Introduction to Agent Skills (二)
实现了"知识即配置"的理念:通过修改指导文档即可调整系统行为,无需改动底层代码,Skills 层向下为分析器提供标准化工具支持,向上为 Agent 提供可编排的能力单元,确保分析过程的一致性和可维护性。Agent 的主要职责是接收高层任务目标,将其拆解为可执行的子任务,协调下方的 Interview Analyzer 和 Survey Analyzer 两个子分析器并行工作,最后整合各分析器的输出
大部分资料源自Datawhale社区 datawhalechina/agent-skills-with-anthropic 项目教程
全篇如无特殊说明,则默认资料来源上述教程,具体参考链接见文末
本文博客链接指路(排版更美观,可能需要科学上网)
【系列博客】:
Introduction to Agent Skills(一)
Introduction to Agent Skills (二)
Skills with the Claude Agent SDK
目录
Skills vs Tools, MCP, and Subagents
Exploring Pre-Built Skills(探索预设Skills)
案例1 generating-practice-questions(练习题生成)
案例2 analyzing-time-series(分析时间序列)
案例3 analyzing-marketing-campaign
Skills vs Tools, MCP, and Subagents
将讲解如何使用 Skills(技能) 与 Tools(工具)、MCP(模型上下文协议) 和 Subagents(子代理) 结合使用,创建强大的智能工作流。将逐一介绍每个组件,了解它们如何协同工作,以及学习何时使用什么。
智能体生态系统概览
在智能体生态系统中,各种技术如 MCP、Skills、Tools 和 Subagents 共同协作:
-
MCP (Model Context Protocol)服务器:提供所需的上下文
