图解强化学习 |强化学习概述
本文介绍了强化学习(RL)的基本概念及其与机器学习的区别。RL通过智能体与环境的交互学习最优决策策略,具有时序关联性和延迟奖励的特点,不同于监督学习的静态识别。文章阐述了RL在污水处理等工业场景的应用案例,展示了其通过端到端训练实现自适应优化的优势。随着算力提升,RL在游戏、机器人等领域取得突破性进展,能够超越人类专家水平。文章还分享了RL在水处理过程中的具体研究成果,包括多目标优化框架和自适应控
🌞欢迎来到图解强化学习的世界
🌈博客主页:卿云阁💌欢迎关注🎉点赞👍收藏⭐️留言📝
📆首发时间:🌹2026年3月7日🌹
✉️希望可以和大家一起完成进阶之路!
🙏作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!
目录
强化学习(reforcement learning,RL)的概念

强化学习的概念
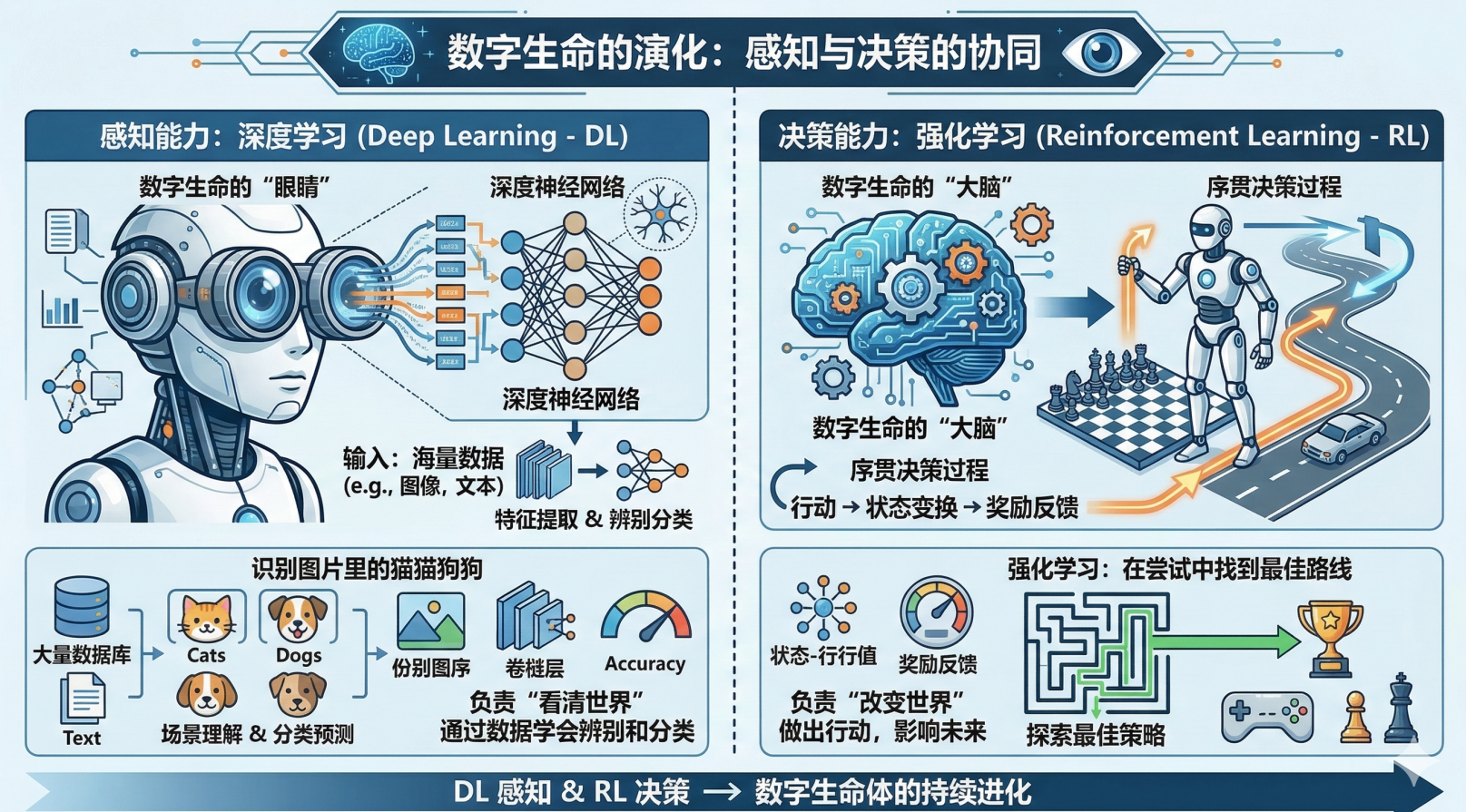
🧠有感知能力和决策能力
“如果把 AI 比作一个数字生命,那么深度学习(DL)就是它的‘眼睛’,而强化学习(RL)则是
它的‘大脑’。”
感知能力(深度学习): 负责“看清世界”。就像我们的大脑识别图片里的猫猫狗狗,深度学习通过
海量数据学会了辨别和分类。
决策能力(强化学习): 负责“改变世界”。它不满足于仅仅看清眼前,更要做出行动。这是一个序
贯决策的过程——就像下棋或开车,每一步都在影响未来。它学会的是在不断的尝试中,找到那条
通往成功的最佳路线。
强化学习(reforcement learning,RL)的概念
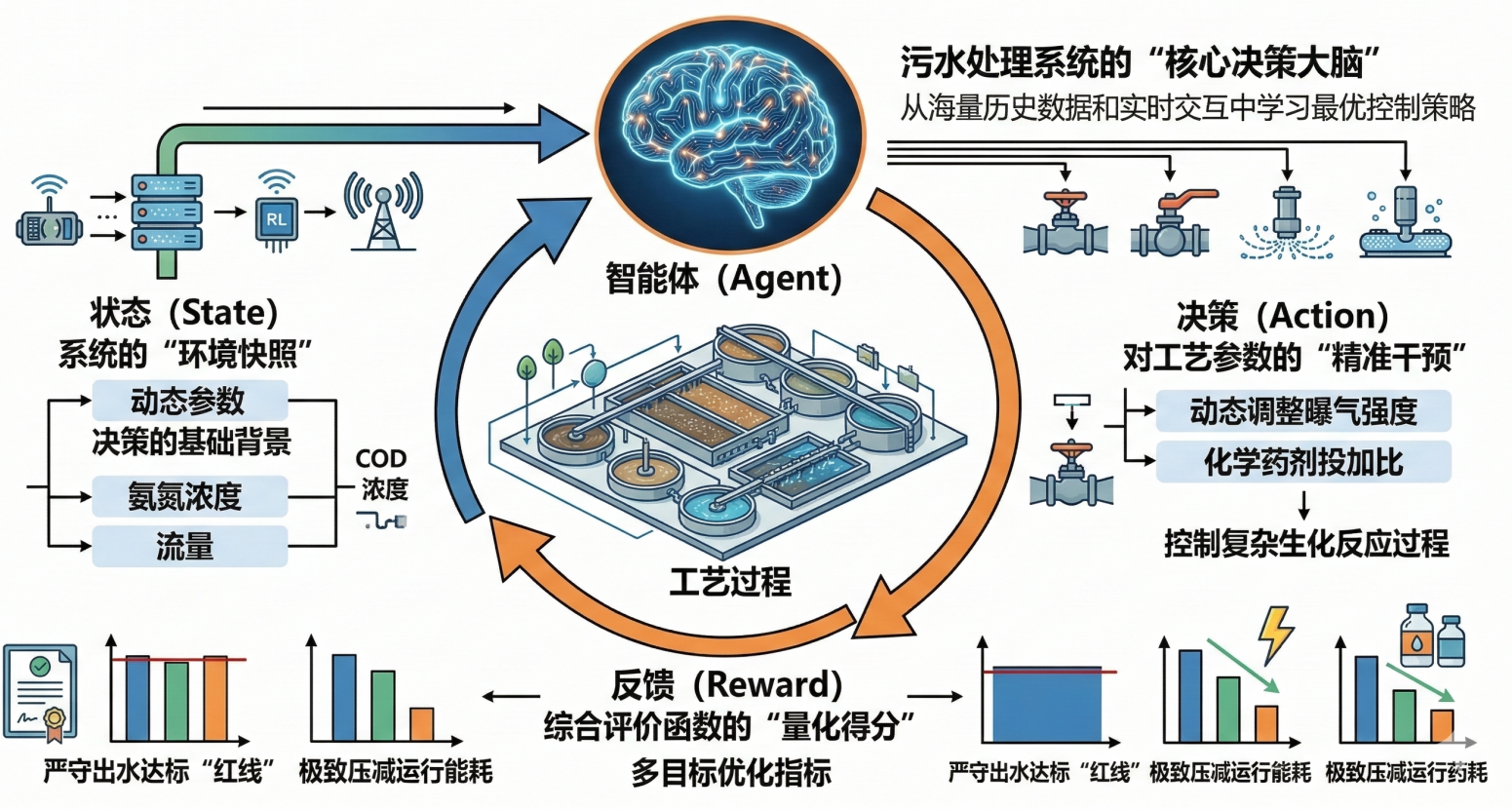
