RAG(检索增强生成Retrieval-Augmented Generation)
RAG(检索增强生成,Retrieval-Augmented Generation):是一种融合“”与“”的技术范式。其核心逻辑为:当用户提出问题时,系统先从预设的知识库中检索与问题高度相关的精准信息,再将这些信息作为上下文输入大语言模型,最终生成基于权威知识、无幻觉的回答。RAG 的思路是:不让模型“凭空记忆”,而是检索到相关文档片段,再让模型引用它们回答。RAG = 先检索资料,再让大模型基于
一:简介
RAG(检索增强生成,Retrieval-Augmented Generation):是一种融合“外部知识检索”与“大语言模型生成”的技术范式。其核心逻辑为:当用户提出问题时,系统先从预设的知识库中检索与问题高度相关的精准信息,再将这些信息作为上下文输入大语言模型,最终生成基于权威知识、无幻觉的回答。
大模型有三个天然问题:
- 知识更新慢:训练数据有截止时间。
- 幻觉:会编造看似合理但不存在的内容。
- 上下文有限:你不可能把所有资料都塞进对话。
相较于传统大模型,RAG具备三大核心优势:
- 解决知识时效性问题,可通过更新知识库同步最新信息。
- 提升回答精准度,依托指定知识库确保内容符合业务规范。
- 降低幻觉风险,避免模型编造无依据信息,尤其适用于企业客服、内部培训等对信息准确性要求极高的场景。
RAG 的思路是:不让模型“凭空记忆”,而是检索到相关文档片段,再让模型引用它们回答。
RAG = 先检索资料,再让大模型基于资料生成答案。
一句话:让大模型回答“有据可依”。
二:知识库设置
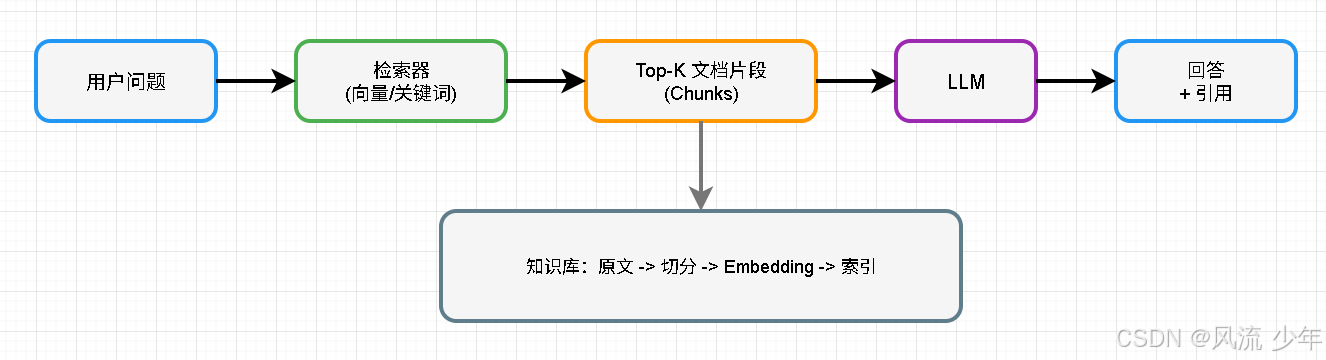
创建知识库分为3个步骤:
- 数据:一堆 PDF/网页/文档
- 处理:抽取文本 → 切分 → 生成 embedding → 存向量库
- 询问:用户问题 → embedding → 检索 Top‑K → 组装 prompt → LLM 输出“答案+引用”
2.1 切分(Chunking)- 分段设置
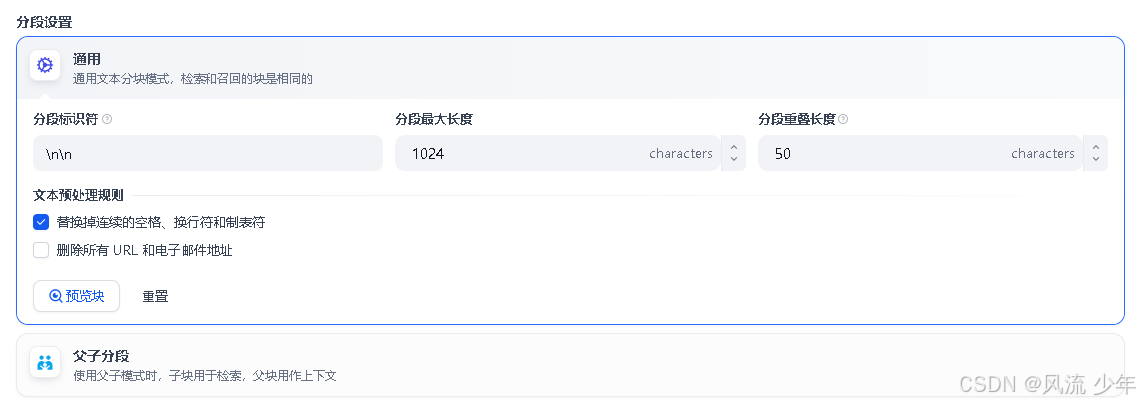
切分是把原始文档按一定规则拆成一段一段更小的文本块(chunk),再对这些块做embedding、建索引、召回。
如果不切分,整篇文档太长,通常会有几个问题:
- 向量表示过于粗糙,一篇里混了很多主题,检索不准。
- 检索命中后上下文太大,塞给 LLM 成本高。
- 很多问题只和文档里的局部内容有关,没必要把整篇都拿出来。
为什么要切分?切分的目标本质上是平衡两件事:
- 每个 chunk 要足够小,便于精准检索。
- 每个 chunk 又要足够完整,不能把一个意思拆碎。
一个好的 chunk,应该尽量满足:
- 语义完整
- 主题单一
- 长度适中
- 和相邻内容保留一定上下文关系