-
Subagents:用于多线程和并行处理
-
Skills:用于可重复的主线程工作流
组件 作用 MCP 外部引入数据 子代理 并行化执行,在独立线程和上下文中运行 Skills 以可预测、可重复、可移植的方式消费所有信息 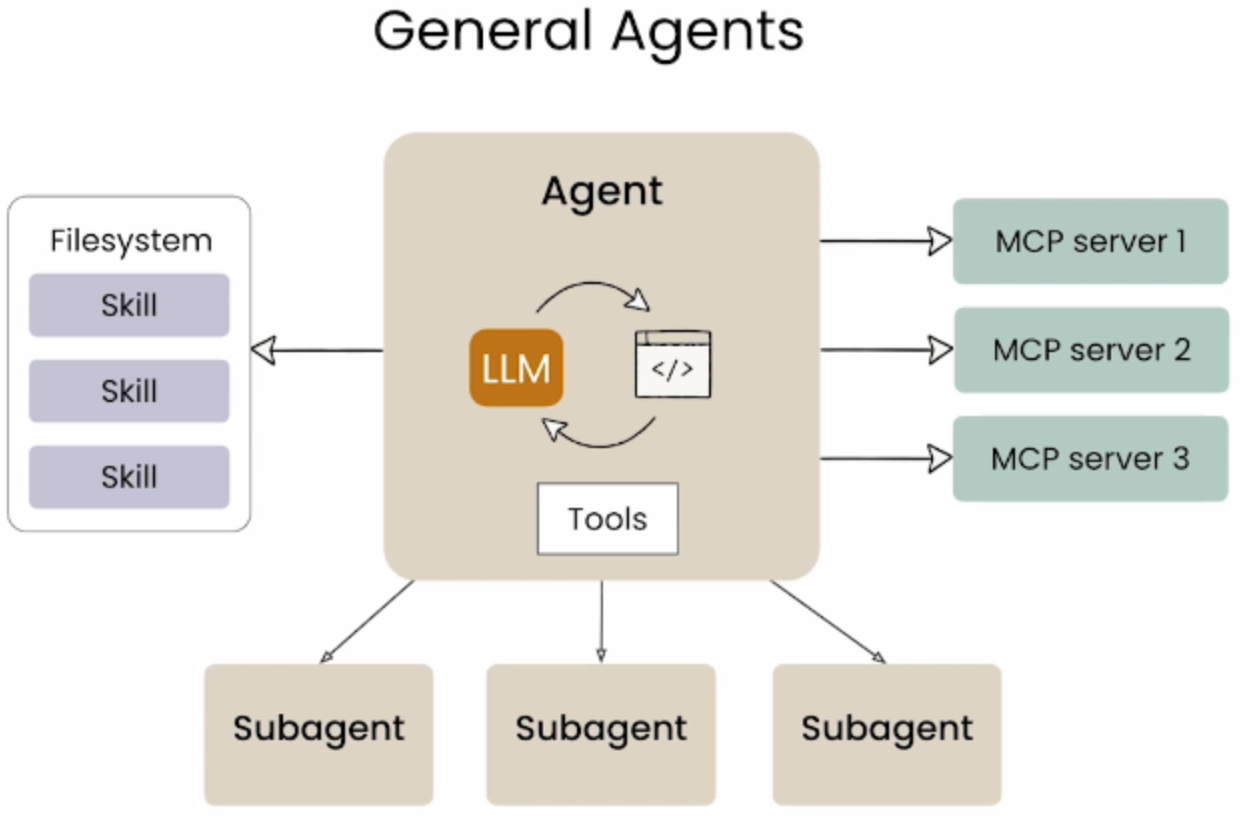
Skills vs Tools
想象你有一些工具:锤子、锯子和钉子。
你有一个技能:如何建造书架。
区别 如下表
| Tools(工具) | Skills(技能) |
|---|---|
| 提供访问文件系统的方式 | 扩展智能体的能力,提供专业知识和指令 |
| 提供底层能力来生成、读取技能 | 引入需要执行的额外文件和脚本 |
| 支持文件编辑、执行代码、加载技能 | 创建可预测的工作流 |
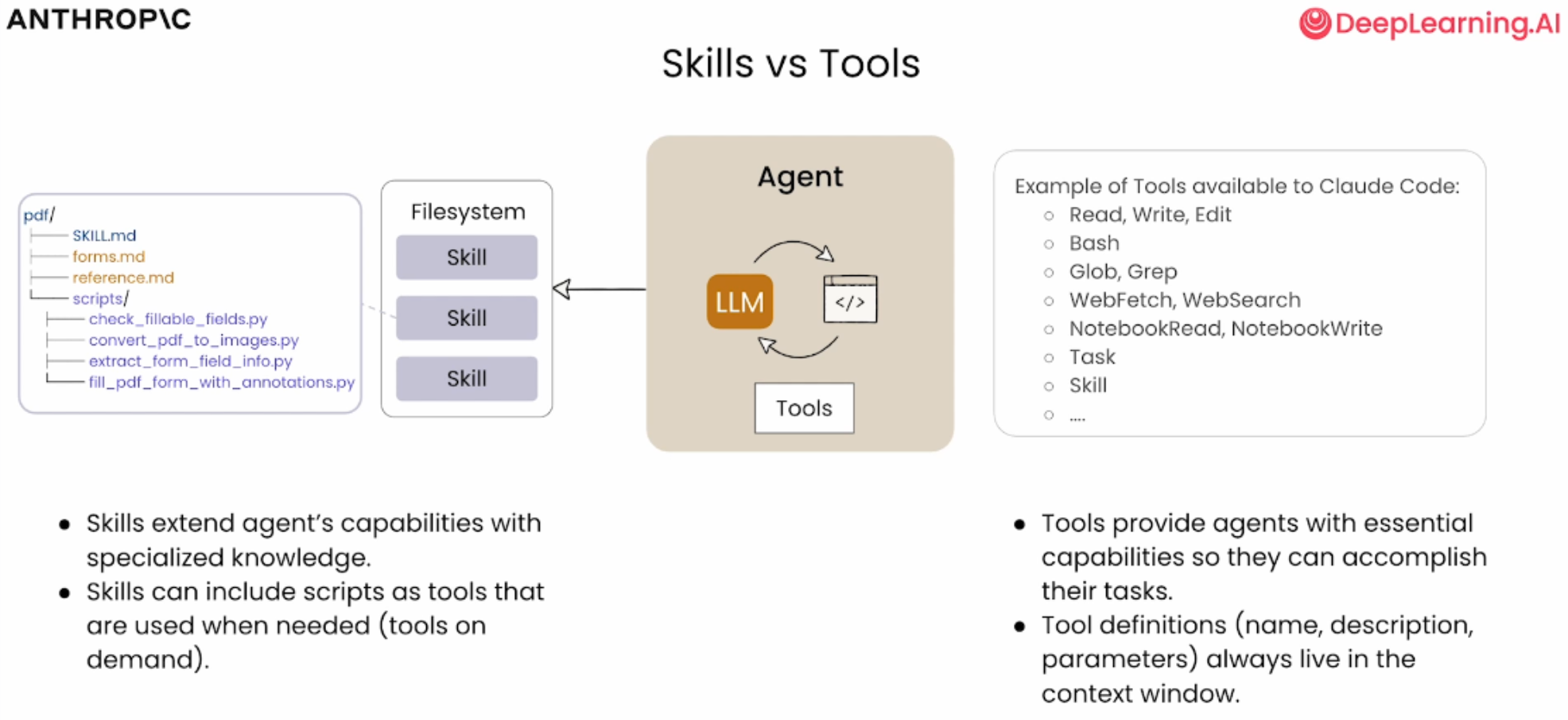
重要特性
- 工具定义(名称、描述、参数)始终存在于上下文窗口中
