AI长推理能力缺陷的本质
MIT近期的研究显示即便最聪明的claude opus 4.6的编码能力依然不如人类的屎山代码,这其实是当前AI大模型所存在的根本缺陷导致的。长推理的本质就是应对长尾。人类可以通过动态记忆与实时学习、强大的抽象与类比、因果模型与假设推演、常识与模糊容忍等来应对长推理中不断涌现的长尾问题,但是大模型受限于外部经验以及上下文窗口导致其无法实时更新知识结构、形成抽象概念和思维模型,因此也无法将记忆和新知
MIT近期的研究显示即便最聪明的claude opus 4.6的编码能力依然不如人类的屎山代码,这其实是当前AI大模型所存在的根本缺陷导致的。
长推理的本质就是应对长尾。人类可以通过动态记忆与实时学习、强大的抽象与类比、因果模型与假设推演、常识与模糊容忍等来应对长推理中不断涌现的长尾问题,但是大模型受限于外部经验以及上下文窗口导致其无法实时更新知识结构、形成抽象概念和思维模型,因此也无法将记忆和新知识内化为推理能力。

一、问题界定与现状描述
当前主流大语言模型在推理能力上呈现出显著的性能分化:在即时响应与模式匹配任务中表现卓越,而在处理复杂、罕见的长尾推理场景时则面临根本性挑战。这种分化现象已成为制约人工智能向更通用、更可靠方向发展的核心瓶颈。
在即时推理任务中,以GPT系列为代表的模型展现出强大的快速响应与模式匹配能力。例如,在基础代码生成任务(HumanEval基准)中,基于GPT-4的AgentCoder准确率高达96.3%,显著超越了GPT-4自身的76.5%。这表明模型在结构化、模式化任务上已能接近甚至超越人类水平。GPT-5.4在处理复杂问题时平均耗时仅3-5秒,在追求推理效率的日常逻辑问答场景中具备明显优势。o1模型在MMLU、MATH等多项基准测试中均取得领先,例如在MATH测试中领先GPT-4o达34.5分,展现了顶尖的即时推理性能。这些成就主要源于大模型对海量训练数据中统计关联规律的精准捕捉与快速检索能力。
