计算机毕业设计:基于python的电商销量预测可视化系统 Django ARIMA预测 爬虫可视化 机器学习 深度学习 agent 大数据 大模型(建议收藏)✅
本文介绍了一个基于Django和ARIMA模型的淘宝商品数据分析预测系统。该系统通过requests爬虫采集淘宝商品多维数据,利用ARIMA时序模型进行销量预测,并采用多种可视化技术展示分析结果。主要功能包括:商品数据管理、价格区间分布分析、品类销量占比统计、省份商品分布热力图、价格销量关联分析以及基于ARIMA的未来销量预测。系统还提供用户注册登录、后台管理等模块,形成完整的数据分析闭环。技术栈
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈
Django框架用于Web后端开发,requests库实现淘宝商品数据自动化爬取,ARIMA时序预测模型作为核心销量预测算法,MySQL数据库负责数据存储,Python语言支撑整体开发,数据可视化技术用于图表、地图和词云的多维度展示。
功能模块
· 首页
· 数据中心
· 可视化词云图
· 商品价格区间分布
· 不同类别商品销量分布
· 商品价格与销量的关系
· 不同省份商品销量分布
· 不同省份商品数量分布
· 销量数据预测
· 后台数据管理
· 注册登录
项目介绍
本项目针对淘宝商家在电商运营中面临的销量预测滞后、库存管理失衡等实际问题,设计并实现了一套基于Django与ARIMA模型的商品数据分析预测系统。系统通过requests爬虫定向采集淘宝商品的价格、销量、省份分布等多维度数据,经清洗后存入MySQL数据库。核心功能采用ARIMA时序模型对历史销量数据进行建模分析,通过差分处理将非平稳序列转化为平稳数据,结合自回归与移动平均机制实现未来销量趋势预测。可视化层面整合地图热力图、词云、折线图、饼图等多种形式,直观呈现省份商品分布、价格销量关联、品类销量占比等分析结果。系统同时配备商品数据管理和后台管控模块,形成从数据采集、存储、分析、预测到可视化展示的完整闭环,为商家提供科学的销量预判工具和市场洞察视角,助力优化库存策略和运营决策。
2、项目界面
-
不同省份商品数量分布地图(各省份商品数量地理分布热力图)
该页面是电商网站采集分析可视化系统的不同省份商品数量分布模块,以中国地图热力图的形式直观展示各省份商品数量分布情况,同时左侧菜单栏还提供了首页、数据中心、可视化词云图、商品价格区间分布、不同类别商品销量分布、商品价格与销量的关系、不同省份商品销量分布、销量数据预测、后台数据管理及退出登录等功能选项。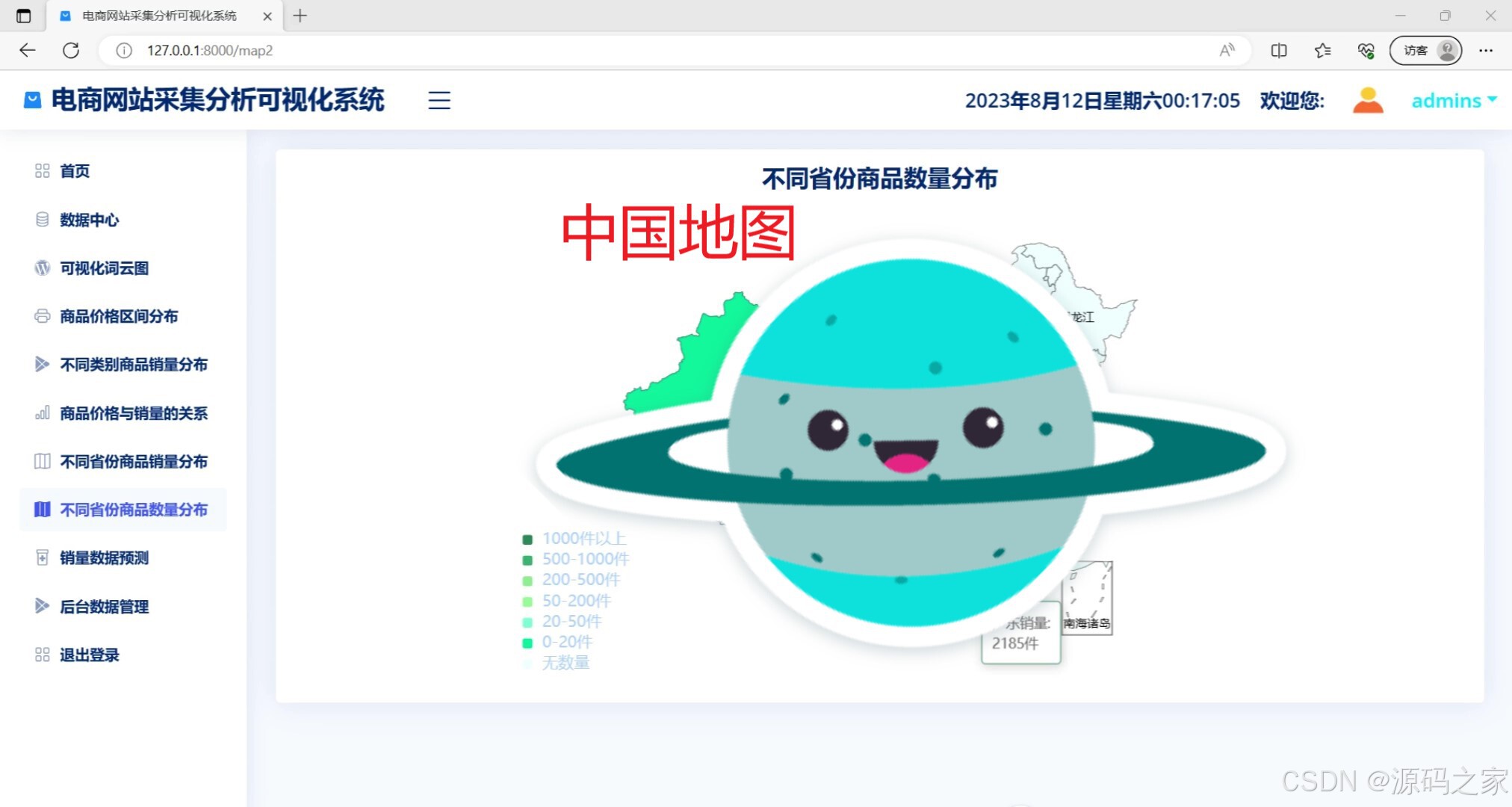
-
销量预测------ARIMA时序预测模型(基于历史数据的未来销量趋势预测图表)
该页面是电商网站采集分析可视化系统的销量数据预测模块,以柱状图和折线图结合的形式,分别展示冰箱和洗衣机的未来销量趋势预测,其中红色柱代表预测值,同时左侧菜单栏还提供了首页、数据中心、可视化词云图、商品价格区间分布、不同类别商品销量分布、商品价格与销量的关系、不同省份商品销量分布、不同省份商品数量分布、后台数据管理及退出登录等功能选项。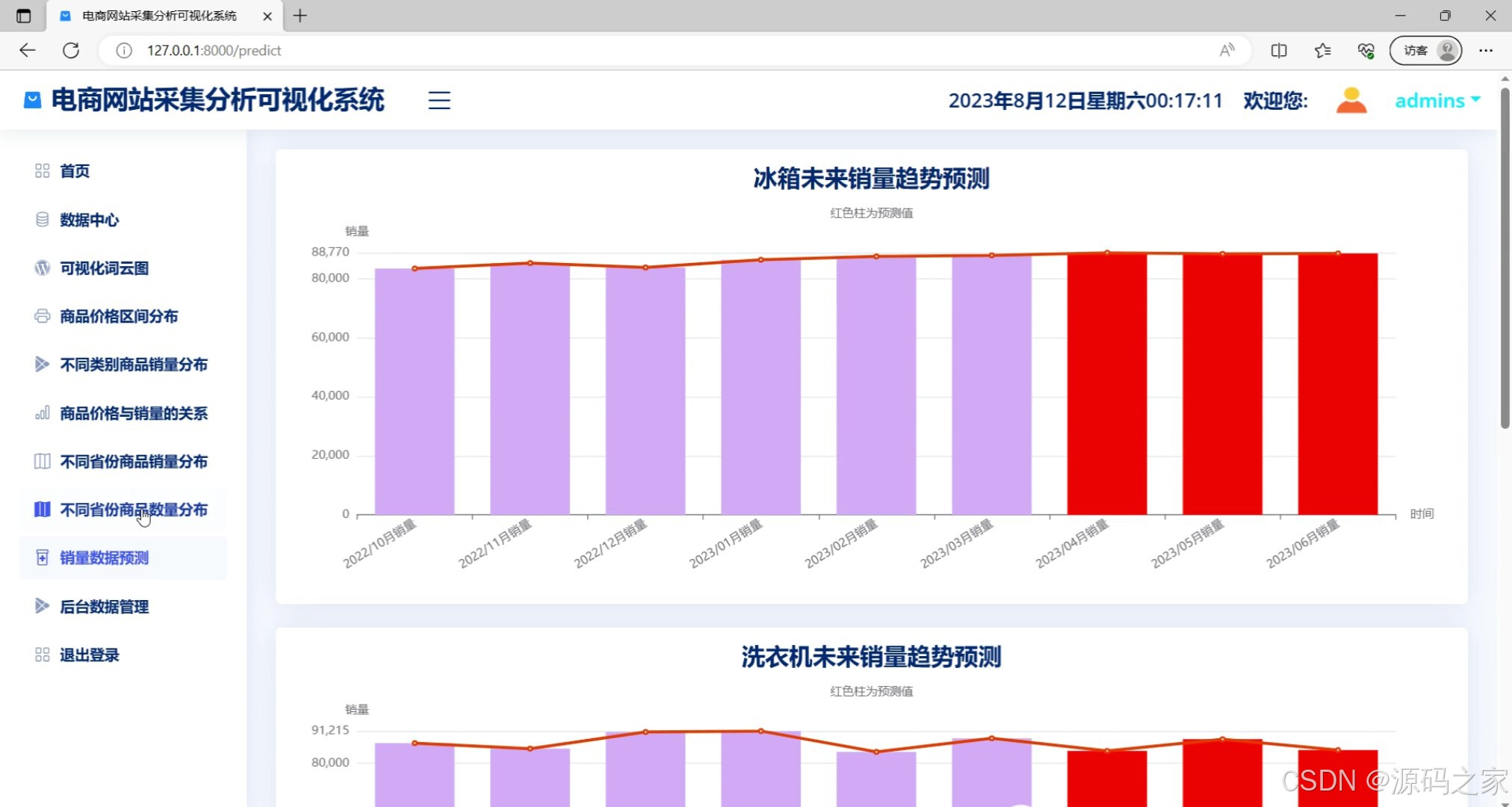
