大模型算法(六):强化学习
1、RL算法
1.1 基础理论算法
是所有 RL 算法的底层框架,定义了 RL 的核心学习范式,无工程直接落地性,但必须掌握。
-
Monte-Carlo RL(MC,蒙特卡洛强化学习):基于完整轨迹回报的无模型学习,首次实现 “从经验中学习”,适用于短轨迹、无终止状态任务。
-
Temporal-Difference RL(TD,时序差分学习):融合 MC 和动态规划,基于单步增量回报学习,是 RL 的核心框架,在线更新、无需完整轨迹。
-
Sarsa (λ)/Q-Learning (λ)(资格迹 TD 学习):TD 的扩展,引入资格迹(Eligibility Trace),融合单步 TD 和多步 MC,平衡学习速度和稳定性,λ∈[0,1] 调节。
-
Dynamic Programming(DP,动态规划):有模型 RL 的基础,基于环境模型做策略迭代 / 价值迭代,仅适用于小状态空间(如网格世界)。
-
MDP Solver(马尔可夫决策过程求解器):含策略评估、策略改进、价值迭代,是所有 RL 算法的理论参照,无实际工程应用。
-
POMDP Solver(部分可观测马尔可夫决策过程求解器):MDP 的扩展,解决状态部分观测问题,代表算法POMCP(蒙特卡洛树搜索 + POMDP),适用于传感器受限场景。
1.2 无模型价值基算法(离散动作核心)
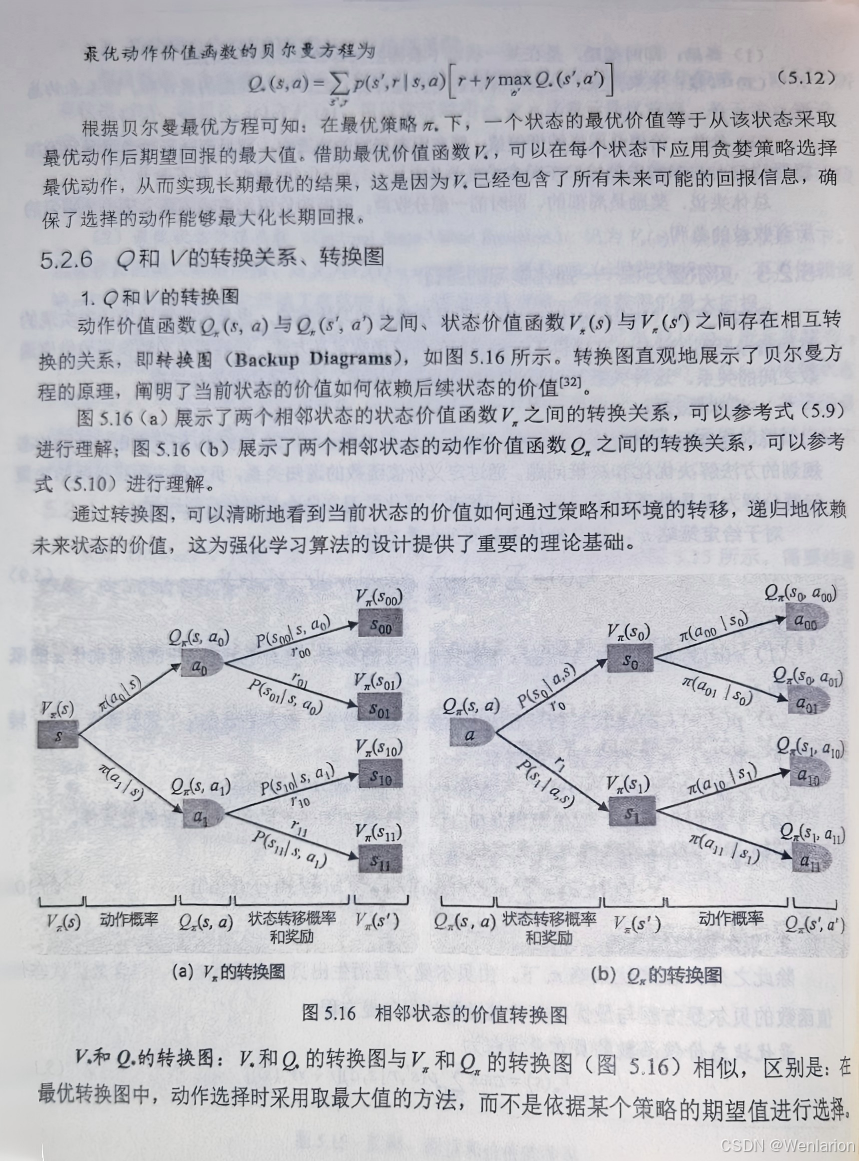
仅适配离散动作空间,训练稳定、实现简单,是入门首选,核心优化动作价值函数 Q (s,a)。
经典基础
-
Q-Learning:离线策略 TD 算法,核心是 “异策略更新”,无需遵循当前策略选动作,是所有价值基算法的鼻祖。
