CCF-CSP 37-4集体锻炼【C++】考点:数学(最大公因数gcd特性),常数优化
题目
TUOJ![]() https://sim.csp.thusaac.com/contest/37/problem/3
https://sim.csp.thusaac.com/contest/37/problem/3
思路参考:第37次CCF计算机软件能力测试-第四题_csp集体锻炼-CSDN博客![]() https://blog.csdn.net/Sioy2/article/details/148313669
https://blog.csdn.net/Sioy2/article/details/148313669
这题卡常了,大佬的代码亲测有3/32的测试点TLE
优化1:把创建vector放在遍历右端点的循环外,每次循环clear
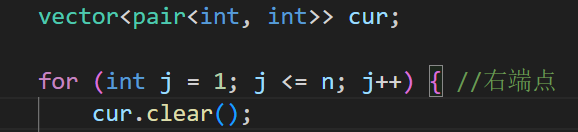
对此AI给出的解释是:
`cur.clear()` 仅将 vector 的大小置零,但保留已分配的内存(capacity),后续 `push_back` 可直接复用现有空间;而每次重新创建 vector 会频繁分配和释放内存,带来大量的堆操作开销,在循环次数多时差距尤其明显。
优化2:库函数__gcd比手写gcd快一点点(非必要,有了优化1,手写gcd也能拿满)
对此AI的解释是:
内置优化:__gcd 是编译器内置的函数,通常会针对特定的 CPU 架构进行底层优化(如利用硬件指令),不仅是简单的递归逻辑。
核心思路
大佬的思路写得很清晰且精炼,但是看懂代码还是要费一番功夫

gcd核心性质:
关键观察:
如果固定子数组的左端点 l,随着右端点 r 从 l 向右移动,子数组 [l,r] 的 GCD 是单调不增的(只会变小或不变)
更重要的是,GCD 值最多只会变化 logn 次
原因:每次 GCD 变化时,至少会除以 2(或变成更小的约数),而一个数最多能被整除 log n 次
有同学看代码的时候可能会觉得这行很费解,为什么这样能work,在此简单解释一下
vector<pii>new_seg存的是gcd值相同的区间(gcd值,左端点),这个for循环每次取出的p,左端点是越来越小的,下一个区间的右侧下标=当前区间左侧下标-1
那为什么vec<pii>中左端点是越来越小的?
每次遍历到新的右端点j
new_seg.clear();
new_seg.push_back({a[j],j});
每次都先加入pair.second最大的(表示[j,j]),天然地导致,左端点值最大的放在前面
觉得不好理解的,可以看一个简单的例子,6,4,2
new_seg 存储以当前位置为右端点、具有相同 GCD 值的区间(格式为 {gcd, 该区间最左端点})。
1. j = 1 (a[1] = 6)
new_seg 加入 {6, 1}。
区间:[1, 1] 的 GCD 是 6。
计算:sum_l = 1,ans = (1 * 1 * 6) = 6。
old_seg = {{6, 1}}。
2. j = 2 (a[2] = 4)
首先加入新点:new_seg = {{4, 2}}。
处理 old_seg:__gcd(6, 4) = 2。由于 2 != 4,加入新区间。
new_seg = {{4, 2}, {2, 1}}。
区间:
[2, 2] GCD 是 4:sum_l = 2,ans += 2 * 2 * 4 = 16。
[1, 1] GCD 是 2:sum_l = 1,ans += 1 * 2 * 2 = 4。
ans = 6 + 16 + 4 = 26。
old_seg = {{4, 2}, {2, 1}}。
3. j = 3 (a[3] = 2)
首先加入新点:new_seg = {{2, 3}}。
处理 old_seg:
__gcd(4, 2) = 2。与 new_seg 末尾 GCD 相同,合并左端点:new_seg = {{2, 2}}。
__gcd(2, 2) = 2。与 new_seg 末尾 GCD 相同,再次合并:new_seg = {{2, 1}}。
区间:
[1, 3] 的 GCD 全都是 2:sum_l = (1+2+3) = 6。
计算:ans += 6 * 3 * 2 = 36。
ans = 26 + 36 = 62。
代码
笔者给出的代码有很多注释(手敲的),变量名也尽量保证代码的可读性,如果还是不理解建议用一个简单的案例(如6,4,2)动笔模拟一下
可以让AI总结一下代码逻辑
算法目标
