大模型的“推理能力” vs. AgentScope 框架的“推理循环”:你分清楚了吗?
摘要:大模型的“推理能力”指其单次生成中完成逻辑推导的能力,源于预训练和微调;而AgentScope框架的“推理循环”是工程架构,通过多轮交互和工具调用逐步解决问题。前者是模型内在认知能力,后者是外部协调机制。两者协同工作:模型提供单步推理,框架组织多步流程。区别在于模型推理是基础能力,框架循环是应用扩展,共同实现复杂任务处理。(149字)
大模型的“推理能力” vs. AgentScope 框架的“推理循环”:你分清楚了吗?
很多开发者在接触大模型应用框架(如 AgentScope)时,会被一个名字困惑:框架里明明有
_reasoning方法,循环调用模型;而大模型本身也常被说“具备推理能力”。这两个“推理”是一回事吗?如果大模型已经能推理了,为什么框架还要再搞一个循环?
本文将从概念、机制、实例三个维度,帮你彻底厘清这两者的本质区别,以及它们如何协同工作。
一、什么是大模型的“推理能力”?
大模型的“推理能力”,指的是模型在一次生成(单次前向传播) 中,利用其从海量数据中学到的知识,进行逻辑推导、数学计算、因果分析、多步思考并最终给出答案的能力。
这种能力是模型内在的,源于预训练和微调:
- 预训练阶段:模型通过阅读数万亿 tokens 的文本(包含数学题、代码、科学论文、逻辑推理等),习得了“如果…那么…”、“因为…所以…”等推理模式。
- 微调阶段:像 DeepSeek R1、QwQ 等模型,会专门用包含思维链(Chain-of-Thought)的数据进一步训练,让模型学会在输出答案前先展示推理过程(如
<think>标签内的内容)。
你可以在聊天框里直接验证:
用户:一个水池,进水管 3 小时注满,出水管 5 小时排空,同时打开,多久注满?
模型(具备推理能力):
首先,进水管每小时注入 1/3 的水,出水管每小时排出 1/5 的水。
净进水速度 = 1/3 - 1/5 = 2/15(池/小时)。
因此,注满时间 = 1 ÷ (2/15) = 7.5 小时。
模型在一次回答中完成了完整的推理链条。
二、AgentScope 框架中的“推理步骤”是什么?
你贴出的代码是 AgentScope 中一个典型的 ReAct(Reasoning + Acting)循环。这里的 _reasoning 并不是让模型做内在推理,而是框架的一个方法名,它代表“调用模型,并让模型决定下一步要做什么”。
整体流程如下:
_reasoning:将当前上下文(包括历史消息、工具描述)发给模型,模型返回一个结构化的响应,可能包含工具调用(tool_use),也可能直接给出最终答案。_acting:如果模型要求调用工具,框架就执行这些工具(如查天气、计算器、数据库查询),并获取结果。- 循环:将工具结果再次放入上下文,重复步骤 1,直到模型给出最终答案或达到最大迭代次数。
这个循环的核心是“多步交互”,而不是“单步推理”。它让模型可以借助外部工具,逐步解决问题,弥补了模型自身无法获取实时信息或执行精确计算的局限。
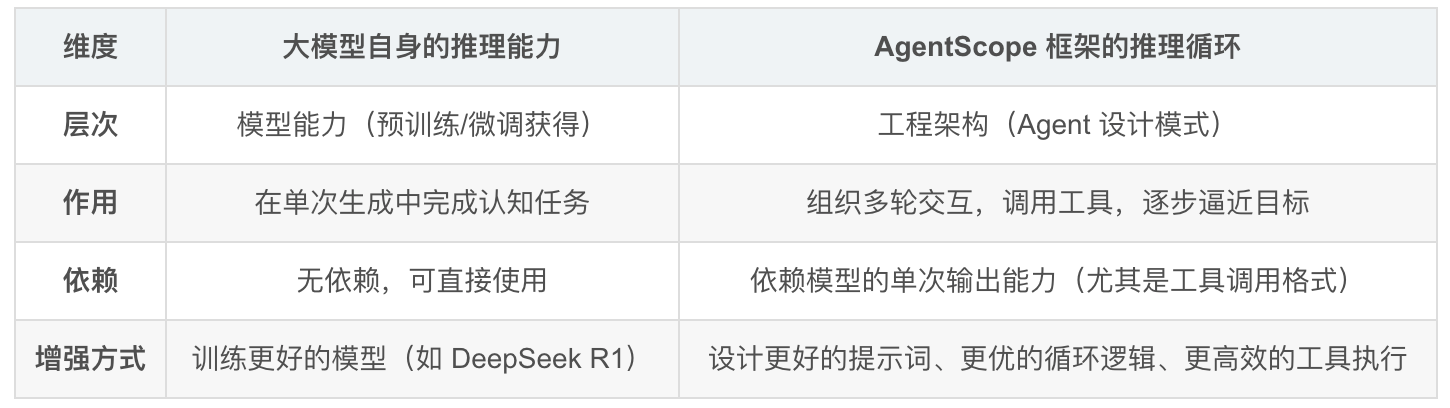
三、两者关系:基础能力 vs. 工程编排