- 技能是渐进式加载的,只在需要时加载
- 如果某个工具不是每次对话都需要,通过仅在需要时加载可以节省大量 token
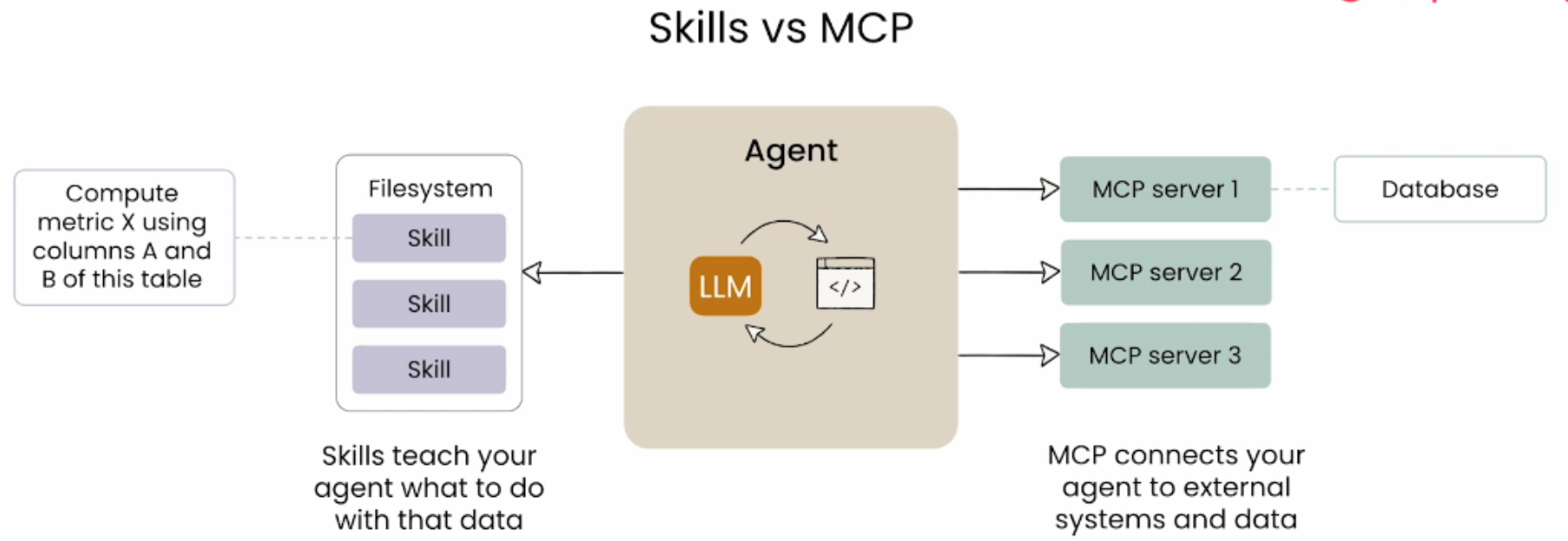
Skills vs MCP
| 对比维度 | MCP | Skills |
|---|---|---|
| 核心功能 | 连接智能体与外部系统和数据 | 定义可重复的工作流 |
| 数据来源 | 外部数据库等 | 利用 MCP 提供的工具和数据 |
| 使用场景 | 获取模型不知道的外部数据 | 教智能体如何处理这些数据 |
- MCP 就像带来所有底层工具和资源的连接器
- Skills 就像使用这些工具构建特定工作流的可重复流程 当利用外部数据计算指标、研究和计算数据时,所有底层工具和资源都可以通过 MCP 服务器外部提供
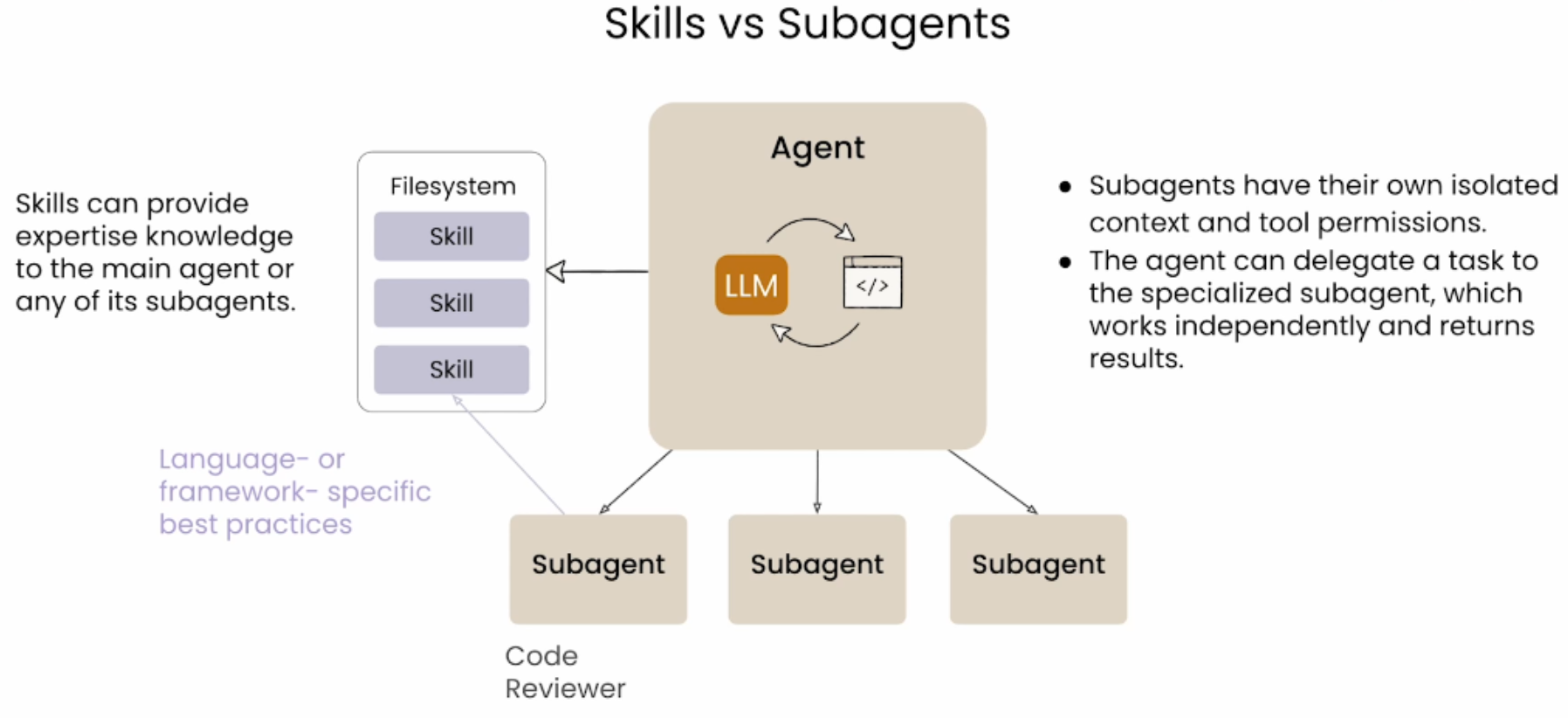
Subagents vs Skills
什么是 Subagent?
