开源项目 superpowers 深度解读:把 AI Coding Agent 变成遵守工程流程的协作伙伴
摘要:superpowers 不是一个普通的 Prompt 仓库,而是一套面向 AI Coding Agent 的工程化工作流系统。本文基于对仓库核心 skills、平台配置文件和工作流设计的系统阅读,梳理它如何通过 brainstorming、planning、TDD、debugging、review、verification 和多代理协作,把 AI 从“会写代码”进一步约束为“按流程做开发”的协作伙伴。
项目地址: https://github.com/obra/superpowers
一、前言:为什么 superpowers 值得专门写一篇解读
最近在看 AI Coding Agent 相关的开源项目时,我注意到了 obra/superpowers 这个仓库。
最初吸引我的,不是它有没有某个炫酷功能,而是它在试图解决一个更本质的问题:当 AI 真正参与软件开发时,我们到底该怎样约束它、组织它、使用它?
很多时候,我们会把 AI 当成一个“更快的程序员”。但真正用久了就会发现,AI 最大的问题往往不是不会写代码,而是缺少稳定的工程纪律。比如:
- 它太容易跳过需求澄清
- 太容易看到问题就直接下手改
- 太容易在没验证的情况下宣称“已经完成”
- 太容易在复杂任务中途跑偏
- 太容易把多步骤工作做成一次性冲动输出
而 superpowers 做的事情,就是把这些原本依赖资深工程师经验把控的研发纪律,拆解成一组可发现、可调用、可组合的 skills,让 AI 不只是“会写代码”,而是“按流程做开发”。
所以在我看来,这个仓库最有价值的地方,并不是它教会模型某个具体技巧,而是它在尝试建立一套面向 AI Coding Agent 的研发工作流。
如果把普通 Prompt Engineering 理解成“怎么让模型更会答题”,那么 superpowers 更像是在做另一件事:
怎么让模型进入一种更接近真实工程团队的工作方式。
这也是我觉得这个项目值得认真读一遍、并且值得专门写成文章的原因。
二、superpowers 到底是什么?
从仓库 README.md 的介绍来看,superpowers 的官方定位非常明确:
Superpowers is a complete software development workflow for your coding agents.
也就是说,它不是单点能力增强,而是一套完整的软件开发工作流。
1. 它服务的对象不是“人”,而是“Coding Agent”
这个仓库面向的是 Claude Code、Cursor、Codex、OpenCode、Gemini CLI 等 AI 编码平台。它不是直接给开发者提供一个按钮或页面,而是给这些“会写代码的 AI 代理”提供一套可调用的技能系统。
从仓库里的配置文件可以看到这一点:
.claude-plugin/plugin.json.cursor-plugin/plugin.jsongemini-extension.json.codex/INSTALL.md.opencode/INSTALL.mdGEMINI.md
这说明作者一开始就不是按单平台来设计,而是按“跨平台 Agent 技能分发系统”来设计的。
2. 它的核心不是代码逻辑,而是技能与规则
这个仓库最重要的目录不是 src/、app/、components/ 之类,而是:
skills/agents/commands/hooks/
其中最关键的是 skills/。
每个 skill 基本都是一个结构化的 Markdown 文件,里面包含:
- 技能名
- 触发条件
- 使用场景
- 核心原则
- 执行流程
- 红线与反模式
- 示例与注意事项
所以从本质上说,superpowers 更像是:
一个把工程最佳实践封装成可发现、可调用、可组合“技能模块”的仓库。
三、项目试图解决什么问题?
如果你经常使用 AI Coding Agent,大概率都见过这些问题:
1. 一上来就写代码
你说“帮我做个功能”,AI 经常直接开始实现,甚至还没搞清楚你的真正需求。
2. 调 bug 时喜欢拍脑袋
看到报错以后,很多模型会直接给出“可能是这里有问题,改一下试试”的建议,但并没有真正定位根因。
3. 跳过测试与验证
不少时候,AI 改完代码就开始说“现在应该可以了”“问题已经修复”,但它并没有真正跑测试,也没有拿到证据。
4. 没有计划意识
稍复杂一点的需求,如果不先拆任务,AI 很容易出现:
- 中途偏题
- 重复修改
- 忘记关键步骤
- 改出额外副作用
5. 多代理协作缺乏纪律
当平台支持子代理、多代理并发时,如果没有流程约束,很容易出现:
- 角色混乱
- 上下文污染
- reviewer 形同虚设
- 任务拆分不清晰
而 superpowers 的思路是:
不要期待模型天然具备稳定的工程纪律,而要把这些纪律写成规则、技能和流程,让它“被迫遵守”。
这正是这个仓库最有意思的地方。
四、仓库结构解读:它是怎么组织起来的?
