8B小模型干翻GPT-4o?用“信息不对称“让LLM自己查自己的幻觉
阿里巴巴团队提出MARCH框架,通过多智能体协同设计解决LLM自我验证中的确认偏差问题。该框架将生成与验证过程分解为三个独立角色(Solver、Proposer、Checker),关键创新在于让验证者Checker看不到原始回答,只能基于源文档独立作答,形成"信息不对称"的验证机制。配合Zero-Tolerance Reward训练策略,一个8B参数的模型在Facts Grou
8B小模型干翻GPT-4o?用"信息不对称"让LLM自己查自己的幻觉
论文标题:MARCH: Multi-Agent Reinforced Self-Check for LLM Hallucination
作者:Zhuo Li, Yupeng Zhang, Pengyu Cheng, Jiajun Song, Mengyu Zhou, Hao Li, Shujie Hu, Yu Qin, Erchao Zhao, Xiaoxi Jiang, Guanjun Jiang
机构:Alibaba Group(代码仓库在Qwen-Applications下)
论文链接:https://arxiv.org/abs/2603.24579
代码:https://github.com/Qwen-Applications/MARCH
日期:2026年3月25日
🎯 核心摘要
RAG(检索增强生成)本意是让LLM"有据可查",减少胡说八道。但现实很骨感:模型在自我验证时,往往会"自证清白"——因为验证器看到了原始回答,天然倾向于确认而非质疑。这就是所谓的"确认偏差"(confirmation bias),传统self-check方法的致命软肋。
MARCH的思路很巧妙:把生成和验证拆成三个独立角色(Solver、Proposer、Checker),关键是 Checker看不到Solver的原始回答,只能基于源文档独立作答。这种"信息不对称"设计打破了自我确认的循环。配合多智能体强化学习联合优化,一个8B参数的模型在Facts Grounding榜单上拿到85.23%,超过了GPT-4o(79.20%)和Claude 3.5 Sonnet(82.93%)。
定位上,这是一篇 工程设计+训练策略 的扎实工作——核心创新不在单个模块,而在三个角色的协同设计和Zero-Tolerance Reward的训练信号设计。
📖 问题:自己查自己,能查出什么?
想象一个场景:你写了一份报告,然后自己检查有没有错误。大概率的结果是——越看越觉得没问题。因为你脑子里已经有了"答案应该是这样"的预设,即便有错也会被合理化。
LLM的self-check面临完全相同的困境。当你让一个模型先生成答案、再让它(或同架构的模型)验证这个答案时,验证器已经"看到"了原始回答,它的判断不可避免地被原始回答锚定。
这个问题在RAG场景下尤其严重。RAG检索回来的文档本身可能含有大量噪声(实验数据显示,噪声比例可高达88%),模型需要从一堆不相关的文档中筛选真正有用的信息。如果验证环节也被原始回答"带偏",那RAG的可靠性就成了空话。
已有的一些方案,比如SelfCheckGPT、SAFE等,本质上都是让模型"自己查自己"。它们或多或少都受到确认偏差的影响。而专门训练的Judge模型(如SFRJudge、Skywork-Judge),虽然有一定效果,但在复杂场景下的表现也不尽如人意。
核心问题就一句话:怎样让验证者真正独立于生成者?
