从“算得多”到“算得巧”,RedundancyLens:重塑多模态大模型的效率边界
该论文由合合信息团队参与完成,聚焦多模态大模型推理阶段的效率优化问题。研究发现,在主流的 decoder-only 架构中,视觉 Token 在多层处理过程中存在明显的结构性冗余,这使模型在高分辨率输入和长序列场景下面临较大的算力压力。为此,研究团队提出了RedundancyLens,可在推理阶段动态识别并削减视觉 Token 的冗余计算,在无需额外训练的前提下显著降低计算开销,同时保持模型性能提
论文简介
该论文由合合信息团队参与完成,聚焦多模态大模型推理阶段的效率优化问题。研究发现,在主流的 decoder-only 架构中,视觉 Token 在多层处理过程中存在明显的结构性冗余,这使模型在高分辨率输入和长序列场景下面临较大的算力压力。为此,研究团队提出了RedundancyLens,可在推理阶段动态识别并削减视觉 Token 的冗余计算,在无需额外训练的前提下显著降低计算开销,同时保持模型性能提升,为多模态模型的高效部署提供了新的工程思路。
合合信息是一家中国领先的人工智能产品公司,长期关注多模态大模型与文本智能技术在实际场景中的应用,相关能力已在多个 C 端与 B 端业务中落地。在这项工作中体现了其对模型效率优化和实际部署问题的持续关注。
研究背景与现有不足
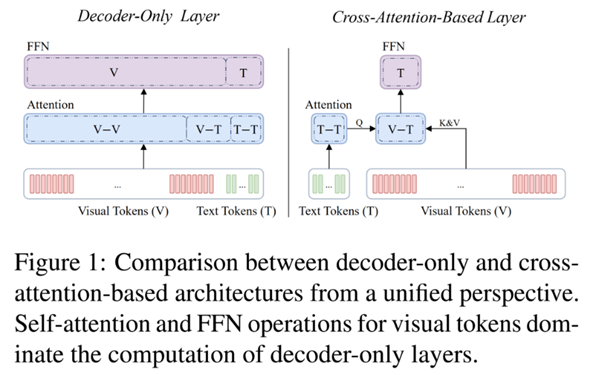
多模态大语言模型(MLLM)在计算机视觉和自然语言处理交叉领域快速发展,但其架构设计面临性能与效率的关键权衡。当前主流架构包括decoder-only 架构和交叉注意力架构:decoder-only 架构如LLaVA将图像token与文本token拼接,由LLM统一处理,自注意力和FFN操作占计算主导,视觉token数量多导致效率低下;交叉注意力架构如Flamingo通过交叉注意力层集成视觉信息,跳过LLM对视觉token的处理,效率高但整体性能较低。现有工作如NVLM比较显示,decoder-only 架构性能更优,但处理高分辨率图像时计算开销大,限制实际应用。视觉token压缩方法如FastV通过减少token数量加速,但剩余 token 仍然需要较高的计算开销,而本文从减少每个视觉token计算的角度出发,填补了研究空白。核心问题在于:是否在视觉token处理中存在冗余?如何无训练地分析和利用这种冗余?这为探索高效MLLM架构提供了动机。