先看仓库的核心组成。
1. 顶层关键文件
README.md
项目的总说明文件,介绍了:
- 项目定位
- 支持的平台
- 安装方式
- 基础工作流
- skills 列表
- 哲学与贡献方式
package.json
这个文件非常简洁:
{
"name": "superpowers",
"version": "5.0.6",
"type": "module",
"main": ".opencode/plugins/superpowers.js"
}这也从侧面说明:
- 它不是一个典型前端应用或 Node 服务
package.json在这里只承担很轻量的插件入口声明作用- 真正的核心内容不在传统源码目录里,而在 skill 文档与平台配置中
2. 配置与平台适配文件
我重点看了以下几个文件:
.claude-plugin/plugin.json.cursor-plugin/plugin.jsongemini-extension.jsonGEMINI.mdhooks/hooks.json
这些文件分别承担:
- 向 Claude Code 声明插件元信息
- 向 Cursor 声明 skills / agents / commands / hooks 的入口位置
- 向 Gemini CLI 提供上下文文件入口
- 向平台注册会话启动时的初始化动作
举个例子,.cursor-plugin/plugin.json 中明确声明了:
skills:./skills/agents:./agents/commands:./commands/hooks:./hooks/hooks-cursor.json
这意味着:
在 Cursor 这类平台里,superpowers 其实是一组“平台可识别的结构化能力模块”。
3. 核心目录说明
skills/
仓库真正的灵魂所在。
我这次系统阅读了 skills/ 目录下的全部核心 SKILL.md 文件,包括:
using-superpowersbrainstormingwriting-planstest-driven-developmentsystematic-debuggingsubagent-driven-developmentexecuting-plansdispatching-parallel-agentsrequesting-code-reviewreceiving-code-reviewusing-git-worktreesverification-before-completionfinishing-a-development-branchwriting-skills
这些 skill 共同构成了一整套开发工作流。
agents/
这里定义一些专门角色,例如:
agents/code-reviewer.md
它本质上是一个“高级代码审查员”角色说明,用于在某些技能流程里被当作子代理调用。
commands/
这里放的是快捷命令入口,例如:
brainstorm.mdwrite-plan.mdexecute-plan.md
其中有些命令已经被标记为 deprecated,说明作者在逐步把“命令式入口”收敛到“技能式入口”。
hooks/
这里主要是会话启动钩子。比如 hooks/hooks.json 中定义了 SessionStart 时触发的命令。
这意味着 superpowers 并不是只有“手动使用技能”这一个入口,它还在尝试通过 hook 把一些行为前置到会话生命周期里。
docs/
这里包括:
- Codex 适配文档
- OpenCode 适配文档
- 测试文档
- 历史设计与计划文档
这部分对于理解项目如何跨平台运行非常有帮助。
tests/
我阅读了 tests/claude-code/README.md,它说明了项目是如何测试 skills 行为的。
这点很重要,因为它表明作者并没有把技能当成“不可验证的文字说明”,而是在尝试让它们也具备可测试性。
五、这不是“提示词堆砌”,而是一套技能系统
这是我阅读后最强烈的感受之一。
很多人理解 Prompt Engineering,还是停留在“写几段提示词”的层面。但在 superpowers 里,Prompt 已经被进一步工程化了。
1. 每个 skill 都有 frontmatter 元数据
以 SKILL.md 为例,开头通常会写:
---
name: using-superpowers
description: Use when starting any conversation...
---这里的 name 和 description 并不是装饰,它们是平台进行技能发现与匹配的重要依据。
2. skill 的 description 被精心设计成“触发条件”
在 writing-skills/SKILL.md 里,作者反复强调一件事:
- description 只能描述“何时使用”
- 不能把完整流程浓缩写在 description 里
因为一旦 description 直接总结了流程,模型可能只看 description,不认真读取 skill 正文。
这个细节非常值得写进文章,因为它揭示了一个很真实的 Prompt Engineering 问题:
模型会走捷径,因此提示词设计不仅要表达规则,还要防止模型误读规则。
3. skill 是一个“可复用行为模块”
这些 skill 不是普通文档,它们承担的作用更像:
- 一个工程规范
- 一个行为控制器
- 一个流程模板
- 一个角色指令集
所以比起“提示词仓库”,我更愿意把 superpowers 理解成:
AI Coding Agent 的行为操作系统。
六、先给出总览:superpowers 的完整工作流长什么样?
在具体解读各个 skill 之前,先把 superpowers 的主流程放在前面,这样后面的阅读顺序会更清晰。
按照我对 README 和全部核心 skill 的梳理,它的完整工作流大致可以分成下面几个阶段:
会话开始
↓
using-superpowers:先判断该用哪些 skill
↓
需求澄清与设计
↓
brainstorming:理解上下文、提问、比较方案、形成 spec
↓
准备实施
↓
using-git-worktrees:创建隔离工作区,验证基线
↓
writing-plans:把 spec 写成详细实施计划
↓
选择执行方式
↓
subagent-driven-development / executing-plans
↓
实现中的纪律约束
├─ test-driven-development:先测后写
├─ systematic-debugging:遇到问题先查根因
├─ requesting-code-review:完成后请求审查
├─ receiving-code-review:理性处理反馈
├─ dispatching-parallel-agents:独立问题可并行派发
└─ verification-before-completion:没有验证就不能宣称完成
↓
收尾阶段
↓
finishing-a-development-branch:测试、合并、PR、保留或丢弃分支
↓
能力演进
↓
writing-skills:把新的有效方法沉淀成 skill从这个结构里可以看出,superpowers 并不是把 skill 零散堆在一起,而是在试图构建一条完整的、可复用的软件研发流水线。
接下来,我就按照这条工作流来依次解读各个核心 skill。
