常见二进制漏洞原理及分析
当用户输入一个负数,会将这个负数的补码存在内存中,当使用时,会直接将补码当做超大正数,首先绕过检测,然后进行read函数时发生溢出。上面的代码就是可能触发UAF漏洞的高危代码,程序首先定义一个新类型Person,然后定义了创建该类型的函数,main函数中创建后使用,然后释放,但是释放后未将指针置空,造成野指针。上图的日志写入函数中,想将用户输入进行拼接,然后输出,但是printf()函数有两个特殊
本文将介绍常见二进制漏洞类型及避免方法。
一.虚拟内存的布局
Linux中进程使用虚拟内存,再由MMU转换成物理内存,其虚拟内存布局如下,其中堆区向高 地址生长,栈区向低地址生长,且代码段和rodata段为只读属性。
| 栈区 (高地址) |
| 共享库 / 内存映射区(mmap 区) |
| 堆区 |
| 数据段(.data/.rodata/.bss) |
| 代码段(.text) (低地址) |
二.常见漏洞类型
1.缓冲区溢出漏洞
由于用户输入时,未进行长度校验,导致用户输入长度超过缓冲区长度,因而覆盖其他内存
int main() {
char buffer[16];
printf("please input");
read(0, buffer, 100);//这里有明显的溢出
printf("your content:%s\n", buffer);
return 0;
}上面的代码中read的长度明显超过buffer的长度,会造成栈溢出。同理当使用malloc()申请堆内存时,就会造成堆溢出。所以在开发中,尽量避免使用gets(),strcpy(),read()等危险函数,同时要对用户输入进行长度校验。
2.整形漏洞
由于对整数的取值范围,符号,隐式类型转换的忽略,导致的安全问题。
void check_length(int input_len) {
unsigned int safe_len = input_len;//触发漏洞
if (input_len <= 16) {
char buffer[16];
printf("input:");
read(0, buffer, input_len);
printf("content:%s\n", buffer);
} else {
printf("overflow\n");
}
}上图输入长度校验函数中,因为int类型默认为有符号,将int类型的input_len转化为无符号的int类型,就会产生问题。当用户输入一个负数,会将这个负数的补码存在内存中,当使用时,会直接将补码当做超大正数,首先绕过检测,然后进行read函数时发生溢出。
3.格式化字符串漏洞
格式化字符串漏洞是指用户输入中含有格式化字符换,导致的printf()函数被错误执行。
void log_write(const char* user_input) {
char log_buf[256];
strcpy(log_buf, "用户操作:");
strcat(log_buf, user_input);
printf(log_buf);//触发漏洞
printf("\n");
}上图的日志写入函数中,想将用户输入进行拼接,然后输出,但是printf()函数有两个特殊的格式化字符串,%p可以输出地址,%n可以向内存写入数据,这样就会导致地址泄露相关问题。
4.指针相关漏洞
下面一种典型的可能触发Use after free漏洞代码例子,主要由于free()函数触发。
typedef struct {
int id;
char* name;
} Person;
Person* create_Person(int id, const char* name) {
Person* p = (Person*)malloc(sizeof(Person));
p->id = id;
p->name = (char*)malloc(strlen(name) + 1);
strcpy(p->name, name);
return p;
}
int main() {
Person* person = create_Person(1001, "ZhangSan");
printf("ID=%d, Name=%s\n", person->id, person->name);
free(person->name);
free(person);
return 0;
}上面的代码就是可能触发UAF漏洞的高危代码,程序首先定义一个新类型Person,然后定义了创建该类型的函数,main函数中创建后使用,然后释放,但是释放后未将指针置空,造成野指针。
如果下面的代码出现再次使用这个指针的时候,就会触发漏洞。
下面则是空指针解引用漏洞的典型例子。
struct data{
int id;
int value;
};
int main(){
struct data* p = NULL;
p = (struct data*)malloc(sizeof(struct data));
p->id = 1;
p->value = 100;
free(p);
p = NULL;
return 0;
}这段代码中使用的p指针进行对data对象的处理,但是其实我们并不知道p指针是否创建成功。