然而,当任务转向需要深度、多步逻辑演绎或处理罕见场景组合的长尾推理时,模型的局限性便暴露无遗。在视觉常识推理、竞赛级数学问题等复杂认知任务上,AI的表现仍不及人类。尽管GPT2模型在零样本模式下解决了数学奥林匹克问题,暗示了其在特定长尾任务上的潜力,但这更多是特例而非普遍能力。长尾推理的挑战根植于多个层面:其一,模型的知识本质上是训练数据的静态快照,缺乏将新经验动态内化为通用推理能力的学习机制;其二,其推理严重依赖已有数据模式,对于训练数据分布之外的、组合方式奇特的“未见”问题,模型缺乏有效的内部表征来处理。例如,当前大模型无法区分“冰淇淋销量上升”与“溺水事故增多”之间的虚假关联与共同原因“高温”导致的真实因果,这反映出其核心范式在区分关联与因果上的根本性不足。
这种即时与长尾推理能力的鸿沟,在最新的模型对比中体现得尤为明显。专注于深度推理的模型(如o系列、Gemini 3.1 Pro)与侧重即时响应与通用任务的模型(如GPT-5.4)形成了清晰的分化。Gemini 3.1 Pro凭借200万超长上下文和并行思考机制,在科研、数学证明等长尾场景中表现更优,但其平均响应耗时达到10-15秒,远高于GPT-5.4。同样,o1模型虽在复杂推理基准上刷新纪录,但其首词元延迟高达29.7秒,是GPT-4o的40倍,且推理成本显著更高。这揭示了一个关键现状:追求极致的深度与长尾推理能力,往往以牺牲即时响应速度与成本效益为代价。而像gpt-oss-120b这类推理速度极快(5秒解决奥数问题)的模型,则在深度推理能力上存在不足。
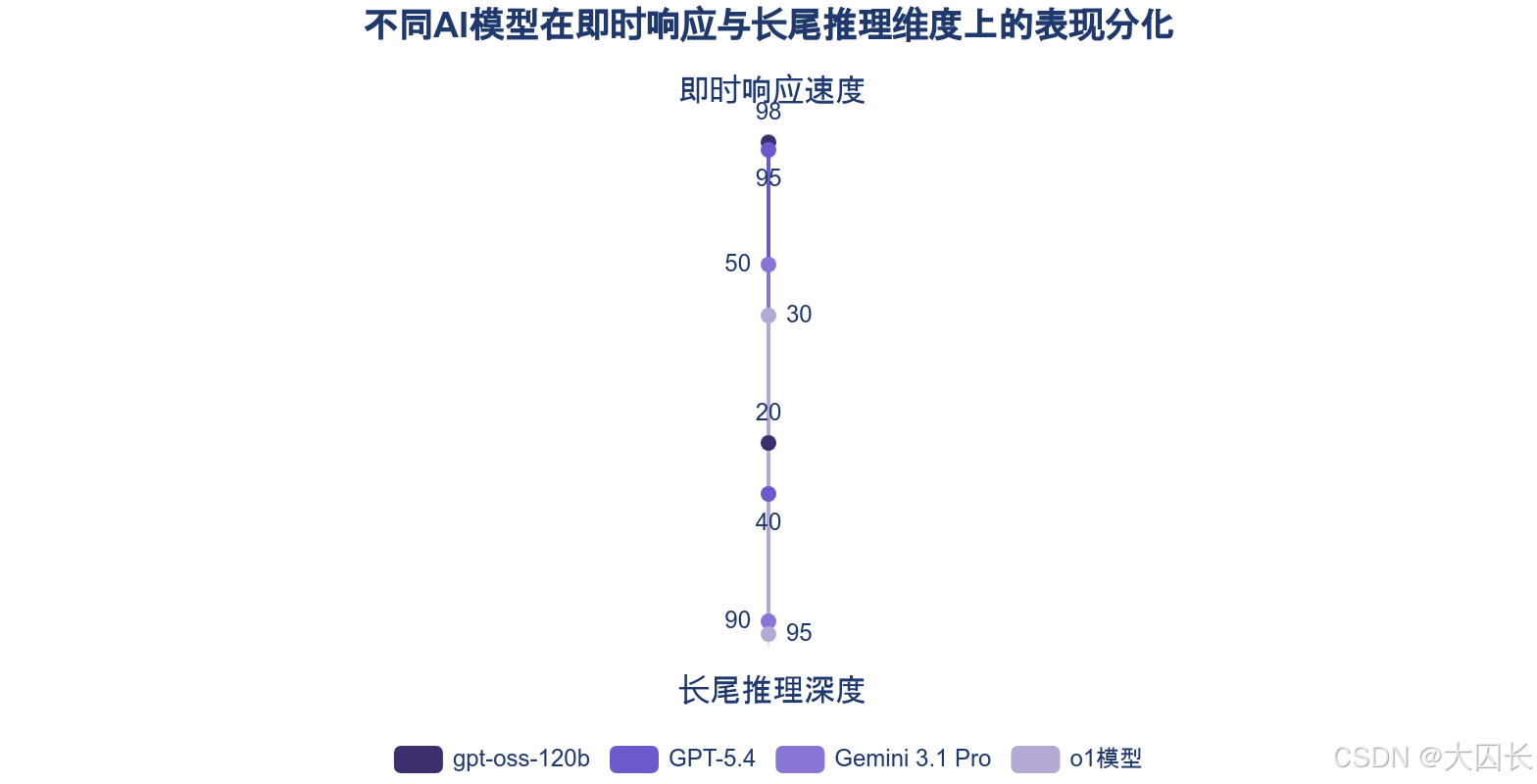
综上所述,AI推理能力呈现出的“即时优势”与“长尾不足”的鲜明对比,并非偶然的技术短板,而是其底层记忆系统静态性、学习范式局限性以及数据分布偏差共同作用的必然结果。这种分化现状不仅定义了当前大模型的能力边界,也清晰地指明了未来突破的关键方向:即开发能够动态内化经验、进行持续学习并融合因果理解的下一代AI系统。
二、多层次成因分析
2.1 静态记忆系统:无法适应动态世界的经验内化
