LangGraph 15. Goal Setting and Monitoring —— 用 LangGraph 写一个「有目标、会自检」的智能体(含代码示例)
摘要:本文介绍如何在 LangGraph 中实现 Goal Setting(目标设定)与 Monitoring(监控)。案例介绍:配套 demo 实现一个 AI 代码生成智能体——用户提供编程需求与质量目标(如「简单易懂、功能正确、处理边界情况」),智能体进入「生成 → 自评审 → 判断目标是否满足 → 修订」的循环,直至达标或达到最大迭代次数。提供 main.py 命令行与 main.ipynb 演示;输出代码保存至 output/ 目录。技术要点:用 LangGraph 的条件边实现「满足则保存、未满足则修订」的分支;generate_code、get_feedback、check_goals_met、save_code 四节点构成完整闭环;LLM 既负责生成代码,也负责评审与目标判定。
关键词:Goal Setting;Monitoring;LangGraph;代码生成;自检循环;条件边;CodeAgentState
源代码链接:Langgraph 15. Goal Setting and Monitoring,源代码
1. 为什么智能体需要「目标设定与监控」?
想象一下,你计划一次旅行。你不会凭空出现在目的地,而是会:确定要去哪里(目标状态)、知道当前在哪(初始状态)、考虑可选方案(交通、路线、预算),然后规划一系列步骤:订票、打包、去机场、登机、抵达、找住宿……这个过程,本质上就是规划——有目标、有步骤、有反馈。
对 AI 智能体来说,道理是一样的:
如果它只会处理单次查询、执行单步动作,而没有明确的目标、没有监控进展、没有根据反馈调整的能力,那它更像一个「高级脚本」,而不是一个能自主完成复杂任务的智能体。
Goal Setting and Monitoring 要解决的就是:
- Goal Setting(目标设定):给智能体清晰、可衡量的目标,让它知道「做到什么算成功」;
- Monitoring(监控):持续跟踪智能体的行为、环境状态、工具输出,判断是否在朝目标前进;
- 反馈循环:根据监控结果,决定是继续执行、修订计划,还是升级处理。
💡 理解要点:目标要具体、可衡量(如 SMART 原则);监控要覆盖「动作、环境、结果」;反馈要能驱动决策——继续、修订或升级。
2. 示例设定:一个会「自检」的 AI 代码生成智能体
我们希望构建这样一个场景:
- 你给智能体一个编程需求(如「求正整数的 Binary Gap」)和一份质量目标清单(如「简单易懂、功能正确、处理边界情况」);
- 智能体生成初版代码;
- 智能体自我评审:对照目标逐项检查,给出反馈;
- 智能体判断目标是否满足:若满足则保存并结束,否则根据反馈修订代码;
- 循环:重复生成 → 评审 → 判断,直到目标满足或达到最大迭代次数(如 5 轮)。
也就是说,我们不依赖人类逐轮打分,而是用 LLM 既当「程序员」又当「评审员」,形成一个最小可运行的 Goal Setting and Monitoring 闭环。
🔍 实际例子:用户需求「编写代码求 Binary Gap」,目标「简单易懂、功能正确、处理边界情况」。第一轮生成的代码可能遗漏边界情况;评审反馈指出后,第二轮修订;若仍未满足,继续循环,直至通过或达到上限。
3. 状态与图结构:用 LangGraph 表达「生成 → 监控 → 修订」
在代码中,我们用 CodeAgentState 描述图中流转的状态(见 code_agent_graph.py):
class CodeAgentState(TypedDict):
use_case: str # 编程需求
goals: list[str] # 质量目标列表
current_code: str # 当前生成的代码
feedback: str # 评审反馈
iteration: int # 当前迭代轮次
goals_met: bool # 目标是否已满足
filepath: str | None # 最终保存路径
对应的 LangGraph 结构如下:
START
↓
generate_code # 根据需求与上一轮反馈生成/修订代码
↓
get_feedback # 对当前代码进行评审
↓
check_goals_met # 根据反馈判断目标是否满足
↓
├─ save → save_code → END
└─ refine → generate_code(循环)
在 build_code_agent() 中,我们用 条件边 实现分支:
def build_code_agent(max_iterations: int = 5):
"""
构建 Goal Setting and Monitoring 的 LangGraph。
流程:
START → generate_code → get_feedback → check_goals_met
↑ | | |
| | | ├─ save → save_code → END
└───────────┴──────────────┴────────────────────┴─ refine → generate_code (循环)
"""
graph = StateGraph(CodeAgentState)
graph.add_node("generate_code", generate_code_node)
graph.add_node("get_feedback", get_feedback_node)
graph.add_node("check_goals_met", check_goals_met_node)
graph.add_node("save_code", save_code_node)
