全网最全!OpenClaw源码拆解实录,多Agent并发核心秘密全公开,这一篇含金量极高!
我见过太多人在演示多 Agent 系统的时候,本质上做的是同一件事:开好几个对话窗口,让几个 GPT 互相"聊天",然后说这是 Multi-Agent。
我见过太多人在演示多 Agent 系统的时候,本质上做的是同一件事:
开好几个对话窗口,让几个 GPT 互相"聊天",然后说这是 Multi-Agent。
这不是多 Agent,这是多个单 Agent 在凑热闹。
真正的多 Agent 系统要解决的问题跟这个差远了——它要解决的是:当一个复杂任务需要多种专业能力协同完成时,系统如何稳定、高效、可控地把这件事做完。
OpenClaw 是我见过在这个方向上做得比较认真的开源框架之一。今天我想从底层机制讲清楚它到底是怎么运行的,不讲概念,讲原理。
一、先说清楚一件事:你对多 Agent 的理解可能是错的
有段时间我自己也这么想:多 Agent 嘛,就是多个 AI 模型一起跑,互相传信息,像一个团队一样分工合作。
听起来合理,但问题全在细节里。
问题一:角色混乱。 你让同一个 Agent 又写代码、又分析数据、又回复客户,上下文很快就乱了。它不知道自己现在是程序员还是客服,结果两件事都没做好。这不是模型能力不够,是架构设计有问题。
问题二:上下文爆炸。 多步骤任务里,每一步的输入输出都往上下文里塞。跑到第五步,前四步的内容已经撑满了 context window,模型开始"遗忘",输出质量断崖式下降。
问题三:成本失控。 每次推理都带着一整条对话历史,token 用量呈指数增长。跑个稍微复杂的工作流,API 费用能让你怀疑人生。
问题四:不可控。 任何一步失败,整个链条断掉。没有重试,没有降级,更没有追踪,就是一个黑盒崩掉了。
AutoGPT 当年火的时候,很多人发现跑着跑着就乱套了,原因就在这里——它没有真正解决上面这些问题,只是把单 Agent 的能力拼凑了一下。
OpenClaw 的切入点不一样。它的核心主张是:
多 Agent 不是让更多模型参与对话,而是把大模型推理能力微服务化。
Agent 是一个可执行的独立单元,有自己的角色、自己的记忆、自己的工具权限,通过一套严格定义的通信协议跟其他 Agent 协作。这更像是一个组织架构设计问题,而不是一个模型调用问题。
二、在 OpenClaw 里,Agent 到底是什么?
这个问题比你想的重要。很多框架里,Agent 只是一个 Prompt 的别名——换个 system message,就叫另一个 Agent 了。
OpenClaw 不是这样的。
Agent 的三层结构
最底下一层是 LLM(大脑),就是具体调用的模型,可以是 GPT-4、Claude、本地的 Llama,可插拔,可替换。
中间一层是 Skill(能力)。Skill 是独立注册的功能模块,比如"执行 Python 代码"、“控制浏览器”、“检索知识库”。它们不属于任何特定 Agent,按需调用。
最上面一层才是 Agent(角色封装),它把 LLM、Skill、记忆和执行策略组合在一起,形成一个有具体角色的可执行单元。
所以一个 Agent 完整的内部结构大概是这样的:
Role → 角色定义(你是谁)Instruction → 行为约束(你能做什么,不能做什么)Context → 当前上下文(你现在知道什么)Skill Binding → 绑定了哪些能力Execution Policy → 执行策略(最多跑几步,超时怎么处理)
有个关键点要强调:Agent 是"可执行单元",不是"聊天人格"。
它更像是一个进程,有生命周期,有状态,有资源限制,有通信接口。你不是在"和它聊天",你是在"调度它执行任务"。
三层隔离:为什么不同 Agent 不会"串话"
OpenClaw 里多个 Agent 可以同时运行,但它们之间不会互相干扰,原因是实现了三层隔离。
身份隔离:每个 Agent 有自己的模型配置和 API 密钥。一个 Agent 用 GPT-4,另一个用 Claude,各自独立,互不影响。