七、工作流第一步:using-superpowers —— 先决定流程,再开始行动
如果把整套系统比作一个研发流程框架,那么 using-superpowers 就是它的总控开关。
1. 它的任务不是做事,而是决定“该怎么做”
这个 skill 的核心要求非常激进:
- 只要有 1% 的可能某个 skill 适用
- 就必须先检查并调用 skill
- 连澄清问题之前都要先做 skill 判断
也就是说,它不允许模型靠“直觉”直接进入执行状态。
2. 它在压制 AI 最典型的坏习惯:先动手再说
作者在这个 skill 里把很多常见想法都列成 red flags,比如:
- “我先问点问题再说”
- “我先看看代码再决定”
- “这任务太简单,不需要 skill”
这些在人类开发者看来很正常,但在作者眼里,这些往往意味着模型正在绕开流程。
3. 它的真正意义
我觉得 using-superpowers 的价值在于,它不是给 AI 更多选择,而是在收紧 AI 的自由度。
只要系统里存在合适的方法论,就不能靠即兴发挥跳过去。
这正是整套 superpowers 能成立的前提。没有这个总控 skill,后面的其他 skills 很容易沦为“存在但不使用”的摆设。
八、工作流第二步:brainstorming —— 先把需求讲清楚,再进入实现
在 using-superpowers 判断出这是一项需要设计和实现的任务后,最先进入的核心 skill 就是 brainstorming。
1. 它在解决“AI 过早实现”的问题
这个 skill 明确要求:
- 先探索项目上下文
- 一次只问一个问题
- 理解目标、约束和成功标准
- 提供 2~3 个方案与权衡
- 分段给出设计
- 让用户确认后再继续
- 最终输出 spec 文档
也就是说,它不是“边问边写代码”,而是“先设计,再谈实现”。
2. 它特别重视提问方式
我觉得这个 skill 很成熟的一点是,它连“提问姿势”都规范了:
- 一次只问一个问题
- 优先多选题
- 项目过大时先拆子项目
- 视觉问题才使用 visual companion
这说明作者很清楚:
需求澄清不是随便问几个问题,而是一种需要被设计的交互过程。
3. 它的产物不是聊天记录,而是 spec
这点很关键。
很多 AI 对话在需求聊清楚后就结束了,但 brainstorming 要求把结果落地成文档。这样做有两个好处:
- 后面
writing-plans有了稳定输入 - 后面 review 时有了明确参照物
所以这个 skill 更像是从“对话式需求”走向“文档化设计”的桥梁。
九、工作流第三步:using-git-worktrees —— 在隔离环境里启动实施
设计确认后,superpowers 并不是马上开始写代码,而是先进入工作区准备阶段。这一步由 using-git-worktrees 负责。
1. 为什么它会出现在实现之前?
因为作者认为,正式开始实现前,必须先保证:
- 当前工作在隔离分支里进行
- 不会污染主工作目录
- 项目依赖已安装
- 基线测试状态已确认
这其实是一个非常典型的工程化动作,只是很多 AI 工具默认不会主动做。
2. 这个 skill 做了哪些事?
它会引导代理:
- 优先检查
.worktrees/或worktrees/ - 检查是否有项目约定目录
- 必要时询问用户 worktree 放在哪里
- 验证目录是否被
.gitignore忽略 - 创建新 worktree 和分支
- 自动识别项目类型并运行安装命令
- 再跑测试验证干净基线
3. 这个 skill 的价值
我觉得它非常像一个团队里的“开工前检查清单”。
它的重点不在“Git worktree 这个功能新不新”,而在于:
正式实施之前,要先把隔离环境和验证基线搭好。
这会让后续开发、调试和收尾都更清晰。
十、工作流第四步:writing-plans —— 把 spec 写成可执行施工图
完成设计并建立隔离工作区之后,下一步就是 writing-plans。
1. 它是整套系统里最像“项目经理 + 技术负责人”的 skill
这个 skill 不只是让 AI 列个待办清单,而是要求它产出一份极度具体的实施计划,包括:
- 每个任务对应哪些文件
- 哪些文件需要新建、哪些需要修改
- 测试文件在哪
- 每一步的代码长什么样
- 运行什么命令验证
- 预期看到什么结果
- 每个动作要小到 2~5 分钟级别
2. 为什么计划要写得这么细?
因为作者默认执行代理有这些特点:
- 上下文有限
- 容易跑偏
- 不会自动补足隐含前提
- 一旦计划模糊就容易自由发挥
所以 writing-plans 的本质是:
在执行之前,尽可能消灭模糊空间。
3. 它是后续一切执行与 review 的共享契约
没有这份详细计划,后面的:
- 子代理执行
- 规格审查
- 代码质量审查
- 完成验证
都很容易失去统一坐标。
所以在整个工作流里,writing-plans 可以说是“从设计走向实施”的关键枢纽。
十一、工作流第五步:进入执行分支 —— subagent-driven-development 与 executing-plans
到这一步,设计、工作区、实施计划都准备好了,才真正进入“干活阶段”。但 superpowers 并没有只提供一种执行方式,而是提供了两条不同的执行路径。
1. subagent-driven-development:更推荐的主路径
这是整个仓库里最有代表性的 skill 之一。
它的思路是:
- 每个任务派一个新的 implementer 子代理
- 子代理完成后,先做 spec compliance review
- 再做 code quality review
- 如果有问题,就打回给 implementer 修复
- 直到通过后,才进入下一任务
为什么它重要?
因为它体现的不是“AI 更聪明”,而是“AI 更像一个有分工的团队”。
作者特别强调:
- fresh subagent per task
- review 顺序不能乱
- 规格对了,才有资格谈代码质量
这一点让我觉得非常成熟。它已经不是单 agent 编码,而是流程化的多代理协作。
2. executing-plans:没有子代理时的替代路径
如果平台不支持子代理,或者当前就想在本会话里执行,也可以走 executing-plans。
它的要求是:
- 先读计划
- 先做批判性 review
- 再逐个执行任务
- 遇到阻塞就停下来问
- 最后进入
finishing-a-development-branch
也就是说,它虽然没有多代理那种精细流水线,但仍然遵守“先计划、再执行、最后收尾”的主逻辑。
3. 两条路径的差异
我觉得可以这样理解:
subagent-driven-development更像“团队协作模式”executing-plans更像“单人按施工图施工”
前者质量更高、结构更完整;后者更通用,但精度略低。
十二、执行中的刚性纪律一:test-driven-development —— 先写失败测试,再写实现
进入真正实现阶段后,第一个非常关键的纪律 skill 就是 test-driven-development。
1. 这个 skill 的铁律非常明确
它反复强调:
NO PRODUCTION CODE WITHOUT A FAILING TEST FIRST
也就是说,没有先失败的测试,就不允许写生产代码。
2. 它在压制什么?