-
商品价格与销量的关系(价格区间与对应销量的关联分析图表)
该页面是电商网站采集分析可视化系统的商品价格与销量的关系模块,以折线图的形式展示淘宝商品价格与销量之间的关联,同时左侧菜单栏还提供了首页、数据中心、可视化词云图、商品价格区间分布、不同类别商品销量分布、不同省份商品销量分布、不同省份商品数量分布、销量数据预测、后台数据管理及退出登录等功能选项。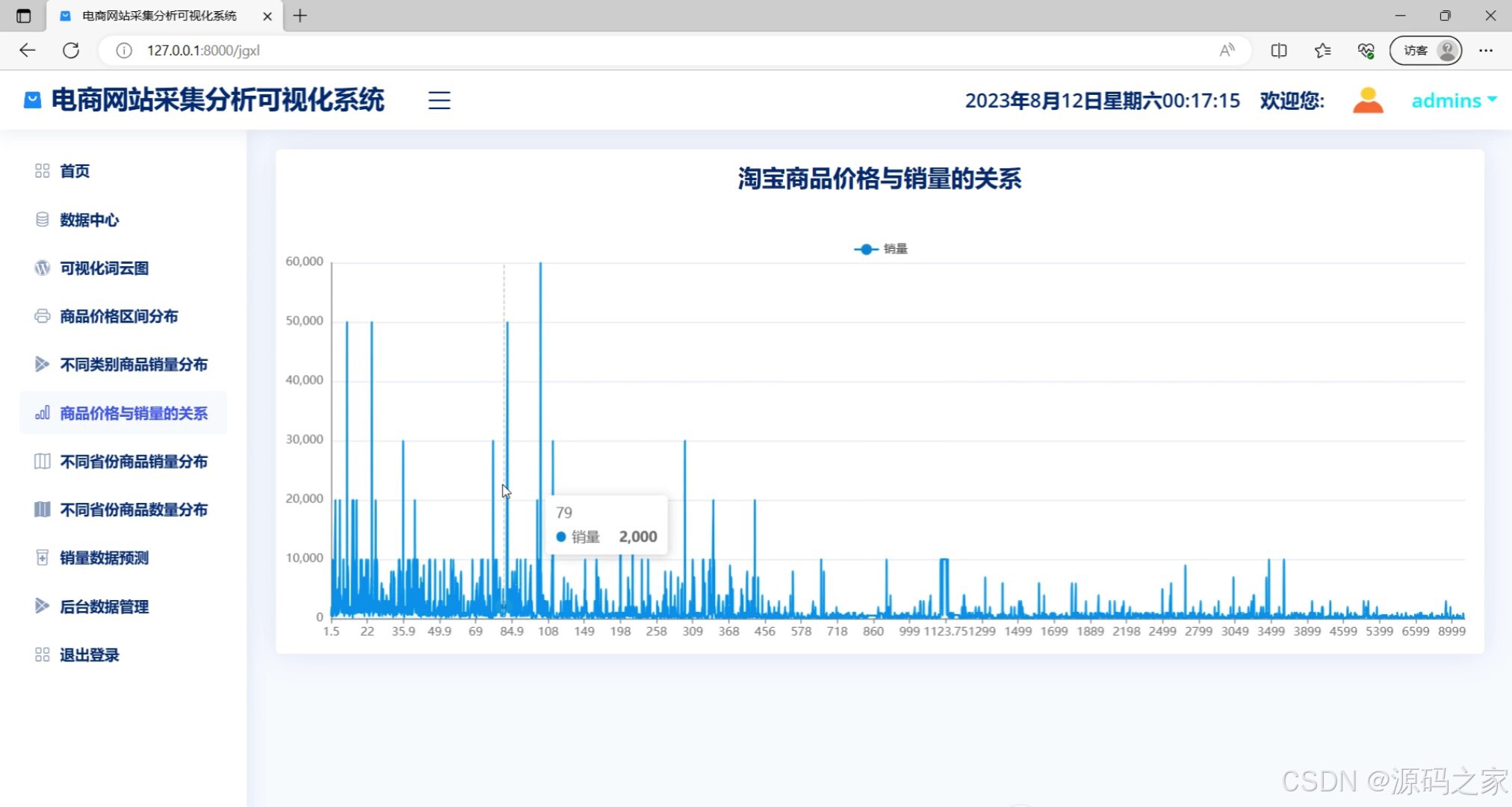
-
商品数据(商品基础信息列表,含名称、价格、销量等详情)
该页面是电商网站采集分析可视化系统的数据中心模块,以列表形式展示淘宝商品数据,支持按商品名称、价格、销量等字段排序,同时提供分页和搜索功能,方便用户快速定位和查看商品信息,左侧菜单栏还提供了首页、可视化词云图、商品价格区间分布、不同类别商品销量分布、商品价格与销量的关系、不同省份商品销量分布、不同省份商品数量分布、销量数据预测、后台数据管理及退出登录等功能选项。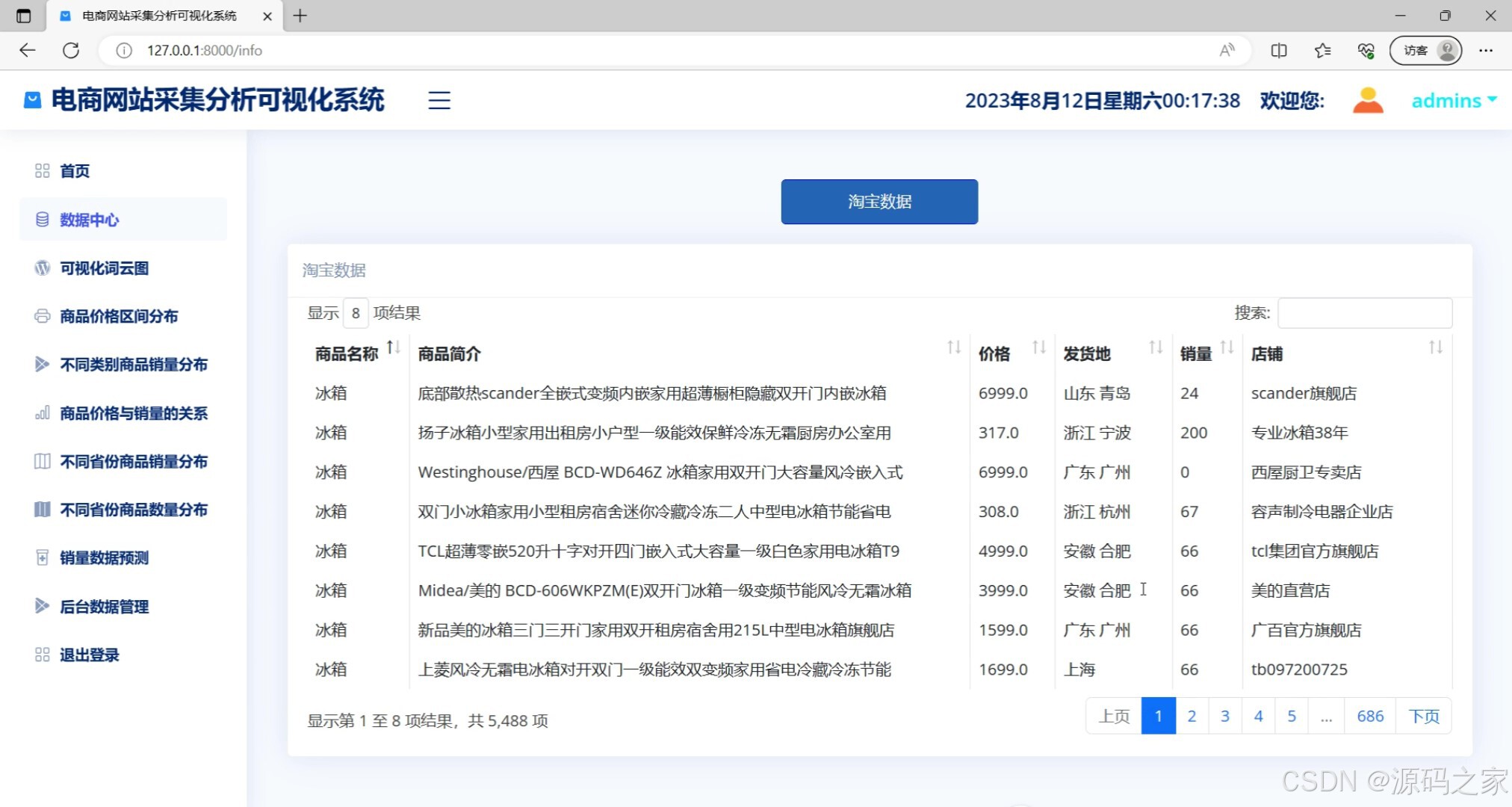
-
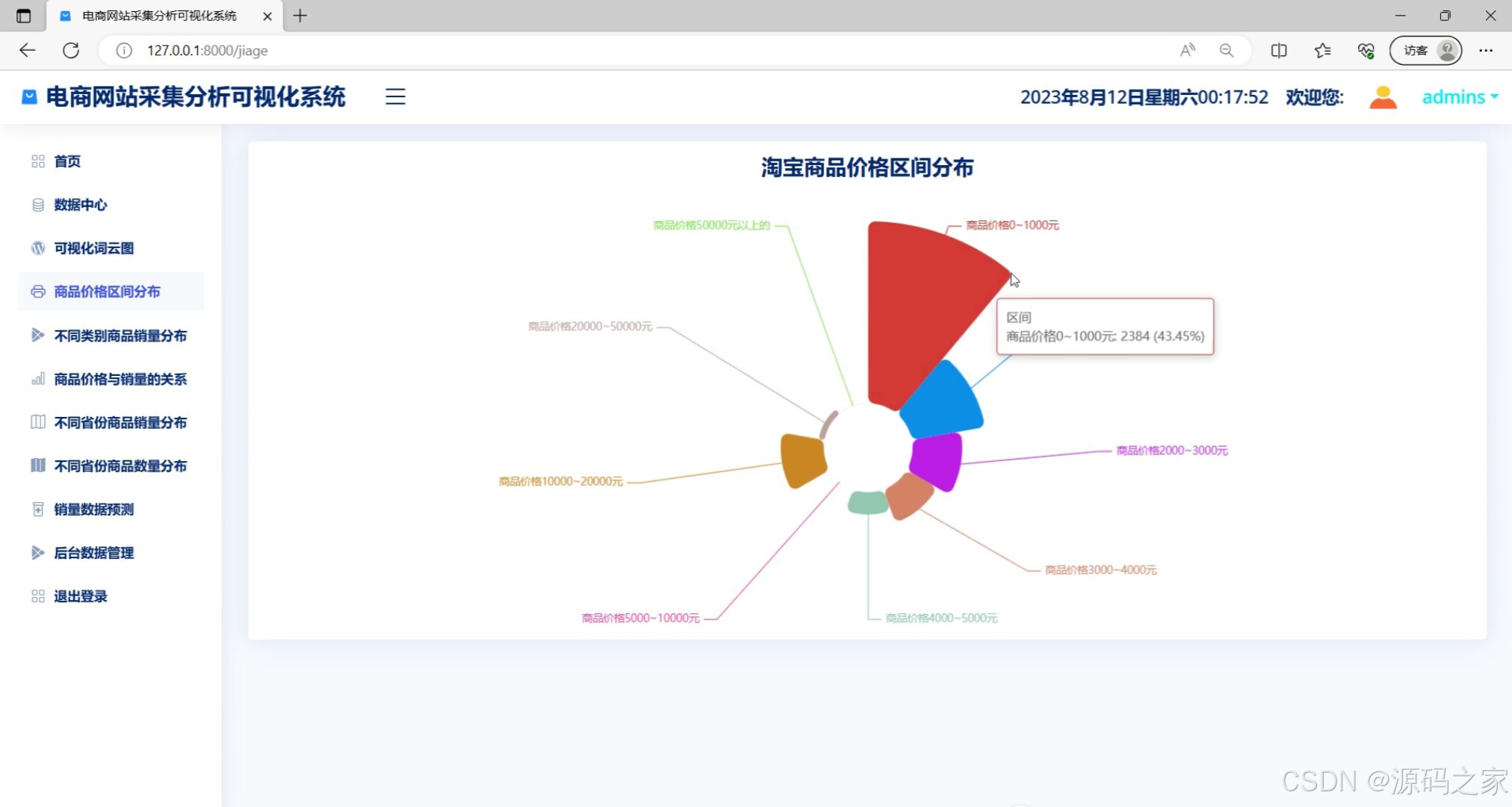
商品价格区间分布(不同价格段商品数量占比的统计图表)
该页面是电商网站采集分析可视化系统的商品价格区间分布模块,以环形饼图的形式直观展示淘宝商品在不同价格区间的数量占比情况,同时左侧菜单栏还提供了首页、数据中心、可视化词云图、不同类别商品销量分布、商品价格与销量的关系、不同省份商品销量分布、不同省份商品数量分布、销量数据预测、后台数据管理及退出登录等功能选项。
-
各类商品销量分布(不同品类商品销量占比的可视化图表)
该页面是电商网站采集分析可视化系统的不同类别商品销量分布模块,以漏斗图的形式直观展示淘宝不同类别商品的销量分布情况,同时左侧菜单栏还提供了首页、数据中心、可视化词云图、商品价格区间分布、商品价格与销量的关系、不同省份商品销量分布、不同省份商品数量分布、销量数据预测、后台数据管理及退出登录等功能选项。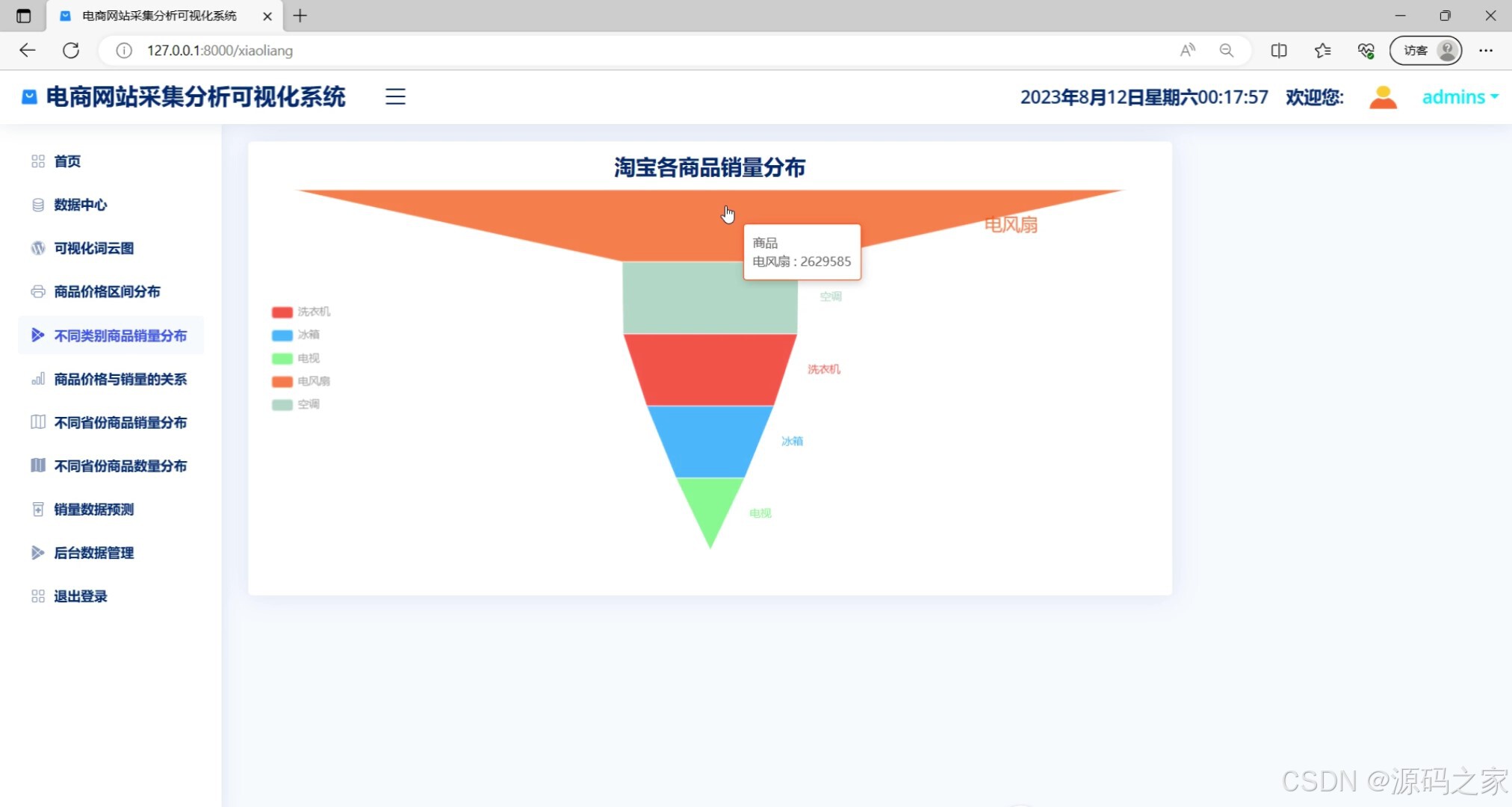
-
首页(系统功能入口与核心数据概览)
该页面是电商网站采集分析可视化系统的首页,主要介绍了系统的技术栈和四大核心模块,包括用户模块、爬虫模块、数据可视化模块和算法预测模块,同时左侧菜单栏还提供了数据中心、可视化词云图、商品价格区间分布、不同类别商品销量分布、商品价格与销量的关系、不同省份商品销量分布、不同省份商品数量分布、销量数据预测、后台数据管理及退出登录等功能选项。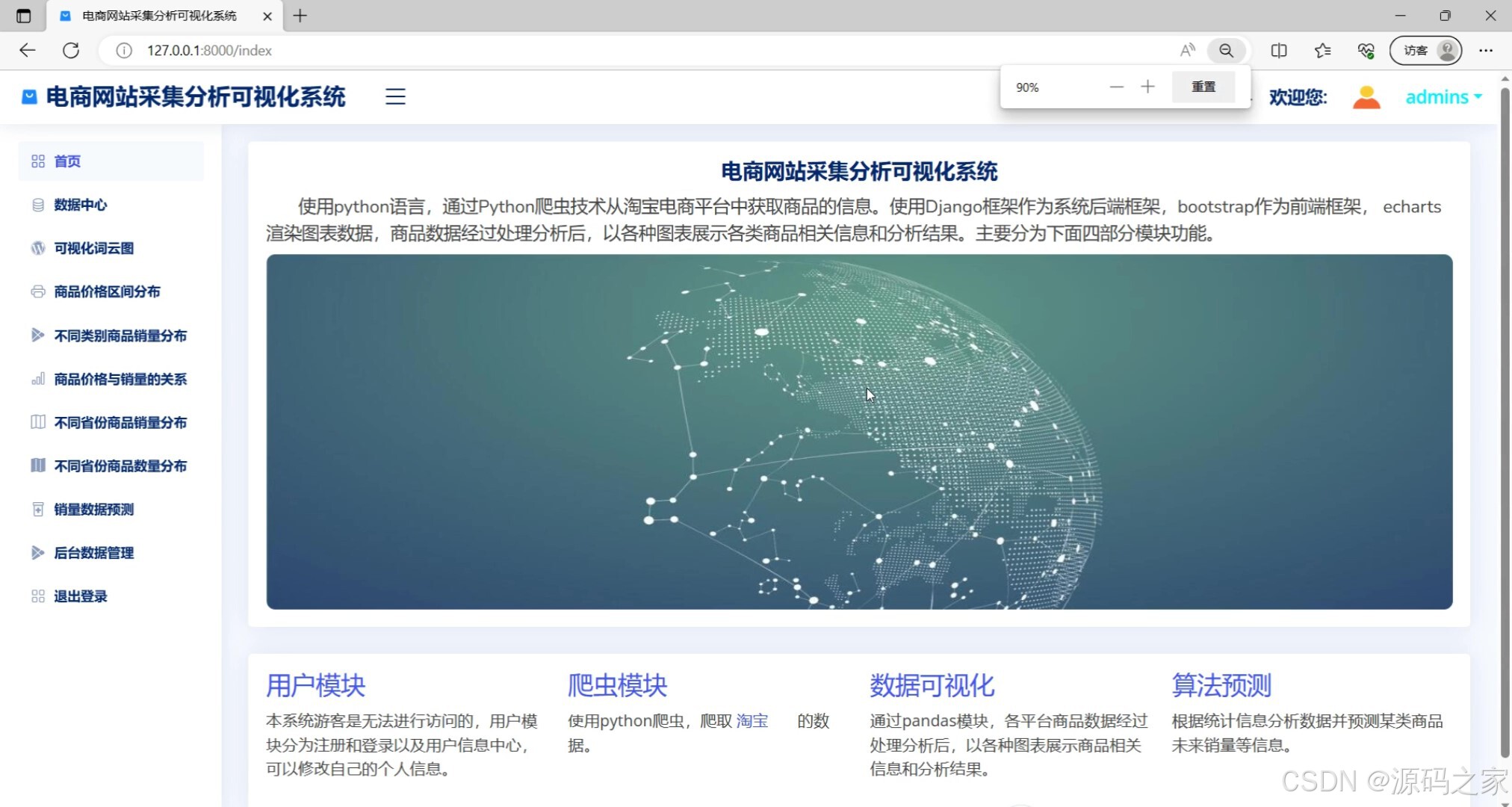
-
词云图分析(商品关键词/用户评价高频词的词云展示)
该页面是电商网站采集分析可视化系统的可视化词云图模块,以词云图的形式直观展示淘宝商品标题中的高频关键词,并在下方提供词频统计和分析结论,同时左侧菜单栏还提供了首页、数据中心、商品价格区间分布、不同类别商品销量分布、商品价格与销量的关系、不同省份商品销量分布、不同省份商品数量分布、销量数据预测、后台数据管理及退出登录等功能选项。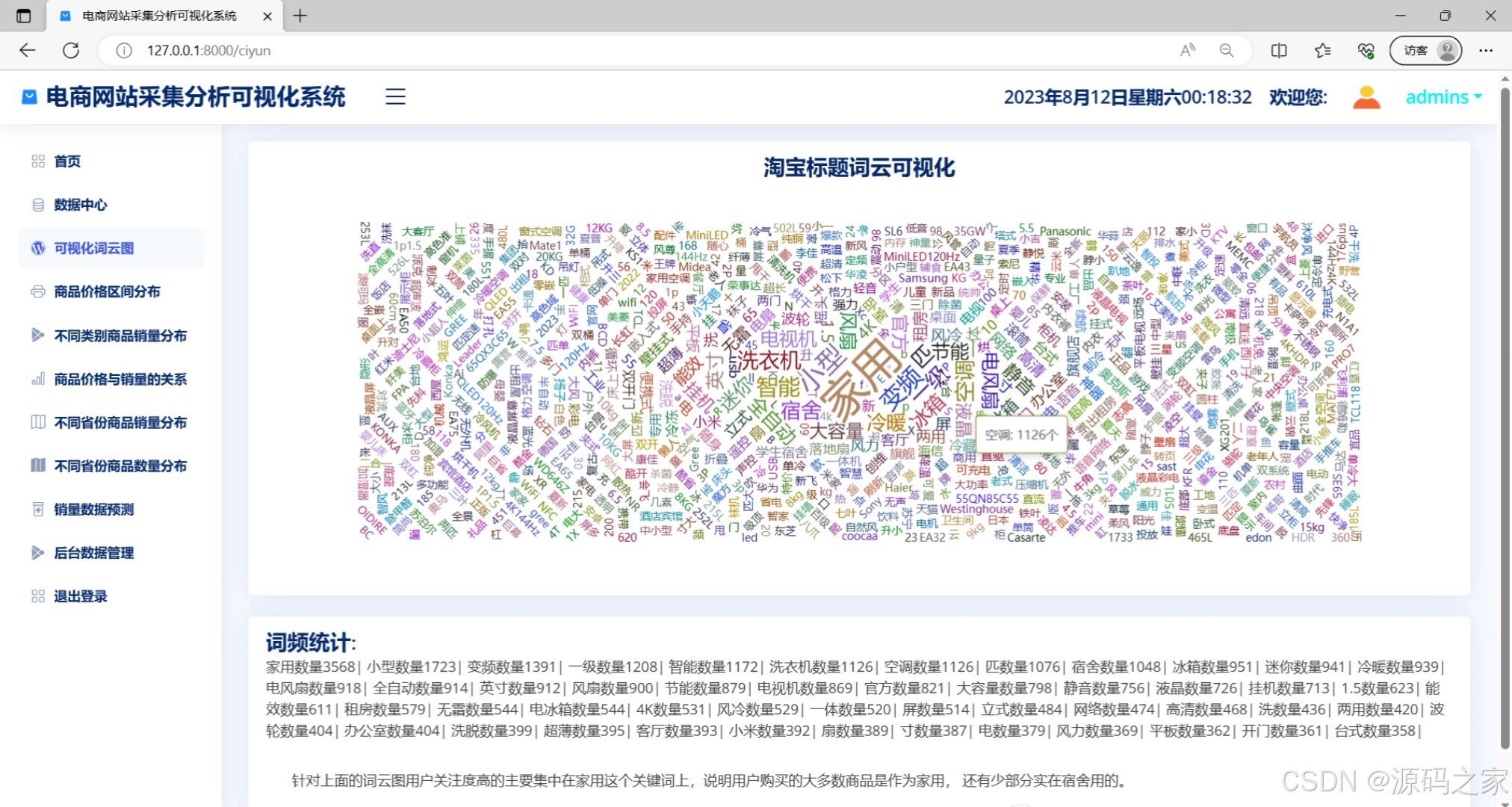
