从只会聊天到真正干活:一个客服助手带你理解 LLM 到 Agent 的完整进化
本文通过智能客服案例,系统解析AI从LLM到Agent的进化过程。先介绍LLM的局限性及如何通过Prompt、RAG、Context等技术使其成为"合格客服";再阐述Agent如何通过Tools、Orchestration、Memory等组件实现从"只会说"到"能做事"的跨越;最后介绍Agent能力分级和技术演进路径,帮助读者建立清晰的AI认知框架,掌握从基础模型到智能应用的完整技术脉络。
给 AI 初学者的系统性指南:用一个客服助手的故事,看懂从 LLM 到 Agent 的完整进化
写在前面
如果你是刚接触 AI Agent 的产品经理,可能会被一堆术语搞得晕头转向:LLM、Prompt、RAG、Agent、上下文、记忆、编排……这些词到底是什么意思?它们之间又是什么关系?
这篇文章会用一个你熟悉的场景——智能客服助手——带你从零开始,看看 AI 是如何一步步从“只会聊天”进化到“真正能干活”的。
读完这篇文章,你会清楚地理解:
- LLM 和 Agent 的本质区别
- Agent 的核心组成部分(大脑、双手、神经系统)
- 什么时候该用 Agent,什么时候不该用
- Agent 在真实世界中如何运作
更重要的是,你会建立起一个清晰的认知框架,不再被各种新概念搞晕。
我们先从最简单的聊天机器人开始。
1.只会说话的新员工(LLM)
1.1 什么是 LLM?
LLM(Large Language Model,大语言模型) ——它就像一个读过海量书籍的聪明人,它能理解你的问题,用自然语言回答你。
假设你是一家电商公司的产品经理,老板让你做一个智能客服。如果你直接接入了 LLM,那它会基于**训练时学到的知识乱说,**一会儿像百科,一会儿像网友。
所以在他上岗之前,需要给他一个“岗位说明书”
1.2 Prompt Engineering - “写一本详细的工作手册”
于是你给它写了一段Prompt(提示词),就像给新员工的工作手册。
Prompt 就是你给 LLM 的指令和背景信息,告诉它应该扮演什么角色、遵循什么规则。
你是 XX 电商的客服助手。
【公司政策】
- 退货政策:7天无理由退货,需保持商品完好
- 运费规则:满99元包邮
- 会员权益:会员享受95折优惠
【回答规则】
1. 态度友好,称呼用户为"亲"
2. 不确定的信息不要编造,告诉用户"我帮您查一下"
3. 复杂问题转人工客服
4. 请用友好、专业的语气回答用户问题
用户问题:{用户问题}
当用户再问时,LLM 就能以一个客服的身份和要求回答问题了
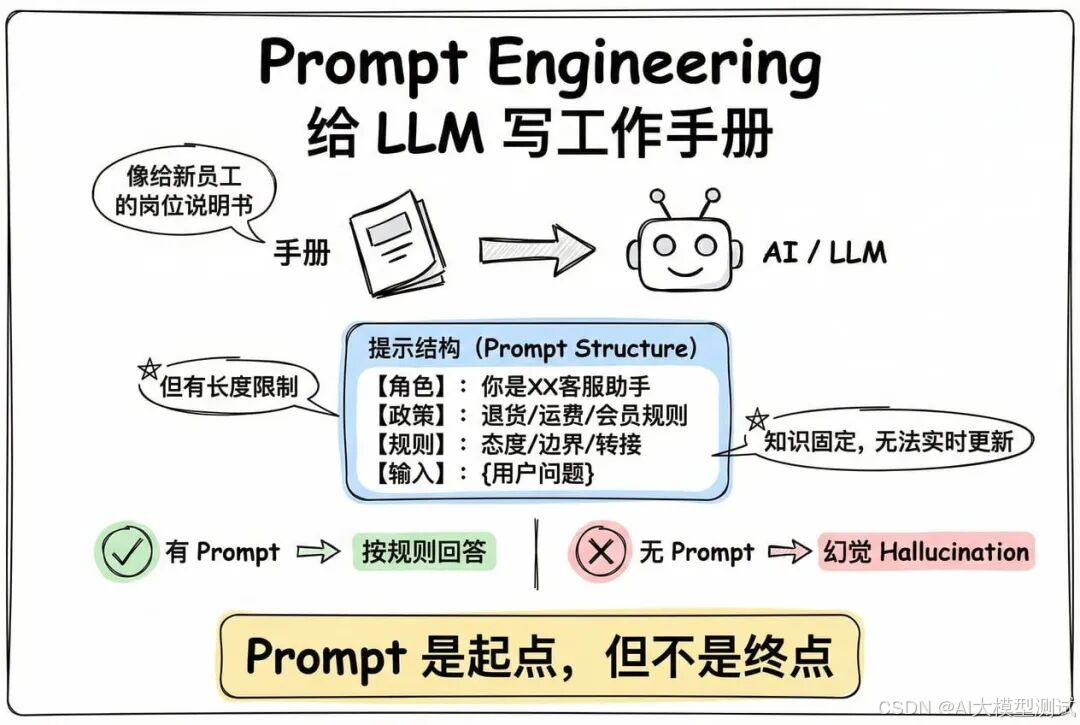
但新问题来了:但 LLM 的知识是固定的,Prompt 又有长度限制(通常几千字),你不可能把所有公司信息都塞进去。而且,公司的产品信息、订单数据每天都在变化,你总不能每天改 Prompt 吧?
