自进化Agent的现状调研和总结
自进化agent 的现状以及常见的框架调研和分析
一、自进化Agent时代到来
2026年2月,Openclaw迅速出圈,紧着接针对Openclaw的自动优化skills 的插件Evomap、Foundry和self-improving-agent等插件迅速走红,对应的Agent自进化的工程化实践的可行性被验证。
2026年3月1日,Karpathy 开源了 AutoResearch——Agent 自己改 train.py、跑实验、看结果、再改代码,循环迭代。没有人告诉它先调学习率还是先换优化器。
2026年3月18日,MiniMax 在 M2.7 的技术报告里披露了一件事:模型在 RL 阶段自己跑了 100 多轮"做题→分析失败→改 scaffold→重做"的循环,承担了自身 30%-50% 的 RL 训练工作量,内部评分提升 30%。
AI的发展走向同一个趋势:Agent 不再只是执行指令的工具,它开始"改进自己做事的方式"。
1.1 什么是自进化 Agent
部署后能力还会增长的 Agent。传统 Agent 就像是是一个常量函数是静态的,自进化 Agent 是一个随着时间和环境进行更新的函数是动态成长和自适应的:
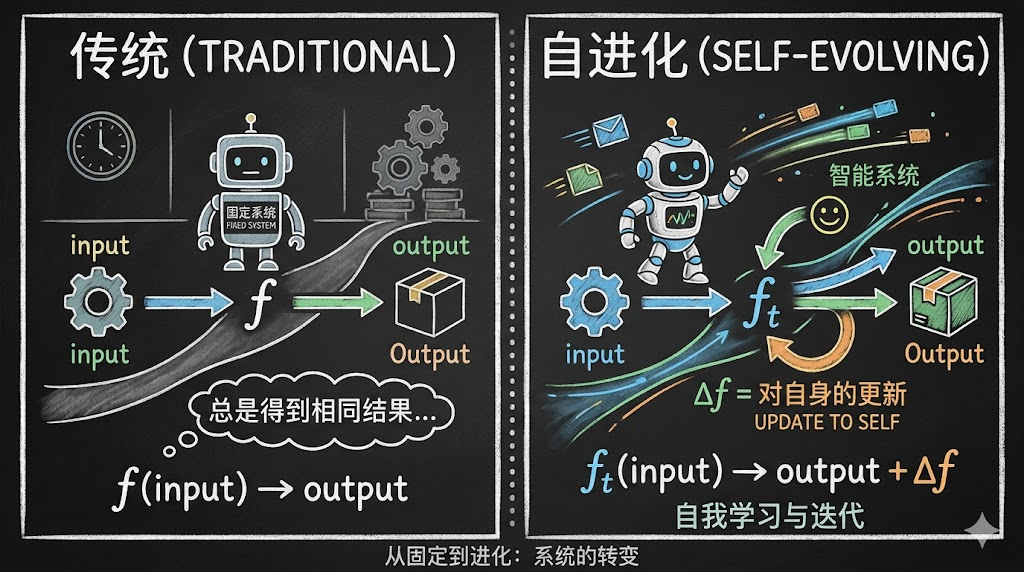
Δf 可以是一条新 Prompt 规则、一段沉淀的纠错经验、一个新工具、乃至模型权重更新。
1.2 自进化框架能力分类:
|
级别 |
特征 |
对应什么 |
代表 |
|
L1 |
出错重试,但不积累 |
大部分现有 Agent 框架 |
LangChain ReAct, AutoGen |
|
L2 |
从反馈中学习,跨会话积累经验 |
当前产品化竞争焦点 |
Hermes Agent,AutoResearch, SkillLite |
|
L3 |
能修改自身代码或模型权重 |