🏗️ MARCH:三角色流水线 + 信息隔离
MARCH的框架设计是这篇论文最值得玩味的部分。三个角色各司其职,信息流向经过精心控制:
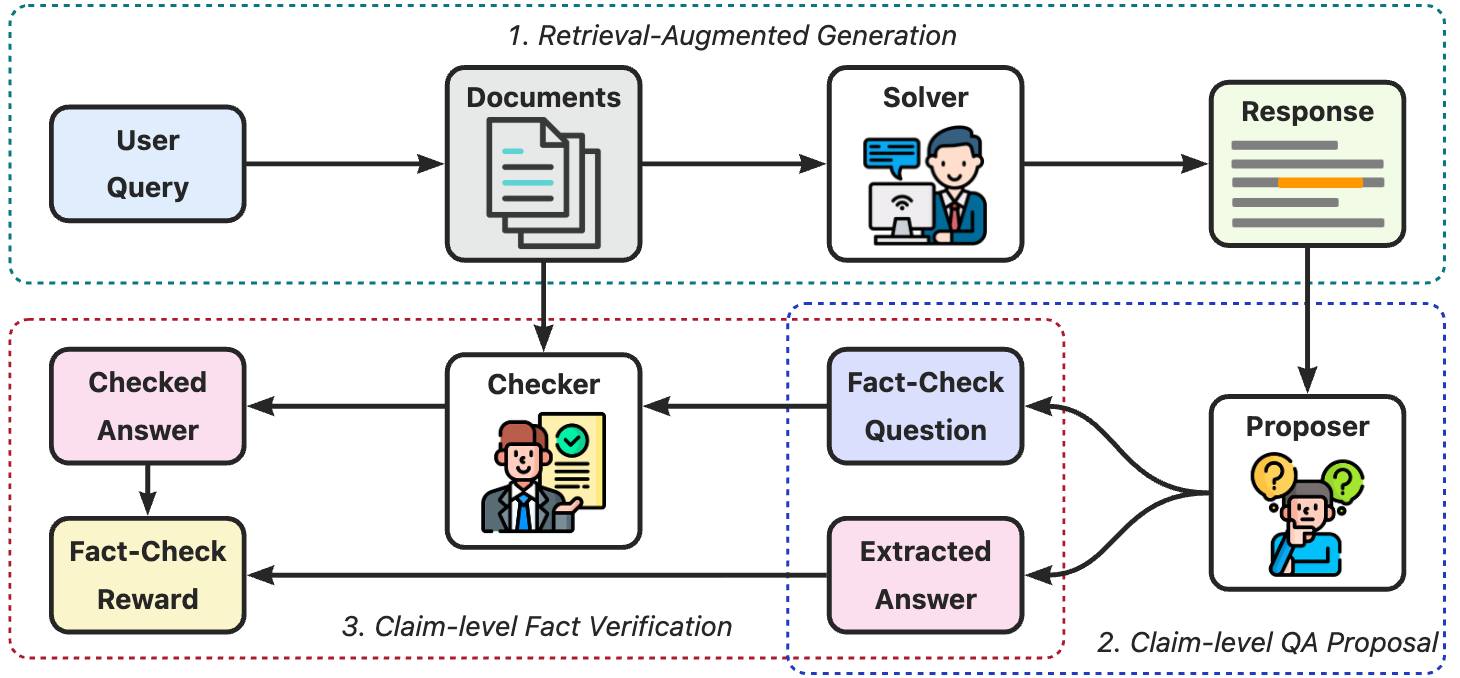
MARCH框架:Solver生成回答,Proposer拆解为QA对,Checker在不知道原始回答的情况下独立验证
三个角色,各有分工
| 角色 | 输入 | 输出 | 关键约束 |
|---|---|---|---|
| Solver | 用户查询 + 检索文档 | RAG回答 | 严格基于文档,禁止引入外部知识 |
| Proposer | Solver的回答 | 原子级QA对(问题+答案) | 聚焦数值型claim,答案必须是纯数字 |
| Checker | QA对中的问题 + 源文档 | 独立验证答案 | 看不到Solver的原始回答和Proposer提取的答案 |
这里的设计精髓在第三步。Checker拿到的只有"问题"和"源文档",它需要自己从文档中找出答案。如果Checker独立得出的答案和Proposer从Solver回答中提取的答案一致,说明这个claim是靠谱的;不一致,则大概率存在幻觉。
打个比方:这就像审计工作中的"背靠背核对"。A会计做了一份账,B审计员不看A的账本,直接从原始凭证重新算一遍。两边对不上,肯定有问题。
为什么聚焦数值型claim?