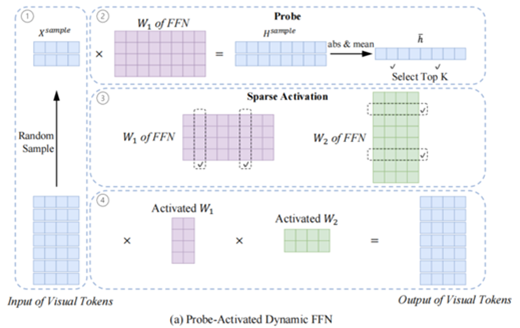
创新点一:Probe-Activated Dynamic FFN
Probe-Activated Dynamic FFN 旨在减少视觉token在前馈网络中的计算,通过动态选择FFN参数子集,实现免训练加速。其原理受MoE启发,但无需训练路由器,而是通过探针采样策略激活参数:从视觉token中随机采样一小部分子集,计算隐藏表示并取绝对值均值,选择top-K个激活值对应的参数索引,仅激活这些参数处理所有视觉token。
具体实现中,采样子集用于估计隐藏表示的激活模式,从而确定哪些FFN参数对当前输入最重要,避免了全参数计算。与已有工作如MoE相比,该方法无需额外训练,直接在推理时应用,降低了部署成本;同时,它仅针对视觉token,文本token保持原样,确保了语言能力的完整性。
优点包括计算量大幅减少、兼容现有MLLM变体(如带门控机制的FFN),但可能因采样不确定性引入波动,通过设置采样比例和激活参数数来平衡效率与准确性。
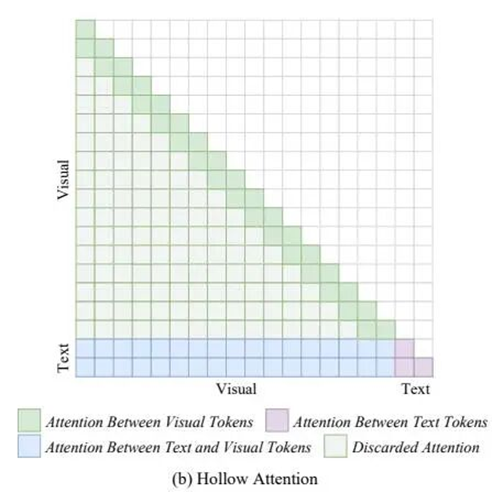
创新点二:Hollow Attention
Hollow Attention 是一种自定义稀疏注意力模式,旨在减少视觉token在自注意力中的计算,同时保留视觉与文本token间的注意力关系。其原理基于稀疏注意力,将视觉token间的全局注意力替换为局部注意力:每个视觉token仅关注前R_A个视觉token和所有文本token,而文本token仍可关注所有token,从而显著降低注意力开销,因为视觉token通常远多于文本token。动机在于视觉token序列长,全局注意力计算复杂度高,而局部注意力能捕捉空间相关性,减少冗余交互;同时,保持视觉-文本注意力确保多模态信息融合不受影响。