它在压制的是人类和 AI 共同的一个冲动:
- 先写出来再说
- 等功能跑通了再补测试
- 觉得这个功能“太简单了,不用测”
而这个 skill 的态度非常坚决:
- 如果你先写了实现代码,就删掉重来
- 如果没有亲眼看到测试失败,就不算完成
- 测试通过之前不能宣称完成
3. 它为什么在执行阶段这么重要?
因为真正开始写代码后,模型最容易滑回“先实现再说”的惯性。
所以这个 skill 的存在,本质上是在整个执行过程中不断提醒:
你不是在证明自己会写代码,而是在证明你的代码真的被测试约束住了。
十三、执行中的刚性纪律二:systematic-debugging —— 一旦出问题,先查根因
真实开发不可能一路顺滑,因此在执行阶段,另一个非常关键的 skill 就是 systematic-debugging。
1. 它规定:不能直接修,必须先调查
这个 skill 的核心原则是:
NO FIXES WITHOUT ROOT CAUSE INVESTIGATION FIRST
它要求模型在遇到 bug、测试失败、意外行为时,按四个阶段走:
- 根因调查
- 模式分析
- 假设与验证
- 实施修复
2. 它为什么是执行阶段不可缺的一环?
因为只要开始写代码,就一定会遇到:
- 某个测试失败
- 某个边界条件不对
- 某个环境行为异常
而这时候,如果没有调试纪律,模型最容易做的就是拍脑袋给修复建议。
3. 它和 TDD 其实是互补关系
test-driven-development约束“怎么开始实现”systematic-debugging约束“出问题时怎么处理”
前者防止无测试实现,后者防止无证据修复。
这两个 skill 放在一起,基本构成了 superpowers 在执行阶段的底层纪律框架。
十四、执行中的协作机制:requesting-code-review 与 receiving-code-review
代码写完不代表流程结束,superpowers 还把 review 做成了明确的两步机制。
1. requesting-code-review:主动发起审查
这个 skill 负责的不是“顺便看一眼”,而是结构化地发起 code review。
它要求:
- 明确本次实现了什么
- 明确依据的是哪份计划或需求
- 明确 git diff 的起止范围
- 把这些上下文提供给 reviewer
这说明作者并不把 review 看成一件模糊的事,而是认为:
review 的质量,很大程度取决于 review 输入是否被结构化。
2. receiving-code-review:收到意见后不能表演式认同
这个 skill 我个人非常喜欢,因为它很少见。
它要求模型在收到 review 后:
- 先完整阅读
- 先理解反馈要求
- 再回到代码里验证
- 如果 reviewer 对,就修改
- 如果 reviewer 不对,要做技术性反驳
它甚至明确反对这种表达:
- “你说得对”
- “非常好的建议”
- “我这就改”
原因很简单:
review 不是情绪表演,而是技术判断。
3. 这两个 skill 合起来,构成了完整的 review 闭环
也就是说,superpowers 不只是规范“怎么提审”,还规范“怎么接审”。
这让整个执行流程更像真实工程团队,而不是“AI 自己写、自己夸、自己结束”。
十五、执行中的并行能力:dispatching-parallel-agents —— 独立问题才适合并发处理
并不是所有任务都必须串行执行。
在一些场景下,比如:
- 多个测试文件同时失败
- 多个独立子系统都有问题
- 几个故障域之间互不依赖
superpowers 会建议使用 dispatching-parallel-agents。
1. 它强调的不是“多开几个 agent”,而是“按独立问题域拆分”
这个 skill 最重要的判断标准是:
- 问题是否独立
- 是否存在共享状态
- 是否会互相影响
如果相关,就不要并行;如果独立,就一域一个代理。
2. 这体现了作者对并发边界的清醒认知
很多所谓的多 agent 工作流,只强调“并行更快”。
但 dispatching-parallel-agents 更强调的是:
不是能并发就该并发,而是只有在问题真正独立时,并发才是增益。
这说明 superpowers 并不是把多代理当噱头,而是把它当工程上的调度策略。
十六、执行中的最后一道门:verification-before-completion —— 没有验证证据,就不能说完成
在我看来,verification-before-completion 是整个仓库价值观最鲜明的一个 skill。
1. 它只强调一件事:证据先于结论
这个 skill 的铁律是:
NO COMPLETION CLAIMS WITHOUT FRESH VERIFICATION EVIDENCE
翻译过来就是:
如果你没有在当前这条消息对应的上下文里跑过验证命令,就不能说“完成了”“修好了”“通过了”。
2. 它在修正 AI 最常见的“自信型错误”
比如这些话:
- “现在应该可以了”
- “这个问题已经修复”
- “测试应该都过了”
在人类看来这可能只是口头语,但在工程语境里,这类表达其实会直接伤害信任。
所以这个 skill 明确要求:
- 先识别需要什么命令证明
- 运行完整命令
- 查看输出和退出码
- 再据此表达状态
3. 它其实是在给 AI 建立“完成声明的准入门槛”
这一点非常重要。
因为很多时候,不是 AI 不会干活,而是它太容易在没证据时做出“完成姿态”。
而 verification-before-completion 的作用,就是让“完成”这句话必须有证据托底。
十七、工作流最后一步:finishing-a-development-branch —— 正式收尾,而不是一句“搞定了”
当实现、调试、review、验证都走完之后,才轮到 finishing-a-development-branch。
1. 它把收尾动作流程化了
这个 skill 要求先做一件事:
- 再跑一次测试确认当前状态真的通过
然后再给用户四种明确选项:
- 本地合并回基础分支
- 推送并创建 Pull Request
- 保留当前分支,稍后处理
- 丢弃这次工作
2. 为什么这个 skill 很重要?