-
SARSA:在线策略 TD 算法,“同策略更新”(动作选择与更新一致),比 Q-Learning 更保守,适用于需规避风险的场景(如机器人避障)。
-
Expected SARSA:SARSA 的改进,用动作期望回报替代单步采样回报,降低训练方差,稳定性优于 SARSA。
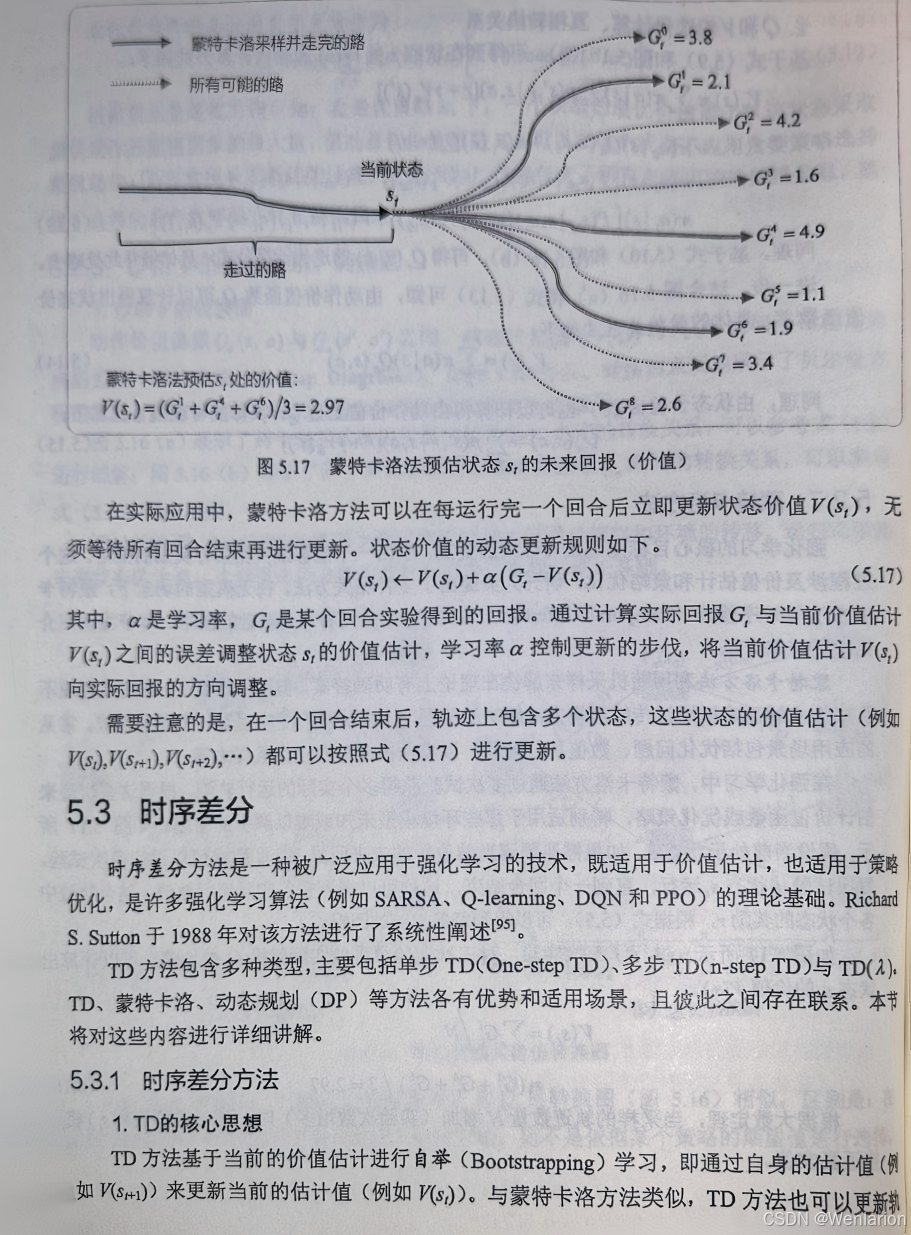
DQN 及全变种(深度价值基核心,工程落地主流)
-
DQN(Deep Q-Network):深度 RL 里程碑,引入经验回放 + 目标网络,解决深度学习与 RL 结合的不稳定性,适配高维状态空间(如雅达利游戏)。
-
Double DQN:解决 DQN 的Q 值过估计问题,用当前 Q 网络选动作、目标 Q 网络评价值,提升估计精度。
-
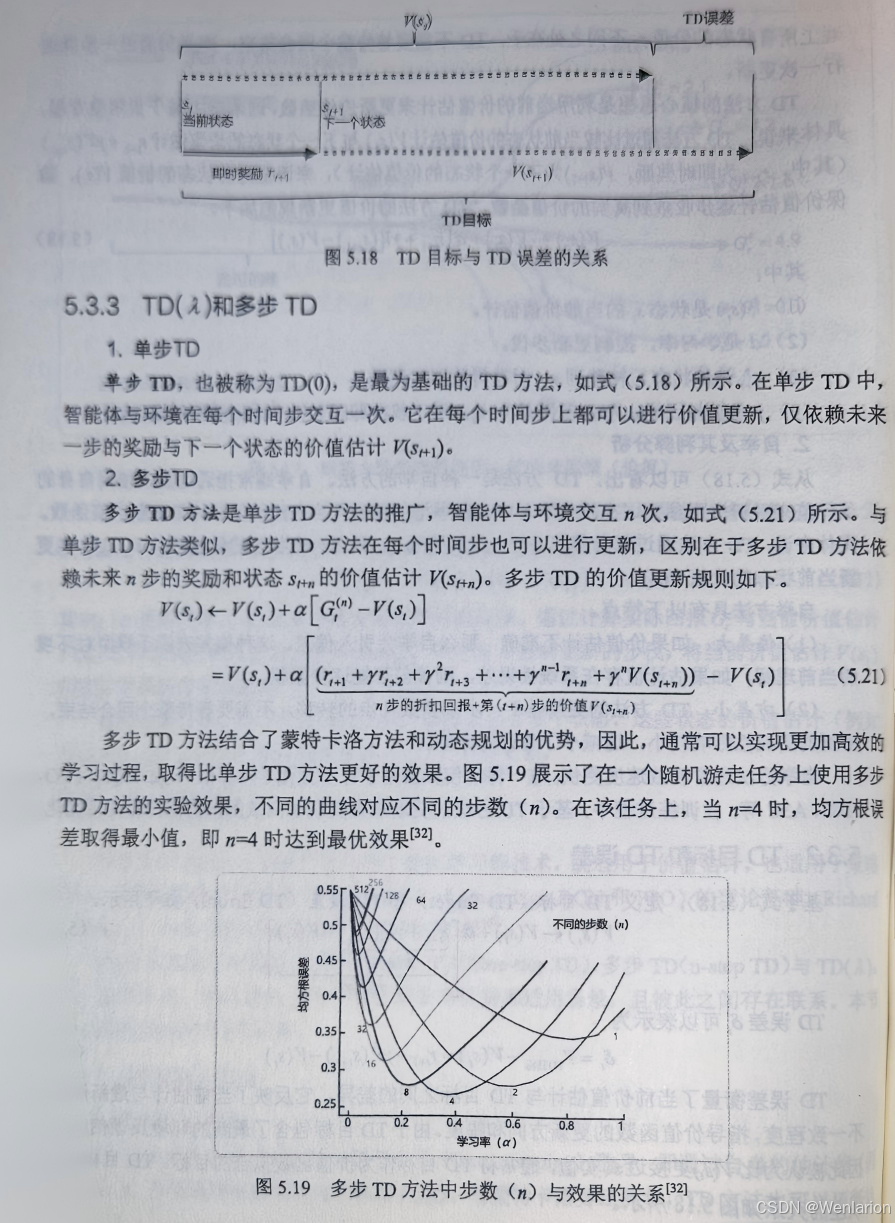
Dueling DQN:将 Q 网络拆分为状态价值 V (s)和优势函数 A (s,a),精准学习 “状态本身的价值”,适用于状态影响远大于动作的场景。
-
Prioritized Experience Replay(PER-DQN):基于回报误差加权经验回放,优先学习 “高价值样本”,提升样本效率。
-
Noisy DQN:引入噪声线性层替代 ε- 贪心探索,实现自适应探索,探索效率更高,适用于复杂探索任务。
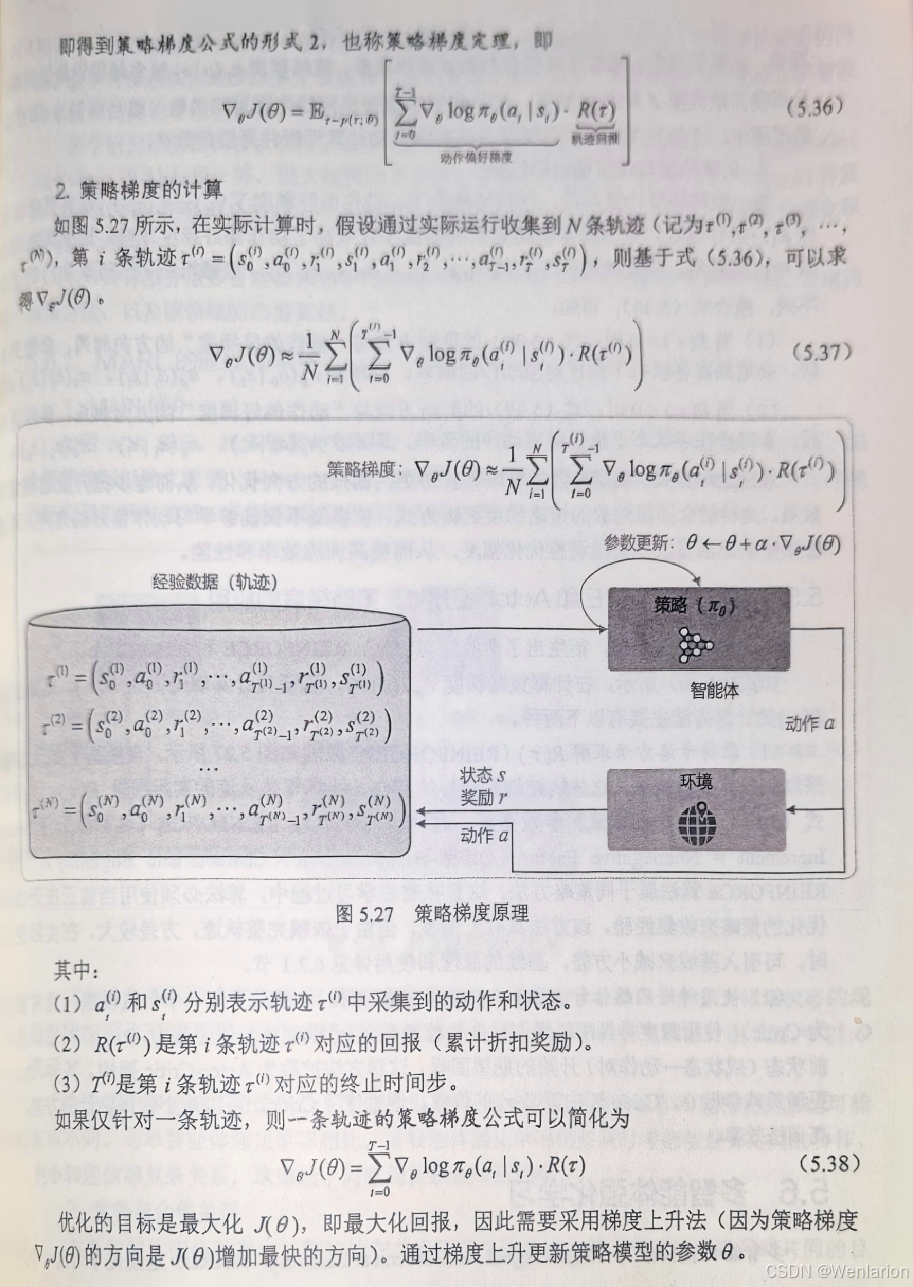
-
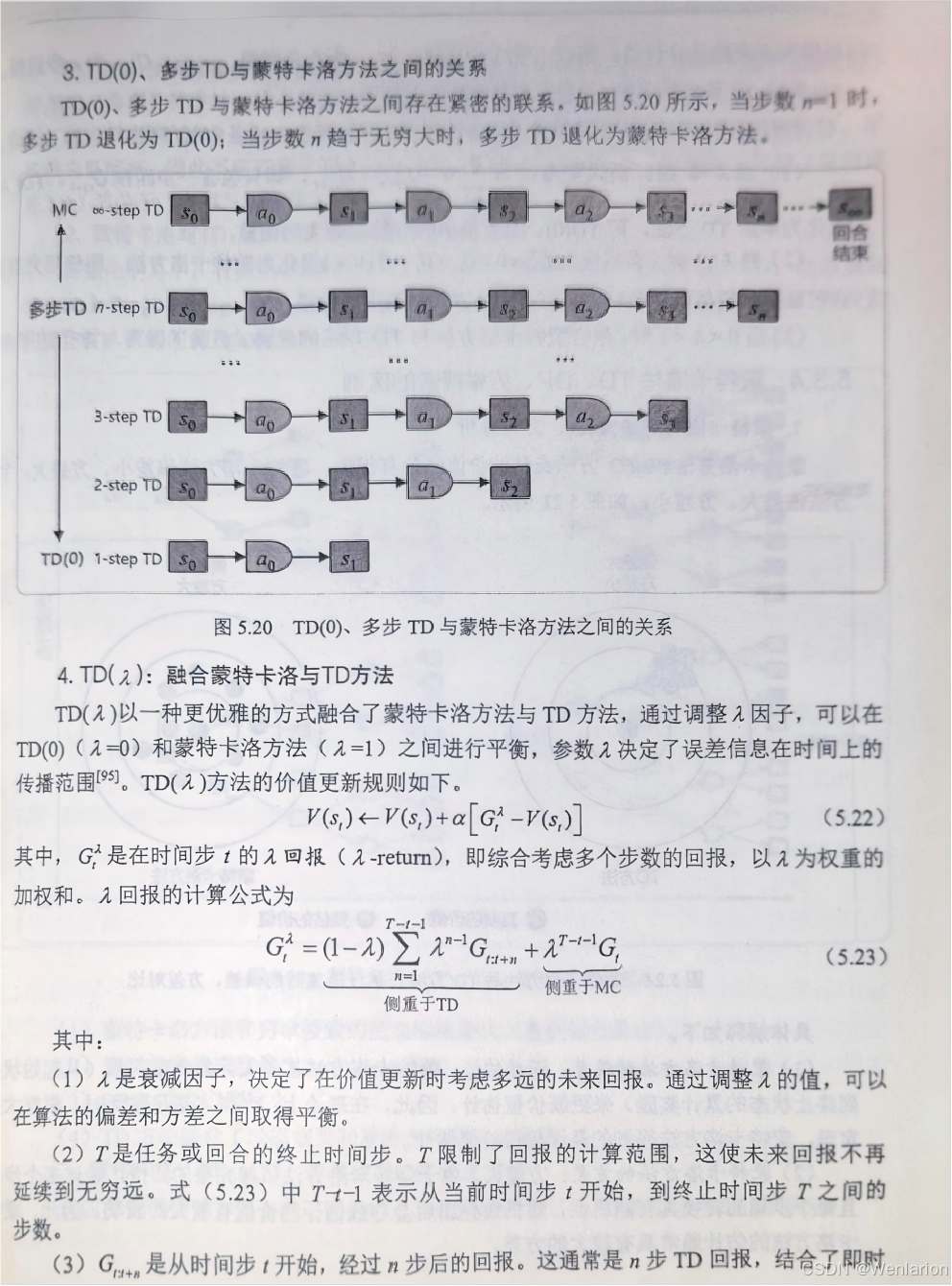
DQN with Dueling+Double+PER+NoisyNet:DQN 基础改进融合版,性能大幅提升。