如果你提问的问题 LLM不知道,Prompt 也没有涉及,那它就会一本正经的胡说八道。LLM就会出现幻觉(Hallucination)

1.3 RAG - “给它一个可以随时查的知识库”
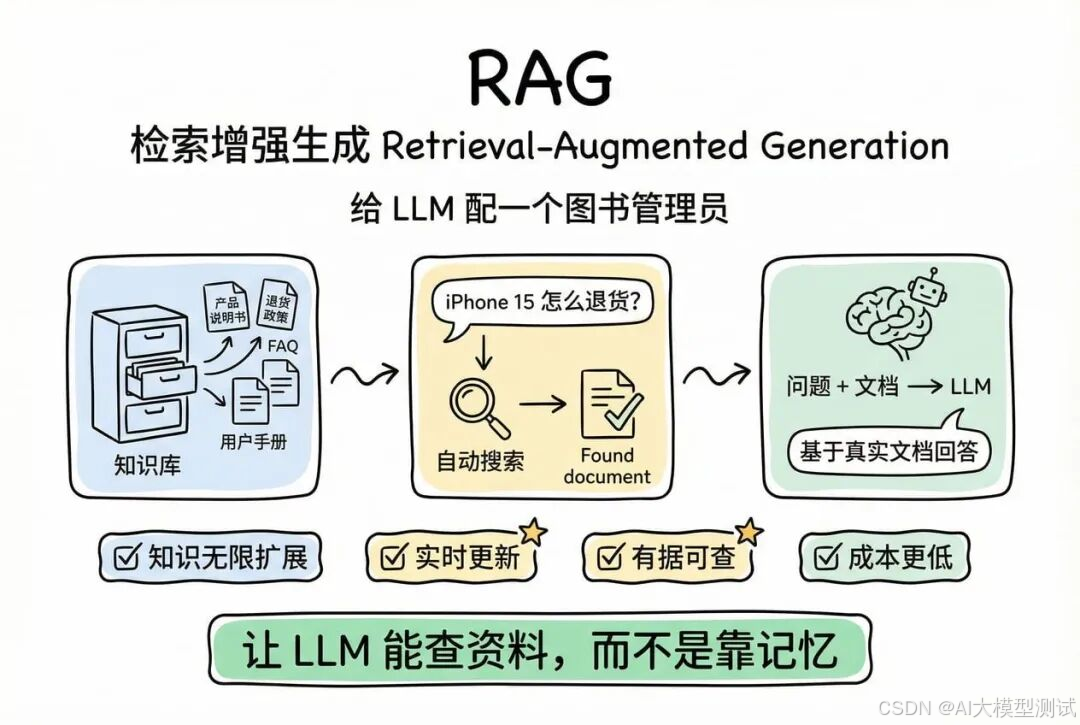
什么是 RAG?RAG(Retrieval-Augmented Generation,检索增强生成)就像给 LLM 配了一个图书管理员。当用户提问时,系统先去公司的知识库里搜索相关信息,然后把搜到的内容和用户问题一起交给 LLM,让它基于这些实时信息来回答。
你把所有公司文档放进知识库
- 产品说明书
- 退货政策
- FAQ
- 用户手册
2. 用户提问时:
用户:"iPhone 15 怎么退货?"
↓
系统自动搜索知识库
↓
找到相关文档:"iPhone 15 退货政策.pdf"
↓
把文档内容和用户问题一起给 LLM
↓
LLM 基于真实文档回答
3. LLM:"iPhone 15 支持7天无理由退货……"
RAG 的核心价值:
- 知识可以无限扩展
- 更新文档就自动更新知识
- 回答有据可查,不会乱编
- 成本更低(不用重新训练模型)
1.4 Context - “给它一个记事本”
我们先不管这个术语,先看它解决了什么问题。
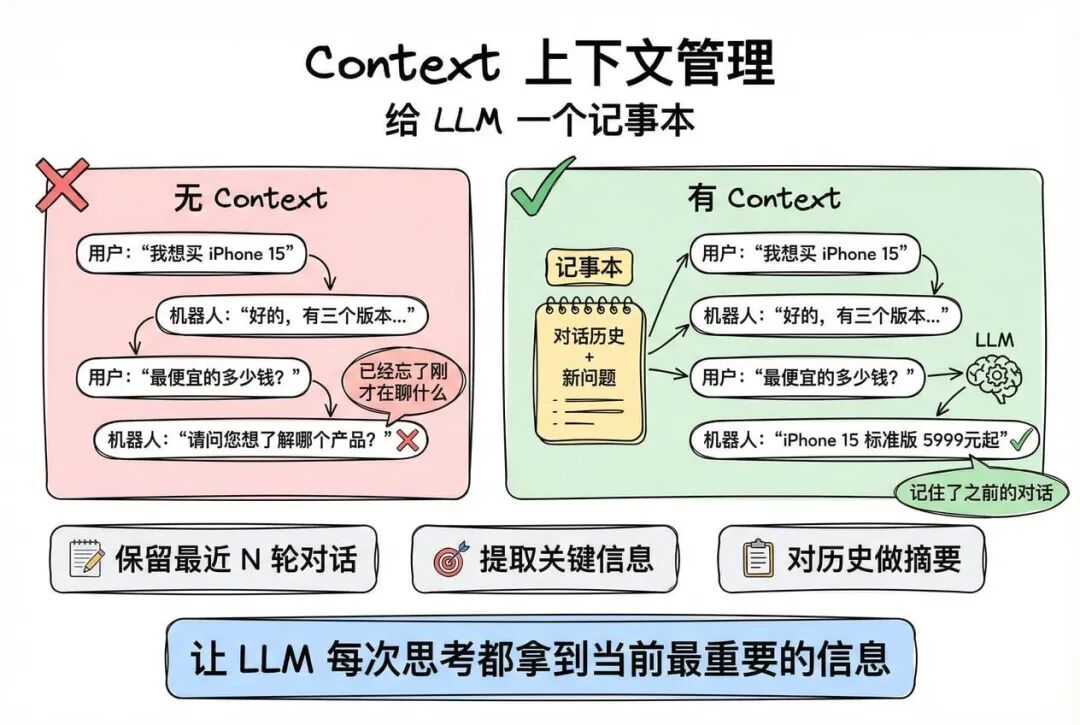
用户:"我想买 iPhone 15"
机器人:"好的,iPhone 15 有三个版本……"
用户:"最便宜的多少钱?"