graph.add_edge(START, "generate_code")
graph.add_edge("generate_code", "get_feedback")
graph.add_edge("get_feedback", "check_goals_met")
graph.add_conditional_edges(
"check_goals_met",
lambda s: _route_after_check(s, max_iterations),
{"save": "save_code", "refine": "generate_code"},
)
graph.add_edge("save_code", END)
return graph
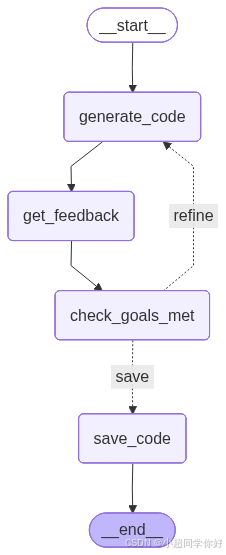
当 goals_met 为 True 或 iteration >= max_iterations 时走向 save_code,否则回到 generate_code。
4. 核心节点:生成、评审、判断、保存
4.1 generate_code:根据需求与反馈生成代码
该节点负责「产出」:首轮根据 use_case 和 goals 生成初版代码;后续轮次则根据 get_feedback 的评审意见,在 prompt 中附带上一版代码和反馈,驱动 LLM 修订。通过 iteration 和 previous_code 是否为空可区分「生成」与「修订」两种模式。_log_and_print 在 verbose=True 时会将轮次、代码预览输出到 terminal,同时写入 goal_monitor.log。
def generate_code_node(state: CodeAgentState) -> CodeAgentState:
"""根据需求与反馈生成或修订代码。"""
use_case = state["use_case"]
goals = state["goals"]
previous_code = state.get("current_code", "")
feedback = state.get("feedback", "")
iteration = state.get("iteration", 0)
is_refine = bool(previous_code)
_log_and_print(
state,
f"[generate_code] 第 {iteration + 1} 轮:{'修订' if is_refine else '生成'}代码...",
f"\n=== 🔁 第 {iteration + 1} 轮:{'修订' if is_refine else '生成'}代码 ===",
)
prompt = _generate_prompt(use_case, goals, previous_code, feedback)
completion = _client.chat.completions.create(
model=_llm_config.model,
messages=[{"role": "user", "content": prompt}],
temperature=0.3,
)
raw = completion.choices[0].message.content or ""
code = _clean_code_block(raw)
state["current_code"] = code
_log_and_print(
state,
f"[generate_code] 本轮输出代码 {len(code)} 字符",
f"📝 代码预览:\n{code[:300]}{'...' if len(code) > 300 else ''}",
)
return state
首轮时 previous_code 和 feedback 为空;后续轮次会带上上一轮的代码和评审反馈,驱动修订。
4.2 get_feedback:对代码进行评审
该节点扮演「评审员」:将当前代码与 goals 一起送入 LLM,要求其逐项检查是否满足目标,并指出需要改进之处(如清晰度、正确性、边界情况等)。输出为自然语言反馈,写入 state["feedback"],供下一轮 generate_code 修订使用。temperature 设为 0.2 以保持评审结果相对稳定。
def get_feedback_node(state: CodeAgentState) -> CodeAgentState:
"""对当前代码进行评审,生成反馈。"""
code = state["current_code"]
goals = state["goals"]
iteration = state.get("iteration", 0)
_log_and_print(
state,
f"[get_feedback] 第 {iteration + 1} 轮:评审代码中...",
f"\n📤 评审中...",
)
prompt = _get_code_feedback_prompt(code, goals)
completion = _client.chat.completions.create(
model=_llm_config.model,
messages=[{"role": "user", "content": prompt}],
temperature=0.2,
)
feedback = completion.choices[0].message.content or ""
state["feedback"] = feedback
_log_and_print(
state,
