[FMQL30TAI开发]FPAI开发相关重要概念梳理
FPAI是复旦微电子自主研发的异构融合智能芯片,集成多核CPU、NPU和FPGA,支持端侧全流程AI计算。
1. FPAI异构融合可编程智能芯片
FPAI是复旦微电子集团面向人工智能应用场景,自主研发设计的异构融合可编程智能芯片,FPAI创新地采用多核异构融合架构设计,单芯片集成多核高性能处理器系统(PS/SoC)、神经网络处理器(NPU)和可编程逻辑(FPGA/PL)。单芯片即可满足端侧智能应用全流程计算需求(预处理、AI推理、后处理),具备异构协同、高集成、高能效、可扩展、高灵活性等优势,搭配全自主设计软件工具链Icraft,赋能多场景智能应用快速落地。
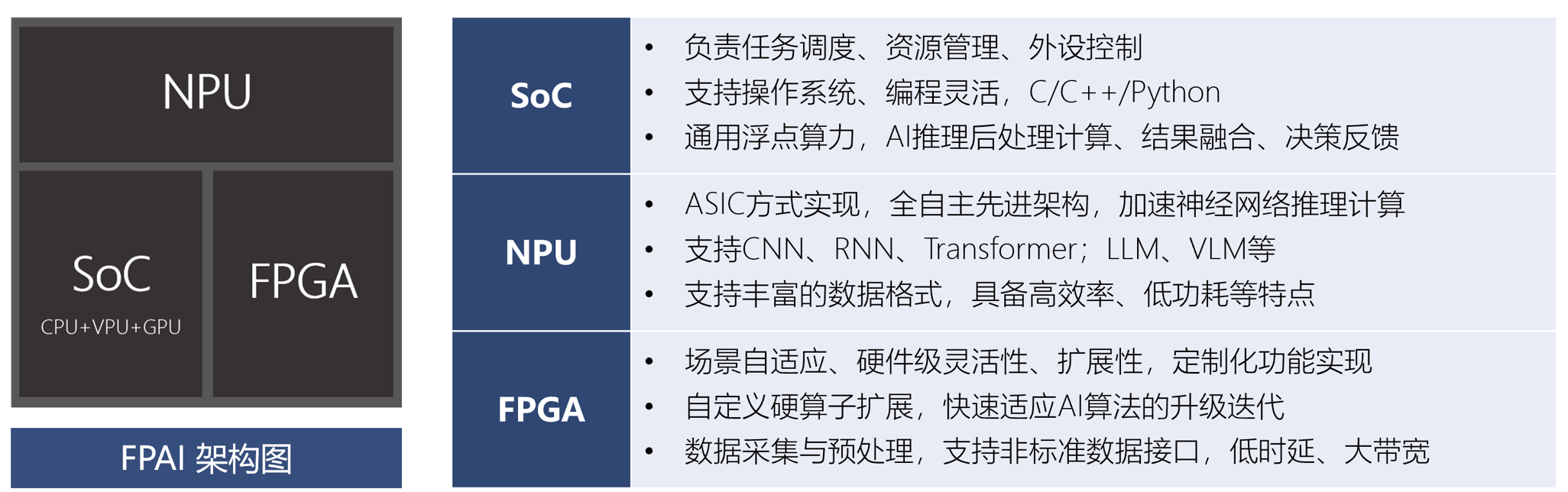
2. FPAI产品谱系
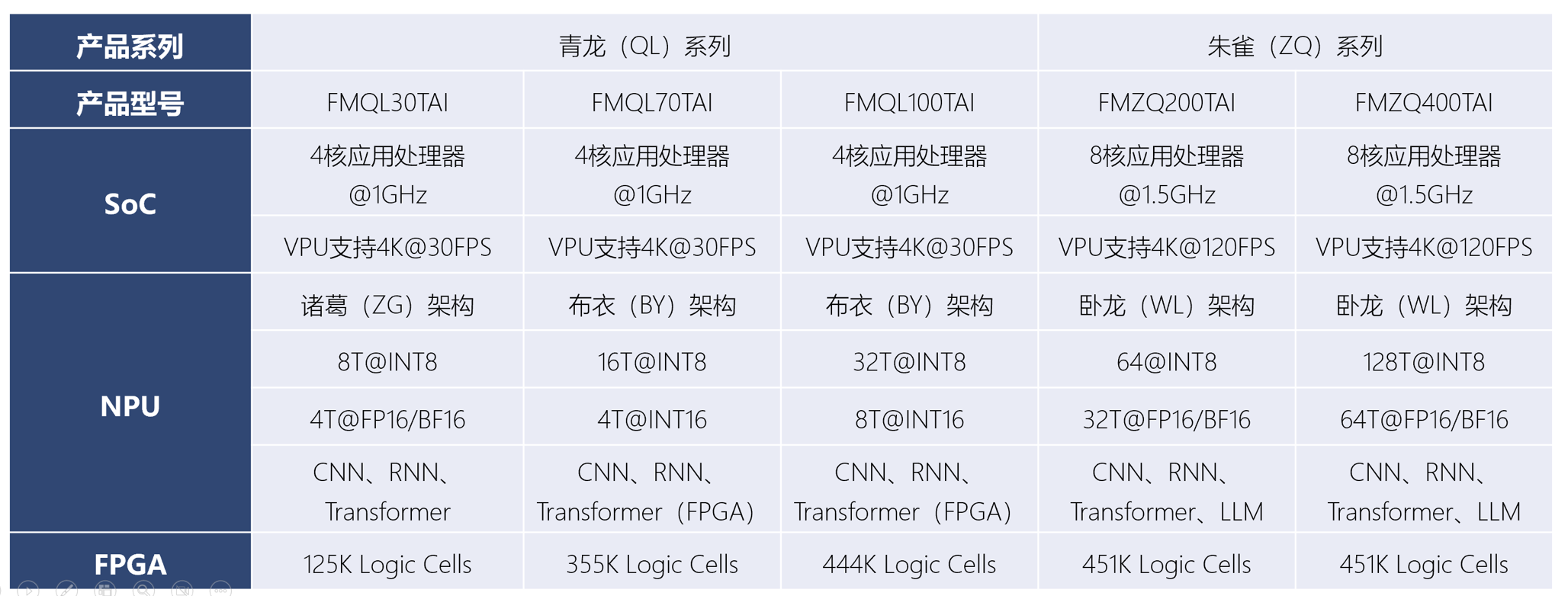
3. 青龙系列FPAI
青龙(QL)系列FPAI面向端侧中等规模算力场景需求,包括三款产品:
- FMQL30TAI:4核CPU(1GHz)+8T 诸葛架构NPU+125 K逻辑单元FPGA
- FMQL70TAI: 4核CPU(1GHz)+16T 布衣架构NPU+355 K逻辑单元FPGA
- FMQL100TAI: 4核CPU(1GHz)+32T 布衣架构NPU+444K逻辑单元FPGA
青龙系列FPAI芯片内部架构图:
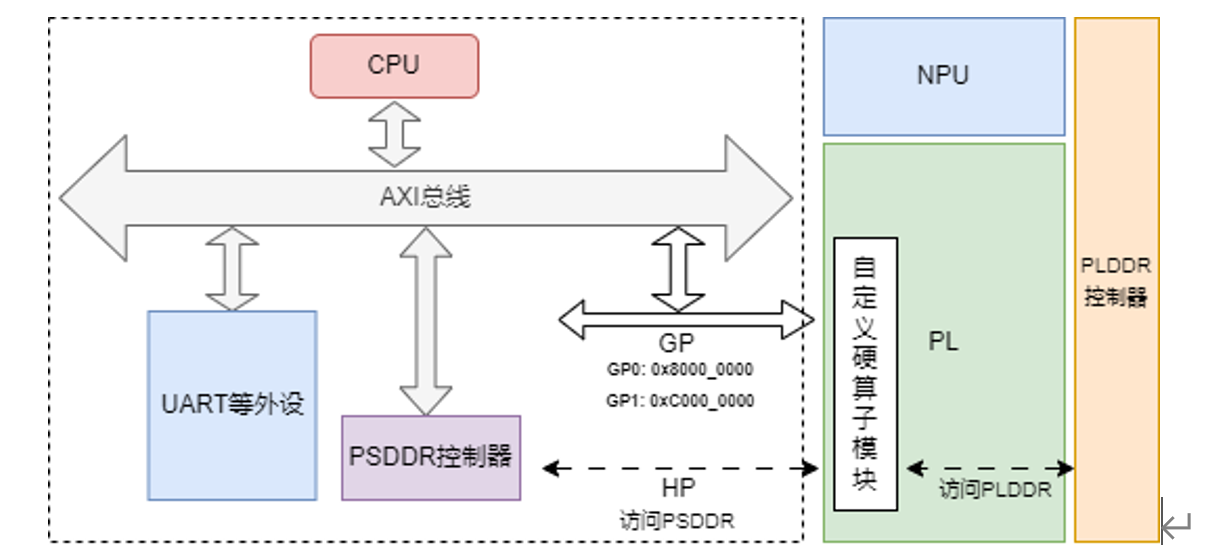
4. PS(处理器系统)
高性能多核处理器系统(Processing System,PS/SoC),集成CPU、VPU、GPU三个计算单元。PS负责FPAI芯片的系统控制与资源调度,同时也是通用浮点算力,NPU和FPGA都可以视为其外设,智能应用程序(runtime app)运行在PS上,负责调度管理智能计算任务以及控制数据流。
- PS支持部署嵌入式操作系统,支持ubuntu20.04以及多种国产操作系统。
- PS支持裸机(baremetal)部署运行智能应用程序,不依赖操作系统,启动时间快、强实时控制。
