从被动应答到主动行动:LangChain Agent深度解析与实战构建
本文系统解析了LangChain Agent的架构原理与实现方法。Agent通过"思考-行动-观察"循环模式,将大语言模型(LLM)的推理能力与外部工具执行能力结合,实现复杂任务自主解决。文章对比了Agent与传统AI模型的核心差异,详细介绍了ReAct、Plan-and-Execute、Multi-Agent等主流范式,并提供了完整的代码示例指导开发者构建智能体。同时提出了工
本文深入探讨了LangChain Agent的核心理念和技术架构,阐述了其如何通过"思考-行动-观察"的循环模式,结合大语言模型(LLM)和外部工具,实现复杂任务的自主解决。文章详细解析了Agent与传统AI模型的能力差异,并介绍了ReAct、Plan-and-Execute、Multi-Agent等主流范式,同时以完整的代码示例,手把手指导读者构建自主思考、调用工具的智能体。此外,文章还提供了工具调用优化策略,包括意图分类模型、动态加载工具、统一工具规范、工具过滤Prompt和层次化/多级Agent架构,旨在帮助开发者构建更稳定、高效的Agent系统。
未来的AI不只是回答问题,而是解决问题。本文将带你深入LangChain Agent的核心理念、技术架构,并通过完整的代码示例,手把手教你构建一个能自主思考、调用工具的智能体。
如果说大语言模型(LLM)是知识渊博的“大脑”,那么Agent(智能体)就是为这个大脑装上了“手脚”和“行动力”。传统的AI模型,如ChatGPT,是被动的响应者,你问一句,它答一句。而Agent是主动的行动者,它能理解你的复杂指令,自主规划步骤,调用搜索引擎、计算器、数据库等外部工具,最终完成一个具体的任务,比如“帮我订一张下周去北京的机票,并查一下那边的天气”。
在LangChain 1.0框架中,Agent不再是一个简单的问答机器人,它更像一个“拥有万能工具箱的超级项目经理”,通过“思考-行动-观察”的循环,将复杂任务化繁为简。
本文将从核心概念、技术架构到实战代码,为你揭开LangChain ReAct Agent的神秘面纱。
- Agent 核心概念与能力维度
==================
1.1 什么是 Agent 智能体?
Agent 智能体是以大语言模型(LLM)为“大脑”,能够自主感知环境、进行推理规划,并调用外部工具执行复杂任务的系统。根据 LangChain 框架的定义,Agent 的核心是以 LLM 作为其推理引擎,并依据 LLM 的推理结果来决定如何与外部工具进行交互以及采取何种具体行动。
- LLM(大模型) = 大脑(项目经理):它负责思考、规划、决定下一步做什么,但它不能联网,也不能算复杂的数学(如果不借助工具)。
- Tools(工具) = 手脚(执行专员):比如谷歌搜索(负责看世界)、计算器(负责算数)、数据库(负责查档案)。
- Agent = 大脑 + 手脚 + 循环机制:把大脑和手脚结合起来,通过不断的"思考-行动-观察"循环来解决问题。
这种架构将 LLM 的强大语言理解与生成能力,与外部工具的实际执行能力相结合,突破了单一 LLM 的知识限制和功能边界。Agent 的本质可以被理解为一种高级的提示工程(Prompt Engineering)应用范式。
1.2 Agent vs. 传统 AI 模型:一场能力维度的跃迁

1.3 Agent 的五大核心特征
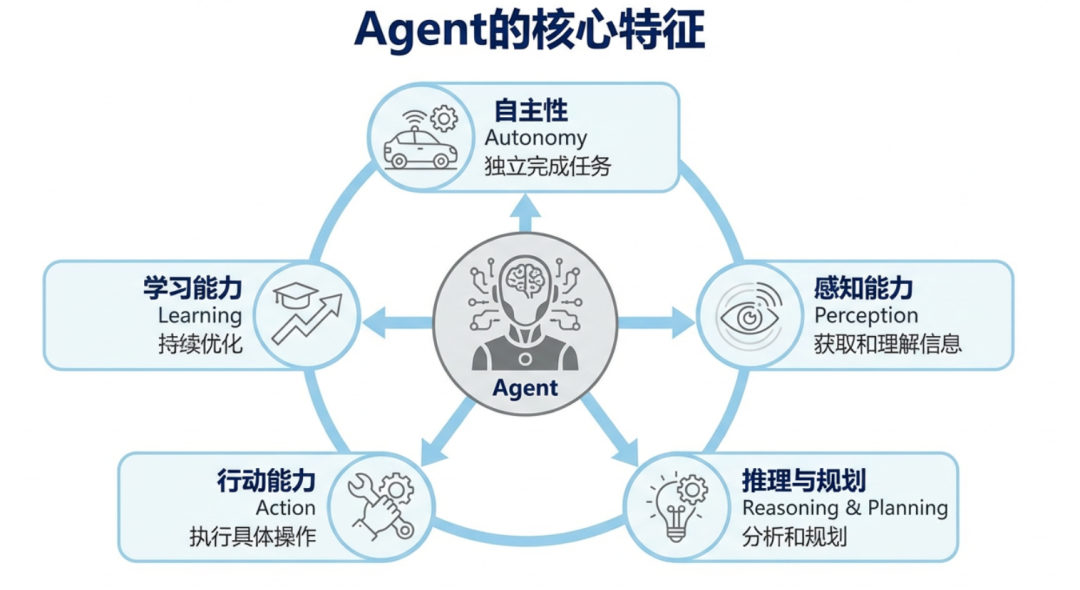
Agent智能体通常具备以下几个核心特征,这些特征共同构成了其强大的能力基础:
-
自主性 (Autonomy): Agent 能够在没有人类直接干预的情况下,独立完成任务的感知、规划、决策和行动。例如,当用户询问“北京的天气怎么样?”时,Agent 能自主识别需要调用天气 API,无需开发者编写显式的条件判断。
-
感知能力 (Perception):Agent 获取和理解环境信息的能力。在基于 LLM 的 Agent 中,环境信息主要以文本形式存在,包括用户输入、工具输出以及系统状态。Agent 通过 LLM 解析这些信息,提取关键指令和上下文。
-
推理与规划 (Reasoning & Planning):Agent 需要分析任务目标,并将其分解为可执行的子步骤。ReAct(Reasoning and Acting)范式要求 LLM 在每一步都生成“思考”过程,解释当前理解和下一步计划,然后生成“行动”。
-
行动能力 (Action):Agent 通过调用外部工具(Tools)来执行具体操作。工具可以是 API 调用、数据库查询、代码执行器,甚至是其他 Agent。这种“思考-行动-观察”的循环,使 Agent 能够与外部世界有效交互。
-
学习能力 (Learning):真正的智能体应该具备从经验中学习并优化自身行为的能力。通过记忆系统(Memory)和反馈机制,Agent 可以持续优化其决策模型。
- Agent 的“思考方式”:ReAct 范式与其他范式
2.1 主流范式:ReAct(Reasoning + Acting)
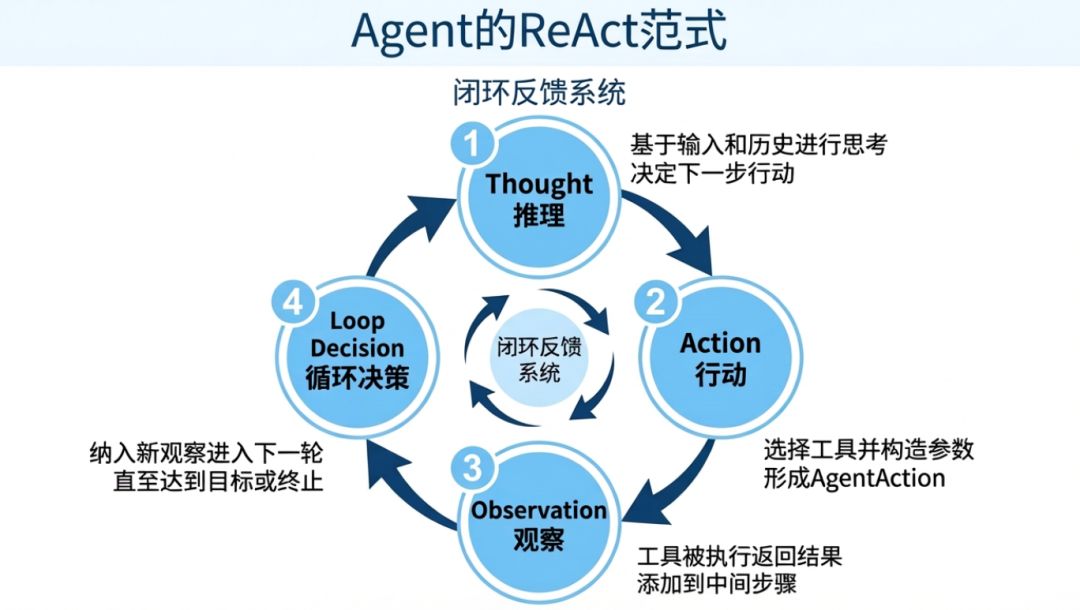
ReAct(Reasoning + Acting)范式强调"推理—行动—观察"的闭环:Agent先形成Thought(推理),据此选择并调用工具(Action),再吸收工具返回的Observation(观察),进入下一轮决策。闭环在达到最终答案、迭代上限或时间上限时终止。在LangGraph中,这一闭环由状态机与检查点驱动,保证每次行动的原子性、状态的可见性与轨迹的可回放性。并且推理与规划不是代码逻辑,而是LLM的生成行为,关键的 Thought: 步骤并非由确定性算法执行,而是prompt触发LLM生成推理文本。模型能力是ReAct性能的天花板。
# ReAct 循环的伪代码表示
def react_loop(task):
while not completed:
thought = llm.think(current_state) # 思考:当前应该做什么
action = llm.decide_action(thought) # 行动:选择并调用工具
observation = execute_tool(action) # 观察:获取工具执行结果
current_state = update_state(observation) # 更新状态
return final_answer
Agent的认知循环本质上是一个闭环反馈系统。每一次"行动"的执行结果都会作为新的输入反馈到系统,影响下一轮的"思考"和"行动"。这种反馈机制使得Agent能够动态调整策略,应对不确定的环境和复杂任务。在LangChain中,这一循环被实现为:
- Thought (推理):大模型基于当前输入和历史记录进行思考,决定下一步行动。
- Action (行动):大模型选择一个工具并构造输入参数,形成一个
AgentAction。 - Observation (观察):工具被执行,其返回结果作为观察值,并与
AgentAction一起被添加到中间步骤(intermediate_steps)中。 - 循环决策:Agent将新的观察结果纳入上下文,进入下一轮"推理-行动"循环,直至达到最终目标或触发终止条件(如达到最大迭代次数)。
2.2 其他范式
2.2.1 Plan-and-Execute(先规划后执行)
适用于步骤明确、依赖关系强的任务:
# Plan-and-Execute 流程
def plan_and_execute(task):
# 第一阶段:制定完整计划
plan = llm.create_plan(task) # ["步骤1", "步骤2", "步骤3"]
# 第二阶段:按顺序执行
results = []
for step in plan:
result = execute_step(step)
results.append(result)
return synthesize_results(results)
优势:避免执行过程中跑偏,适合流程固定的任务。
2.2.2 Multi-Agent(多智能体系统)
