卷积神经网络
真实的图片是 RGB 三彩的,而且我们不可能只找“猫耳”,我们还要找“猫眼”、“猫胡须”、“垂直边缘”、“水平边缘”。所以必须引入**通道(Channel)**的概念。值得注意的是,net.eval() 后,会关闭BatchNorm,net.train() 下,会打开 BatchNorm。,我们其实关心的是“它正上方的一个像素”、“它右下角的一个像素”,而不是“全图第 5 行第 10 列的像素”。
文章目录
一、从全连接到卷积
1.1 当你试图用MLP来处理图像
假设我们有一张 1000 x 1000 像素的高清猫咪照片,它是彩色的(RGB 3个通道),所以输入特征有 1000 × 1000 × 3 = 300 万 1000 \times 1000 \times 3 = 300万 1000×1000×3=300万 个维度。
如果我们用全连接层(多层感知机 MLP)来处理:
哪怕隐藏层只设置 1000 个神经元,这一层的权重参数量就会高达:3,000,000 (输入) × 1000 (输出) = 30亿 个参数!
后果:
- 内存不够:几张哪怕最顶级的显卡也存不下这么大的模型。
- 极其容易过拟合:模型太复杂了,它宁愿把你家猫的每一根毛死死记住,也学不会什么是“猫的通用特征”。
1.2 两大直觉
《寻找沃尔多》游戏画面
为了压缩参数,科学家从人类玩“找茬”或“寻找沃尔多”的游戏中获得了两个伟大的直觉(先验假设/归纳偏置):
1. 平移不变性 (Translation Invariance)
- 猫就是猫,不管它在图片的左上角还是右下角,它看起来都一样。
- 启发:我们不需要为“左上角的猫”和“右下角的猫”分别学习两套参数。我们可以打造一个**“通用的猫耳探测器”**,让它在整张图片上滑动扫描。
2. 局部性 (Locality)
- 为了认出这是一只猫的耳朵,我根本不需要看远在天边的像素(比如背景里的树叶)。我只需要看猫耳附近的那一小块区域就够了。
- 启发:神经元不需要连接全图的所有像素,它只需要连接一个很小的局部窗口(比如 3x3 像素)。
1.3 数学推导
1.3.1 回顾最简单的 1D 全连接层 (MLP)
假设我们处理的不是图片,而是一维的数据(比如房价预测的 5 个特征)。
- 输入是一个一维向量: x = [ x 1 , x 2 , x 3 , x 4 , x 5 ] \mathbf{x} = [x_1, x_2, x_3, x_4, x_5] x=[x1,x2,x3,x4,x5]
- 隐藏层的输出也是一个一维向量: h = [ h 1 , h 2 , h 3 ] \mathbf{h} = [h_1, h_2, h_3] h=[h1,h2,h3]
计算隐藏层的第 i i i 个神经元 h i h_i hi 的公式非常简单:
h i = b i + ∑ k W i , k ⋅ x k h_i = b_i + \sum_k W_{i, k} \cdot x_k hi=bi+k∑Wi,k⋅xk
- x k x_k xk 是输入的第 k k k 个数据点。
- W i , k W_{i, k} Wi,k 是连接“输入 k k k”和“输出 i i i”的权重。
- 把所有的输入 x k x_k xk 乘以它们各自的权重 W i , k W_{i, k} Wi,k,加起来,再加上一个偏置 b i b_i bi,就得到了 h i h_i hi。
1.3.2 把 1D 公式升级为 2D(处理图像)
现在,我们要处理的是图片。图片不是一维的线条,而是二维的矩阵。
- 输入图片是一个矩阵 X \mathbf{X} X。它的像素位置用行和列 ( k , l ) (k, l) (k,l) 来表示,即 [ X ] k , l [\mathbf{X}]_{k, l} [X]k,l。
- 隐藏层输出也是一个矩阵 H \mathbf{H} H(为了方便理解,假设输出矩阵和输入图片一样大)。它的像素位置用 ( i , j ) (i, j) (i,j) 来表示,即 [ H ] i , j [\mathbf{H}]_{i, j} [H]i,j。
所以,权重 W W W 不能是二维矩阵了,它必须升级成一个四维的超级张量(Tensor),我们叫它 W i , j , k , l \mathsf{W}_{i, j, k, l} Wi,j,k,l。
- W i , j , k , l \mathsf{W}_{i, j, k, l} Wi,j,k,l 的意思是:连接“输入图片位置 ( k , l ) (k, l) (k,l)”和“输出图片位置 ( i , j ) (i, j) (i,j)”的权重。
按照前面的逻辑,我们写出二维图片的 MLP 公式:
[ H ] i , j = [ U ] i , j + ∑ k ∑ l W i , j , k , l ⋅ [ X ] k , l [\mathbf{H}]_{i, j} = [\mathbf{U}]_{i, j} + \sum_k \sum_l \mathsf{W}_{i, j, k, l} \cdot [\mathbf{X}]_{k, l} [H]i,j=[U]i,j+k∑l∑Wi,j,k,l⋅[X]k,l
(注: [ U ] i , j [\mathbf{U}]_{i, j} [U]i,j 就是偏置项,对应上面的 b i b_i bi。)
1.3.3 从“绝对位置”到“相对偏移”
在看图片时,我们更关心的是相对坐标(偏移量)。
对于输出位置 ( i , j ) (i, j) (i,j),我们其实关心的是“它正上方的一个像素”、“它右下角的一个像素”,而不是“全图第 5 行第 10 列的像素”。
我们定义两个新变量:
- a a a:行偏移量(比如 a = − 1 a=-1 a=−1 代表上一行)
- b b b:列偏移量(比如 b = 1 b=1 b=1 代表右一列)
那么,输入图片的位置 ( k , l ) (k, l) (k,l),就可以改写为输出位置 ( i , j ) (i, j) (i,j) 加上偏移量:
