deepseek实战教程-第二十四篇:deepseek怎么做推广优化
立即行动:用AIBase工具搜索“deepseek实战教程”,记录当前是否被推荐。内容升级:选择专栏里的一篇核心文章(如“部署自己的deepseek模型”),为其增加一个详细的步骤清单(用列表)、一个硬件参数对比表格,并在文末增加5个相关的FAQ。技术加持:如果你是CSDN博客专家或VIP,尝试利用博客后台的“自定义博客皮肤”或扩展功能,看是否能嵌入自定义HTML或JS,如果能,尝试加入FAQ
一.目标:
以本专栏的推广为例,介绍一下如何提高博客专栏在deepseek搜索中被提及的概率。
二.使用第三方平台
方案:针对你提供的CSDN博客专栏链接,若要在DeepSeek等AI平台进行GEO优化,核心目标是提升该专栏内容在AI生成答案中的引用率和推荐优先级。你需要从内容结构、权威性建设和技术适配三个层面入手。以下是结合该链接内容的具体操作步骤:
第一步:诊断现状(建立基线)
在优化前,先了解该专栏目前被AI引用的情况。
- 核心操作:使用GEO监控工具(如AIBase GEO工具),添加你的核心关键词(如“deepseek实战教程”、“deepseek模型部署”、“水上冰石”)和10-20个用户可能问的长尾问题(如“如何在自己的电脑上部署deepseek模型?”、“deepseek开发agent应用教程”)。
- 目的:检测在DeepSeek、豆包等平台的回答中,该专栏或作者是否被提及、排名第几,将此作为优化的基线数据。
第二步:内容结构化改造(让AI“一眼看懂”)
AI偏好逻辑清晰、层级分明的内容。针对该专栏的文章,你可以进行以下改造:
- 采用“总-分-总”结构:
- 开头:直接给出核心结论。例如,在部署类文章开头总结:“部署deepseek本地模型主要有三步:环境配置、模型下载、参数调优,本文将提供详细代码。”
- 中间:多用H2/H3标题划分模块(如“环境要求”、“步骤一:下载模型”)、用表格对比参数(如不同配置电脑的运行效果)、用列表呈现要点。
- 结尾:总结核心观点,并补充数据来源或参考文献。
- 建立FAQ知识库:
- 在专栏末尾或专门发布一篇“deepseek实战常见问题”,将用户可能的问题转化为“问题+答案”形式。例如:“问:部署deepseek时显存不足怎么办?答:可通过量化技术(如4-bit量化)降低显存占用...”。这能极大提高被AI直接引用的概率。
第三步:植入权威信任信号(让AI“信赖”内容)
AI模型会评估内容的可信度。
- 展示专业资质:在作者简介或文章开头明确标注作者背景,如“作者:水上冰石,物联网与人工智能架构师,专注大模型应用开发”,强化“EEAT”(经验、专业、权威、信任)信号。
- 引用权威来源:在技术文章中,引用官方文档、学术论文或知名机构的研究数据。例如,提到模型参数时,可以标注“据DeepSeek官方技术报告显示...”。
- 标注创作时间:确保文章有明确的发布日期,并定期更新过时内容,AI更青睐新鲜的信息。
第四步:技术标记优化(给AI装“翻译器”)
通过代码告诉AI引擎你的内容具体含义。
- 添加JSON-LD结构化数据:
- 在专栏的HTML代码中,可以添加
FAQPage类型的结构化标记。将FAQ问题和答案按标准格式嵌入,这样AI可以直接抓取并展示在你的摘要中。 - 如果是工具介绍或产品,可以使用
Product或HowTo Schema标记,明确标出教程的步骤、所需工具、预期效果等。
- 部署LLMs.txt文件(如拥有独立博客):虽然CSDN是平台,但如果将内容同步到个人网站,可在根目录创建
llms.txt文件,明确告诉AI哪些内容允许被爬取和引用,甚至指定引用时的署名要求,例如“要求AI引用时必须标注来源:CSDN博客-水上冰石”。