智能体(agent)不断的感知环境(environment)的当前的状态(State),做出相关的决策(Action) ,再获得环境的反馈(Reward) 。
以污水处理厂为例:
智能体:就是污水厂的管理员
状态:就是当前的入水水质
决策:就是当前时刻需要调整的曝气量和加药量
反馈:就是水质达标和能耗最低这个目标的分数
强化学习和机器学习的区别
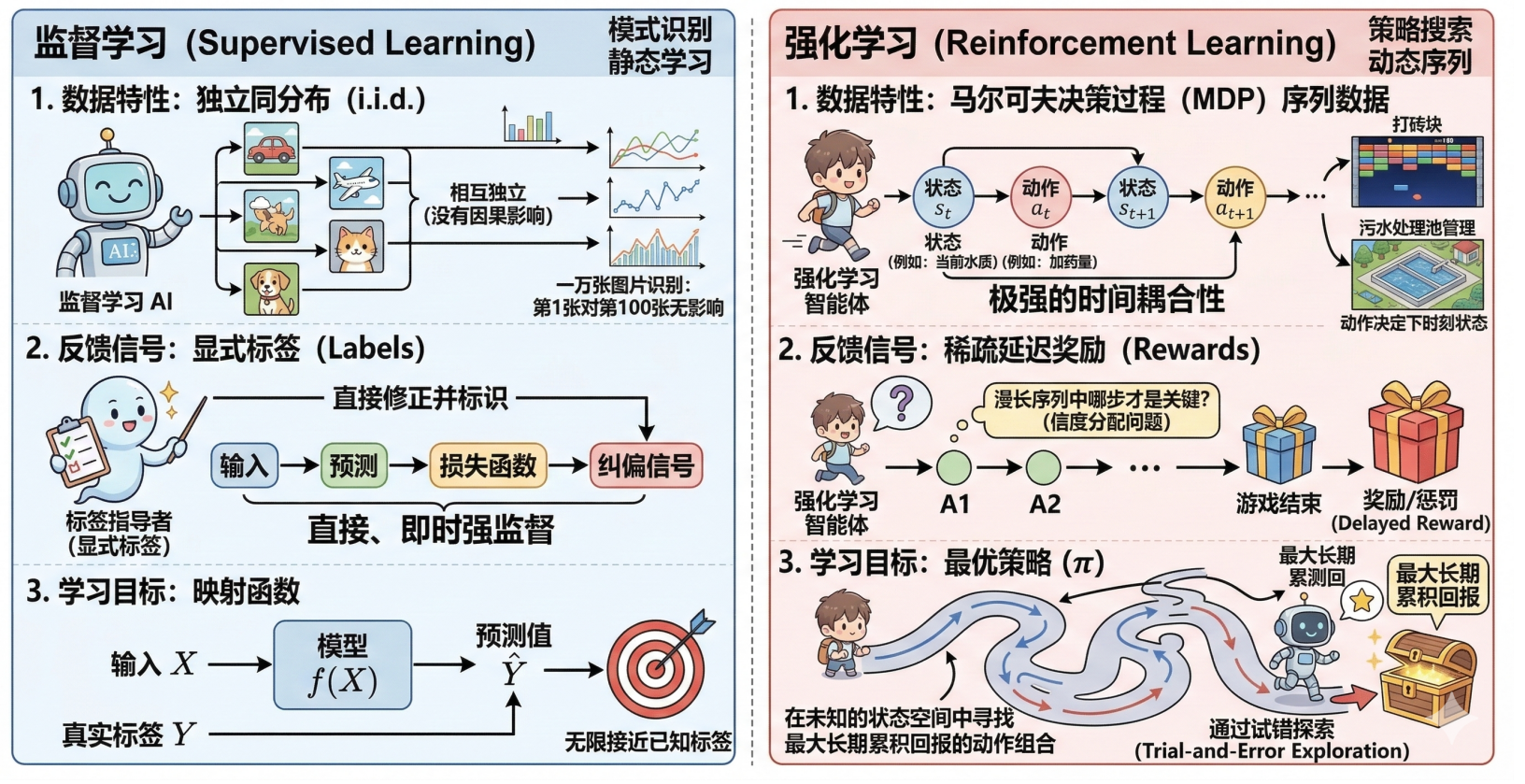
数据特性:独立同分布 (i.i.d.) vs. 时序关联性
监督学习(静态识别):核心假设是数据满足独立同分布。例如在图片分类中,你给 AI 输入一万
张图片,第 1 张是“汽车”还是“飞机”,对第 100 张的识别没有任何物理上的因果影响。
强化学习(动态序列):处理的是马尔可夫决策过程 (MDP) 中的序列数据。在玩“打砖块”或管理
“污水处理池”时,当前时刻的状态 s_t(如当前水质)和动作 a_t(如加药量)直接决定了下
一时刻的状态 s_{t+1}。数据之间存在极强的时间耦合性。
反馈信号:显式标签 (Labels) vs. 稀疏奖励 (Rewards)
监督学习(即时纠偏):拥有“上帝视角”的标签指导。算法每预测一次,损失函数(Loss
Function)就会立刻告诉它预测值与真实值的偏差,这是一种直接且即时的强监督信号。
强化学习(延迟评价):只有奖励信号,且往往具有延迟性 (Delayed Reward)。智能体做出的一
个动作,其好坏可能要到很久之后(如游戏结束或出水指标检测完)才能体现。它面临着“信度分
配问题”——即在漫长的操作序列中,到底哪一步才是导致最后成功的关键?