机器人:"请问您想了解哪个产品的价格?"(已经忘了刚才在聊 iPhone)
Context简单说,就是管理对话历史,让 LLM“记住”之前说了什么。就像给它一个记事本。
有 Context 管理:
【对话历史】
用户:"我想买 iPhone 15"
机器人:"好的,iPhone 15 有三个版本……"
用户:"最便宜的多少钱?"
↓
系统把对话历史一起给 LLM:
- 用户之前说想买 iPhone 15
- 现在问最便宜的多少钱
↓
机器人:"iPhone 15 标准版 5999 元起"
本质上,这一步是在帮 Agent 每一次思考,都拿到“当前最重要的信息”。
常见策略:
- 只保留最近 N 轮对话
- 提取关键信息(比如用户意图、订单号)
- 对历史对话做摘要
这三个真实场景,暴露了纯 LLM 的三大致命问题:
- **没有限制乱发挥:**只会说话没有经过岗位培训的新员工
- **知识过时:**只知道训练时学到的“通用知识”,不知道公司的真实政策、最新产品、库存情况
- **没有记忆:**每次对话都是全新的,不记得上一次说了什么,多轮对话体验很差
通过这3个工具,让 LLM 从“只会背书”变成“会查资料的客服”
- **Prompt Engineering:**给 LLM 明确的角色和规则
- **RAG:**让 LLM 查询大量外部知识
- **Context:**管理多轮对话历史,补充多轮对话的重要内容
你的助手已经是一个“合格的客服”了:
- 知道公司政策
- 能查资料
- 能理解上下文
- 不会乱编
但它还不是 Agent!
为什么?因为它只能“回答问题”,不能“执行操作”。
LLM 和Agent真正的分水岭,是它能不能替你做事。
