FLUX-Text: A Simple and Advanced Diffusion Transformer Baseline for Scene Text Editing
利用了AnyWord-3M数据集,多语言数据集,整合了多个数据,包括wukong(中文),Laion(英文),以及一些专门为ocr设计的数据,包括丰富的文本场景,例如城市风景、书籍封面、广告海报和电影画面,该数据集大概有3M图像,其中语言分布约为1.6M张包含中文文本,1.39M中包含英文文本,以及额外的10K张展示其他语言的文本,为了训练fluxtext,我们从AnyWord-3M中提取了一个小

1.abstract
场景文本编辑旨在修改和添加自然图像中的文本,同时确保生成的文本准确无误,并与背景无缝融合。要处理复杂多样的视觉环境中的多种语言,字体,字号和文本行数,极具挑战性。
flux这些模型在场景文本编辑方面的性能有严重的局限性,这些模型通常无法准确的渲染文本,尤其是在处理非拉丁语系复杂字形(例如,拥有超过15w个字符的中文)或密集的多行布局等高要求场景时。其根本原因在于这些模型缺乏明确的文本相关先验知识,必须从零开始学习如何渲染每个字符,同时还要推断字体,颜色,布局和其他属性,这常常导致错误和不自然的结果,从而影响视觉质量(与背景的无缝融合)和文本保真度(字形的结构正确性)。
为了解决上述问题,现有的方案通常尝试将文本编辑线索注入扩散模型,以增强其文本编辑能力,这些线索大致可分为两类,1.视觉嵌入,TextDiffuser-2和Anytext,对文本的视觉外观或布局进行编码,并将其与背景信息融合到嵌入向量中,从而指导模型生成目标文本;2.文本嵌入,例如Anytext和Seedream,利用ocr特征或类似Glyph-ByT5的语义表示来约束生成过程。尽管这些方法有效,但它们依然存在两个主要局限性,1.大多基于controlnet架构,引入了大量的可学习参数;2.基于unet不如dit。