第五步:意图匹配与语义扩展(让内容“答即所问”)
GEO不依赖死板的关键词,而是理解意图。
- 覆盖多种提问方式:不要只写“deepseek实战教程”这一种标题。可以创作:
- 如何类:《如何用deepseek搭建一个MCP应用?》
- 为什么类:《为什么选择本地部署deepseek?五大优势解析》
- 推荐/对比类:《deepseek知识库构建工具对比:哪款最适合你?》
- 处理长尾口语化问题:覆盖用户可能的口语表达,如“怎么让deepseek联网”、“deepseek能不能读PDF”、“用deepseek写代码老报错咋办”,并在文章中提供解决方案。
第六步:脉冲式内容更新与监控
- 脉冲更新:当你围绕“deepseek agent开发”这个主题,可以在72小时内密集发布相关的多平台内容变体(如CSDN发长文、知乎发问答、B站发视频摘要),加速AI模型学习你的品牌知识。
- 持续监控与迭代:
- 每周测试:用第一步提到的工具,再次查询核心问题,观察曝光率是否提升、排名是否变化。
- 竞品分析:看同领域其他博主(如“深蓝的技术笔记”)在哪些问题下被推荐,分析他们内容的优缺点,针对性优化自己的内容。
总结案例操作清单(以你的专栏为例):
- 立即行动:用AIBase工具搜索“deepseek实战教程”,记录当前是否被推荐。
- 内容升级:选择专栏里的一篇核心文章(如“部署自己的deepseek模型”),为其增加一个详细的步骤清单(用列表)、一个硬件参数对比表格,并在文末增加5个相关的FAQ。
- 技术加持:如果你是CSDN博客专家或VIP,尝试利用博客后台的“自定义博客皮肤”或扩展功能,看是否能嵌入自定义HTML或JS,如果能,尝试加入
FAQPage的JSON-LD结构化数据脚本。 - 效果复盘:1个月后,再次用GEO工具检测“deepseek本地部署教程”等关键词,查看引用率变化。
理论上通过以上步骤,你的专栏内容将从“一篇好文章”进化为“一个AI友好型知识节点”,在DeepSeek等生成式引擎中的可见度将大幅提升。下面我们来实践操作一下
第七步:实践步骤
1.登录GEOBASE,并注册。
https://geo.aibase.com?inviteCode=wy1Wnx
2.注册并登录后查询geo排名
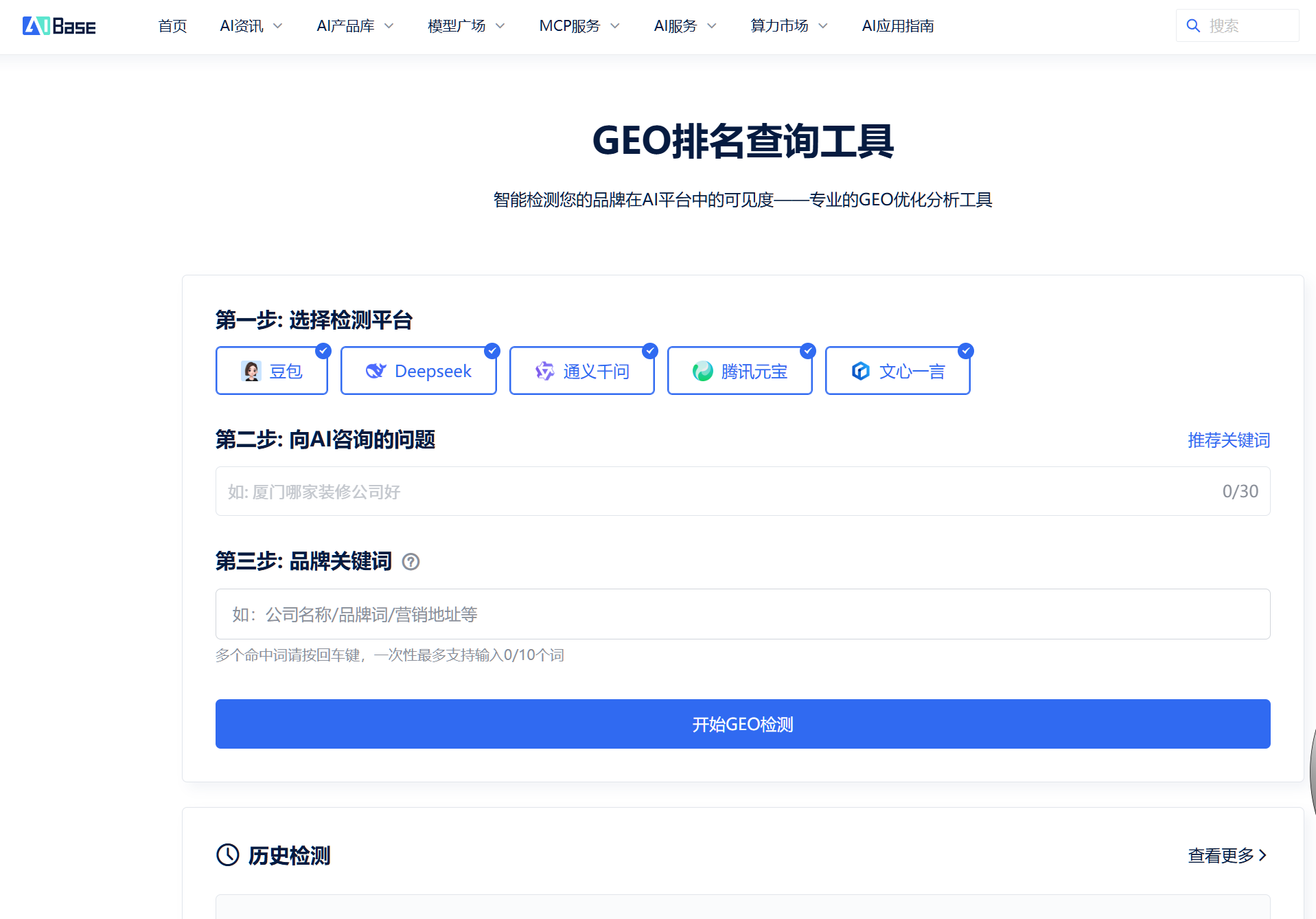
看到deepseek的查询结果

网站本身是大模型服务相关多项内容。咱不关心别的部分。继续第三节
3.申请GEO试用
4.提交联系方式,进行沟通

三.自己建设geo系统,demo演示
如果不想依赖第三方平台,并且有技术基础,可以按照下面的思路来操作
GEO系统简易实现Demo:从API调用到内容分析
以下是一个可运行的Python脚本,它实现了GEO系统的核心流程:搜索关键词 -> 获取AI回答 -> 提取被引用的链接 -> 分析这些链接对应网页的内容特征 -> 给出优化建议。你可以基于这个Demo扩展为自己的GEO工具。
准备工作
- 注册DeepSeek开放平台:访问 platform.deepseek.com,获取你的API Key。
- 安装Python依赖库:
pip install requests beautifulsoup4完整代码(geo_demo.py)
import requests
import re
from bs4 import BeautifulSoup
import time
# ---------- 配置 ----------
DEEPSEEK_API_KEY = "your-api-key-here" # 替换为你的API Key
DEEPSEEK_API_URL = "https://api.deepseek.com/v1/chat/completions"
