计算机毕业设计源码:基于python的双协同过滤电商推荐平台 Django 可视化 淘宝电商 商品 推荐算法 数据分析 管理系统 大数据 大模型 deepseek agent(建议收藏)✅
本文介绍了一个基于双协同过滤算法的商品推荐系统。系统采用Python+Django技术栈,结合MySQL和SQLite数据库,实现了个性化商品推荐功能。主要技术特点包括: 采用基于用户和基于物品的两种协同过滤推荐算法 使用Echarts实现多维度数据可视化(柱状图、词云图等) 包含完整的用户交互功能,如商品收藏、评论、评分等 提供后台管理模块,支持用户、商品和权限管理 系统有效解决了电商平台信息过
·
1、项目介绍
技术栈
Python语言支撑系统整体开发,MySQL数据库承担核心数据存储任务,SQLite数据库辅助存储轻量配置信息,Django框架构建Web后端,两种协同过滤推荐算法(基于用户和基于物品)实现核心推荐功能,Echarts可视化技术呈现多维度图表,HTML与Bootstrap框架搭建前端界面。
功能模块
· 注册登录
· 系统首页
· 商品标签分类
· 商品列表排序
· 商品搜索
· 商品详情页
· 基于用户的协同过滤推荐
· 基于物品的协同过滤推荐
· 我的收藏
· 我的评论
· 我的评分
· 个人信息管理
· 数据可视化柱状图
· 数据可视化词云图
· 数据可视化饼状图
· 数据可视化折线图
· 后台用户管理
· 后台商品管理
· 后台权限管控
项目介绍
本系统针对电商平台用户面临的信息过载问题以及传统热门推荐缺乏个性化的实际痛点,研发了一套基于双协同过滤算法的商品推荐系统。系统后端采用Django框架完成架构搭建,通过MySQL与SQLite协同完成用户信息、商品详情、行为记录等核心数据的存储管理。推荐核心运用基于用户的协同过滤算法计算用户间偏好相似度,同时结合基于物品的协同过滤算法分析商品间关联程度,两种算法相互补充实现精准个性化推荐。前端借助HTML与Bootstrap构建响应式界面,并整合Echarts技术完成柱状图、词云图、饼状图、折线图等多维度数据可视化展示。系统还配备了完整的用户交互功能,涵盖注册登录、商品标签分类查询、列表排序、商品收藏评论评分等模块,以及后台用户管理、商品维护和权限管控功能,构建起从数据存储、算法推荐、可视化分析到后台管理的完整业务闭环,有效提升用户购物体验与平台运营效率。
2、项目界面
系统首页(功能导航与核心推荐商品展示)
该页面是协同过滤算法的商品推荐系统,包含首页、标签、数据可视化、管理员操作、退出登录等导航功能,设有商品搜索框,可按热度排序展示商品,还能基于用户进行商品推荐并可换一批查看。
数据可视化1----柱状图分析(如商品销量/分类占比柱状图)