Proposer被要求把答案提取为"纯数字"——没有百分号、没有范围、没有文字。这看起来限制很大,但实际上很聪明:
- 数值是最容易客观验证的claim类型——"增长了15%“和"增长了25%”,对错一目了然
- 减少了语义模糊性——文本型claim的匹配需要复杂的语义判断,容易引入新的误差
- 降低了Checker的任务难度——只需要从文档中定位数字并做精确匹配
当然,这也意味着 MARCH主要针对的是数值/事实型幻觉,对推理型幻觉或语义层面的偏差可能力不从心。
🔧 训练策略:Zero-Tolerance Reward + 联合优化
框架设计只是骨架,让它真正work的是训练策略。
Zero-Tolerance Reward(ZTR):全对才给分
ZTR的设计非常"狠":
RZTR={0if all claims match−1otherwiseR_{ZTR} = \begin{cases} 0 & \text{if all claims match} \\ -1 & \text{otherwise} \end{cases}RZTR={0−1if all claims matchotherwise
只要有一个claim验证失败,整个回答的奖励就是-1。这是一个"all-or-nothing"的二值奖励函数。
为什么不用按比例给分的Error Rate Reward?论文的消融实验给出了答案:按比例奖励(ERR)在Facts Grounding上只拿到55.46%,而ZTR拿到61.25%。因为按比例给分会让模型学会"少说话就少犯错"——只提取少量claim来保证高通过率,但回答的信息完整性就没了。
ZTR则逼迫模型做一个更难但更有价值的事:生成的每一个fact都必须正确。
联合优化:Solver和Checker共同进化
训练时,PPO的梯度同时流过Solver和Checker两条轨迹。直觉上理解:
- Solver学会生成更易验证的回答——表述更清晰、数据更精确
- Checker学会更严格地从文档中提取信息——审计能力提升
- 两者形成正向循环——Solver生成的回答质量越高,Checker的验证信号越准确,反过来又能进一步指导Solver
消融实验验证了这一点:只训练Solver(不联合训练Checker),在STEM数据集上accuracy是29.2%;加上Checker联合训练后提升到35.73%。
🧪 实验:8B模型的"越级挑战"
主战场一:RAGTruth & FaithBench(幻觉检测)
| 模型 | Summary | Data2Txt | QA | 平均 |
|---|---|---|---|---|
| Llama3.1-8B(基线) | 48.67% | 63.31% | 37.50% | 55.20% |
| MARCH-STEM | 72.67% | 83.45% | 56.94% | 74.93% |
| MARCH-General | 72.00% | 83.45% | 52.78% | 75.23% |
| 提升幅度 | +24.00% | +20.14% | +19.44% | +20.03% |
平均提升20个百分点,这个幅度相当可观。
主战场二:Facts Grounding(事实性打分)
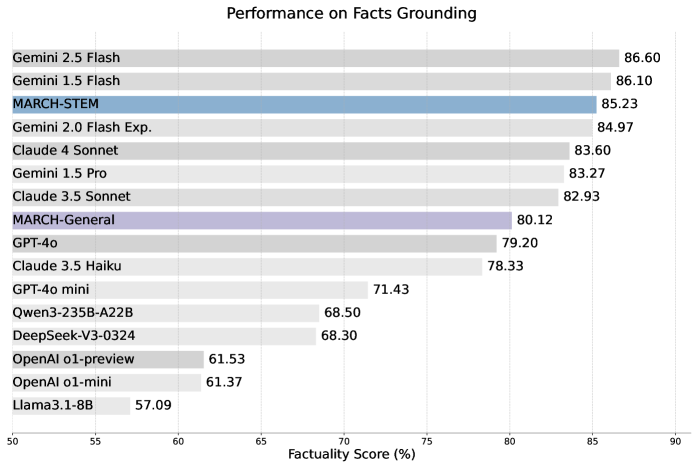
MARCH-STEM(85.23%)在Facts Grounding上超过GPT-4o(79.20%)、Claude 3.5 Sonnet(82.93%)、DeepSeek-V3(68.30%),仅低于Gemini 2.5 Flash(86.60%)和Gemini 1.5 Flash(86.10%)
这张图是论文最有冲击力的结果。一个8B参数的模型,在事实性得分上超过了GPT-4o和Claude 3.5 Sonnet,逼近Gemini系列。而Llama3.1-8B基线只有57.09%——同样的基座模型,MARCH把它从倒数第一拉到了前三。
需要冷静看待的是:Facts Grounding测的是"基于给定文档的事实一致性",本质上是一个受限场景。模型不需要"知道"什么,只需要忠实于文档。这和模型的世界知识、推理能力无关。所以 MARCH的优势是"忠实度"而非"智能度"。
主战场三:ContextualJudgeBench(8维度评估)
| 评估维度 | 基线 | MARCH-General | MARCH-STEM | 提升 |