-
后台数据管理(商品数据维护、爬虫任务管控等后台功能界面)
该页面是电商网站采集分析可视化系统的后台数据管理模块,支持对数据表、用户表和认证授权组进行增加和修改操作,同时可查看最近动作记录,顶部还提供了查看站点、修改密码和注销等功能选项。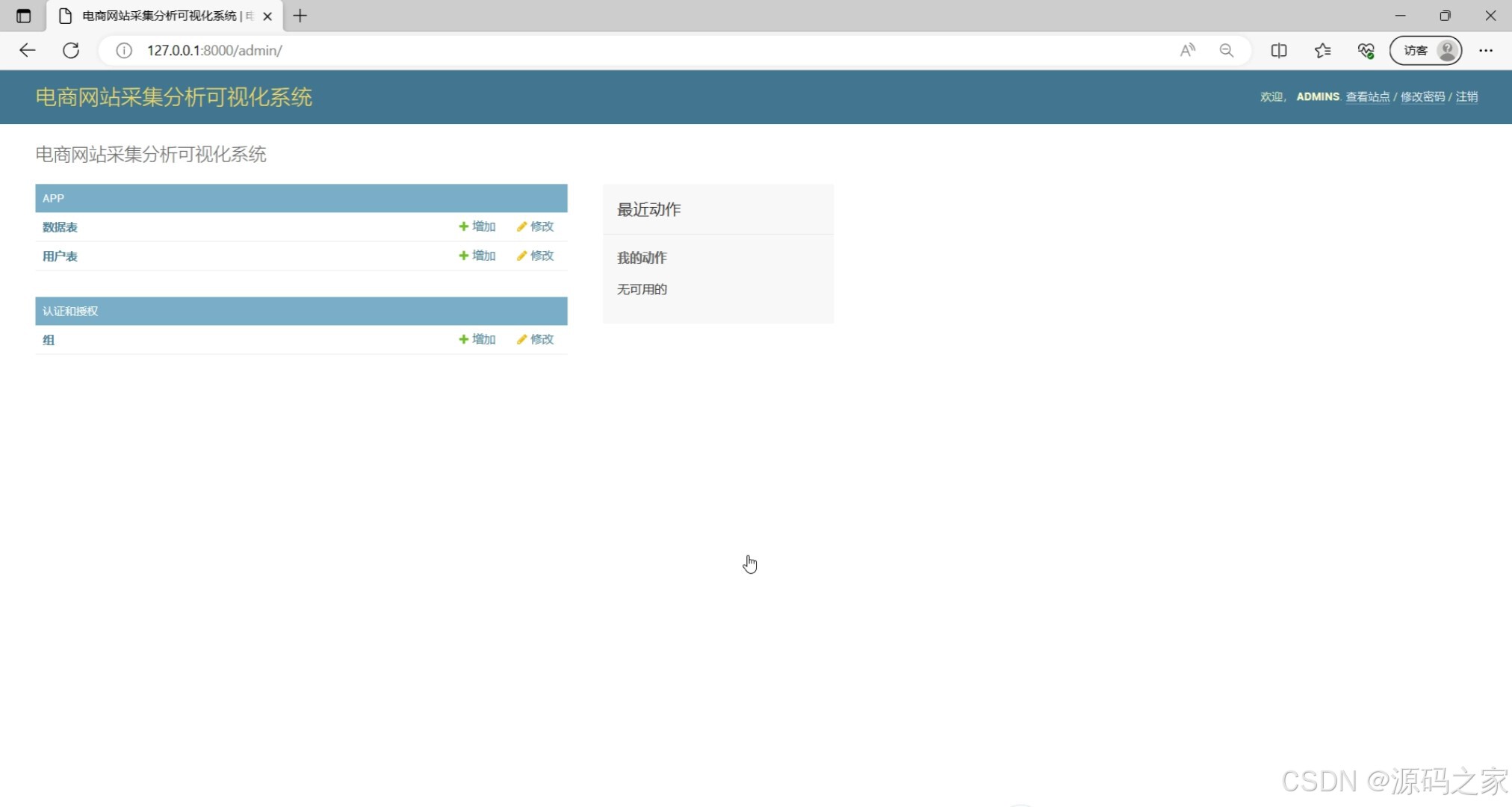
10.注册登录
该页面是电商网站采集分析可视化系统的用户登录模块,提供用户名和密码输入框,支持记住密码、选择普通用户或管理员两种登录类型,同时提供登录和注册功能,用于用户身份验证和账号管理。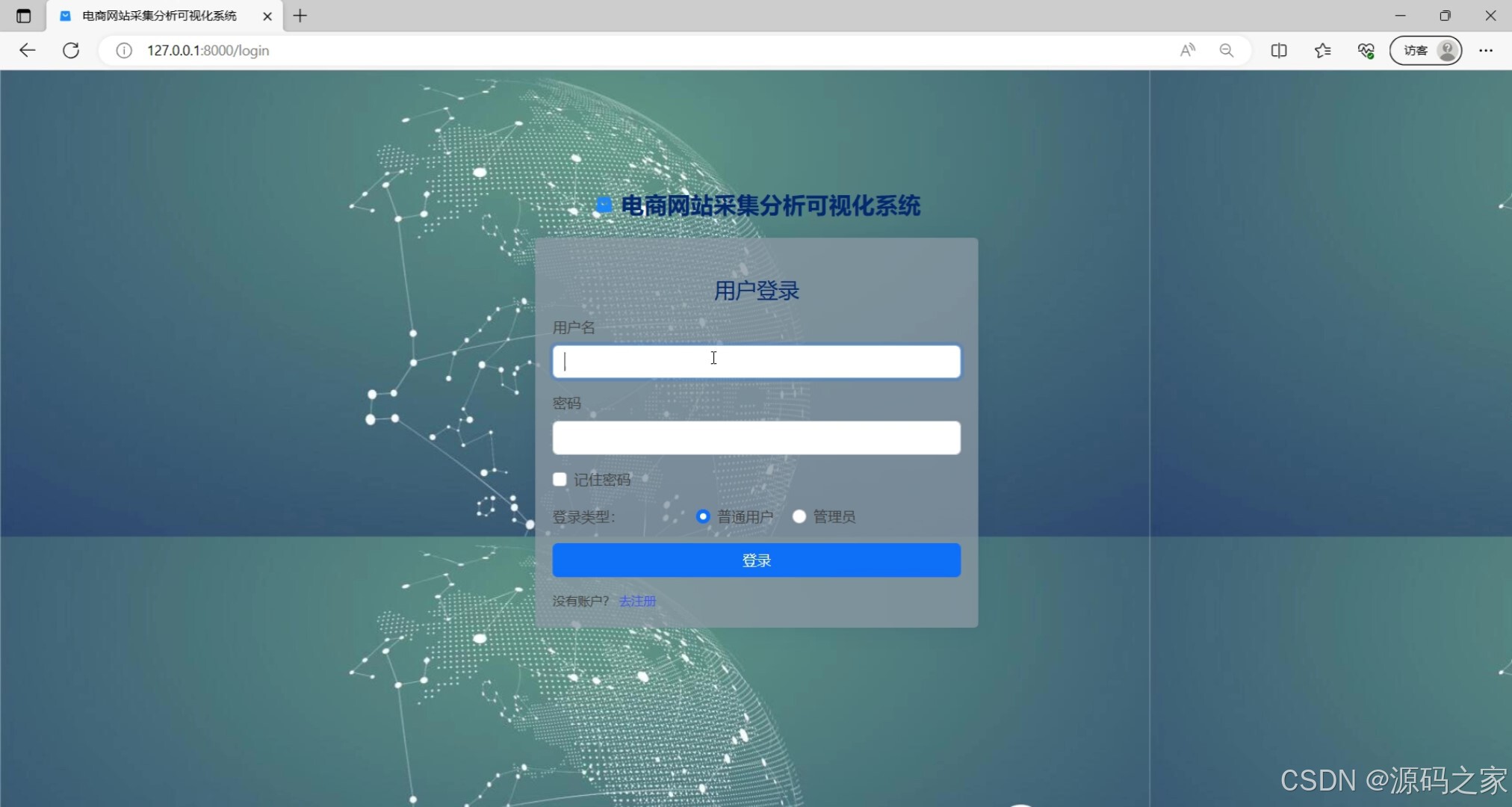
3、项目说明
一、技术栈简要说明
本系统以Python为开发语言,后端采用Django框架构建稳定的Web架构,利用其MTV模式实现各层级的解耦。数据采集通过requests库实现淘宝商品信息的自动化抓取,涵盖商品名称、价格、销量及地域分布等字段。核心算法选用ARIMA时序预测模型,对历史销量数据进行差分平稳化处理,结合自回归与移动平均机制实现未来趋势预测。MySQL数据库负责采集数据的结构化存储与管理。可视化层面整合ECharts等工具,实现地图热力图、词云、折线图、饼图、漏斗图等多种图表的动态展示。
二、功能模块详细介绍
· 用户注册登录模块:系统入口处提供完整的身份验证功能,界面包含用户名密码输入框、记住密码选项以及用户类型选择下拉框,支持普通用户和管理员两种角色切换。新用户可通过注册链接创建账号,保障系统访问的安全性和权限分级管理。
· 首页概览模块:作为系统的功能引导界面,首页以卡片布局展示四大核心组件,包括用户管理、爬虫采集、数据可视化和算法预测模块的简要说明。左侧固定菜单栏提供所有功能页面的快速跳转入口,方便用户在不同分析模块间自由切换。
· 数据中心模块:以表格形式集中呈现淘宝商品的完整数据清单,包含商品名称、当前售价、累计销量、商品链接等关键字段。表格支持按任意字段进行升序或降序排序,提供分页浏览功能,并配备搜索框支持商品名称关键词检索,便于用户快速定位目标商品。
· 可视化词云图模块:基于商品标题文本进行分词处理和词频统计,将高频关键词以词云形式直观呈现,关键词字体大小与其出现频率成正比。图表下方同步展示详细的词频统计列表和文本分析结论,帮助商家快速把握市场热点和消费者关注焦点。
· 商品价格区间分布模块:采用环形饼图展示商品在不同价格区间的数量占比情况。系统将商品价格划分为多个连续区间段,各区间商品数量以扇形比例呈现,饼图中心显示商品总数,直观反映商品定价的整体结构分布特征。
· 不同类别商品销量分布模块:通过漏斗图呈现各品类商品的销量对比情况。漏斗图从上至下依次排列不同商品类别,各层级宽度代表该类别的销量规模,清晰展示销量从高到低的递减趋势,帮助商家识别主力销售品类和潜力增长品类。
· 商品价格与销量关系模块:以折线图形式揭示商品定价与销量之间的关联规律。横轴为价格区间分段,纵轴为对应区间的平均销量或总销量,通过曲线走势分析是否存在最优定价区间,为商家制定价格策略提供数据参考。