该页面是协同过滤算法的商品推荐系统的数据可视化页面,设有首页、标签、数据可视化下拉选项、管理员操作、退出登录等导航功能和商品搜索框,图表可展示不同商品分类的数量与付款人数相关数据,还支持图表下载功能。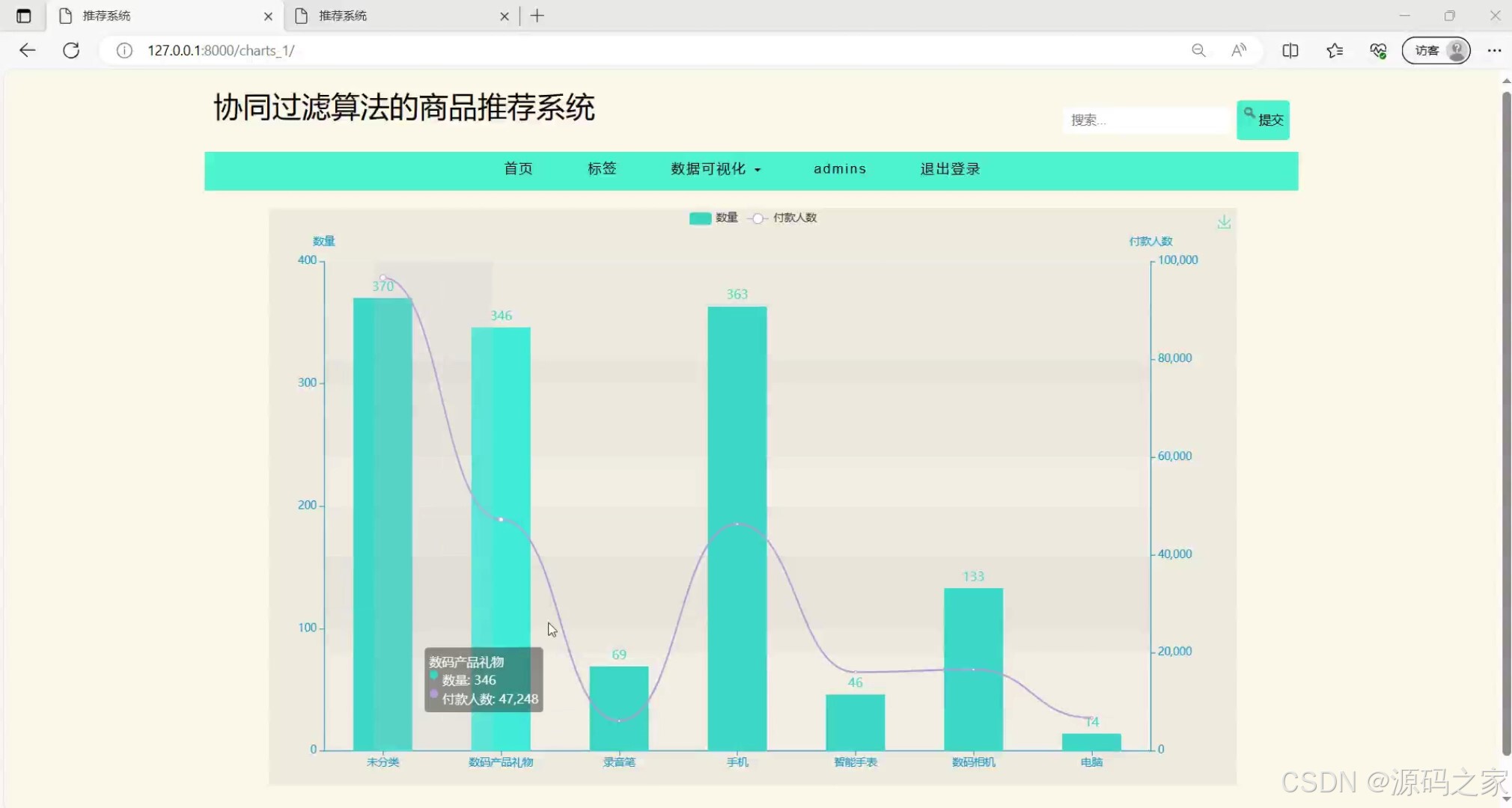
数据可视化2—词云图分析(商品关键词/用户评价高频词展示)
该页面是协同过滤算法的商品推荐系统的词云可视化页面,设有首页、标签、数据可视化下拉选项、管理员操作、退出登录等导航功能和商品搜索框,词云图可直观展示不同店铺名称的出现频次等相关信息,帮助用户快速识别高频店铺。
数据可视化3—饼状图分析(如商品品类分布/用户购买偏好占比)
该页面是协同过滤算法的商品推荐系统的饼图可视化页面,设有首页、标签、数据可视化下拉选项、管理员操作、退出登录等导航功能和商品搜索框,饼图可清晰呈现不同商品分类的占比情况,还能显示各分类占比的具体数值。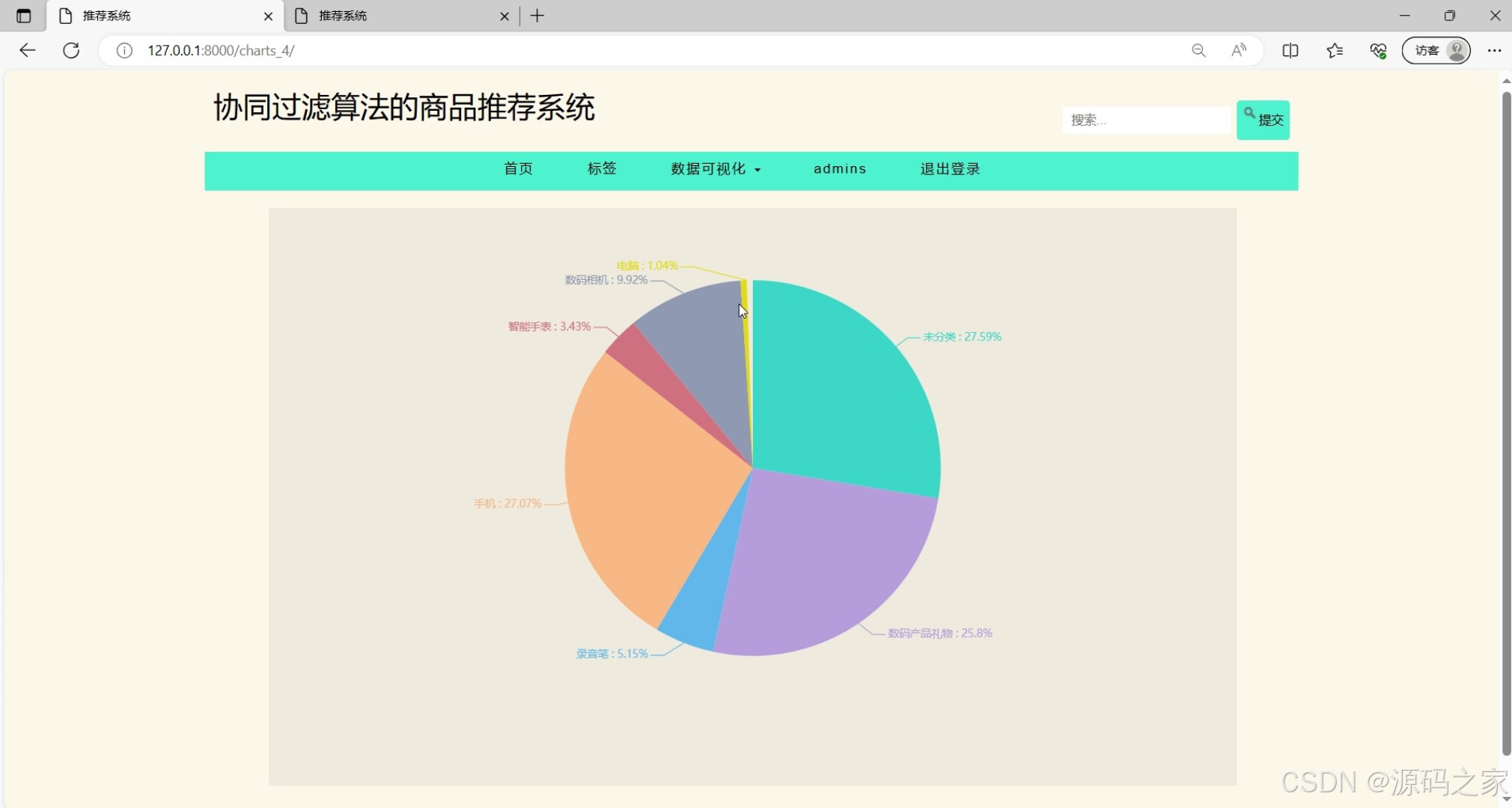
数据可视化4—折线图分析(如商品销量趋势/用户活跃度变化)
该页面是协同过滤算法的商品推荐系统的折线图可视化页面,设有首页、标签、数据可视化下拉选项、管理员操作、退出登录等导航功能和商品搜索框,折线图可展示商品上架数量随时间的变化趋势,还支持通过时间滑块筛选查看对应时段的数据变化。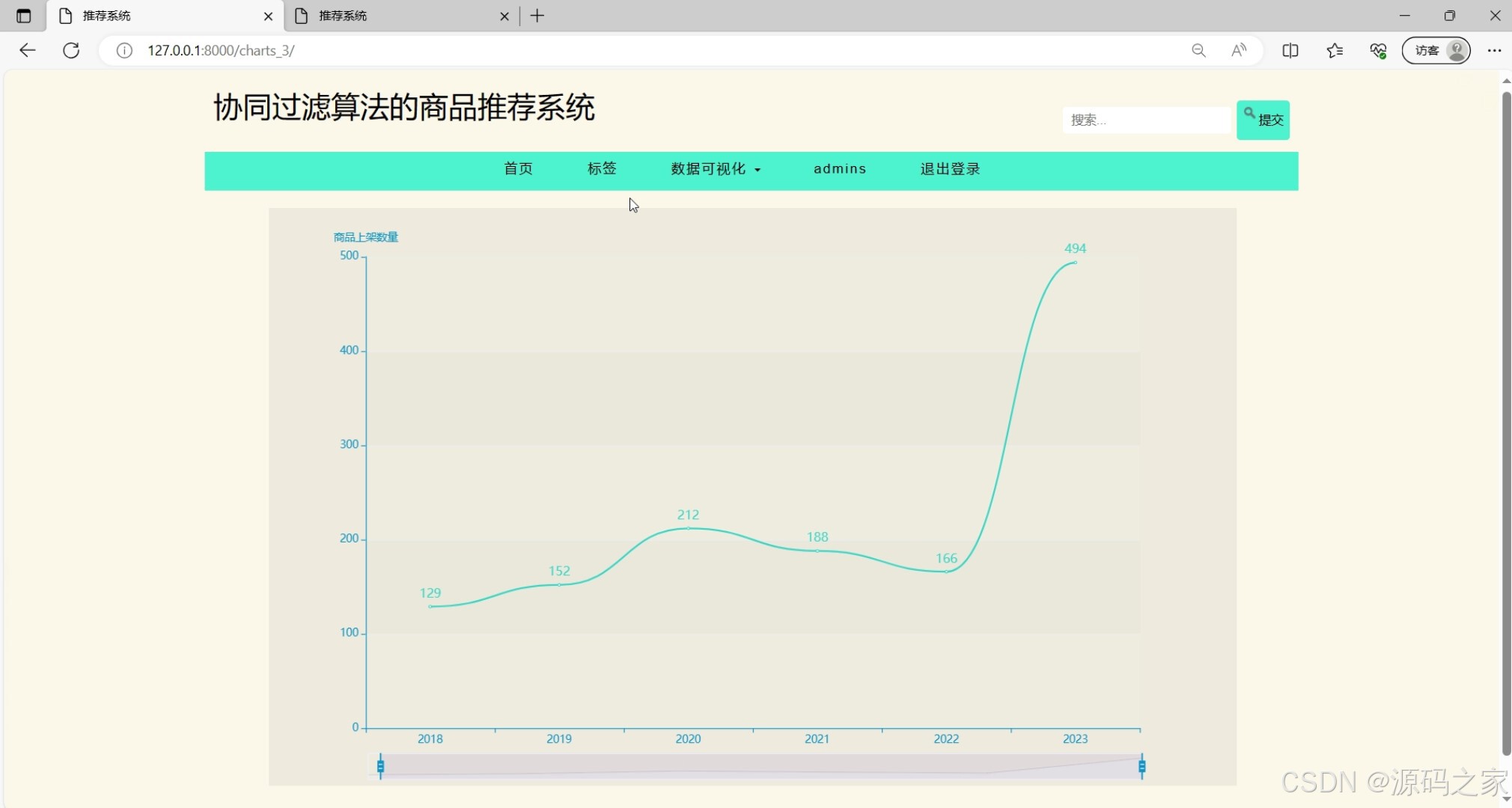
商品详情页-----双推荐算法(商品信息+基于用户/物品的推荐列表)
该页面是协同过滤算法的商品推荐系统的商品详情页,设有首页、标签、数据可视化、管理员操作、退出登录等导航功能和商品搜索框,可展示商品详细信息并支持收藏操作,同时提供基于用户和基于物品的商品推荐功能,且两类推荐模块均支持换一批查看。
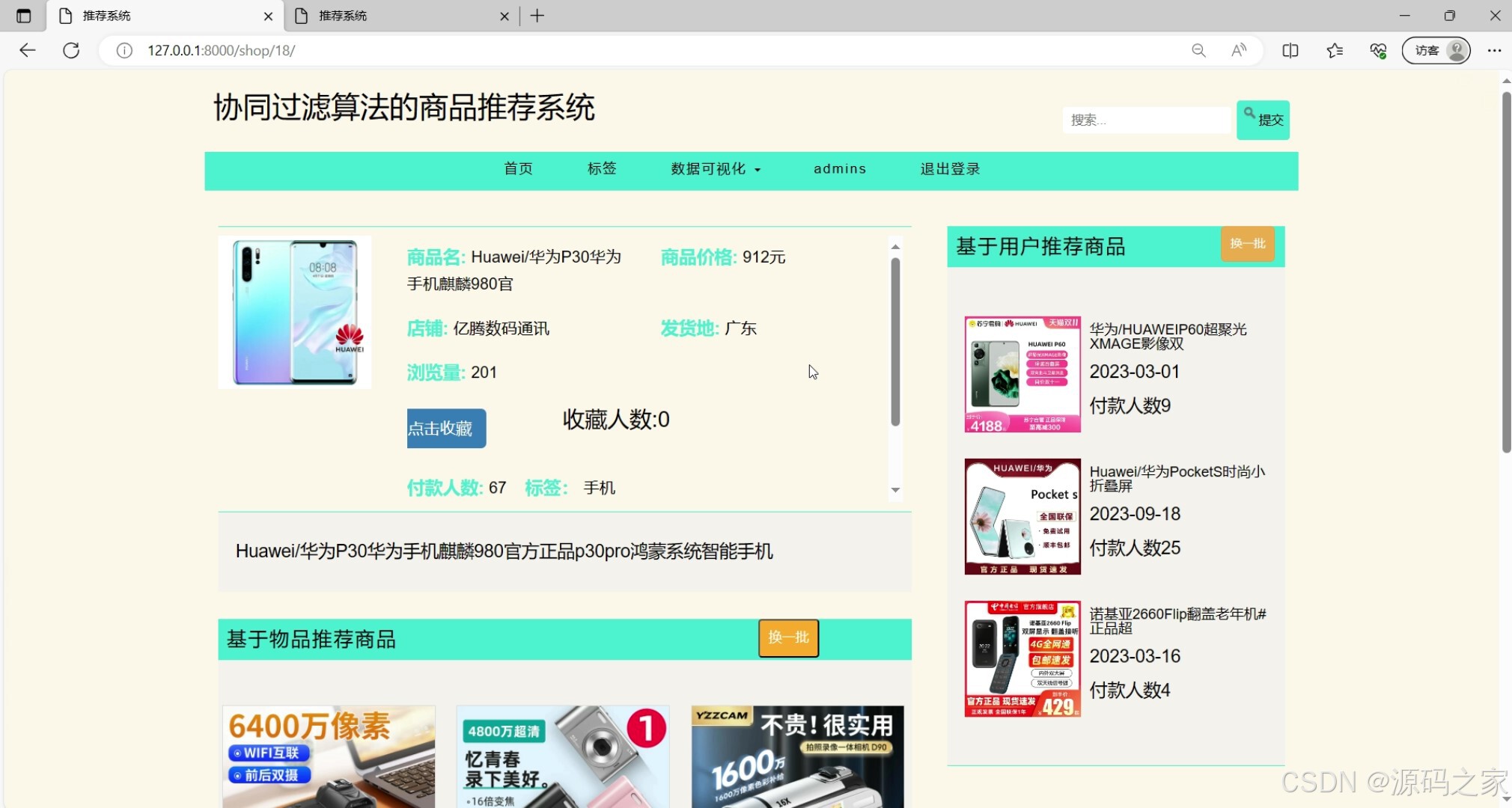
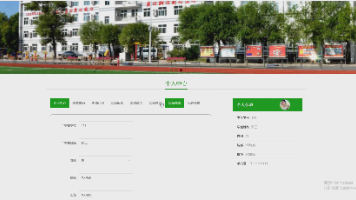
个人信息页面(用户基本信息查看与编辑)
该页面是协同过滤算法的商品推荐系统的个人中心页,设有首页、标签、数据可视化、管理员操作、退出登录等导航功能和商品搜索框,可展示个人信息,支持查看我的收藏、我的评论、我的评分,还能进行账号、邮箱、密码等信息的修改操作,同时提供基于用户的商品推荐功能并可换一批查看。
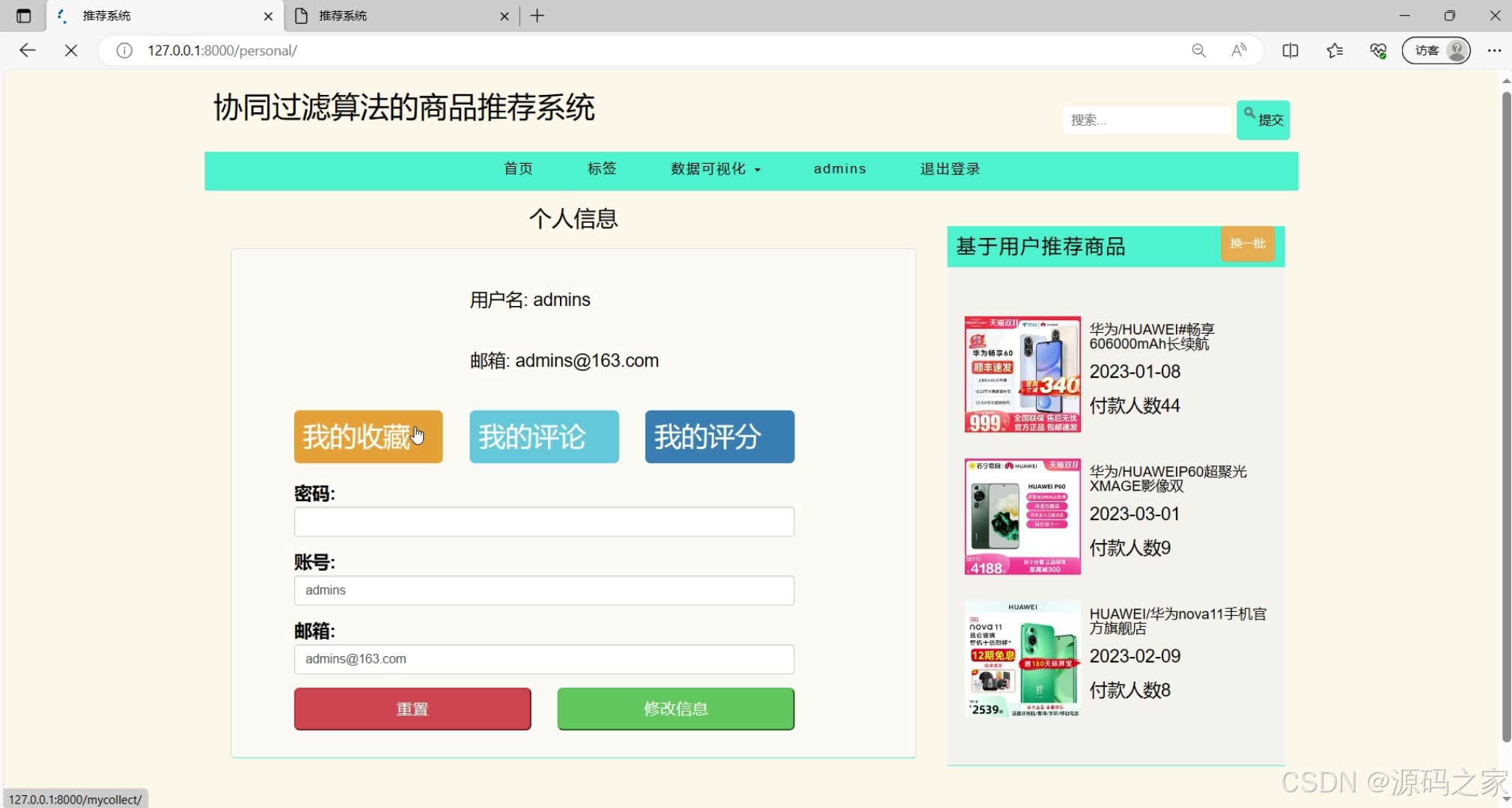
后台数据管理(商品/用户/权限的维护与管控界面)
该页面是协同过滤算法的商品推荐系统的后台管理页面,设有首页、商品、标签、偏好等管理模块,可对商品信息进行查看、增加、删除等操作,同时支持主题切换和管理员账号相关操作。
注册登录
该页面是协同过滤算法的商品推荐系统的用户登录页,设有用户名和密码输入框,支持用户输入账号信息进行登录操作,同时提供注册入口,方便没有账号的用户跳转进行账号注册。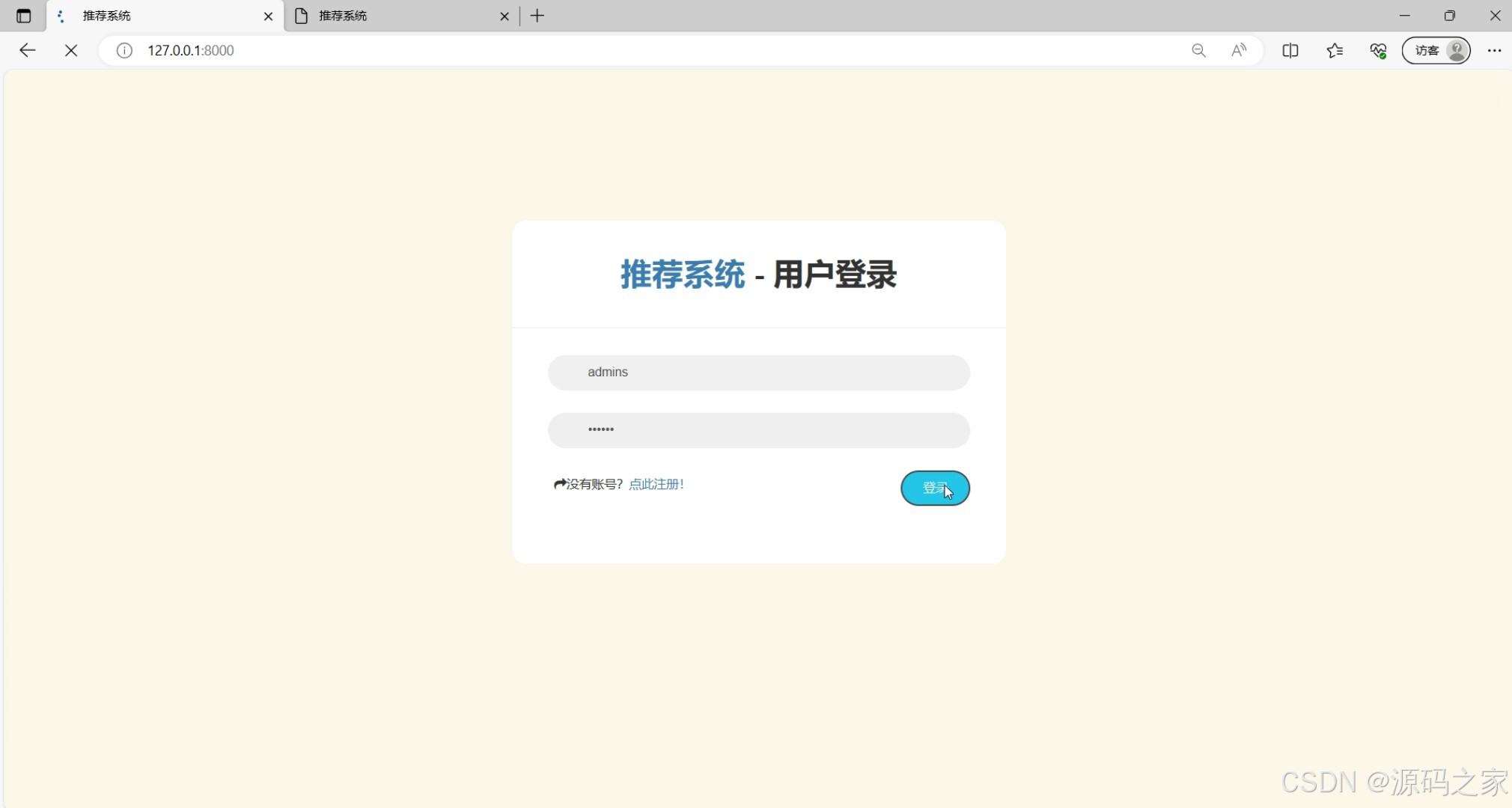