状态隔离:对话历史完全隔离。Agent A 和用户聊了什么,Agent B 完全不知道。这是防止 Context Pollution(上下文污染)的关键——很多多 Agent 系统最大的问题就是不同 Agent 的上下文互相污染,导致输出越来越乱。
工作隔离:每个 Agent 有自己独立的文件系统区域和记忆存储(在 OpenClaw 里叫 soul.md)。Agent 的"长期记忆"是真正物理隔离的,不是靠 Prompt 里加几个标记来区分。
这三层加在一起,让每个 Agent 真正做到了"独立办公"。它们之间的协作,通过接下来要讲的通信机制来实现,而不是靠共享状态。
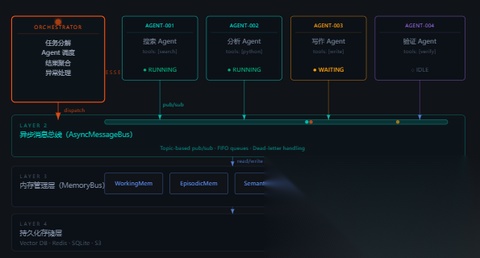
三、整体运行时架构:六层结构
现在来看 OpenClaw 多 Agent 系统完整的运行时架构。自顶向下有六层,我依次讲。
用户请求 ↓① Router(路由层) ← 意图识别,决定谁来接 ↓② Planner(任务拆解层) ← 把大任务拆成子任务图 ↓③ Agent Scheduler(调度器)← 决定谁先跑、谁并行、失败怎么办 ↓④ Agent Execution(执行层)← 每个 Agent 跑自己的 ReAct 循环 ↓⑤ Skill / Tool(能力层) ← 真正调用工具、执行操作 ↓⑥ Aggregator(汇总层) ← 合并结果,返回给用户
这六层不是随便分的,每一层的职责边界都很清晰,而且遵循一个原则:上层决策,下层执行,层与层之间只通过接口通信,不共享内部状态。
类比一下:Router 是公司前台,Planner 是项目经理,Scheduler 是排班系统,Agent 是员工,Skill 是员工手里的专业工具,Aggregator 是最后的汇报会。每个角色都知道自己的边界在哪。
接下来重点讲每一层的底层机制。
四、底层机制逐层拆解
第一层:Router — 谁来决定"这件事交给谁"
Router 是所有外部请求的入口。用户的消息,不管来自 Telegram、飞书还是 API,都先经过 Router,然后才进入 Agent 体系。
Router 干的事情本质上是两件:意图识别和任务路由。
它不是一个简单的关键词匹配,而是"轻量分类模型 + Prompt 规则系统"的组合。识别出"这是一个写代码的请求",然后路由到 Code Agent;识别出"这是一个数据分析请求",路由到 Analysis Agent。
OpenClaw 里 Router 有一套 8 级优先级路由机制,从最精确的"绑定到特定 Agent",到最兜底的"默认 Agent 处理",每一级都有明确的匹配规则。这保证了每一条消息都有确定性的去向,不会因为"没人接"而丢失。
这个设计有个很重要的价值:可追踪性。每一条消息从进入系统的第一步开始,就有了完整的路由记录。出了问题,你知道从哪里查。
第二层:Planner — 任务拆解是一次推理,不是写配置
Planner 是整个多 Agent 系统能跑起来的起点,也是 OpenClaw 和传统工作流引擎最本质的区别。
传统工作流引擎(比如 n8n、Airflow)里,任务拆解是人写配置文件来定义的。你要告诉系统"第一步做什么、第二步做什么、分支条件是什么",这是人的工作。
OpenClaw 里,Planner 本身是一个 LLM。
用户说"帮我分析这个项目,并生成一份报告",Planner 会把这句话拆成:
任务图(DAG):① 获取项目数据 → 无前置依赖,可以立刻开始② 分析代码结构 → 依赖①的结果③ 生成结构化总结 → 依赖②的结果④ 排版输出报告 → 依赖③的结果
这个拆解过程本身是一次 LLM 推理,输出的是结构化的 DAG JSON,交给下一层的 Scheduler 来执行。
这意味着 Planner 能处理模糊的、自然语言描述的任务,不需要用户提前把任务拆好。任务分解是 AI 的工作,不是用户的工作。