· 不同省份商品销量分布模块:基于商品销量的地域属性,采用柱状图或条形图展示各省份的销量规模对比,支持按销量高低排序显示。该模块帮助商家识别重点销售区域和市场空白区域,为区域化运营策略提供依据。
· 不同省份商品数量分布模块:采用中国地图热力图形式,以颜色深浅直观反映各省份的商品数量分布密度。颜色越深的省份代表商品数量越多,鼠标悬停可显示具体数值,便于从地理维度分析商品供给的区域集中度。
· 销量数据预测模块:基于ARIMA时序预测模型,对冰箱、洗衣机等重点品类的未来销量趋势进行预测分析。页面采用柱状图与折线图结合的形式呈现,红色柱体代表模型预测值,灰色柱体代表历史实际值,清晰展示未来一段时间的销量走势,为库存管理提供决策支持。
· 后台数据管理模块:面向管理员的系统维护界面,支持对数据表结构、用户信息、权限组进行增删改查操作。页面顶部提供查看站点、修改密码和注销功能,右侧展示最近操作记录,便于系统日常维护和权限管理。
三、项目总结
本系统针对淘宝商家在电商运营中面临的销量预测滞后和库存管理难题,构建了集数据采集、分析、预测与可视化于一体的完整解决方案。技术层面实现了Django框架与ARIMA时序模型的深度整合,打通从爬虫数据抓取、MySQL存储到前端ECharts展示的全流程链路。功能层面覆盖商品数据管理、多维度统计分析、时序销量预测等核心业务场景,地图热力图、词云、漏斗图等多样化图表为商家提供直观的数据洞察视角。系统既具备时序预测算法在电商领域的应用研究价值,又兼具辅助商家优化库存配置、调整定价策略的实际商业效用,通过将复杂的数据分析过程封装为可视化操作界面,降低了数据驱动决策的技术门槛,为电商精细化运营提供有力的工具支撑。
4、核心代码
def login(request):
if request.method == "GET":
return render(request, 'login.html')
if request.method == 'POST':
# 验证表单数据
username = request.POST['username']
password = request.POST['password']
login_type = request.POST.get('login_type', 'frontend')
# 认证用户
user = auth.authenticate(request, username=username, password=password)
if user is not None:
if user.is_active:
# 登录用户并跳转到相应页面
auth.login(request, user)
if login_type == 'admin':
return redirect('admin:index')
else:
return redirect('index')
else:
error_msg = '用户名或密码错误'
return render(request, 'login.html', context={'error_msg': error_msg})