2. 能真的帮你办事的员工(Agent)
2.1 给它“双手”(Tools)
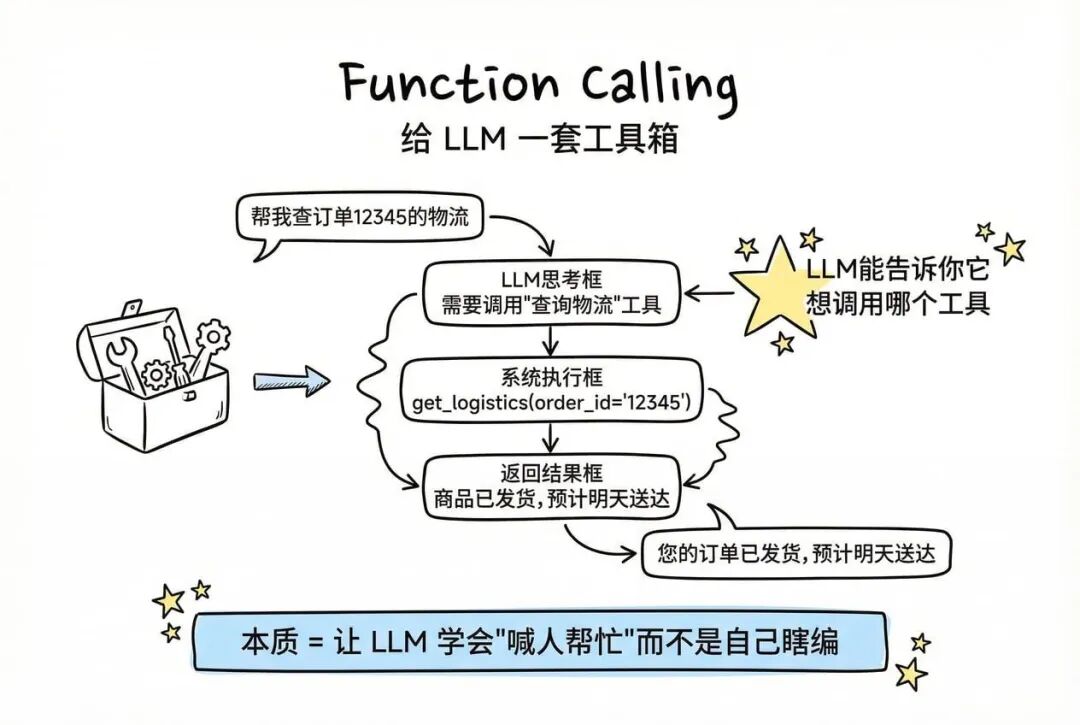
如果用户说"帮我查一下我的订单",这需要真正去调用订单系统的 API,而不只是查知识库。
Tools(工具)——简单说,Tool 就像给 LLM 配了一套工具箱:查订单、退款、修改地址、发优惠券……每个工具都是一个可以执行的功能。
用户:"帮我查一下订单 12345 的物流"
LLM 判断:需要调用"查询物流"工具
系统调用:get_logistics(order_id="12345")
返回结果:商品已发货,预计明天送达
LLM 整理回复:"您的订单已发货,预计明天送达,快递单号是 SF1234567890。"
tool调用的关键技术: Function Calling
这个术语听起来很技术,但本质很简单:LLM 现在能“告诉你它想调用哪个工具”。
这就是 LLM 和 Agent 的本质区别:
-
LLM - 只能“说”,像一个顾问。你问它问题,它给你建议,但不会帮你执行。
Agent - 能“说”也能“做”,像一个员工。它不仅告诉你怎么办,还能真的帮你办了。
| 维度 | LLM | Agent |
|---|---|---|
| 能力 | 只能“说” | 能“说”也能“做” |
| 类比 | 顾问 | 员工 |
| 工具 | 无 | 有(API、数据库等) |
| 自主性 | 被动回答 | 主动执行任务 |
2.2 给它“神经系统”(Orchestration)
现在 Agent 有“大脑”(LLM)和“双手”(Tools)了,但还缺一样东西:怎么协调它们?