因为很多 AI 工具在最后一步往往只有一句话:
- “已经完成”
- “代码写好了”
- “你可以提交了”
但真实开发里,完成实现不等于完成研发流程。
你还得决定:
- 怎么集成
- 是否开 PR
- 是否保留现场
- 是否清理 worktree
而 finishing-a-development-branch 正是在把这些真实研发动作显式化。
3. 这一步说明 superpowers 真正在模拟团队开发闭环
它不是把“写完代码”当终点,而是把“完成一次标准研发交付动作”当终点。
这是我觉得这个项目很有意思的地方之一。
十八、工作流之外的能力沉淀:writing-skills —— 把有效经验反过来沉淀成新的 skill
前面的所有 skill,解决的是“如何使用 superpowers 做开发”。而 writing-skills 解决的问题更偏向元层:
如果我们发现一种新的有效方法,应该怎样把它写成新的 skill?
1. 它把“写 skill”本身也做成了流程
这个 skill 明确提出:
- 写 skill 也应该遵守类似 TDD 的方式
- 先设计压力场景
- 看看没有这个 skill 时模型会怎么失败
- 再写 skill 去修复这些失败模式
- 最后再验证 skill 是否真的起作用
2. 它非常看重可搜索性与可维护性
例如:
description只描述何时使用- skill 名称要可检索
- 要覆盖用户可能搜索的关键词和症状
- 要控制 token 长度
- 要避免让 description 取代 skill 正文
3. 这说明作者把 Prompt / Skill 当成“软件资产”而不是“一次性文本”
我觉得这是这个仓库特别值得学习的一点。
因为它意味着:
- skill 需要测试
- skill 需要维护
- skill 需要性能优化(token)
- skill 需要检索优化
这已经非常接近软件工程思维了。
十九、使用演示:如果我真的用 superpowers 做一个功能,它会怎么跑?
这一节作为“使用演示模块”,方便后续插截图。你完全可以在这里补上 Claude Code、Cursor 或其他平台中的真实对话截图、计划截图、执行截图。
1.在ClaudeCode中安装superpowers插件

/plugin marketplace add obra/superpowers-marketplace注册插件市场

/plugin install superpowers@superpowers-marketplace从此市场安装插件

https://github.com/obra/superpowers
我已经安装好该插件了,请你向我介绍如何使用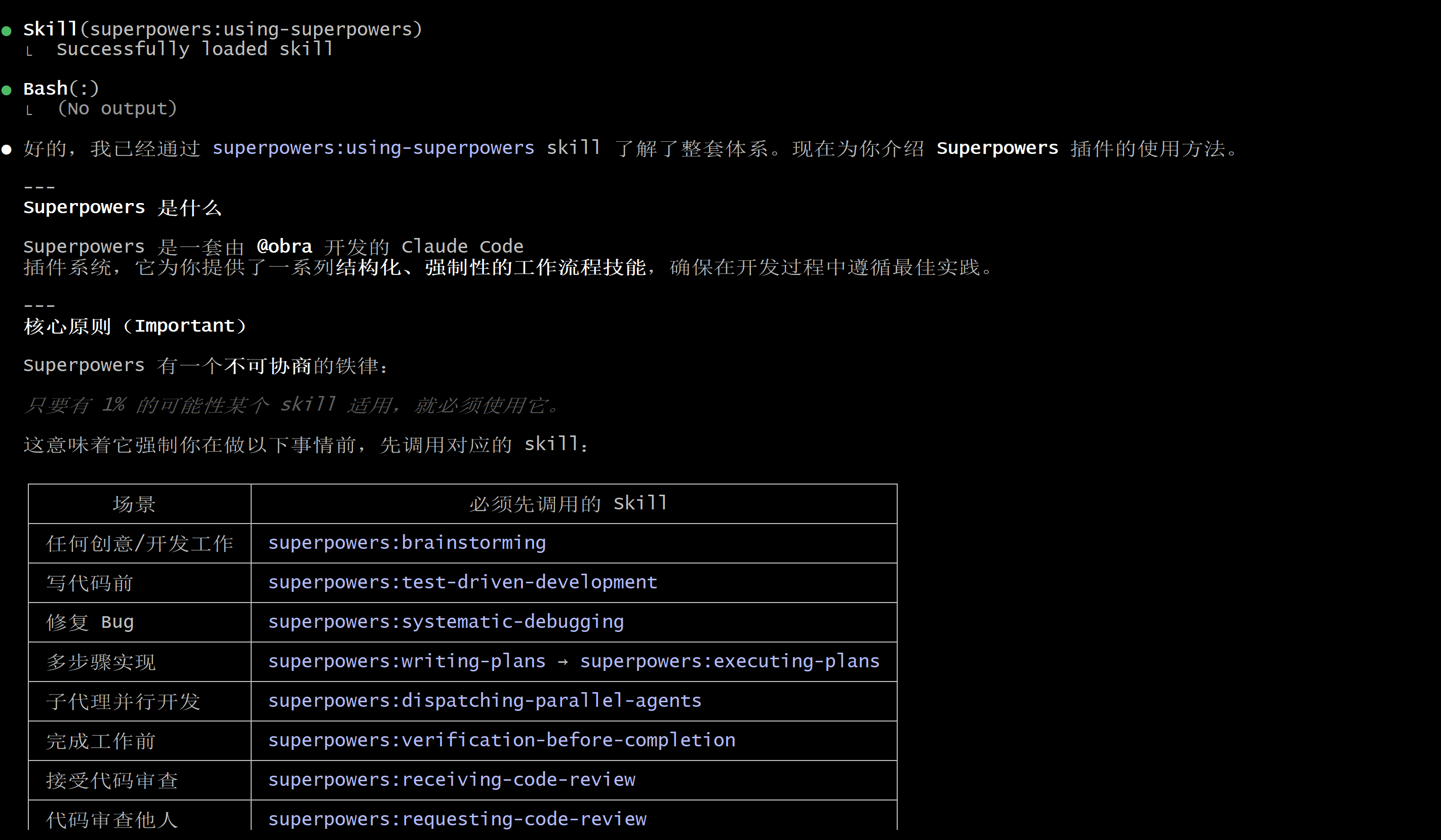
查看该插件功能
● Skill(superpowers:using-superpowers)
⎿ Successfully loaded skill
● Bash(:)
⎿ (No output)
● 好的,我已经通过 superpowers:using-superpowers skill 了解了整套体系。现在为你介绍 Superpowers 插件的使用方法。
--- Superpowers 是什么
Superpowers 是一套由 @obra 开发的 Claude Code
插件系统,它为你提供了一系列结构化、强制性的工作流程技能,确保在开发过程中遵循最佳实践。
---
核心原则(Important)
Superpowers 有一个不可协商的铁律:
只要有 1% 的可能性某个 skill 适用,就必须使用它。
这意味着它强制你在做以下事情前,先调用对应的 skill:
┌───────────────────┬─────────────────────────────────────────────────────────┐
│ 场景 │ 必须先调用的 Skill │
├───────────────────┼─────────────────────────────────────────────────────────┤