所以必须要对p指针进行是否为NULL的判断
if(p == NULL){
return 1;
}5.多线程相关程序漏洞
主要是由于程序使用了多线程,但是多线程同时访问了同一个内存或文件,从而造成竞争。
int count = 0;
void* task(void* arg){
int i;
for(int i = 0; i < 1000000; i++){
count++;
}
return NULL;
}
int main(){
pthread_t t[10];
for(int i=0;i<10;i++){
pthread_create(&t[i],NULL,task,NULL);
}
for(int i=0;i<10;i++){
pthread_join(t[i],NULL);
}
printf("count = %d\n",count);
return 0;
}上面这段程序中就是点典型的动态竞争漏洞,程序中开启了十个线程同时给count变量进行自增的任务,但是并没有加锁,导致会出现两个线程同时对count做操作,造成结果错误。
5.类型混淆漏洞
由于强制类型转换导致的内存作物修改,致使数据出错。
class father {
public:
virtual void func1() { std::cout << "father" << std::endl; }
int a;
};
class childA : public father {
public:
void func1() override { std::cout << "child1" << std::endl; }
int b;
};
class childB : public father {
public:
void func1() override { std::cout << "child2" << std::endl; }
int c;
};
int main() {
childA* Ap = new childA();
Ap->b = 10;
childB* Bp = (childB*)Ap;
Bp->c = 20;
std::cout<<Ap->b<<std::endl;
return 0;
}这个就是一个类型混淆的基本实例,由于强制将chiildA类型转化为childB类型,导致程序按照childB的方式解析childA的内存布局了,导致修改出错。
三.常见防范手段
1.缓冲区溢出防护手段主要有内存地址随机化(PIE),Canary,以及NX等,可以使用下面命令查看
checksec ./your_program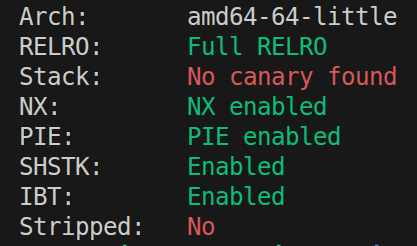
如图,就是开启了PIE和NX,但是没有开启canary保护,栈保护较弱。
Canary就是一个标志位,如果栈被篡改,标志位也会被篡改,就可以发现栈溢出问题。NX就是让栈上的数据不可执行,PIE 是让整个程序的基地址(包括代码段、数据段、栈、堆)随机化,从而大幅增加 offset的计算难度。
2.对于由于多线程造成的漏洞,可以采用加互斥锁或这个改用原子操作。
互斥锁常用函数主要有三个,初始化锁,上锁和开锁
//初始化锁
int pthread_mutex_init(pthread_mutex_t *restrict mutex,
const pthread_mutexattr_t *restrict attr);
//上锁
int pthread_mutex_lock(pthread_mutex_t *mutex);
//开锁
int pthread_mutex_unlock(pthread_mutex_t *mutex);进入任务函数时,要上锁防止其他线程竞争,同时完成任务时也要开锁,让其他线程继续使用。
同时也可以使用原子操作,原子操作就是将好几步完成的事,强制一步干完了,使得CPU不能打断,其性能高于互斥锁,但是操作比较简单。常用数据结构如下。
atomic_int a = 0; // 原子int
atomic_short b = 0; // 原子short
atomic_long b = 0; // 原子long
atomic_char c = 'x'; // 原子char常见函数及示例如下
1.原子读取:返回原子变量count的当前值给val
int val = atomic_load(&count);//示例2.原子赋值:把 val 写入原子变量
atomic_store(&count, 0);3.原子加操作
atomic_fetch_add(&count, 1); // count++4.原子减操作
atomic_fetch_and(&flag, 0x01);// count-=25.比较并交换
atomic_compare_exchange_strong(&a,&b,c)
//当a == b,将a改成c,返回true
//当a != b,将b改成a,返回false以上是一些常用二进制漏洞以及一些预防方式,同时这些只是基础原理,真实漏洞会更加复杂。
本人新手,如有错误,欢迎各位大佬指点。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)