3、项目说明
一、技术栈说明
本系统采用Python语言支撑整体开发,MySQL数据库承担核心数据存储任务,SQLite数据库辅助存储轻量配置信息。后端基于Django框架构建,核心推荐功能通过基于用户和基于物品的两种协同过滤算法实现。前端采用HTML与Bootstrap框架搭建响应式界面,结合Echarts可视化技术呈现柱状图、词云图、饼状图、折线图等多维度图表。
二、功能模块详细介绍
· 注册登录
系统提供用户认证功能,登录页面包含用户名和密码输入框,支持新用户通过注册入口创建账号,保障系统访问安全性和用户身份识别。
· 系统首页
作为功能入口,首页包含首页、标签、数据可视化、管理员操作等导航功能,设有商品搜索框,可按热度排序展示商品,同时提供基于用户的商品推荐模块并支持换一批查看。
· 商品标签分类
用户可通过标签分类导航快速筛选感兴趣的商品类别,提升商品查找效率和浏览体验。
· 商品列表排序
支持按销量、价格等维度对商品列表进行排序,帮助用户根据自身需求快速定位目标商品。
· 商品搜索
提供全局搜索功能,用户可通过关键词搜索商品,系统返回匹配的商品列表供用户浏览选择。
· 商品详情页
展示商品详细信息,包括图片、价格、描述等,支持收藏操作。页面同时集成基于用户和基于物品的两种推荐模块,且均支持换一批查看。
· 基于用户的协同过滤推荐
通过相似度计算算法分析用户间偏好相似程度,筛选相似用户群体感兴趣的商品进行个性化推荐。
· 基于物品的协同过滤推荐
分析商品之间的关联度和共现关系,为正在浏览某商品的用户推荐与之相似的其他商品。
· 我的收藏
用户可查看自己收藏的商品列表,方便后续快速访问和购买决策。
· 我的评论
展示用户发表过的商品评论,支持查看和管理历史评价内容。
· 我的评分
记录用户对商品的评分情况,为推荐算法提供更精准的偏好数据支撑。
· 个人信息管理
支持用户查看和编辑个人资料,包括账号、邮箱、密码等信息的修改操作。
· 数据可视化柱状图
以柱状图形式展示不同商品分类的数量与付款人数等相关数据,支持图表下载功能。
· 数据可视化词云图
通过词云图直观展示不同店铺名称的出现频次,帮助用户快速识别高频店铺和热门品牌。
· 数据可视化饼状图
以饼图形式清晰呈现不同商品分类的占比情况,并显示各分类占比的具体数值。
· 数据可视化折线图
展示商品上架数量随时间的变化趋势,支持通过时间滑块筛选查看对应时段的数据变化。
· 后台用户管理
管理员可对系统用户账号进行查看、增加、删除等维护操作,保障用户数据规范管理。
· 后台商品管理
支持对商品信息进行增删改查操作,包括商品详情、分类、价格等字段的维护。
· 后台权限管控
支持普通用户与管理员权限区分,保障系统数据安全与操作规范性。
三、项目总结