│ 任何创意/开发工作 │ superpowers:brainstorming │
├───────────────────┼─────────────────────────────────────────────────────────┤
│ 写代码前 │ superpowers:test-driven-development │
├───────────────────┼─────────────────────────────────────────────────────────┤
│ 修复 Bug │ superpowers:systematic-debugging │
├───────────────────┼─────────────────────────────────────────────────────────┤
│ 多步骤实现 │ superpowers:writing-plans → superpowers:executing-plans │
├───────────────────┼─────────────────────────────────────────────────────────┤
│ 子代理并行开发 │ superpowers:dispatching-parallel-agents │
├───────────────────┼─────────────────────────────────────────────────────────┤
│ 完成工作前 │ superpowers:verification-before-completion │
├───────────────────┼─────────────────────────────────────────────────────────┤
│ 接受代码审查 │ superpowers:receiving-code-review │
├───────────────────┼─────────────────────────────────────────────────────────┤
│ 代码审查他人 │ superpowers:requesting-code-review │
├───────────────────┼─────────────────────────────────────────────────────────┤
│ 创建/修改 skill │ superpowers:writing-skills │
├───────────────────┼─────────────────────────────────────────────────────────┤
│ Git Worktrees │ superpowers:using-git-worktrees │
└───────────────────┴─────────────────────────────────────────────────────────┘
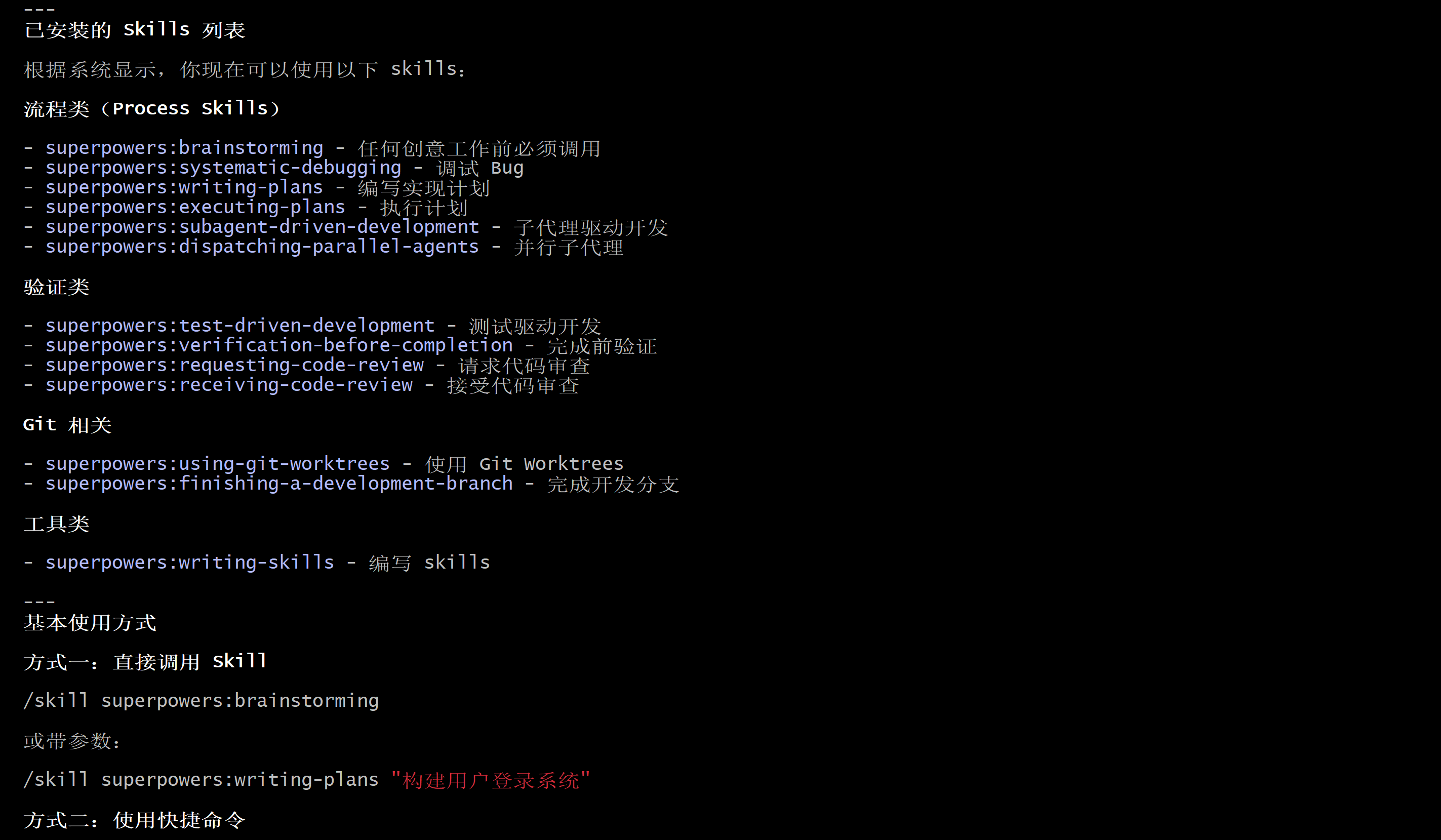
---
已安装的 Skills 列表
根据系统显示,你现在可以使用以下 skills:
流程类(Process Skills)
- superpowers:brainstorming - 任何创意工作前必须调用
- superpowers:systematic-debugging - 调试 Bug
- superpowers:writing-plans - 编写实现计划
- superpowers:executing-plans - 执行计划
- superpowers:subagent-driven-development - 子代理驱动开发
- superpowers:dispatching-parallel-agents - 并行子代理
验证类
- superpowers:test-driven-development - 测试驱动开发
- superpowers:verification-before-completion - 完成前验证