这也带来了一个连锁好处:任务图是动态生成的,可以根据任务内容灵活调整,不是提前写死的固定流程。
第三层:Scheduler — OpenClaw 的"灵魂组件"
如果说 Planner 是项目经理,那 Scheduler 就是排班系统,负责把任务图翻译成实际的执行顺序。
它有四种调度策略:
- 串行(Chain):任务一个接一个,严格按顺序
- 并行(Parallel):所有任务同时开跑,互不等待
- 条件执行(If/Else):根据上一步的结果决定走哪条路
- 递归执行(Loop):某个步骤循环执行直到满足条件
实际工作流里用得最多的是 DAG 调度——有依赖关系,但可以部分并发。
DAG 调度的核心逻辑是:把 Planner 生成的任务图做一遍拓扑排序,所有入度为 0(没有前置依赖)的节点,同时发给对应的 Agent 执行。某个节点完成后,它的下游节点入度减一,减到 0 了就立刻触发。
实现上用的是 asyncio.wait(FIRST_COMPLETED)——同时监听所有在跑的任务,任意一个完成就立刻处理,解锁下游,而不是傻等所有任务都完成再继续。
async def execute_dag(self, dag: TaskDAG) -> dict: completed = {} pending = set(dag.get_ready_nodes()) # 入度为 0 的节点 in_flight: dict[str, asyncio.Task] = {} while pending or in_flight: # 同时 dispatch 所有 ready 节点 for node_id in pending: task = dag.nodes[node_id] agent = self._select_agent(task) coro = self.bus.request( f"task/{agent.id}", TaskMessage(task, context=completed) ) in_flight[node_id] = asyncio.create_task(coro) pending.clear() # 等待任意一个完成,立刻处理 done, _ = await asyncio.wait( in_flight.values(), return_when=asyncio.FIRST_COMPLETED ) for fut in done: node_id = _find_key(in_flight, fut) completed[node_id] = fut.result() in_flight.pop(node_id) # 解锁下游 pending |= dag.unlock_downstream(node_id, completed) return completed
这段代码不复杂,但它实现了一个很重要的效果:在满足依赖约束的前提下,最大化并发度。该并行的时候绝不串行,该等待的时候绝不乱动。
容错方面,Scheduler 内置了 WatchDog 协程。如果某个 Agent 超时未回复,任务会被转入 Dead Letter Queue(死信队列),触发重试或降级策略。单个 Agent 的失败不会让整个工作流崩掉。
第四层:Agent 执行 — 每个 Agent 是一个持久运行的进程
到了执行层,才是真正到了 Agent 干活的地方。
这里有一个很多人会忽略的设计细节:在 OpenClaw 里,每个 Agent 不是一个函数,而是一个持久运行的 asyncio 事件循环。
它不是"被调用一次,返回结果,结束",而是一直在跑,持续监听自己的消息队列(Mailbox),有任务来了就处理,处理完了等下一个。这个区别非常关键,它是真并发的基础——多个 Agent 可以同时在不同的事件循环里处理不同的任务,互不阻塞。