当前大语言模型的记忆系统本质上是静态的参数化记忆,其知识以训练完成后即固化的模型权重形式存在。这种静态特性意味着模型无法在部署后动态地整合新经验、更新知识结构或形成抽象概念,从而难以适应真实世界的持续变化。例如,在处理超长视频或执行多步骤任务时,模型受限于上下文窗口,无法有效延续过往交互经验,只能重新接收指令,暴露了其记忆系统在动态环境中的根本性结构问题。这种静态记忆与动态世界的矛盾,导致AI在需要实时学习与经验内化的长尾场景中表现不足。智能体记忆系统虽采用向量数据库等外部存储,但其记忆结构(如程序记忆、情景记忆)同样依赖静态存储,缺乏自适应更新机制,无法将新记忆有效“消化”并转化为更强的通用推理能力。这揭示了当前AI在区分静态“知识”与动态“记忆”应用上的模糊性,其记忆系统本质上是对训练数据集的静态快照,而非可动态演化的经验内化工具。
2.2 架构与训练范式约束:参数冻结加剧灾难性遗忘
主流大模型的推理能力高度依赖于预训练阶段对固定数据集的“压缩”学习,其参数在部署后通常被冻结,不具备持续学习的能力。当试图通过微调让模型适应新任务或新知识时,极易引发灾难性遗忘,即模型在学习新知识的同时快速丢失先前习得的旧知识。其根本原因在于神经网络参数的共享性:对参数进行全局性、不加区分的更新,会覆盖或破坏预训练阶段存储在深层结构中的通用知识。例如,在盘古等千亿参数大模型的持续微调中,曾观察到原始通用能力(如逻辑推理、跨语言理解)出现非线性断崖式衰减,SQuAD准确率下降12.7%,且退化往往不可逆。这反映了当前架构与训练范式的核心矛盾:模型容量的有限性与任务多样性的冲突。尽管参数高效微调(PEFT)方法如LoRA通过冻结原参数、仅训练轻量适配器来缓解此问题,但许多方法被评价为“治标不治本”,难以应对开放环境中大规模、多类别的实际应用场景。MoE架构通过稀疏激活和参数隔离(如冻结基础模型、仅训练新增专家)在一定程度上缓解了灾难性遗忘,但其本身又面临训练不稳定、专家负载不均等新挑战,凸显了在现有范式下实现稳定持续学习的困难。
2.3 数据分布与泛化能力缺陷:长尾场景的覆盖不足