- superpowers:requesting-code-review - 请求代码审查
- superpowers:receiving-code-review - 接受代码审查
Git 相关
- superpowers:using-git-worktrees - 使用 Git Worktrees
- superpowers:finishing-a-development-branch - 完成开发分支
工具类
- superpowers:writing-skills - 编写 skills
---
基本使用方式
方式一:直接调用 Skill
/skill superpowers:brainstorming
或带参数:
/skill superpowers:writing-plans "构建用户登录系统"
方式二:使用快捷命令
Superpowers 提供了一系列快捷命令:
┌─────────────┬────────────────────┐
│ 命令 │ 作用 │
├─────────────┼────────────────────┤
│ /brainstorm │ 启动头脑风暴 │
├─────────────┼────────────────────┤
│ /plan │ 创建实现计划 │
├─────────────┼────────────────────┤
│ /execute │ 执行计划 │
├─────────────┼────────────────────┤
│ /tdd │ 测试驱动开发 │
├─────────────┼────────────────────┤
│ /debug │ 系统调试 │
├─────────────┼────────────────────┤
│ /review │ 请求代码审查 │
├─────────────┼────────────────────┤
│ /verify │ 完成前验证 │
├─────────────┼────────────────────┤
│ /worktree │ 使用 Git Worktrees │
└─────────────┴────────────────────┘
---
使用流程示例
场景:我要开发一个新功能
Step 1: 头脑风暴
/skill superpowers:brainstorming
→ 它会引导你探索需求、明确意图
Step 2: 制定计划(如果需要多步骤)
/skill superpowers:writing-plans
→ 它会帮你创建详细的实现计划
Step 3: 执行计划
/skill superpowers:executing-plans
→ 它会按步骤执行,并设置检查点
Step 4: 完成前验证
/skill superpowers:verification-before-completion
→ 确保所有测试通过、代码质量达标
Step 5: 代码审查
/skill superpowers:requesting-code-review
---
关键约束
1. 技能优先:做任何事之前,先检查是否有对应的 skill
2. 顺序执行:多个 skill 冲突时,先执行流程 skills,再执行实现 skills
3. 禁止绕过:不能"随便先看一下"再调用 skill,必须先调用
4. 用户指令最高:如果 CLAUDE.md 和 skill 冲突,听用户的
---
你现在可以做什么
试试运行:
/skill superpowers:using-superpowers --help
或者查看更多 skill 的细节:
/skill superpowers:brainstorming
这就是 Superpowers 的核心使用方法——强制纪律、结构化流程、确保质量。
✻ Brewed for 1m 47s2.使用superpowers进行开发
第一步:进入 using-superpowers
AI 会先判断:这个任务是否涉及设计、计划、实现、测试、review。
第二步:进入 brainstorming
AI 会开始问:
- 失败重试适用于哪些接口?
- 最多重试几次?
- 是否需要指数退避?
- 出错后前端如何提示?