- k = i + a k = i + a k=i+a
- l = j + b l = j + b l=j+b
原先的权重 W i , j , k , l \mathsf{W}_{i, j, k, l} Wi,j,k,l 可以写做 V i , j , a , b \mathsf{V}_{i, j, a, b} Vi,j,a,b。
公式变为:
[ H ] i , j = [ U ] i , j + ∑ a ∑ b V i , j , a , b ⋅ [ X ] i + a , j + b [\mathbf{H}]_{i, j} = [\mathbf{U}]_{i, j} + \sum_a \sum_b \mathsf{V}_{i, j, a, b} \cdot [\mathbf{X}]_{i+a, j+b} [H]i,j=[U]i,j+a∑b∑Vi,j,a,b⋅[X]i+a,j+b
注意:到这一步为止,数学上没有任何删减,它依然是一个拥有几十亿参数、庞大且笨重的全连接层(MLP)。只是写法变了。
1.3.4 两大直觉的优化
平移不变性 (Translation Invariance)
- 物理意义:不论你站在图片的哪个位置 ( i , j ) (i, j) (i,j) 去找猫耳,你往偏移方向 ( a , b ) (a, b) (a,b) 看去的“判定标准(权重)”应该是一模一样的。
- 数学操作:权重 V \mathsf{V} V 根本不需要关心当前的绝对位置 ( i , j ) (i, j) (i,j),所以下标i,j可以删去。
- V i , j , a , b \mathsf{V}_{i, j, a, b} Vi,j,a,b ,变成了只有偏移量的二维矩阵 V a , b \mathbf{V}_{a, b} Va,b。偏置 [ U ] i , j [\mathbf{U}]_{i, j} [U]i,j 也变成了一个常数 u u u。
公式变成了:
[ H ] i , j = u + ∑ a ∑ b V a , b ⋅ [ X ] i + a , j + b [\mathbf{H}]_{i, j} = u + \sum_a \sum_b \mathbf{V}_{a, b} \cdot [\mathbf{X}]_{i+a, j+b} [H]i,j=u+a∑b∑Va,b⋅[X]i+a,j+b
(即全图卷积,参数量从几十亿降到了几百万)
局部性 (Locality)
- 物理意义:为了判断某个点是不是猫耳,我只需要看它附近的一小圈就行了,不需要看偏移量 a , b a,b a,b 非常大的像素。
- 数学操作:限制偏移量 a a a 和 b b b 的范围,它们不能无限大,只能在一个很小的窗口 − Δ -\Delta −Δ 到 Δ \Delta Δ 之间取值(比如 Δ = 1 \Delta=1 Δ=1 时,就是一个 3 × 3 3 \times 3 3×3 的九宫格)。(即远处的权重强制规定为 0,直接不看了)
最终公式:
[ H ] i , j = u + ∑ a = − Δ Δ ∑ b = − Δ Δ V a , b ⋅ [ X ] i + a , j + b = u + V ∗ X , ∗ 是二维交叉运算操作子 [\mathbf{H}]_{i, j} = u + \sum_{a=-\Delta}^{\Delta} \sum_{b=-\Delta}^{\Delta} \mathbf{V}_{a, b} \cdot [\mathbf{X}]_{i+a, j+b} = u + V * X,*是二维交叉运算操作子 [H]i,j=u+a=−Δ∑Δb=−Δ∑ΔVa,b⋅[X]i+a,j+b=u+V∗X,∗是二维交叉运算操作子
- 参数V,u 均可以梯度下降
这就是**卷积神经网络(CNN)**的原理。
1.3.5 通道 (Channel)
真实的图片是 RGB 三彩的,而且我们不可能只找“猫耳”,我们还要找“猫眼”、“猫胡须”、“垂直边缘”、“水平边缘”。所以必须引入**通道(Channel)**的概念。
- 输入通道(Input Channels):RGB 图片有 3 个通道。所以我们的卷积核不能是薄薄的一片 2D 矩阵,必须是厚厚的 3D 积木(例如 3 × 3 × 3 3 \times 3 \times 3 3×3×3),和输入通道一样厚,一下把红绿蓝三个通道的信息都混合起来。
- 输出通道(Output Channels):如果我们想要提取 64 种不同的特征(64种探测器),我们就准备 64 个这种 3D 积木。算完之后,输出的隐藏层就会有 64 层厚(称为特征图 Feature Maps)。
最终卷积核变成了 4D 张量:[核高, 核宽, 输入通道数, 输出通道数]。
《DIVE INTO DEEP LEARNING》中的一些问题:
1. 假设局部区域 Δ = 0 \Delta = 0 Δ=0,证明卷积层为每组通道独立地实现一个全连接层。
- 当 Δ = 0 \Delta = 0 Δ=0 时,卷积核的大小是 1 × 1 1 \times 1 1×1。它不再看周围的像素,只盯着当前坐标 ( i , j ) (i,j) (i,j) 这一个点看。它做的事情,就是把这个点在不同通道(红绿蓝等)上的数值,乘以权重加起来。这在数学上完全等价于:把每个像素点看作一个独立的样本,对其通道维度做了一次普通的全连接层计算(多层感知机)。这就是著名的 1x1卷积,常用来做通道数的降维或升维。
2. 为什么平移不变性可能也不是好主意呢?
- 因为有些任务极其依赖绝对位置信息。
比如人脸识别:眼睛永远在上面,嘴巴永远在下面。如果你的网络彻底平移不变,它可能会认为“嘴巴长在额头上”的人也是正常人。
比如医学图像:肺部上半部分出现的阴影和下半部分的阴影,医学诊断可能完全不同。
(所以后来的 Vision Transformer (ViT) 会强行加入“位置编码”来弥补这个缺陷)。3. 当从图像边界像素获取隐藏表示时,我们需要思考哪些问题?
- 当 3x3 的卷积核滑到图像最边缘(比如左上角点)时,它的左边和上边已经没有像素了!
