AI Agent企业实战入门到精通,抛弃复杂框架,一个终端搞定一切的真相,收藏这篇就够了!
一句话讲清楚👉🏻** ServiceNow联合Mila的研究团队发现,一个只有终端和文件系统的极简Agent,在729个企业自动化任务上能匹敌甚至超越MCP工具增强Agent和Web GUI Agent,成本低了一个数量级。
一句话讲清楚👉🏻 ServiceNow联合Mila的研究团队发现,一个只有终端和文件系统的极简Agent,在729个企业自动化任务上能匹敌甚至超越MCP工具增强Agent和Web GUI Agent,成本低了一个数量级。
当大家都在给AI Agent堆工具、搭框架、封装MCP Server的时候,ServiceNow和Mila(Quebec AI Institute)的研究团队扔出了一篇论文,标题直截了当——“Terminal Agents Suffice for Enterprise Automation”。
他们在ServiceNow、GitLab、ERPNext三个真实企业平台上跑了729个任务,用Claude Sonnet 4.6、Claude Opus 4.6、GPT-5.4 Thinking和Gemini 3.1 Pro四个前沿大模型对比了三种Agent范式。结论出奇一致:终端Agent在大多数场景下成本最低、效果最好。
这篇文章来拆解这篇论文的实验设计、核心发现和值得思考的问题。
三种Agent范式
当前企业级AI Agent主要走三条路线:
MCP工具增强Agent 通过Model Context Protocol暴露一组预定义的API工具——创建工单、更新字段、查询记录等等。Agent从工具列表里挑一个,填参数调用。好处是交互被压缩成高级操作,坏处是工具注册表里没有的操作,Agent就干瞪眼。
Web GUI Agent 通过浏览器观察页面DOM和截图,模拟人类点击、输入、翻页。理论上能执行人类在界面上能做的任何操作,但每次交互都要处理庞大的可访问性树和截图,Token消耗巨大,对界面布局变化也特别敏感。
终端Agent 只给一个终端和一个文件系统。Agent自己写代码调用平台API,动态发现能力,灵活组合操作。没有预定义工具的限制,也不需要渲染UI。
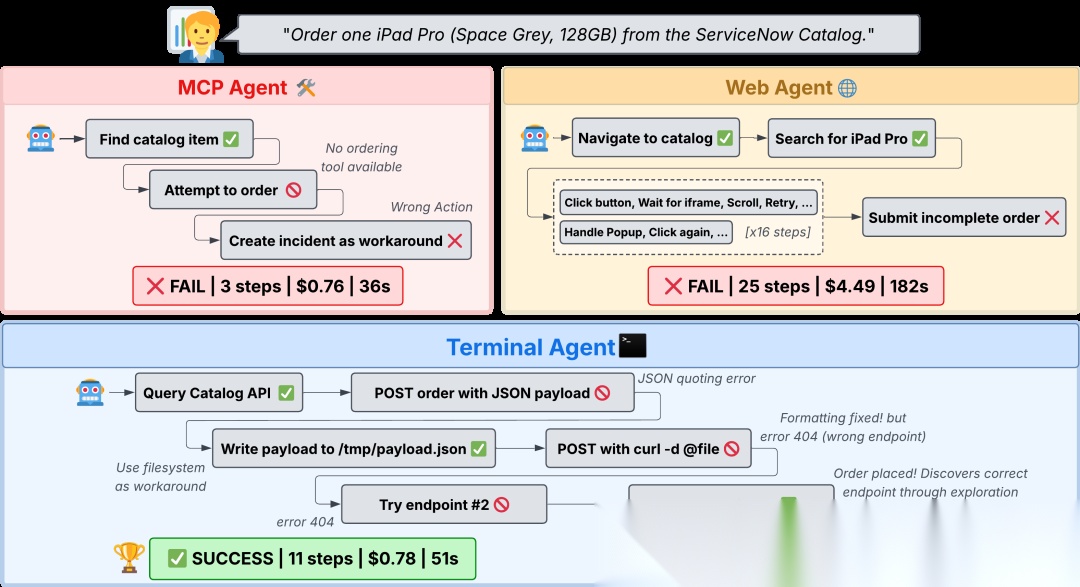
三种Agent在"订购iPad Pro"任务上的执行轨迹对比。左上:MCP Agent找到商品但缺少订购工具,降级创建工单后失败。右上:Web Agent到达商品页面但在iframe界面中迷失,轨迹冗长且昂贵,最终失败。下方:终端Agent遇到JSON转义错误和404,但通过写临时文件和探索替代端点成功完成任务,成本仅为Web Agent的十分之一。