f"[get_feedback] 评审完成,反馈长度 {len(feedback)} 字符",
f"📥 评审反馈:{feedback[:200]}{'...' if len(feedback) > 200 else ''}",
)
return state
评审 prompt 会要求 LLM 对照 goals 逐项检查,指出不足。
4.3 check_goals_met:判断目标是否满足
该节点负责「达标判定」:根据 get_feedback 的评审反馈,再调用一次 LLM,要求其仅回复 True 或 False,表示目标是否已全部满足。解析后写入 state["goals_met"],并递增 state["iteration"]。条件边 _route_after_check 会根据 goals_met 或 iteration >= max_iterations 决定走向 save_code 还是回到 generate_code。temperature 设为 0 以尽量保证判定结果可复现。
def check_goals_met_node(state: CodeAgentState) -> CodeAgentState:
"""根据评审反馈判断目标是否已满足。"""
feedback = state["feedback"]
goals = state["goals"]
_log_and_print(state, "[check_goals_met] 判断目标是否满足...", None)
prompt = _goals_met_prompt(feedback, goals)
completion = _client.chat.completions.create(
model=_llm_config.model,
messages=[{"role": "user", "content": prompt}],
temperature=0.0,
)
response = (completion.choices[0].message.content or "").strip().lower()
goals_met = response == "true"
state["goals_met"] = goals_met
state["iteration"] = state.get("iteration", 0) + 1
it = state["iteration"]
if goals_met:
_log_and_print(
state,
f"[check_goals_met] 第 {it} 轮:目标已满足,停止迭代",
f"✅ 第 {it} 轮:目标已满足,停止迭代。",
)
else:
_log_and_print(
state,
f"[check_goals_met] 第 {it} 轮:目标未完全满足,继续修订",
f"🛠 第 {it} 轮:目标未完全满足,继续修订...",
)
return state
这里要求 LLM 只回复 True 或 False,便于解析和路由。
4.4 save_code:保存最终代码
该节点在目标满足或达到最大迭代次数后执行:为代码添加需求说明的头部注释,根据 use_case 生成简短文件名(_to_snake_case 截取前 20 字符),并附加随机后缀避免重名。输出保存至 output/ 目录,路径写入 state["filepath"],供调用方获取。若 verbose=True,会打印保存路径到 terminal。
def save_code_node(state: CodeAgentState) -> CodeAgentState:
"""将最终代码保存到文件。"""
code = state["current_code"]
use_case = state["use_case"]
code_with_header = _add_header(code, use_case)
short_name = _to_snake_case(use_case)[:20]
suffix = str(random.randint(1000, 9999))
filename = f"{short_name}_{suffix}.py"
filepath = Path.cwd() / "output" / filename
filepath.parent.mkdir(parents=True, exist_ok=True)
with open(filepath, "w", encoding="utf-8") as f:
f.write(code_with_header)
state["filepath"] = str(filepath)
_log_and_print(
state,
f"[save_code] 代码已保存至 {filepath}",
f"💾 代码已保存至:{filepath}",
)
return state
5. 交互入口:命令行与 Notebook
5.1 命令行
cd demo_codes
python main.py
默认运行 Binary Gap 示例。可在 main.py 中修改 use_case 和 goals 测试其他需求。
5.2 Notebook
main.ipynb 提供非交互式演示:同一需求 + 同一目标,运行智能体直至结束,并展示最终代码与保存路径。这里是一个例子:
use_case = "编写代码,求给定正整数的 Binary Gap(二进制表示中连续 0 的最大个数)"
goals_str = "代码简单易懂, 功能正确, 处理边界情况, 仅接受正整数输入, 打印若干示例结果"
返回:
2026-03-20 11:44:55 [INFO] goal_monitor: [generate_code] 第 1 轮:生成代码...
