KGGen:用大模型从纯文本中提取高质量知识图谱,解决信息稀疏难题&代码
KGGen:用大模型从纯文本中提取高质量知识图谱,解决信息稀疏难题
本文基于斯坦福大学等机构发表于NeurIPS 2025的论文《KGGen: Extracting Knowledge Graphs from Plain Text with Language Models》进行解读。文章介绍了如何利用大语言模型(LLM)从非结构化文本中自动构建高质量、稠密的知识图谱,并提出了首个用于评估文本到图谱提取能力的基准测试MINE。
项目地址:https://github.com/stair-lab/kg-gen/
引言:知识图谱的“数据荒”与质量困境
知识图谱(KG)作为以“实体-关系-实体”三元组形式组织知识的结构化表示,已成为信息检索、推荐系统及检索增强生成(Graph RAG)等任务的核心基础。然而,当前主流知识图谱(如 Wikidata、DBpedia)面临两大挑战:
- 数据稀缺:高质量图谱多为人工标注,规模有限。
- 质量参差:自动化提取的图谱(如基于早期NLP技术或规则)通常存在信息不完整、关系缺失严重的问题。
传统提取方法(如 OpenIE)和较新的方案(如微软的 GraphRAG)虽能直接从文本中抽取三元组,但普遍缺乏有效的实体解析和关系归一化机制。这导致生成的图谱中,不同实体和关系类型过多,图谱极度稀疏、连通性差,严重制约了其在下游任务(如图嵌入、RAG)中的实用价值。
为此,研究团队提出了 KGGen——一个开创性的文本到知识图谱生成器。它不仅能利用大语言模型从纯文本中提取知识,更关键的是,通过一种新颖的迭代聚类算法对实体和关系进行解析与去重,显著减少了图谱的稀疏性,生成了更稠密、更通用的知识图谱。
KGGen核心方法:三步构建高质量图谱
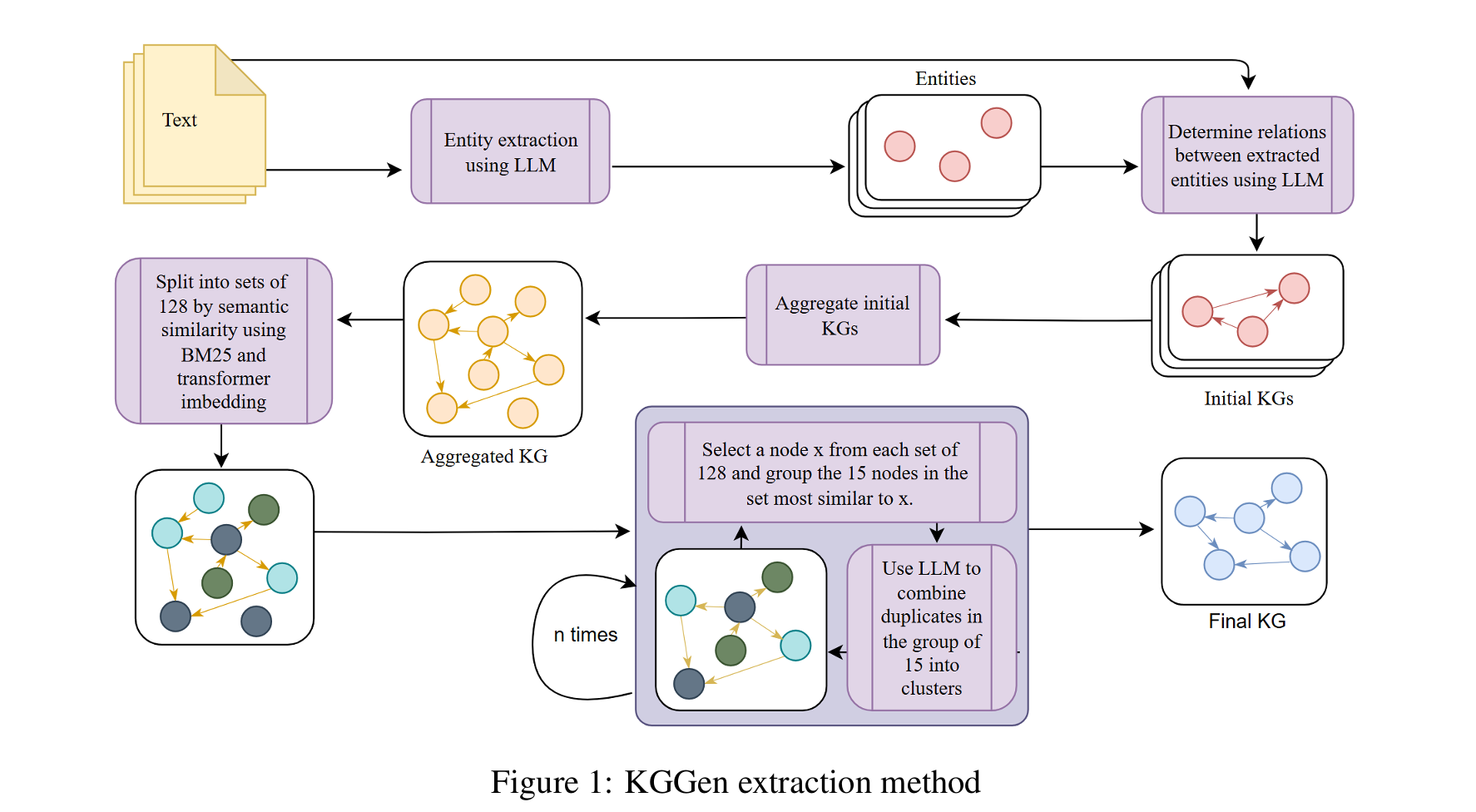
KGGen采用一种多阶段的、稳健的流程,确保最终生成的知识图谱既丰富又紧凑。
1. 实体与关系提取
首先,使用大语言模型(论文中采用 Google Gemini 2.0 Flash)分两步处理输入文本:
- 第一步:识别并列出文本中的所有关键实体。
- 第二步:基于已识别的实体列表,提取出规范的(主语,谓语,宾语)三元组。
这种两步法优于单步提取,能更好地保证实体在不同三元组中的一致性。
2. 图谱聚合
将从多个文本源中提取出的所有三元组(实体和边)汇集,合并成一个统一的原始图谱,并进行基础的正规化(如全部转为小写)。此步骤主要在结构层面进行整合,不涉及语义理解。
3. 实体与边解析(核心创新)
这是KGGen区别于以往方法的关键。前两步得到的原始图谱包含大量指代相同现实概念的重复或同义实体/关系(例如,“冬季奥运会”、“冬奥会”、“Winter Olympic Games”)。KGGen采用一种结合了嵌入聚类与大模型判别的混合策略来解决此问题:
- 聚类:使用Sentence-BERT获取所有实体和关系的语义嵌入,然后用k-means进行初步聚类。
- 相似性检索:在每个簇内,为每个项目,通过融合BM25和语义相似度的方法,检索出top-k个最相似的项目。
- 大模型判别:将检索出的相似项目组合并输入给大语言模型,由其判断哪些是真正的重复项(考虑时态、单复数、缩写等变体)。
- 规范代表选择:对于被判定为重复的一组项目,由LLM选出一个最能代表其共同含义的“规范名称”,类似知识库中的“别名”机制。
通过这一步骤,KGGen能够将分散的、表达各异的同义信息进行合并,大幅减少图中节点和边类型的数量,从而得到一个更稠密、更具通用性、更适合进行嵌入学习的知识图谱。
全新基准测试:MINE
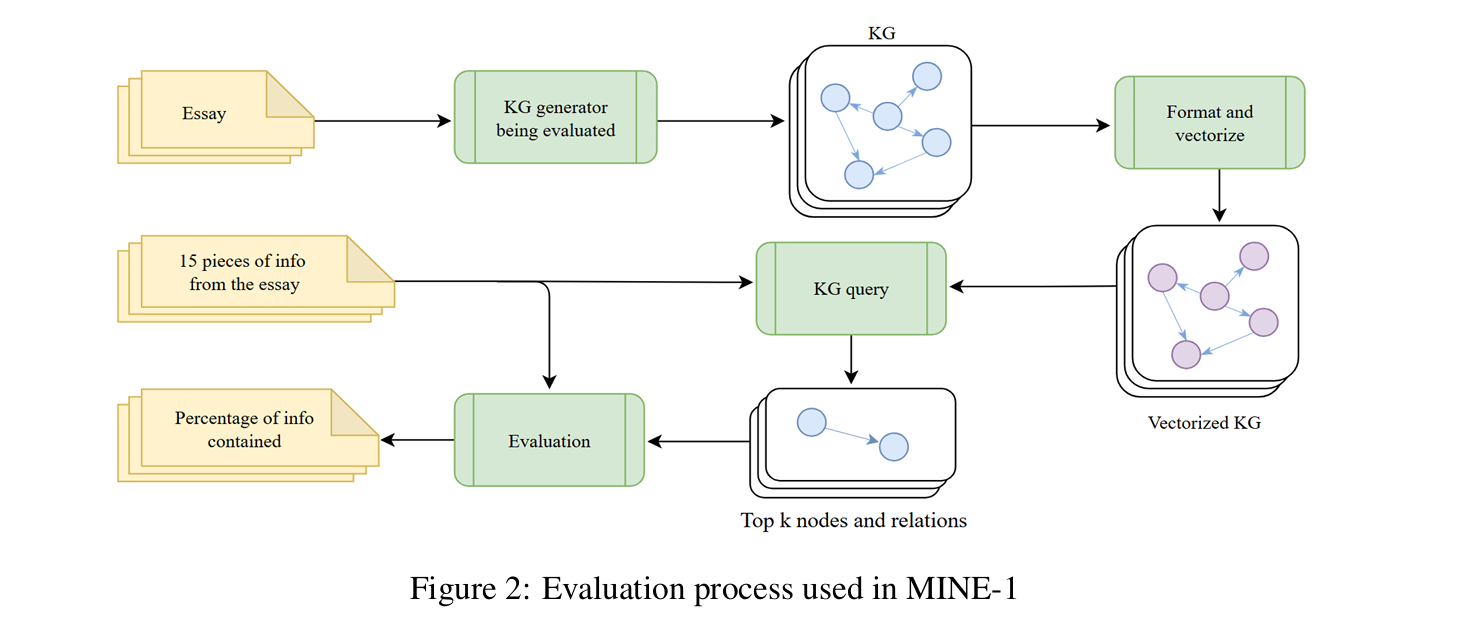
MINE‑1 简要解析
MINE‑1 是一个不依赖下游任务的知识图谱(KG)抽取器评测指标,直接衡量抽取器从文章中能捕捉到的真实信息比例,避免因下游任务提升干扰对抽取器本身效果的判断。
数据集构成
- 共 100 篇文章,每篇对应 15 条已验证存在于文中的事实
- 平均长度 592 词(标准差 85,范围 440–976)
- 主题均衡覆盖:艺术文化社会、科学、技术、心理/人类体验、历史文明
- 文章由 LLM 生成,保证领域分布均衡
评估流程