已有工业级案例,但尚在验证 |
MiniMax M2.7, Meta Hyperagent |
判断:L2 → L3 的跨越不是能力问题,是信任问题——你敢不敢让 Agent 改自己的代码?这背后是一个安全架构设计的命题,后面会详细展开。
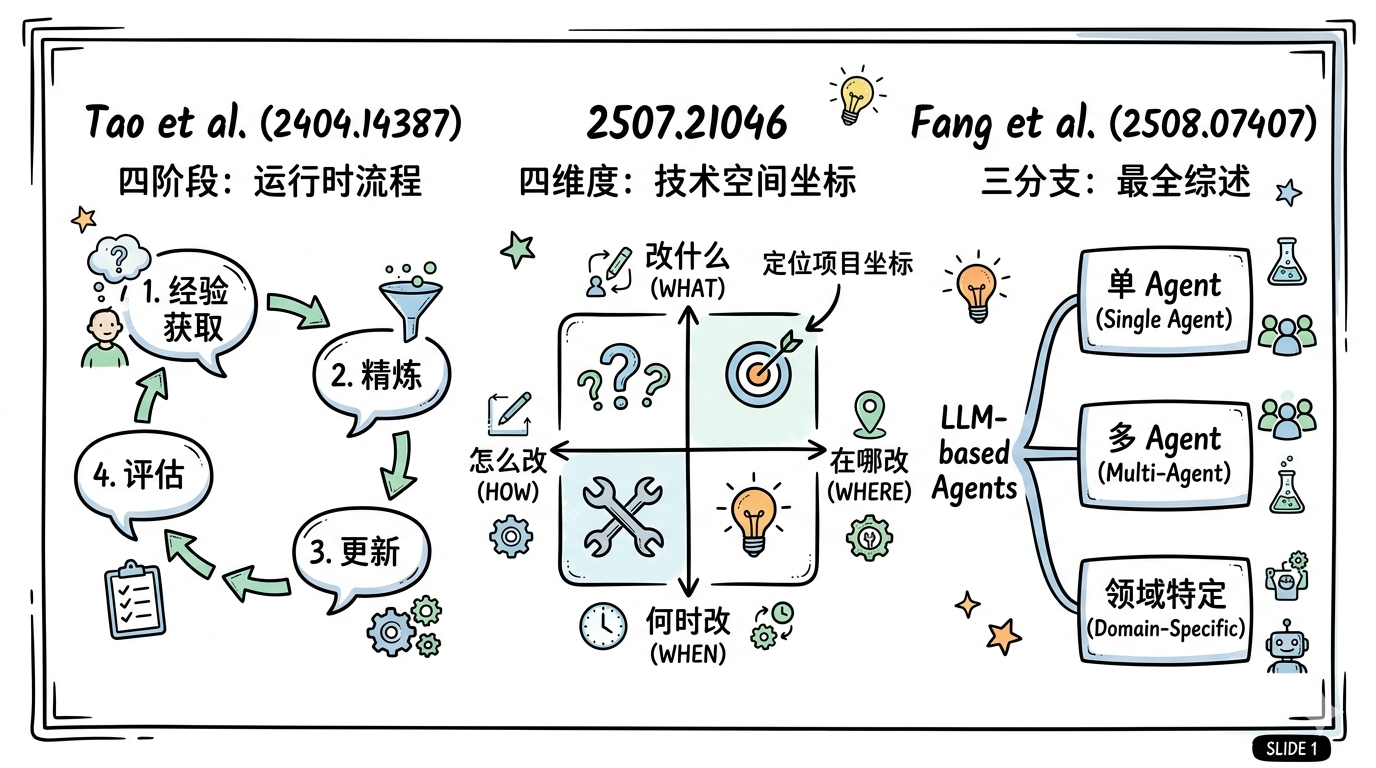
1.3 自进化学术框架分类:三个坐标系
- 运行时四阶段:经验获取 → 精炼 → 更新 → 评估。描述运行时流程。
- 进化四维度:改什么 × 何时改 × 怎么改 × 在哪改。定位一个项目在技术空间的坐标。
- 进化Agent三分支:单 Agent / 多 Agent / 领域特定。
二、五条技术路线
自进化技术路线总结来说有五条,分布在 Agent 系统的不同层次。成本和风险逐层递增,选从那一层切入取决于业务场景约束。
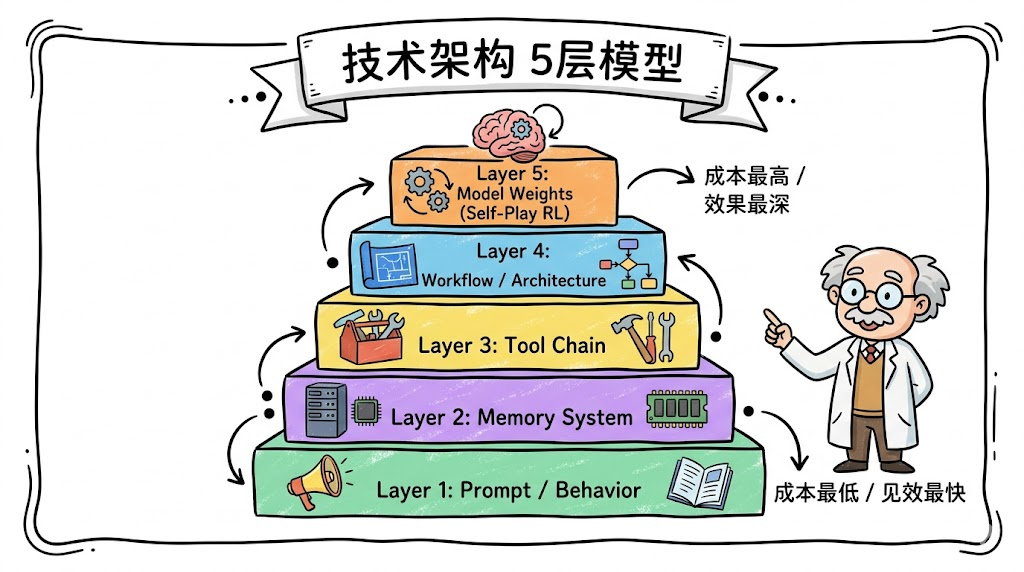
2.1 Prompt 自进化 — ROI 最高
Layer 1: 不动模型不动架构,只优化 Prompt。
EvoPrompt 做的事情说起来简单——维护一个 Prompt 种群,用遗传算法做交叉变异,跑评测集做适应度筛选,迭代收敛到最优 Prompt。实测在分类任务上有 10-15% 的精度提升。TextGrad 走另一条路——让 LLM 对 Prompt 做"文本梯度反馈",比如输出"在否定句场景缺少 few-shot 示例"这样的优化建议,然后沿这个方向改 Prompt。
这是工程上最该先做的一层:不需要 GPU,不需要沙箱,Prompt 变更的风险可控。
2.2 记忆系统自进化
Layer 2: Agent 应该记住什么?这个问题看起来简单,工程上很不好做。