def logout(request):
auth.logout(request)
return redirect('login') # 重定向到登录
def query_database(query, args=()):
conn = sqlite3.connect(BASE_DIR + '/db.sqlite3')
cursor = conn.cursor()
cursor.execute(query, args)
result = cursor.fetchall()
headers = [i[0] for i in cursor.description]
conn.commit()
conn.close()
data = [headers] + list(result)
df = pd.DataFrame(data[1:], columns=data[0])
# print(df)
return df
@login_required
def home(request):
return redirect('index')
@login_required
def index(request):
return render(request, 'index.html')
@login_required
def info(request):
query1 = 'select * from 淘宝数据'
df1 = query_database(query1)
rows1 = df1.values
return render(request, 'info.html', locals())
@login_required
def ciyun(request):
query1 = 'select * from 淘宝数据'
df1 = query_database(query1)
def cy(df):
# 词云图数据处理
titles = df['标题'].tolist()
# 加载停用词表
stopwords = set()
with open(BASE_DIR + r'./app/StopWords.txt', 'r', encoding='utf-8') as f:
for line in f:
stopwords.add(line.strip())
# 将数据进行分词并计算词频
words = []
for item in titles:
if item:
words += jieba.lcut(item.replace(' ', ''))
word_counts = Counter([w for w in words if w not in stopwords])
# 获取词频最高的词汇
top20_words = word_counts.most_common()
words_data = []
for word in top20_words:
words_data.append({'name': word[0], 'value': word[1]})
return words_data