论文中的一个具体例子很能说明问题:三种Agent被要求"订购一台iPad Pro"。MCP Agent找到了目录商品,但工具注册表里没有下单工具,降级创建了一个支持工单后失败。Web Agent成功进入了商品页面,但在iframe嵌套的下单界面里彻底迷路,走了很长一段昂贵的轨迹后放弃。终端Agent也不顺利——构建请求载荷时遇到JSON转义错误,API端点返回404——但它把载荷写到临时文件绕过引号问题,换个端点重试,最终完成任务,成本只有Web Agent的十分之一。
StarShell:极简终端Agent的设计
论文实现的终端Agent叫StarShell,设计极其克制。
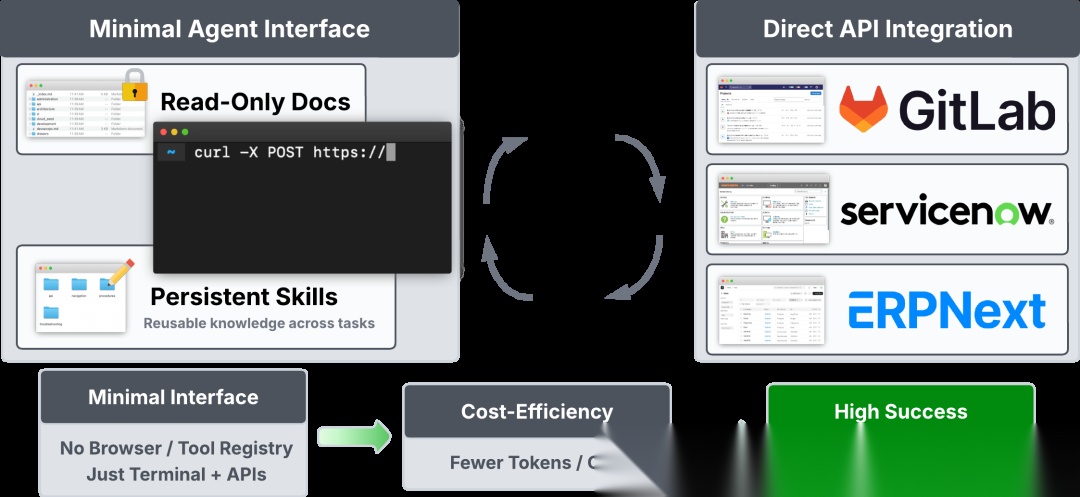
StarShell架构概览。Agent通过终端和文件系统直接调用企业平台API(ServiceNow、GitLab、ERPNext),可选地使用文档和持久化Skills来发现和调用API。
Agent只暴露两个接口:终端用于执行命令,文件系统用于存储中间结果。每个任务开始时接收自然语言描述,然后迭代生成命令或代码片段。典型操作是用curl查询平台REST API、用python3或jq处理返回的JSON、把中间结果写到文件里缓存。
跟MCP Agent不同,StarShell不依赖预定义的action schema。它通过读文档或直接检查API响应来动态发现平台能力。这种设计让它能组合出工具注册表里不存在的操作序列。
文件系统还承担着"外部记忆"的角色——Agent可以读取文档、缓存中间结果、保存可复用的"技能"脚本。这跟Claude Code、OpenHands等现代coding agent的模式一致。
评测环境:三个真实企业平台
研究团队在三个企业平台上构建了729个评测任务:
- ServiceNow(IT服务管理):330个任务,93个MCP工具,61k文档页
- GitLab(软件开发生命周期):192个任务,107个MCP工具,2.65k文档页
- ERPNext(企业资源规划):207个任务,7个MCP工具,5.41k文档页
任务从简单记录查询到多步骤工作流都有,覆盖过滤、条件更新、跨对象推理等操作类型。所有环境跑在容器化实例里,每个任务执行完后容器重置到初始状态,确保任务之间不互相干扰。