Hermes Agent 的 Nudge 机制是我看到的最有意思的设计——Agent 自己决定什么值得记住。不是外部规则说"每次执行完都存日志",而是 Agent 在执行过程中发现一个重要信息时,主动发起一次持久化调用。比如它在帮你部署服务时发现公司 CI/CD 必须先过安全扫描,它会自己把这条存到长期记忆里。下次不同会话再做部署,这条记忆被 FTS5 全文检索召回,直接影响决策。
这比预设规则的记忆系统灵活得多,但也引入了一个风险:Agent 如果记住了一条错误的"经验"怎么办?SkillLite 在记忆写入后面加了 Gatekeeper 验证——经验需要过审才能持久化。
2.3 工具和工作流自进化
Layer 3和Layer 4:工具和技能自进化,这两层放一起说。
工具自进化有两条路:自己造(SkillLite 的 skill_synth,Agent 写代码生成新工具)和接入现有生态(ToolLLM 掌握 16000+ API,MCP 标准化工具协议)。自己造更灵活,但安全约束重,SkillLite将自动生成的代码必须过沙箱。
工作流自进化更激进——EvoAgentX 能从一个 Prompt 自动生成多 Agent 协作的 DAG,然后用 TextGrad 等算法迭代优化这个 DAG。搜索空间大,但收敛也慢。
📎 EvoAgentX 的 workflow autoconstruction pipeline 架构图值得看(arxiv 2507.03616 Figure 1),比文字描述清楚。
2.4 模型参数自进化 — 2025-2026 最热方向
Layer 5,MiniMax M2.7 做的事值得深入理解。传统 RLHF 的瓶颈在人类标注产能——大约 1000 条/人天。M2.7 把瓶颈推到了 GPU 算力上:
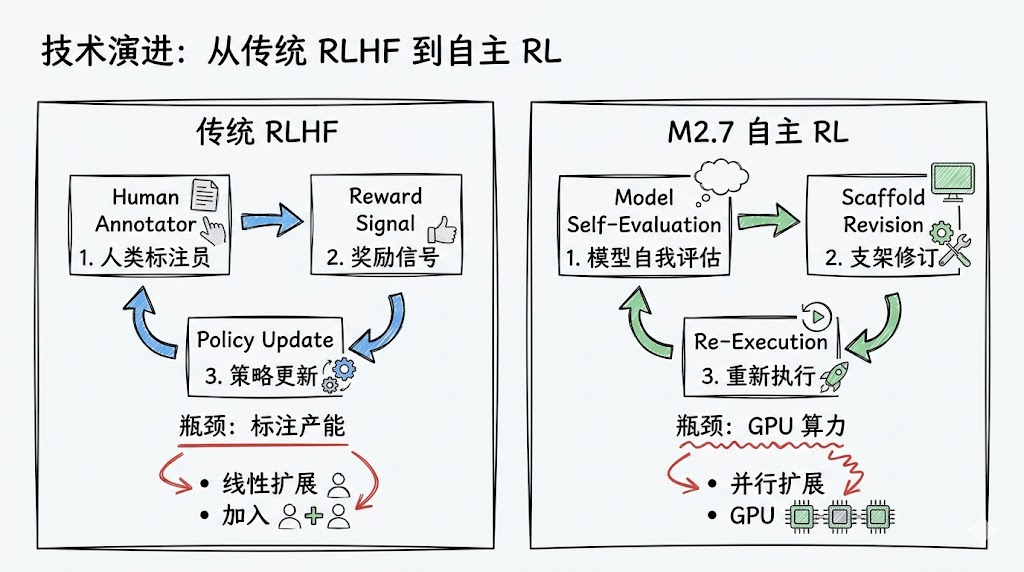