class BaseAgent(AsyncRunnable): def __init__(self, agent_id: str, config: AgentConfig): self.id = agent_id self.mailbox = asyncio.Queue() # 私有消息队列 self.working_mem = WorkingMemory() # 短期工作内存 self.reasoner = Reasoner(config.llm) # LLM 推理引擎 self.tool_runner = ToolRunner(config.tools) self.status = AgentStatus.IDLE async def run(self): # 核心事件循环:持续监听邮箱 whilenotself._shutdown: msg = await self.mailbox.get() self.status = AgentStatus.RUNNING result = await self._process(msg) await self.bus.publish(f"result/{self.id}", result) self.status = AgentStatus.IDLE
收到任务后,Agent 进入 ReAct 推理循环:
① 看当前任务和上下文② 决定下一步:是调用工具,还是给出最终答案?③ 如果调用工具:执行工具,把结果写回 working memory④ 回到①,继续推理⑤ 直到得出最终答案,把结果发布出去
这个循环最多跑几步是有限制的(max_steps),防止 Agent 陷入死循环。工具调用是沙盒化的,有超时、有重试、有结果校验,不会因为一个工具调用挂掉就把整个 Agent 搞崩。
第五层:Skill / Tool — 真正干活的地方
很多人会把 Agent 和 Skill 的职责搞混。
简单说:Agent 负责决策,Skill 负责执行。
Agent 的工作是"决定用什么工具",Skill 的工作是"把这个工具用好"。
Skill 在 OpenClaw 里是独立注册的,不属于任何特定 Agent。这是一个微服务式的解耦设计——你可以随时给系统新增一个 Skill(比如"发送邮件"),然后所有有权限的 Agent 都能用它,不需要改任何 Agent 的代码。
常见的 Skill 包括:文件操作、浏览器控制(Playwright)、API 调用、Python 代码执行、数据库查询、向量检索……本质上,任何可以被包装成函数调用的操作,都可以成为一个 Skill。
这个设计解决了传统框架里一个很蛋疼的问题:能力跟 Agent 绑定死了,想复用就要复制一遍。现在 Skill 是公共资源,Agent 按需取用。
第六层:Aggregator — 把碎片拼回完整答案
最后一层是结果汇总。多个 Agent 并发跑,各自返回自己那一块的结果,最后需要有人把这些碎片拼成一个完整、连贯的答案。
这件事比看起来要复杂。你要处理:不同 Agent 输出的格式可能不一样;有些结果有重叠;有些结果之间有逻辑依赖,不能简单拼接;还有一种情况是某个子任务失败了,结果里有缺口,需要降级处理。
Aggregator 在 OpenClaw 里做的是:合并、去重、排序、结构化,最后输出一个对用户来说语义完整的结果。用户看到的是"一次回答",但底层发生的是一场有组织的团队协作。
五、Agent 间通信:消息总线是整个系统的神经中枢
把上面六层串起来的,是 OpenClaw 的 AsyncMessageBus(异步消息总线)。
这个设计有一个非常坚定的原则:Agent 之间不允许直接调用,任何通信都必须经过消息总线。
为什么这么设计?两个原因。
第一,可观测性。所有消息都经过总线,就意味着所有消息都可以被记录、追踪、分析。出了问题,你能完整地复现出整个执行过程里每一条消息是什么、什么时候发的、有没有被正常处理。直接调用就没有这个能力。
第二,可替换性。Agent A 调用 Agent B 的时候,它不需要知道 B 的具体实现,只需要知道往哪个 Topic 发消息、期望收到什么格式的回复。这意味着你可以随时替换掉 B 的实现,只要接口不变,A 完全感知不到。