Orchestration(编排) ——就是让 Agent 能“像人一样做事”:先想想怎么做,再一步步执行。
业界形成了 6 类主流编排模式,从「最可控」到「最灵活」:
- 顺序编排(Chain / Workflow)
- 条件路由(Router)
- Planner → Executor(计划-执行)
- ReAct(思考-行动循环)
- Orchestrator → Workers(调度-工人)
- 多 Agent 协作(Role-based / Debate / Team)
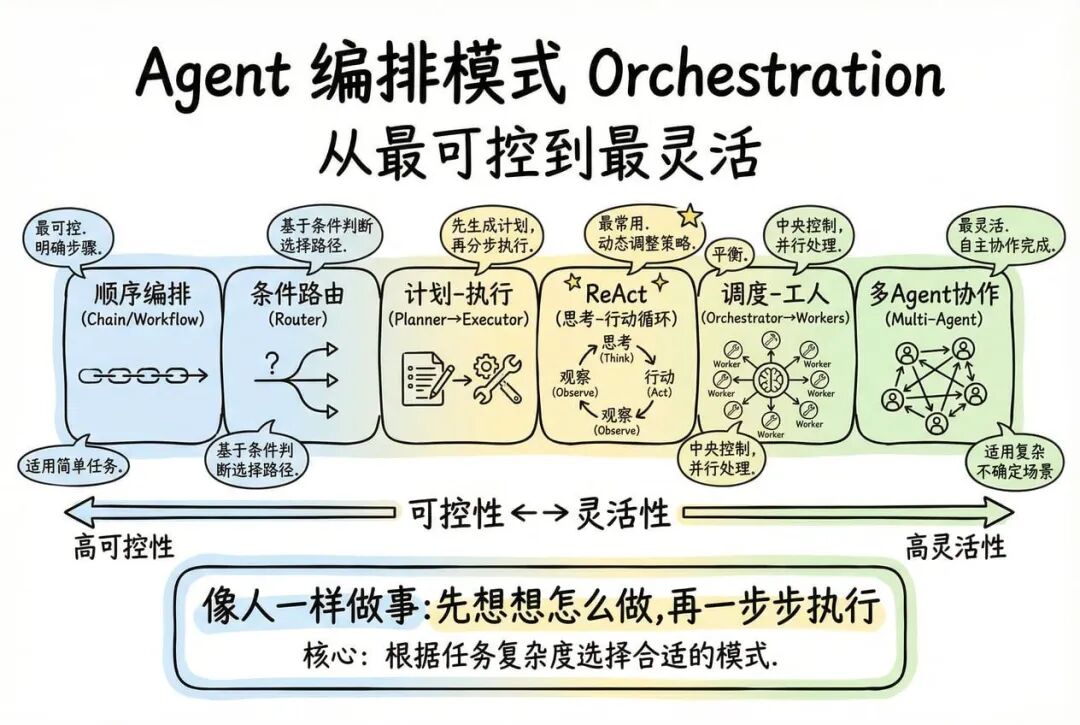
核心模式: ReAct(Reason + Act)
ReAct ——这个模式在学术上叫 ReAct(Reason + Act),但本质上,这一步是在让 Agent “像人一样做事”。
工作流程:
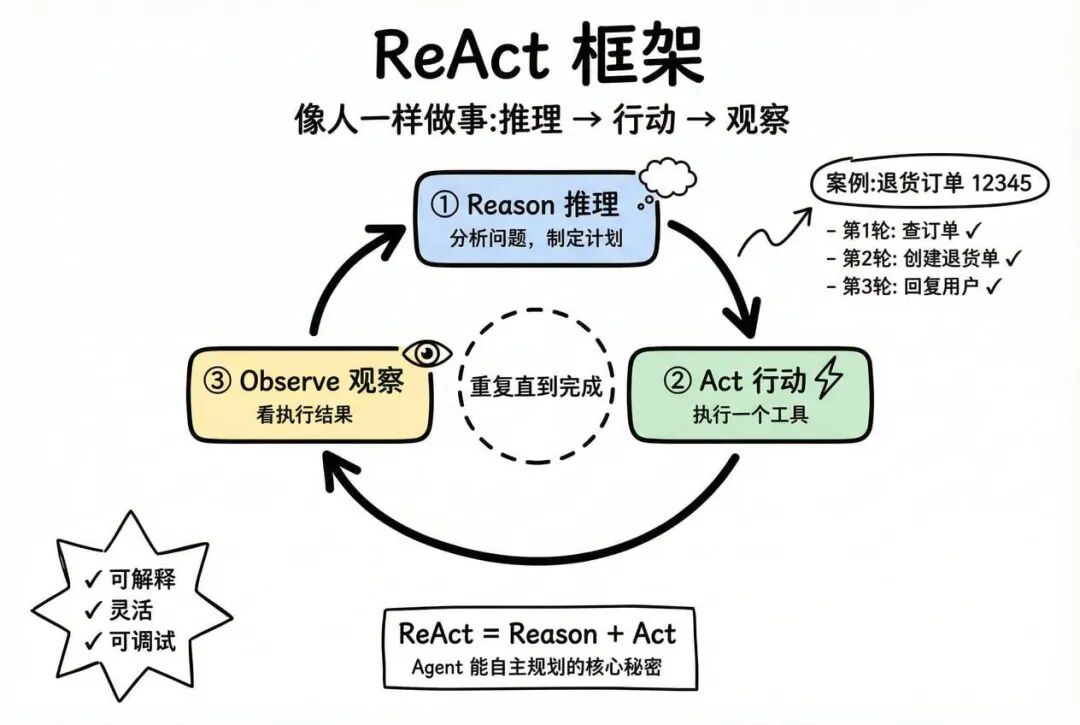
实际案例:
用户:"帮我退货,订单号 12345"
【第 1 轮】
Reason:"我需要先查订单信息,确认能否退货"
Act: 调用 query_order(12345)
Observe: 返回 {"status": "已签收", "can_refund": true}
【第 2 轮】
Reason:"订单可以退货,现在创建退货单"
Act: 调用 create_refund(12345)
Observe: 返回 "退货单已创建,退货单号 R789"
【第 3 轮】
Reason:"任务完成,告诉用户"
Act: 回复用户
Observe: 完成
为什么 ReAct 重要?
