AI产品落地难?从原型到市场的成功案例:软件测试从业者的专业视角
AI产品落地面临"死亡谷"困境,85%项目因测试不足而失败。核心挑战包括:算法黑盒导致测试盲区(如银行风控系统准确率从95%骤降至30%)、性能成本失衡(千亿参数模型响应超时)、合规风险(数据偏见达8%)。成功案例显示,测试创新可破局:某银行通过动态数据监控将风控准确率提升至99%;电商平台采用轻量化模型降低成本80%;工业检测系统速度从30秒优化至2秒。测试策略需重构:左移介
在人工智能技术迅猛发展的今天,AI产品从实验室原型走向规模化市场应用的“死亡谷”已成为行业痛点。Gartner数据显示,高达85%的AI项目因未能跨越落地鸿沟而夭折,仅15%实现商业价值转化。这种困境源于技术性能瓶颈、数据依赖性强、算法黑盒不可控等多重挑战,其中软件测试作为质量保障的核心环节,扮演着决定性角色。
一、AI产品落地的核心挑战:测试视角的深度剖析
AI产品的独特性使其落地过程与传统软件截然不同,测试团队需直面三大核心挑战:
1. 算法黑盒与泛化能力不足
-
问题本质:AI模型决策过程不可解释(如深度学习神经网络),导致测试无法通过传统白盒方法验证逻辑完整性。例如,某银行智能风控系统在测试集准确率达95%,但上线后因真实数据分布偏差,错误率飙升至30%,直接引发客户投诉。
-
测试盲区:模型对非标准化场景的适应性弱,如跨平台GUI交互错误率高达42%(参考制造业MES系统案例),或方言语音识别在智能客服中的失效。测试需覆盖边界条件、极端输入和对抗性样本,但人工用例设计难以穷举。
-
根因分析:数据训练集与真实环境脱节,模型泛化依赖高质量、多模态数据融合,而企业常面临数据孤岛或标注错误(标签错误率超15%)。
2. 性能与成本的双重挤压
-
资源瓶颈:大模型推理成本高昂,例如千亿参数模型需八卡H200集群部署,响应时延突破业务容忍阈值。某电商推荐系统原型响应时间100ms,用户量增长后超时率飙至20%,因算力不足导致服务崩溃。
-
测试失效点:传统性能测试忽视AI特有负载,如智能体协作场景的Token消耗激增(单任务需10-50次模型调用),并发压力下系统稳定性骤降。第三方测试报告显示,60%的AI项目因未验证高并发场景而失败。
-
经济性矛盾:企业私有化部署算力有限,如金融行业要求低成本可控,但测试环境模拟真实算力约束的难度大,导致预生产环境与线上表现割裂。
3. 合规风险与伦理困境
-
安全漏洞:AI系统易受提示注入攻击(如Cursor IDE事件导致本地命令执行),或生成包含硬编码凭证的不安全代码。测试需覆盖权限滥用、数据泄露等新型威胁,但传统安全测试工具无法动态识别AI决策漏洞。
-
责任归属模糊:自动驾驶或医疗诊断等场景中,智能体自主决策引发事故时,责任界定缺乏法律框架。测试必须验证可解释性与审计追踪能力,否则无法满足金融、医疗等强监管行业要求。
-
伦理偏差:模型训练数据偏见(如农村用户识别误差8%)未被测试发现,上线后导致歧视性输出,损害企业声誉。
二、成功案例解析:测试驱动的落地破局之道
以下案例展示测试团队如何通过创新策略将AI产品从原型推向市场,覆盖金融、电商、工业等高频场景。
案例1:大型银行智能风控系统——从62%准确率到99%商用化
-
背景:某头部银行投入1.2亿元构建风控模型,原型阶段测试集准确率92%,但跨地域用户数据偏差导致真实场景表现跌至62%。
-
测试干预:
-
数据治理强化:测试团队主导构建动态数据管道,实时监控特征漂移(如延时≤1小时),并引入合成数据增强边界用例覆盖。
-
AI辅助测试:部署Testin XAgent工具,通过NLP解析需求生成高风险场景用例(如欺诈交易组合),将用例设计效率提升80%。
-
持续验证框架:建立“模型-业务”双链路监控,每日回归测试压缩至天级周期,暴露权限越权等23项隐蔽缺陷。