这会导致:1. 边缘信息丢失;2. 输出的图像尺寸会变小。
解决方案:我们需要在图像边缘人为地补一圈“假像素”(通常补 0),这个操作叫做 Padding(填充)。4. 描述一个类似的音频卷积层的架构。
- 图像是 2D 的(有高和宽),所以用 2D 卷积。而音频是一维的时间序列(一段声波)。所以音频卷积层应该是 1D 卷积(一维卷积)。它的卷积核是一个短线条,只沿着时间轴从左向右单向滑动,去捕捉局部的音频模式(比如某个音节)。
5. 卷积层也适合于文本数据吗?为什么?
- 非常适合! 文本和音频一样,也是一维的词序列。
- 满足局部性:几个相邻的词往往构成一个短语(N-gram,如“深度/学习”),理解短语只需要看这几个词,不需要看隔了 100 个词的句尾。
- 满足平移不变性:“太棒了”这个词汇,无论出现在句首还是句尾,表达的情感特征是相似的。
所以 1D-CNN 早期在文本分类(如情感分析)任务上大放异彩。6. 证明 f ∗ g = g ∗ f f * g = g * f f∗g=g∗f。
- 数学推导:
( f ∗ g ) ( i ) = ∑ a f ( a ) g ( i − a ) (f * g)(i) = \sum_a f(a) g(i-a) (f∗g)(i)=∑af(a)g(i−a)
设一个新的变量 k = i − a k = i - a k=i−a,那么 a = i − k a = i - k a=i−k。
由于求和域是无限的(或完整的),遍历所有的 a a a 就等同于遍历所有的 k k k。
代入得: ∑ k f ( i − k ) g ( k ) = ∑ k g ( k ) f ( i − k ) \sum_k f(i-k) g(k) = \sum_k g(k) f(i-k) ∑kf(i−k)g(k)=∑kg(k)f(i−k)
这正是 ( g ∗ f ) ( i ) (g * f)(i) (g∗f)(i) 的定义,证明完毕。(这也说明在数学上,信号和滤波器是谁卷谁都一样)。
1.4 卷积层代码实现
import torch
from torch import nn
from d2l import torch as d2l
二维交叉运算
- 值得注意的是,pytorch中,* 做的是 阿达玛乘积
def corr2d(X, K):
'''二维互相关运算'''
h, w = K.shape
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i: i + h, j: j + w] * K).sum()
return Y
class Conv2D(nn.Module):
def __init__(self, kernal_size):
super().__init__()
self.weight = nn.Parameter(torch.rand(kernal_size))
self.bias = nn.Parameter(torch.zeros(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias
手造一个小数据来检测物体边缘
X = torch.ones((6, 8))
X[:, 2: 6] = 0
X
输出
tensor([[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.]])
只能检测竖直边缘线的卷积核
K = torch.tensor([[1., -1.]])
K
输出:
tensor([[ 1., -1.]])
学习卷积核
conv2d = nn.Conv2d(1, 1, kernel_size = (1, 2), bias = False)
X = X.reshape((1, 1, 6, 8))
Y = Y.reshape((1, 1, 6, 7))
for i in range(10):
Y_hat = conv2d(X)
l = (Y_hat - Y)**2
conv2d.zero_grad()
l.sum().backward()
conv2d.weight.data[:] -= 3e-2 * conv2d.weight.grad
if (i + 1) % 2 == 0:
print(f'batch {i+1}, loss = {l.sum():.3f}')
输出:
batch 2, loss = 5.405
batch 4, loss = 1.545
batch 6, loss = 0.521
batch 8, loss = 0.194
batch 10, loss = 0.076
conv2d.weight.data.reshape((1, 2))
输出:
tensor([[ 0.9632, -1.0195]])
1.5 填充和步幅
1.5.1 动机
标准的卷积运算中,存在两个致命的痛点:
- 图像越卷越小:假设输入是 3 × 3 3\times3 3×3,卷积核是 2 × 2 2\times2 2×2,输出就变成了 2 × 2 2\times2 2×2。如果图像是 240 × 240 240\times240 240×240,经过 10 层 5 × 5 5\times5 5×5 的卷积后,就缩水成 200 × 200 200\times200 200×200 了。
- 边缘信息丢失:图像边缘的像素(比如左上角的点),卷积核只扫到了一次;而图像中间的像素,卷积核滑过时会被反复计算。这意味着标准卷积会“忽视”图像边缘的有用信息。
- 计算量太大:有时候输入图像非常大(比如 4 K 4K 4K 高清图),像素非常冗余,如果一格一格滑,计算量会爆炸。
为了解决前两个问题,我们引入了“填充(Padding)”;为了解决第三个问题,我们引入了“步幅(Stride)”。
填充和步幅均为卷积层的超参数
1.5.2 填充
即,在输入图像的四周,人为地补上一圈(或多圈)数字,通常补的是 0。
效果:
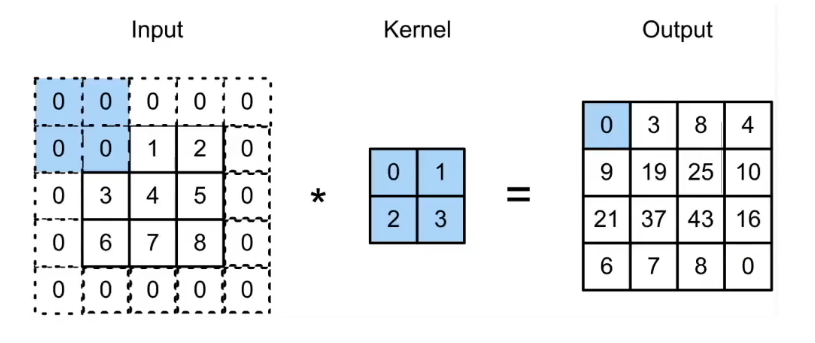
看文档里的 原来 3 × 3 3\times3 3×3 的图像,四周各补一圈 0,变成了 5 × 5 5\times5 5×5。这时再用 2 × 2 2\times2 2×2 的卷积核去滑,输出就变成了 4 × 4 4\times4 4×4。不仅没变小,反而变大了。
在实际写代码时,我们通常希望输入图像和输出图像的尺寸保持完全一致(比如输入 32 × 32 32\times32 32×32,输出还是 32 × 32 32\times32 32×32),这样方便网络层数的叠加。
为了达到这个目的,有一个固定套路:
- 卷积核大小(Kernel Size)通常选奇数:比如 3 × 3 3\times3 3×3、 5 × 5 5\times5 5×5、 7 × 7 7\times7 7×7。
- k h ∗ k w k_h * k_w kh∗kw
- 行填充大小和列填充大小通常分别设置为卷积核的高 - 1、宽 - 1