- 可解释:每一步的思考过程都看得见
- 灵活:可以根据中间结果动态调整
- 可调试:出错了能看到是哪一步出了问题
2.3 给它“记忆”(Memory)
Memory(记忆) ——是让 Agent 记住重要信息,不用每次都重新问。
两种记忆:
短期记忆(Short-term Memory)
- 只记住当前对话
- 对话结束就清空
长期记忆(Long-term Memory)
- 跨对话的持久化信息
- 比如用户偏好、历史行为
- 永久保存
Memory 是 Agent 从“工具”变成“伙伴”的关键 - 有记忆的 Agent 能理解你,提供个性化服务。
2.4 Context Engineering(上下文工程) - “动态组装信息”
每次 Agent 思考时,需要把所有相关信息组装成一个“完整的上下文”:
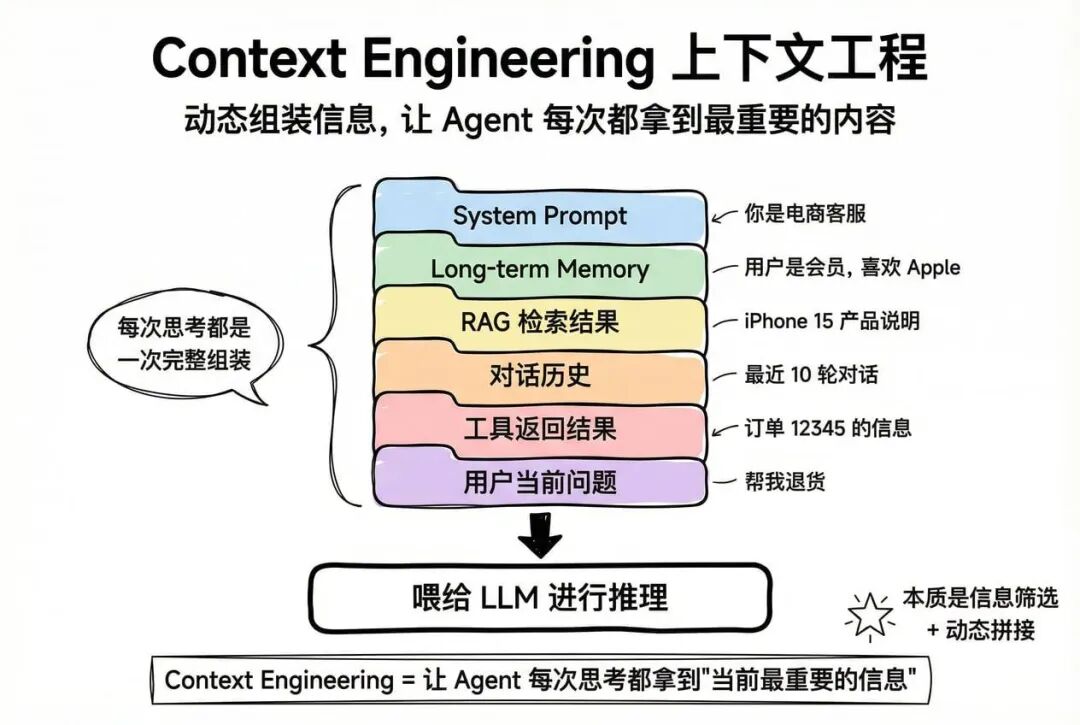
2.5 Agent 的完整架构
现在,我们可以画出 Agent 的完整架构了:
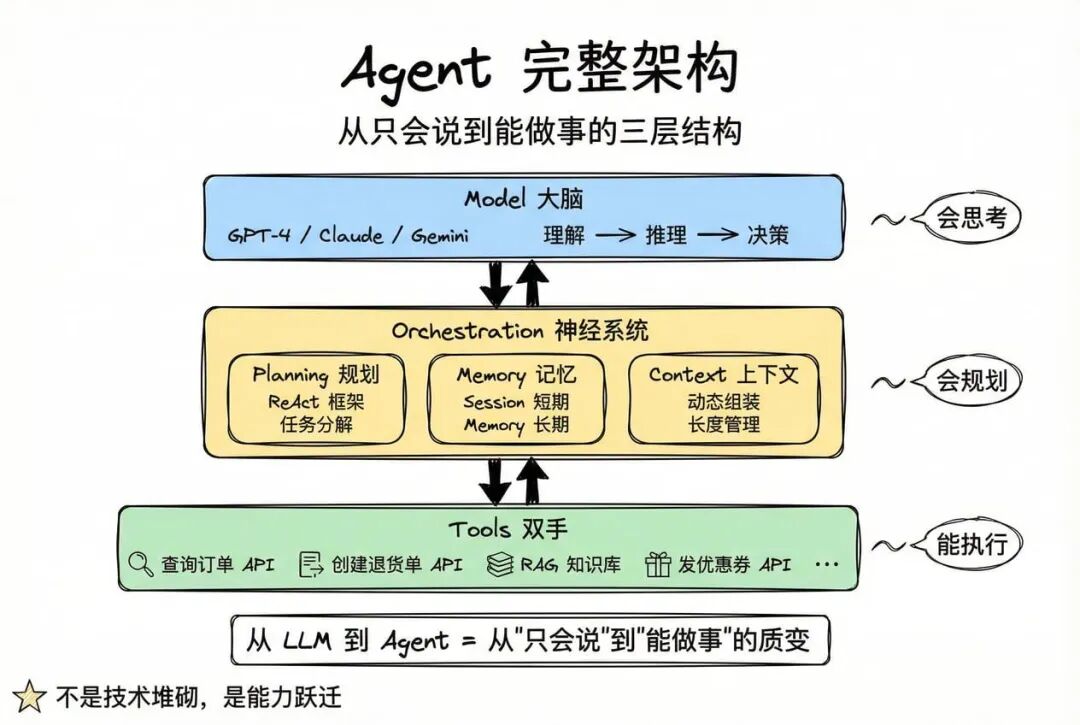
现在你的客服助手已经是一个真正的 Agent 了!
它能:
- 理解用户意图(LLM)
- 查询知识库(RAG)
- 记住对话历史(Context)
- 记住用户偏好(Memory)
- 规划多步骤任务(Planning)
- 调用工具执行操作(Tools)
从 LLM 到 Agent,本质上是从“只会说”到“能做事”的跨越。这不是技术的堆砌,而是能力的质变。
3. 从新手到专家的能力分级
你的 Agent 上线了,效果不错。但老板又问:“别的公司的 Agent 能做什么?我们处于什么水平?”