这个迁移的战略含义:当训练瓶颈从人力变成算力,模型迭代速度的上限就不一样了。标注产能线性扩展(加人),GPU 算力并行扩展。SWE-Pro 56.22 本身不是关键,关键是 30% 的评分提升有显著比例来自自训练——说明自训练不仅在补充人工标注,在某些维度上已经超越了人工设计的训练方案。
SPELL 走的是多角色自博弈路线——模型分饰多角色互相出题批改,专练长上下文理解。思路与 AlphaGo 的 Self-Play 同源,区别在于搜索空间从棋盘变成了文本。
三、不同项目,不同取舍
这里不做全面罗列,我挑四个项目重点讲它们各自做了什么取舍、放弃了什么换来了什么。
3.1 MiniMax M2.7 — 算力换标注
M2.7 在自训练循环中修改的是 scaffold(推理框架),不是模型权重本身。这是一个务实的工程选择——scaffold 的修改可以快速验证和回退,模型权重的修改不可逆且成本高。
放弃了什么:完全的自主性(scaffold 的搜索空间还是受限的)
换来了什么:可控性和工程可行性
这个思路对我们做数据 Agent 有直接参考价值——与其让 Agent 自己训练自己的模型(成本太高),不如让它自己优化自己的推理策略和 Prompt(ROI 更高)。
3.2 Hermes Agent — 可移植性换性能
Nous Research 做了一个明确的架构取舍:跑在 $5/月 VPS 上也行,GPU 集群也行,不绑定任何平台。代价是放弃了特定硬件的深度优化。
它的自进化闭环是我见过设计最完整的:
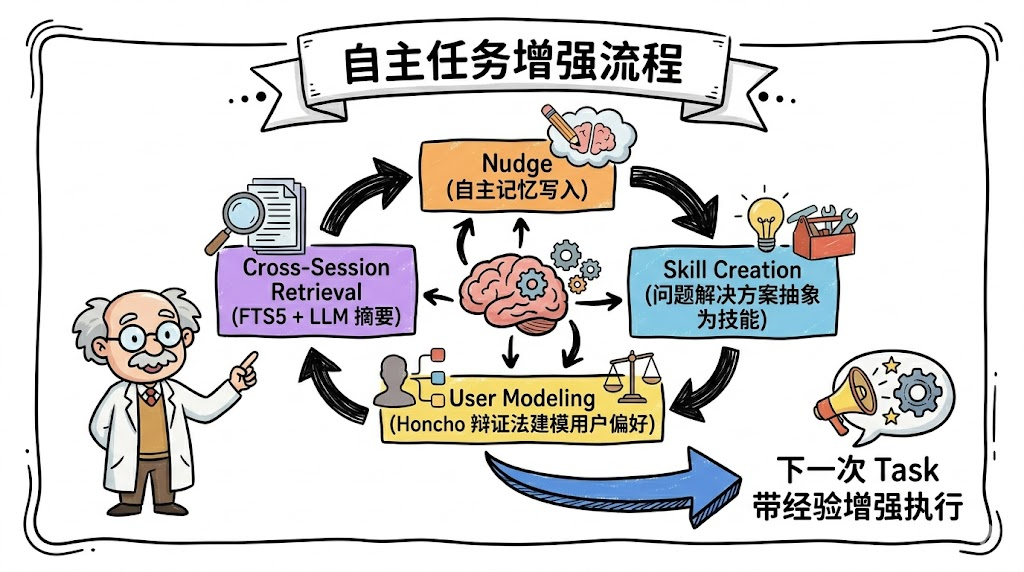
📎 建议看 Hermes Agent 的 GitHub README 中的系统架构图,展示了网关层、终端后端、记忆系统的完整交互。
几个值得注意的设计:
- 网关抽象:单进程支持 Telegram/Discord/Slack/WhatsApp/CLI。在 Slack 上学到的经验,在 CLI 上也能用。
- 模型无关:200+ 提供商间切换不改代码。进化状态(记忆、技能)独立于底层 LLM。
