【深度学习实战】3D医疗影像分割背后的工程黑箱:基于 UX-Net 等模型的数据处理全链路解析
本文从软件工程视角解析3D医疗影像AI的数据处理流程。首先通过HU值裁剪和归一化完成数据清洗,将CT值映射到[0,1]区间;然后采用96×96×96子体积分块策略解决显存限制;接着引入旋转、强度偏移等数据增强技术提升模型鲁棒性;最后采用AdamW优化器以0.0001学习率进行40000次迭代优化。整个流程展示了深度学习系统与传统软件开发在数据标准化、内存管理和鲁棒性设计上的共通之处。
白色笔记科研分享,源码或云运行请移步白色笔记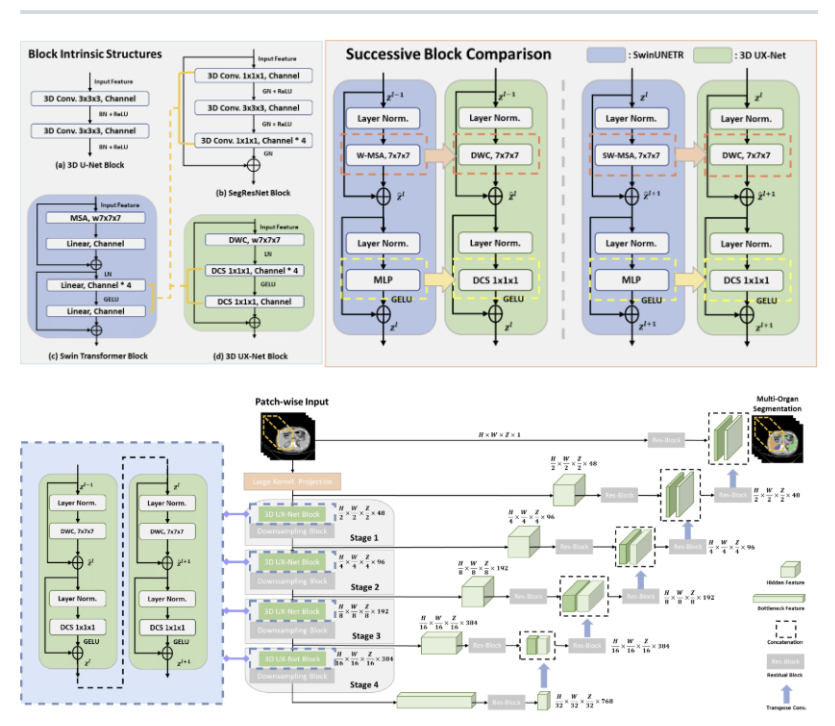
在日常的后端或客户端开发中,我们处理的数据往往是结构化的 JSON、行列整齐的数据库表,或者是二维的 JPG/PNG 图片。但如果业务需求是:在一个包含几千万个数据节点的 3D 矩阵(比如人体的 CT 或 MRI 扫描)中,精准地把肝脏、脾脏等几十个器官的三维轮廓“抠”出来,这该怎么写代码?