两个设计细节值得注意。第一,每个任务都加了"导航"要求——Agent不拿到起始URL或记录直链,必须根据自然语言描述自行判断该调哪个API端点。第二,任务描述里的歧义被系统性地消除了,比如"按优先级排序"被改写成"按优先级排序incident列表",因为Agent没有浏览器上下文来消歧。
验证方式也很讲究:不检查Agent的中间行为,只对比执行前后的平台状态。ServiceNow和GitLab用API调用验证,ERPNext直接查SQL。
核心实验:终端Agent赢在哪里
实验用的指标是成功率(SR)和每任务成本。成本按底层LLM的token用量计算,比wall-clock time更稳定、跟环境无关。
MCP Agent受限于工具覆盖。在所有模型中MCP Agent成功率最低。ServiceNow上仅11.5%–16.1%——93个工具听着不少,但很多任务需要的操作超出了可用端点。GitLab上有107个工具,性能好一些(45%–49%),但仍远低于其他范式。反直觉的是,MCP Agent表现最接近对手的平台是ERPNext——它只暴露了7个工具。原因是ERPNext的API提供对所有文档类型的通用CRUD操作,少量设计良好的通用工具比大量窄端点更管用。
Web Agent灵活但贵得离谱。Web Agent在12个平台-模型组合中的8个拿到最高准确率,但成本高得吓人。在ServiceNow上比终端Agent贵4–6倍,每次交互都要处理大型可访问性树和截图。最夸张的是Opus 4.6在ERPNext上:Web Agent每任务,终端每任务0.72,9倍成本换来的准确率差距不到5个百分点(81.6% vs. 76.8%)。
终端Agent性价比最优。终端Agent在12个组合中的7个匹配或超越Web Agent,成本始终更低,通常低5倍以上。Gemini 3.1 Pro配合终端Agent在所有环境平均达到77.5%成功率,每任务仅$0.09——整张表里最省钱的配置。用Opus 4.6时终端Agent在ServiceNow上达到79.1%,高于Web Agent的77.6%。
工具调用分析:失败不是因为工具不可靠
一个自然的疑问是:终端Agent会不会因为工具调用失败率高而吃亏?论文对ServiceNow上Sonnet 4.6的轨迹做了详细分析。Agent几乎全部(97.3%)用curl调用ServiceNow REST API,所以工具调用失败基本就是API交互错误。
论文把工具调用结果分成了8类:成功、成功但被截断、非JSON成功、API错误、Shell错误、空响应、Curl错误、JSON解析错误、Python错误、超时、HTML重定向。
