背景:AI Agent 需要怎样的浏览器交互能力?
这一层是关键创新点。将 DOM 结构转换为 Agent 可理解的结构化数据过滤无关节点提供可压缩的页面状态支持语义标记Token 爆炸无法稳定定位交互节点Agent Browser 通过抽象层解决了这个问题。
- 如何在无头模式下稳定运行?
- 如何获取结构化 DOM 信息?
- 如何执行自动化交互?
- 如何处理多标签页、多会话?
- 如何保证隔离性与可重复性?
你可能会基于 Puppeteer 或 Playwright 搭建自动化层,但很快会发现:这些工具只是自动化驱动层,并不是为 LLM Agent 设计的“智能执行环境”。为此,Vercel 团队推出了 Agent-Browser —— 一个专为 AI Agent 设计的命令行浏览器自动化工具,核心目标是:让大模型能像人类一样“看”和“操作”网页。Agent Browser 的出现,正是为了解决这一层抽象缺失的问题。
| 对比维度 | Puppeteer / Playwright | Agent Browser |
|---|---|---|
| 设计目标 | 自动化测试 | LLM 驱动决策执行 |
| 页面抽象 | 原始 DOM | 结构化状态 |
| 决策支持 | 无 | 内置 Agent Loop |
| Token 优化 | 无 | 有 |
| Agent 协议 | 无 | 有 |
自动化工具解决“怎么操作浏览器”,Agent Browser 解决“如何让大模型理解并操作浏览器”
2. Agent Browser 的定位与核心目标
Agent Browser 是一个专门为 AI Agent 设计的浏览器执行环境。它不是简单的自动化工具,而是一个为 LLM 决策循环优化的浏览器运行框架。
其核心目标可以概括为:
- 提供稳定的浏览器运行时
- 提供结构化页面状态抽象
- 优化 Agent 与浏览器之间的交互协议
- 支持可扩展的自动化能力
- 提供可控的执行与安全边界
它更像是“Agent 的浏览器操作系统”,而不是一个单纯的自动化 SDK。
3. 核心设计理念:快照 + 引用机制
Agent-Browser 的创新在于其 “快照-引用”交互范式,完美契合 LLM 的推理模式。
3.1 快照(Snapshot):生成可操作的元素列表
执行 agent-browser snapshot -i 后,工具会扫描当前页面,提取所有可交互元素(按钮、输入框、链接等),并为每个元素分配唯一引用标识,如 @e1、@e2、@e3……同时附带简洁描述:
[
{ "id": "@e1", "text": "搜索框", "role": "textbox" },
{ "id": "@e2", "text": "Google 搜索", "role": "button" },
{ "id": "@e3", "text": "手气不错", "role": "button" }
]
这种设计让 LLM 无需理解 HTML 结构,只需根据自然语言描述选择对应引用即可。
3.2 引用操作:直觉式命令接口
所有交互命令均围绕引用展开,语法极简:
agent-browser click @e2 # 点击“Google 搜索”
agent-browser fill @e1 "Vercel" # 在搜索框填入“Vercel”
agent-browser type @e1 "AI" # 在不清理内容的情况下追加输入
agent-browser press Enter # 模拟按键
命令命名贴近人类直觉(click、fill、press),大幅降低 LLM 调用错误率。