本系统针对电商平台用户面临的信息过载问题以及传统热门推荐缺乏个性化的实际痛点,研发了一套基于双协同过滤算法的商品推荐系统。系统后端采用Django框架完成架构搭建,通过MySQL与SQLite协同完成用户信息、商品详情、行为记录等核心数据的存储管理。推荐核心运用基于用户的协同过滤算法计算用户间偏好相似度,同时结合基于物品的协同过滤算法分析商品间关联程度,两种算法相互补充实现精准个性化推荐。前端借助HTML与Bootstrap构建响应式界面,并整合Echarts技术完成柱状图、词云图、饼状图、折线图等多维度数据可视化展示。系统还配备了完整的用户交互功能,涵盖注册登录、商品标签分类查询、列表排序、商品收藏评论评分等模块,以及后台用户管理、商品维护和权限管控功能,构建起从数据存储、算法推荐、可视化分析到后台管理的完整业务闭环,有效提升用户购物体验与平台运营效率。
4、核心代码
# -*-coding:utf-8-*-
import os
os.environ["DJANGO_SETTINGS_MODULE"] = "recomend.settings"
import django
django.setup()
from shop.models import *
from math import sqrt, pow
import operator
from django.db.models import Subquery, Q, Count
# from django.shortcuts import render,render_to_response
class UserCf:
# 获得初始化数据
def __init__(self, all_user):
self.all_user = all_user
# 通过用户名获得列表,仅调试使用
def getItems(self, username1, username2):
return self.all_user[username1], self.all_user[username2]
# 计算两个用户的皮尔逊相关系数
def pearson(self, user1, user2): # 数据格式为:商品id,浏览此
sum_xy = 0.0 # user1,user2 每项打分的成绩的累加
n = 0 # 公共浏览次数
sum_x = 0.0 # user1 的打分总和
sum_y = 0.0 # user2 的打分总和
sumX2 = 0.0 # user1每项打分平方的累加
sumY2 = 0.0 # user2每项打分平方的累加
for shop1, score1 in user1.items():
if shop1 in user2.keys(): # 计算公共的浏览次数
n += 1
sum_xy += score1 * user2[shop1]
sum_x += score1
sum_y += user2[shop1]