Subagent 是为执行单一、明确任务而构建的专用 AI 智能体。它通常在编排器(Orchestrator)的协调下,与其他 Subagent 协作完成复杂任务。
在多智能体系统中,Subagent 通过专业化分工、独立上下文、可定制性以及多种交互模式,提升了开发效率与代码质量。
工作方式 : 主智能体可生成或创建 Subagent,子智能体向父智能体汇报。创建方式包括:
- Claude Code
- Agent SDK
- 自定义实现
| 特性 | 说明 |
|---|---|
| 隔离上下文 | 提供独立的运行环境 |
| 有限权限 | 限制工具的使用范围 |
| 技能访问 | 每个子智能体可调用特定技能 |
应用场景
主智能体作为编排器,按需调用具备相应技能的 Subagent。子智能体也遵循同一理念,专注于特定技能的执行。
例如:可构建一个专门的代码审查 Subagent,其唯一职责是分析代码库,并根据团队或公司的审查规范执行审查任务。
关键术语&性质表格总结
| 组件 | 定义 | 核心特性 | 内容构成 | 加载时机 | 持久性 | 最佳场景 |
|---|---|---|---|---|---|---|
| Prompts | 与模型交互的基础指令单元 | 灵活但不易扩展 | 自然语言 | 每轮对话 | 单次对话 | 快速一次性请求 |
| Skills | 封装程序性知识的可复用模块 | 可预测、可移植、可复用 | 指令+代码+资源 | 按需动态加载 | 跨对话 | 需标准化的专业任务 |
| Subagents | 执行单一任务的专用智能体 | 独立上下文、有限权限 | 完整智能体逻辑 | 被调用时启动 | 跨会话 | 需隔离执行的委派任务 |
| MCP | 外部工具与数据源的标准化接口 | 持续连接、按需调用 | 工具定义 | 始终可用 | 持续连接 | 数据访问与系统集成 |
综合示例:客户洞察分析器
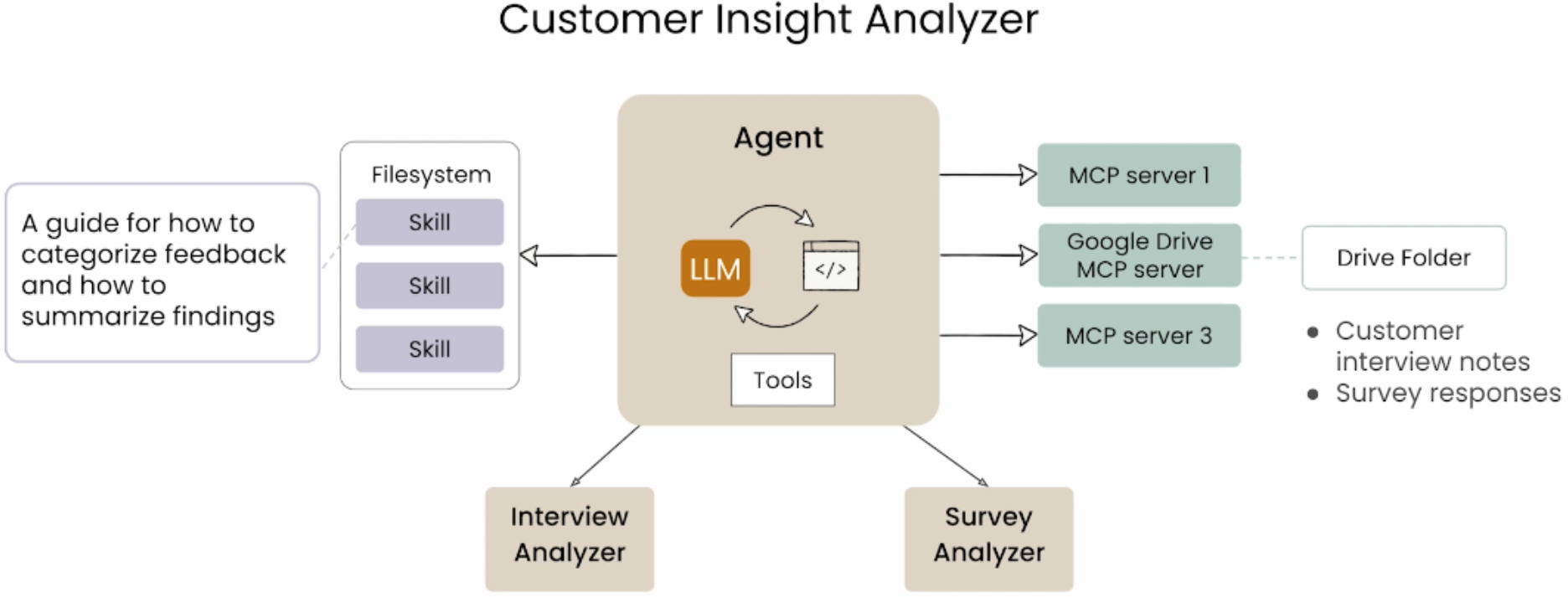
Agent 是整个架构的大脑与指挥中心,LLM 作为推理引擎,能够理解复杂指令、进行多步思考和决策规划;同时配备代码执行环境,支持动态调用工具和执行脚本。Agent 的主要职责是接收高层任务目标,将其拆解为可执行的子任务,协调下方的 Interview Analyzer 和 Survey Analyzer 两个子分析器并行工作,最后整合各分析器的输出结果,生成统一、结构化的客户洞察报告。Agent 还负责管理与多个 MCP 服务器的通信,确保数据流的顺畅传输。
Interview Analyzer & Survey Analyzer 是 Agent 的执行手臂;Interview Analyzer 专注于处理非结构化的客户访谈记录,运用自然语言理解技术提取关键观点、情感倾向和深层需求;Survey Analyzer 则针对结构化的问卷数据进行统计分析、模式识别和趋势归纳。这两个工具相互独立又可并行运行,各自接收 Agent 分配的任务后,调用 Filesystem 中的 Skills 和 LLM 能力进行深度处理,最终将结构化分析结果返回给 Agent 进行汇总。这种分工设计使得系统能够高效处理不同类型的数据源,同时保持模块化的可扩展性。