三大通信原语
OpenClaw 定义了三种基本的通信方式:
sessions_send(点对点私信),就是同步或异步地给另一个 Agent 发消息,等待它回复。适合"我需要你做一件事,做完告诉我结果"的场景,比如项目管理 Agent 问法务 Agent"这个合同条款有没有风险"。
sessions_spawn(子代理派生),这个是 OpenClaw 并发能力的关键。它让一个 Agent 可以动态孵化出一个或多个子 Agent,非阻塞地交给它们执行子任务,父 Agent 不等待直接继续干自己的事,子任务完成后回调返回结果。
举个直观的例子:用户说"帮我分析这 3 个文件",主 Agent 收到请求后,立刻 Spawn 出 3 个子 Agent,每个负责分析一个文件,三个并行跑,主 Agent 继续等其他任务。三个都跑完了,结果统一汇报给主 Agent 处理。对比串行处理,时间从"3 倍"变成"1 倍",这就是并发效率的来源。
# sessions_spawn 的核心逻辑async def spawn_agent(self, task: Task) -> AgentResult: child_id = f"{self.id}_child_{uuid4().hex[:8]}" child = Agent(child_id, config=self.config) # 非阻塞,父 Agent 不等待 asyncio.create_task(child.run()) result = await self.bus.request( f"task/{child_id}", TaskMessage(task), timeout=30.0 ) return result
sessions_broadcast(广播通知),一对多。不是请求某个 Agent 干事,而是通知所有相关 Agent 某件事发生了。适合配置更新、状态同步这类场景——比如"知识库更新了,所有 Retrieval Agent 注意一下"。
消息投递的内部机制
消息总线本身用的是 Pub/Sub(发布-订阅) 模式,基于 asyncio.Queue 实现。
关键设计是 Fire-and-Forget(发完就走)。发布者把消息投到总线,立刻返回,不等接收方处理完。接收方从自己的私有 Mailbox 里异步消费消息。两边完全解耦,互不阻塞。
async def publish(self, topic: str, msg: Message) -> None: for queue in self._topics.get(topic, []): try: queue.put_nowait(msg) # 非阻塞投递 except asyncio.QueueFull: await self._dead_letter.put(msg) # 满了转死信队列
如果 Agent 正忙,消息在队列里等着,不会丢失。如果队列满了(背压),消息转入 Dead Letter Queue,等待后续处理。整个流程里没有一个强制等待点,这是 OpenClaw 能实现真并发的底层原因。
六、内存架构:Agent 的"记忆"是怎么工作的
多 Agent 系统里最容易被忽略、但实际上非常重要的一层,是内存管理。
一个 Agent 在执行任务时需要"记住"东西。但记什么、记多久、怎么用,这些问题如果没设计好,要么 token 爆炸,要么上下文丢失,要么不同 Agent 之间互相污染。
OpenClaw 把 Agent 的记忆分成三层:
Working Memory(工作内存),存的是当前任务的上下文——正在处理什么、已经调用了哪些工具、工具返回了什么。它是短暂的,任务结束就清空。好处是每次任务开始都是干净的,不会被历史信息拖累。
Episodic Memory(情节记忆),存的是当前会话内的历史轨迹。这个 Agent 在这次会话里做了什么、用户反馈怎么样,这些信息通过 Redis 持久化,可以在同一会话的多轮交互里被引用。