学习目标:模式识别 vs. 策略搜索
监督学习:本质是学习一个映射函数,目标是使预测值无限接近已知标签。
强化学习:本质是学习一个最优策略 。它没有预设的“正确动作”,必须通过试错探索 (Trial-and-
Error Exploration) 在未知的状态空间中寻找能带来最大长期累积回报的动作组合。
强化学习的例子
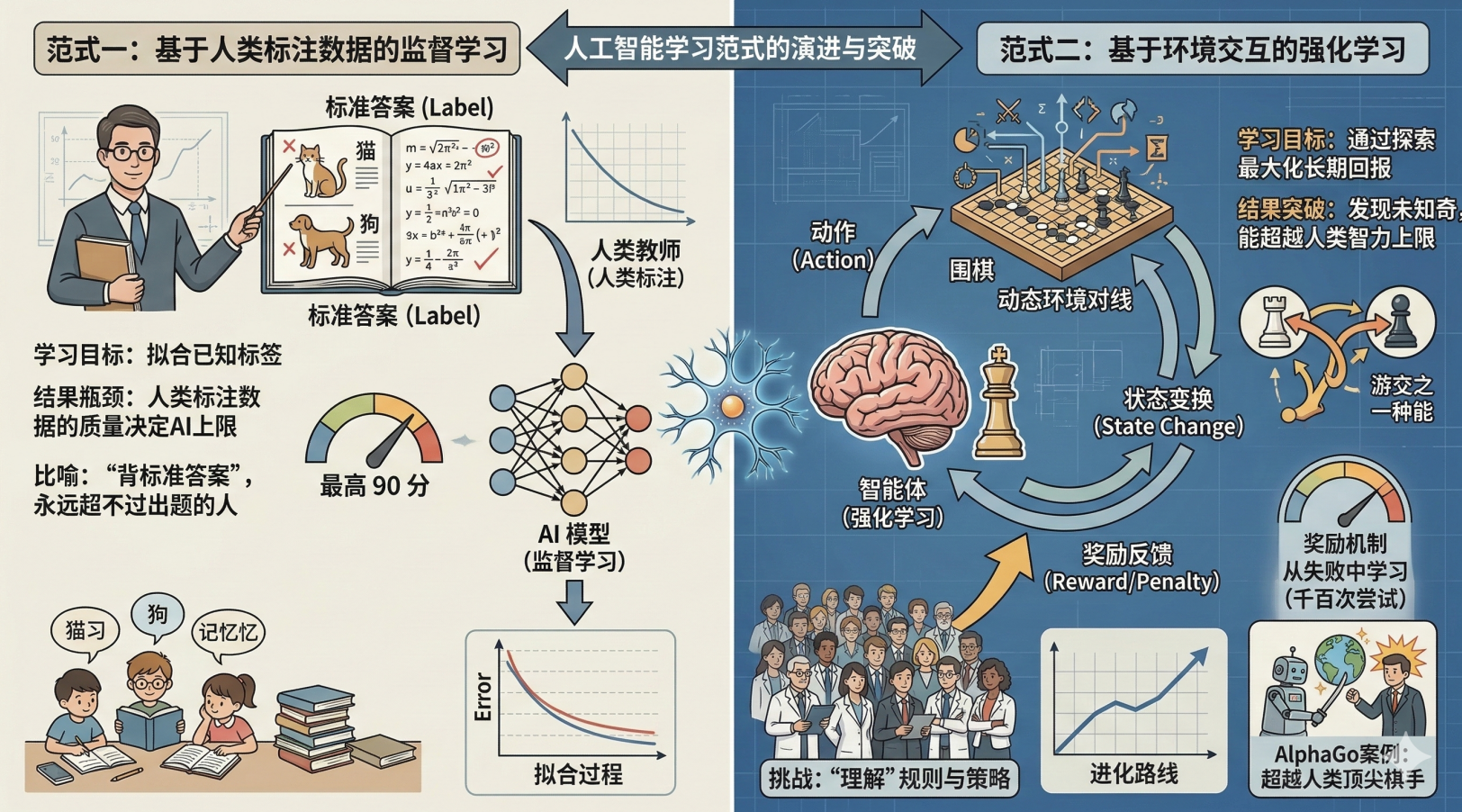
“如果说监督学习是让 AI 成为一个好学生,那强化学习就是让 AI 成为一个‘进化大师’。它不满足
于学会人类已有的知识,它要通过自学,推开人类从未触碰过的新世界大门。”
监督学习学习的是人类标注的数据。如果人类老师的水平只有 90 分,AI 再怎么学也顶多是 90
分。它是在“背标准答案”,永远超不过出题的人。强化学习它不看人的答案,它直接跟环境对线。
它在千万次的尝试中,能悟出人类根本没见过的奇招。就像 AlphaGo,它不是在模仿人类下棋,
而是在“理解”围棋。所以,它能打败全世界最聪明的大脑。
强化学习的历史
深度强化学习 = 深度学习 + 强化学习
在标准强化学习或传统计算机视觉时代,做事得分两步:
第一步:人工找重点(特征提取)。凭经验设计各种“滤镜”(比如 HOG、DPM),告诉电脑:这
张图里的线条、边缘在哪里。第二步:单独做判断(分类器)。找完重点后,再交给另一个工具
(比如 SVM)去猜这是猫还是狗。
2012 年 AlexNet 的出现彻底打破了这个僵局。它把上面两步合二为一了:
全自动学习:现在的神经网络既负责“看重点”,又负责“做决定”。它能在训练中自己悟出图片
的特征。端到端(End-to-End):数据从左边进去,结果从右边出来。
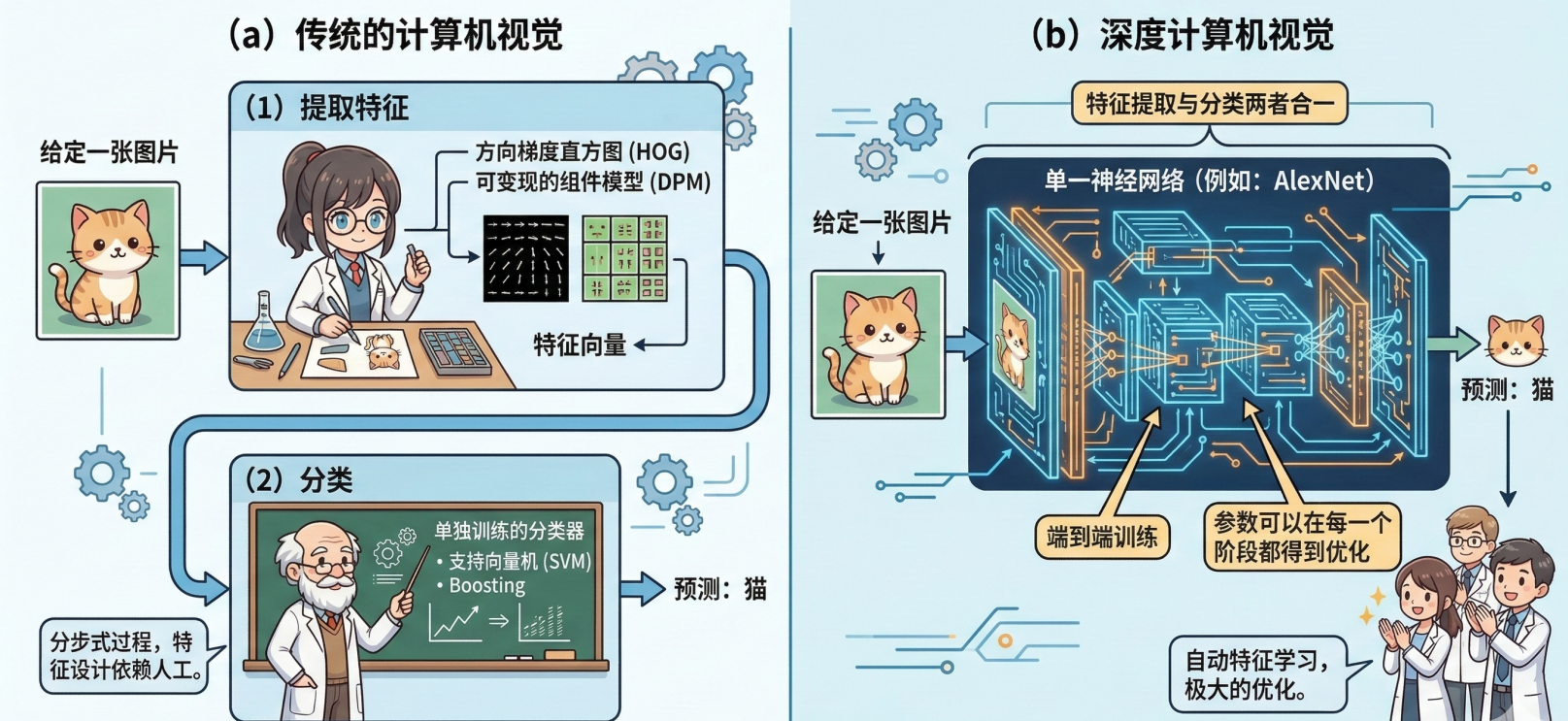
标准强化学习:比如 TD-Gammon 玩 Backgammon 游戏的过程,其实就是设计特征,然后训练价