它还可能提出多种方案,例如:
- 简单固定重试
- 指数退避重试
- 区分错误类型后重试
然后形成一份 spec。
第三步:进入 using-git-worktrees
AI 会为这次任务建立隔离工作区,并确认当前测试基线是否通过。
第四步:进入 writing-plans
AI 会把“登录失败重试机制”拆成一系列可执行任务,比如:
- 为重试逻辑写失败测试
- 实现最小版本的重试函数
- 为错误类型分支补测试
- 更新调用方
- 补集成测试
- 提交 commit
第五步:进入执行阶段
这里通常会有两种路线:
subagent-driven-development:每个任务交给独立子代理执行executing-plans:在当前会话里按计划逐步执行
第六步:实现过程中穿插其他 skills
例如:
- 写代码前走
test-driven-development - 测试失败或行为异常时走
systematic-debugging - 每个阶段结束后走
requesting-code-review - 收到 review 后走
receiving-code-review - 宣称完成前走
verification-before-completion
第七步:进入 finishing-a-development-branch
最后 AI 不会直接说“完成了”,而是会:
- 先确认测试通过
- 询问你是要本地合并、创建 PR、保留分支,还是丢弃工作
二十、跨平台适配:为什么说它不是某个平台的私有技巧?
这也是我认为 superpowers 很值得学习的一点。
1. 它在多平台上做了分发设计
根据仓库内容,它至少覆盖了:
- Claude Code
- Cursor
- Codex
- OpenCode
- Gemini CLI
2. 各平台接入方式不同
对 Codex
通过 ~/.agents/skills/ 的发现机制和符号链接接入。
对 OpenCode
通过 plugin 数组注册,并用 hook 把技能目录和上下文注入进去。
对 Cursor
通过插件 marketplace 元数据接入。
对 Gemini
通过 GEMINI.md 指定上下文文件。
3. 这背后体现的抽象能力
作者没有把 skill 与某个平台深度耦合,而是尽量抽象成:
- skill 内容
- 元数据
- 角色文件
- hook 配置
- 命令入口
然后在不同平台上做轻量适配。
这很像软件工程里“核心逻辑与运行时适配分层”的思路。
二十一、这个项目最值得学习的 5 个地方
读完之后,我觉得 superpowers 最值得学习的,不是某条具体 skill,而是以下五点。
1. 它把 Prompt Engineering 软件工程化了
不是几段提示词,而是:
- 模块化
- 可分发
- 可测试
- 可适配
- 可持续演化
2. 它非常清楚 AI 的弱点在哪
整个仓库几乎都在围绕这些弱点设计:
- 爱跳步骤
- 爱拍脑袋
- 爱跳过验证
- 爱过早实现
- 爱在模糊要求下自由发挥
3. 它不迷信模型能力,而是强调流程治理
这个项目传达出的一个很强烈的信号是:
提升 AI 编码质量,不一定靠更强的模型,也可以靠更强的流程。
4. 它把多代理协作设计成了流水线,而不是噱头
不是“有多个 agent 就厉害”,而是:
- 什么时候该拆
- 怎么给上下文
- review 顺序怎么安排
- 什么时候并行,什么时候串行
都有明确原则。
5. 它很重视“证据”
无论是 TDD、debugging、verification,还是 code review,底层都在强调同一件事:
- 不要先说结论
- 先拿证据
- 没证据就不要宣称完成
这其实是很典型的工程思维。
二十二、这个项目的局限与争议点
当然,superpowers 也不是没有代价。
1. 流程很重
这是最明显的。
从 brainstorming 到 spec,再到 worktree、plan、子代理、review、finish,整个链路比普通聊天式编码重得多。
对于简单任务,很多人会觉得它太“官僚”。
2. 对平台能力有依赖
比如:
- 有的平台子代理能力更强
- 有的平台 skill 发现机制更成熟
- 有的平台 hook 更完善
这会直接影响 superpowers 的使用效果。
3. 不一定适合所有使用风格
如果你的开发方式更偏:
- 快速试错
- 边做边改
- 原型优先
那这套流程可能会让你觉得被束缚。
4. 强规则也可能导致机械执行
当规则非常细时,模型虽然更不容易乱来,但也可能变得:
- 过度拘泥
- 对简单任务反应迟缓
- 把流程当目标本身
所以它本质上是一种取舍:
用灵活性换稳定性,用速度换可控性。
二十三、从 superpowers 我得到的最大启发
如果只把这个项目看成“一个给 Claude/Cursor 用的增强仓库”,其实会低估它。
我更愿意把它理解成:
一套针对 AI Coding Agent 的流程治理实验。
它的启发不在于某条规则本身,而在于它回答了一个更重要的问题:
当 AI 参与软件研发时,我们该如何约束它?
作者给出的答案是:
- 用 skill 约束行为入口
- 用 spec 限制需求歧义
- 用隔离工作区控制实施环境
- 用 plan 降低执行偏差
- 用 subagent 拆角色
- 用 review 和 verification 建证据链
- 用 hooks 和 metadata 做平台化分发
这套设计说明,未来的 AI 编码工具竞争,可能不只是模型参数的竞争,也包括:
- 工作流设计能力
- 流程治理能力
- 多代理编排能力
- 行为约束能力
从这个意义上说,superpowers 的价值已经不只是“好不好用”,而是“它揭示了下一阶段 Agent 工程的一种方向”。
二十四、总结:为什么这个项目值得认真读一遍?
如果你是前端、后端、全栈,甚至只是一个经常使用 AI 编码助手的开发者,我都觉得这个仓库值得读。
原因不一定是因为你会原封不动采用它的所有流程,而是因为它能帮你重新思考这几个问题:
- AI 写代码时,哪些步骤最容易偷懒?
- 哪些最佳实践应该被写成“硬规则”而不是“软建议”?
- Prompt 能不能像代码一样被模块化、测试和维护?
- 多代理协作真正需要什么样的流程设计?
对我来说,superpowers 最值得学习的地方,不是它把某个模型“变得更聪明”,而是它试图把模型“变得更守规矩”。
而在工程世界里,很多时候:
守规矩,往往比自作聪明更重要。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)