- 子 Agent 隔离:fork 出隔离子 Agent 做并行处理,独立执行环境但共享记忆——隔离性和协作性的平衡。
3.3 OpenHands,SkillLite — 安全换灵活
这个项目最值得关注的不是它能做什么,而是它不允许 Agent 做什么。 当 Agent 能自我修改时,安全模型发生了根本变化:
- 传统 Agent: 威胁来自外部 → 防御策略: 输入校验 + 输出过滤
- 自进化 Agent: 威胁同时来自内部 → 防御策略: 进化过程本身需要被约束
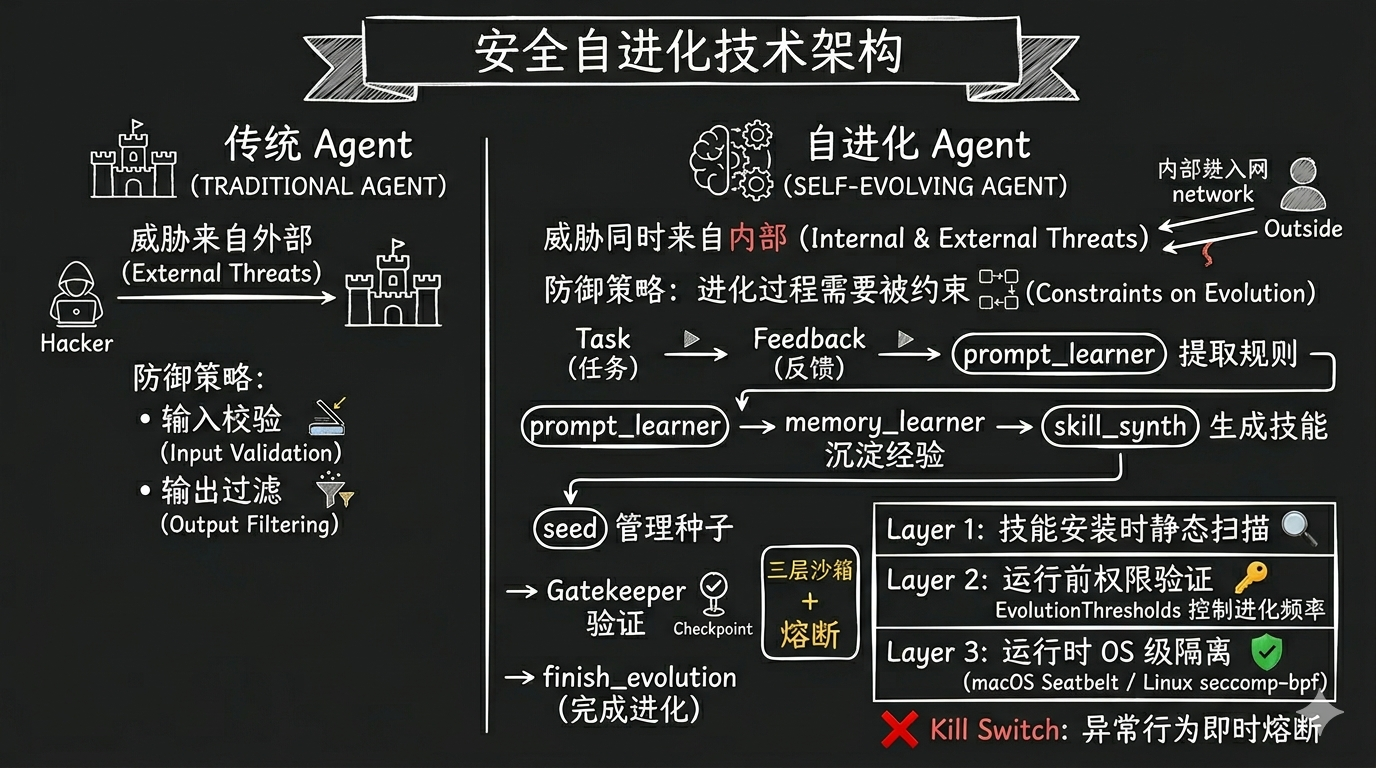
Python 的动态类型和 GC 不确定性在这个新模型下是结构性弱点。Rust 的编译时检查和内存安全成了核心优势。
EVO 模块数据流 (建议配合 SkillLite docs.rs 文档中的架构图阅读):
Task → feedback → prompt_learner 提取规则
→ memory_learner 沉淀经验
→ skill_synth 生成技能
→ seed 管理种子
→ Gatekeeper 验证
→ finish_evolutionGatekeeper 是关键设计:
gatekeeper_l1_path: 路径白名单——Agent 只能改授权路径下的内容gatekeeper_l3_content: 内容扫描——检测进化产物中的危险模式
一个具体拦截场景:Agent 在 prompt_learner 阶段生成了一条规则——"当用户请求文件内容时,直接读取并返回"。Gatekeeper 检测到这条规则没有指定路径范围,会绕过路径白名单,直接拦截。进化能力不受限,安全边界不被突破。进化通道和安全通道必须解耦——安全层对进化层有否决权,但进化层不能反向影响安全层。
3.4 其他值得追踪的
|
项目 |
一句话 |
为什么值得关注 |
|