- p h = k h − 1 , p w = k w − 1 p_{h} = k_{h} - 1,p_{w} = k_{w} - 1 ph=kh−1,pw=kw−1
- 如果 k h k_h kh 为奇数,在上下填充 $\left \lfloor p_h/2 \right \rfloor $
- 如果 k h k_h kh 为偶数,在下侧填充 $\left \lfloor p_h/2 \right \rfloor $,在上侧填充 $\left \lceil p_h/2 \right \rceil $
1.5.3 步幅
做法:卷积核原来是每次向右/向下移动 1 格。现在我们让它每次移动 2 2 2 格、 3 3 3 格甚至更多。这个每次移动的格数,就是步幅(stride)。
极大地降低输出图像的尺寸(降维/下采样),从而成倍地减少计算量。
通常我们将步幅设为 2。
如果步幅为 2,图像的宽和高都会变成原来的一半,整体特征图的面积就变成了原来的 四分之一。这在处理大图像时非常高效。
1.5.4 形状计算公式
给定高度 s h s_h sh和宽度 s w s_w sw的步幅,输出形状是
⌊ ( n h − k h + p h + s h ) / s h ⌋ × ⌊ ( n w − k w + p w + s w ) / s w ⌋ \left \lfloor (n_h - k_h + p_h + s_h) / s_h \right \rfloor \times \left \lfloor (n_w - k_w + p_w + s_w) / s_w \right \rfloor ⌊(nh−kh+ph+sh)/sh⌋×⌊(nw−kw+pw+sw)/sw⌋
推导非常简单,算一下边界下标就行了
如果 p h = k h − 1 , p w = k w − 1 p_h = k_h - 1,p_w = k_w - 1 ph=kh−1,pw=kw−1
⌊ ( n h + s h − 1 ) / s h ⌋ × ⌊ ( n w + s w − 1 ) / s w ⌋ \left \lfloor (n_h + s_h - 1) / s_h \right \rfloor \times \left \lfloor (n_w + s_w - 1) / s_w \right \rfloor ⌊(nh+sh−1)/sh⌋×⌊(nw+sw−1)/sw⌋
如果输入高度和宽度都可以被步幅整除
( n h / s h ) × ( n w / s w ) (n_h / s_h) \times (n_w / s_w) (nh/sh)×(nw/sw)
1.5.5 代码实现
在所有侧边填充1个像素
import torch
from torch import nn
def comp_conv2d(conv2d, X):
X = X.reshape((1, 1) + X.shape)
Y = conv2d(X)
return Y.reshape(Y.shape[2:])
conv2d = nn.Conv2d(1, 1, kernel_size = 3, padding = 1)
X = torch.rand(size = (8, 8))
comp_conv2d(conv2d, X).shape
- 卷积核大小为3*3,上下左右各填充一排0
输出:
torch.Size([8, 8])
填充不同的高度和宽度
conv2d = nn.Conv2d(1, 1, kernel_size = (5, 3), padding = (2, 1))
comp_conv2d(conv2d, X).shape
- 卷积核大小5*3,左右各填充2排0,上下各填充1排0
输出:
torch.Size([8, 8])
将高度和宽度的步幅设置为2
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2)
comp_conv2d(conv2d, X).shape
输出:
torch.Size([4, 4])
稍微复杂一点的例子
conv2d = nn.Conv2d(1, 1, kernel_size=(3, 5), padding=(0, 1), stride=(3, 4))
comp_conv2d(conv2d, X).shape
输出:
torch.Size([2, 2])
1.6 多个输入和输出通道
输出通道数是卷积层的另一个超参数
1.6.1 为什么需要多通道
在之前的学习中,我们处理的都是二维张量(单通道),比如黑白图像。
但现实中,数据要丰富得多:
- 彩色图像:包含红(R)、绿(G)、蓝(B)三个通道。
- 网络深层特征:随着网络加深,图像会被提取出边缘、纹理、形状等各种特征,这些特征在网络中也就是以“通道”的形式存在的。
因此,我们的输入不再是一个二维矩阵,而是变成了三维张量:通道数 × \times × 高度 × \times × 宽度( c × h × w c \times h \times w c×h×w)。
1.6.2 多输入通道
当输入数据有多个通道(比如 c i = 3 c_i = 3 ci=3 的RGB图像)时,我们的卷积核也要随之变化。
1. 卷积核形状的变化
- 规则:卷积核的“输入通道数”必须和输入数据的“通道数”严格相等。
- 形状:卷积核从原来的二维矩阵 k h × k w k_h \times k_w kh×kw,变成了三维张量 c i × k h × k w c_i \times k_h \times k_w ci×kh×kw。
2. 运算过程
- 按通道配对:输入数据的第1个通道,只和卷积核的第1个通道做二维互相关运算;第2个配第2个……以此类推。
- 按通道相加:各个通道算完后,会得到 c i c_i ci 个二维矩阵。把这 c i c_i ci 个矩阵按元素加在一起,最终只输出一个二维矩阵。
简单实现:
from d2l import torch as d2l
import torch
def corr2d_multi_in(X, K):
# 先遍历“X”和“K”的第0个维度(通道维度),再把它们加在一起
return sum(d2l.corr2d(x, k) for x, k in zip(X, K))
X = d2l.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]],
[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]])
K = d2l.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])
corr2d_multi_in(X, K)
输出:
tensor([[ 56., 72.],
[104., 120.]])
1.6.3 多输出通道
很多时候,我们需要提取图像的多种特征(比如有的提取水平边缘,有的提取颜色渐变)。这就需要多输出通道。
1. 如何实现多输出通道?