- 用待测 KG 抽取器从每篇文章生成知识图谱
- 预先通过 LLM + 人工校验得到每篇 15 条真实事实
- 用语义嵌入(all‑MiniLM‑L6‑v2)对事实与 KG 节点做相似度检索
- 取 top‑k 节点并扩展两跳关系子图,再用 LLM 判断该事实能否从子图推理得出(输出 0/1)
- 最终得分:100 篇文章中,能被 KG 恢复的事实占比的平均值
可靠性验证
随机选 60 对事实‑KG 做人工标注,与 LLM 判断 一致率 90.2%,相关系数 0.80,证明评估方式可信。
MINE‑2 简要解析
研究在 WikiQA 数据集(20400 个问题、1995 篇维基百科文章)上评估 RAG 系统。
- 先用对应方法从数据集文章里构建统一知识图谱(KG)。
- 用
all-MiniLM-L6-v2对问题和 KG 三元组做向量编码,计算余弦相似度;同时用 BM25 算相关性,两者等权融合。 - 取融合得分最高的 top‑10 三元组,再做两跳扩展,补充 10 个相邻三元组,支持多跳推理。
- 因为 KGGen、GraphRAG 会把关系关联到原文块,所以把 20 个三元组+原文块+问题 一起输入大模型生成答案。
- 最后用 LLM-as-a-Judge 自动评估答案是否正确。
- OpenIE 未参与对比,因为它生成的 KG 无法把关系关联回原文块。
文提出了 MINE 基准测试,包含两个任务:
-
MINE-1:知识留存评估
评估提取器从短文本文档中保留原始信息的能力。它包含100篇涵盖各领域的文章,每篇文章附带15个已知事实。通过计算从生成的知识图谱中能成功推断出这些事实的比例,来评价提取器的“信息保真度”。实验表明,KGGen在不同大模型(Claude Sonnet 3.5, GPT-4o等)上均能保持稳健且领先的性能。 -
MINE-2:图谱辅助的RAG性能评估
评估基于所生成图谱进行问答检索的效果。基于WikiQA数据集,用提取器从所有相关文章构建一个大型知识图谱,然后测试在该图谱上检索答案的准确率。KGGen在此项任务上与GraphRAG表现相当,但其图谱结构更为简洁和通用。
效果对比:KGGen为何更胜一筹?