由多个 Agent 组成,每个扮演不同角色:
# 多 Agent 协作示例
agents = {
"planner": PlannerAgent(), # 负责制定计划
"executor": ExecutorAgent(), # 负责执行任务
"critic": CriticAgent(), # 负责评估结果
}
def multi_agent_collaboration(task):
plan = agents["planner"].plan(task)
result = agents["executor"].execute(plan)
feedback = agents["critic"].evaluate(result)
if feedback.is_acceptable():
return result
else:
return refine(task, plan, feedback) # 迭代优化
优势:通过角色分工处理极其复杂的任务。
- Agent 的技术架构核心——五模块闭环
现代Agent的技术架构由五个核心模块构成,形成完整的"感知-思考-行动"闭环。
- 感知模块 (Perception):负责接收文本、图像、语音等多模态输入。
- 认知中枢 (Brain/Planning):基于大语言模型(LLM)和检索增强生成(RAG)技术,进行推理和决策,弥补LLM无法获取实时信息和执行具体操作的缺陷。
- 记忆系统 (Memory):通过短期记忆维持对话连贯,长期记忆积累经验与偏好。
- 工具生态 (Tools):通过API调用、数据库访问等方式与外部系统交互。
- 执行引擎 (Action):负责执行具体任务并反馈结果。
class AgentArchitecture:
"""
Agent 的五模块架构
"""
def __init__(self):
self.perception = PerceptionModule() # 感知模块:多模态输入
self.brain = CognitiveModule() # 认知中枢:LLM + RAG
self.memory = MemorySystem() # 记忆系统:短期+长期
self.tools = ToolEcosystem() # 工具生态:API/数据库
self.executor = ExecutionEngine() # 执行引擎:任务执行
def run(self, input_data):
# 环境感知
perceived = self.perception.process(input_data)
# 结合记忆进行规划
context = self.memory.get_context()
plan = self.brain.plan(perceived, context)
# 执行并反馈
for action in plan:
result = self.executor.execute(action, self.tools)
self.memory.update(result) # 学习与优化
self.brain.reflect(result) # 自我反思
return self.brain.synthesize()
这一机制形成了完整的执行闭环:环境感知 → 任务规划 → 工具调用 → 执行反馈 → 自我反思 → 优化调整。
- LangChain 与 Agent 的深度结合
4.1 核心结合点:create_agent + LangGraph
LangChain 1.0 的 create_agent 通过这 9 个核心参数,实现了从快速原型到生产部署的全覆盖,开发者可根据场景灵活组合。
- create_agent 的核心价值在于它通过 “三要素 + 三扩展” 的极简抽象,彻底重构了 Agent 的开发范式。所谓三要素,即模型(Model)、工具(Tools)与提示词(System Prompt),这三者构成了 Agent 的"灵魂"——决定了它能思考什么、能做什么以及行为边界何在。而三扩展——中间件(Middleware)、内存管理(Memory)与状态管理(State)——则构建了 Agent 的"神经系统",使其具备生产级应用所需的可靠性、可观测性与可维护性。
- 这一设计将开发者从繁琐的 ReAct 循环手写、工具调用异常处理、上下文压缩等底层细节中解放出来,转而采用声明式编程模式:只需描述"Agent 应该做什么",框架自动编译为高效、可靠、安全的执行计划。其本质是 LangGraph 的编译器前端 ,将高层意图转换为优化的图结构,自动集成持久化、流式输出、断点恢复等运行时能力。 这种架构带来了三重革命性影响:首先,开发效率提升 10 倍,10 行代码即可构建一个可投产的智能客服或数据分析 Agent;其次,运维成本降低 60%,中间件机制将 PII 检测、人工审批、自动重试等横切关注点解耦,无需侵入业务代码;最后,可扩展性实现质的飞跃,通过 TypedDict 扩展 State,可无缝集成用户画像、多模态输入、性能监控等复杂场景。
4.2 create_agent 核心参数
from langchain.agents import create_agent
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.store.memory import InMemoryStore
agent = create_agent(
# ========== 三要素 ==========
model=model, # 推理引擎(大脑)
tools=[search_tool, calc_tool], # 工具列表(手脚)
system_prompt="你是一个智能助手", # 行为准则
# ========== 三扩展 ==========
middlewares=[log_middleware], # 中间件:日志、安全、限流
checkpointer=InMemorySaver(), # 短期记忆:对话状态
store=InMemoryStore(), # 长期记忆:跨会话知识
# ========== 可选配置 ==========
state_schema=CustomState, # 扩展状态
context_schema=CustomContext, # 动态上下文
response_format=ResponseModel # 结构化输出
)
# 配置执行参数
config = {
"configurable": {"thread_id": "session_123"}, # 会话ID
"recursion_limit": 15 # 最大迭代次数
}
# 执行
result = agent.invoke(
{"messages": [{"role": "user", "content": "帮我查询订单"}]},
config=config
)
- 实战演练——从零构建生产级 Agent
5.1 环境准备与模型加载
本次LangChain版本和Python版本:
langchain 1.0.8
langchain-chroma 1.0.0
langchain-classic 1.0.0
langchain-community 0.4.1
langchain-core 1.0.7
langchain-deepseek 1.0.0
langchain-experimental 0.4.0
langchain-google-genai 3.0.3
langchain-mcp-adapters 0.1.13
langchain-ollama 1.0.0
langchain-openai 1.0.2
langchain-tavily 0.2.13
langchain-text-splitters 1.0.0
#python 版本!python --version
Python 3.11.14
加载大模型:
"""
环境准备:加载环境变量、配置速率限制
"""
import os
from dotenv import load_dotenv
from langchain.chat_models import init_chat_model
