为什么大模型能记住那么多知识?从参数到涌现能力讲透
模型架构的能力增强(Model Scaling)是指通过增加神经网络的参数数量、训练数据规模或计算资源来提升模型性能的现象。这种增强不仅仅是简单的"量变",更常常带来意想不到的"质变"——模型开始展现出在小规模时完全不具备的新能力。想象你有一个学生,当他只读过几本书时,只能回答简单的问题。但当他读过的书越来越多,大脑中的神经连接越来越复杂时,他不仅能回答更难的问题,甚至开始能够进行逻辑推理、创作诗
🚀 本文收录于Github:AI-From-Zero 项目 —— 一个从零开始系统学习 AI 的知识库。如果觉得有帮助,欢迎 ⭐ Star 支持!
什么是模型架构的能力增强?为什么更大的模型能记住更多知识?
一、简介
模型架构的能力增强(Model Scaling)是指通过增加神经网络的参数数量、训练数据规模或计算资源来提升模型性能的现象。这种增强不仅仅是简单的"量变",更常常带来意想不到的"质变"——模型开始展现出在小规模时完全不具备的新能力。
说人话就是: 想象你有一个学生,当他只读过几本书时,只能回答简单的问题。但当他读过的书越来越多,大脑中的神经连接越来越复杂时,他不仅能回答更难的问题,甚至开始能够进行逻辑推理、创作诗歌、解决从未见过的数学题。大模型就像这个超级学生——更多的参数就是更大的"脑容量",让它能够存储和处理更丰富的知识。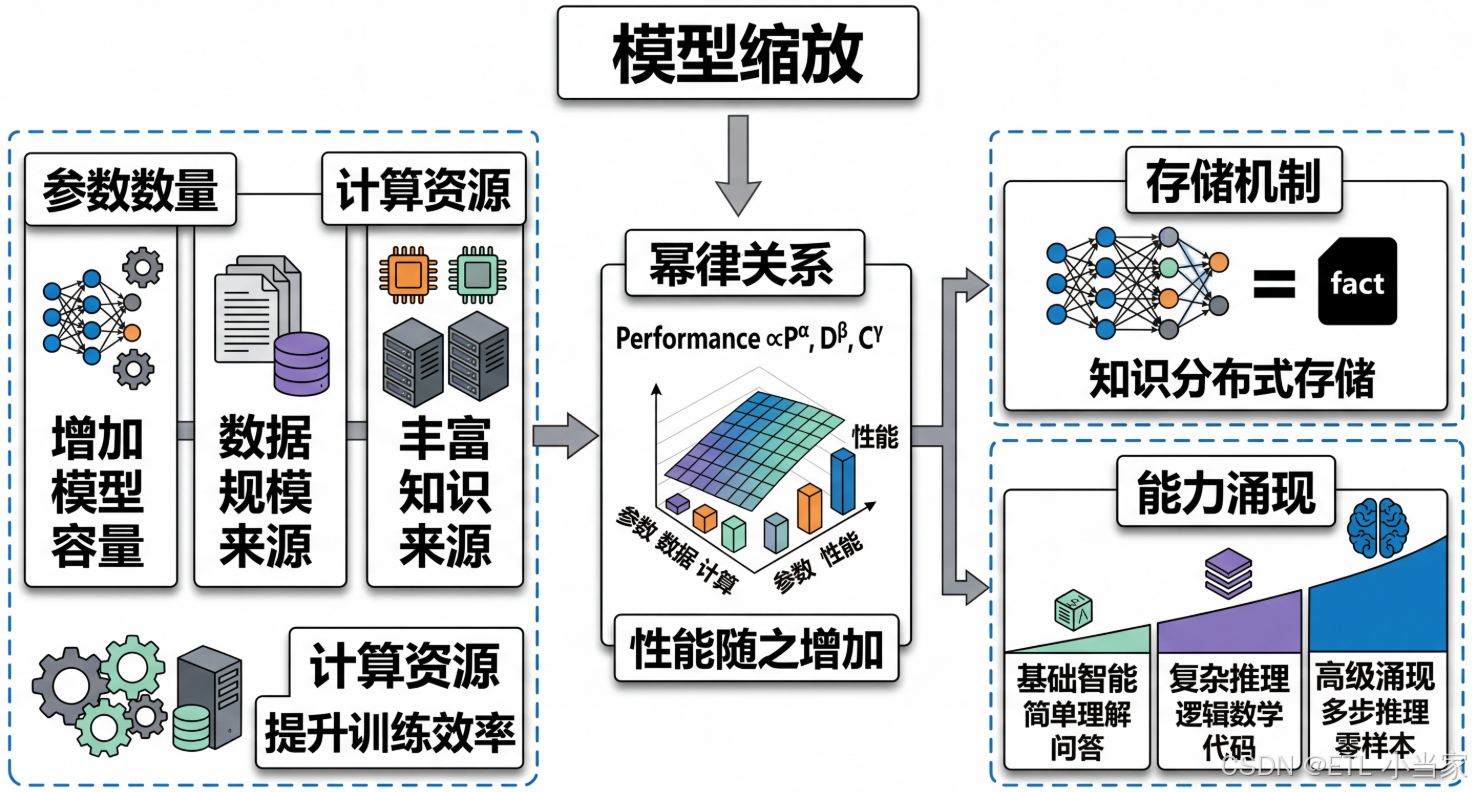
二、为什么更大的模型能记住更多知识?
