KingbaseES融合数据库:多模态引擎深度集成,实现一库多能异构统一
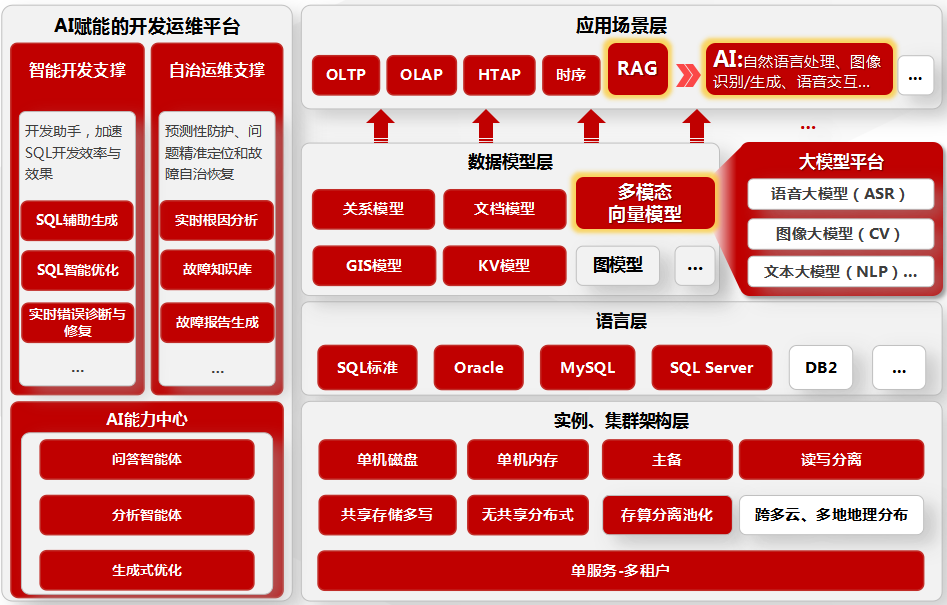
字化转型越深入,企业踩的坑就越具体——现在大家头疼的早就不是“数据存不下、查不快”,而是“数据格式杂、类型多、想关联还难”。传统多组件堆砌的 “烟囱式” 方案不仅带来数据孤岛、一致性难保障,还大幅提升运维与开发成本。2026 年,随着 AI 应用爆发与非结构化数据占比超 80%,人大金仓 KingbaseES 推出融合数据库架构,通过多模态引擎深度集成,将关系、文档、键值、图、时空、向量检索能力统
引言:告别数据孤岛,融合数据库才是真答案
数字化转型越深入,企业踩的坑就越具体——现在大家头疼的早就不是“数据存不下、查不快”,而是“数据格式杂、类型多、想关联还难”。传统多组件堆砌的 “烟囱式” 方案不仅带来数据孤岛、一致性难保障,还大幅提升运维与开发成本。2026 年,随着 AI 应用爆发与非结构化数据占比超 80%,人大金仓 KingbaseES 推出融合数据库架构,通过多模态引擎深度集成,将关系、文档、键值、图、时空、向量检索能力统一到单一内核,真正实现 “一库多能、异构统一”,为企业构建面向未来的数据底座。
文章目录
一、核心架构革新:从“插件凑数”到“内核级真融合”
早期的多模数据库,大多是在核心引擎上挂插件实现扩展功能——看着灵活,实则坑不少:事务一致性没法保证、资源隔离乱套、查询优化器也没法协同工作。而KingbaseES的新一代架构,走的是“统一内核,多模引擎”的路子,从根上解决了这些问题。
1.1 统一存储引擎:一套底层搞定所有数据
KingbaseES重构了底层存储引擎,用上了LSM-Tree和B+ Tree混合存储结构,不同场景都能适配:
- 行存(Row Store):专门优化过,扛高并发OLTP事务没问题,ACID特性稳稳的;
- 列存(Column Store):针对OLAP分析场景,压缩比高,聚合查询跑得贼快;
- 多模适配层:在这之上搭了统一的元数据管理层——不管是JSON文档、图节点还是向量索引,底层数据块都映射成统一的页(Page)结构,共享Buffer Pool和WAL(预写日志)机制。
简单说,改个文档数据和更个关系表,都在同一个事务ID(XID)管控下,真正做到了强一致性,再也不用操心数据同步出问题。
二、多模态能力拆解:一个库搞定所有数据场景
KingbaseES可不是只支持多种数据类型就完事了,关键是给每种数据类型都配了原生算子和专用索引,性能一点不打折,啥场景都能hold住。
2.1 关系+文档:一张表就能装下结构化和半结构化数据
做电商的朋友肯定有这体会:商品基础信息(ID、价格、库存)是结构化的,规格参数、用户评价又都是半结构化的。用KingbaseES,这些数据能直接存在同一张表里,查起来贼方便。
代码示例:创建混合模型表并完成复杂查询
-- 建表:把关系字段、JSON文档、向量数据放一起
CREATE TABLE products (
product_id BIGINT PRIMARY KEY, -- 商品ID(结构化)
category_id INT, -- 分类ID
price NUMERIC(10, 2), -- 价格
stock INT, -- 库存
attributes JSONB, -- 商品规格(半结构化,原生支持不用插件)
image_vector vector(512) -- 图片向量(用于以图搜图)
);
-- 建索引:加速不同类型数据查询
CREATE INDEX idx_attrs ON products USING GIN (attributes); -- GIN索引提JSON查询速度
CREATE INDEX idx_image_vec ON products USING hnsw (image_vector vector_cosine_ops); -- HNSW索引加速向量检索
-- 实战查询:找数码类、屏幕>6英寸、图片相似度最高的前5个商品
SELECT
product_id,
price,
attributes->>'screen_size' as screen, -- 提取JSON里的屏幕尺寸
-- 计算向量相似度(值越大越相似)