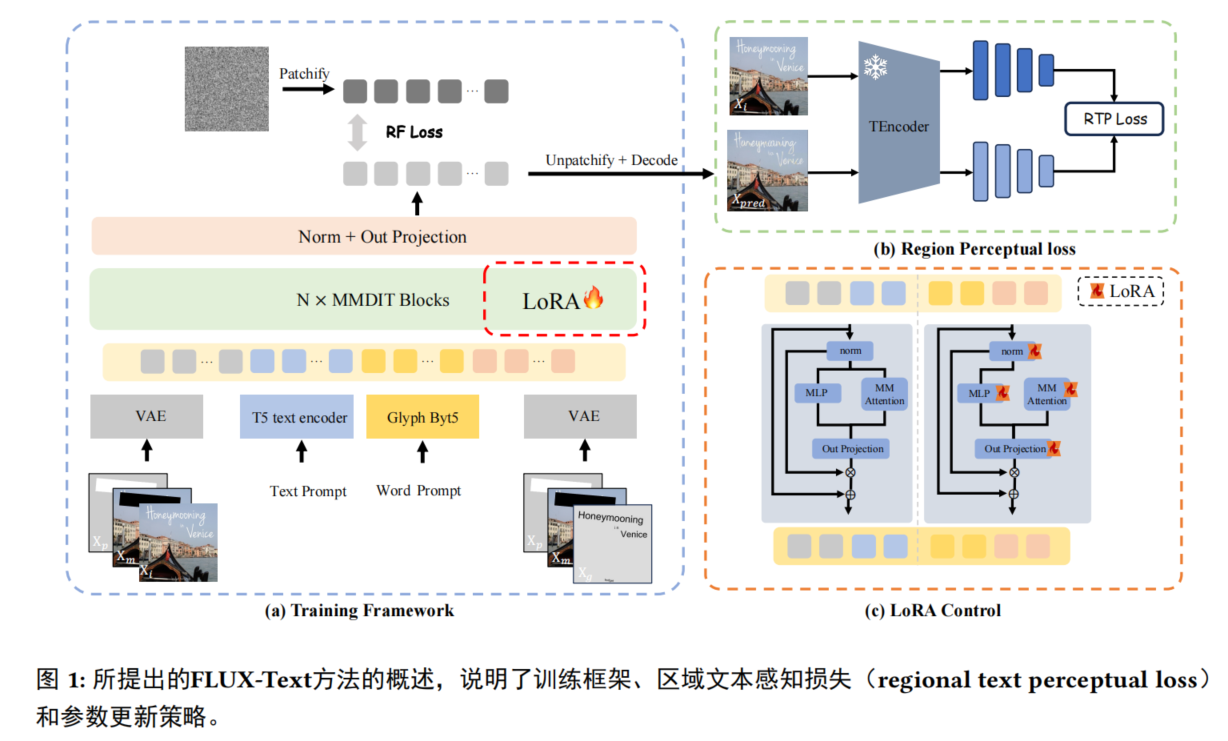
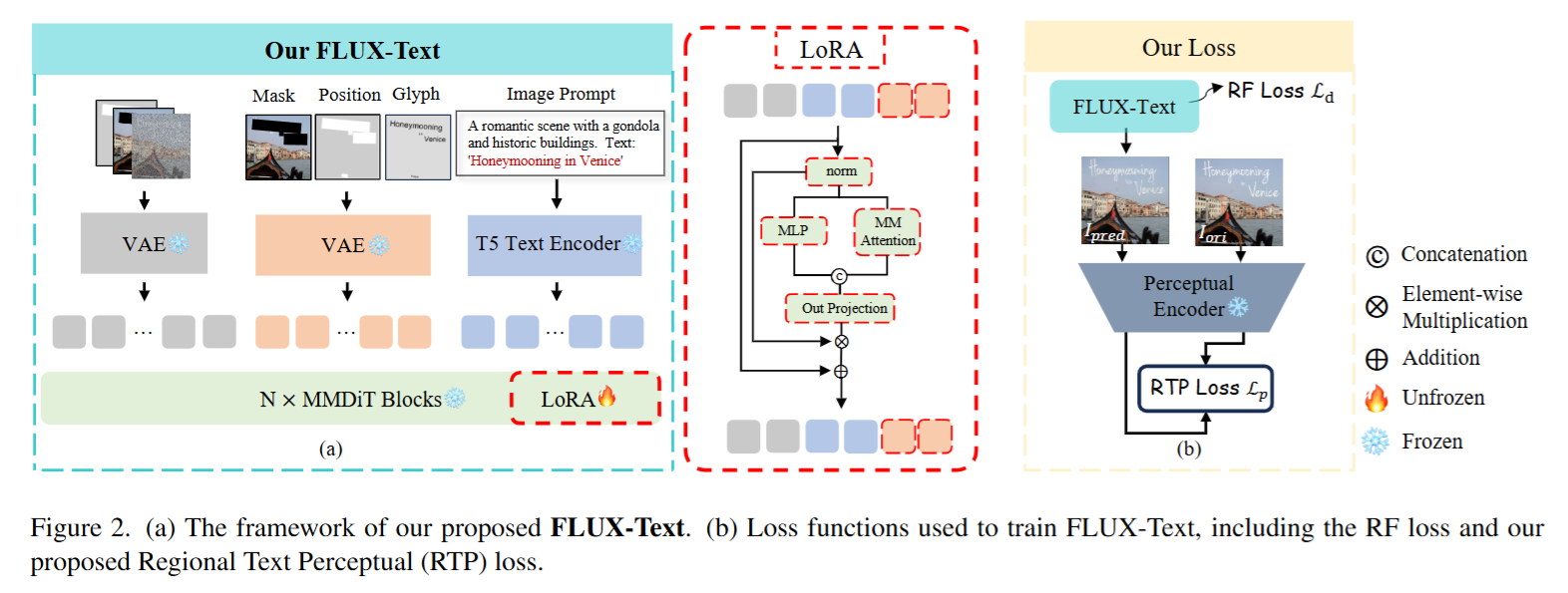
深入研究了视觉嵌入和文本嵌入模块,提出了一种新的文本编辑线索注入策略,该策略特别适用于DiT架构,还提出了区域文本感知损失和两阶段训练策略,以引导模型专注于文本区域,这不仅确保了文本和背景的和谐融合,而且显著提高了文本区域的生成质量。仅用100k即可在文本编辑任务上达到最先进的性能,训练样本可减少97%,从而显著提升了训练数据集的效率,这种效率提升主要得益于DiT骨干网络和我们的高效的文本编辑提示词注入策略。
2.Related work
由于字体多样,背景复杂,布局多变,基于扩散模型的图像中生成和编辑视觉文本依然面临挑战。利用glyph条件,分割mask或character-aware text encoders来改进生成,这些方法提供了额外的视觉先验信息和文本编辑相关的语义信息。大语言模型例如T5和基于transformer的布局预测进一步提高了拼写准确性和复杂文本的放置能力,而ocr监督和预渲染字形则提高了字符保真度,大多数方法仍然基于unet,卷积的局限性限制了他们对全局上下文进行建模和灵活适应布局变化的能力,这些方法通常依赖controlnet和大型标注数据集,增加了计算成本和复杂性,fluxtext基于DiT的场景文本编辑方法,比unet更有效的建模全局上下文和布局变化,同时所需的参数和训练数据量也少得多,且无需依赖庞大的辅助网络。
3.Methods
3.1 Preliminary