- 规则:想要几个输出通道(设为 c o c_o co),就准备几个刚才那种“多输入通道的卷积核”。
- 终极卷积核形状:变成了四维张量: c o × c i × k h × k w c_o \times c_i \times k_h \times k_w co×ci×kh×kw (输出通道数 × \times × 输入通道数 × \times × 核高 × \times × 核宽)。
2. 运算过程
- 每个输出通道的计算,都是将整个输入数据与属于该输出通道的那组卷积核进行运算。
- 最后把算出来的 c o c_o co 个二维结果叠在一起,输出形状变成了 c o × h ′ × w ′ c_o \times h' \times w' co×h′×w′。
代码实现:
def corr2d_multi_in_out(X, K):
# 迭代“K”的第0个维度,每次都对输入“X”执行互相关运算。
# 最后将所有结果都叠加在一起
return d2l.stack([corr2d_multi_in(X, k) for k in K], 0)
K = d2l.stack((K, K + 1, K + 2), 0)
K.shape
corr2d_multi_in_out(X, K)
tensor([[[ 56., 72.],
[104., 120.]],
[[ 76., 100.],
[148., 172.]],
[[ 96., 128.],
[192., 224.]]])
1.6.4 1×1卷积层
- 它不跨像素,只跨通道: 1 × 1 1 \times 1 1×1 卷积的本质是对同一位置的所有通道像素进行一次线性组合。
- 等价于全连接层:如果你把每个像素位置(包含 c i c_i ci 个通道的值)看作一个特征向量,那么 1 × 1 1 \times 1 1×1 卷积就是一个输入节点数为 c i c_i ci,输出节点数为 c o c_o co 的全连接层!
- 核心作用:降维与升维:它可以兵不血刃地改变通道数量。比如输入是 256 通道,用 64 个 1 × 1 1 \times 1 1×1 的卷积核,就能把通道数降到 64,大幅减少后续计算量。这在 ResNet、Inception 等经典网络中是标准操作。
def corr2d_multi_in_out_1x1(X, K):
c_i, h, w = X.shape
c_o = K.shape[0]
X = d2l.reshape(X, (c_i, h * w))
K = d2l.reshape(K, (c_o, c_i))
# 全连接层中的矩阵乘法
Y = d2l.matmul(K, X)
return d2l.reshape(Y, (c_o, h, w))
X = d2l.normal(0, 1, (3, 3, 3))
K = d2l.normal(0, 1, (2, 3, 1, 1))
Y1 = corr2d_multi_in_out_1x1(X, K)
Y2 = corr2d_multi_in_out(X, K)
assert float(d2l.reduce_sum(d2l.abs(Y1 - Y2))) < 1e-6
一些课后题
1. 两个连续卷积核 k 1 , k 2 k_1, k_2 k1,k2(无非线性激活)等价于一个单次卷积吗?
- 是的。因为卷积运算本质是线性组合。两个线性操作的嵌套仍然是线性操作。
- 维数:假设 k 1 k_1 k1 大小是 h 1 × w 1 h_1 \times w_1 h1×w1, k 2 k_2 k2 是 h 2 × w 2 h_2 \times w_2 h2×w2,等效卷积核的大小通常是 ( h 1 + h 2 − 1 ) × ( w 1 + w 2 − 1 ) (h_1+h_2-1) \times (w_1+w_2-1) (h1+h2−1)×(w1+w2−1)。
- 反之亦然吗? 不一定。一个大的卷积核不一定能分解为两个小的卷积核连乘(相当于矩阵分解不一定存在实数解)。
2. 计算成本与内存占用(假设输出特征图大小为 h o u t × w o u t h_{out} \times w_{out} hout×wout)
- 计算成本 (FLOPs):一次输出元素的计算需要 c i × k h × k w c_i \times k_h \times k_w ci×kh×kw 次乘加。总输出有 c o × h o u t × w o u t c_o \times h_{out} \times w_{out} co×hout×wout 个元素。因此总计算量约为: O ( c o × c i × k h × k w × h o u t × w o u t ) O(c_o \times c_i \times k_h \times k_w \times h_{out} \times w_{out}) O(co×ci×kh×kw×hout×wout)。
- 内存占用:包含参数量( c o × c i × k h × k w c_o \times c_i \times k_h \times k_w co×ci×kh×kw)+ 输出特征图激活值( c o × h o u t × w o u t c_o \times h_{out} \times w_{out} co×hout×wout)+ 优化器状态等。
3. 通道数翻倍,计算量如何变化?
- 看上一题的公式,计算量里包含了 c o × c i c_o \times c_i co×ci。如果两者都翻倍,计算量会变成原来的 2 × 2 = 4 2 \times 2 = \mathbf{4} 2×2=4 倍!这也是为什么设计网络时通道数不能随便乱加的原因。填充翻倍对输出大小有影响,计算量增加取决于 h o u t × w o u t h_{out} \times w_{out} hout×wout 增加的比例。
4. 1 × 1 1 \times 1 1×1 卷积的计算复杂度?
- 代入上面的公式,令 k h = k w = 1 k_h=k_w=1 kh=kw=1,复杂度骤降为: O ( c o × c i × h × w ) O(c_o \times c_i \times h \times w) O(co×ci×h×w)。这也是为什么常用它来降维减小计算量的原因。
5. 非 1 × 1 1 \times 1 1×1 卷积如何用矩阵乘法实现?
使用一种叫
im2col(Image to Column) 的技术。把输入图像中每个卷积窗口滑动覆盖到的区域,强行“拉平”成一个一维向量,组合成一个大矩阵。
- 虽然极大的浪费了内存,但是现代飞快的矩阵乘法省下的时间还是很划算的
- 而且,现在有隐式矩阵乘法,也不一定真的要拉显存把所有滑窗存下来
把多输出通道的卷积核也拉平。
然后做一次大规模的矩阵乘法,最后再把结果
col2im变回图像形状。这样可以极大地利用 GPU 的矩阵运算加速能力(如 cuBLAS 库)。
1.7 池化层
1.7.1 为什么需要池化层?