常见切分方式:
1. 固定长度切分
按字符数、token 数直接切,比如每 500 token 一段。
优点:实现最简单、处理速度快、适合大规模预处理
缺点: 容易把一句话、一个段落、一个表格切断,语义边界不自然,召回质量一般
2. 固定长度 + 重叠(这是很多 RAG 系统默认的入门方案)
例如每段 500 token,重叠 100 token。
优点:缓解“关键信息刚好被切断”的问题,对问答场景通常比纯固定切分更稳
缺点:索引数据变多,检索结果可能更重复
3. 按结构切分
根据文档天然结构拆分,比如:标题、小节、段落、列表、表格、代码块
优点:更符合语义边界、检索质量通常更好、适合技术文档、说明书、知识库
缺点:需要先识别文档结构、对格式混乱的文本效果不稳定
4. 语义切分
根据语义变化来决定切分点,比如主题变了就切一段。
优点:最接近“按意思切”、对长文、多主题文本更友好
缺点:实现复杂、预处理成本高、有时不如结构化规则稳定
5. 分层切分
先粗切,再细切。比如:先按章节切再按段落或 token 切。
这在复杂知识库里很常见,适合做多级检索。
切分参数
chunk size 每个块多大
太小:检索精确,但上下文不完整,太大:上下文完整,但主题可能混杂,召回变差。经验上常见范围:
- 200-800 tokens 比较常见
- FAQ、短知识点:可以更小
- 技术说明、法务、论文:可以稍大
chunk overlap 相邻块之间重复多少内容
作用:防止一个句子/概念跨块断裂
常见经验:10%-20% 的 overlap 比较常见。例如 500 token chunk + 50~100 token overlap
切分边界
优先按这些边界切:标题、段落、句号、列表项、代码块边界、表格边界
尽量避免硬切在:半句话中间、表格中间、一段代码中间、定义和解释之间。
退款规则:
1. 用户在7天内可申请退款。
2. 超过7天但未使用服务,可部分退款。
3. 已开票订单退款需要额外审核。
如果整段作为一个 chunk,问题不大;但如果文档很长,这段可能被埋在大段文本中。切分后可能变成:
Chunk 1:
退款规则:
1. 用户在7天内可申请退款。
2. 超过7天但未使用服务,可部分退款。
Chunk 2:
2. 超过7天但未使用服务,可部分退款。
3. 已开票订单退款需要额外审核。
这里 Chunk 2 和 Chunk 1 有重叠,能减少边界断裂问题。不同内容类型的切分建议:
- 文本说明类:适合按段落/标题切、再补少量 overlap
- FAQ / 知识问答:适合一问一答作为一个 chunk,不要把多个问题混成一块
- API 文档 / 技术文档:适合按接口、类、方法、配置项切,保留参数说明和示例在同一个 chunk
- 代码 适合按函数、类、文件结构切,不建议纯按字符数切函数签名、注释、实现最好放一起