分析结果出人意料:成功和失败任务的错误分布非常接近。成功任务和失败任务遇到API错误、curl失败、shell错误的比例几乎一样。这说明Agent通常能从单次工具调用失败中恢复,任务级失败的根源不是工具不可靠,而是Agent在底层任务上无法取得进展。
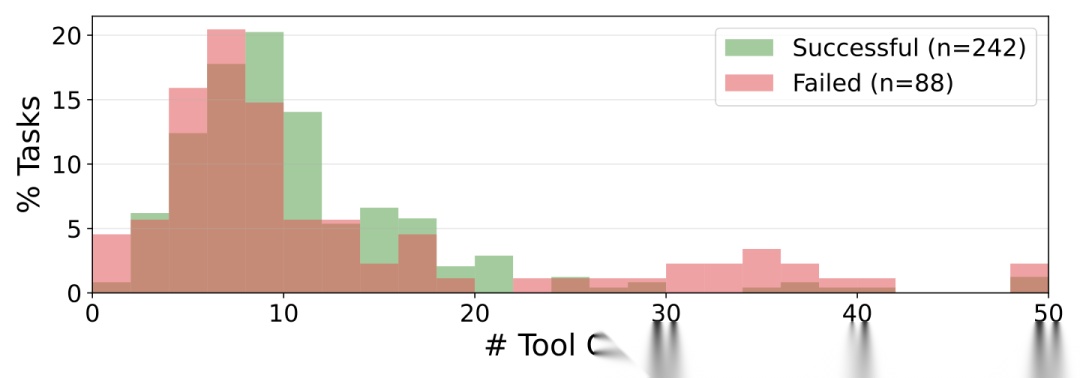
成功和失败任务的每任务工具调用数分布。超过50次的按50次封顶。两者的分布大体相似,但失败任务在零附近有更重的集中(Agent过早放弃),在30次以上有个小凸起(Agent陷入无产出循环)。
那什么导致任务失败?论文发现两个特征:一是失败任务有更多集中在零附近的记录——Agent尝试了很少几次就放弃了;二是失败任务在30次以上工具调用处有个小凸起——Agent偶尔陷入无产出的循环后撞上轮次限制。
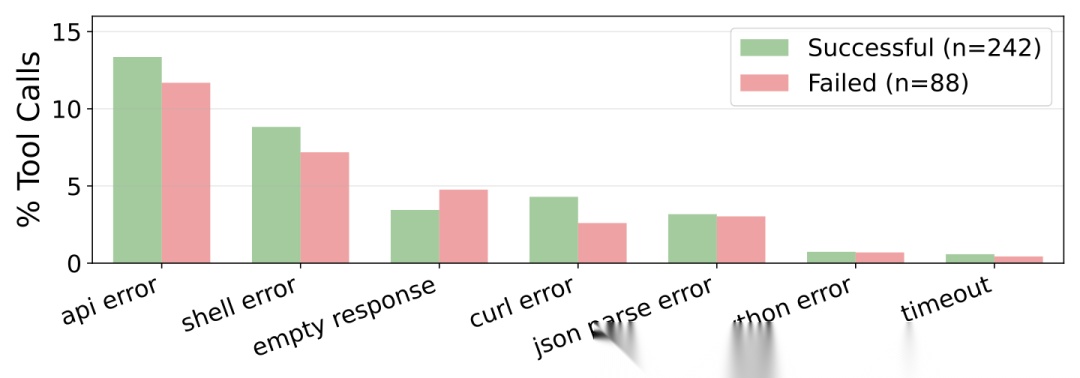
成功和失败任务中各类API错误占总工具调用的百分比。两组的错误类型分布惊人地相似——Agent能从单次失败中恢复,任务级失败不是因为工具不可靠。
文档:不一定有用,关键看结构
论文还测了一个变量:给终端Agent提供官方文档,会不会提升效果?
整体答案是没有明显帮助。Sonnet 4.6下无文档Agent总体略好(72.7% vs. 71.8%),Opus 4.6下两者几乎持平(78.7% vs. 79.2%)。
但拆开看各平台差异很大:
ServiceNow文档帮倒忙。Sonnet下成功率下降6.3个百分点。原因很明确:ServiceNow的文档主要面向Web UI用户写的,API部分是"参考型"的——罗列完整API表面,不告诉Agent哪些端点适合常见操作。Agent读了之后采用了不必要的复杂策略,把大量工具调用预算花在检索和阅读文档上,而非执行任务。
ERPNext文档有帮助。Sonnet下成功率提升4.7个百分点,且几乎不增加成本。ERPNext的文档是"任务型"的——每个页面描述特定实体及其字段,直接对应Agent需要构造的API调用。Agent快速找到了关键信息,比如schema探索无法发现的非直观doctype名称。
GitLab文档不影响准确率,但成本翻倍。Agent读了文档,但没从中获益——GitLab的API足够直观,Agent靠参数化知识就够了。
这个发现指向一个结论:面向人类的参考文档可能误导Agent,简洁的任务导向内容才真正有效。