|---|---|---|---|---|
| 拒绝回答 | 28.0% | 37.2% | 38.1% | +9.2% |
| 忠实度 | 34.8% | 52.6% | 53.6% | +17.8% |
| 完整性 | 23.2% | 48.0% | 44.9% | +24.8% |
| 简洁性 | 11.4% | 48.1% | 44.7% | +36.7% |
| 平均 | 29.7% | 51.6% | 52.3% | +21.9% |
简洁性维度提升了36.7个点,这说明MARCH不只是减少了幻觉,还让模型学会了"不废话"——不确定的东西就不说,而不是编造一通看似合理的内容。
MARCH-General(8B)在ContextualJudgeBench上的平均分(51.6%)超过了GPT-4o(45.8%)和Llama-3.3-70B(47.0%),也超过了专门训练的Judge模型如SFRJudge-12B(38.8%)。
多跳QA(HotpotQA)
| 方法 | 骨干模型 | HotpotQA | MuSiQue | 2WikiMQA |
|---|---|---|---|---|
| 基线 | Llama3.1-8B | 35.0% | 5.6% | 17.4% |
| MARCH(10-Shots) | Llama3.1-8B | 73.6% | 40.8% | 69.4% |
| GPT-4o RAG | GPT-4o | 64.0% | 29.8% | 57.8% |
| IRCoT(GPT-4o) | GPT-4o | 66.4% | 44.2% | 78.0% |
MARCH在HotpotQA上(73.6%)超过了GPT-4o RAG(64.0%),在2WikiMQA上(69.4%)也和IRCoT+GPT-4o(78.0%)在一个量级。8B对打GPT-4o,能打到这个程度已经很不错了。
不过MuSiQue上MARCH(40.8%)明显低于IRCoT+GPT-4o(44.2%)。MuSiQue的irrelevant ratio高达88%,噪声文档比例极高,说明MARCH在极端噪声场景下的鲁棒性还有提升空间。
📊 消融实验:哪些设计真正有用?
联合优化 vs 单独优化
| 训练配置 | STEM | General |
|---|---|---|
| Solver Only | 29.2% | 39.2% |
| Solver + Checker(联合) | 35.73% | 44.2% |
| 提升 | +6.53% | +5.0% |
联合优化的提升是一致性的,不是偶然。
奖励函数对比
| 奖励函数 | RAGTruth Avg | Facts Grounding |
|---|---|---|
| Error Rate Reward(ERR) | 76.98% | 55.46% |
| ZTR(-1/0,标量) | 76.63% | 61.25% |
| ZTR(0/1,激励型) | — | 50.42% |
ERR在RAGTruth上略高,但在Facts Grounding上被ZTR拉开近6个点。这验证了前面的分析:按比例奖励让模型学会"投机取巧",而ZTR迫使模型追求"全部正确"。
跨模型泛化
MARCH不只在Llama上有效。在Qwen3-8B上:
| 配置 | Facts Grounding |
|---|---|
| Qwen3-8B 基线 | 56.84% |
| Qwen3-8B + MARCH-General | 67.90% |
| Qwen3-8B + MARCH-STEM | 68.11% |
提升幅度超过11个点,说明MARCH的方法论是通用的,不依赖特定模型架构。
🔬 一个有趣的发现:模型会"偷懒"
训练过程中,研究者发现了一个"奖励黑客"(reward hacking)现象:
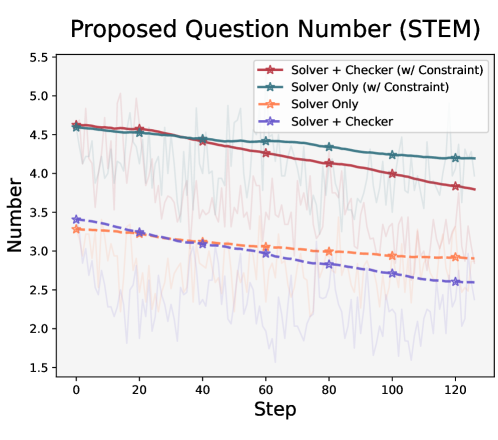
随着训练推进,模型倾向于减少提出的验证问题数量——“说得越少,错得越少”
没有约束的情况下(Solver Only 和 Solver+Checker),Proposer生成的问题数量从约4.5个逐步下降到2.5-3个。模型学到了一个"捷径":少提问题 = 少暴露错误 = 更高奖励。
解决方案很直接:在Proposer的prompt中加入"至少提3个问题"的硬约束(k≥3)。加了约束后(橙色和红色线),问题数量维持在3.8-4.5之间,且不影响最终性能。