- 表格:适合尽量整表保留,如果表太大,可按行组切,但要重复表头
Chunking 对效果有着直接的影响:检索召回率、检索精度、上下文是否完整、LLM 回答是否“答非所问”、成本和延迟,
很多 RAG 效果差,不一定是模型不行,而是切分没做好。常见问题有:
- chunk 太大,召回不精准
- chunk 太小,信息不完整
- 没有 overlap,边界断裂
- 把不同主题混在一个 chunk 里
- 元数据没保留,导致无法过滤
实践建议,一个比较稳妥的默认策略是:
- 优先按文档结构切
- 单块控制在 300-600 tokens
- 加 50-100 tokens overlap
- 为每个 chunk 保留元数据
常见元数据包括:文档名、章节标题、页码、来源 URL、chunk 序号、上下文路径
Chunking 不是简单“把文本切小”,而是把知识切成“既能被准确检索、又足够保留语义”的最小可用单元。
2.2 Embedding 模型
Embedding 模型的作用是把文本变成“可计算的语义向量”,让系统能按“意思相近”而不是只按“关键词相同”去检索内容。
Embedding 模型本身通常“不负责回答问题”,而是负责“找到最相关的上下文”。
RAG 通常分两步:
- 离线建库:把知识库里的文档、段落、表格说明等切分后,用 Embedding 模型转成向量,存进向量库。
- 在线检索:用户提问后,也先用同一个 Embedding 模型把问题转成向量,再去向量库里找最相似的内容,最后把召回结果交给大模型生成答案。
一个典型流程是:
- 文档切 chunk
- 用 Embedding 模型生成向量
- 存入向量数据库
- 用户提问后生成 query 向量
- 相似度检索 TopK
- 可选 rerank
- 把结果交给 LLM 回答
它到底做了什么?
比如这两句话:“如何申请报销?”“费用报销流程怎么走?”,虽然字面不同,但语义接近。Embedding 模型会把它们映射到向量空间中比较接近的位置,因此系统可以把相关文档检索出来。
Embedding 模型会直接影响:召回准确率、相关片段排序效果、最终答案质量,如果检索阶段拿错了内容,后面的生成模型再强,也容易“基于错误上下文一本正经地回答”。所以很多 RAG 项目里,真正决定效果上限的,往往不只是生成模型,还包括:文档切分策略、Embedding 模型、检索/重排策略。
它和大语言模型的区别:
- Embedding 模型:负责“表示”和“检索”
- LLM / 大模型:负责“理解上下文并生成答案”
前者像“找资料”,后者像“看资料后作答”。
2.3 检索方式
向量检索
向量检索(Vector Search)的做法是:
- 先把文档 chunk 转成向量(embedding)
- 把用户问题也转成向量
- 在向量空间里计算“距离”或“相似度”
- 找出最接近的几个 chunk
它擅长什么?