-
Rainbow:DQN终极改进版本,集成 Double/Dueling/PER/NoisyNet/ 多步 TD / 分布型 RL,是传统离散动作价值基算法的性能天花板。
-
C51(Categorical DQN):分布型价值基算法,学习Q 值的概率分布而非标量,鲁棒性远高于传统 DQN,是分布型 RL 的基础。
-
QR-DQN(Quantile Regression DQN):基于分位数回归的分布型 DQN,比 C51 更灵活,适配非高斯 Q 值分布。
1.3、无模型策略基算法(直接优化策略)
适配离散 / 连续动作空间,策略平滑,核心直接优化策略函数 π_θ(a|s),但原生训练方差高,多与 AC 结合落地。
19. REINFORCE:经典蒙特卡洛策略梯度算法,基于完整轨迹计算梯度,方差高、收敛慢,是策略基算法的鼻祖。
20. REINFORCE with Baseline:REINFORCE 的改进,引入基线函数(如 V (s)) 消除梯度均值偏移,大幅降低方差。
21. Stochastic Policy Gradient(SPG,随机策略梯度):TD 版策略梯度,在线更新、无需完整轨迹,比 REINFORCE 收敛快。
22. Deterministic Policy Gradient(DPG,确定性策略梯度):适用于连续动作空间,输出确定动作而非概率,样本效率远高于 SPG,是 DDPG 的基础。
23. TRPO(Trust Region Policy Optimization):通过信任域约束限制策略更新幅度,保证优化单调性,解决策略梯度 “更新过大导致发散” 问题,计算复杂度高。