在医学影像 AI 领域(如 AMOS 腹部多器官分割竞赛、FLARE 竞赛),以 3D UX-Net 和 Swin-UNet 为代表的 3D 视觉模型给出了答案。今天,我们将跳出深奥的 Transformer 架构和数学推导,以纯粹的软件工程和数据流视角,拆解这套深度学习系统是如何进行数据预处理(ETL)并跑通整个核心业务闭环的。
步骤一:数据清洗与归一化(Data Sanitization & Normalization)
医疗 CT 设备扫描出来的原始数据并不是我们常见 RGB 色值(0-255),而是一种物理密度值(Hounsfield Units, HU),范围可能从 -1000(空气)到 +2000(骨骼)。如果直接把这些原始数据喂给神经网络,就像把未清洗的脏数据和乱码直接塞进数据库,模型会直接“崩溃”。
工程解法:
- 强度裁剪(Intensity Clipping):
在代码中,这相当于执行了一个严格的边界校验clamp(value, min=-175, max=250)。为什么是这个区间?因为这是人体软组织(如肝、胆、脾)所在的密度范围。把这个区间外的极值(骨头或空气)全部截断,相当于在 IDE 中开启了“语法高亮”,让神经网络聚焦于最重要的业务数据。 - Min-Max 归一化(Normalization):
随后,算法通过公式(X - X_min) / (X_max - X_min)将截断后的数值统一映射到[0, 1]的浮点数区间。在软件工程中,这等同于统一全局的时间戳格式或字符编码,确保后续的所有矩阵乘法运算都在同一个量纲下进行,防止由于数值溢出导致 NaN(Not a Number)报错。
步骤二:内存分块与滑动读取(Memory Chunking)
一个完整的高精度 3D CT 影像,其体素(3D 像素)数量往往上亿。哪怕是现今最顶配的 NVIDIA Quadro RTX 5000 显卡,其显存(GPU RAM)也绝对无法一次性吞下一个完整的 3D 影像张量。
工程解法:
就像我们在处理超大日志文件时不会用 ReadAllLines(),而是使用流式读取(Stream Reader)或分块(Chunking)。
算法在预处理阶段,会在原始的 3D 影像中随机抓取大小为 96 × 96 × 96 的子体积(Sub-volumes)切块。这种局部切片机制保证了每一批次(Batch)输入的数据量是恒定的,完美规避了 OOM(Out of Memory)内存溢出问题。
步骤三:模糊测试与数据增强(Fuzzing & Data Augmentation)
在写单元测试时,如果所有的输入测试用例都是完美无瑕的,一旦上线遇到一点异常格式,程序就会崩溃。深度学习也一样,如果它只见过笔直躺着的病人的 CT 切片,只要遇到稍微倾斜的图像,它就会“懵逼”(这种现象在 AI 中叫过拟合 Overfitting)。
工程解法:
算法团队在数据流中引入了类似于 **混沌工程(Chaos Engineering)**或 模糊测试(Fuzzing) 的机制——数据增强(Data Augmentations)。
每次将 96x96x96 的数据块送入模型前,都会通过代码随机对这个 3D 矩阵进行折磨:
- Rotations(旋转): 模拟病人躺歪了。
- Intensity Shifting(强度偏移): 模拟不同医院、不同 CT 机扫描出的亮度偏差。
- Scaling(缩放): 赋予 0.1 的缩放因子,模拟器官大小的个体差异。
这迫使 AI 不能死记硬背像素位置,而是必须真正理解“什么是器官的三维几何特征”。
步骤四:模型编译与迭代寻优(Optimizer & Training Loop)
所有的预处理做完后,就进入了深度学习的核心死循环。在本文的架构中,模型使用了 AdamW 优化器,学习率(Learning Rate)设置为 0.0001,总共要跑 40000 个循环步骤(Steps)。
工程解法:
你可以把这套训练机制理解为一个智能的自适应 PID 控制器或数据库索引调优工具:
- AdamW(优化器): 它是一个能根据历史执行状态,动态调整步长的高级寻路算法。它会计算当前模型输出的器官轮廓和医生手工标注的真实轮廓之间的“偏差值(Loss)”,并顺着能让偏差变小的方向修改模型内部的参数权重。
- Learning Rate(学习率): 决定了模型每次修正自己错误的“步伐大小”。
0.0001是一个极其微小的步伐,这意味着算法团队选择了“小步快跑、谨慎微调”的策略,以防止步伐太大直接跨过了最优解。
当我们揭开深度学习中 3D 医疗影像分割的神秘面纱,你会发现它本质上是一个高度成熟的数据处理流水线(Data Pipeline)。
从底层的业务逻辑来看,它利用边界截断和归一化完成了数据的清洗与标准化,利用空间切块解决硬件内存瓶颈,利用随机数据增强(Fuzzing)提升系统的鲁棒性,最后依靠 AdamW 优化器这个“智能调度引擎”在成千上万次循环中逼近最优解。无论是前端、后端还是 AI 算法开发,追求高并发、高可用与高鲁棒性的系统架构思维,其实是完全互通的。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)