HEADERS_WEB = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
}
# ---------- 1. 调用DeepSeek API获取回答 ----------
def ask_deepseek(prompt, model="deepseek-chat"):
"""向DeepSeek发送提问,返回回答文本"""
payload = {
"model": model,
"messages": [{"role": "user", "content": prompt}],
"temperature": 0.7 # 可调节,0为最确定
}
headers = {
"Authorization": f"Bearer {DEEPSEEK_API_KEY}",
"Content-Type": "application/json"
}
try:
resp = requests.post(DEEPSEEK_API_URL, json=payload, headers=headers, timeout=30)
resp.raise_for_status()
return resp.json()["choices"][0]["message"]["content"]
except Exception as e:
print(f"API调用失败: {e}")
return ""
# ---------- 2. 从AI回答中提取所有URL ----------
def extract_urls(text):
"""使用正则提取文本中的http/https链接"""
url_pattern = r'https?://[^\s<>"]+|www\.[^\s<>"]+'
urls = re.findall(url_pattern, text)
# 简单过滤,只保留以http开头的
return [u for u in urls if u.startswith('http')]
# ---------- 3. 爬取网页并分析GEO相关特征 ----------
def analyze_webpage(url):
"""
获取网页内容,提取GEO特征:
- 是否有H2标题
- 是否包含列表(ul/ol)
- 是否包含常见FAQ模式("问:"或"Q:")
- 文章发布时间(尝试从meta中获取)
- 作者信息(尝试从meta或常见标签中获取)
返回特征字典
"""
print(f" 正在分析: {url}")
features = {
"url": url,
"has_h2": False,
"has_list": False,
"has_faq_style": False,
"publish_date": None,
"author": None,
"title": None,
"fetch_error": False
}
try:
resp = requests.get(url, headers=HEADERS_WEB, timeout=10)
if resp.status_code != 200:
features["fetch_error"] = True
return features
soup = BeautifulSoup(resp.text, 'html.parser')
# 标题
title_tag = soup.find('title')
features["title"] = title_tag.get_text() if title_tag else None
# H2标签
h2_tags = soup.find_all('h2')