24. PPO(Proximal Policy Optimization):目前工业界最主流 RL 算法,TRPO 的简化版,通过裁剪目标函数替代信任域,兼顾稳定性、效率、通用性,适配所有动作空间。
25. PPO-Clip:PPO 主流版本,通过裁剪优势函数实现策略约束,实现简单、训练稳定。
26. PPO-Penalty:PPO 的另一种实现,通过 KL 散度惩罚约束策略更新,适用于对策略平滑性要求高的场景。
1.4、Actor-Critic(AC)算法(融合价值 + 策略)
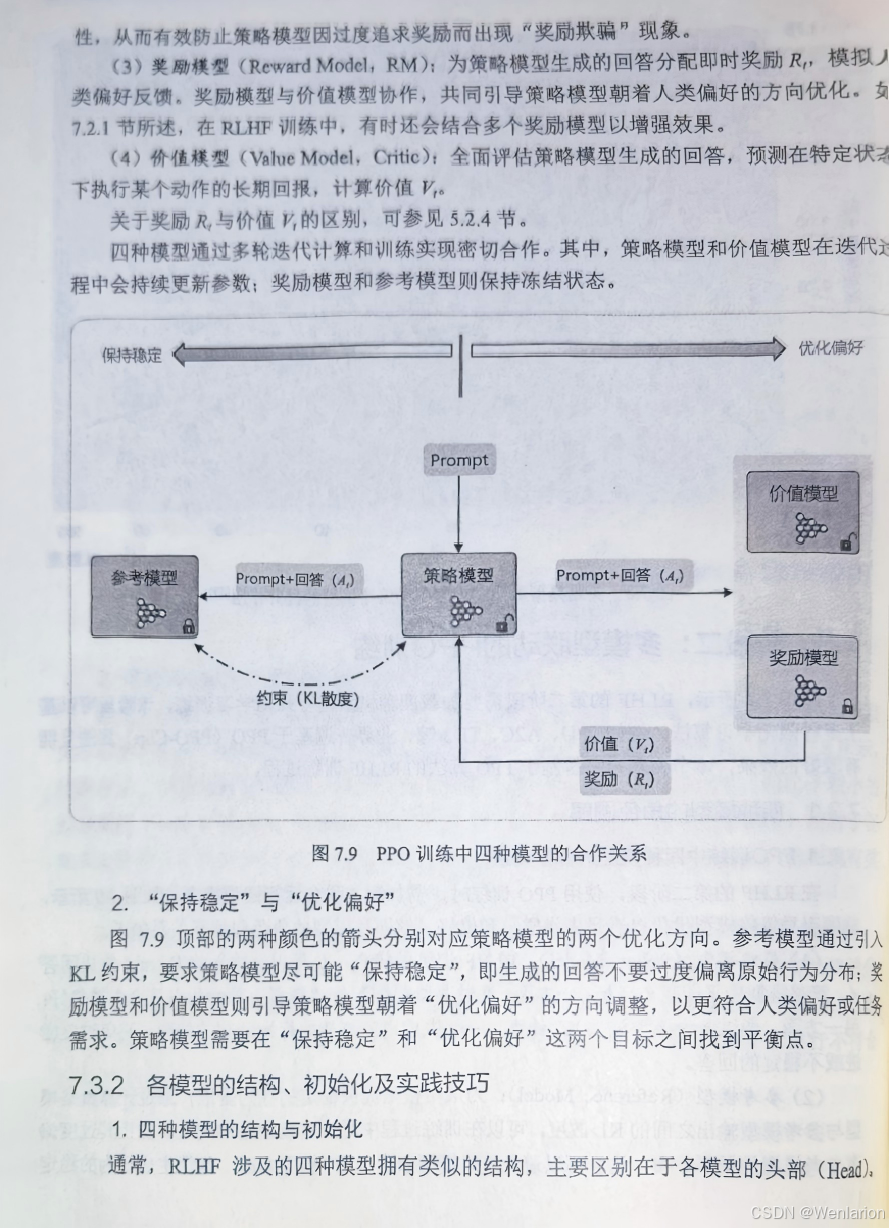
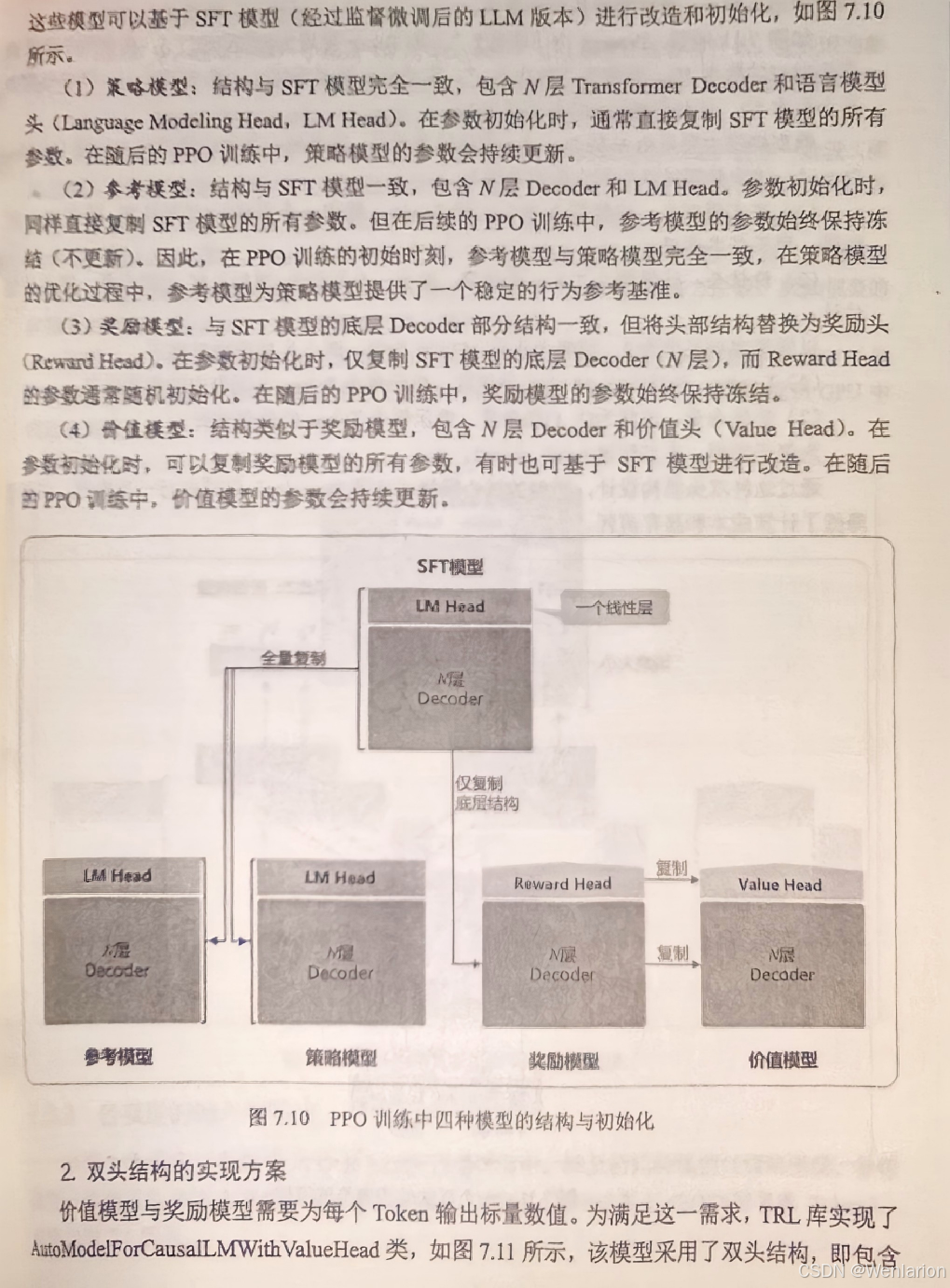
RL工程落地核心框架,适配所有动作空间,由 Actor(策略)+Critic(价值)组成,兼顾策略基的适配性和价值基的低方差,是目前绝大多数实际任务的首选。
经典基础 AC
-
AC(Actor-Critic):基础框架,Actor 输出动作,Critic 评估 V (s),用 V (s) 作为基线降低策略梯度方差,是所有 AC 算法的鼻祖。
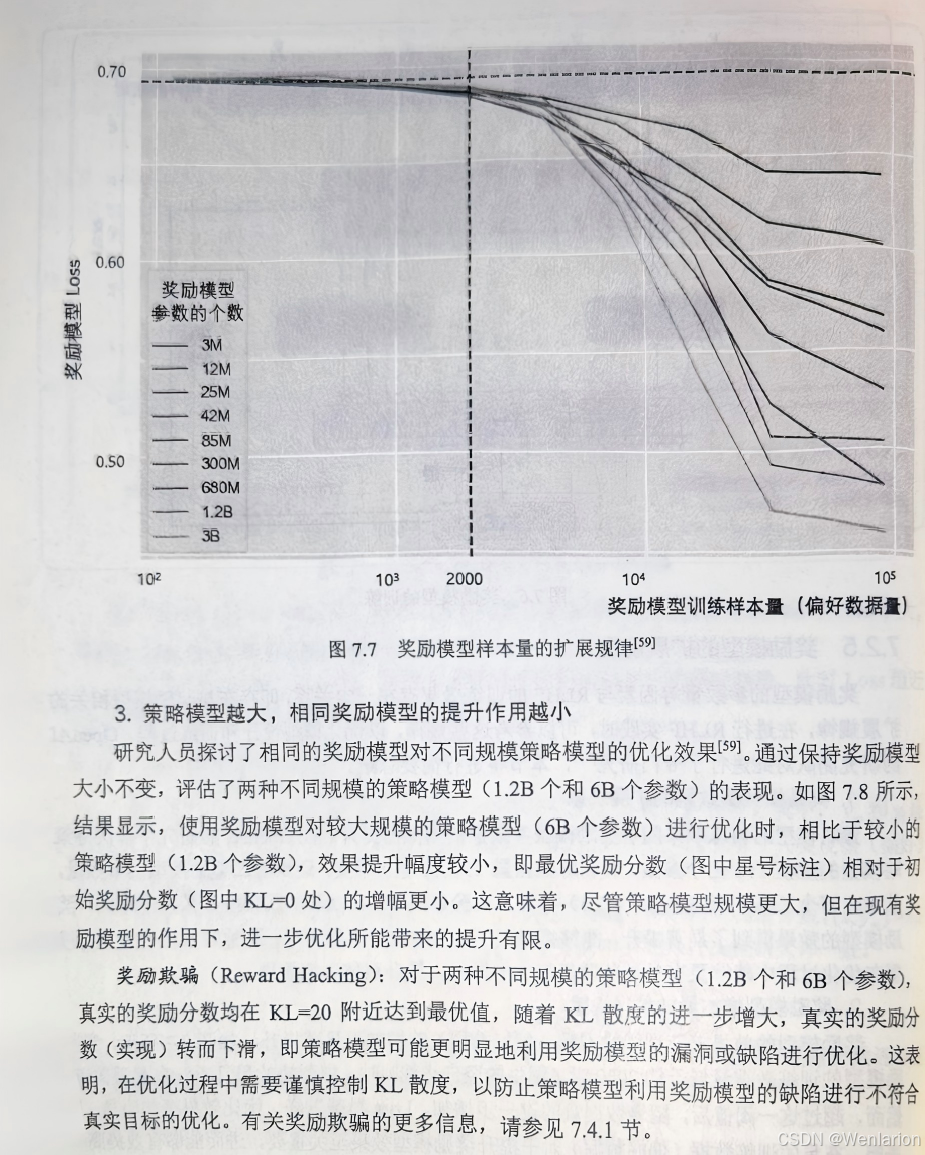
-
Advantage AC(优势 Actor-Critic):用优势函数 A (s,a)=Q (s,a)-V (s) 替代 V (s) 评估,进一步降低方差,提升训练效率。
经典进阶 AC
-
A2C(Synchronous Advantage Actor-Critic):同步多线程 AC,批量计算梯度,训练稳定、实现简单,是入门 AC 的首选。
-