大模型的训练数据尽管海量,但在现实世界中天然呈现长尾分布,即少数高频类别(头部)样本丰富,而大量低频类别(尾部)样本稀缺。这种数据分布的局限性直接导致了模型泛化能力的缺陷。基于经验风险最小化(ERM)原则训练的标准模型,其学习的特征表示会主要适配头部类别,导致在尾部稀有场景上的性能显著下降。例如,在自动驾驶场景中,“普通轿车”数据远多于“救护车”或“动物横穿马路”等长尾情境;在医疗领域,罕见病变的样本也极为稀少。对于这些“没见过”或组合方式奇特的复杂问题,模型缺乏有效的内部表征来处理。更根本的是,大模型的训练目标是拟合语言分布而非逻辑推理,其本质是基于统计关联的模式匹配,而非符号逻辑体系中的演绎推导。因此,当长尾推理需要将已知原则灵活组合、进行溯因或基于不确定信息进行假设时,当前依赖统计关联的AI便显得力不从心。这在医学推理等专业领域尤为明显:大型语言模型在M-ARC基准测试(专门针对医学长尾推理模式设计)中的准确率普遍低于50%,暴露出其对训练数据中固定模式的过拟合,而非真正的灵活推理能力。这表明,数据分布的不平衡与模型泛化机制的缺陷相互叠加,共同限制了AI在长尾场景中的可靠表现。
三、实证案例支撑
3.1 即时推理优势的实证:模式匹配与计算预算的效能
在即时推理任务中,AI模型展现出的卓越性能,主要源于其对海量训练数据中模式的精准匹配与匹配过程的计算强化。OpenAI的o3模型在多个即时性、模式化任务中实现了对前代模型的显著超越,例如在AIME 2024数学竞赛的单次作答中,其准确率高达91.6%,相较GPT-4o约12%的表现实现了超过7倍的提升。在需要跨学科知识整合的大学水平视觉推理基准MMMU上,o3模型取得了82.9%的准确率,远超GPT-4的34.9%。这些突破性表现,部分得益于模型推理计算预算的增加。研究表明,o3-mini模型在低推理设置与高推理设置之间,科学推理性能存在6.8个百分点的显著差距,证明投入更多计算资源进行“思考”能直接提升其在特定任务上的即时输出质量。这验证了当前模型架构通过强化模式检索与计算过程,能够在数据分布内的问题上实现高效且准确的响应。