sumX2 += pow(score1, 2)
sumY2 += pow(user2[shop1], 2)
if n == 0:
# print("p氏距离为0")
return 0
molecule = sum_xy - (sum_x * sum_y) / n # 分子
denominator = sqrt((sumX2 - pow(sum_x, 2) / n) * (sumY2 - pow(sum_y, 2) / n)) # 分母
if denominator == 0:
return 0
r = molecule / denominator
return r
# 计算与当前用户的距离,获得最临近的用户
def nearest_user(self, current_user, n=1):
distances = {}
# 用户,相似度
# 遍历整个数据集
for user, rate_set in self.all_user.items():
# 非当前的用户
if user != current_user:
distance = self.pearson(self.all_user[current_user], self.all_user[user])
# 计算两个用户的相似度
distances[user] = distance
closest_distance = sorted(
distances.items(), key=operator.itemgetter(1), reverse=True
)
# 最相似的N个用户
print("closest user:", closest_distance[:n])
return closest_distance[:n]
# 给用户推荐商品
def recommend(self, username, n=3):
recommend = {}
nearest_user = self.nearest_user(username, n)
for user, score in dict(nearest_user).items(): # 最相近的n个用户
for shops, scores in self.all_user[user].items(): # 推荐的用户的商品列表
if shops not in self.all_user[username].keys(): # 当前username没有看过
if shops not in recommend.keys(): # 添加到推荐列表中
recommend[shops] = scores*score
# 对推荐的结果按照商品
# 浏览次数排序
return sorted(recommend.items(), key=operator.itemgetter(1), reverse=True)
