别再被“AI幻觉“骗了!一文看懂RAG,给大模型装上最强“外挂大脑”,秒懂原理!
RAG(检索增强生成)是大模型解决知识滞后和幻觉问题的关键技术。它通过三个核心步骤实现:离线阶段将知识库切分并向量化存储;检索阶段根据问题查找相关片段;生成阶段结合检索结果输出可靠答案。相比微调,RAG具有成本低、可追溯、数据安全等优势,并正向智能体RAG演进,具备自主迭代能力。目前RAG有无代码平台、开发者框架、云端服务和开源方案四种实现路径,企业可根据需求选择。掌握RAG技术已成为AI工程师的
别再被“AI幻觉”骗了!一文看懂RAG:给大模型挂上最强“外挂大脑”
你是否有过这样的经历:问大模型(LLM)一个最新的新闻,或者你们公司的内部制度,它要么一本正经地胡说八道(幻觉),要么委婉地告诉你它的知识库只更新到2023年。这就是大模型的“先天缺陷”:**知识滞后且不可靠。**
为了解决这个问题, **RAG(Retrieval-Augmented Generation,检索增强生成)油然而生**。科技巨头一致认为,这是大模型走向实用的必经之路。今天,我们用最通俗的语言,带你彻底搞懂这个“外挂大脑”。
01
什么是RAG
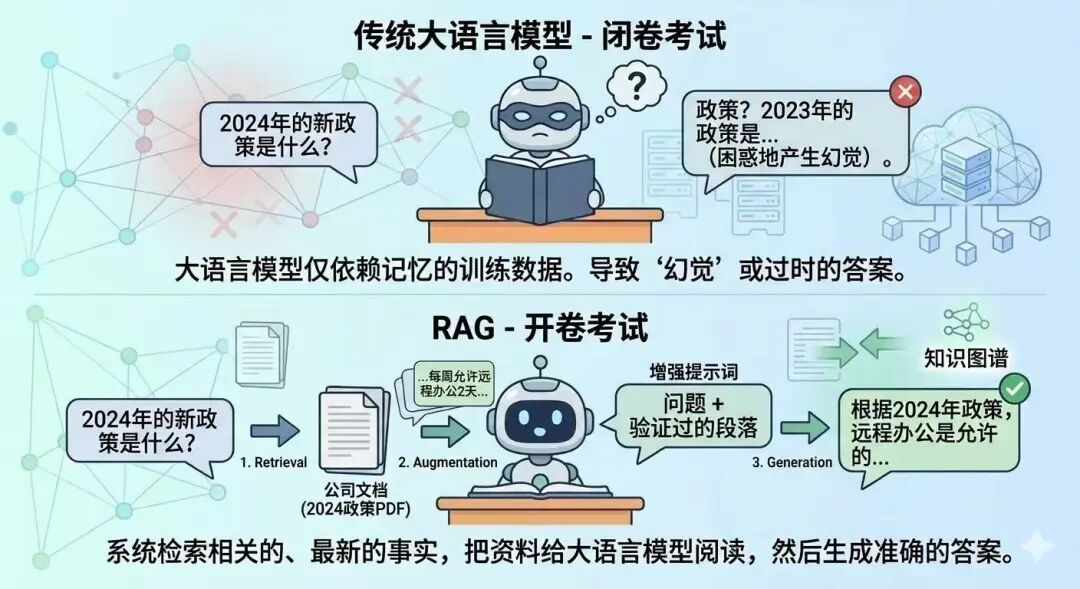
IBM Research 在其经典综述中提出了一个神级比喻,瞬间让所有人秒懂 RAG:过去的大模型,是在参加一场“闭卷考试”。它的知识全靠在预训练阶段死记硬背。