- 中央处理单元(Central Processing Unit,CPU),运算和控制核心,是信息处理、程序运行的最终执行单元。
- 视频处理单元(Video Processing Unit,VPU)是一种视频处理平台核心引擎,具有硬解码功能,可对原始视频源进行压缩、亦可对压缩视频流进行解压。
- 图形处理单元(Graphics Processing Unit,GPU),主要用来做图像显示渲染工作。
- PS集成了丰富的通用外设接口,USB/CAN/以太网等。
5. PL/FPGA
可编程逻辑(Programmable Logic,PL),具备可编程特性以及场景自适应能力,负责自定义硬算子实现、数据采集接口与预处理、用户自定义业务功能实现等。FPAI芯片的应用涉及到FPGA工程的开发。
- AI_MATE_IP:对于30TAI/70TAI/100TAI,NPU硬核的调用需要AI_MATE加速软核IP,AI_MATE_IP集成在官方提供的FPGA工程源码中,主要实现了寄存器功能定义、数据通路设置、DDR内存访问配置以及集成了官方开源的自定义硬算子IP,用户根据需要进行配置选择。
- 自定义硬算子(FPGA IP):通过FPGA对某个计算模块进行电路加速实现,实现了智能算法的全流程硬件加速,显著提高了计算效率。
- 参考实现:针对典型应用场景的数据流以及智能任务需求,官方提供了多类型参考实现工程,参考实现工程中包括不同类型FPGA工程源码,其中集成了AI_MATE_IP以及外围数据接口模块,建议基于参考实现的FPGA工程进行二次开发。
6. PS-PL接口
对于30TAI/70TAI/100TAI,芯片内部采用AXI总线高速互联,PS-PL接口情况:
- AXI GP接口:PS作为主机访问PL寄存器,实现控制与状态交互。
- AXI HP接口:PL作为主机高速访问PS DDR,常配合DMA实现大数据量传输。
- 其他。
7. PSDDR
对于FPAI芯片需外挂DDR,对于30TAI/70TAI/100TAI,PS侧挂载的DDR内存称之为PSDDR。
8. PLDDR
对于FPAI芯片需外挂DDR,对于30TAI/70TAI/100TAI,PL侧挂载的DDR内存称之为PLDDR。NPU计算需要访问PLDDR,因此推荐PLDDR位宽挂满DDR。