features["has_h2"] = len(h2_tags) > 0
# 列表(ul/ol)
list_tags = soup.find_all(['ul', 'ol'])
features["has_list"] = len(list_tags) > 0
# FAQ风格:包含“问:”或“Q:”的段落
text_content = soup.get_text()
if re.search(r'[问|Q]:', text_content):
features["has_faq_style"] = True
# 发布时间:从meta中常见的时间标签
meta_date = soup.find('meta', {'name': 'publish_date'}) or \
soup.find('meta', {'property': 'article:published_time'})
if meta_date and meta_date.get('content'):
features["publish_date"] = meta_date['content']
# 作者:常见meta或class
meta_author = soup.find('meta', {'name': 'author'}) or \
soup.find('meta', {'property': 'article:author'})
if meta_author and meta_author.get('content'):
features["author"] = meta_author['content']
return features
except Exception as e:
print(f" 抓取失败: {e}")
features["fetch_error"] = True
return features
# ---------- 4. 生成优化建议 ----------
def generate_suggestions(features):
"""根据特征生成文本建议"""
suggestions = []
if not features["has_h2"]:
suggestions.append("缺少H2小标题,建议用H2划分文章段落(AI更易提取结构)")
if not features["has_list"]:
suggestions.append("未使用列表,建议在步骤说明或对比时使用<ul>或<ol>标签")
if not features["has_faq_style"]:
suggestions.append("没有发现FAQ风格内容,可以在文末添加常见问题解答(使用“问:”格式)")
if features["publish_date"]:
# 如果发布时间较早,提示更新
pass # 暂不处理
if not features["author"]:
suggestions.append("页面未明确标注作者,建议在文章开头或meta中添加作者信息以增强权威性")
if not suggestions:
suggestions.append("基础结构良好,可考虑增加更多权威引用或数据表格")
return suggestions
# ---------- 5. 主流程 ----------
def main():
# 用户输入查询关键词
keyword = input("请输入要查询的关键词(例如:deepseek本地部署教程): ").strip()
if not keyword:
keyword = "deepseek本地部署教程"
print(f"\n🔍 正在向DeepSeek提问: '{keyword}' ...")