word1 = cy(df1)
return render(request, 'ciyun.html', locals())
@login_required
def jiage(request):
query1 = 'select * from 淘宝数据'
df1 = query_database(query1)
def cy(df):
# 商品价格区间分布
data_res = [[], [], [], [], [], [], [], [], [], []]
for data in df['价格'].values.tolist():
print(data)
if data <= 1000:
data_res[0].append(data)
if 1000 < data <= 2000:
data_res[1].append(data)
if 2000 < data <= 3000:
data_res[2].append(data)
if 3000 < data <= 4000:
data_res[3].append(data)
if 4000 < data <= 5000:
data_res[4].append(data)
if 5000 < data <= 10000:
data_res[6].append(data)
if 10000 < data <= 20000:
data_res[7].append(data)
if 20000 < data <= 50000:
data_res[8].append(data)
if 50000 < data:
data_res[9].append(data)
data_col = [f'商品价格0~1000元',
f'商品价格1000~2000元',
f'商品价格2000~3000元',
f'商品价格3000~4000元',
f'商品价格4000~5000元',
f'商品价格5000~10000元',
f'商品价格10000~20000元',
f'商品价格20000~50000元',
f'商品价格50000元以上的', ]
data_num = [len(i) for i in data_res]
data_price_interval = []
for key, value in zip(data_col, data_num):
data_price_interval.append({'name': key, 'value': value})
return data_price_interval
word1 = cy(df1)
return render(request, 'jiage.html', locals())
@login_required
def xiaoliang(request):
query1 = 'select * from 淘宝数据'
df1 = query_database(query1)
def cy(sales_df):
# 商品销量分布情况
data_dict = {}
for i in sales_df:
print(i)
key = i[0]
value = '0'