9. NPU
神经网络处理器(Neural Processing Unit,NPU)是一种专门为深度学习和神经网络计算设计的处理器。它通过模拟人脑神经网络的工作原理,利用大规模并行计算单元和高效的数据流架构,显著提升了人工智能任务的计算效率和能效比。
NPU 的核心功能是加速神经网络中的复杂运算,例如矩阵运算、卷积操作和激活函数计算。与传统的 CPU 和 GPGPU 相比,NPU 在处理 AI 任务时表现出更高的性能和更低的功耗,尤其适用于图像识别、语音识别、自然语言处理等场景。
FPAI芯片中的NPU支持加载运行Icraft编译生成的模型文件(json&raw),并由Icraft-runtime进行调度管理。
FPAI芯片中集成的NPU,均采用自主定义架构设计,具体包括以下两个架构:
- 布衣/BY/buyi架构
- 数据精度:支持INT8/INT16
- 算子支持:支持CNN/RNN等神经网络
- 对于Transformer类神经网络,需要依赖FPGA进行自定义硬算子扩展
- 诸葛/ZG/zhuge架构
- 数据精度:支持INT8/FP16/BF16/TF32
- 算子支持:支持CNN/RNN/Transformer等神经网络
- 支持电源开关动态切换
- 支持自动时钟门控,精准控制运行功耗
10. FPAI工作模式
1.PSIN模式
- 数据从PS侧(SD卡存的图片/以太网压缩数据流等)接入芯片->HP口->PLDDR->NPU计算->后处理计算等
- PS侧运行runtime app 调度管理智能计算任务和数据流
2. PLIN模式
- 数据从PL侧(LVDS/SDI/光纤等)接入->FPGA接口模块->PLDDR->NPU计算->后处理计算等
- PS侧运行runtime app 调度管理智能计算任务和数据流
3. HOST_IN模式(PCIE加速卡形式)
- 系统组成:上位机(HOST)+FPAI,二者需要通信与协同
- HOST数据->PCIE接口->PLDDR->NPU计算->后处理计算等
- PS侧运行runtime app 调度管理智能计算任务和数据流