在用卷积层提取特征后,面临两个现实痛点:
- “只见树木,不见森林”
当我们判断一张图“是不是猫”时,底层的卷积核只能看到“一根胡须”或“一块毛皮”。要做出全局判断,高层神经元必须能“看”到整张图片。如果全靠卷积层硬算,计算量会爆炸。我们需要一种方法,把图像缩小,浓缩信息,让后续的层能一眼看到更大的区域。 - 对位置过于敏感(缺乏平移不变性)
假设你在拍一只猫,手稍微抖了一下,猫的边缘在照片上向右移动了 1 个像素。对于死板的卷积核来说,这可能完全变成了另一种输入,导致识别失败。我们需要网络有一定的**“容错率”**,只要特征在附近,就能被识别出来。
解决方案:汇聚层(池化层)
它故意丢失一些精确的细节(到底在哪个具体像素),来换取对全局特征的把握和对位置移动的容忍度。
1.7.2 最大池化 vs 平均池化
池化层的操作和卷积层非常像,也有一个“滑动窗口”,但它没有权重参数(不需要学习),它是一个死板的、确定性的操作。
1. 最大汇聚层 (Max Pooling)
- 规则:窗口滑到一个区域,挑出这个区域里的最大值作为代表,其他值丢弃。
- 意义:最大值代表了该区域内最强烈的特征信号(比如最明显的边缘、最亮的斑点)。
- 效果:只要这个特征在这个 2 × 2 2 \times 2 2×2 的小窗口里出现了,不管它在左上角还是右下角,输出的都是那个最大值。这就完美解决了“手抖1个像素”的问题(平移不变性)
2. 平均汇聚层 (Average Pooling)
- 规则:窗口滑到一个区域,计算这个区域所有值的平均值。
- 意义:保留了该区域的整体背景信息或平均响应。
- 效果:它比较温和,通常用在网络的最后端(如 Global Average Pooling),把一整张特征图压缩成一个数字,代表这张图的整体特征。
1.7.3 填充、步幅与多通道
池化层也可以像卷积层一样设置窗口大小 (pool_size)、步幅 (stride) 和 填充 (padding),但有几个关键的区别:
1. 步幅的默认潜规则
在卷积层中,默认步幅通常是 1(慢慢滑,一点点看)。
但在池化层中,深度学习框架(PyTorch/TensorFlow)的默认步幅往往等于窗口大小
- 为什么?因为池化的主要目的就是降维(缩小图片)。如果窗口是 2 × 2 2 \times 2 2×2,步幅也是 2,那么窗口滑动时刚好不重叠,长和宽都会直接减半,图像面积缩小为原来的 1 / 4 1/4 1/4。
2. 多通道独立运算
这是池化层和“多输入通道卷积层”最大的不同:
- 卷积层:面对 RGB 3 个通道,卷积核会把 3 个通道的结果相加,融合成 1 个通道(跨通道融合)。
- 池化层:它在 R 通道做一次池化,在 G 通道做一次,在 B 通道做一次。
- 结论:池化层的输入有多少个通道,输出就一定有多少个通道!它绝不改变通道数,只改变特征图的高和宽。
一些课后题
1. 尝试将平均汇聚层作为卷积层的特殊情况实现。
- 可以实现
- 做法:假设平均池化窗口是 3 × 3 3 \times 3 3×3。我们只需要构造一个 3 × 3 3 \times 3 3×3 的卷积核,把里面的 9 个权重参数全部固定死,设为 1 / 9 1/9 1/9(且不参与梯度更新)。这样卷积滑过的时候,刚好就是求这 9 个像素的平均值。
2. 尝试将最大汇聚层作为卷积层的特殊情况实现。
- 不可能
- 原因:卷积运算的本质是线性组合(乘法和加法)。而“求最大值
max()”是一个纯粹的非线性操作。你无法用任何线性矩阵乘法来等价替换max()操作。这也是为什么最大池化能为网络引入一定的非线性能力的原因之一。3. 池化层的计算成本是多少?
- 假设输入是 c × h × w c \times h \times w c×h×w,窗口 p h × p w p_h \times p_w ph×pw,输出大小是 h o u t × w o u t h_{out} \times w_{out} hout×wout。
- 计算成本极低:不需要做乘法!如果是最大池化,每个输出像素只需要做 ( p h × p w − 1 ) (p_h \times p_w - 1) (ph×pw−1) 次比较操作。
- 总成本约为: O ( c × h o u t × w o u t × p h × p w ) O(c \times h_{out} \times w_{out} \times p_h \times p_w) O(c×hout×wout×ph×pw) 次比较或加法。相比于卷积层的海量乘法,池化层的计算量几乎可以忽略不计。
4. 为什么最大池化和平均池化工作方式不同?(本质区别)
- 最大池化提取的是纹理、边缘等响应最强烈的“高频信号”。哪怕背景全黑,只有一个白点,最大池化也能敏锐捕捉到。
- 平均池化提取的是背景、色彩等平滑的“低频信号”。它把所有信号抹匀了看。现代 CNN 中,特征提取阶段多用最大池化,最后分类前的汇总阶段多用平均池化。
5. 我们需要最小汇聚层吗?可以用已知函数替换它吗?
- 理论上存在,可以用
MinPool(X) = -MaxPool(-X)来实现(取相反数,求最大,再取反)。- 为什么不需要? 因为在神经网络中(特别是 ReLU 激活后),重要的特征信号往往表现为正的大数值,而没有特征的背景往往是 0。我们关心的是“哪里有特征”,而不是“哪里特征最弱”,所以极少使用最小池化。
6. 除平均和最大池化外,还有其他函数吗(回想 softmax)?为什么不流行?