from langchain_core.rate_limiters import InMemoryRateLimiter
# 加载环境变量
load_dotenv(override=True)
# 配置速率限制器,防止 API 调用过载
rate_limiter = InMemoryRateLimiter(
requests_per_second=5, # 每秒最多 5 个请求
check_every_n_seconds=1.0 # 每 1 秒检查一次
)
def load_chat_model(model: str, provider: str, temperature: float = 0.7):
"""
统一加载聊天模型
Args:
model: 模型名称,如 "gpt-4o-mini", "deepseek-chat"
provider: 模型供应商,如 "openai", "deepseek"
temperature: 控制随机性,0-1之间
Returns:
初始化好的聊天模型实例
"""
return init_chat_model(
model=model,
model_provider=provider,
temperature=temperature,
rate_limiter=rate_limiter
)
5.2 LangChain中工具Tools
工具是Agent与外部世界交互的桥梁。在LangChain中,工具的name、description和args_schema至关重要,它们共同决定了模型是否以及如何选择和调用工具。一个设计良好的工具描述是提示工程的关键部分。
- 工具注册:通过
@tool装饰器或继承BaseTool类来定义工具。 - 工具调用:Agent在决策时,会根据工具描述选择最合适的工具。执行引擎负责调用该工具并处理其返回结果或异常。
- 安全与治理:在生产环境中,应对工具的调用进行严格的风险控制,如速率限制、权限隔离、输入校验等,这些可以通过中间件或在工具实现中直接加入。
LangChain内置工具列:https://python.langchain.com/docs/integrations/tools/
5.2.1 工具创建
方法一:@tool 装饰器(最简洁)
from langchain_core.tools import tool
from langchain.agents import create_agent
@tool
def multiply(a: int, b: int) -> int:
"""
计算两个数的乘积
Args:
a: 第一个数
b: 第二个数
Returns:
乘积结果
"""
return a * b
# 创建 Agent
model = load_chat_model("gpt-4o-mini", "openai")
agent = create_agent(
model=model,
tools=[multiply],
system_prompt="你是一个数学计算助手"
)
# 调用
response = agent.invoke({
"messages": [{"role": "user", "content": "12乘以6等于多少?"}]
})
print(response["messages"][-1].content) # 输出:12乘以6等于72。
方法二:StructuredTool.from_function()(生产推荐)
这是最常用的方式,通过函数直接创建结构化工具,支持同步和异步双重实现。StructuredTool.from_function()方法提供了更强大的工具创建能力,支持完整的参数校验和异步执行,适合生产环境使用。
技术概述:
- 强类型校验:支持Pydantic模型进行参数验证
- 异步支持:通过
coroutine参数支持异步函数 - 完整元数据:支持name、description、return_direct等完整配置
- 生产就绪:内置错误处理和参数校验机制
核心特性:
- 参数schema完全可控,支持复杂数据结构
- 异步执行支持,适合I/O密集型操作
- 完整的工具元数据配置
- 生产环境级别的错误处理
适用场景:
- 生产环境工具开发
- 需要严格参数校验的场景
- 异步操作需求
- 企业级应用
代码实现:
from pydantic import BaseModel, Field
from langchain_core.tools import StructuredTool
"""
1. 通过 Pydantic BaseModel 定义参数,提供:
- 参数描述(description)
- 必填/可选约束
- 更清晰的 Schema 文档
"""
class DivideInput(BaseModel):
"""除法工具输入参数"""
dividend: float = Field(description="被除数")
divisor: float = Field(description="除数,不能为零")
def divide(dividend: float, divisor: float) -> float:
"""执行除法运算,支持浮点数"""
if divisor == 0:
raise ValueError("除数不能为零")
return dividend / divisor
# 2. 创建带参数校验的工具
division_tool = StructuredTool.from_function(
func=divide,
name="DivisionTool",
description="安全执行除法运算,自动处理除零错误",
args_schema=DivideInput, # 显式指定参数模式
return_direct=False, # 是否直接返回工具结果(不经过 LLM 再次处理)
)
# 3. 测试参数校验(触发 Pydantic 验证)
try:
division_tool.invoke({"a": 10, "b": 2}) # 错误:参数名不匹配
except Exception as e:
print(f"参数校验失败:{e}")
# 4. 正确调用
result = division_tool.invoke({"dividend": 10, "divisor": 2})
print(f"除法结果:{result}")

方法三:继承 StructuredTool(最强大)
通过继承StructuredTool类创建工具提供了最大的灵活性和控制力,适合复杂业务逻辑和状态管理需求。
技术概述:
- 完全自定义:可以完全控制工具的所有行为
- 状态管理:支持工具内部状态维护
- 复杂逻辑:适合实现复杂的业务逻辑
- 企业级特性:支持完整的生命周期管理
核心能力:
- 完整的Pydantic集成和类型系统
- 自定义错误处理和重试机制
- 工具内部状态管理
- 复杂的业务逻辑封装
适用场景:
- 企业级复杂工具开发
- 需要状态管理的工具
- 复杂的业务逻辑封装
- 高性能要求的场景
import os # 导入操作系统模块,用于获取环境变量
from langchain.chat_models import init_chat_model # 导入初始化聊天模型的函数
from langchain.agents import create_agent # 导入创建Agent的函数
from langgraph.checkpoint.memory import InMemorySaver # 导入内存检查点保存器,用于存储对话状态
from pydantic import BaseModel, Field # 导入Pydantic的数据模型和字段定义
from langchain_core.tools import StructuredTool # 导入结构化工具基类
from typing import Type # 导入类型提示中的Type,用于类型注解
# 1. 定义包含业务逻辑的工具
class OrderQueryInput(BaseModel):
"""订单查询参数"""