# 基于用户的推荐
def recommend_by_user_id(user_id):
user_prefer = UserTagPrefer.objects.filter(user_id=user_id).order_by('-score').values_list('tag_id', flat=True)
current_user = User.objects.get(id=user_id)
# 如果当前用户没有打分 则看是否选择过标签,选过的话,就从标签中找
# 没有的话,就按照浏览度推荐15个
if current_user.rate_set.count() == 0:
if len(user_prefer) != 0:
shop_list = shop.objects.filter(tags__in=user_prefer)[:15]
else:
shop_list = shop.objects.order_by("-num")[:15]
return shop_list
# 选取评分最多的10个用户
users_rate = Rate.objects.values('user').annotate(mark_num=Count('user')).order_by('-mark_num')
user_ids = [user_rate['user'] for user_rate in users_rate]
user_ids.append(user_id)
users = User.objects.filter(id__in=user_ids)#users 为评分最多的10个用户
all_user = {}
for user in users:
rates = user.rate_set.all()#查出10名用户的数据
rate = {}
# 用户有给商品打分 在rate和all_user中进行设置
if rates:
for i in rates:
rate.setdefault(str(i.shop.id), i.mark)#填充商品数据
all_user.setdefault(user.username, rate)
else:
# 用户没有为商品打过分,设为0
all_user.setdefault(user.username, {})
user_cf = UserCf(all_user=all_user)
recommend_list = [each[0] for each in user_cf.recommend(current_user.username, 15)]
shop_list = list(shop.objects.filter(id__in=recommend_list).order_by("-num")[:15])