- HOST运行应用程序负责数据分发以及结果回收
4.Socket模式(多用于前期开发调试、精度测试与系统功能演示)
- 系统组成:上位机(windows系统)+FPAI,二者通过网线连接
- 上位机数据->socket协议>NPU计算-> socket协议->上位机
- PS侧运行 icraft-serve,启动NPU计算响应服务,FPAI只负责NPU计算
- 上位机运行socket模式运行时程序,负责前后处理以及调用NPU服务
11. 开发软件工具链Icraft
为配套FPAI芯片的开发,复旦微自主设计了端到端软件开发套件Icraft,由编译、运行和分析工具几部分组成。
- Icraft编译器(compiler):负责将用户神经网络(ONNX/Torchscript)编译转换成FPAI芯片能够识别和运行的数据文件(json&raw),用于上板部署和仿真。
- Icraft运行时(runtime):负责加载模型文件(json&raw),将其写入指定地址空间,调度NPU进行相应的智能计算。
- Icraft支持对json和raw在上位机(windows)进行仿真,仿真的结果与芯片推理结果在设计上能够保证完全一致。
- Icraft-docs:在windows系统安装icraft后,可查看icraft docs了解详细功能介绍以及算子支持清单、技术细节等。
- Icraft-show:支持对json和raw进行可视化、支持量化效果分析等。
Icraft-Modelzoo
为方便用户快速入门FPAI开发,已将主流神经网络算法适配到FPAI芯片上,提供全流程代码及教程,并进行了详细性能测试,为用户选型评估以及快速入门提供支撑。
参考实现(解决方案)
针对典型应用场景,完成了底层传感器数据接口定义、软件应用开发全流程的工程实现,将代码和教程开源,具体包括:位流(开发板可直接使用)、文档、FPGA工程和runtimeapp。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 24
24 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)