如果你问它 2024 年的新政策,它的脑子里根本没这块数据,为了交卷,它只能根据概率强行拼凑答案,这就是“幻觉”的来源。而 RAG,是给大模型发了一本“参考书”,让它参加“开卷考试”。当你提出问题时,系统会先去海量的文档库里翻书,把最相关的段落找出来,贴在题目后面,然后递给大模型说:“答案就在这几段里,请根据这些资料回答。”
总结一下,RAG = 检索(找到对的资料)+ 增强(把资料喂给模型)+ 生成(写出标准答案)。
02
RAG三个核心环节
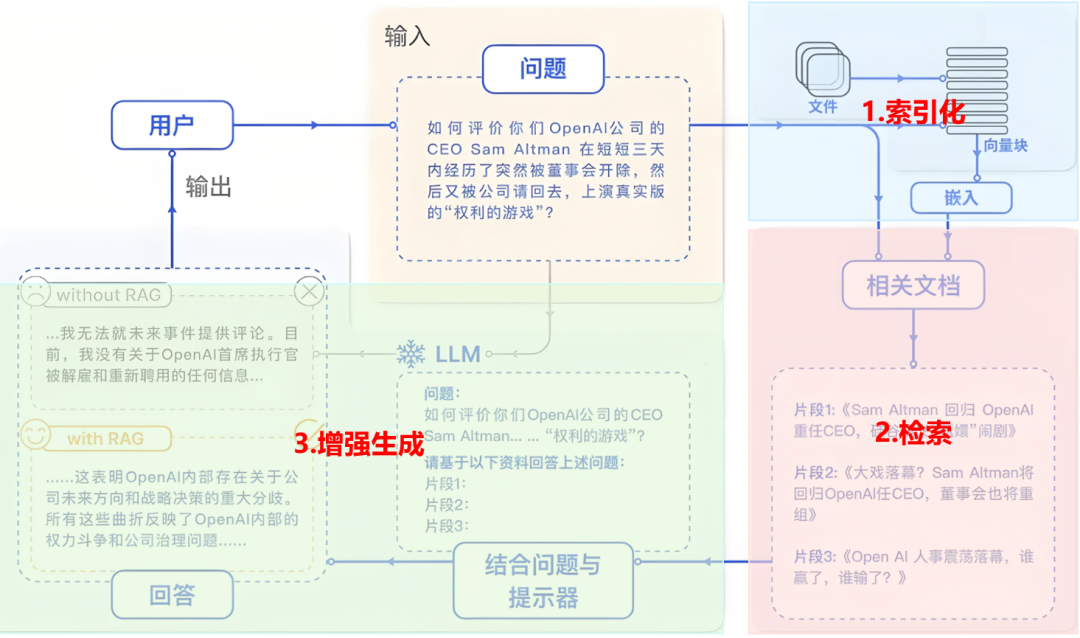
根据 NVIDIA 官方的技术博客,一套标准的 RAG 系统就像一个高效的图书管理员,分为三个关键步骤:
- 离线阶段(索引化):知识的“切碎”与“索引”
大模型没法一次性读完 100 万字的文档,所以我们要先做预处理:
- 文档切分(Chunking): 把长文档切成一个个 500 字左右的小方块。
- 向量化(Embedding): 这是最神奇的一步。利用算法把文字转换成成千上万个数字组成的“坐标”。
- 向量数据库: 把这些坐标存起来。语义相近的话,在坐标系里的距离就近。比如“苹果”和“梨”离得近,而“苹果”和“波音747”离得远。
- 检索阶段:精准的“大海捞针”
当你问“我们公司的报销流程是什么?”时,系统会把你的问题也转成向量坐标,去数据库里找最靠近的几个“知识方块”。
- 生成阶段:逻辑的“最后润色”
系统会将找回来的知识和你的原始问题组合在一起,形成一个新的指令(Prompt):