计算所有子数组的 gcd(子数组) × 左端点下标 × 右端点下标 之和(下标从1开始),结果对 998244353 取模。
核心思想
利用固定右端点时,随着左端点向左移动,区间 GCD 值单调不增且最多变化 O(log n) 次的性质,将连续相同 GCD 的左端点合并成段,批量计算贡献。
数据结构
-
old_seg:存储上一个右端点的区间信息,每个元素为(gcd值, 最左端点),按左端点从大到小排列 -
new_seg:存储当前右端点的区间信息,同样按左端点从大到小排列
主循环流程(右端点 j 从1到n)
1. 构建当前右端点的区间信息
-
先将当前元素
[j, j]作为一个新区间加入 -
遍历上一轮的每个旧区间,将其与当前元素求新 GCD
-
如果新 GCD 等于
new_seg中最后一个区间的 GCD,则合并(向左扩展左端点) -
否则作为新区间加入,保持 GCD 值递减
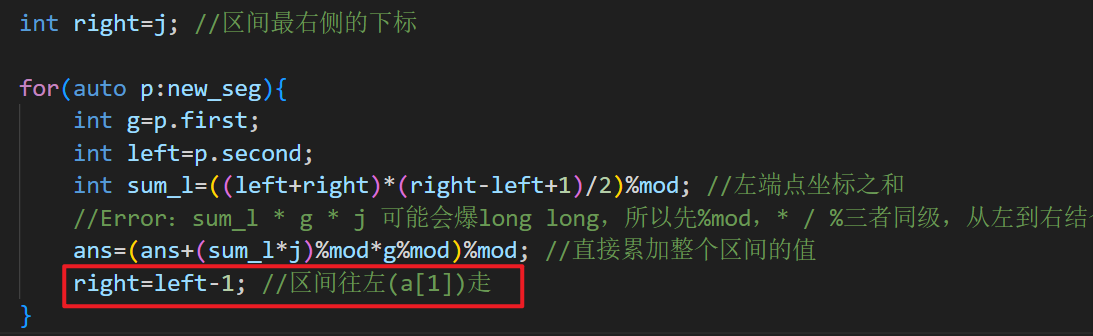
2. 计算当前右端点的贡献
-
从右向左遍历
new_seg中的每个区间 -
对于区间
(g, left),它表示左端点在[left, right]范围内的所有子数组 GCD 都等于 g -
用等差数列求和公式计算这些左端点的和
-
每个子数组的贡献 = g × 左端点 × 右端点 j,累加到答案
-
更新 right = left - 1,继续处理左边的区间
3. 准备下一轮
-
将
new_seg赋值给old_seg,继续下一个右端点
时间复杂度
O(n log n),每个右端点处理的区间段数量不超过 O(log n)
#include<bits/stdc++.h>
using namespace std;
#define endl '\n'
#define int long long
#define pii pair<int,int>
const int N=1e6+5, mod=998244353;
int a[N];
void solve(){
int n; cin>>n;
for(int i=1;i<=n;i++) cin>>a[i];
vector<pii>old_seg; //old_segments 存上一个右端点j的gcd值相同的区间(gcd值,左端点)
vector<pii>new_seg; //new_segments 存当前j的gcd值相同的区间
int ans=0; //最终结果 //warn:局部变量初始化
for(int j=1;j<=n;j++) {//右端点
new_seg.clear(); //比每次新定义一个vector时间开销小
new_seg.push_back({a[j],j});//天然地导致,左端点值最大的放在前面
for(auto p:old_seg){ //取出旧的区间,进行更新
int g=p.first; //gcd值
int left=p.second; //区间左端点
int new_gcd=__gcd(g,a[j]); //库函数比手写更快一点
if(new_gcd==new_seg.back().first) new_seg.back().second=left; //如果跟最后一个的gcd值相同,合并区间
else new_seg.push_back({new_gcd,left}); //gcd值不同,加入新的区间
}
int right=j; //区间最右侧的下标
for(auto p:new_seg){
int g=p.first;
int left=p.second;
int sum_l=((left+right)*(right-left+1)/2)%mod; //左端点坐标之和
//Error:sum_l * g * j 可能会爆long long,所以先%mod,* / %三者同级,从左到右结合
ans=(ans+(sum_l*j)%mod*g%mod)%mod; //直接累加整个区间的值
right=left-1; //区间往左(a[1])走
}
old_seg=new_seg; //warn:存下旧的区间
}
cout<<ans<<endl;
}
signed main(){
ios::sync_with_stdio(0),cin.tie(0);
solve();
return 0;
}

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 29
29 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)