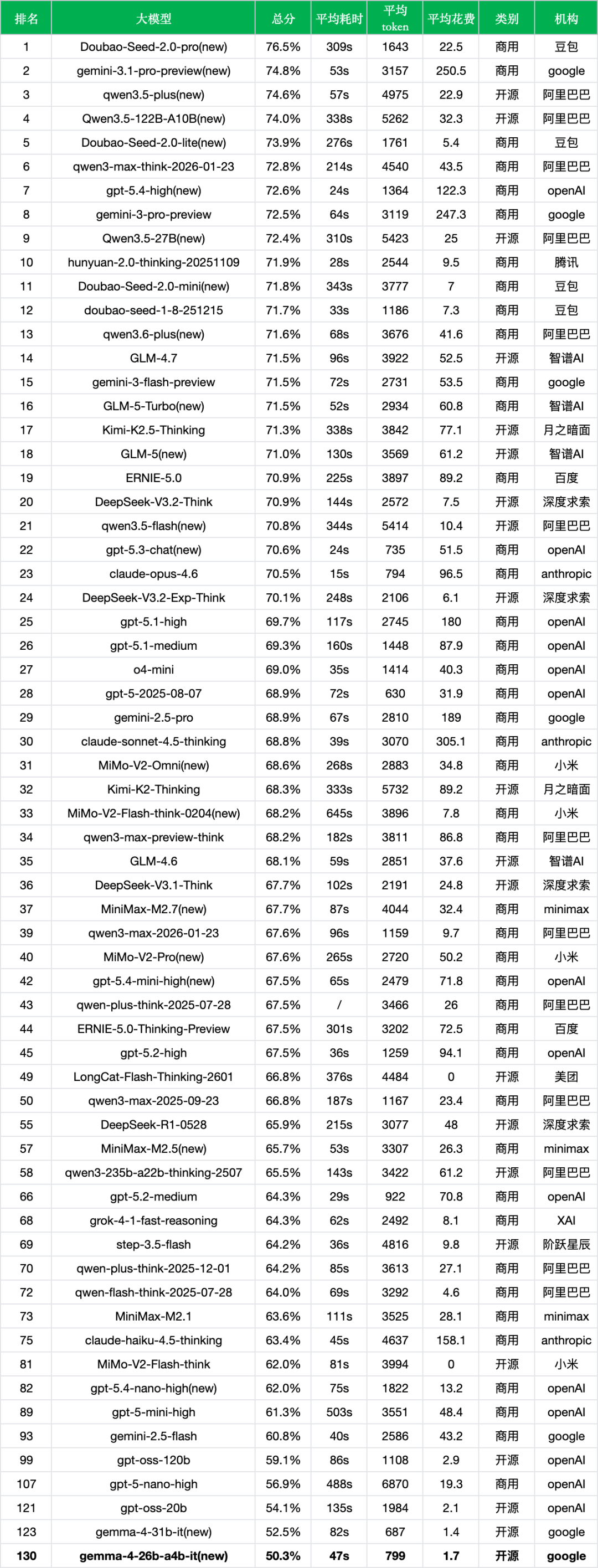
*数据来源:非线智能ReLE评测https://github.com/jeinlee1991/chinese-llm-benchmark
同成本档位对比
- 超低成本区间的速度标杆:gemma-4-26b-a4b-it每千次调用花费仅1.7元,与同系列的gemma-4-31b-it(52.5%,1.4元)同处最低成本区间。两者准确率差距为2.2个百分点(50.3% vs 52.5%),但MoE版本的响应速度更快(47s vs 82s),适合对延迟敏感的实时交互场景。
- 与gpt-oss-20b(54.1%,2.1元)相比,gemma-4-26b-a4b-it在准确率上存在3.8个百分点的差距,花费略低(1.7元 vs 2.1元)。考虑到Gemma 4 26B MoE每次仅激活38亿参数,其参数效率在同成本档位中具备一定竞争力。
- 与gpt-oss-120b(59.1%,2.9元)相比,准确率差距拉大至8.8个百分点,但花费仅为后者的约60%。对于优先考虑部署灵活性而非极限准确率的场景,MoE版本的低资源占用是其差异化优势。
新旧模型对比
- 代际进步明显:从gemma-3-27b-it的39.0%到gemma-4-26b-a4b-it的50.3%,11.3个百分点的提升印证了Gemma 4系列整体架构升级的有效性。
- 与31B Dense版本的互补关系:在Gemma 4家族内部,31B Dense(52.5%,82s,1.4元)与26B MoE(50.3%,47s,1.7元)形成了清晰的产品矩阵——前者适合对准确率要求更高的离线批处理场景,后者适合对响应速度敏感的在线交互场景。两者准确率差距仅2.2个百分点,但速度差异达43%。
- 在谷歌系模型的完整版图中,从闭源旗舰gemini-3.1-pro-preview(74.8%)到轻量API gemini-3-flash-preview(71.5%),再到开源本地部署的Gemma 4系列(50%至52%区间),形成了从云端到边缘的覆盖。
开源VS闭源对比
- 开源轻量模型的生态价值:gemma-4-26b-a4b-it的50.3%准确率在开源模型中排名靠后,与头部开源模型qwen3.5-plus(74.6%)、Qwen3.5-27B(72.4%)差距明显。但Gemma 4 26B MoE的核心价值在于其MoE架构带来的极低推理开销——仅激活38亿参数,意味着它可以在消费级GPU甚至移动设备上流畅运行。
- 与同为开源的Qwen3.5-27B(72.4%,25元)相比,gemma-4-26b-a4b-it的准确率差距达22.1个百分点,但花费仅为后者的约7%。两者面向的是完全不同的使用场景:Qwen3.5-27B追求的是开源阵营中的极限智能,Gemma 4 26B MoE追求的是边缘设备上的可用智能。
目前所有大模型评测文章在公众号:大模型评测及优化NoneLinear

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)