order_id: str = Field(description="订单编号,格式:ORD-2024-XXXX") # 订单ID字段,必填,带有描述信息
include_details: bool = Field(default=False, description="是否包含商品明细") # 是否包含明细,可选,默认为False
class OrderQueryTool(StructuredTool):
"""订单查询工具"""
name: str = "query_order" # 工具名称,用于Agent识别
description: str = "查询电商平台订单状态和物流信息" # 工具描述,告诉Agent这个工具的用途
args_schema: Type[BaseModel] = OrderQueryInput # 参数模式,定义工具接受的参数格式
return_direct: bool = False # 是否直接返回工具结果(False表示结果会经过LLM处理)
def _run(self, order_id: str, include_details: bool = False) -> dict:
# 执行工具的核心逻辑,order_id为订单号,include_details是否包含明细
# 模拟数据库查询
order_db = {
"ORD-2024-1234": {"status": "已发货", "express": "顺丰", "amount": 299}, # 模拟订单1234的数据
"ORD-2024-5678": {"status": "待付款", "express": "", "amount": 149}, # 模拟订单5678的数据
}
# 处理查询逻辑
if order_id not in order_db: # 如果订单ID不在数据库中
return {"error": f"订单 {order_id} 不存在"} # 返回错误信息
result = order_db[order_id] # 获取订单信息
# 处理包含明细的情况
if include_details: # 如果需要包含商品明细
result["items"] = ["商品A × 2", "商品B × 1"] # 添加商品明细列表
return result # 返回查询结果
# 2. 初始化模型
model = init_chat_model(
model="openai:gpt-4o-mini", # 指定使用OpenAI的gpt-4o-mini模型
temperature=0, # 温度参数设为0,使输出更确定性和一致性
api_key=os.getenv("OPENAI_API_KEY") # 从环境变量获取OpenAI API密钥
)
# 3. 创建 ReAct Agent(自动处理工具调用)
agent = create_agent(
model=model, # 传入初始化好的模型
tools=[OrderQueryTool()], # 直接传入 StructuredTool 实例列表,Agent可以使用这些工具
system_prompt="你是一个电商客服助手,使用工具查询订单信息,回答要友好且准确", # 系统提示词,定义Agent的角色和行为
checkpointer=InMemorySaver() # 使用内存检查点保存器,用于保存对话历史状态
)
# 4. 执行并观察 ReAct 过程
async def run_agent():
# 定义异步函数,执行Agent的对话流程
config = {
"configurable": {"thread_id": "customer_001"}, # 配置线程ID,用于区分不同会话
"recursion_limit": 15 # 最大递归次数限制,防止无限循环,最大15次迭代
}
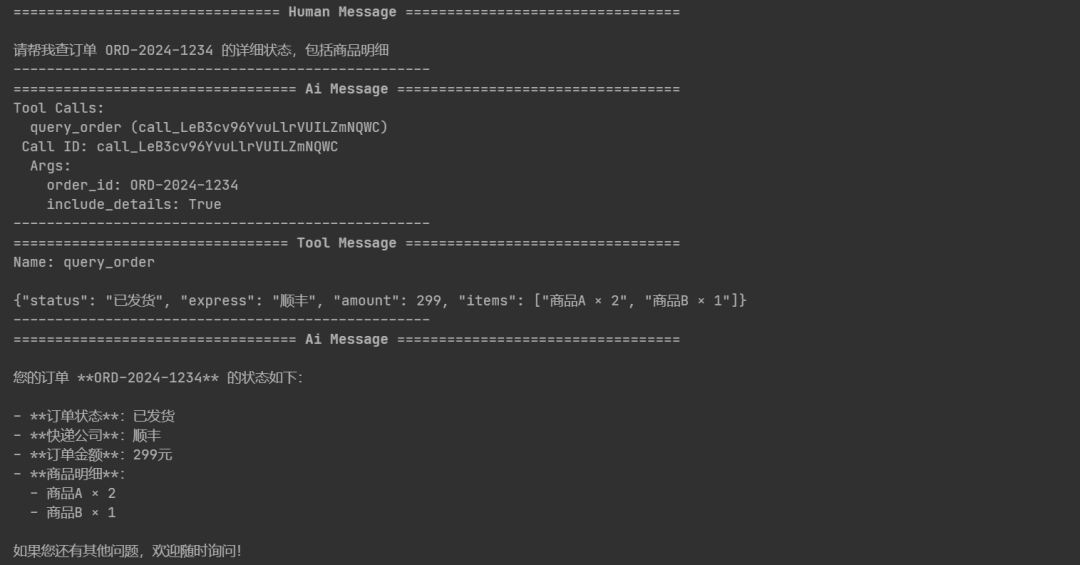
query = "请帮我查订单 ORD-2024-1234 的详细状态,包括商品明细" # 用户查询内容
# 异步流式处理Agent的响应
async for step in agent.astream(
{"messages": [{"role": "user", "content": query}]}, # 输入消息,角色为用户,内容是查询
config=config, # 传入配置
stream_mode="values" # 流式输出模式,返回每一步的完整状态
):
message = step["messages"][-1] # 获取最新的一条消息
message.pretty_print() # 美化打印消息内容
print("-" * 50) # 打印分隔线,便于区分不同步骤
# 运行
if __name__ == "__main__": # 判断是否直接运行此脚本
import asyncio # 导入异步IO模块
asyncio.run(run_agent()) # 运行异步函数run_agent
核心要点总结
- 参数校验:始终使用 args_schema 定义 Pydantic 模型,确保输入合法
- 异步优先:为网络 I/O 操作提供 _arun 实现,提升 Agent 并发性能
- 文档清晰:description 字段是 LLM 选择工具的唯一依据,必须详细描述功能和参数
- 返回值控制:return_direct=True 适合无需 LLM 润色的确定性格式数据
- 调试友好:使用 tool.invoke() 单独测试工具,确保逻辑正确后再集成到 Agent
5.2.3 多工具协同使用
from langchain.agents import create_agent # 导入创建Agent的函数
from langchain_core.tools import tool # 导入tool装饰器,用于快速创建工具
from langchain.chat_models import init_chat_model # 导入初始化聊天模型的函数(根据实际情况调整)
# 定义天气查询工具
@tool # 使用tool装饰器将函数转换为LangChain工具
def get_weather(city: str) -> str:
"""获取指定城市的天气信息。"""
weather_data = { # 模拟天气数据字典
"北京": "晴朗,气温25°C", # 北京的天气
"上海": "多云,气温28°C", # 上海的天气
"广州": "小雨,气温30°C" # 广州的天气
}
# 返回城市天气,如果城市不存在则返回"未知"
return f"{city}的天气是:{weather_data.get(city, '未知')}"
# 定义数学计算工具
@tool # 使用tool装饰器将函数转换为LangChain工具
def calculate(expression: str) -> str:
"""计算一个数学表达式的结果。"""
try:
result = eval(expression) # 使用eval计算数学表达式(注意:生产环境需谨慎使用)
return f"计算结果是:{result}" # 返回计算结果
except Exception as e: # 捕获所有异常
return f"计算出错:{str(e)}" # 返回错误信息
# 1. 初始化LLM
llm = init_chat_model(
model="gpt-4o-mini", # 指定模型名称
provider="openai", # 指定提供商
temperature=0 # 设置温度为0,使输出更确定性
)
# 2. 创建Agent
agent = create_agent(
model=llm, # 传入初始化好的模型
tools=[get_weather, calculate], # 传入工具列表,Agent可以调用这些工具
system_prompt="你是一个多功能的助手,可以查询天气和进行数学计算。" # 系统提示词
)
# 3. 测试多工具调用
user_queries = [
"北京和上海的天气怎么样?", # 第一个测试:查询天气
"如果北京气温是25度,上海是28度,那么北京的温度比上海低多少度?" # 第二个测试:数学计算