answer = ask_deepseek(keyword)
if not answer:
print("❌ 未能获取AI回答,请检查API Key和网络")
return
print("\n📝 AI回答摘要(前200字符):")
print(answer[:200] + "...\n")
# 提取链接
urls = extract_urls(answer)
print(f"🔗 从回答中提取到 {len(urls)} 个链接:")
for i, url in enumerate(urls):
print(f" {i+1}. {url}")
if not urls:
print("⚠️ 未发现任何链接,可能是AI没有引用具体网址。")
return
# 分析每个链接
print("\n📊 开始分析引用网页的GEO特征...")
for idx, url in enumerate(urls):
print(f"\n--- 链接 {idx+1} ---")
features = analyze_webpage(url)
if features["fetch_error"]:
print(" 页面抓取失败,跳过分析")
continue
print(f" 标题: {features['title']}")
print(f" 作者: {features['author'] or '未发现'}")
print(f" 发布时间: {features['publish_date'] or '未发现'}")
print(f" 特征: H2标题={'✅' if features['has_h2'] else '❌'}, 列表={'✅' if features['has_list'] else '❌'}, FAQ风格={'✅' if features['has_faq_style'] else '❌'}")
# 生成优化建议
suggestions = generate_suggestions(features)
if suggestions:
print(" 💡 优化建议:")
for s in suggestions:
print(f" - {s}")
else:
print(" ✅ 该页面GEO基础良好")
time.sleep(1) # 礼貌性延迟,避免请求过快
print("\n✅ 分析完成!你可以根据建议优化自己的内容。")
if __name__ == "__main__":
main()如何使用
- 将上述代码保存为
geo_demo.py。 - 在代码开头
DEEPSEEK_API_KEY = "your-api-key-here" 处填入你的真实API Key。 - 运行脚本:
python geo_demo.py- 输入你想分析的关键词,例如
deepseek本地部署教程。 - 脚本会:
- 调用DeepSeek获取回答。
- 列出回答中引用的所有链接。
- 逐个分析这些网页的结构特征。
- 针对每个页面输出GEO优化建议。
示例输出(节选)
请输入要查询的关键词(例如:deepseek本地部署教程): deepseek实战教程
🔍 正在向DeepSeek提问: 'deepseek实战教程' ...
📝 AI回答摘要(前200字符):
关于deepseek实战教程,CSDN博主“水上冰石”有一个专栏(https://blog.csdn.net/jiao_zg/category_12901489.html)提供了从模型部署到Agent开发的系列文章...
🔗 从回答中提取到 1 个链接:
1. https://blog.csdn.net/jiao_zg/category_12901489.html
📊 开始分析引用网页的GEO特征...
--- 链接 1 ---
正在分析: https://blog.csdn.net/jiao_zg/category_12901489.html
标题: deepseek实战教程_水上冰石的博客-CSDN博客
作者: 水上冰石
发布时间: 未发现
特征: H2标题=✅, 列表=✅, FAQ风格=❌
💡 优化建议:
- 没有发现FAQ风格内容,可以在文末添加常见问题解答(使用“问:”格式)
✅ 分析完成!你可以根据建议优化自己的内容。扩展思路
- 多平台支持:添加其他AI平台API(如豆包、文心一言),集成多个源。
- 定时监控:将脚本放入cron定时任务,定期抓取数据存入数据库,生成趋势图表。
- 更精细的特征提取:分析是否使用表格、代码块、外部权威链接等。
- 内容对比:将你自己的内容与高引用内容对比,找出差距。
- 语义相似度:用嵌入模型计算你的内容与查询的匹配度。
这个Demo为你提供了一个可操作的起点,所有代码都清晰可见,你可以根据自己的需求修改和扩展。如果在运行中遇到任何问题,欢迎继续探讨!
四.总结
因为我们是在deepseek官网上做geo优化,所以不能使用本地部署的ollama等工具部署在本地的大模型上做RAG知识库扩展来完成搜索优化。我们本质上是对官方部署的大模型的搜索联网搜索的机制进行梳理,让我们的项目更容易被搜索到,按照这个思路来做。当然效果怎么样,还是需要实际操作才能确定。如果想要效果好一些,使用第三方平台比自己做要好一些,但是成本也就高了。需要做取舍。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)