论文从多个维度将KGGen与OpenIE、GraphRAG进行了对比:
-
图谱质量与稀疏性:
- KGGen 提取的三元组符合规范,实体和关系经过合并,图谱稠密,关系可复用性强。例如,当文本语料库规模增大时,KGGen定义的关系类型会被重复使用,平均每个关系类型可使用约10次,且次数随语料库增大而增加。
- GraphRAG 提取的结构通常包含很长的、非规范的文本片段作为节点和边,更接近“带关系的文本摘要”而非标准知识图谱。其图谱通常非常稀疏,且关系泛化能力弱,平均每个关系类型仅使用约2次。
- OpenIE 常产生大量超特定、不连贯的短语作为节点,并包含大量无信息的通用节点(如“it”, “are”),导致图谱嘈杂、冗余且连通性不合理。
-
效率与扩展性:
- 在处理百万字符量级的大型文本时,KGGen(包含提取和解析全过程)的总处理时间(551秒)远低于GraphRAG仅完成提取阶段所需的时间(2319秒)。
- 在去重效果上,对于百万字符文本,KGGen通过智能合并,减少了约22.4%的实体和23%的边,且去重率随规模增大而提升,证明了其算法的高效性。
应用前景与社区反响
KGGen为缓解高质量知识图谱数据稀缺的问题提供了一个强大、开源的解决方案。更优质的知识图谱提取器有望促进结构化知识的普及,提升信息检索系统的准确性和可靠性。自发布以来,KGGen已在社区中获得广泛关注,其GitHub仓库已收获超过700颗星,下载量超过12,000次。
局限性
尽管优势明显,KGGen仍有改进空间,例如在实体/关系合并过程中可能存在“过度合并”或“合并不足”的情况。此外,当前基准测试的语料规模(最高500万词元)与构建真正的“图谱基础模型”所需的网络级文本规模相比仍有差距。在医疗、金融等专业领域,通用大语言模型可能缺乏领域知识,影响提取精度,未来可探索结合领域本体来提升效果。
总结
KGGen通过巧妙地将大语言模型的强大理解能力与传统的语义聚类、去重算法相结合,成功实现了从纯文本到高质量、低稀疏性知识图谱的自动化构建。它不仅提供了实用的工具,还通过MINE基准测试为这一研究方向设立了评估标准。对于任何需要从大量非结构化文档中构建结构化知识,并用于增强RAG、图分析或机器学习的开发者来说,KGGen都是一个值得关注和尝试的优秀框架。
项目代码简要解析
📊 kg-gen 项目全面解读
🎯 项目核心功能
1️⃣ 主要用途
- 从纯文本中自动提取结构化知识图谱
- 支持 RAG(检索增强生成)应用
- 生成用于模型训练的图数据
- 分析概念间的关系
2️⃣ 支持的模型
支持多种模型提供商:
- OpenAI (如
openai/gpt-4o,openai/gpt-5) - Google Gemini (如
gemini/gemini-2.5-flash) - Ollama 本地模型 (如
ollama_chat/deepseek-r1:14b) - Anthropic、Deepseek 等
🏗️ 项目架构
kg-gen/
├── src/kg_gen/ # 核心代码
│ ├── kg_gen.py # 主类 KGGen 实现
│ ├── cli.py # 命令行接口
│ ├── models.py # 数据模型定义
│ ├── steps/ # 处理步骤
│ │ ├── _1_get_entities.py # 实体提取
│ │ ├── _2_get_relations.py # 关系提取
│ │ └── _3_deduplicate.py # 去重聚类
│ └── utils/ # 工具函数
│ ├── chunk_text.py # 文本分块
│ ├── deduplicate.py # 去重逻辑
│ └── visualize_kg.py # 可视化
├── mcp/ # MCP 服务器(AI 助手记忆)
├── examples/ # 示例代码
└── tests/ # 测试文件
🔧 核心工作流程
三步处理流程:
# 第 1 步:实体提取
entities = get_entities(text)
# 输出:{'Linda', 'Ben', 'Andrew', 'Josh'}
# 第 2 步:关系提取
relations = get_relations(text, entities)
# 输出:{('Linda', 'is mother of', 'Josh'), ...}
# 第 3 步:去重聚类
deduplicated_graph = deduplicate(graph)
# 合并相似实体和关系
💻 核心 API 使用
基础用法:
from kg_gen import KGGen
# 初始化
kg = KGGen(model="openai/gpt-4o", temperature=0.0)
# 从文本生成知识图谱
graph = kg.generate(
input_data="Linda 是 Josh 的母亲。Ben 是 Josh 的兄弟。",
context="家庭关系"
)
# 结果包含:
# - entities: 实体集合
# - relations: (主体,谓词,客体) 三元组
# - edges: 关系类型集合
高级功能:
- 处理长文本(分块处理):
graph = kg.generate(
input_data=large_text,
chunk_size=5000, # 每块 5000 字符
cluster=True # 自动聚类
)
- 对话数据处理:
messages = [
{"role": "user", "content": "法国的首都是?"},
{"role": "assistant", "content": "巴黎"}
]
graph = kg.generate(input_data=messages)
- 多图聚合:
combined = kg.aggregate([graph1, graph2])
- 可视化:
KGGen.visualize(graph, "output.html", open_in_browser=True)
🤖 技术亮点
1. DSPy 框架
- 使用 DSPy 进行结构化输出生成
- 自动优化提示词
- 支持思维链(Chain of Thought)
2. 智能去重
三种去重策略:
- SEMHASH: 基于语义哈希的规则去重
- LM_BASED: KNN 聚类 + LLM 去重
- FULL: 两者结合
3. 嵌入与检索
# 生成嵌入
node_emb, rel_emb = kg.generate_embeddings(graph)
# 检索相关节点
top_nodes, context = kg.retrieve(query, node_emb, graph)
🌐 MCP 服务器(AI 助手记忆)
这是项目的特色功能,为 AI 助手提供持久化记忆能力:
# 启动 MCP 服务器
kggen mcp
# 自定义配置
kggen mcp --model gemini/gemini-2.0-flash --storage-path ./memory.json
提供的工具:
add_memories: 从文本提取并存储记忆retrieve_relevant_memories: 检索相关记忆visualize_memories: 生成记忆图谱可视化get_memory_stats: 查看记忆统计
📦 安装与依赖
# 基础安装
pip install kg-gen
# 从源码安装
pip install -e '.[dev]'
# MCP 功能
pip install 'kg-gen[mcp]'
核心依赖:
dspy-ai: 提示词优化litellm: 统一模型调用接口sentence-transformers: 语义嵌入semhash: 语义去重networkx: 图算法pydantic: 数据验证
🎨 可视化功能
项目提供了精美的交互式 Web 可视化界面:
- 力导向图展示实体和关系
- 支持聚类分组显示
- 可交互探索节点邻居
- 统计面板显示图谱指标
📝 实际应用示例
from kg_gen import KGGen
text = """
神经网络是一种机器学习模型。
深度学习是机器学习的子集,使用多层神经网络。
监督学习需要训练数据来学习模式。
"""
kg = KGGen(model="openai/gpt-4o")
graph = kg.generate(
input_data=text,
chunk_size=5000,
cluster=True
)
# 查看结果
print(f"实体:{graph.entities}")
print(f"关系:{graph.relations}")
# 可视化
KGGen.visualize(graph, "ml_knowledge_graph.html", open_in_browser=True)
🎯 适用场景
✅ 构建领域知识库
✅ RAG 系统的图结构索引
✅ 对话历史的结构化存储
✅ 学术论文概念关系提取
✅ 法律文档事实抽取
✅ AI 助手的长期记忆系统

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)