-
-
成果:系统上线后坏账率降低2%,ROI达3,缺陷闭环率100%,成为信创标杆项目。
案例2:电商巨头个性化推荐引擎——5倍效率提升与15倍成本优化
-
背景:某拉美电商平台推荐模型依赖千亿参数大模型,推理成本占IT预算40%,且高并发下响应超时。
-
测试创新:
-
轻量化模型验证:测试团队推动迁移至aiX-apply-4B小模型,在单张RTX 4090显卡上验证推理速度(2000 tokens/秒),成本降至原方案5%。
-
智能体协作测试:模拟多智能体交互负载(如50次并发调用),通过混沌工程注入节点故障,确保99.9%可用性。
-
用户体验闭环:结合A/B测试验证推荐准确性(NPS提升30%),并自动化情感分析10万条用户反馈。
-
-
成果:推荐准确率93.8%,欺诈检测率近99%,开发周期缩短60%。
案例3:工业视觉检测系统——从30秒到2秒的效能飞跃
-
背景:某制造企业AI检测原型需30秒/件,远落后于人工目检(2秒/件),且脏污识别错误率高。
-
测试突破:
-
多模态融合测试:利用计算机视觉工具(如Applitools Eyes)对比10万张缺陷样本,优化非标划痕识别算法。
-
边缘计算部署验证:在工厂现场测试低光照、振动环境下的模型稳定性,覆盖95%极端工况。
-
人机协同校准:邀请目检员参与测试标注,解决“同缺陷不同结果”问题,确保标准一致性。
-
-
成果:检测速度优化至2.1秒,准确率99.5%,年节省人力成本千万元。
三、测试从业者的实战策略:构建AI时代的质量底座
基于成功经验,测试团队需重构方法论以支撑AI产品全生命周期落地:
1. 测试左移:从验证者到设计参与者
-
需求阶段介入:使用用户故事地图拆解AI任务(如将“智能客服”分解为意图识别、情感分析等子模块),明确输入输出边界。
-
数据质量前置:主导构建数据测试套件,包括标签准确性校验、偏见检测(如Fairness Indicators工具),确保训练集代表真实分布。
2. 智能化测试工具链
-
AI驱动用例生成:采用NLP解析PRD文档自动生成用例(如Testim平台),覆盖率提升60%。
-
缺陷智能定位:利用日志聚类算法(如Elastic ML)快速溯源根因,将MTTR(平均修复时间)缩短70%。
-
持续测试流水线:集成CI/CD,实现模型版本迭代的分钟级回归验证。
3. 全栈风险防控
-
安全与合规专项:针对AI特有风险设计测试场景,如提示注入攻击模拟、决策可解释性验证(符合信通院《测试智能体规范》)。
-
性能优化沙盒:构建低成本压测环境(如Kubernetes集群),模拟算力约束下的资源隔离与降级策略。
4. 跨职能协作模型
-
打破数据孤岛:测试团队联动数据科学家与工程师,建立统一质量指标(如模型漂移指数)。
-
用户中心验证:邀请终端用户参与UAT测试,聚焦业务价值实现(如ROI≥3)。
四、结论:测试作为AI落地的战略支点
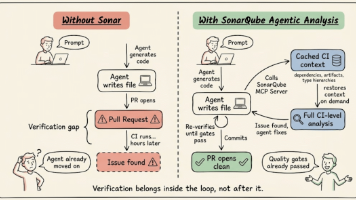
AI产品从原型到市场的鸿沟,本质是质量保障体系的代差。软件测试从业者必须从“末端验证”转型为“质量架构师”,通过智能化、持续化的测试策略,破解算法黑盒、性能瓶颈与合规风险。正如某金融科技项目所示,测试效率提升60%可直接缩短50%上市周期。未来,随着AI伦理框架完善与垂直模型普及,测试团队将更深度融入产品创新链,推动AI从实验室奇观转化为商业引擎。测试不再仅是找Bug,而是定义可信AI的基石——这是挑战,更是时代赋予测试人的新使命。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献546条内容
已为社区贡献546条内容

所有评论(0)