它擅长找“语义相近”的内容,而不是只看字面是否一致。比如用户问:“怎么取消订单?”文档里写的是:“订单提交后可发起撤销申请”,虽然“取消订单”和“撤销申请”字面不同,但语义接近,向量检索更容易召回。
优点:能处理同义词、近义表达,对自然语言问法更友好,适合 FAQ、知识库、说明文档、长文本问答
缺点: 对精确关键词不一定稳定, 对代码、ID、错误码、版本号、专有名词可能不够敏感, 检索结果有时“看起来相关”,但不够精确
适用场景: 用户提问比较自然、文档以说明性文本为主,需要语义理解而不是纯关键词匹配。
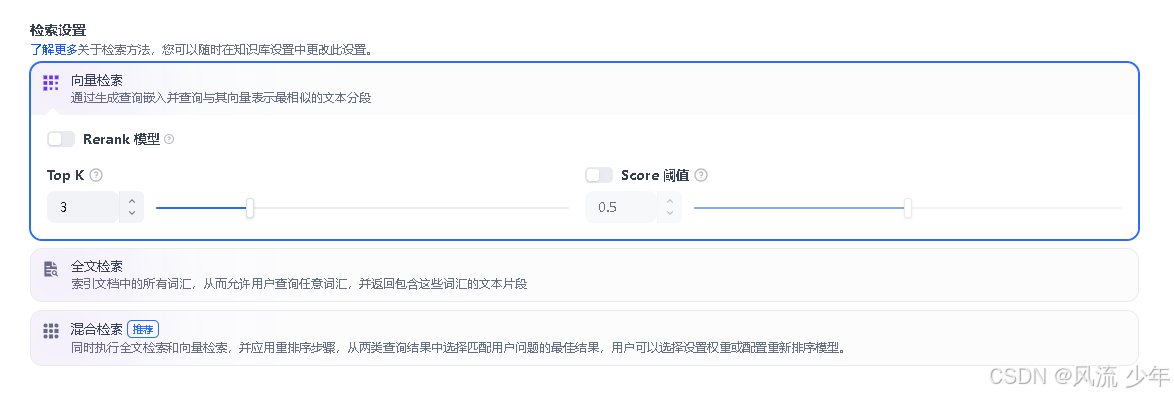
Top-K
用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整分段数量。
Score 阈值
score本质上是“结果和查询相关程度的排序分”,score 阈值 就是用来裁掉低相关结果的门槛。
设置 score threshold,本质是为了过滤掉“看起来不够相关”的结果。比如:
- 只保留 score >= 0.75 的向量结果
- 只返回 BM25 命中分超过某个值的文档
- 只把 rerank 后分数高于阈值的 chunk 送给 LLM
假设用户问:“员工差旅报销需要哪些材料?”混合检索后返回:
- 文档A:score 0.91
- 文档B:score 0.84
- 文档C:score 0.62
- 文档D:score 0.31
如果阈值设成 0.8,只保留 A 和 B。意思不是说:A 有 91% 概率正确,B 有 84% 概率正确
而是说:在当前这套检索和融合规则下,A/B 被认为和 query 更相关,C/D 相关性偏弱。
它的目的通常有几个:
- 减少低质量召回
- 降低无关上下文干扰
- 控制送给 LLM 的 token 成本
- 降低答非所问和幻觉风险
一般是将Top-K 和 Score结合使用,如TopN + score threshold 先取前K条,再过滤低分结果。
Rerank 模型
就是 RAG 里的“精排器”: 先让检索器广泛找,再让它把最相关的内容重新排序,从而把更准的上下文交给大模型回答。把搜索分成两个阶段,第一个阶段是向量检索更像是“粗筛”、第二个阶段是Rerank 更像是“精排”。
一个典型 RAG 流程通常是:
- 用户提问
- 检索器先召回一批候选内容 例如通过向量检索、BM25、混合检索拿到 Top 20 / Top 50
- Rerank 模型对这批候选重新打分排序
- 选出前几条高质量上下文
- 把这些上下文交给 LLM 生成答案
所以它解决的是:
- 初次召回“有点相关但不够准”
- 检索结果顺序不理想
- 上下文窗口有限,必须把最有价值的内容排前面
一个直观例子:
用户问:“合同审批超时后,系统会触发什么状态流转?”第一轮检索可能找回很多包含“合同”“审批”“状态”的段落,但不一定最关键。这时 rerank 会更倾向把真正回答“超时后状态如何变化”的段落排到前面,而不是只在词面或语义上接近的泛说明文档。
常见使用方式:
- 先用向量检索召回 Top 50
- 再用 rerank 排序
- 最后取 Top 5 给 LLM
有时也会混合: - 全文检索 + 向量检索做混合召回
- 然后统一用 rerank 精排
全文检索
全文检索(Full-text Search / Keyword Search)它主要看的是:词有没有出现、出现了多少次、位置是否重要。做法是:
- 建立倒排索引
- 按关键词、词频、字段权重等规则检索