A3C(Asynchronous Advantage Actor-Critic):异步多线程 AC,多线程独立探索 + 参数异步更新,训练效率远高于 A2C,是分布式 RL 的基础。
-
GAE(Generalized Advantage Estimation):非独立算法,AC 核心组件,融合多步优势估计,精准平衡偏差和方差,所有现代 AC 算法均基于 GAE。
连续动作专属 AC(工程主流)
-
DDPG(Deep Deterministic Policy Gradient):结合 DPG 和 DQN,引入经验回放 + 目标网络,是首个落地的深度连续动作 AC 算法,适用于机器人控制、自动驾驶。
-
TD3(Twin Delayed DDPG):DDPG 的终极改进版,引入双 Critic + 策略延迟更新 + 动作噪声正则,解决 DDPG 的过估计、训练震荡问题,连续动作经典算法。
-
SAC(Soft Actor-Critic):最大熵 AC 核心算法,兼顾 “奖励最大化” 和 “策略熵最大化”,自适应探索,鲁棒性、样本效率远高于 DDPG/TD3,连续控制落地首选。
-
SAC-v1/SAC-v2:SAC 的两个版本,v2 引入自动温度系数调整,无需手动调参,实用性更强。
-
PPO-AC:广义 PPO 归为 AC 框架,Critic 学习 V (s),Actor 基于 GAE 优化,是目前离散 / 连续动作通用的最优 AC 算法。
分布型 AC(前沿改进)
-
QR-DQN AC:结合分位数回归的分布型 AC,学习 Q 值分布,鲁棒性更高。
-
CAC(Categorical Actor-Critic):分布型 AC 的经典版本,基于 C51 的思想,适用于噪声较大的场景。
其他改进 AC
-