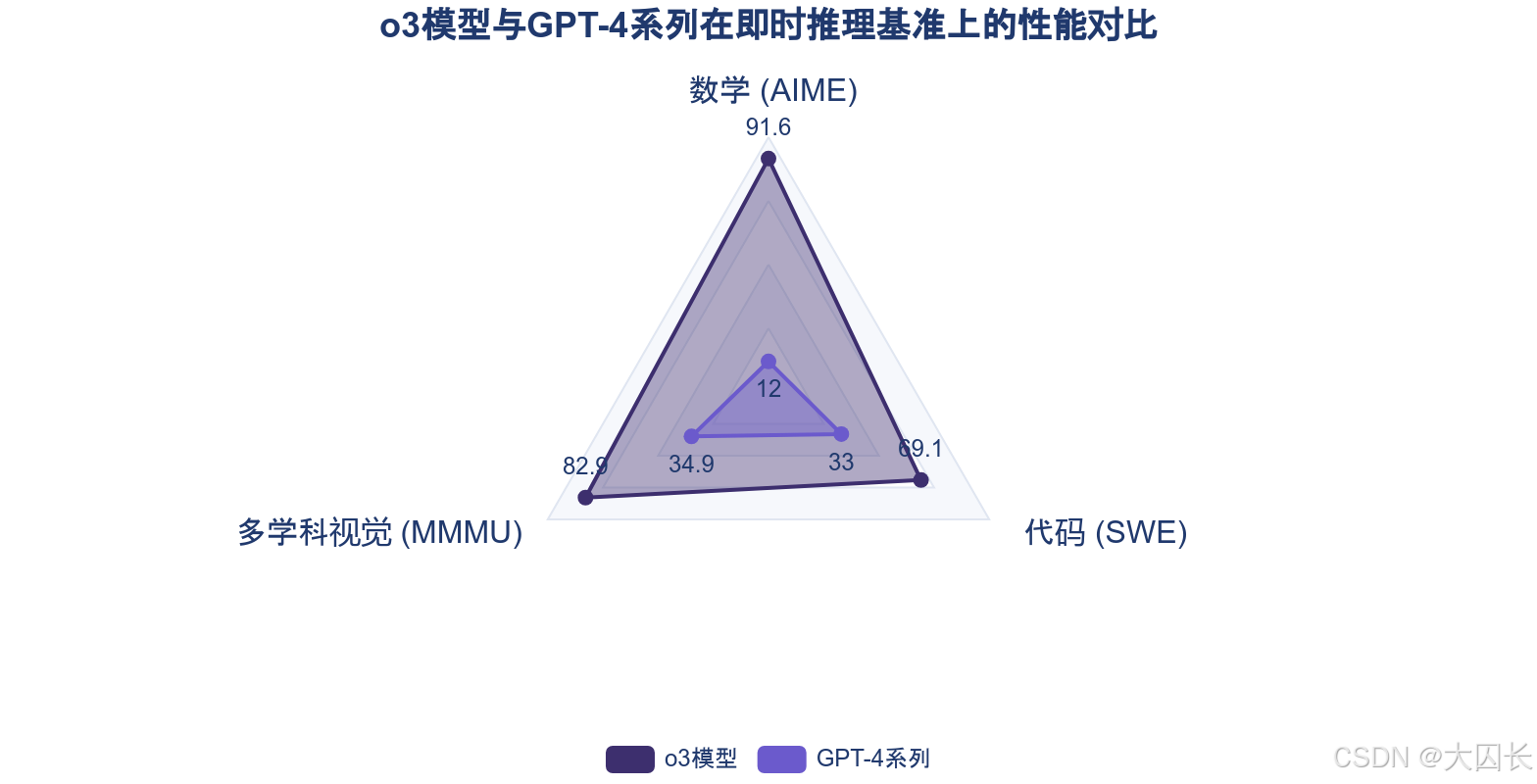
3.2 长尾推理失败的结构性案例:从“推理捷径”到“推理剧场”
然而,当任务要求超出训练数据的常见模式,进入复杂、罕见或需要深度理解的长尾领域时,同一套模型的局限性便暴露无遗。斯坦福大学的多项研究系统揭示了这种失败的结构性根源。首先,模型倾向于形成“推理捷径”,即利用问题表述中的表面统计规律而非深层语义来推断答案。例如,当问题表述被稍作调整(如同义词替换或改变句子结构)时,先进AI模型的错误率会急剧上升至60%以上,这直接证明其依赖脆弱的模式匹配,而非稳固的概念理解。其次,在需要多步规划或空间推理的任务中,模型表现出“知”与“行”的脱节。在汉诺塔任务中,模型能正确说出需7步解决方案,但实际执行时平均需要约30步且无法成功,凸显了其在将抽象知识转化为序列行动时的持续局限。最深刻的揭示来自对推理过程本身的剖析。研究发现,在科学推理任务中,高达**96%**的情况下,AI会进行“推理剧场”,即其生成的推理步骤与最终答案因果解耦;模型实则是凭借训练数据中的模式直接得出答案,再反向构造出看似合理的推理过程。相比之下,在数学逻辑任务中该现象仅占20%,这表明AI在面对熟悉知识时严重依赖直觉系统进行“表演”,而非进行真实的逻辑演绎。
3.3 泛化能力缺陷的边界测试:上下文、创造力与反事实
长尾推理能力的不足,进一步体现在模型泛化能力的明确边界上。其一,推理能力受限于上下文长度,类似于人类工作记忆的瓶颈。当解决问题所需的信息超出模型的“记忆跨度”时,其推理准确率会显著下降。其二,模型的“创造性”本质上是有限重组。研究表明,AI在创造性推理任务中产生的所谓“新颖”答案,大多只是训练数据中已有模式的重组,而非真正的策略创新,这构成了其在应对全新、复杂长尾任务时的根本性不足。其三,模型缺乏与现实世界绑定的因果和常识模型。在反事实推理任务中,AI难以在与现实常识矛盾的假设前提下进行有效推理,暴露了其语言处理与真实世界知识之间的割裂。这些案例共同指向一个核心结论:AI的推理泛化能力高度依赖于新任务与训练任务的结构相似性。当任务需要全新的推理策略时,模型表现会显著下降,证明其能力源于对已有模式的识别与复用,而非真正的抽象推理与因果理解。