这就需要了解 Agent 能力分级 了。
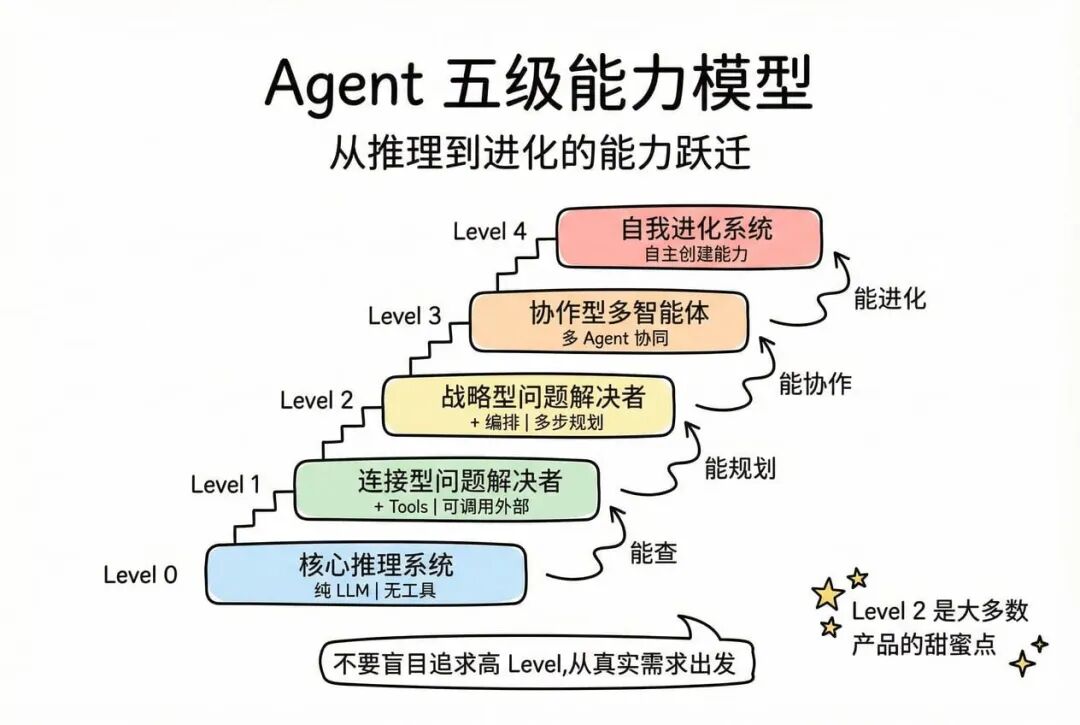
Google 五级能力模型
Level 0: 核心推理系统(The Core Reasoning System)-这是你的第一个版本
- 能力:纯 LLM,没有任何工具、记忆或与外部环境的交互
- 特点:只能基于预训练知识回答问题,无法获取实时信息
- 例子:可以解释棒球规则和洋基队历史,但无法回答"昨晚洋基队比赛结果"
Level 1: 连接型问题解决者(The Connected Problem-Solver)-这是你加了 Tools 之后的版本
- 能力:推理引擎 + 外部工具调用
- 特点:可以通过工具获取实时数据(搜索、API、数据库等)
- 例子:通过 Google Search API 查询昨晚的比赛结果并回答
Level 2: 战略型问题解决者(The Strategic Problem-Solver)-这是你加了编排能力后的版本
- 能力:多步规划 + 上下文工程(Context Engineering)
- 特点:能够规划复杂的多步骤任务,主动选择和管理相关信息
- 例子:找到两个地址的中点,然后在该地点搜索高评分咖啡店
Level 3: 协作型多智能体系统(The Collaborative Multi-Agent System)-需要多个 Agent 协同工作
- 能力:多个专业化 Agent 协同工作
- 特点:采用"专家团队"模式,Agent 之间相互调用,分工协作
- 例子:项目管理 Agent 将任务委派给市场研究、营销、网页开发等专业 Agent
Level 4: 自我进化系统(The Self-Evolving System)-这还在研究阶段
- 能力:自主识别能力缺口并动态创建新工具或新 Agent
- 特点:可以自主扩展能力,从固定资源使用转向主动创造资源
- 例子:项目管理 Agent 发现需要监控社交媒体情绪,自动创建一个情感分析 Agent
不要一上来就追求高Level,从用户真实需求出发,选择合适的能力层级。