值函数的过程,如图 1.10a 所示。标准强化学习先设计很多特征,这些特征可以描述现在整个状
态。得到这些特征后,我们就可以通过训练一个分类网络或者分别训练一个价值估计函数来采取动
作。
深度强化学习:自从我们有了深度学习,有了神经网络,就可以把智能体玩游戏的过程改进成一个
端到端训练(end-to-end training)的过程,如图 1.10b 所示。我们不需要设计特征,直接输入状
态就可以输出动作。我们可以用一个神经网络来拟合价值函数或策略网络,省去特征工程(feature
engineering)的过程。


强化学习的应用
为什么强化学习在这几年有很多的应用,比如玩游戏以及机器人的一些应用,并且可以击败人类的
顶尖棋手呢?这有如下几点原因。首先,我们有了更多的算力(computation power),有了更多
的 GPU,可 以更快地做更多的试错尝试。其次,通过不同尝试,智能体在环境里面获得了很多信
息,然后可以在环境里面取得很大的奖励。最后,我们通过端到端训练把特征提取和价值估计或者
决策一起优化,这样就可以 得到一个更强的决策网络。

强化学习在水厂的应用和思考
从“全时段”到“按需控”:一种污水处理自适应节能策略
Yan, Yi-Fan & Li, Dapeng & Li, Dongjuan & Liu, Lei & Liu, Yan. (2025). Reinforcement Learning-
Based Adaptive Event-Triggered Control for Wastewater Treatment Process. IEEE Transactions
on Industrial Informatics. PP. 1-12. 10.1109/TII.2025.3626044.
链接:https://ieeexplore.ieee.org/document/11247853/(阅读原文)