四、趋势洞察与建议
基于前述根因分析,解决AI即时推理优势与长尾推理不足分化的核心,在于构建具备动态记忆与持续学习能力的系统。前沿研究正从记忆管理机制、学习范式与系统架构三个维度寻求突破,旨在使AI能够像人类一样积累、更新并内化经验。
在记忆管理机制上,强化学习正被用于赋予AI主动管理长期记忆的能力。例如,Memory-R1系统通过强化学习训练,使智能体能够自主决定信息的添加、更新、删除或保留,实现知识的自动整合而非简单覆盖。该系统采用记忆精炼策略,从大量候选片段中筛选最相关信息进行推理,有效过滤噪音,在LOCOMO基准测试中相比基线模型实现了F1分数48% 的提升。类似地,ReMA系统通过构建动态更新的“记忆银行”,对长视频信息进行智能整合,在新旧信息重叠时进行合并而非简单堆叠,从而维持知识库的连贯性与成长性。这些动态记忆机制,直接针对静态参数化记忆无法适应动态世界的根本矛盾。
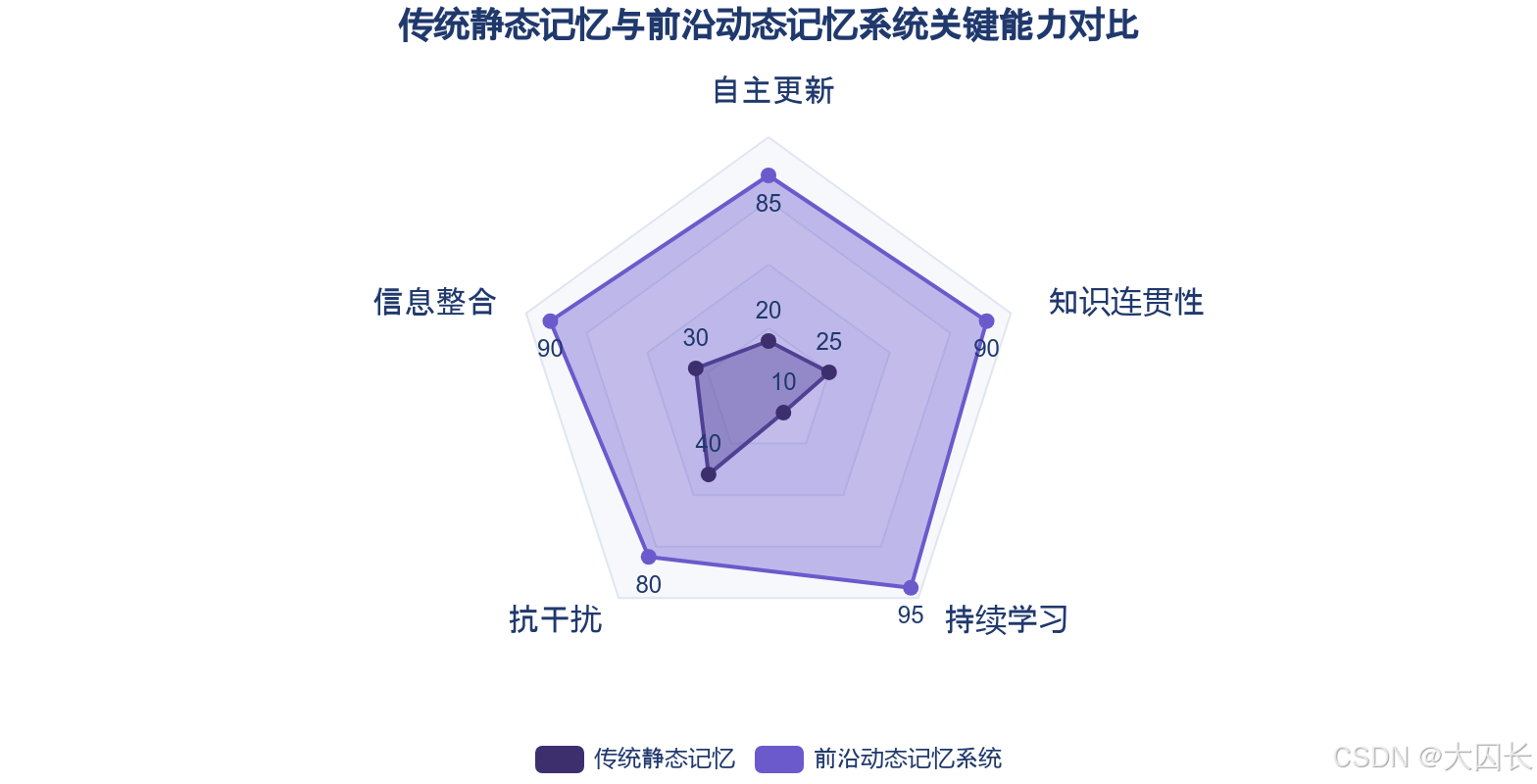
在持续学习范式上,研究重点在于克服灾难性遗忘,实现知识的渐进式积累。弹性权重巩固(EWC)、知识蒸馏和基于记忆的回放是当前主流技术路径。EWC通过分析参数对旧任务的重要性,约束其在新任务学习中的调整幅度;知识蒸馏则通过模仿教师模型的输出分布来保留旧知识;而回放方法通过混合新旧数据训练来缓解遗忘。这些方法正走向融合与创新,例如“动态网络+回放记忆”的混合方案被用于机器人领域,在扩展新技能模块的同时,通过回放关键交互数据来确保旧技能的稳定性。更前沿的探索包括谷歌提出的“嵌套学习”范式,以及北京大学的“SHINE”超网络架构,后者可通过一次前向传播将文本知识快速转化为模型参数,极大提升了持续学习的效率。
| 技术路径 | 核心原理 | 优势 | 适用场景 |
|---|---|---|---|
