什么是 RAG
什么是RAG,RAG 是一种通过“检索外部知识”来增强大模型生成能力的技术。
在做 AI 应用开发时,你一定会遇到一个问题:
为什么 AI 有时候“一本正经胡说八道”?
这背后的核心原因是:
大模型只依赖训练数据,无法获取最新或私有数据
这时候,一个非常关键的技术就登场了:
RAG(检索增强生成)
一、什么是 RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种:
让大模型在回答问题前,先去“查资料”的技术
更正式一点的定义是:
它通过连接外部知识库,让 AI 在生成答案之前先检索相关信息,从而提高准确性 (ibm.com)
用一句人话解释
RAG 就是:
AI:我先查一下资料,再回答你
为什么需要 RAG?
传统大模型(例如 DeepSeek / GPT):
- 只能用训练时的数据
- 知识可能过时
- 不知道你的私有数据
RAG 解决的问题:
- 可以接入你的本地文档(PDF / txt / 数据库)
- 可以用最新数据
- 大幅减少“胡说八道”(幻觉)
二、RAG 的核心工作流程
一个完整的 RAG 系统,其实就 5 步:
Step 1:用户提问
用户:什么是 Vue?
Step 2:去知识库查资料
系统会去你的数据里找:
例如:
- 你上传的 PDF
- 文档
- 数据库
Step 3:找到相关内容
找到最相关的几段文本
Step 4:拼接 Prompt
把“资料 + 问题”一起发给 AI:
根据以下内容回答问题:
【资料】
【问题】
Step 5:大模型生成答案
这时候:
AI不是瞎编,而是“参考资料回答”
三、RAG 的核心组成(重点)
一个 RAG 系统 = 4 个核心模块:
知识库(Knowledge Base)
存你的数据:
- 文档
- 网页
- txt
Embedding(向量化)
把文本变成“数字向量”
专业解释:
embedding 是把文本转成一串数字,用来计算“相似度”
举例:
“猫” → [0.123, 0.98, ...]
“狗” → [0.120, 0.95, ...]
数值越接近 → 越相似
向量数据库(Vector DB)
存这些向量,例如:
- Chroma
- FAISS
- Milvus
作用:
- 快速找到“最像用户问题”的内容
大模型(LLM)
例如:
- DeepSeek
- GPT
- Claude
作用:
根据“检索到的资料”生成答案
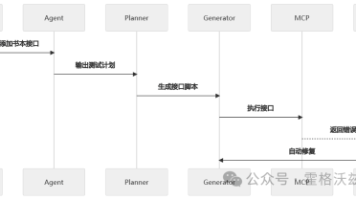
四、DeepSeek + 本地向量数据库实践项目的架构(重点)
其实是一个标准架构:
用户上传文件
↓
文本切分
↓
Embedding(向量化)
↓
Chroma(存储)
↓
用户提问
↓
向量检索
↓
DeepSeek 生成答案
用一句话总结:
DeepSeek 负责“回答”,Embedding 负责“找资料”
五、踩的坑(非常关键)
DeepSeek 不能做 embedding
这是很多人第一次做 RAG 都会踩的坑:
- DeepSeek 只负责聊天(LLM)
- 不提供向量能力
所以会遇到:
- 上传失败
- Timeout
- OpenAIEmbeddings 报错
六、正确解决方案(推荐)
需要补一个“向量模型”:
推荐方案:本地 embedding(Ollama)
使用:
- Ollama
- nomic-embed-text
优点:
- 免费
- 不需要 OpenAI key
- 不会超时
方案2:HuggingFace
优点:
- 简单好用
缺点:
- 需要网络
- 可能限流
七、RAG 的本质理解
RAG 是一种通过“检索外部知识”来增强大模型生成能力的技术。
它的核心流程是:
- 先将文档向量化存入数据库,
- 在用户提问时通过相似度检索相关内容,
- 再结合这些内容生成更准确的答案。
相比传统大模型,RAG 可以:
- 使用私有数据
- 提供最新信息
- 减少幻觉
八、总结(最重要)
一句话总结:
RAG = 检索(找资料) + 生成(AI回答)
再通俗一点:
- 普通AI:靠记忆回答
- RAG AI:查资料回答

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)