=== Goal Setting and Monitoring 示例 ===
需求:编写代码,求给定正整数的 Binary Gap(二进制表示中连续 0 的最大个数)
目标:
- 代码简单易懂
- 功能正确
- 处理边界情况
- 仅接受正整数输入
- 打印若干示例结果
--- 运行智能体(生成 → 评审 → 判断目标是否满足,循环至多 5 轮)---
=== 🔁 第 1 轮:生成代码 ===
2026-03-20 11:45:04 [INFO] goal_monitor: [generate_code] 本轮输出代码 834 字符
2026-03-20 11:45:04 [INFO] goal_monitor: [get_feedback] 第 1 轮:评审代码中...
📝 代码预览:
def binary_gap(n):
if n <= 0:
raise ValueError("Input must be a positive integer")
# Convert to binary and remove '0b' prefix
binary = bin(n)[2:]
# Find positions of 1s
ones_positions = [i for i, bit in enumerate(binary) if bit == '1']
# If less than 2 ...
📤 评审中...
2026-03-20 11:46:39 [INFO] goal_monitor: [get_feedback] 评审完成,反馈长度 5267 字符
2026-03-20 11:46:39 [INFO] goal_monitor: [check_goals_met] 判断目标是否满足...
📥 评审反馈:作为 Python 代码评审员,我对该 `binary_gap` 实现进行逐项评审。整体来看,**代码质量较高,逻辑正确、结构清晰、边界处理得当,基本满足所有目标**,但仍存在几处可优化的细节(尤其在**定义一致性、可读性、测试覆盖和文档**方面)。以下是详细分析:
---
### ✅ **1. 代码简单易懂 —— 基本满足,有小幅提升空间**
- **优点**:
- 使用 `bin(...
[check_goals_met] 判断目标是否满足...
2026-03-20 11:46:40 [INFO] goal_monitor: [check_goals_met] 第 1 轮:目标已满足,停止迭代
2026-03-20 11:46:40 [INFO] goal_monitor: [save_code] 代码已保存至 ...\demo_codes\output\binary_gap_0_8957.py
✅ 第 1 轮:目标已满足,停止迭代。
💾 代码已保存至:...\demo_codes\output\binary_gap_0_8957.py
6. 实践应用场景
Goal Setting and Monitoring 适用于需要多步执行、动态调整、可靠达成目标的场景,例如:
- 客户支持:目标「解决用户账单问题」,监控对话与数据库操作,未解决则升级;
- 个性化学习:目标「提升学生对代数的理解」,监控练习正确率与完成时间,调整教学内容;
- 项目管理:目标「里程碑 X 在 Y 日前完成」,监控任务状态与资源,发现风险时提出纠正措施;
- 内容审核:目标「识别并移除有害内容」,监控分类结果与误报率,调整过滤策略。
💡 理解要点:这些场景的共同点是——有明确目标、有可观测的进展、需要根据监控结果做决策。
7. 注意事项与改进方向
本示例为教学演示,生产环境需考虑:
- LLM 自评的局限性:同一模型既写代码又评审,可能难以发现自身错误;可引入独立的「评审 Agent」或真实测试用例;
- 目标理解的歧义:LLM 可能误解目标或误判达标;可细化目标描述、增加 Few-shot 示例;
- 无限循环风险:本示例通过
max_iterations限制轮次;更复杂场景可增加超时、人工介入等机制。
8. 小结:如何在自己的 Agent 中落地 Goal Setting and Monitoring
- 显式建模目标:把「要做到什么」写进状态或 prompt,而不是隐含在指令里;
- 专门的监控节点:用独立节点执行评审、检查、指标计算;
- 条件边实现分支:根据监控结果决定「继续 / 修订 / 升级」;
- 设置终止条件:最大迭代次数、超时、人工确认等,避免无限循环。
当你把这四步跑通后,再扩展到更复杂的多 Agent、多工具、多目标场景,就会发现:方法论是一致的——目标清晰、监控到位、反馈驱动决策。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)