D4PG(Distributed Distributional Deep Deterministic Policy Gradient):融合 DDPG + 分布型 RL + 分布式训练,样本效率和性能大幅提升,适用于大规模连续动作任务。
-
PPO-FP(PPO with Fixed Point):PPO 的改进,基于不动点理论优化策略更新,收敛速度更快。
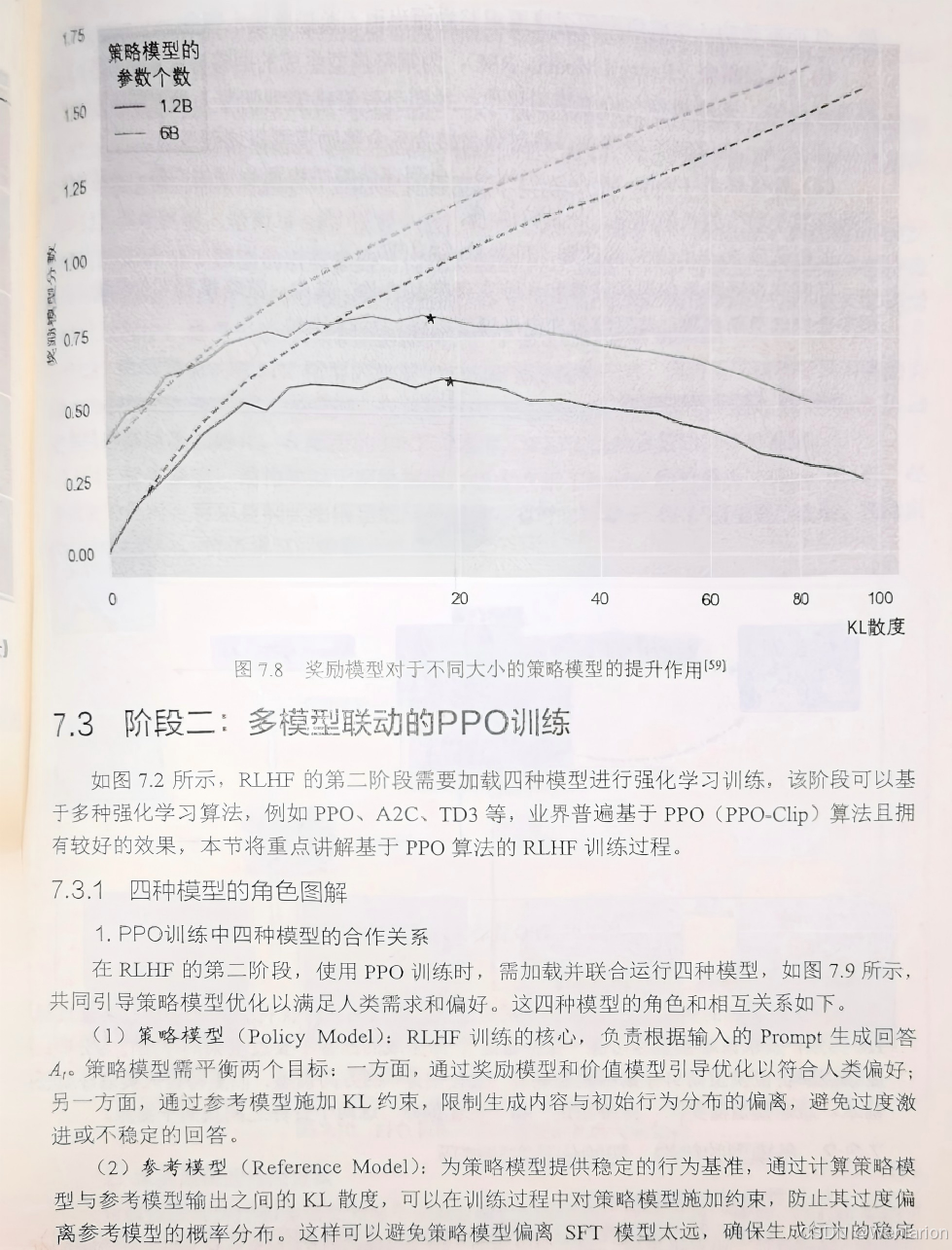
1.5、有模型(Model-Based)RL 算法(样本效率核心)
先学习环境模型 P (s'|s,a)+ 奖励模型 R (s,a),再基于模型规划,样本效率比无模型 RL 高 1-2 个数量级,适用于环境交互成本高的场景(如机器人实机、物理仿真)。
41. Dyna-Q:经典有模型 RL,融合 “无模型 Q-Learning + 模型模拟规划”,是有模型 RL 的入门算法。
42. Dyna-2:Dyna-Q 的改进,分离 “模型学习” 和 “策略学习”,提升规划效率。
43. MBPO(Model-Based Policy Optimization):目前主流有模型 RL 算法,用无模型 RL(SAC)优化模型生成的虚拟数据,兼顾样本效率和泛化性,连续控制首选。
44. PETS(Probabilistic Ensemble Trajectory Sampling):基于概率集成模型的有模型 RL,处理模型不确定性,鲁棒性高于 MBPO。
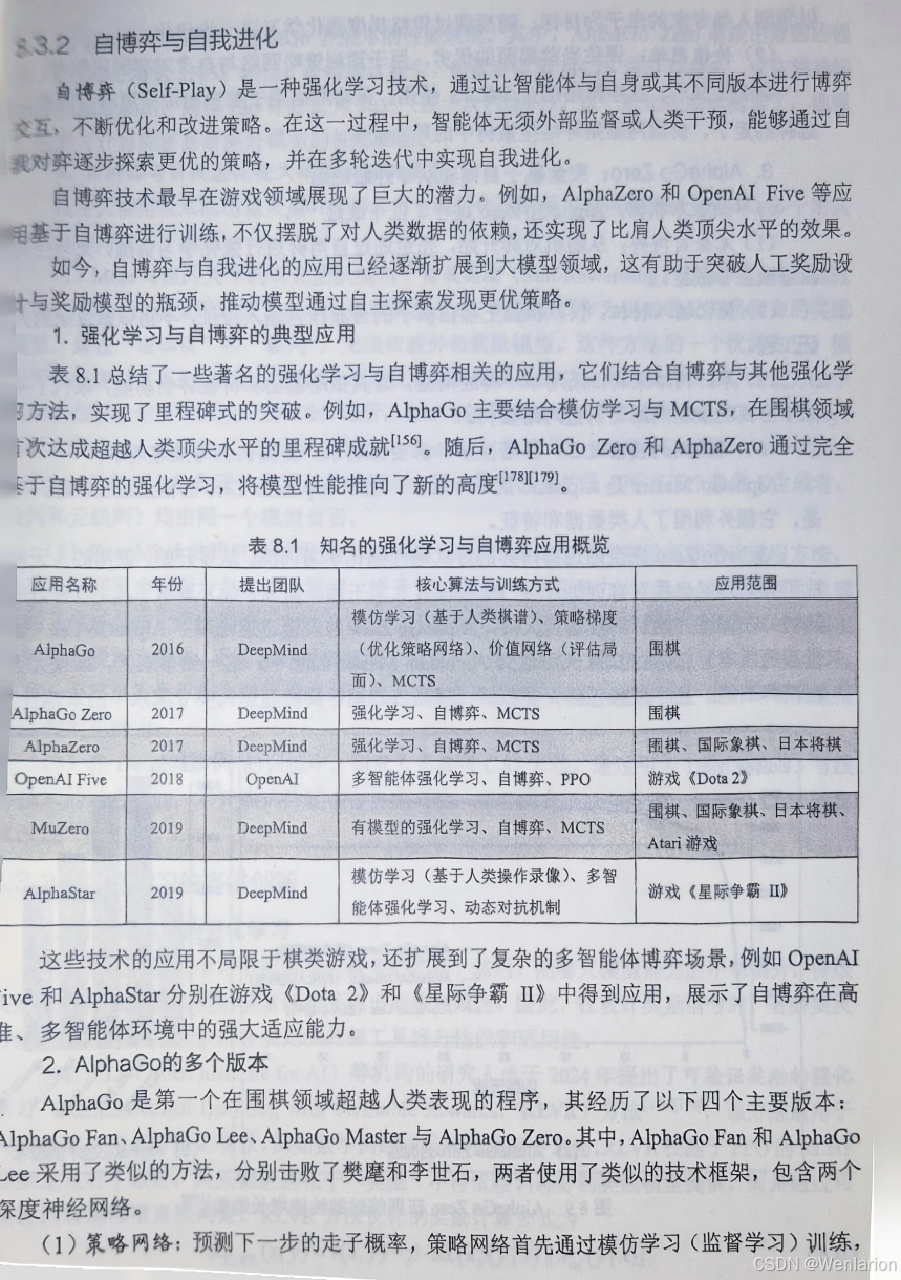
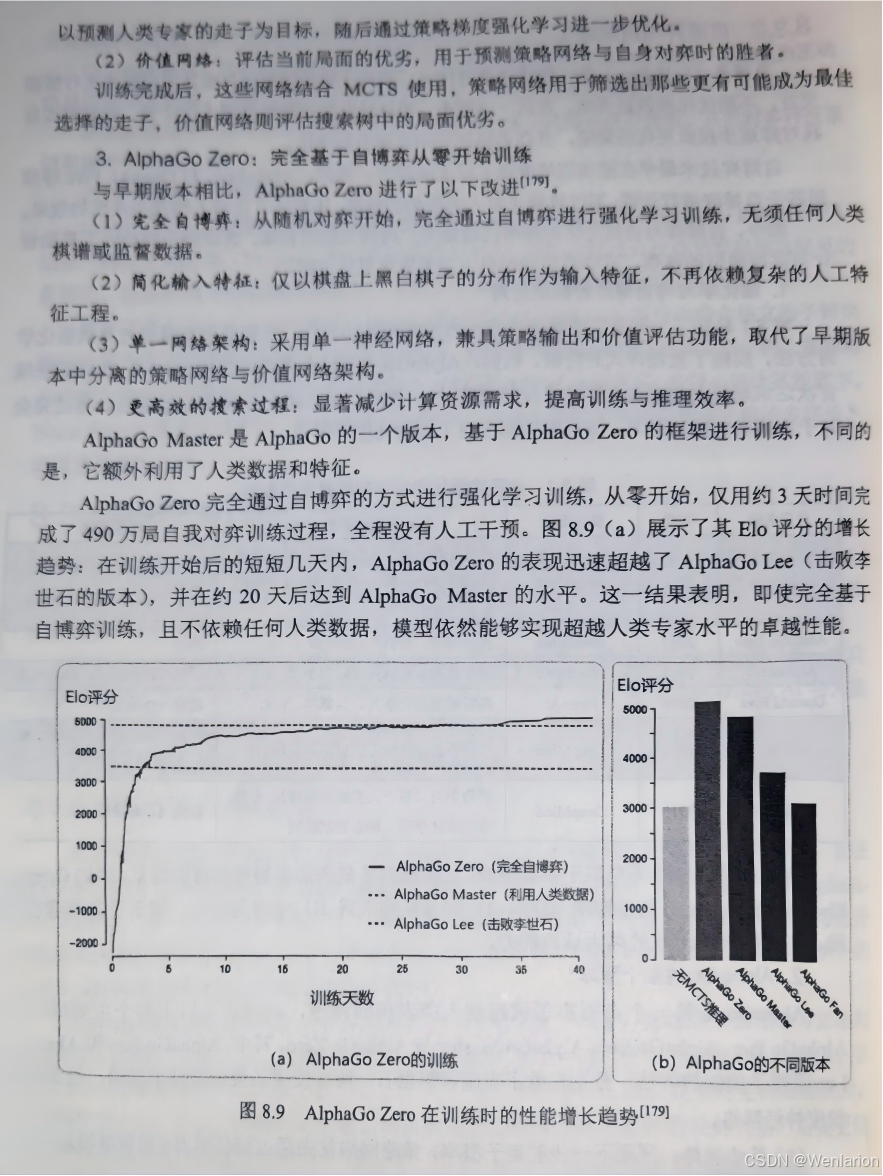