]
# 4. 执行测试
for query in user_queries: # 遍历所有测试查询
print(f"用户: {query}") # 打印用户查询
response = agent.invoke({ # 调用Agent处理查询
"messages": [{"role": "user", "content": query}] # 构建消息列表
})
# 打印Agent的最终回复(获取最后一条消息的内容)
print(f"Agent: {response['messages'][-1].content}")
print("-" * 50) # 打印分隔线

查看运行流程:
import getpass # 用于安全地获取密码输入(虽然本示例未直接使用)
import operator # 导入操作符模块(可能用于自定义操作)
from typing import Annotated, List, Union # 导入类型提示相关
import os # 导入操作系统模块,用于环境变量
from langchain_openai import ChatOpenAI # 导入OpenAI聊天模型
from langchain_core.tools import tool # 导入tool装饰器
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage, ToolMessage # 导入消息类型
from langchain.agents import create_agent # 导入创建Agent的函数
# 引入 UI 库
from rich.console import Console # Rich控制台,用于美化输出
from rich.panel import Panel # Rich面板组件
from rich.text import Text # Rich文本组件
from rich.markdown import Markdown # Rich Markdown渲染组件
# 初始化控制台
console = Console() # 创建Rich控制台实例,用于美化打印
# --- 第一步:定义工具 (和以前一样,这是 Core 标准) ---
# 定义天气查询工具
@tool # 使用tool装饰器将函数转换为LangChain工具
def get_weather(city: str) -> str:
"""获取指定城市的天气信息。"""
weather_data = { # 模拟天气数据字典
"北京": "晴朗,气温25°C", # 北京的天气
"上海": "多云,气温28°C", # 上海的天气
"广州": "小雨,气温30°C" # 广州的天气
}
# 返回城市天气,如果城市不存在则返回"未知"
return f"{city}的天气是:{weather_data.get(city, '未知')}"
# 定义数学计算工具
@tool # 使用tool装饰器将函数转换为LangChain工具
def add(a: float, b: float) -> float:
"""计算两个数的和"""
return a + b # 返回两个数的和
# 创建工具列表
tools = [get_weather, add] # 将定义的工具放入列表中
# --- 第二步:初始化模型 (必须绑定工具) ---
# 初始化OpenAI聊天模型
model = ChatOpenAI(
model="gpt-4o", # 指定使用gpt-4o模型
temperature=0, # 温度设为0,使输出更确定性和一致性
api_key=os.getenv("OPENAI_API_KEY") # 从环境变量获取API密钥
)
# --- 第三步:构建图 (使用 prebuilt 的 ReAct Agent) ---
# 在 LangChain 1.0+ 中,这是 AgentExecutor 的官方替代品
# 它自动构建了:State -> Model Node -> Tool Node -> Loop 逻辑
graph = create_agent(model, tools=tools) # 创建ReAct Agent图
# --- 第四步:编写"教学专用"的可视化流式运行器 ---
def run_demo_with_visualization(user_input: str):
"""运行演示并可视化Agent的执行过程"""
print("\n" + "=" * 50) # 打印分隔线
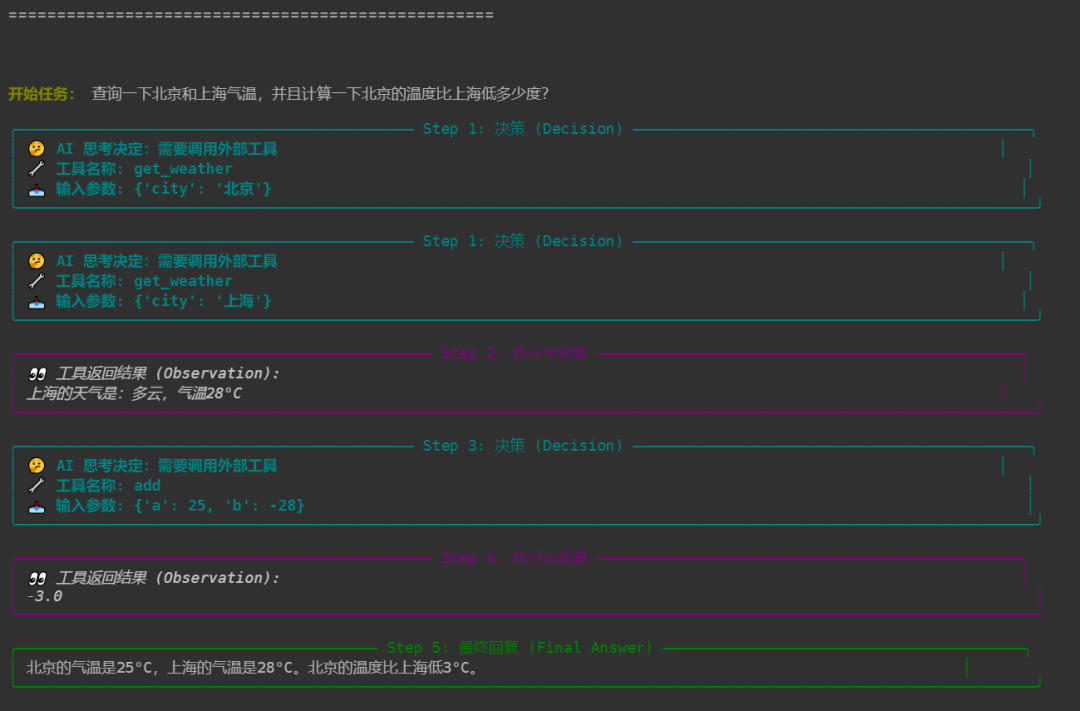
console.print(f"[bold yellow]开始任务:[/bold yellow] {user_input}") # 打印开始任务信息
messages = [HumanMessage(content=user_input)] # 创建用户消息列表
# graph.stream 是 LangGraph 的核心
# 它可以让我们看到状态流转的每一步 (step-by-step)
step_count = 1 # 初始化步骤计数器
# values 模式会返回当前的 message 列表状态
for event in graph.stream({"messages": messages}, stream_mode="values"):
# 获取最新的一条消息
current_message = event["messages"][-1]
# 1. 如果是人类的消息 (初始状态)
if isinstance(current_message, HumanMessage):
continue # 跳过,这是输入消息,不需要显示
# 2. 如果是 AI 的消息 (思考与决策)
if isinstance(current_message, AIMessage):
# 检查是否有工具调用
if current_message.tool_calls:
# 提取工具调用的细节
for tool_call in current_message.tool_calls:
# 使用Rich面板显示AI的决策
console.print(Panel(
Text(f"🤔 AI 思考决定:需要调用外部工具\n"
f"🔧 工具名称: {tool_call['name']}\n"
f"📥 输入参数: {tool_call['args']}", style="bold cyan"),
title=f"Step {step_count}: 决策 (Decision)",
border_style="cyan"
))
else:
# 如果没有工具调用,说明是最终回复
# 使用Rich面板显示最终答案,支持Markdown格式
console.print(Panel(
Markdown(current_message.content), # 使用Markdown渲染回复内容
title=f"Step {step_count}: 最终回复 (Final Answer)",
border_style="green"
))
step_count += 1 # 步骤计数加1
# 3. 如果是工具的消息 (观察与结果)
if isinstance(current_message, ToolMessage):
# 使用Rich面板显示工具执行结果
console.print(Panel(
Text(f"👀 工具返回结果 (Observation):\n{current_message.content}",
style="italic white"),
title=f"Step {step_count}: 执行与观察",
border_style="magenta"
))
step_count += 1 # 步骤计数加1
# --- 第五步:运行演示 ---
if __name__ == "__main__":
# 这是一个多步任务:先查询天气,再计算温差
run_demo_with_visualization("查询一下北京和上海气温,并且计算一下北京的温度比上海低多少度?")