Semantic Memory(语义记忆),也就是 soul.md 里的内容,是跨会话的长期知识库。存的是 Agent 的角色设定、过往经验总结、领域知识,通过 Vector DB 支持语义检索。新任务开始时,Agent 会先检索一遍相关的长期记忆,作为上下文的一部分注入。
这三层的访问速度、容量、持久性各不相同,用来平衡"记得快"和"记得久"之间的矛盾。
SharedContext:共享内容要小心
多个 Agent 有时候需要共享一些信息,比如"当前任务的总体进度"或者"用户偏好设置",这些放在 SharedContext 里。
这里有一个坑值得专门提一下:多个 Agent 同时修改 SharedContext 的同一个 key,会发生写冲突。
OpenClaw 用乐观锁来解决这个问题——每个 key 有一个 version tag,写入时检查版本号,如果发现"我读的时候是版本 3,现在要写的时候已经是版本 4 了",说明有别人改过,当前写操作失败,返回 ConflictError,调用方需要重新读取最新值,然后 merge 之后再写。
这个机制能保证数据一致性,但也意味着:不要让多个 Agent 频繁并发地写同一个 SharedContext 字段,不然大家都在不停地读-冲突-重试,效率反而下降。设计 Agent 协作逻辑的时候,要尽量让每个 Agent 写自己独占的数据域,需要共享的内容尽量通过消息传递,而不是共享内存。
七、一个完整案例:从用户输入到最终输出
光讲机制有点抽象,用一个具体案例把上面所有内容串起来。
场景:用户输入"帮我分析这个 GitHub 项目,生成一份完整的技术评估报告"。
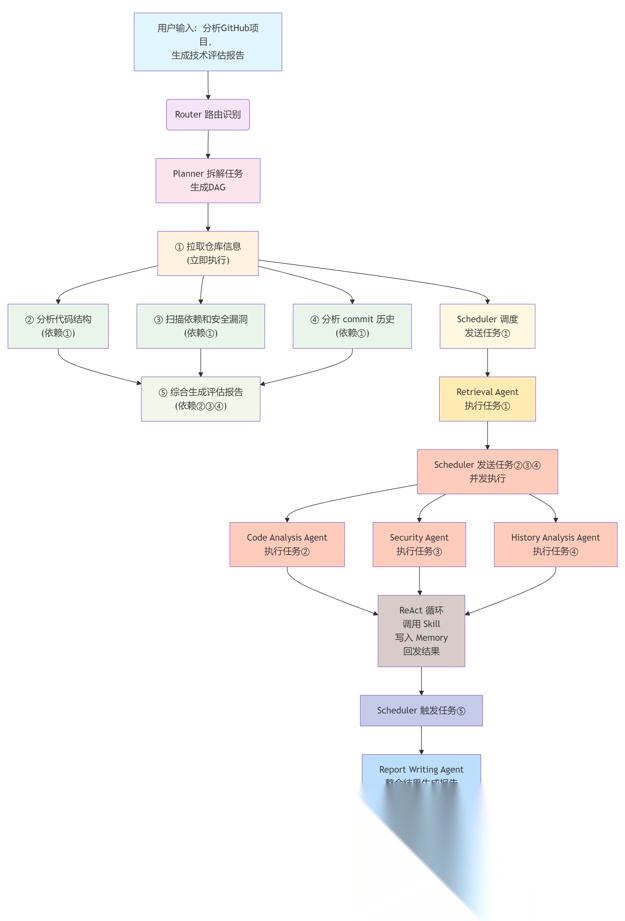
第一步:Router 路由
消息进入 Router,识别为"技术分析 + 报告生成"的复合任务,路由到 Planner。
第二步:Planner 拆解任务
Planner 接收后,推理生成如下 DAG:
① 拉取仓库信息 (可立刻执行)② 分析代码结构 (依赖①)③ 扫描依赖和安全漏洞 (依赖①) ← 和②并行④ 分析 commit 历史 (依赖①) ← 和②③并行⑤ 综合生成评估报告 (依赖②③④)
注意 ②③④ 都依赖①,但三者之间互不依赖,可以并行。
第三步:Scheduler 调度
Planner 把 DAG 交给 Scheduler。
Scheduler 先发任务①(拉取仓库信息)给 Retrieval Agent。
①完成后,立刻同时发出②③④三个任务,分别给 Code Analysis Agent、Security Agent、History Analysis Agent——三个 Agent 并发执行,互不等待。
第四步:三个 Agent 各自推理执行
每个 Agent 在自己的事件循环里跑 ReAct 循环,调用各自绑定的 Skill(代码解析工具、漏洞扫描工具、git log 分析工具),结果写入 working memory,推理完成后通过消息总线回发给 Scheduler。
第五步:触发最终任务
②③④全部完成,任务⑤(生成报告)的入度变为 0,Scheduler 立刻触发,把②③④的结果作为 context 注入,发给 Report Writing Agent。
Report Writing Agent 整合所有分析结果,生成结构化报告。
第六步:Aggregator 汇总
最终结果经过 Aggregator 格式化,返回给用户。
用户看到的是一份完整的技术评估报告。而整个过程里,②③④是并行跑的,总时间远比串行短。如果其中一个子任务失败(比如安全扫描工具挂了),Scheduler 的 WatchDog 会捕获到,重试一次,或者用降级方案(跳过这一项,在报告里标注"安全扫描数据不可用"),不会让整个工作流崩掉。
八、和传统 AI 的本质区别
到这里可以做一个横向对比了:
从本质上说,OpenClaw 不是一个聊天工具的升级版,它更像一个操作系统:
- Agent = 进程