边干边学:Agent的"技能"积累
论文最有意思的实验是让终端Agent"在工作中学习"。Agent执行任务时可以把解决问题的策略、工作流和笔记保存到持久化的skills目录,后续任务可以复用。
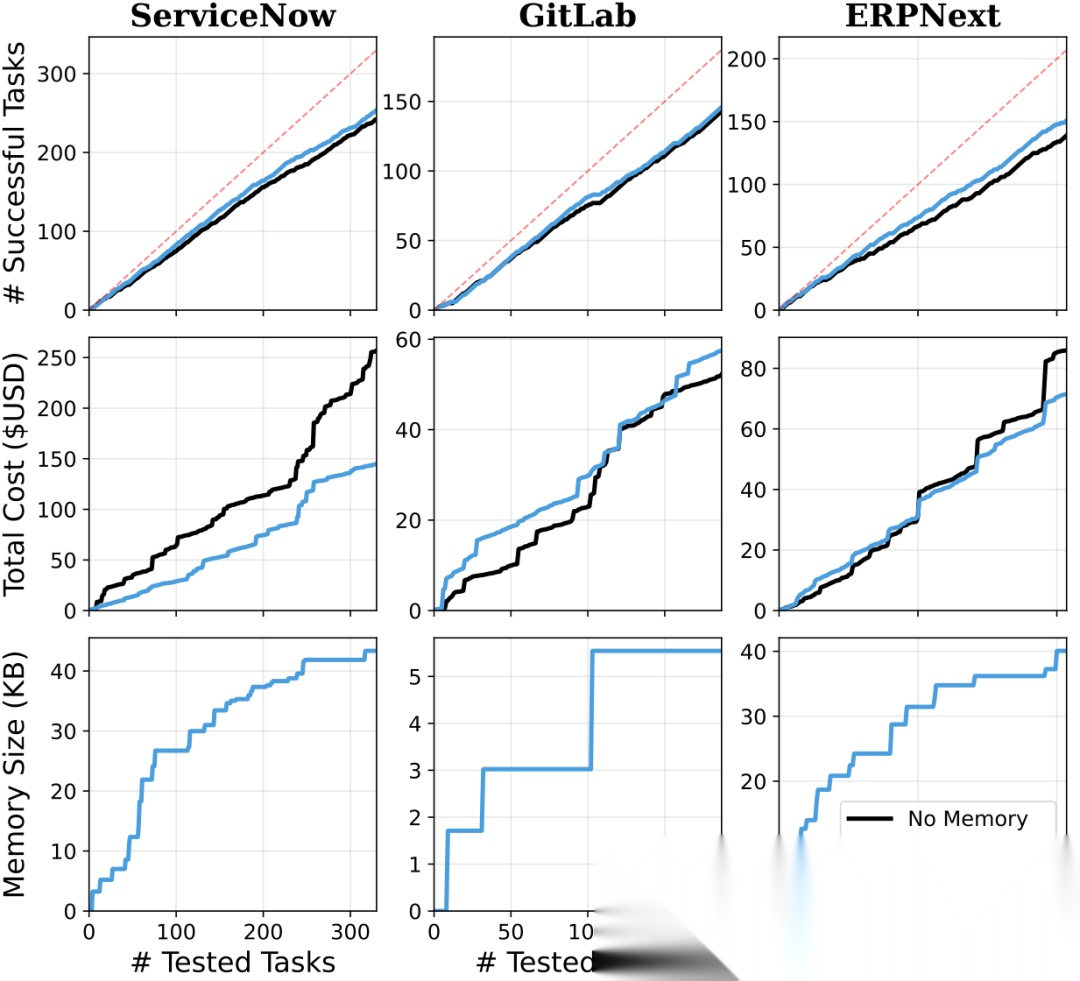
技能积累随任务序列的变化。上:累计成功任务数。中:累计成本(美元)。下:技能目录大小(KB)。蓝色线为有持久化记忆的Agent,黑色线为每次都从零开始的基线。有记忆的Agent在ServiceNow和ERPNext上成本曲线明显更低。
效果在各平台上不同:
ERPNext收益最大——成功率提升5.8个百分点,因为这个平台相对冷门,Agent的参数化知识不够,需要通过积累来补。
ServiceNow提升3.6个百分点,同时每任务成本降低43.7%(0.78)。省钱的幅度比提升准确率更抢眼。
GitLab仅提升1.6个百分点。Agent对GitLab的参数化知识已经足够强,不太需要额外记忆。
技能文件的内容也很有意思。大多数是过程性的——逐步指导如何通过API创建或修改记录。但真正有价值的不是步骤本身(通常就是一个API调用),而是陷阱和字段映射:UI标签和API字段名的对应关系、有效字段值、哪些端点存在、shell引号问题的变通方案。
论文统计了各平台的技能特征。ServiceNow上技能文件平均3.9KB,比较"百科全书式"——积累跨任务的字段映射和标识符。ERPNext上技能文件更多(25个)但更小(平均1.8KB),每个关注单一实体类型,记录细微的schema不一致和副作用,比如so_required=1这个字段的语义是反的——设为1反而允许在没有销售订单的情况下创建发票。GitLab上只创建了2个技能文件,记录了两个非直观的API约定:项目创建时未文档化的模板名plainhtml和成员邀请时的access level映射。
一个跨平台的共同模式是:技能文件都反复警告shell引号问题——eval curl配合JSON载荷的各种坑——建议用临时文件或脚本替代。这种基础设施层面的教训说明,技能捕获的知识可以超越单个任务泛化。
终端Agent的固有局限
终端Agent不是万能的。论文识别了三类固有局限:
浏览器会话绑定操作。ServiceNow的"用户模拟"(impersonation)功能需要浏览器会话cookie交换。终端Agent发现了一个看起来正确的端点/api/now/ui/user/impersonate并收到HTTP 200,但模拟并没有实际生效。Web Agent只需两步点击(用户菜单→选择目标用户)就搞定了。