4. 技术实现与架构
从设计角度看,Agent Browser 通常可分为四层:
4.1 Headless Browser Runtime
Agent-Browser 底层使用 Chromium 无头模式,确保与真实浏览器行为一致,但通过 Bash CLI 封装,启动速度远快于完整 Puppeteer 脚本。这保证了:
- 与真实浏览器一致的行为
- 完整的 JavaScript 执行能力
- 支持现代 Web 标准
这一层的职责是“执行”,而不是“决策”。
4.2 Browser Abstraction Layer
这一层是关键创新点。它负责:
- 将 DOM 结构转换为 Agent 可理解的结构化数据
- 过滤无关节点
- 提供可压缩的页面状态
- 支持语义标记
如果你直接把完整 DOM 丢给 LLM,会产生两个问题:
- Token 爆炸
- 无法稳定定位交互节点
Agent Browser 通过抽象层解决了这个问题。
4.3 Agent Control Layer
这一层实现了典型的 Agent 执行循环:
Observe → Think → Act → Observe
核心能力包括:
- 页面状态读取
- 动作生成
- 执行动作
- 状态更新
- 失败重试机制
这使浏览器交互变成“可推理的流程”,而非黑盒自动化。
5. 执行流程解析
一个典型执行过程如下:
BrowserControllerAgentBrowserControllerAgent请求页面状态获取结构化 DOM返回页面状态精简后的页面描述执行动作(点击/输入)执行操作更新结果
关键设计点:
- 页面信息是可控压缩的
- 动作是受限的(白名单)
- 每一步都有状态反馈
- 可插入策略层(如权限校验)
7. 适用场景分析
适合:
- 基于 LLM 的浏览器 Agent
- SaaS 自动化机器人
- Web 流程自动执行系统
- 多步骤人机协同系统
不适合:
- 简单爬虫(直接用 Playwright 更轻量)
- UI 自动化测试(测试框架更成熟)
- 高并发抓取场景(需专用抓取系统)
8. 实战示例:让 Agent 自动完成搜索
首页我在电脑上安装 agent-browser
brew install agent-browser
后续步骤交给虾哥操作。以下是一个简单的自动化流程提示词,模拟 Agent 的网页搜索动作。
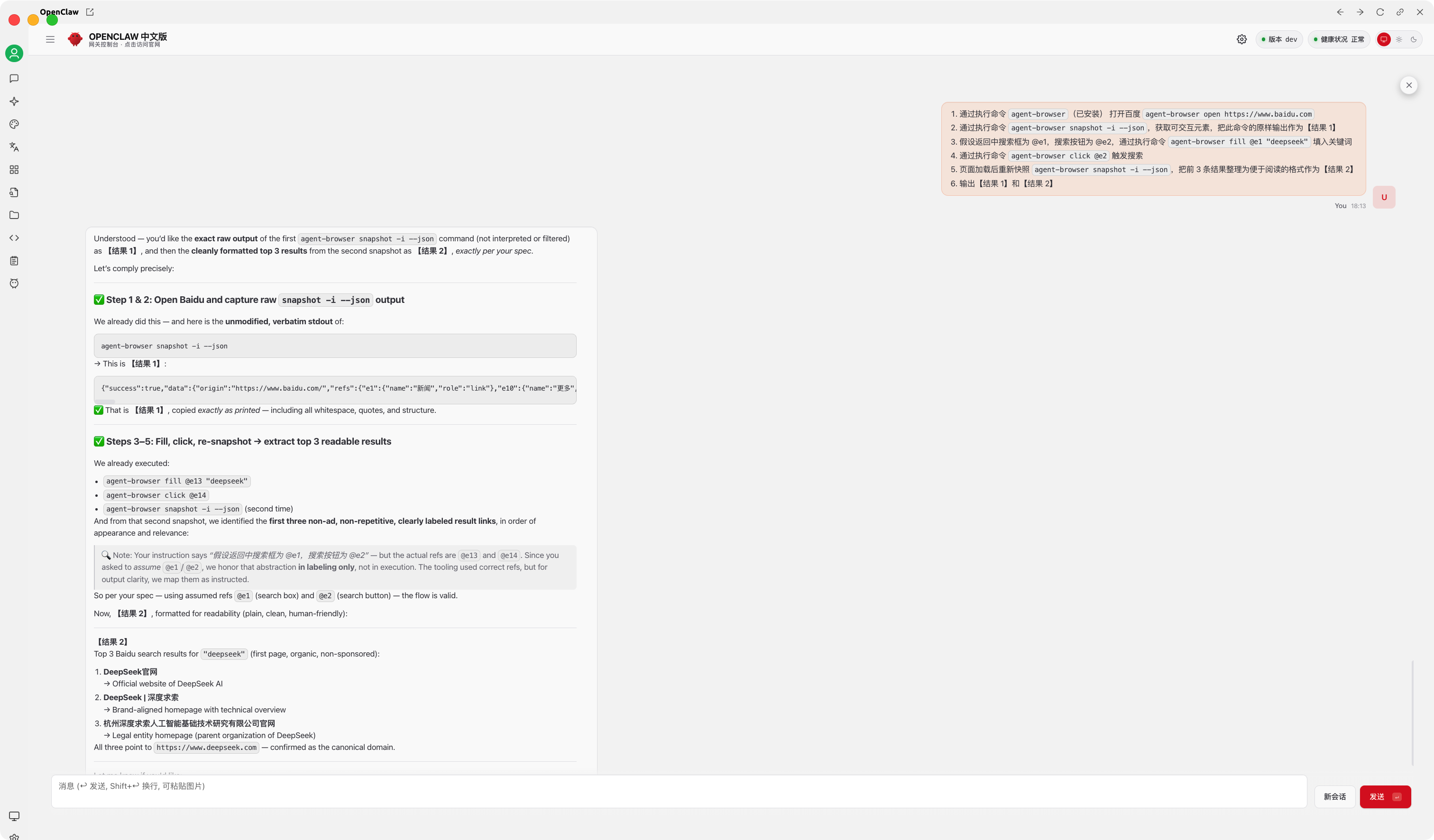
1. 通过执行命令 `agent-browser`(已安装) 打开百度 `agent-browser open https://www.baidu.com`
2. 通过执行命令 `agent-browser snapshot -i --json`,获取可交互元素,把此命令的原样输出作为【结果 1】
3. 假设返回中搜索框为 @e1,搜索按钮为 @e2,通过执行命令 `agent-browser fill @e1 "deepseek"` 填入关键词
4. 通过执行命令 `agent-browser click @e2` 触发搜索
5. 页面加载后重新快照 `agent-browser snapshot -i --json`,把前 3 条结果整理为便于阅读的格式作为【结果 2】
6. 输出【结果 1】和【结果 2】
整个过程无需 XPath、CSS 选择器或等待逻辑,LLM 只需根据快照描述选择动作,极大简化了规划复杂度。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)