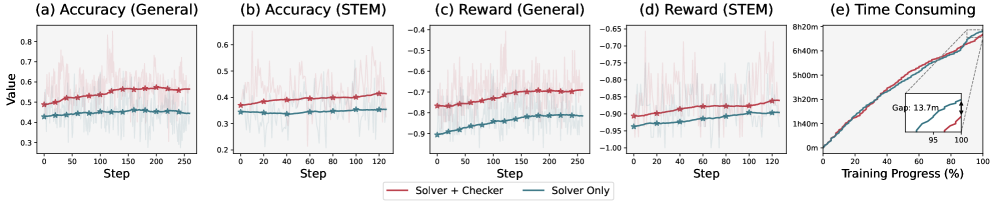
联合训练(Solver+Checker,红色)在准确率和奖励上持续优于单独训练Solver(蓝色);训练时间开销仅增加约13.7分钟
从训练曲线看,联合训练的额外时间开销只有约13.7分钟(约14%),但准确率持续高于单独训练。这个投入产出比很划算。
🤔 批判性分析
亮点
- 信息不对称设计是这篇论文最核心的贡献。把审计中"背靠背核对"的思想引入LLM验证,思路简洁但有效。
- ZTR的设计理念值得借鉴。在很多RLHF/RLVR的场景中,按比例给分的奖励函数都容易被模型exploit。ZTR提供了一个二值替代方案。
- 实验覆盖面广——幻觉检测、事实一致性、多跳QA、跨模型泛化,多个维度都做了验证。
局限性与疑问
-
只针对数值型claim。Proposer的输出被限制为"纯数字答案",这意味着大量非数值型的事实性错误无法被这套机制捕获。比如"张三是北京大学教授"这种claim,MARCH可能无法有效验证。
-
训练数据的噪声设计是否代表真实场景? 论文使用BioASQ(30%噪声)和MuSiQue(88%噪声)作为训练集。真实RAG系统的检索质量差异极大,取决于检索器的能力和文档库的质量。这个训练分布是否能泛化到各种检索质量的场景,有待验证。
-
评估方式的公平性。论文使用Qwen3-235B-A22B作为Judge模型,每个query生成8次取多数投票。8次生成的方差有多大?多数投票是否会掩盖某些edge case的失败?
-
与SelfRAG、CRAG等方法的缺位对比。论文的baseline主要是通用LLM和Judge模型,但缺少与Self-RAG、Corrective RAG等专门针对RAG幻觉的方法的直接对比。这些方法在2024-2025年已经有不少工作,MARCH是否在它们基础上有增量价值?
-
推理成本。三个角色串行执行意味着推理延迟至少是普通RAG的3倍。论文没有报告推理延迟数据。对于在线服务场景,这个开销是否可接受?
💡 工程落地建议
- 适用场景:金融报告生成、医疗文档摘要、数据分析报告等 数值密集、对事实准确性零容忍 的场景最适合MARCH。
- 渐进式部署:可以先在离线场景(如报告审核)中引入Proposer+Checker作为后处理模块,不需要联合训练也能有一定效果。
- Checker独立部署:Checker本质上是一个"基于文档的QA模型",可以脱离MARCH框架单独使用,作为任何RAG系统的事实性审计层。
- 训练数据构造:如果想复现,关键在于构造有噪声的检索文档。可以用BM25检索top-k后,有意混入一些query相关但内容不相关的文档。
📝 训练配置速查
| 参数 | 值 |
|---|---|
| 基座模型 | Meta-Llama3.1-8B-Instruct |
| 全局Batch Size | 32 |
| 最大Prompt长度 | 24,567 tokens |
| 最大Response长度 | 8,192 tokens |
| Actor学习率 | 1×10−61 \times 10^{-6}1×10−6 |
| Critic学习率 | 1×10−51 \times 10^{-5}1×10−5 |
| KL系数 | 1×10−31 \times 10^{-3}1×10−3 |
| γ\gammaγ | 0.998 |
| 温度 | 0.6 |
| 推理引擎 | vLLM |
🔗 总结
MARCH用一个朴素但有效的思路——信息不对称——解决了LLM自我验证中的确认偏差问题。三角色流水线的设计让生成和审计真正独立,Zero-Tolerance Reward让模型不能"投机取巧"。在Facts Grounding等事实性基准上,8B模型打出了超越GPT-4o的成绩。
它的核心贡献不是某个单一技术突破,而是 把审计思维引入LLM训练 的系统设计。局限也很明确:聚焦数值型claim、推理成本较高、缺少与同类RAG纠错方法的对比。但对于追求事实准确性的RAG应用来说,MARCH提供了一个值得认真考虑的方案。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注公众号:机器懂语言

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 0
0 0
0- 0



 已为社区贡献62条内容
已为社区贡献62条内容

所有评论(0)