渲染后的UI状态。有些平台状态只能通过Web UI看到——比如仪表盘图表的渲染结果。终端Agent可以查底层表并重新计算聚合值,但渲染输出可能因舍入、格式化或图表特定逻辑而有差异。Web Agent直接读取渲染后的状态。
复杂UI交互。拖拽式工作流编辑器这类操作目前没有公共API暴露。比如"创建一个每天触发的工作流,查找所有分配给某人的高优先级incident并发邮件"——Web Agent可以通过标准UI交互在Flow Designer里完成,但终端Agent没有可靠的方式执行这类操作。
多Agent和混合Agent:额外的实验
论文还做了几个额外实验,值得简要介绍。
单Agent vs. 多Agent系统。论文比较了单终端Agent和Planner-Executor双Agent设计。结果:Planner-Executor在较弱模型(Sonnet 4.6)上略好(总体74.8% vs. 73.3%),但成本高48%。用Opus 4.6时两者几乎一样(78.7% vs. 78.8%),单Agent更便宜。更强的模型似乎内部化了规划步骤,多Agent编排主要补偿底层模型的推理能力不足。
混合Agent(终端+浏览器)。论文问了一个关键问题:给终端Agent加上浏览器访问能力,能不能弥补各自的短板?先看补性数据——在ServiceNow的330个任务中,终端Agent解决了52个Web Agent搞不定的,Web Agent解决了55个终端Agent搞不定的。理论上一个完美的oracle选择器可以达到89.1%,比任何单一Agent高16个百分点。
但实际的混合Agent没有达到这个上限。Sonnet 4.6下混合Agent在ServiceNow上72.1%,反而低于终端Agent的73.6%和Web Agent的72.4%。原因很直白:Agent过度依赖浏览器——82%的工具调用是浏览器操作,即使终端Agent能更高效地完成的任务也走了浏览器路径。
Opus 4.6下情况改善了:混合Agent在ServiceNow上达到83.0%,比终端(79.1%)和Web(77.6%)都高,成本$2.57介于两者之间。更强的模型能更好地选择正确的工具。
这暗示了一个方向:用Skills帮助Agent判断什么时候用终端、什么时候用浏览器,可能比简单地给两种能力更有效。
失败分析工具和工具调用分类
论文开发了一套自定义的轨迹分析工具(StarShell Viewer),用于检查Agent的执行轨迹并对比不同运行。