other_length = 15 - len(shop_list)
if other_length > 0:
fix_list = shop.objects.filter(~Q(rate__user_id=user_id)).order_by('-collect')
for fix in fix_list:
if fix not in shop_list:
shop_list.append(fix)
if len(shop_list) >= 15:
break
return shop_list
# 计算相似度
def similarity(shop1_id, shop2_id):
shop1_set = Rate.objects.filter(shop_id=shop1_id)
# shop1的打分用户数
shop1_sum = shop1_set.count()
# shop_2的打分用户数
shop2_sum = Rate.objects.filter(shop_id=shop2_id).count()
# 两者的交集
common = Rate.objects.filter(user_id__in=Subquery(shop1_set.values('user_id')), shop=shop2_id).values('user_id').count()
# 没有人给当前商品打分
if shop1_sum == 0 or shop2_sum == 0:
return 0
similar_value = common / sqrt(shop1_sum * shop2_sum)#余弦计算相似度
return similar_value
#基于物品
def recommend_by_item_id(user_id, k=15):
# 前三的tag,用户评分前三的商品
user_prefer = UserTagPrefer.objects.filter(user_id=user_id).order_by('-score').values_list('tag_id', flat=True)
user_prefer = list(user_prefer)[:3]
print('user_prefer', user_prefer)
current_user = User.objects.get(id=user_id)
# 如果当前用户没有打分 则看是否选择过标签,选过的话,就从标签中找
# 没有的话,就按照浏览度推荐15个
if current_user.rate_set.count() == 0:
if len(user_prefer) != 0:
shop_list = shop.objects.filter(tags__in=user_prefer)[:15]
else:
shop_list = shop.objects.order_by("-num")[:15]