参数即记忆容量
在神经网络中,参数(parameters)就是模型的记忆单元。每个参数都存储着某种模式或知识的权重。当模型规模增大时:
- 更多的参数 = 更大的知识库:可以同时记住更多的事实、概念和关系
- 更深的网络 = 更复杂的抽象能力:能够建立多层次的概念理解
- 更宽的层 = 更并行的处理能力:可以同时考虑多个维度的信息
缩放定律(Scaling Laws)
研究人员发现了一个惊人的规律:模型性能与参数数量、数据规模、计算量之间存在可预测的幂律关系。
| 要素 | 影响 | 典型关系 |
|---|---|---|
| 参数数量 | 模型容量 | 性能 ∝ 参数^α |
| 训练数据 | 知识广度 | 性能 ∝ 数据^β |
| 计算资源 | 训练效率 | 性能 ∝ 计算量^γ |
其中α、β、γ是经验常数,通常在0.1-0.3之间。
三、能力涌现(Emergent Abilities)
最神奇的是,大模型会表现出能力涌现现象——某些能力在模型达到特定规模之前完全不存在,一旦超过阈值就突然出现。
经典涌现能力示例
| 模型规模 | 能力表现 |
|---|---|
| < 1亿参数 | 基础语言理解,简单问答 |
| 1-10亿参数 | 复杂问答,基础推理 |
| 10-100亿参数 | 数学计算,代码生成 |
| > 1000亿参数 | 涌现能力:多步推理、零样本学习、复杂规划 |
比如,小模型可能无法理解"如果A比B高,B比C高,那么A和C谁高?"这样的传递性推理问题。但当模型足够大时,它突然就能正确回答这类问题,即使训练数据中从未明确教过这种逻辑规则。
四、知识存储的机制
分布式表示 vs 符号存储
大模型并不像数据库那样存储具体的事实,而是采用分布式表示:
- 知识被编码在参数的权重分布中
- 相似概念在向量空间中距离相近
- 关系通过向量运算体现(如"国王 - 男人 + 女人 ≈ 女王")
这种表示方式让模型能够:
- 泛化:从未见过的组合也能合理推断
- 容错:部分信息缺失仍能保持整体理解
- 压缩:用相对较少的参数存储海量知识
上下文窗口 vs 参数记忆
大模型有两种记忆方式:
| 记忆类型 | 特点 | 限制 |
|---|---|---|
| 上下文记忆 | 通过注意力机制记住当前对话历史 | 受限于上下文窗口长度(如8K-128K tokens) |
| 参数记忆 | 知识固化在模型参数中 | 需要重新训练才能更新,但容量巨大 |
五、实际影响与挑战
积极影响
- 更强的通用性:一个大模型可以胜任多种任务,无需为每个任务单独训练
- 更好的零样本/少样本学习:面对新任务时,只需少量示例就能快速适应
- 更自然的交互:能够理解复杂的指令和上下文
面临挑战
- 计算成本:训练千亿参数模型需要数千GPU数月时间
- 推理延迟:大模型响应速度较慢,难以实时应用
- 知识固化:训练完成后无法轻易更新知识
- 环境影响:巨大的能源消耗带来碳足迹问题
六、未来发展方向
1. 高效缩放
研究如何用更少的参数获得相同的性能,如稀疏激活、混合专家(MoE)等技术。
2. 持续学习
让大模型能够在不遗忘旧知识的前提下持续学习新知识。
3. 模块化架构
将大模型分解为专门的子模块,按需调用,提高效率。
4. 知识编辑
开发技术直接修改模型中的特定知识,而无需重新训练整个模型。
模型架构的能力增强不仅是技术进步,更是我们理解智能本质的重要窗口。正如人类大脑的进化一样,更大的规模带来了更复杂的能力,但这只是智能演化的开始,而非终点。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)