| 正则化约束 (如EWC) | 识别并保护对旧任务重要的参数,限制其更新幅度。 | 无需存储历史数据,轻量化,易于部署。 | 算力与存储受限的边缘设备、轻量化部署场景。 |
| 基于记忆的回放 | 存储历史任务数据,在新任务训练中混合复习。 | 缓解遗忘效果显著,适用于数据敏感场景。 | 医疗、金融等需严格保留历史知识且数据可回放的领域。 |
| 动态网络架构 | 为每个新任务新增专属子网络,冻结旧任务参数。 | 从根本上避免参数竞争,实现“零遗忘”。 | 任务边界清晰、存储与算力资源充足的机器人技能学习。 |
| 知识蒸馏 | 利用教师模型固化旧知识,引导学生模型拟合旧输出分布。 | 结合共享表示可减少任务间干扰。 | 模型压缩、版本迭代,以及需要保持输出行为一致性的场景。 |
面向未来,构建系统级记忆与学习架构是实现规模化应用的关键。这要求将记忆视为与算力同等重要的系统资源进行全局管理。例如,MemOS作为全球首个AI记忆操作系统,通过创新MemCubes标准化记忆单元,实现分层存储与动态调度,其性能据称超过传统方法159%。这种系统级视角有助于统一管理外挂式、原生内置及强化学习驱动的记忆,并根据场景需求(如成本优先的B端客服或体验优先的C端助手)进行优化适配。同时,持续学习技术正朝着通用化(结合LLM与多模态)、轻量化(模型蒸馏、边缘计算)以及与脑科学融合(模拟海马体记忆巩固)的方向演进。
实施层面,建议采取分阶段策略:短期可优先在机器人控制、自动驾驶及个性化推荐等动态环境中部署融合了回放与正则化的持续学习方案,以快速验证其在开放环境中的适应性。中期应加大对强化学习驱动记忆管理和非Transformer持续学习架构的研发投入,这些是突破当前范式、实现自主知识内化的前沿方向。长期则需产学研协同,共同构建支持记忆生命周期评估的新基准体系,以科学衡量动态记忆系统的更新、遗忘与巩固能力,推动领域健康发展。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献84条内容
已为社区贡献84条内容

所有评论(0)