“已知信息:[知识方块 A + B + C]。问题:报销流程是什么?请严格基于已知信息回答。”
这样,AI 就不再信口开河,而是成了一个严谨的“复读机+分析师”。
03
RAG为什么比微调(Fine-tuning)更强
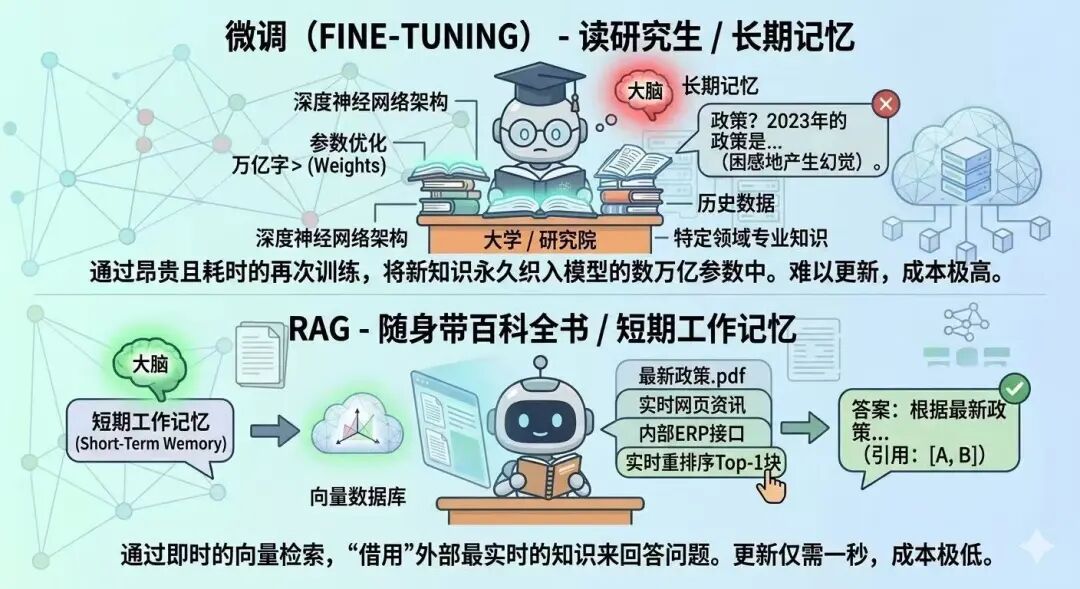
这个是长期记忆 vs 短期记忆的问题,很多人问:既然模型知识旧,我直接重新训练(微调)它不就行了吗? Linuxera 的深度博文给出了一个非常感性的解释:微调像“读研究生”,而 RAG 像“随身带百科全书”。
- 成本极低: 微调一次大模型可能要几万美金,耗时几天甚至几周;而 RAG 更新知识只需要往数据库里丢一个 PDF,几秒钟生效。
- 可追溯性(引用): 这是一个巨大的痛点。微调后的模型给出的答案你不知道是从哪来的;而 RAG 可以直接告诉你:“我的答案来自《2024员工手册》第15页”。
- 数据安全: RAG 可以设置权限。如果用户没权限看 A 文档,检索时直接跳过,这在企业级应用中是微调无法实现的。
04
RAG的未来从“搜索”进化到“智能体”
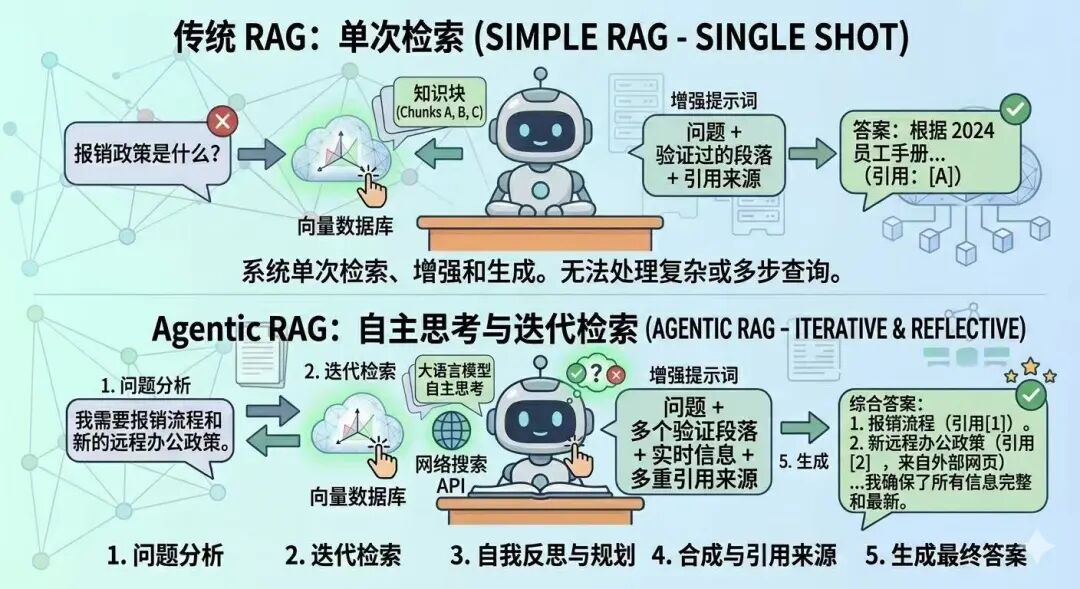
在 2026 年的今天,单纯的 RAG 已经不够用了。顶级开发者正转向 **Agentic RAG(智能体 RAG)**。
传统的 RAG 比较死板:搜一次,答一次。如果搜到的资料没用,AI 也就“摆烂”了。 而**智能体RAG**拥有“自主意识”:
-
它会先分析问题:这个问题需要搜几个关键词?