Filesystem 与 Skills 层构成了系统的能力基础设施;Filesystem 作为技能容器,封装了多个可复用的 Skill 模块,这些 Skill 是经过抽象的业务能力单元。左侧的指导文档("A guide for how to categorize feedback and how to summarize findings")作为元指令(Meta-prompt),定义了系统处理数据的标准方法论——包括分类维度、总结框架和质量标准。实现了"知识即配置"的理念:通过修改指导文档即可调整系统行为,无需改动底层代码,Skills 层向下为分析器提供标准化工具支持,向上为 Agent 提供可编排的能力单元,确保分析过程的一致性和可维护性。
MCP 服务器层是系统的外部连接关键,这一层包含三个 MCP 服务器:通用型的 MCP server 1 和 MCP server 3,以及专门对接云存储的 Google Drive MCP server,Agent 能够以统一的方式调用不同服务商的 API,无需关心底层接口差异;
Exploring Pre-Built Skills(探索预设Skills)
Skill Creator
Skill Creator(技能创建器) 是 Claude Desktop(桌面版 Claude) 中的一个本地能力入口,用于:
- 识别本地 Skills
- 加载本地 Skills
- 在本地 Skill 修改后执行 update(更新)
- 让修改后的 Skill 重新在 Desktop 中可用
路径:
Claude Desktop > Capabilities > Skill Creator
不同版本菜单名称可能略有差异,但核心识别方式是:Capabilities 页面内是否存在 Skill Creator
Skill Creator 的作用不是“写 Skill”,而是解决 本地迭代(local iteration) 问题:
- 把官方 Skill 作为样板复制到本地
- 小范围修改 prompt、参数、数据源、脚本
- 通过 update 重新加载
- 直接在 Desktop 中验证修改效果
因此它是一个 实验入口(experimentation entry point),不是单纯的展示功能。
重点代码路径
skill-creator/scripts/
这一目录的定位 skills/skill-creator/scripts/ 是教程提示的重点路径,本质上是 Skill Creator(技能创建器) 的脚本入口区域,通常承担以下职责:
- 入口脚本(entry script):从哪里开始执行 Skill 的创建 / 更新流程
- 配置解析(configuration parsing):读取 Skill 的描述、参数、依赖、元信息
- 产物生成(artifact generation):将模板、配置、资源整理成可运行的 Skill 产物
- 打包 / 发布(packaging / publishing):把 Skill 变成 Desktop 能识别和加载的形式
本地 Skills 目录结构要求
- 从官方仓库复制 skill 时,必须保持原有目录结构,不能扁平化或重组文件
- Desktop 依据固定目录结构识别 skill,结构变更会导致无法加载
修改与更新机制
| 操作 | 目的 | 预期结果 |
|---|---|---|
修改 prompt 文件 |
