LLM-QAT: Data-Free Quantization Aware Training for Large Language Models
多种训练后量化(PTQ)方法已应用于大语言模型(LLM),并证明在低至 8 位(8-bit)精度时表现良好。我们发现,当位宽进一步降低时,这些方法将失效;因此,我们研究了针对大语言模型的量化感知训练(LLM-QAT),以进一步提升量化水平。我们提出了一种,该方法利用预训练模型生成的文本进行训练,能够更好地保留原始输出分布,并允许在不依赖原始训练数据的情况下量化任何生成模型,这一点与训练后量化方法类
Abstract
多种训练后量化(PTQ)方法已应用于大语言模型(LLM),并证明在低至 8 位(8-bit)精度时表现良好 。我们发现,当位宽进一步降低时,这些方法将失效;因此,我们研究了针对大语言模型的量化感知训练(LLM-QAT),以进一步提升量化水平 。我们提出了一种无数据蒸馏(data-free distillation)方法,该方法利用预训练模型生成的文本进行训练,能够更好地保留原始输出分布,并允许在不依赖原始训练数据的情况下量化任何生成模型,这一点与训练后量化方法类似 。除了对权重和激活值进行量化外,我们还对 KV 缓存(KV cache) 进行了量化,这对于提高模型吞吐量以及支持当前模型规模下的长序列依赖至关重要 。我们在 7B、13B 和 30B 规模的 LLaMA 模型上进行了实验,量化水平低至 4 位(4-bit) 。我们观察到,相较于无需训练的方法,本方法取得了显著改进,尤其是在低位宽设置下 。
1 Introduction
继 GPT-3 之后,OPT、PaLM、BLOOM、Chinchilla 以及 LLaMA 等多个大语言模型(LLM)家族已经证实,增加模型规模可以显著提升模型能力 。因此,拥有数百亿甚至数千亿参数的语言模型已成为当今 AI 领域的常态 。尽管 LLM 令人兴奋,但由于其巨大的计算成本和环境足迹,要让数十亿用户受益仍面临重大障碍 。
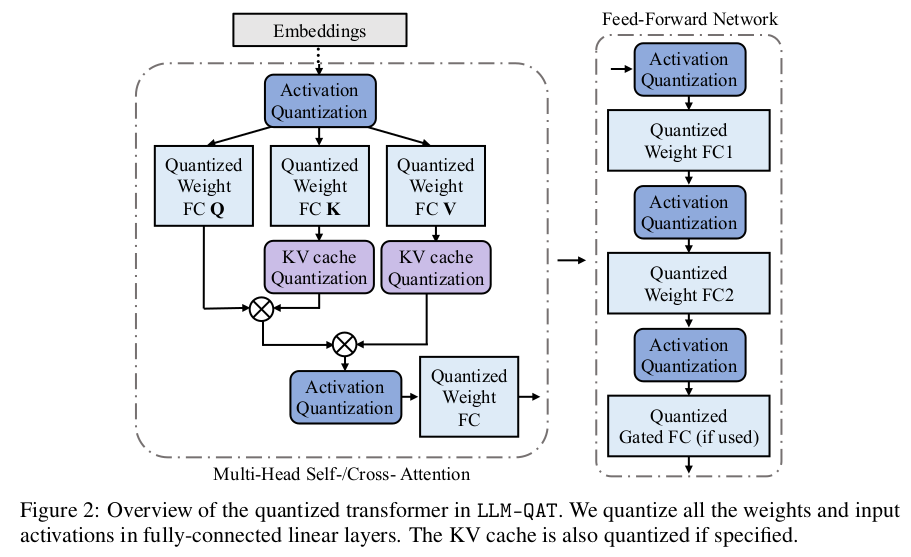
幸运的是,在实现 LLM 精确量化方面已有越来越多的努力,多项近期研究专注于权重和激活值的 8 位(8-bit)训练后量化,并实现了几乎无损的准确度 。然而,一个拥有 650 亿参数的 LLaMA 模型仅权重就需要占用 65GB 的 GPU 显存 。此外,用于存储注意力层激活值的键值(KV)缓存很容易达到数十 GB,并成为当今应用中常见的长序列生成场景下的吞吐量瓶颈 。上述研究并未将 KV 缓存量化与权重及激活值量化结合考虑 。遗憾的是,最先进的(SoTA)训练后量化方法在位宽低于 8 位时,质量会大幅下降 。对于更高水平的量化,我们发现有必要求助于量化感知训练(QAT) 。
据我们所知,此前尚未有人研究过针对 LLM 的 QAT 。这主要有两个原因:首先,LLM 的训练技术难度大且资源密集 ;其次,QAT 需要训练数据,而 LLM 的训练数据很难获取 。预训练数据的庞大规模和多样性本身就是一个障碍 。数据预处理可能成本极高,甚至有些数据由于法律限制而无法获得 。此外,LLM 越来越多地采用涉及指令微调和强化学习的多阶段训练方式,这在 QAT 过程中很难复制 。
在本研究中,我们通过利用 LLM 自身生成的文本进行知识蒸馏,巧妙地避开了这一问题 。这种简单的解决方案被我们称为“无数据知识蒸馏(data-free knowledge-distillation)”,它适用于任何生成模型,无论原始训练数据是否可用 。我们证明,与在原始训练集的大型子集上训练相比,该方法能更好地保留原始模型的输出分布 。此外,我们仅使用一小部分(10 万条)采样数据就能成功蒸馏出量化模型,从而将计算成本控制在合理范围内 。我们所有的实验均在单个 8-GPU 训练节点上完成 。
因此,我们能够将 7B、13B 和 30B 规模的 LLaMA 模型的权重和 KV 缓存量化至 4 位 。在这方面,我们的方法相比训练后量化在质量上表现出显著增强 。值得注意的是,采用 QAT 的大模型即使模型大小相近,其表现也优于使用 16 位浮点表示的小模型 。此外,我们成功地将激活值量化至 6 位精度,超越了现有方法的能力 。
总而言之,我们展示了 QAT 在 LLM 上的首次应用,催生了首批精确的 4 位量化 LLM 。我们还证明了在量化权重和激活值的同时量化 KV 缓存的可行性,这对于缓解长序列生成的吞吐量瓶颈至关重要 。所有这一切都是通过一种创新的无数据蒸馏方法实现的,它使 QAT 对于大规模预训练生成模型变得具有实际可行性 。
2 Method
使用量化感知训练(QAT)来量化大语言模型(LLM)是一项非平凡的任务,主要在两个关键方面面临挑战 。首先,LLM 经过预训练以在零样本泛化(zero-shot generalization)方面表现出色,量化后必须保留这一能力 。因此,选择合适的微调数据集至关重要 。如果 QAT 数据所属领域过窄,或与原始预训练分布有显著差异,很可能会损害模型性能 。另一方面,由于 LLM 训练的规模和复杂性,很难完全复制原始的训练设置 。在第 2.1 节中,我们介绍了无数据量化感知训练(data-free QAT),它通过“逐次标记数据生成”来产生 QAT 数据 。事实证明,该方法的性能优于使用原始预训练数据的子集 。其次,LLM 表现出独特的权重和激活分布,其特征是存在大量的异常值(outliers),这使其区别于较小的模型 。因此,针对小模型的最先进(SoTA)量化截断(clipping)方法无法直接应用于 LLM 。在第 2.2 节中,我们将确定适用于 LLM 的量化器 。
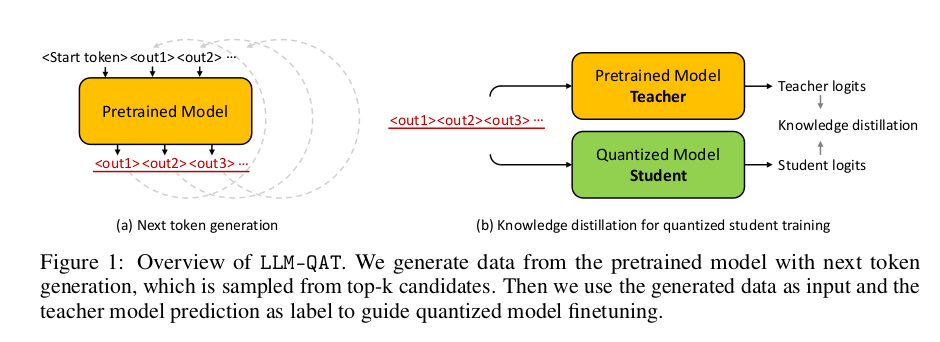
2.1 Data-free Distillation