-
它会自我评价:搜回来的资料能回答问题吗?
-
如果不够,它会换个搜索词重新搜,甚至去查网页,直到找齐所有拼图。
这种“反思”和“迭代”的能力,让 RAG 真正具备了解决复杂业务问题的能力。
05
RAG 实现方式与选型决策矩阵
正如 老黄(NVIDIA 执行官)所言:“RAG 是连接通用人工智能与行业深度的桥梁。”对于企业和创作者来说,大模型是“引擎”,而 RAG 提供的私有知识库则是“燃料”。只有引擎没有燃料,AI 只是个会修辞的空壳;有了 RAG,它才真正变身成一个懂业务、懂专业、不撒谎的超级助手。如果你正在考虑将 AI 引入你的办公流程,或者想在 AI 浪潮中寻找商业机会,请记住:**大模型的上限由模型决定,但大模型的下限(好不好用)是由 RAG 决定的。**
- RAG 实现方式
无论你是只想提高办公效率的管理者,还是准备手撕代码的工程师,目前的 RAG 市场已经形成了四种主流实现路径:
| 实现方式 | 代表工具/平台 | 核心优势 | 适用人群 | 复杂度 |
|---|---|---|---|---|
| 无代码/低代码 | Dify, Coze (扣子), FastGPT | 鼠标拖拽、可视化工作流、自带前端,分钟级上线。 | 业务人员、产品经理、创业小团队 | ⭐ |
| 开发者框架 | LlamaIndex, LangChain | 极高灵活性,支持深度定制复杂的检索逻辑和 Agent。 | AI 开发者、后端工程师、极客 | ⭐⭐⭐⭐ |
| 云端一站式 | Azure AI Search, 百度千帆, 阿里百炼 | 企业级安全保障,省去运维烦恼,大厂背书稳定性高。 | 中大型企业、对数据合规要求高的行业 | ⭐⭐ |
| 开源解决方案 | MaxKB, RagFlow, AnythingLLM | 数据完全本地化,支持私有部署,完全掌控源码。 | 技术团队、隐私敏感型机构 | ⭐⭐⭐ |
- RAG 选型决策矩阵,根据实际需求,可参考以下决策路径:
| 你的身份/需求 | 推荐路径 | 核心建议 (避坑点) |
|---|---|---|
| 个人博主 / 自媒体 | Coze (扣子) / Dify 云端 | 避坑: 不要纠结底层架构。优先关注 Prompt 效果和多模态输出能力。 |
| 寻求就业的工程师 | LlamaIndex + Python | 避坑: 必须掌握 “重排序 (Rerank)” 和 “混合检索”,这是面试常考的进阶点。 |
| 企业内部知识库 | Dify 私有化 / MaxKB | 避坑: 别直接喂原始 PDF。必须先进行 “数据清洗”,剔除乱码和无意义的页眉页脚。 |
| 高并发商业应用 | 云端 API + 向量数据库 | 避坑: 关注 “Token 成本”。一定要做语义分块(Chunking),避免把整本书塞进 Prompt 浪费钱。 |
| 对隐私要求极高 | RagFlow + 本地 DeepSeek | 避坑: 硬件配置要够。本地跑 RAG 建议显存不低于 16GB,否则检索速度会让你崩溃。 |
附:以langchain实现RAG的核心代码
#使用Langchain 快速实现(伪代码)
from langchain_community.vectorstores
import Chromafrom langchain_openai import OpenAIEmbeddings
Huanz
#1.加载知识库
documents = load_documents("./企业知识库/")
#2.构建向量库
vectorstore = Chroma. from_documents (documents, OpenAIEmbeddings())
#3.检索增强问答
retriever = vectorstore.as_retriever()
qa_chain = RetrievalQA.from_chain_type(llm, retriever=retriever)
print(qa_chain.run("公司休假政策如何?"))
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。
接下来告诉你一条最快的邪修路线,
3个月即可成为模型大师,薪资直接起飞。
阶段1:大模型基础

阶段2:RAG应用开发工程

阶段3:大模型Agent应用架构

阶段4:大模型微调与私有化部署

配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇





配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献682条内容
已为社区贡献682条内容

所有评论(0)