调整 skill 的行为逻辑或输出格式 | update 后,skill 按新 prompt 响应 |
修改 skill.json 中的参数 |
变更 skill 的元信息(如名称、描述、参数、依赖、元信息) | update 后,Desktop 显示更新后的信息 |
| 修改数据源或脚本 | 扩展 skill 的功能或接入新数据 | update 后,skill 执行新逻辑 |
| 触发 Skill Creator 的 update | 将本地变更同步到 Desktop 可用的 skill 实例 | 变更生效,可在 Desktop 中测试验证 |
变更生效机制
- 触发 update 是变更生效的必要条件:本地文件修改后,必须通过 Skill Creator 执行 update,Desktop 才能加载到最新版本
- 测试入口固定为 Claude Desktop:所有本地 skill 的验证均在 Desktop 中通过自然语言输入完成
- 输出对比是唯一验证手段:通过对比修改前后的输出差异,确认变更是否符合预期
常见问题
| 阶段 | 常见问题 | 表现 |
|---|---|---|
| 配置解析 | 字段缺失、格式错误、依赖声明错误 | update 失败或报配置错误 |
| 产物生成 | 模板错误、脚本异常、资源缺失 | 中间文件未生成或生成不完整 |
| 打包 / 目录组织 | 目录结构不符合预期 | Desktop 看不到 Skill |
| Desktop 加载 | 缓存旧版本、加载失败 | update 后行为没变化 |
| 测试执行 | Prompt、参数、数据源异常 | Skill 能显示但运行报错 |
排障要点
| 问题现象 | 优先检查项 | 可能原因 |
|---|---|---|
| Desktop 看不到 Skill | 是否开启 Skill Creator;本地目录结构是否正确 | 未开启能力开关;目录层级不符合要求;Skill 未被扫描 |
| update 没生效 | 修改的是否是被真正读取 / 打包的文件 | 改的是草稿文件、未引用文件或非构建输入文件 |
| 运行时报错 | 日志 / 控制台输出;skill-creator/scripts/ 对应阶段 | 配置解析失败、生成失败、打包失败、外部依赖异常 |
Creating Custom Skills
Skills的命名规范
作用:Skills 的 name 是标识符,也是 AI 理解和选择的重要依据。
命名格式:采用 「动词+ing」 格式,如 generating-practice-questions 或 analyzing-time-series。此格式清晰表达动作属性,便于理解、分类和检索。
长度要求:遵循简洁原则,避免过长或复杂的名称,便于记忆、引用和被正确识别。
Skills description
Skills 的 description 是关键的元数据组件,其撰写规范比 name 更严格。
作用:帮助 AI 在复杂任务中正确选择该 Skill。
撰写要点:
- 说明 Skill 做什么、何时使用、如何使用
- 明确包含触发该 Skill 的关键词或短语
- 说明Skill的输入要求、输出格式及特殊使用条件
目标:让使用者无需阅读实现代码,即可理解如何有效使用该 Skill。
| 必填字段 | 约束条件 |
|---|---|