3.2 Visual Embedding Module
场景文本编辑旨在以高视觉保真度修改图像字形,这对于复杂的多笔画字符来说极具挑战性,现有的方法捕捉细粒度视觉线索的能力有限,削弱了降噪器的指导作用,视觉嵌入模块注入了文本编辑所需的细粒度视觉线索来指导文本编辑。
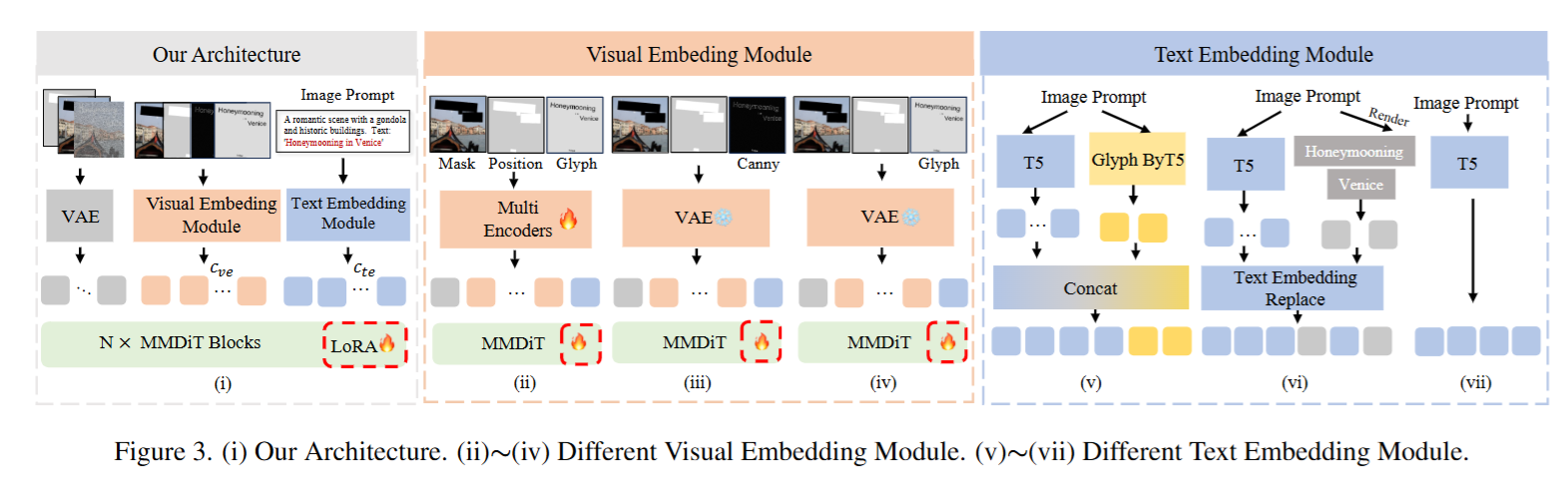
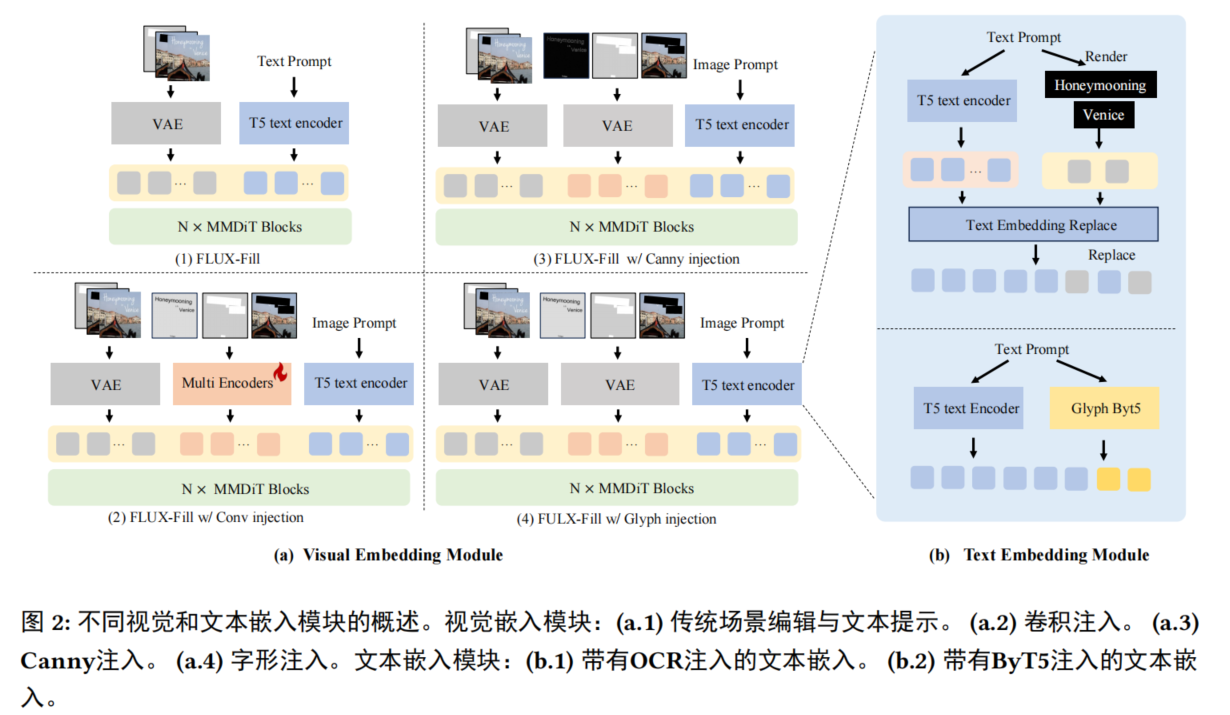
卷积注入:



3.3 Text Embedding Module
T5难以理解中文,尽管这些文本编码器擅长从图像标题中提取语义信息,但用于渲染的文本的语义内容通常是最小的,这妨碍了有效的指导文本生成的能力。将文本语义信息编码到文本嵌入中的方法有OCR和ByT5.


3.4 Regional Perceptual loss
采用额外的文本感知损失(text perceptual loss)与RF loss结合,以提高文本字形的质量。然而对于文本编辑任务,原始文本感知损失往往会被稀释,因为图像中许多区域保持不变,为了解决这个问题,



4.Experiments
4.1 Implementations

4.2 Training Dataset
利用了AnyWord-3M数据集,多语言数据集,整合了多个数据,包括wukong(中文),Laion(英文),以及一些专门为ocr设计的数据,包括丰富的文本场景,例如城市风景、书籍封面、广告海报和电影画面,该数据集大概有3M图像,其中语言分布约为1.6M张包含中文文本,1.39M中包含英文文本,以及额外的10K张展示其他语言的文本,为了训练fluxtext,我们从AnyWord-3M中提取了一个小型数据集,包含100K图像,其中50K中文,50K英文。
4.3 Testing Dataset and Evaluation Metrics
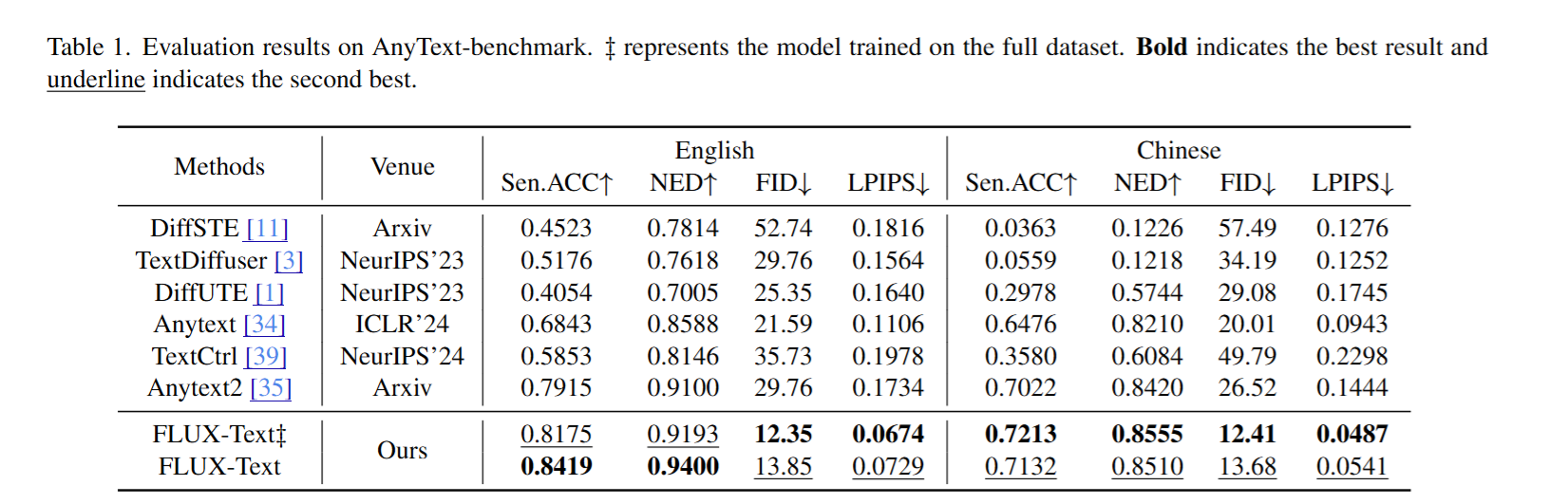
利用AnyText-benchmark作为我们的测评数据集,该数据从Wukong和Laion子集中随机选择的1000张图像组成。分别针对中英文的效果做了定制。
采用了四个不同的指标从内容和风格的角度来衡量文本生成性能,