1 - (image_vector <=> '[0.12, 0.45, 0.78, ..., 0.89]'::vector) as similarity
FROM products
WHERE
category_id = 1001 -- 数码类分类ID
AND (attributes->>'screen_size')::float > 6.0 -- 屏幕尺寸过滤
-- 按向量相似度排序,取前5
ORDER BY image_vector <=> '[0.12, 0.45, 0.78, ..., 0.89]'::vector
LIMIT 5;
这个查询里,数据库会同时用B+Tree(主键)、GIN(JSON属性)、HNSW(向量)三种索引,一次扫描就完成所有过滤和排序,不用在应用层拼数据,效率直接拉满。
2.2 内置图计算:资金链路、社交关系一查就透
传统数据库查多跳关系(比如“从A账户转了几次账到高风险账户”),得写一堆自连接,跳数越多越慢。KingbaseES内置了图引擎,支持属性图模型,还扩展了SQL语法,查多跳关系跟查普通数据一样简单。
场景:金融风控查资金链路
-- 定义图视图:把关系表映射成图结构(物理数据还在原表,不用额外存)
CREATE GRAPH VIEW money_flow AS
NODES FROM accounts (id AS node_id, balance, risk_level) -- 节点:账户信息
EDGES FROM transactions (src_id, dst_id, amount, trans_time AS edge_props); -- 边:转账记录
-- 多跳查询:找从ACC_001出发,最多3次转账到高风险账户的所有路径
SELECT
start_node.id as source, -- 起始账户
end_node.id as target, -- 目标账户
path_edges.amounts as transfer_chain, -- 转账金额链
array_length(path_edges, 1) as hop_count -- 转账次数
FROM money_flow
-- 图遍历语法:1..3表示1到3跳
MATCH (start_node)-[path_edges*1..3]->(end_node)
WHERE
start_node.id = 'ACC_001' -- 起始账户ID
AND end_node.risk_level = 'HIGH' -- 高风险账户
RETURN path_edges;
这种原生图能力,处理反洗钱、社交网络分析这些场景,性能比传统数据库快几十倍,还不用额外搭Neo4j之类的组件。
2.3 向量检索:跟大模型搭伙,做RAG超顺手
AI 2.0时代,向量数据库是RAG(检索增强生成)的核心。KingbaseES原生支持高维向量,还集成了HNSW、IVFFlat这些主流的近似最近邻搜索算法,关键是向量数据能和业务数据存在一起,不用来回同步。
代码示例:RAG场景下的全文+向量混合检索
-- 先建知识库表:存文档信息+向量+部门标签
CREATE TABLE knowledge_base (
doc_id BIGINT PRIMARY KEY,
doc_title VARCHAR(255),
doc_content TEXT,
dept VARCHAR(50), -- 所属部门
embedding vector(768) -- 文档向量(768维,适配主流大模型)
);
-- 建索引:全文检索+向量检索双保险
CREATE INDEX idx_doc_content ON knowledge_base USING GIN (to_tsvector('english', doc_content));
CREATE INDEX idx_doc_embedding ON knowledge_base USING hnsw (embedding vector_cosine_ops);
-- 混合查询:找技术部、含“量子计算”且向量相似度最高的10篇文档
SELECT
doc_title,
doc_content,
-- 余弦相似度(值越小越相似,排序用)
embedding <=> '[0.05, 0.18, ..., 0.92]'::vector AS distance