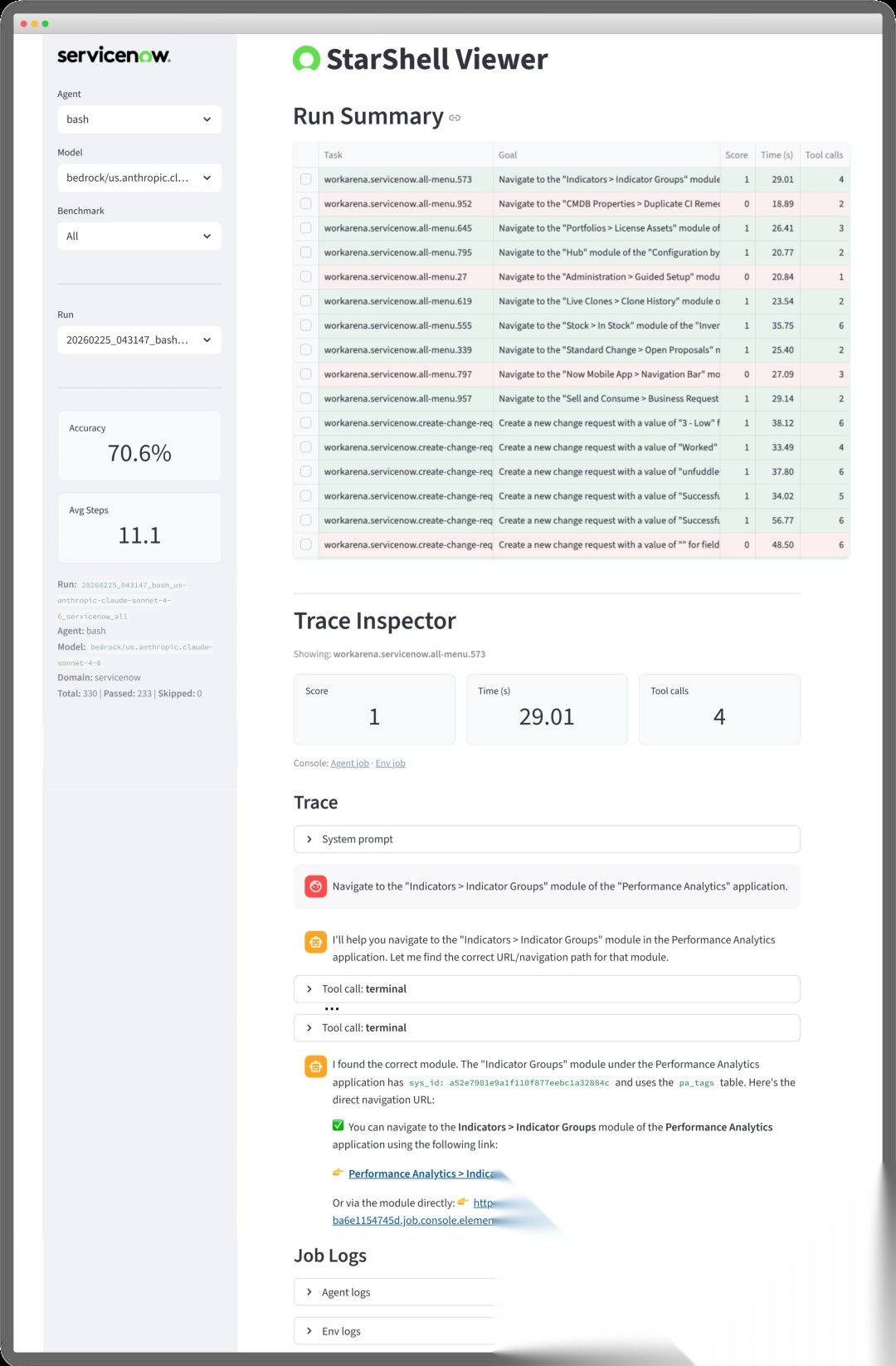
StarShell Viewer界面:用于浏览和检查Agent执行轨迹的自定义工具,支持对比不同运行和深入分析单次工具调用。
Agent与平台的交互几乎全部通过curl命令完成,论文将工具调用结果分为成功和失败两大类。成功类包括:正常JSON响应、响应被截断但内容有效、通过jq/python3/awk处理后的非JSON正确输出。失败类包括:API错误(服务端返回JSON错误)、Shell错误(非零退出码或语法错误,通常来自-d载荷中的未转义字符)、空响应(HTTP方法用错)、Curl错误(多行-d配合eval时命令被拆分)、JSON解析错误、Python内联处理异常、超时、HTML重定向。
论文特别指出,成功的和失败的任务遇到的错误类型分布惊人地相似。Agent从单次失败中恢复的能力很强,任务级失败更多是Agent无法在底层任务上推进,而不是工具本身不可靠。
这意味着什么
这篇论文的结论可以用一句话概括:在API稳定可用的场景下,与其引入更多抽象层,不如暴露可编程接口。
当前Agent领域的趋势是不断加码——更多工具、更复杂的框架、更精细的MCP封装。但ServiceNow的研究表明,一个只有终端和文件系统的极简Agent,配合强大的基础模型,就足以应对大多数企业自动化任务。
逻辑其实不复杂。MCP工具注册表本质上是对同一API表面的封装,但以更不灵活的形式呈现。一个create_incident工具可能只暴露几个参数,而底层API能接受几十个字段。当任务需要设置工具没暴露的字段时,MCP Agent束手无策,而终端Agent可以构造任意载荷。终端Agent面对不熟悉的端点可以探索、调整载荷、写脚本自动化复杂序列——这些是固定工具注册表无法完全复制的能力。
当然,这不意味着MCP和Web Agent没有价值。在需要复杂UI交互或平台不暴露API的场景下,它们仍然不可替代。但对于ServiceNow、GitLab、ERPNext这类API成熟的企业平台,终端Agent可能是目前最务实的选择。
论文的作者来自ServiceNow和Mila(Quebec AI Institute),正在COLM 2026审稿中。评测框架、数据集和代码将在接收后开源。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 2
2 0
0- 0



 已为社区贡献746条内容
已为社区贡献746条内容

所有评论(0)