- 常见算法如 BM25
它擅长什么?它擅长找“字面命中”的内容。比如用户搜:ERR_403_TOKEN_EXPIRED、invoice_no、小米SU7 Pro这种带精确术语、代码符号、字段名、错误码的查询,全文检索通常更稳。
优点:对精确关键词很强,可解释性好,为什么命中比较直观,对术语、型号、API 名、代码符号、表名、错误码效果好
缺点: 不理解语义,同义词改写后容易漏召回,用户表达和文档措辞不一致时,效果可能差
适用场景:
- 搜字段名、函数名、类名、报错码、订单号
- 搜法规条款编号、产品型号、专有术语
- 搜代码和技术文档
混合检索
混合检索(Hybrid Search)就是把:向量检索的语义能力、全文检索的精确匹配能力组合起来一起用。它的目标是:既能理解意思,又不丢精确命中。
常见做法
方式一:两路召回,再合并
一路跑向量检索,一路跑全文检索,合并结果,去重、打分、排序
方式二:加权打分 Score
给每条结果同时计算:向量相似度分数、BM25 / 关键词命中分数再做加权融合,比如:
final_score = 0.6 * vector_score + 0.4 * keyword_score
方式三:召回 + 重排
先用向量检索和全文检索各召回一批,合并候选集,再用 reranker 做精排,这是很多效果较好的 RAG 系统常用方案。
优点:
- 兼顾语义匹配和精确匹配
- 通常比单独用一种检索更稳
- 对真实业务问题适应性更强
缺点:
- 系统复杂度更高
- 需要调权重、去重、融合策略
- 成本和延迟可能略高
适用场景:既有自然语言提问,也有精确术语查询的场景
- 企业知识库
- 技术支持系统
- 文档问答 + 代码检索
三种方式的直观对比
向量检索:关注点“意思像不像”, 适合问题:
- “怎么开票?”
- “退款规则是什么?”
- “为什么会审核失败?”
全文检索:关注点“词有没有出现”,适合问题:完全匹配的关键词
混合检索:关注点“意思像不像” + “词有没有命中”
适合问题:
- “SAP 推送失败的错误码怎么处理?”
- “贴息任务 createSAPJobTask 为什么没生成?”
- “invoiceNumber 字段是从哪里来的?”
这类问题既有语义,又带技术关键词,混合检索通常最好。
一句话总结:
- 向量检索:按“语义相似”找内容
- 全文检索:按“关键词命中”找内容
- 混合检索:把两者结合,兼顾理解能力和精确命中
一个常见的推荐架构:
- 文档切分成 chunks
- 每个 chunk 建两类索引:向量索引、全文索引
- 用户提问后,两路并行召回
- 合并候选结果
- 用 reranker 精排
- 取 Top-N 给 LLM 生成答案
三:RAG 工程落地的 5 个关键点(最常踩坑)
- 切分(Chunking)策略:太短缺上下文,太长检索不准。
- 检索(Retrieval)策略:向量检索 + 关键词检索往往要混合。
- Top‑K 与重排(Rerank):K 太小漏信息,太大浪费 token;重排能显著提升相关性。
- 引用与拒答:强制“带引用”,检索不到就拒答/追问。
- 评测:用固定问题集做回归,不然越改越坏。
四:适合用 RAG 的场景
RAG通常适用于专业性强的领域,不太适合纯创作型(小说)或没有明确资料来源的主观问题。
- 企业知识库问答(制度/流程/产品文档)
- 技术支持与客服(FAQ + 文档引用)
- 代码/仓库问答(README、接口文档、PRD)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)