45. MuZero:DeepMind 经典算法,无模型 + 有模型融合巅峰,无需显式环境模型,通过动态规划 + 蒙特卡洛树搜索(MCTS) 自学习模型,适用于棋类、游戏、机器人。
46. AlphaGo/AlphaGo Zero:基于 MCTS + 有模型 RL,AlphaGo 融合人类棋谱,AlphaGo Zero 纯自博弈,是棋类 AI 的里程碑。
47. AlphaZero:AlphaGo Zero 的通用版本,适配所有完美信息博弈(围棋、国际象棋、将棋),无领域知识,纯自博弈学习。
48. World Models:基于变分自编码器(VAE)+LSTM学习环境模型,用简单策略在虚拟模型中训练,样本效率极高。
49. PILCO(Probabilistic Inference for Learning Control):基于高斯过程的有模型 RL,适用于高精度、小样本的机器人控制任务。
1.6 离线 / 批量强化学习(工业落地核心)
无需与环境实时在线交互,直接利用离线数据集(人类演示 / 历史交互)训练,无试错成本,是从 “实验室” 到 “工业界” 的关键算法,核心解决分布偏移问题。
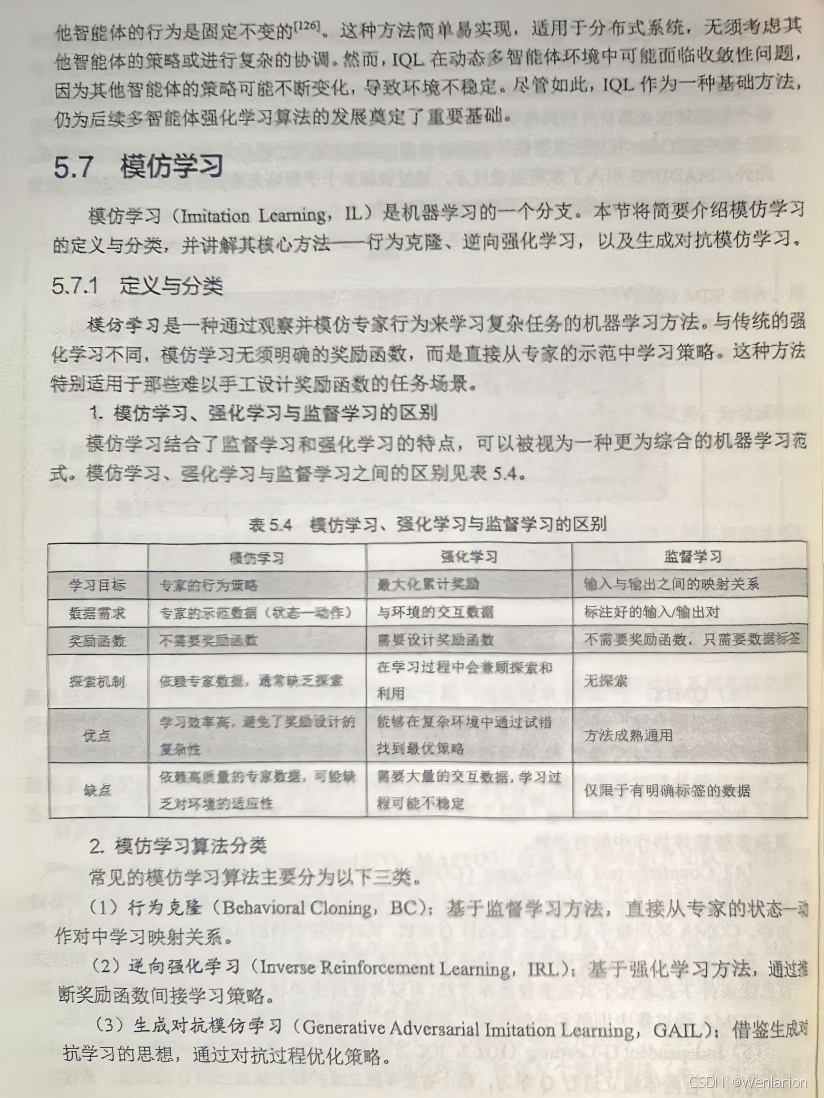
模仿学习(离线 RL 的重要分支,无奖励函数)
-
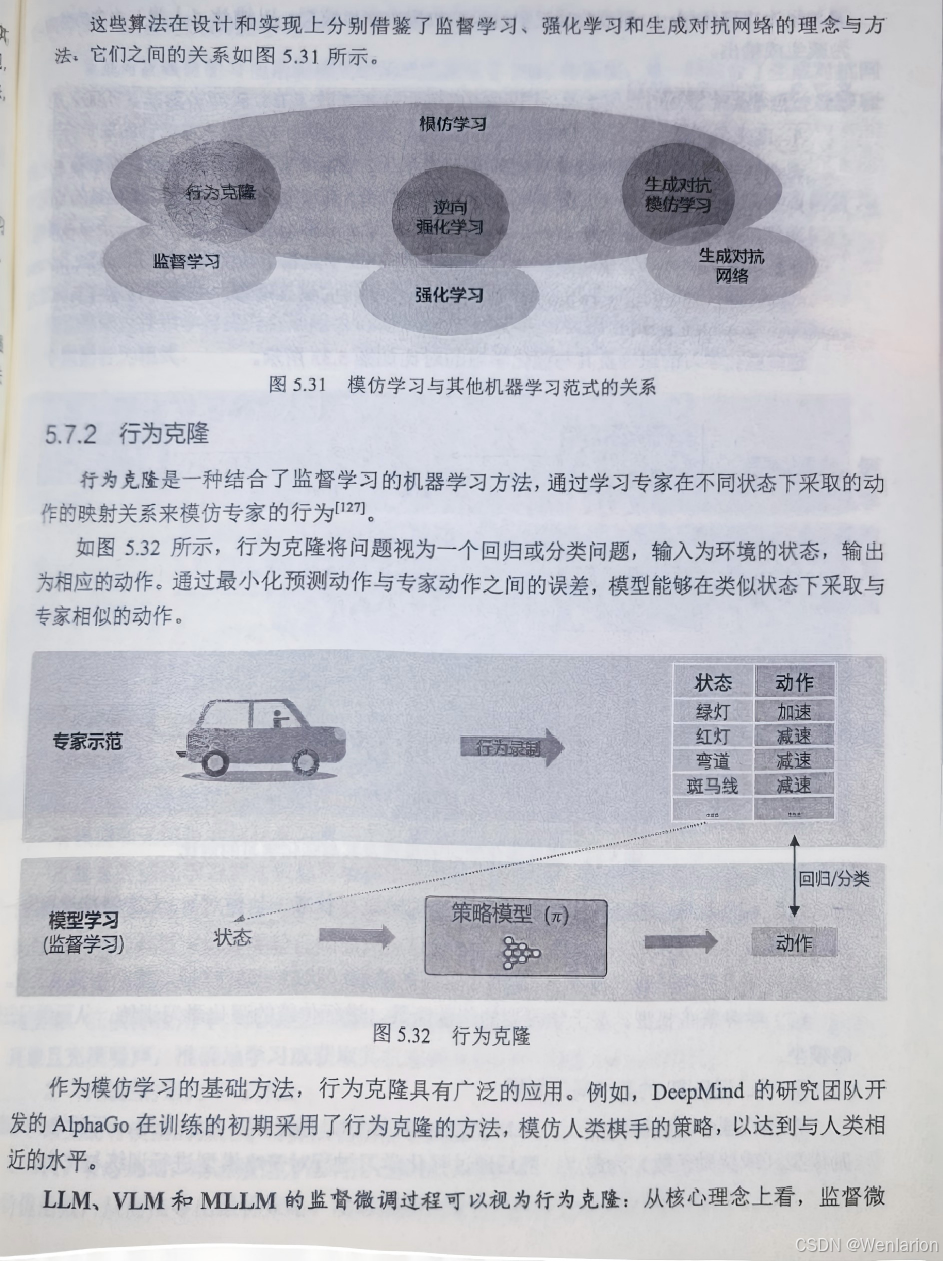
BC(Behavior Cloning,行为克隆):经典模仿学习,监督学习拟合人类演示的 s→a 映射,实现简单、无探索,适用于有大量人类演示的场景。
-
DAGGER(Dataset Aggregation):BC 的改进,迭代收集 “专家 + 智能体” 数据,解决 BC 的分布偏移,提升策略泛化性。
-