| name | • 最多 64 个字符 |
| • 只能包含小写字母、数字和连字符 • 不能以连字符开头或结尾 | |
| • 必须与父目录name匹配 | |
| • 建议使用动名词形式(动词+-ing) | |
| description | • 最多 1024 个字符 |
| • 不能为空 | |
| • 应描述Skills的功能以及何时使用 | |
| • 应包含帮助agent识别相关任务的具体关键词 |
| 可选字段 | 约束条件 |
|---|---|
| license(许可证) | 许可证名称或对许可证文件的引用 |
| compatibility(兼容性) | 最多 500 个字符,指示环境要求 |
| metadata(元数据) | 任意键值对 |
| allowed-tools(允许的工具) | 预批准工具的空格分隔列表(实验性功能) |
可选目录规范
| 目录 | 内容 | 备注 |
|---|---|---|
| /scripts | 任意语言的代码(小程序或函数库) | 清晰记录依赖项;脚本有清晰文档;错误处理明确且有帮助。需在说明中明确 Claude 是执行该脚本,还是仅作为参考阅读 |
| /references | 附加文档(算法说明、API 文档、格式规范等) | 保持单个参考文件的专注性。超过 100 行的参考文件,在顶部包含目录 |
| /assets | 输出资源(模板、图像、徽标、数据文件、模式定义等) | 用于存放各种输出资产,避免将格式定义硬编码在主文件中 |
实践案例教程
案例1 generating-practice-questions(练习题生成)
功能:根据输入的讲义笔记,自动生成多种类型的教育练习题,包括判断题、选择题、简答题、应用题等。
设计目标:让教师或讲师能够快速创建结构统一、质量标准的测试题库。
核心要素:
- 输入:讲义笔记内容
- 输出:按指定格式生成的多类型练习题
- 规范:在
SKILL.md中定义了详细说明、输入输出格式要求、问题生成规则
设计价值:体现了 Skills 的最佳实践——将重复性工作标准化为可复用的能力模块
案例2 analyzing-time-series(分析时间序列)
功能:自动识别时间序列数据中的模式、趋势和异常。
应用领域:金融、工业监控、医疗诊断等。
设计价值:将复杂的数据分析功能封装为可重用单元,用户只需提供数据文件,即可完成特征提取、模式识别和异常检测,降低技术门槛。
工作流程:分为三步:
- 运行诊断
- 生成可视化图表
- 报告结果
通过 /scripts 文件夹中的 Python 脚本执行每个步骤
案例3 analyzing-marketing-campaign
【教程地址】https://github.com/datawhalechina/agent-skills-with-anthropic
【课程列表链接】https://www.datawhale.cn/activityGroup/16?sourceId=1809
【视频教程地址】 吴恩达 DeepLearning.AI - agent-skills-with-anthropic
【官网解读教程】sc-agent-skills-files

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)