5.2.4 高级集成:MCP(Model Context Protocol)
MCP 是连接 Agent 与外部数据源和工具的开放协议。以下演示同时连接本地 MCP 服务和远程高德地图 MCP 服务。
(1). 本地 MCP 服务器
mcp_server.py中代码如下:
"""
MCP 服务器示例:提供数学运算工具
运行方式:python mcp_server.py
"""
from mcp.server import Server
from mcp.server.models import InitializationOptions
import mcp.server.stdio
import mcp.types as types
import asyncio
# 创建服务器实例
server = Server("math-server")
@server.list_tools()
async def handle_list_tools() -> list[types.Tool]:
"""返回可用工具列表"""
return [
types.Tool(
name="add",
description="Add two numbers",
inputSchema={
"type": "object",
"properties": {
"a": {"type": "number"},
"b": {"type": "number"}
},
"required": ["a", "b"]
}
),
types.Tool(
name="multiply",
description="Multiply two numbers",
inputSchema={
"type": "object",
"properties": {
"a": {"type": "number"},
"b": {"type": "number"}
},
"required": ["a", "b"]
}
),
]
@server.call_tool()
async def handle_call_tool(name: str, arguments: dict) -> list[types.TextContent]:
"""执行工具调用"""
if name == "add":
result = arguments["a"] + arguments["b"]
elif name == "multiply":
result = arguments["a"] * arguments["b"]
else:
raise ValueError(f"Unknown tool: {name}")
return [types.TextContent(type="text", text=str(result))]
async def main():
async with mcp.server.stdio.stdio_server() as (read_stream, write_stream):
await server.run(
read_stream,
write_stream,
InitializationOptions(
server_name="math-server",
server_version="0.1.0"
)
)
if __name__ == "__main__":
asyncio.run(main())
主程序连接 MCP 服务
"""
MCP 客户端:连接多个 MCP 服务器并集成到 Agent
"""
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain.agents import create_agent
from langchain_core.tools import tool
import os
# 1. 配置 MCP 服务器连接
mcp_config = {
# 本地数学服务器
"math": {
"transport": "stdio",
"command": "python",
"args": ["mcp_server.py"]
},
# 高德地图服务器(需要 API Key)
"amap-maps": {
"transport": "stdio",
"command": "npx",
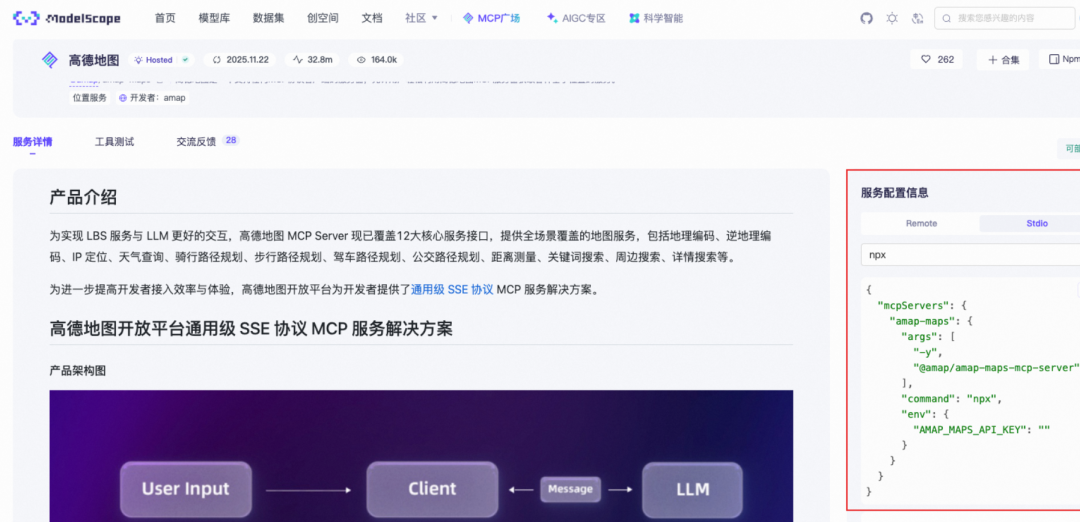
"args": ["-y", "@amap/amap-maps-mcp-server"],
"env": {
"AMAP_MAPS_API_KEY": os.getenv("AMAP_MAPS_API_KEY"),
}
}
}
# 2. 创建 MCP 客户端并加载工具
client = MultiServerMCPClient(mcp_config)
mcp_tools = await client.get_tools()
print(f"成功加载 {len(mcp_tools)} 个 MCP 工具")
# 3. 定义本地工具
@tool
def get_weather(city: str) -> str:
"""获取天气信息"""
weather_data = {"北京": "晴朗,25°C", "上海": "多云,28°C"}
return f"{city}天气:{weather_data.get(city, '未知')}"
# 4. 合并工具并创建 Agent
all_tools = [get_weather] + mcp_tools
llm = load_chat_model("gpt-4o-mini", "openai")
agent = create_agent(
llm,
all_tools,
system_prompt="你是智能助手,可调用天气查询和数学计算工具"
)
# 5. 测试
response = await agent.ainvoke({
"messages": [{"role": "user", "content": "北京天气和上海天气的温差是多少?"}]
})
print(response['messages'][-1].content)
(2). 远程 MCP 服务器
- 魔搭社区高德地图mcp服务器https://www.modelscope.cn/mcp/servers/@amap/amap-maps/tools
- 申请高德地图的api地址:https://console.amap.com/dev/key/app
from langchain_mcp_adapters.client import MultiServerMCPClient # 导入 MCP 客户端,用于连接MCP服务器
from langchain_openai import ChatOpenAI # 导入 OpenAI 聊天模型
from langchain_core.messages import HumanMessage # 导入人类消息类型
from langchain.agents import create_agent # 导入创建Agent的函数
import os # 导入操作系统模块,用于获取环境变量
# 1. 正确的 MCP 配置格式(适用于 langchain_mcp_adapters)
# MultiServerMCPClient 需要的是扁平的字典结构,每个服务器是一个键值对
mcp_config = {
# 本地 Python MCP 服务器(数学计算工具)
"math": { # 服务器名称
"transport": "stdio", # 使用标准输入输出传输方式
"command": "python", # 执行命令:使用Python解释器
"args": ["mcp_server.py"] # 服务器脚本路径(相对于当前目录)
},
# 高德地图 MCP 服务器(地图和天气查询工具)
"amap-maps": { # 服务器名称
"transport": "stdio", # 使用标准输入输出传输方式
"command": "npx", # 使用 npx 运行 npm 包
"args": ["-y", "@amap/amap-maps-mcp-server"], # 运行高德地图 MCP 服务器包
"env": { # 环境变量配置
"AMAP_MAPS_API_KEY": os.getenv("AMAP_MAPS_API_KEY"), # 从环境变量获取高德地图API密钥
}
}
}
# 2. 创建 MCP 客户端
client = MultiServerMCPClient(mcp_config) # 使用配置创建 MCP 客户端实例
print("正在连接 MCP 服务器...") # 打印连接状态信息
# 3. client.get_tools() 会自动:
# 1. 调用所有服务器的 list_tools 接口
# 2. 将 MCP Tool Schema 转换为 LangChain StructuredTool
tools = await client.get_tools() # 异步获取所有 MCP 服务器提供的工具列表
print(f"成功加载 {len(tools)} 个工具: {[t.name for t in tools]}") # 打印加载的工具名称列表
# 4. 创建 Agent
llm = ChatOpenAI(
model="gpt-4o-mini", # 指定使用 gpt-4o-mini 模型
temperature=0, # 温度设为0,使输出更确定性和一致性
api_key=os.getenv("OPENAI_API_KEY") # 从环境变量获取 OpenAI API 密钥
)
# 直接将转换好的 tools 传给 create_agent
agent = create_agent(
llm, # 传入语言模型
tools, # 传入工具列表(来自MCP服务器)
system_prompt="你是会调用工具进行天气查询、地图查询、网页部署的智能助手" # 系统提示词,定义Agent角色
)
# 5. 运行 Agent
print("\n--- 开始测试 Agent ---") # 打印测试开始标记
# 6. 这里我们模拟一个请求(具体 prompt 取决于你的工具功能)
query = "请帮我搜索查询一下北京市今天的天气,并计算一下最大温差是多少度?" # 用户查询内容
# 7. 构建输入消息
inputs = {"messages": [HumanMessage(content=query)]} # 将用户查询包装成消息格式
# 8. 异步流式处理Agent的响应
async for chunk in agent.astream(inputs, stream_mode="values"): # 流式获取Agent的执行步骤
last_msg = chunk["messages"][-1] # 获取最新的一条消息
print(f"\n[{type(last_msg).__name__}]:" ) # 打印消息类型名称