if i[1]:
value = str(i[1]).replace('万', '0000').replace('+', '').replace('评价', '').replace('.', '')
if data_dict.get(key):
data_dict[key] += int(value)
else:
data_dict[key] = int(value)
sales_data = []
sales_key = []
for key, value in data_dict.items():
sales_key.append(key)
sales_data.append({'name': key, 'value': value})
return sales_key, sales_data
sales_key1, sales_data1 = cy(df1[['word', '销量']].values.tolist())
return render(request, 'xiaoliang.html', locals())
@login_required
def map(request):
query1 = 'select * from 淘宝数据'
df1 = query_database(query1)
# 地图销量数据处理
addr = df1[['发货地', '销量']]
addr_data = addr.groupby('发货地')['销量'].sum()
map_data = []
addr_dict = {}
for key, value in addr_data.to_dict().items():
key = key.split(' ')[0]
if addr_dict.get(key):
addr_dict[key] += value
else:
addr_dict[key] = value
for key, value in addr_dict.items():
map_data.append({'name': key, 'value': value})
return render(request, 'map.html', locals())
@login_required
def map2(request):
query1 = 'select * from 淘宝数据'
df1 = query_database(query1)
# 地图销量数据处理
addr = df1['发货地'].value_counts()
map_data = []
addr_dict = {}
for key, value in addr.to_dict().items():
key = key.split(' ')[0]
if addr_dict.get(key):
addr_dict[key] += value
else:
addr_dict[key] = value
for key, value in addr_dict.items():
map_data.append({'name': key, 'value': value})