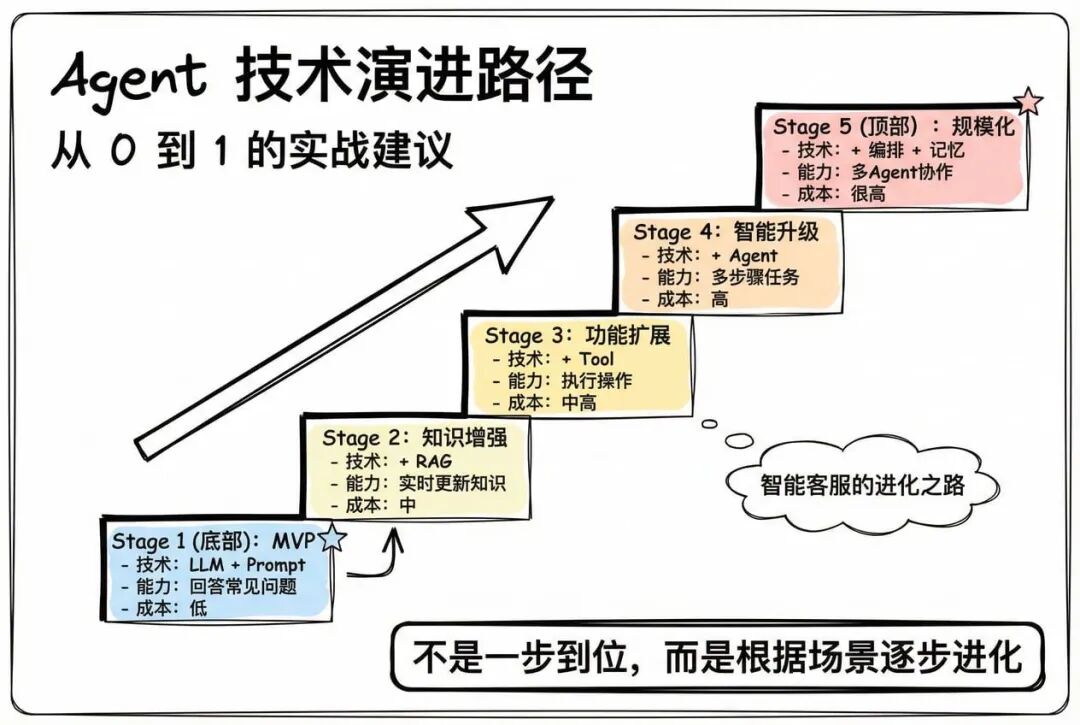
4. 技术演进路径:从 0 到 1 的实战建议
回到我们的智能客服例子,看看一个agent产品是如何一步步进化的:
第一阶段:MVP(最小可行产品)
- 技术: LLM + Prompt
- 能力:回答常见问题
- 成本:低
- 适用:验证需求,快速上线
第二阶段:知识增强
- 技术:+ RAG
- 能力:回答公司特定问题,信息实时更新
- 成本:中
- 适用:知识库丰富,需要准确性
第三阶段:功能扩展
- 技术:+ Tool
- 能力:执行操作(查订单、退款等)
- 成本:中高
- 适用:需要真正“干活”,不只是聊天
第四阶段:智能升级
- 技术:+ Agent(自主规划)
- 能力:处理复杂、多步骤任务
- 成本:高
- 适用:高价值场景,用户体验要求高
第五阶段:规模化
- 技术:+ Agent 编排 + 记忆
- 能力:多 Agent 协作,个性化服务
- 成本:很高
- 适用:企业级应用,长期用户关系
写在最后
从 LLM 到 Agent,技术在进化,但产品思维不变:
- 用户需要什么?
- 最简单的方案是什么?
- ROI 如何?
不要被术语吓到,也不要盲目追求最新技术。理解每个概念的本质,选择适合你产品的方案,才是好的产品经理。
希望这篇文章能帮你理清 AI Agent 的技术脉络。下次再听到 LLM、RAG、Agent 这些词,你就知道它们在整个拼图中的位置了。
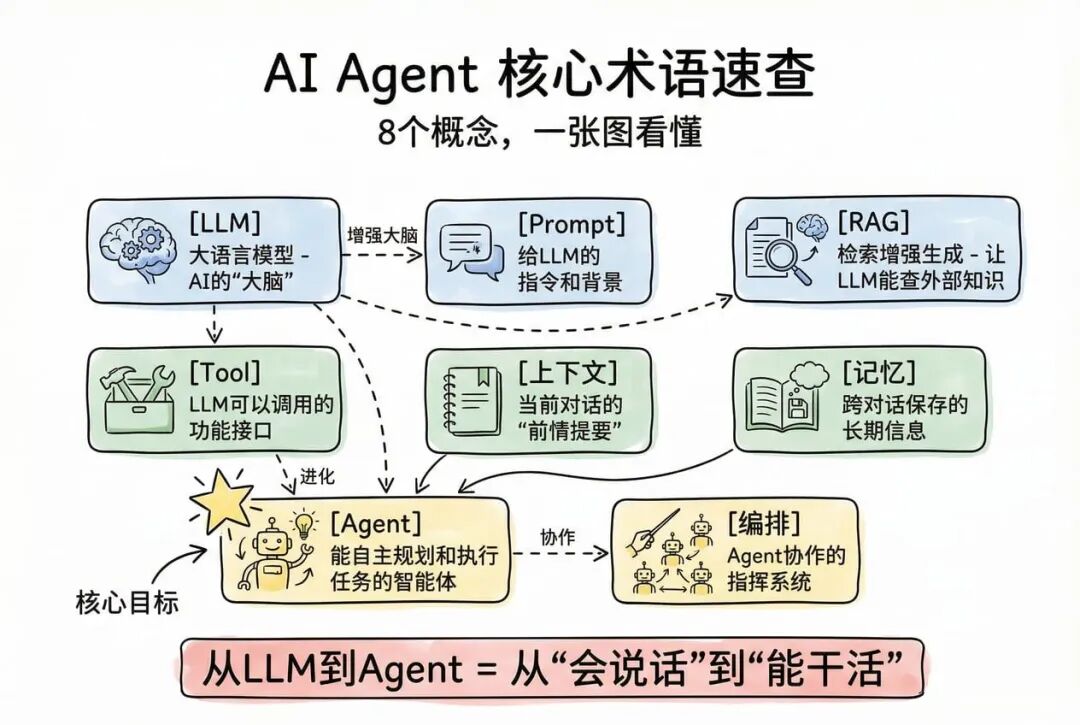
关键术语速查表
- LLM:大语言模型,AI 的“大脑”
- Prompt:给 LLM 的指令和背景
- RAG:检索增强生成,让 LLM 能查外部知识
- Tool: LLM 可以调用的功能接口
- Agent:能自主规划和执行任务的智能体
- 上下文:当前对话的“前情提要”
- 记忆:跨对话保存的长期信息
- 编排:Agent 协作的指挥系统
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献481条内容
已为社区贡献481条内容

所有评论(0)