print(last_msg.content) # 打印消息内容
# 如果消息包含工具调用,打印工具调用详情
if hasattr(last_msg, "tool_calls") and last_msg.tool_calls: # 检查是否有工具调用属性且不为空
print(f">>> 调用工具详情: {last_msg.tool_calls}") # 打印工具调用的详细信息
- 解决工具调用优化策略
在实际的Agent应用中,工具调用的准确性和效率直接影响系统的整体表现。本节将从多个维度介绍工具调用的优化策略,帮助构建更稳定、高效的Agent系统。
6.1 意图分类模型(工程最佳方案)
意图分类模型通过机器学习方法识别用户请求的真实意图,从根本上解决工具误用问题。这是一种工程层面的最佳实践,能够在工具调用前先理解用户真正想要做什么。
技术优势:
- 高精度识别:基于大量训练数据的准确意图识别,减少工具误用
- 动态适应:能够适应新的用户表达方式和语言变化
- 多维度分析:综合考虑语义、上下文、用户历史等多维度因素
实现示例:
"""
层次化 Agent 架构:通过意图分类器路由到不同专业 Agent
"""
from langchain.agents import create_agent
from langchain_core.tools import tool
# 定义各领域工具
@tool
def search_web(query: str) -> str:
"""Web 搜索工具"""
return f"搜索结果:{query}"
@tool
def calculate(expr: str) -> str:
"""数学计算工具"""
return str(eval(expr))
# 工具分组
TOOL_GROUPS = {
"search": [search_web],
"math": [calculate],
}
# 意图分类提示词
INTENT_PROMPT = """
你是一个意图分类器,只返回以下类别之一:search, math
用户问题:{query}
"""
def create_intent_classifier():
"""创建意图分类模型"""
return load_chat_model("gpt-4o-mini", "openai", temperature=0)
def classify_intent(query: str) -> str:
"""分类用户意图"""
classifier = create_intent_classifier()
response = classifier.invoke(INTENT_PROMPT.format(query=query))
return response.content.strip()
def router_agent(user_query: str):
"""路由 Agent"""
intent = classify_intent(user_query)
print(f"检测到意图: {intent}")
# 创建专业 Agent
sub_agent = create_agent(
model=load_chat_model("deepseek-chat", "deepseek"),
tools=TOOL_GROUPS.get(intent, []),
system_prompt=f"你是{intent}领域的专业助手"
)
return sub_agent.invoke({
"messages": [{"role": "user", "content": user_query}]
})
# 测试
result = router_agent("搜索一下 AI 最新进展")
print(result['messages'][-1].content)
6.2 动态加载工具(避免上下文过长)
动态工具加载机制根据当前对话上下文和用户意图,按需加载相关工具,避免一次性加载所有工具导致的上下文过长问题。模型根据"意图"动态读取特定工具,不把所有工具一次性喂给模型。
实现策略:
# 工具配置文件分组
# tools/search.yaml - 搜索相关工具
# tools/finance.yaml - 金融计算工具
# tools/pdf.yaml - PDF处理工具
# 通过工具分组管理
TOOL_GROUPS = {
"search": [search_web, search_documents], # 搜索类工具组
"pdf": [extract_pdf_text, parse_pdf_table], # PDF处理工具组
"database": [query_database, update_database], # 数据库操作工具组
"math": [calculate, add, multiply], # 数学计算工具组
"weather": [get_weather, get_forecast] # 天气查询工具组
}
class DynamicToolLoader:
"""动态工具加载器"""
def __init__(self, tool_groups: dict):
self.tool_groups = tool_groups
self.loaded_tools = []
def load_tools_by_intent(self, intent: str) -> list:
"""根据意图动态加载工具"""
tools_to_load = self.tool_groups.get(intent, [])
self.loaded_tools = tools_to_load
print(f"📦 动态加载 {len(tools_to_load)} 个工具: {[t.name for t in tools_to_load]}")
return tools_to_load
def get_current_tools(self) -> list:
"""获取当前已加载的工具"""
return self.loaded_tools
# 使用示例
loader = DynamicToolLoader(TOOL_GROUPS)
intent = classify_intent("查询北京天气")
relevant_tools = loader.load_tools_by_intent(intent) # 只加载天气相关工具
6.3 统一工具规范(提高准确率)
通过强制化Schema和规范化提示词,建立统一的工具使用规范,让模型更容易理解和使用工具。
规范要求:
- 工具名称必须动词开头:如
query_database、calculate_sum、search_web - 每个工具使用标准化Schema:通过Pydantic定义清晰的参数结构
- 工具描述必须包含三件事:能干什么、不能干什么、典型输入示例
实现示例:
from pydantic import BaseModel, Field
from langchain_core.tools import tool
class DatabaseQueryInput(BaseModel):
"""数据库查询参数模型"""
sql: str = Field(
description="SQL查询语句,仅支持SELECT操作,不支持INSERT/UPDATE/DELETE"
)
database: str = Field(
default="main",
description="数据库名称,可选值:main、archive"
)
@tool(args_schema=DatabaseQueryInput)
def query_database(sql: str, database: str = "main") -> str:
"""
执行SQL查询,仅限内部业务数据库。
功能:
- 对内部业务数据库执行SELECT查询
- 返回查询结果集
限制:
- 仅支持SELECT语句
- 不支持INSERT、UPDATE、DELETE等修改操作
- 单次查询最多返回1000行
示例输入:
- SELECT * FROM users WHERE age > 18 LIMIT 10
- SELECT COUNT(*) FROM orders WHERE status = 'pending'
"""
# 安全检查:确保只执行SELECT语句
if not sql.strip().upper().startswith("SELECT"):
return "错误:只支持SELECT查询操作"
# 模拟执行SQL查询
return f"模拟 SQL 执行:{sql},数据库:{database}"
6.4 采用"工具过滤Prompt"修饰模型行为(成本最低)
通过系统Prompt显式指导模型行为,设置工具使用边界。这是成本最低的优化方式,不需要修改代码结构。
Prompt示例:
from langchain.agents import create_agent
# 增强的工具选择提示词
tool_selection_prompt = """
你是一个智能助手,可以使用工具回答问题。请严格遵守以下规则:
1. **工具选择规则**:
- 必须严格根据工具描述选择工具
- 不能猜测工具功能或假设工具存在
- 优先选择功能最匹配的工具
2. **工具使用限制**:
- 如果多个工具都可以完成任务,选择最精确的
- 如果没有合适的工具,不要尝试自己回答,而是说明"无合适工具"
3. **参数传递**:
- 严格按照工具的Schema传递参数
- 不要添加工具定义之外的参数
4. **错误处理**:
- 如果工具调用失败,说明具体原因
- 不要重复尝试明显会失败的工具调用
请记住:宁可说"不知道",也不要给出错误答案。
"""
agent = create_agent(
model=model,
tools=tools,
system_prompt=tool_selection_prompt
)
6.5 层次化/多级Agent架构
通过层次化Agent架构降低单个Agent的工具复杂度,提高系统稳定性。这种架构将复杂任务分解给多个专门的子Agent处理。
架构优势:
- 模块化设计:每个Agent专注于特定领域,职责清晰
- 降低复杂度:单个Agent工具数量可控,避免工具选择混乱
- 提高稳定性:错误隔离和容错能力更强,单个Agent故障不影响整体
实现示例:
from langchain.tools import tool # 导入tool装饰器,用于创建工具
from langchain.agents import create_agent # 导入创建Agent的函数
from langchain.chat_models import init_chat_model # 导入初始化聊天模型的函数
import os # 导入操作系统模块,用于环境变量
from dotenv import load_dotenv # 导入加载环境变量的函数
load_dotenv() # 加载.env文件中的环境变量