print('from here')
return shop_list
# most_tags = Tags.objects.annotate(tags_sum=Count('name')).order_by('-tags_sum').filter(shop__rate__user_id=user_id).order_by('-tags_sum')
# 选用户最喜欢的标签中的商品,用户没看过的30部,对这30部商品,计算距离最近
un_watched = shop.objects.filter(~Q(rate__user_id=user_id), tags__in=user_prefer).order_by('?')[:30] # 看过的商品
watched = Rate.objects.filter(user_id=user_id).values_list('shop_id', 'mark')
distances = []
names = []
# 在未看过的商品中找到
for un_watched_shop in un_watched:
for watched_shop in watched:
if un_watched_shop not in names:
names.append(un_watched_shop)
distances.append((similarity(un_watched_shop.id, watched_shop[0]) * watched_shop[1], un_watched_shop))#加入相似的商品
distances.sort(key=lambda x: x[0], reverse=True)
print('this is distances', distances[:15])
recommend_list = []
for mark, shop in distances:
if len(recommend_list) >= k:
break
if shop not in recommend_list:
recommend_list.append(shop)
# print('this is recommend list', recommend_list)
# 如果得不到有效数量的推荐 按照未看过的商品中的热度进行填充
print('recommend list', recommend_list)
return recommend_list
if __name__ == '__main__':
# similarity(2003, 2008)
print(recommend_by_item_id(1799))

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)