4.4 Comparsion Results
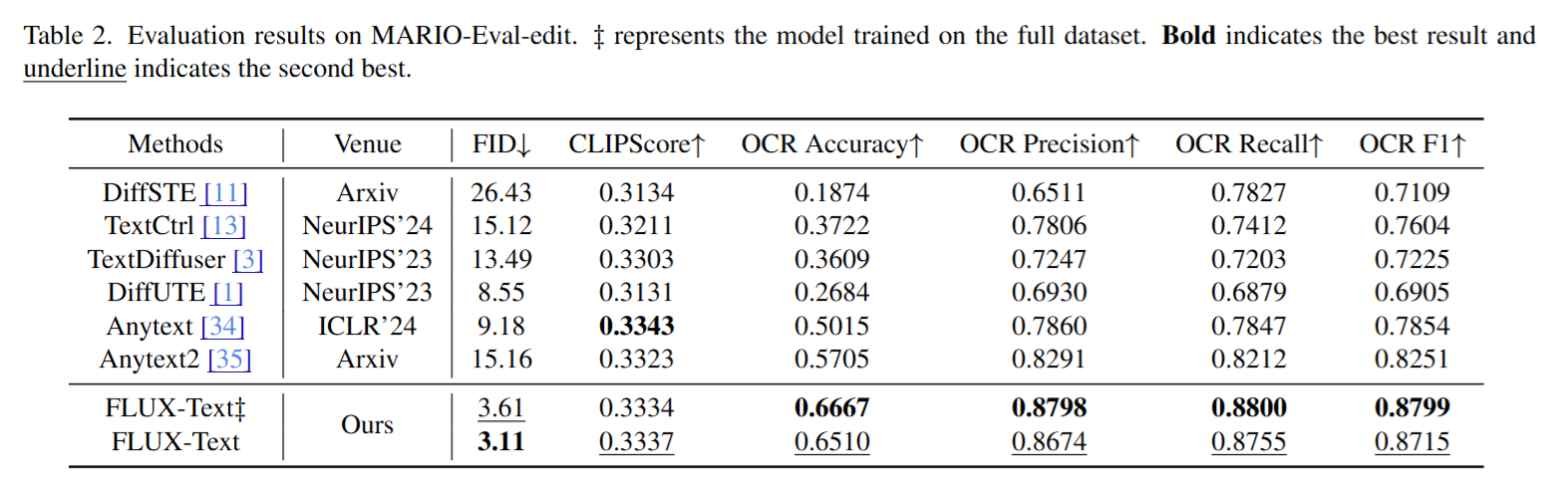
定量测评包括了AnyText-benchmark和MARIO-Eval-edit。


4.5 Ablation study
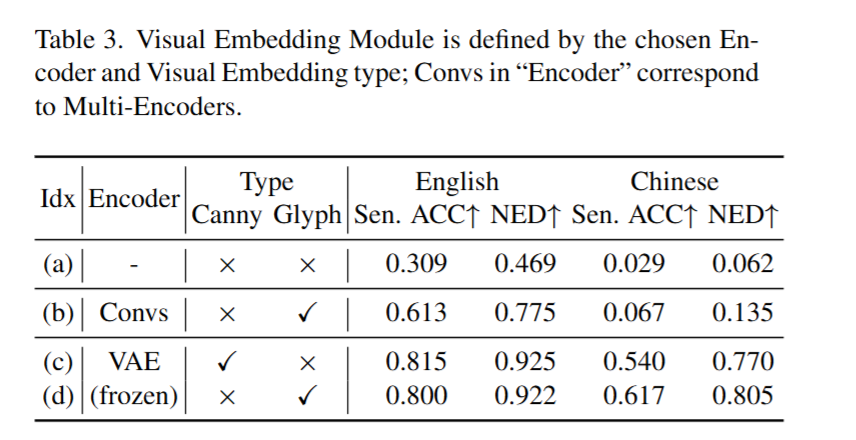
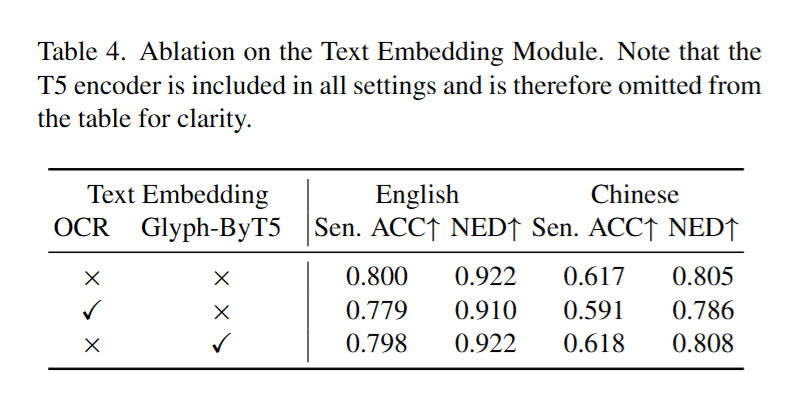
所有的消融研究均在AnyText-benchmark上进行,为了公平起见,每个设置都训练了15k迭代。
Visual embedding: 选择了冻结的VAE;

Text embedding

Perceptual loss

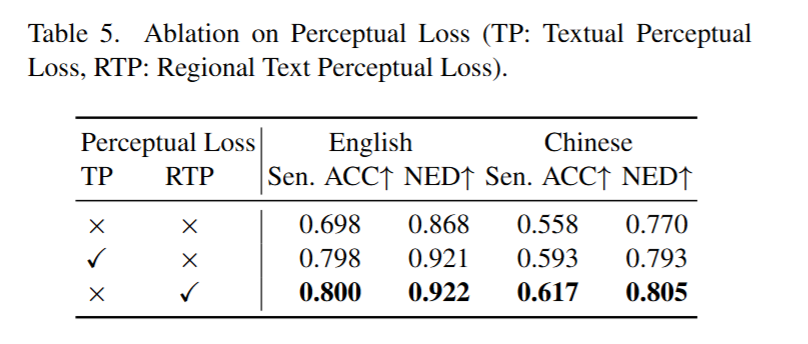
Two-stage Traininf strategy


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)