- 有。 比如 LogSumExp 池化(也叫 Softmax 池化)或 L2 范数池化。
- LogSumExp 介于最大和平均之间: p o o l i n g = log ( ∑ exp ( x i ) ) pooling = \log(\sum \exp(x_i)) pooling=log(∑exp(xi))。它既能突出最大值,又保留了一点其他较小值的信息。
- 为什么不流行? 第一,计算太复杂了,算指数 exp \exp exp 和对数 log \log log 在硬件上非常耗时;第二,实践证明,简单粗暴的 Max Pooling 在分类任务上的效果已经足够好了,没必要杀鸡用牛刀。
简单的代码练习
from d2l import torch as d2l
import torch
from torch import nn
前向传播函数
def pool2d(X, pool_size, mode='max'):
p_h, p_w = pool_size
Y = d2l.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max':
Y[i, j] = X[i: i + p_h, j: j + p_w].max()
elif mode == 'avg':
Y[i, j] = X[i: i + p_h, j: j + p_w].mean()
return Y
X = d2l.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
pool2d(X, (2, 2))
输出:
tensor([[4., 5.],
[7., 8.]])
pool2d(X, (2, 2), 'avg')
输出:
tensor([[2., 3.],
[5., 6.]])
填充和步幅
X = d2l.reshape(d2l.arange(16, dtype=d2l.float32), (1, 1, 4, 4))
X
输出:
tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]]]])
pool2d = nn.MaxPool2d(3) # 3*3 窗口
pool2d(X)
输出:(输出一个10,因为stride 默认和池化窗口大小一致)
tensor([[[[10.]]]])
也可以手动指定 padding 和 stride
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
pool2d(X)
输出:
tensor([[[[ 5., 7.],
[13., 15.]]]])
指定池化核大小为(2, 3):
pool2d = nn.MaxPool2d((2, 3), stride=(2, 3), padding=(0, 1))
pool2d(X)
输出:
tensor([[[[ 5., 7.],
[13., 15.]]]])
1.8 LeNet
1.8.1 为什么我们需要卷积神经网络?
在前面的章节中,我们要识别图像(比如 28 × 28 28 \times 28 28×28 的衣服图片),做法是把图像展平(Flatten),变成一个长度为 784 的一维向量,然后丢给全连接层。
这样做的致命缺点是:丢失了图像的空间结构。 比如,原本在图片上相邻的两个像素,展平后可能相隔很远,网络很难学习到“边缘”、“轮廓”这样的二维空间特征。
卷积层(Convolutional Layer)的引入解决了两个问题:
- 保留空间结构: 卷积核在二维图像上滑动,能够捕捉局部的空间模式(比如水平边缘、垂直边缘)。
- 参数更少: 因为“权重共享”(同一个卷积核扫遍全图),参数量大大减少,模型更轻量且不易过拟合。
LeNet 的历史地位:
1989年由 Yann LeCun 提出,是最早的卷积神经网络之一。它首次证明了用反向传播训练的卷积神经网络在实际任务(识别支票上的手写数字)中是非常有效的。在当时,它的性能可以和主流的 SVM(支持向量机)一较高下。
1.8.2 LeNet 的网络结构解析
LeNet 的设计奠定了现代 CNN 的基本范式,即:卷积层提取特征 + 全连接层进行分类。
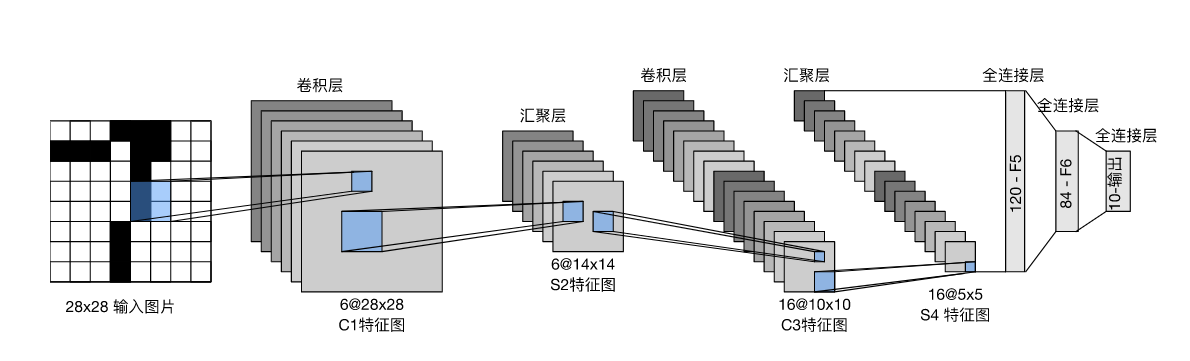
它可以分为两大块:
- 卷积编码器(特征提取): 由两个
卷积层 + 激活函数 + 汇聚层(池化层)组成。 - 全连接层密集块(分类输出): 展平后,由三个
全连接层组成。
详细层级拆解:
- 输入: 1 × 28 × 28 1 \times 28 \times 28 1×28×28 的单通道图像(灰度图)。
- 第一层(Conv1): 使用 5 × 5 5 \times 5 5×5 的卷积核,
padding=2。为了提取更多特征,输出了 6 个通道。激活函数用了 Sigmoid。 - 第一层池化(Pool1): 2 × 2 2 \times 2 2×2 的平均池化层(AvgPool),步幅为 2。这会让图像的长宽缩小一半(降采样),目的是减小计算量,并让特征具有平移不变性。
- 第二层(Conv2): 使用 5 × 5 5 \times 5 5×5 的卷积核,不加 padding。通道数增加到 16 个。激活函数是 Sigmoid。
- 第二层池化(Pool2): 同样是 2 × 2 2 \times 2 2×2 平均池化。
- 展平(Flatten): 将前面输出的三维特征图,拉平变成一维向量,方便喂给全连接层。
- 全连接层(Dense/Linear): 依次经过 120个神经元 → \rightarrow → 84个神经元 → \rightarrow → 10个神经元(因为是10分类任务)。
(注:90年代还没有流行 ReLU 和 MaxPool,所以 LeNet 使用了 Sigmoid 和 AvgPool。在现代网络中,通常会被 ReLU 和 MaxPool 替代。)
1.8.3 代码实现(pytorch)
import torch
from torch import nn
from d2l import torch as d2l
class Reshape(nn.Module):
def forward(self, x):
return x.view(-1, 1, 28, 28)
net = nn.Sequential(
Reshape(),
# first conv
nn.Conv2d(1, 6, kernel_size=5, padding=2), # ci=1, co=6, kernel=5*5, padding=2
nn.Sigmoid(),
# first pool
nn.AvgPool2d(kernel_size=2, stride=2), # 2*2 avgpool
# second conv
nn.Conv2d(6, 16, kernel_size=5), # ci=6, co=16, kernel=5*5, no padding
nn.Sigmoid(),
# second pool
nn.AvgPool2d(kernel_size=2, stride=2), # 2*2 avgpool
nn.Flatten(), # flatten for the next Linear
nn.Linear(16 * 5 * 5, 120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10),
)
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'output shape: \t', X.shape)
输出:
Reshape output shape: torch.Size([1, 1, 28, 28])
Conv2d output shape: torch.Size([1, 6, 28, 28])
Sigmoid output shape: torch.Size([1, 6, 28, 28])