与标准自注意力相比,Hollow Attention 减少了视觉token间的长距离依赖,但实验表明这对性能影响小,说明视觉token处理中存在冗余。实现中,注意力范围R_A设为256,对应单子图像token数,平衡了局部性与计算效率。优点包括计算复杂度降低、易于集成到现有MLLM,但可能损失部分全局视觉上下文,通过实验验证了在大多数任务中性能保持。下图2(b)展示了注意力模式的变化,直观比较了全局与局部注意力,突显了计算缩减的机制。
创新点三:Layer Ranking Algorithm
Layer Ranking Algorithm 用于确定哪些层最适合应用计算缩减,通过排序层优先级,以最大化冗余利用而不损害性能。原理基于贪心搜索算法:构建紧凑验证集,逐步评估每个层应用缩减后的模型性能,选择性能下降最小的层进行排序,形成层排名列表;当需缩减特定层数时,选择排名最高的层。动机在于不同层对视觉token处理的冗余程度不同,全层组合评估计算不可行,因此需高效排序策略。
算法细节包括惩罚机制:如果缩减后性能下降,差异乘以惩罚系数α>1,鼓励优先选择性能稳定的层;实验中发现后几层冗余更高,因此采用混合策略,后L_p层预分配高排名,剩余层通过搜索排序,减少评估次数。与随机或位置策略相比,该算法更准确地识别冗余层,但依赖验证集质量,可能因小样本引入偏差。
优点包括免训练、可适配不同MLLM,但计算成本较高,需数百次评估,未来可优化搜索效率或探索其他特征。

实验与结果分析
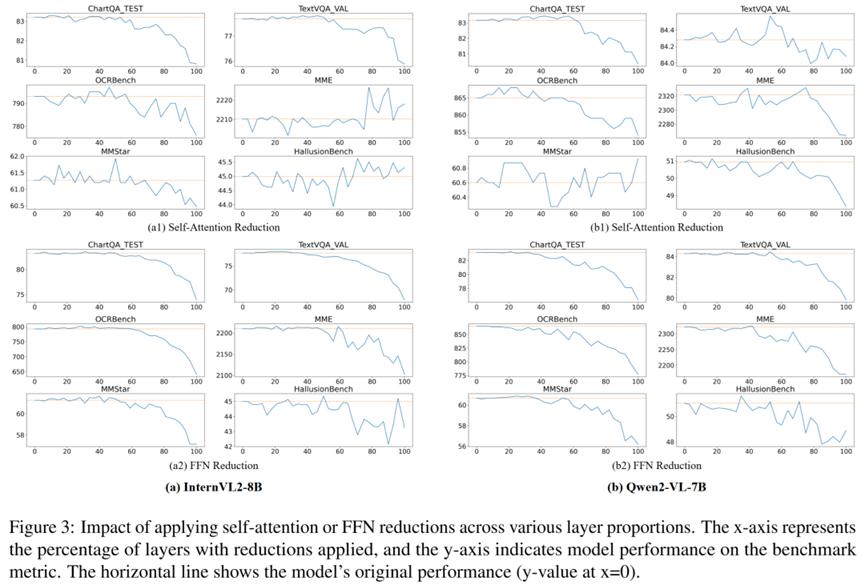
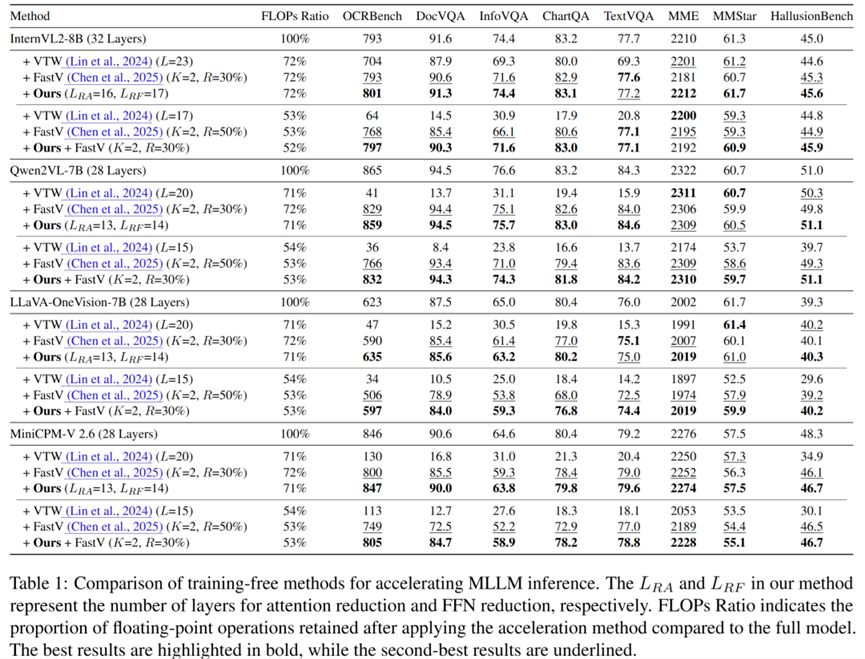
实验在多个主流MLLM上进行,包括InternVL2-8B、Qwen2-VL-7B等,评估八个基准测试如OCRBench、DocVQA等。冗余分析结果显示:在约50%层中应用缩减,模型性能保持甚至提升,如图3所示,性能曲线在缩减层比例增加时先稳定后下降,FFN缩减比注意力缩减下降更陡。
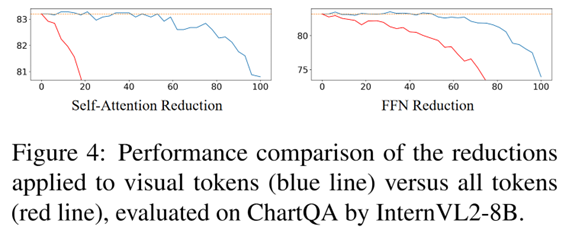
对比视觉token与全token缩减:图4显示仅缩减视觉token性能稳定,而缩减全部token(包括文本)导致性能急剧下降,证实冗余特定于视觉token。与其他免训练加速方法比较:如表1,RedundancyLens在FLOPs减少约30%时,性能达到或优于FastV和VTW,且在OCRBench等文本丰富场景表现更佳,因Token压缩上限低。