| 维度 | 大模型自身的推理能力 | AgentScope 框架的推理循环 |
|---|---|---|
| 层次 | 模型能力(预训练/微调获得) | 工程架构(Agent 设计模式) |
| 作用 | 在单次生成中完成认知任务 | 组织多轮交互,调用工具,逐步逼近目标 |
| 依赖 | 无依赖,可直接使用 | 依赖模型的单次输出能力(尤其是工具调用格式) |
| 增强方式 | 训练更好的模型(如 DeepSeek R1) | 设计更好的提示词、更优的循环逻辑、更高效的工具执行 |
一个简单的类比:
- 大模型的推理能力 = 一个人的智力水平(能否独立解一道数学题)。
- AgentScope 的推理循环 = 一个人拿着计算器、搜索引擎、笔记本反复推演的过程。
即使一个人智力很高(模型强),拿着工具反复推演也能做得更好;但智力低下的人(模型弱),就算给再多工具也难有质的飞跃。
四、为什么容易混淆?
主要原因有两点:
- 术语复用:框架的方法名
_reasoning容易让人误以为这是模型本身的推理,实际上它只是框架中的一步“思考-行动”调度。 - 功能重叠:当模型具备很强的内在推理能力时,它可能一次调用就给出最终答案,框架的循环可能只走一轮;但当任务复杂时,框架会让模型“分步走”,多次调用模型,每次调用中模型仍然发挥其内在推理能力。
关键在于:无论循环多少次,每一次 _reasoning 调用,模型都在执行一次内在推理。框架的作用是串联这些推理步骤,并插入工具执行。
五、实例对比:直接对话 vs. AgentScope 循环
任务:查询“今天北京天气如何,如果下雨就提醒我带伞,否则提醒我防晒”。
-
直接对话(仅用模型推理):
模型只能基于训练数据猜测,可能给出过时的或错误的信息。因为它无法获取实时天气。 -
AgentScope 循环:
- 第一次
_reasoning:模型输出tool_use: get_weather(Beijing)。 _acting:执行天气 API,返回“北京今天晴,气温 28°C”。- 第二次
_reasoning:模型看到天气结果,推理出“晴天需防晒”,最终输出“今天北京晴天,建议防晒”。
- 第一次
这里,模型的内在推理能力用在两次调用中:第一次决定用什么工具,第二次根据结果得出结论。而框架的循环负责协调这两步以及工具的执行。
六、总结:你理解得没错,只是层次不同
你的理解并没有错误——大模型确实有推理能力,AgentScope 框架也提供了“推理循环”。但它们位于不同的层次:
- 大模型的推理能力是 “大脑” ,是模型在单次生成中完成认知任务的本领。
- AgentScope 的推理循环是 “手脚” ,是一个工程流程,通过多次调用大脑并借助外部工具,解决更复杂、需要实时交互的问题。
在实际开发中,两者缺一不可:
- 选择一个基础推理能力强的模型(如 DeepSeek R1),能让框架每一步的思考更准确。
- 利用框架的循环和工具调用,则能将模型能力延伸到现实世界,完成更复杂的自动化任务。
现在,当你再看到框架里的 _reasoning 方法时,就会明白:它是在调度模型的推理能力,而不是替代它。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)