AvgPool2d output shape: torch.Size([1, 6, 14, 14])
Conv2d output shape: torch.Size([1, 16, 10, 10])
Sigmoid output shape: torch.Size([1, 16, 10, 10])
AvgPool2d output shape: torch.Size([1, 16, 5, 5])
Flatten output shape: torch.Size([1, 400])
Linear output shape: torch.Size([1, 120])
Sigmoid output shape: torch.Size([1, 120])
Linear output shape: torch.Size([1, 84])
Sigmoid output shape: torch.Size([1, 84])
Linear output shape: torch.Size([1, 10])
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
评价函数
def evaluate_accuracy_gpu(net, data_iter, device=None):
''' use Gpu to test accuracy of model'''
if isinstance(net, torch.nn.Module):
net.eval()
if not device:
device = next(iter(net.parameters())).device
metric = d2l.Accumulator(2)
for X, y in data_iter:
if isinstance(X, list):
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1] # 正确数目 / 总数
import time
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""用GPU训练模型"""
st_tim = time.time()
# 1. 权重初始化:使用 Xavier 初始化,防止梯度消失/爆炸
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
# 2. 将模型搬到 GPU 上
print('training on', device)
net.to(device)
# 3. 定义优化器 (SGD) 和 损失函数 (交叉熵)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
# 动画绘制工具 (D2L 提供的包,用于画 Loss 曲线)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
# 4. 训练循环
for epoch in range(num_epochs):
metric = d2l.Accumulator(3) # 记录: [训练损失之和, 训练准确率之和, 样本数]
net.train() # 设置为训练模式
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad() # 梯度清零
# 数据搬运到 GPU
X, y = X.to(device), y.to(device)
# 前向传播 -> 计算损失 -> 反向传播 -> 更新参数
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad(): # 记录指标时不计算梯度
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
# 每经过 1/5 的批次,或者到了最后一个批次,更新一下图表
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches, (train_l, train_acc, None))
# 每一个 epoch 结束后,在测试集上评估一次
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
ed_tim = time.time()
all_tim = ed_tim - st_tim
# 打印最终结果和训练速度
print(f'it takes {all_tim // 60}minutes {all_tim % 60}s')
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on {str(device)}')
训练参数
lr, num_epochs = 0.5, 20
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
输出:
it takes 4.0minutes 9.768802165985107s
loss 0.423, train acc 0.843, test acc 0.829
57758.7 examples/sec on cuda:0
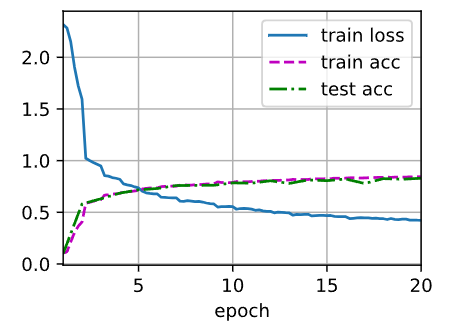
设置了学习率 lr=0.9 和 num_epochs=10。之所以学习率设这么大,是因为模型使用了 Sigmoid 激活函数,且没有批归一化(BatchNorm),容易发生梯度消失,需要较大的学习率来推动参数更新。)
如果我们尝试加入BatchNorm,并且更换AvgPool 为 MaxPool,更换 Sigmoid 为 ReLU
值得注意的是,net.eval() 后,会关闭BatchNorm,net.train() 下,会打开 BatchNorm
net = nn.Sequential(
Reshape(),
# first conv
nn.Conv2d(1, 6, kernel_size=5, padding=2), # ci=1, co=6, kernel=5*5, padding=2
nn.BatchNorm2d(6),
nn.ReLU(),
# first pool
nn.MaxPool2d(kernel_size=2, stride=2), # 2*2 avgpool
# second conv
nn.Conv2d(6, 16, kernel_size=5), # ci=6, co=16, kernel=5*5, no padding
nn.BatchNorm2d(16),
nn.ReLU(),
# second pool
nn.MaxPool2d(kernel_size=2, stride=2), # 2*2 avgpool
nn.Flatten(), # flatten for the next Linear
nn.Linear(16 * 5 * 5, 120),
nn.BatchNorm1d(120),
nn.ReLU(),
nn.Linear(120, 84),
nn.BatchNorm1d(84),
nn.ReLU(),
nn.Linear(84, 10),
)
同样的训练参数:
lr, num_epochs = 0.5, 20
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
输出:
it takes 4.0minutes 4.190480470657349s
loss 0.097, train acc 0.964, test acc 0.900
49093.5 examples/sec on cuda:0
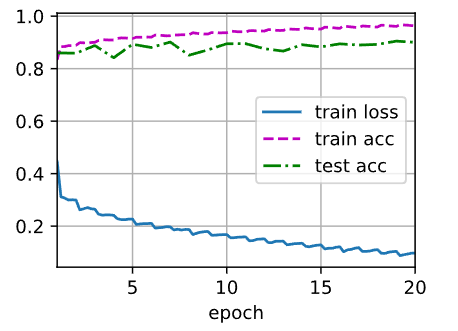
得到了巨大的提升。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)