FROM knowledge_base
WHERE
dept = 'TechDept' -- 过滤技术部文档
-- 全文检索:匹配“Quantum Computing”关键词
AND to_tsvector('english', doc_content) @@ to_tsquery('Quantum & Computing')
-- 按向量相似度排序,取前10
ORDER BY embedding <=> '[0.05, 0.18, ..., 0.92]'::vector
LIMIT 10;
这里的优势很明显:向量和业务数据存在一起,不用在向量库和业务库之间同步,查的时候还能先过滤部门、关键词,再算相似度,又快又准。
三、异构统一:不止省成本,还能提效率
KingbaseES的“异构统一”不只是支持多种数据类型,更关键是工作负载统一、开发体验统一,对企业来说,能省不少事。
3.1 HTAP能力:一份数据,既扛交易又做分析
靠行存和列存的实时同步,KingbaseES能在同一份数据上同时支撑高频交易(OLTP)和实时报表(OLAP):
- 实时性:事务提交后,列存副本毫秒级就能查到,不用等T+1的ETL;
- 资源隔离:用cgroup和资源组技术,复杂的分析查询不会卡在线交易,两边都稳。
3.2 开发运维:少学几套工具,少管几套系统
对开发者来说,最烦的就是学一堆技术栈、来回切换上下文。KingbaseES只用一套SQL接口(兼容Oracle/PostgreSQL语法)、一套连接方式(JDBC/ODBC)、一套权限管理,直接省了不少学习成本。
| 对比维度 | 传统多库架构 | KingbaseES 融合架构 |
|---|---|---|
| 技术栈 | MySQL + Mongo + ES + Neo4j + Milvus | 只用KingbaseES |
| 事务一致性 | 最终一致性(要搭分布式事务框架) | 本地ACID强一致性 |
| 数据同步 | 靠Canal/Flink等中间件,延迟高 | 不用同步,天然一体 |
| 运维复杂度 | 5套监控、备份、扩容策略 | 1套统一管控平台搞定 |
| 硬件成本 | 资源碎片化,利用率低 | 资源池化,利用率提40%+ |
3.3 迁移兼容:老系统也能平滑切换
针对企业现有的老系统,人大金仓提供了专用的 KDTS (Kingbase Data Transformation & Synchronization) 迁移工具。该工具不仅支持 Oracle、MySQL 等关系型数据库的结构与数据迁移,还能自动识别源系统中的非结构化数据特征,将其智能映射为 KingbaseES 的多模态字段,极大降低了代码重写成本。
四、未来展望:数据库也要变“智能”
随着大模型技术发展,数据库早就不是只“存数据”了,而是要往“主动智能”方向走。KingbaseES的融合架构,刚好给这个转变铺好了路:
- 自然语言查数据:靠内置的向量能力和元数据理解,以后不用写SQL,直接说“上个季度华东区销量最高的电子产品是啥”,数据库就能自动解析你的需求,调用对应的引擎查结果;
- 库内跑机器学习:数据不用导出,直接在数据库里做特征工程、训练轻量级模型、跑预测,既安全又省性能,再也不用操心数据移动的问题;
- 自适应索引优化:数据库会根据历史查询习惯,自动调整索引——比如给JSON字段建合适的GIN索引,调向量索引的参数,不用DBA手动优化,跟“自动驾驶”似的。
结语
在数据爆炸与AI普及的双重驱动下,KingbaseES融合数据库以其多模态引擎深度集成的核心竞争力,重新定义了企业数据基础设施的标准。它不仅仅是技术的堆叠,更是架构理念的升维——通过“一库多能、异构统一”,解决了长期困扰行业的数据孤岛、一致性难题和运维复杂性。
对于追求敏捷创新、渴望挖掘数据深层价值的企业而言,选择KingbaseES,就是选择了一个能够从容应对过去、现在乃至未来十年数据挑战的坚实伙伴。在这个万物互联、智能共生的新时代,KingbaseES正助力企业构建起自主可控、高效智能的数据底座,驶向数字经济的深蓝海域。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 73
73 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)