return render(request, 'map2.html', locals())
@login_required
def jgxl(request):
query1 = 'select * from 淘宝数据'
df1 = query_database(query1)
df1 = df1[['价格', '销量']]
# 按价格升序排序
df1 = df1.sort_values(by=['价格'])
# 使用布尔索引选择需要删除的行
rows_to_drop = df1['销量'] < 100
# 使用 drop() 方法删除行
df1 = df1.drop(df1[rows_to_drop].index)
df1_data = [df1['价格'].tolist(), df1['销量'].tolist()]
return render(request, 'jgxl.html', locals())
# ARIMA 时序预测模型 【销量预测】
@login_required
def predict(request):
def arima_model_train_eval(history):
# 构造 ARIMA 模型
model = ARIMA(history, order=(1, 1, 1))
# 基于历史数据训练
model_fit = model.fit()
# 预测接下来的3个时间步的值
output = model_fit.forecast(steps=3)
yhat = output
return yhat
query1 = 'select * from 预测数据'
df = query_database(query1)
df = df[['名称', '2022/10月销量', '2022/11月销量', '2022/12月销量', '2023/01月销量', '2023/02月销量', '2023/03月销量']]
df = df.groupby('名称').sum()
df = df.reset_index()
print(df)
year_data = ['2022/10月销量', '2022/11月销量', '2022/12月销量', '2023/01月销量', '2023/02月销量', '2023/03月销量', '2023/04月销量',
'2023/05月销量', '2023/06月销量']
data = df.iloc[:, 1:].values.tolist()
bingxiang = data[0] + arima_model_train_eval(data[0]).tolist()
xiyiji = data[1] + arima_model_train_eval(data[1]).tolist()
dianshi = data[2] + arima_model_train_eval(data[2]).tolist()
return render(request, 'predict.html', locals())
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)