IEEE Transactions on Industrial Informatics(中科院1区top)
北京工业大学
Environmental Science & Technology上发表了题为“Multi-objective Optimization of
Papermaking Wastewater Treatment Processes under Economic, Energy, and Environmental
Goals”的研究论文(DOI: 10.1021/acs.est.4c03460)
面对这一多目标优化问题,研究在强化学习深度确定性策略梯度算法(Deep Deterministic
Policy Gradient,DDPG)的基础上,提出了一种自适应多目标优化框架,通过基于马尔可夫随
机博弈构
建的自适应过程对智能体进行训练,以寻找污水处理过程的最优控制策略,分别实时代理优化等控
制变量,实现处理过程的表现实现整体提升上述污水处理过程的动态多目标优化问题可以看作是马
尔可夫决策过程中的多智能体非零和随机博弈。其中,两个智能体通过分别代理做出动作,从环境
(SIMULINK模拟的造纸污水处理过程)中依据目标组合函数获取各自的奖励。在学习过程中,智
能体依靠元组{S,A,T,R},通过马尔可夫决策过程(Markov Decision Process,MDP)在与环
境交互中不断学习和优化其动作策略。考虑到不同智能体的经验共享可以提高算法性能研究中设定
每个智能体在动作回合中都可以观察到对方的动作和奖励。其中,污水变量信息组成智能体的状态
空间,计算目标函数得出的运行成本、能耗和温室气体量减量形成模型奖励。智能体在与环境交互
中收到的反馈基础上调整动作策略来调整控制变量设定值,从而改进在环境中的表现。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)