2.2 Quantization-Aware Training
2.2.1 Preliminaries


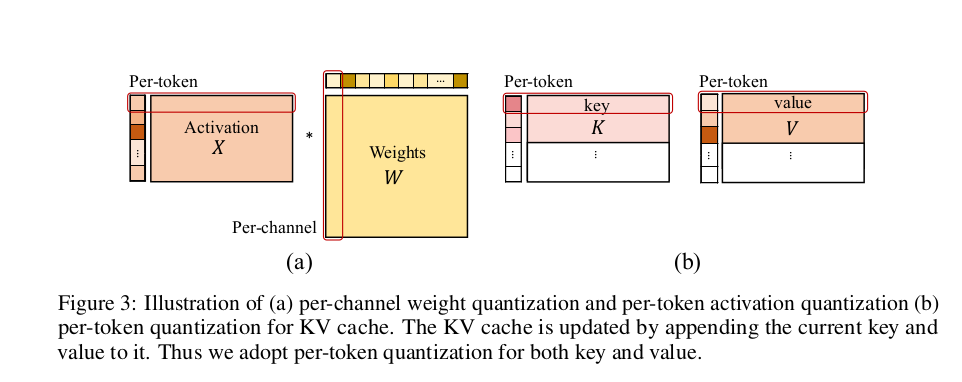
2.2.2 Quantization for Large Language Models




有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)