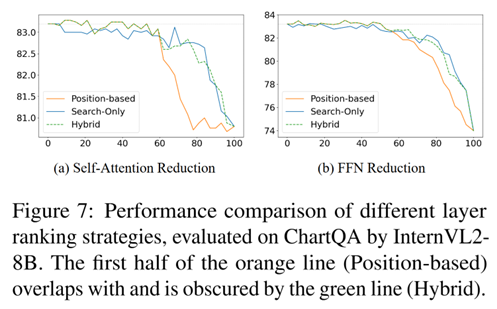
正交性验证:结合FastV,FLOPs减少约50%时,性能显著超过单用FastV,表明token数量缩减与token计算缩减互补。消融研究:图6显示,激活参数比例或注意力范围增加时,可缩减更多层而不影响性能,平衡效率与效果;图7比较层排序策略,混合策略优于纯位置或搜索策略。这些结果证实了视觉token处理中的结构化冗余,为MLLM架构优化提供了实证基础。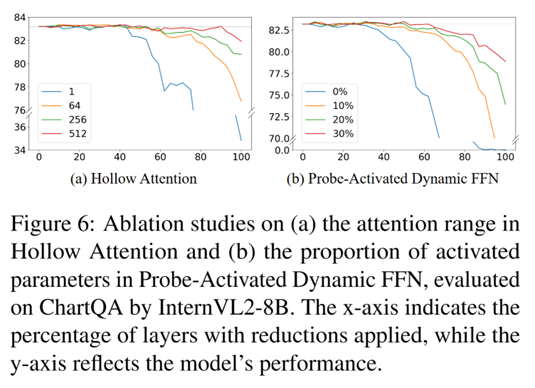
产品应用
在企业应用层面,该方法为多模态模型的大规模落地提供了更现实的路径。在 ToB 侧,如企业级文档扫描与识别、合同与票据 OCR、表单信息抽取、智能审核与质检系统等场景中,模型往往需要在高并发、有限算力或本地化部署条件下稳定运行。通过在推理阶段动态减少每个视觉信息的计算量,系统可以在保持高准确率的同时显著降低算力与能耗成本,从而提升整体服务效率。
在 ToC 侧,该方法同样适用于手机端拍照识别、即时翻译、智能搜索、辅助阅读等应用,使模型在移动设备或实时交互场景中运行得更快、更省电、响应更流畅。整体而言,这一技术让多模态能力不再局限于高算力环境,而是真正具备了在不同产品形态和终端条件下广泛应用的可行性。
总结与展望
本文通过RedundancyLens框架系统分析了解码器-仅MLLM中视觉token处理的冗余,揭示了结构化和聚类化的冗余模式,为高效架构设计提供了新见解。核心贡献包括提出免训练的分析方法、证明冗余存在性,并引入正交于现有token压缩的加速视角,实验验证了性能保持与效率提升。局限性在于层排序算法依赖验证集和贪心搜索,可能未找到最优层组合,且计算成本较高;未来工作可优化算法、探索更鲁棒的特征,或结合其他加速技术。总体而言,该研究推动了MLLM在性能与效率平衡方面的进展,鼓励从token和计算双维度考虑模型优化,具有实际应用潜力。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献673条内容
已为社区贡献673条内容

所有评论(0)