# ==================== 1. 定义工具函数 ====================
@tool
def search_web(query: str) -> str:
"""Web 搜索工具,用于查询网络公开信息,不适用于内部数据。参数:query 用户查询,如 OpenAI发布会"""
return f"模拟搜索结果:你搜索了 {query}" # 模拟网络搜索功能
@tool
def extract_pdf_text(path: str) -> str:
"""解析 PDF 文本文件。参数为文件的本地路径。参数:path 文件路径,如 /files/contract.pdf"""
return f"模拟 PDF 内容:从 {path} 中解析出的内容" # 模拟PDF文本提取功能
@tool
def query_database(sql: str) -> str:
"""执行 SQL 查询,仅限内部业务数据库。参数:sql Sql语句,如 select * from users limit 5"""
return f"模拟 SQL 执行:{sql}" # 模拟数据库查询功能
@tool
def calculate(expr: str) -> str:
"""计算数学表达式。适用于算式运算。参数:expr 数学表达式,如 (12+3)*(8-2)"""
return str(eval(expr)) # 使用eval计算数学表达式(注意:生产环境需谨慎使用)
# ==================== 2. 工具分组配置 ====================
TOOL_GROUPS = {
"search": [search_web], # 搜索类工具组
"pdf": [extract_pdf_text], # PDF处理工具组
"database": [query_database], # 数据库操作工具组
"math": [calculate], # 数学计算工具组
}
# ==================== 3. 意图识别模型 ====================
# 创建一个意图识别模型
intent_llm = init_chat_model(
model="gpt-4o-mini", # 指定OpenAI的gpt-4o-mini模型
provider="openai", # 指定模型提供商为openai
temperature=0, # 温度设为0,确保分类结果稳定
api_key=os.getenv("OPENAI_API_KEY") # 从环境变量获取API密钥
)
# ==================== 4. 意图分类 ====================
# 定义意图分类系统提示
INTENT_SYSTEM_PROMPT = """
你是一个专业的意图分类器,请只返回以下类别之一:
- search # 网络搜索类请求
- pdf # PDF文档处理类请求
- database # 数据库查询类请求
- math # 数学计算类请求
- none # 无法分类的请求
并严格只返回类别名,不要输出其它内容。
"""
def classify_intent(user_query: str) -> str:
"""分类用户查询的意图"""
# 调用意图识别模型进行分类
result = intent_llm.invoke(
[
("system", INTENT_SYSTEM_PROMPT), # 系统提示词
("user", user_query) # 用户查询
]
)
return result.content.strip() # 返回分类结果,去除首尾空白
# ==================== 5. 创建专用Agent ====================
def create_agent_for_group(group: str):
"""根据工具组创建对应的专用Agent"""
# 获取对应工具组的工具列表
tools = TOOL_GROUPS.get(group, [])
# 如果没有工具,返回None
if not tools:
return None
# 初始化模型(使用DeepSeek)
model = init_chat_model(
model="deepseek-chat", # 使用DeepSeek模型
provider="deepseek", # 指定提供商
temperature=0, # 温度设为0,确保输出稳定
api_key=os.getenv("DEEPSEEK_API_KEY") # 从环境变量获取DeepSeek API密钥
)
# 创建专用Agent
agent = create_agent(
model=model, # 传入模型
tools=tools, # 传入工具列表
system_prompt="你是一个 helpful assistant,可以使用工具回答问题。"
"你必须严格根据工具描述选择工具!"
"如果没有合适的工具,请回答\"无合适工具\"" # 系统提示词
)
return agent # 返回创建的Agent
# ==================== 6. 路由Agent ====================
def router_agent(user_query: str):
"""主控路由Agent,根据意图分发任务到专用Agent"""
# 1. 识别用户意图
intent = classify_intent(user_query)
print(f"[Router] 检测到意图: {intent}") # 打印意图识别结果
# 2. 根据意图创建对应的子Agent
sub_agent = create_agent_for_group(intent)
# 3. 如果没有合适的Agent,返回提示信息
if sub_agent is None:
return "无法为该问题找到合适的工具或 Agent。"
# 4. 调用子Agent执行任务
result = sub_agent.invoke({
"messages": [{"role": "user", "content": user_query}]
})
return result # 返回处理结果
# ==================== 7. 测试用例 ====================
# 定义测试查询列表
queries = [
"请帮我搜索一下今年Google最新的大模型版本的发布会", # 搜索类测试
"帮我解析一下这个PDF:/root/files/contract.pdf", # PDF处理类测试
"执行一个SQL:select * from products limit 5", # 数据库查询类测试
"计算 (17+3)*(8-1)", # 数学计算类测试
]
# 执行测试
print("=" * 60)
print("开始测试路由Agent")
print("=" * 60)
for q in queries:
print("\n====== 用户问题 ======")
print(q)
print("====== Agent 回复 ======")
# 调用路由Agent处理查询
result = router_agent(q)
# 打印Agent的回复内容
# 注意:result是一个包含messages的字典,需要获取最后一条AI消息的内容
if isinstance(result, dict) and "messages" in result:
# 获取最后一条AI消息
last_message = result["messages"][-1]
print(last_message.content)
else:
print(result)
print("-" * 40) # 打印分隔线
本文从Agent的核心架构出发,基于LangChain 1.x深入剖析了ReAct Agent的实现机制与工具调用的工程化优化方案。从最基础的Prompt约束,到统一的工具规范,再到意图分类模型与多级Agent架构,我们一步步构建了一个既能“听懂”用户意图、又能“精准”调用工具的智能助手。
实践证明,Agent系统的稳定性并不取决于代码的复杂度,而在于架构设计的合理性与优化策略的系统性。当你的Agent开始“乱用工具”时,不妨回头审视:是否明确了工具边界?是否理解了用户意图?是否做到了按需加载?——这些问题解决了,Agent自然就“听话”了。
当然,优化永无止境。随着工具数量的增长、业务场景的复杂化,我们还可以引入更精细的工具优先级排序、上下文动态裁剪、工具调用链路追踪等高级策略。但无论如何,从小处着手、分层优化、持续迭代,始终是构建可靠Agent系统的最佳路径。
AI行业迎来前所未有的爆发式增长:从DeepSeek百万年薪招聘AI研究员,到百度、阿里、腾讯等大厂疯狂布局AI Agent,再到国家政策大力扶持数字经济和AI人才培养,所有信号都在告诉我们:AI的黄金十年,真的来了!
在行业火爆之下,AI人才争夺战也日趋白热化,其就业前景一片蓝海!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

人才缺口巨大
人力资源社会保障部有关报告显示,据测算,当前,****我国人工智能人才缺口超过500万,****供求比例达1∶10。脉脉最新数据也显示:AI新发岗位量较去年初暴增29倍,超1000家AI企业释放7.2万+岗位……
单拿今年的秋招来说,各互联网大厂释放出来的招聘信息中,我们就能感受到AI浪潮,比如百度90%的技术岗都与AI相关!
就业薪资超高
在旺盛的市场需求下,AI岗位不仅招聘量大,薪资待遇更是“一骑绝尘”。企业为抢AI核心人才,薪资给的非常慷慨,过去一年,懂AI的人才普遍涨薪40%+!
脉脉高聘发布的《2025年度人才迁徙报告》显示,在2025年1月-10月的高薪岗位Top20排行中,AI相关岗位占了绝大多数,并且平均薪资月薪都超过6w!
在去年的秋招中,小红书给算法相关岗位的薪资为50k起,字节开出228万元的超高年薪,据《2025年秋季校园招聘白皮书》,AI算法类平均年薪达36.9万,遥遥领先其他行业!

总结来说,当前人工智能岗位需求多,薪资高,前景好。在职场里,选对赛道就能赢在起跑线。抓住AI风口,轻松实现高薪就业!
但现实却是,仍有很多同学不知道如何抓住AI机遇,会遇到很多就业难题,比如:
❌ 技术过时:只会CRUD的开发者,在AI浪潮中沦为“职场裸奔者”;
❌ 薪资停滞:初级岗位内卷到白菜价,传统开发3年经验薪资涨幅不足15%;
❌ 转型无门:想学AI却找不到系统路径,83%自学党中途放弃。
他们的就业难题解决问题的关键在于:不仅要选对赛道,更要跟对老师!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 1
1 0
0- 0



 已为社区贡献708条内容
已为社区贡献708条内容

所有评论(0)