- Skill = 系统调用
- Scheduler = CPU 调度器
- MessageBus = 进程间通信(IPC)
- Memory = 分级存储(寄存器 / 内存 / 磁盘)
- Router = 系统入口(syscall 表)
这个类比不是为了好听,而是因为它们解决的问题在结构上是一样的:如何让多个独立的执行单元,在有限资源下,高效、稳定、可控地协同完成任务。
操作系统用了几十年把这件事做好了,OpenClaw 在 AI 领域做了一遍类似的事。
九、设计哲学、局限性,以及你该怎么用
四个核心设计原则
理解一个框架,光看功能不够,要看它在做取舍时选择了什么。
本地优先。OpenClaw 的设计出发点是私有化部署,所有数据留在本地,不依赖云服务。这对有数据合规要求的场景非常重要。
消息即界面。整个系统的协作靠消息传递,不靠共享状态。这让系统变得可组合、可替换,也让调试和观测成为可能。
模型无关。LLM 是可插拔的后端,不绑定特定厂商,今天用 GPT-4,明天换 Claude,框架层完全透明。
可组合性优于复杂性。Skill 独立、Agent 独立、层与层之间接口清晰,你可以根据需要组合,不需要理解整个系统就能用好一部分。
当前的局限性
有几个地方值得客观说明:
asyncio 的限制。OpenClaw 用协程实现并发,而不是多进程。对于 I/O 密集型任务(调用 API、读写文件),这非常高效。但如果 Skill 里有 CPU 密集型操作(比如大规模数据处理),需要用 run_in_executor 下放到线程池,否则会阻塞事件循环。这是一个需要开发者注意的边界。
Agent 数量的边界。当同时运行的 Agent 数量很多时,消息总线的调度开销会上升,SharedContext 的写冲突概率也会增加。目前在单机上跑几十个 Agent 没有问题,但要做大规模分布式部署,还需要额外的基础设施支撑。
Planner 的稳定性。任务拆解本身是一次 LLM 推理,偶尔会拆得不合理(子任务粒度太细、依赖关系搞错等),需要在 Planner 层做一定的输出校验和修正逻辑。
实际上手的建议
如果你真的要用 OpenClaw 跑多 Agent,有几个经验值得分享:
从小开始。不要一上来就设计 10 个 Agent 的复杂工作流。先跑通"1 个 Orchestrator Agent + 2 个 Worker Agent"的最小系统,理解清楚消息如何流转,再往上叠。
按任务性质分 Agent,而不是按功能分。"写代码的 Agent"比"什么都干的通用 Agent"好,但"分析 Python 代码的 Agent"和"分析 SQL 代码的 Agent"就可能过度拆分了,除非两者的 Skill 需求确实差异很大。
SharedContext 越少越好。Agent 之间的信息传递尽量通过消息,只把真正需要全局共享的状态放进 SharedContext,减少写冲突的可能性。
把 Skill 写好比把 Agent 设计好更重要。Agent 的决策质量取决于 LLM 本身,但 Skill 的可靠性取决于你的代码。一个没有超时保护、没有错误处理的 Skill,会让整个 Agent 变得不稳定。
十、总结
OpenClaw 让我印象深刻的不是功能清单,而是它在架构设计上的克制——每一层职责清晰,接口定义严格,没有把"灵活"和"强大"搞成"什么都往一起塞"。
多 Agent 这个方向,现在大家都在做,但很多产品做出来的感觉是"多个 AI 凑在一起聊天",而不是"一个有组织的系统在协同工作"。这两者之间的差距,从外表上可能看不出来,但在稳定性、可维护性、可扩展性上,差异是巨大的。
OpenClaw 目前当然还不完善,但它的架构思路是值得参考的。
如果你也在搭建 AI 工作流,花点时间理解这套机制,比直接套模板要有用得多。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献717条内容
已为社区贡献717条内容

所有评论(0)