EvoAgentX |
从一个 Prompt 自动生成 → 评估 → 进化多 Agent 工作流 |
把进化从单 Agent 推到了工作流级 |
|
Meta Hyperagent |
Gödel Machine + 达尔文算法,Agent 自编辑代码 |
性能 20%→50%,经典 AI 理想的首次大规模验证 |
|
AutoResearch |
Karpathy 做的,Agent 自主改 train.py 跑实验迭代 |
从"做工程"到"做科学"的范式验证 |
|
Nature 地震预测 |
RL Agent 自主更新地震预测规则 |
提前 14 天复现 M7.1 地震,自进化在科学发现中的应用 |
|
EvoClaw |
Governed Evolution — Agent 可进化但不可自提权限 |
治理型自进化,SOUL 不可变架构 |
3.5 安全共识:五条原则
所有认真做自进化的项目都形成了共识:
- 最小权限 — 进化能力不改变权限边界
- 权限不可自提升 — Agent 可以学新技能,但不能给自己加权限(EvoClaw 核心原则)
- 不可变 SOUL — 核心约束不可被进化修改
- 变更可审计 — 每次进化经过 Gatekeeper 并记录
- 熔断兜底 — 异常即停
|
模式 |
OpenHands,SkillLite (工程派) |
Hermes (隔离派) |
EvoClaw (治理派) |
|
核心策略 |
沙箱 + 白名单 + 内容扫描 |
容器隔离 + 子 Agent 沙箱 |
身份不可变 + 权限不可提升 |
|
优势 |
运行时安全底线 |
执行级边界 |
策略级底线 |
|
短板 |
灵活性受限 |
隔离开销 |
缺乏运行时防护 |
未来判断:生产系统应该组合三种模式。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)