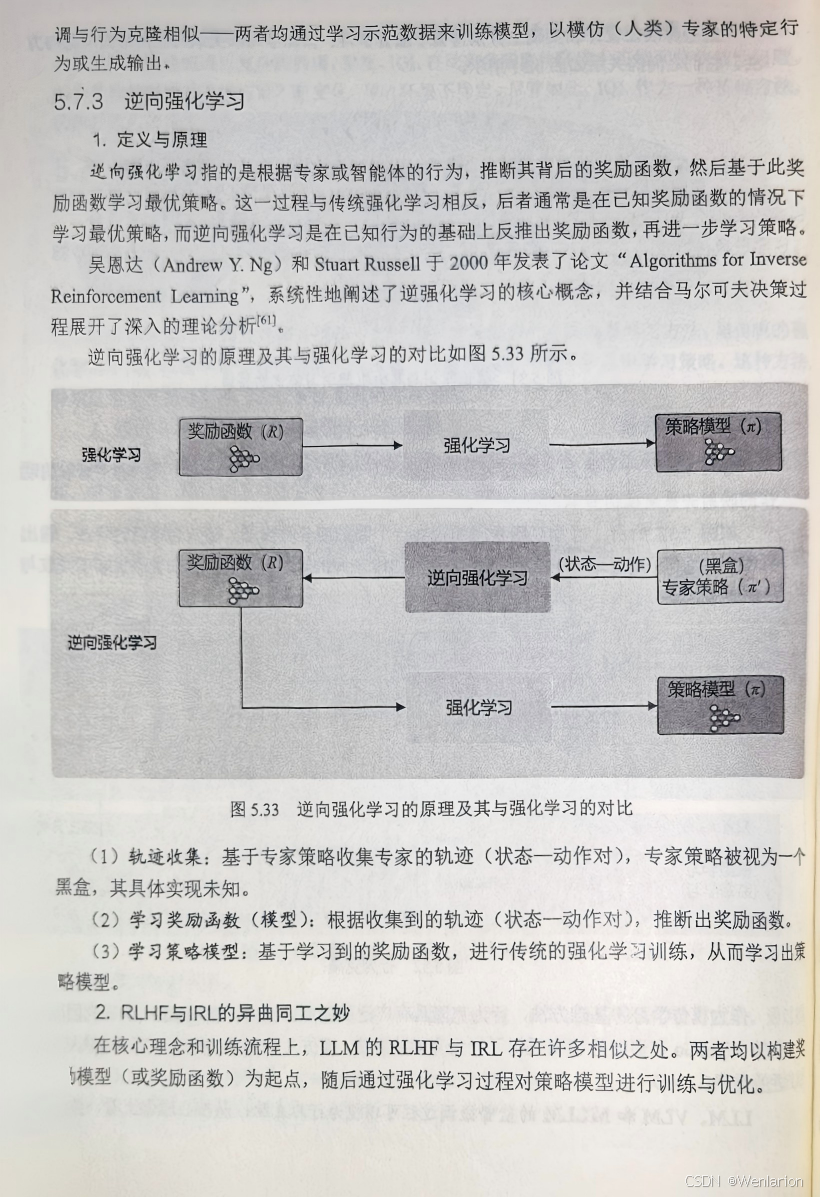
GAIL(Generative Adversarial Imitation Learning,生成式对抗模仿学习):对抗式模仿学习,无需奖励函数,通过 GAN 让智能体策略逼近专家策略,性能优于 BC。
-
FAIRL(Feasible Action Invariant RL):GAIL 的改进,解决 GAIL 的模式崩溃问题,探索更充分。
-
AIRL(Adversarial Inverse RL):融合逆强化学习(IRL)和 GAIL,先学习专家的奖励函数,再用 RL 优化,适用于专家演示少的场景。
纯离线 RL(基于离线数据优化,有奖励函数)
-
IQL(Implicit Q-Learning):目前主流离线价值基算法,基于 Q-Learning 的改进,通过隐式约束解决分布偏移,样本效率高,适配离散 / 连续动作。
-
CQL(Conservative Q-Learning):保守 Q 学习,通过过估计 Q 值实现保守策略优化,避免选择离线数据中未出现的动作,是离线 RL 的经典算法。
-
TD3+BC:离线连续动作主流算法,将 TD3 与 BC 结合,用 BC 约束策略,解决分布偏移,实现简单、性能稳定。
-
SAC+BC:TD3+BC 的改进,基于 SAC 的最大熵特性,探索性更强,鲁棒性更高。
-
AWAC(Advantage Weighted Actor-Critic):离线 AC 算法,用优势函数加权专家动作,提升策略向专家靠拢的速度。
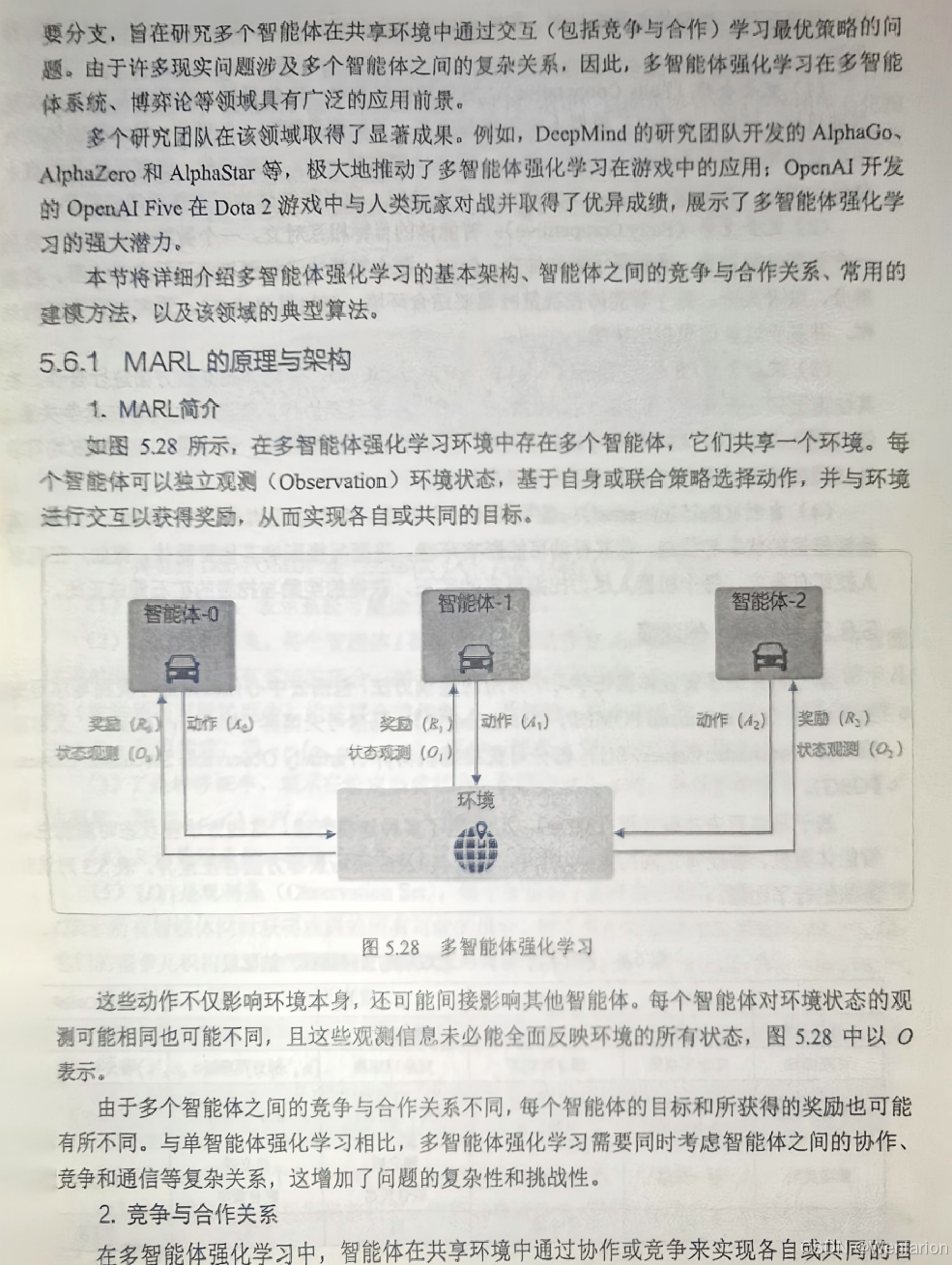
1.7、多智能体强化学习(MARL,多主体决策)
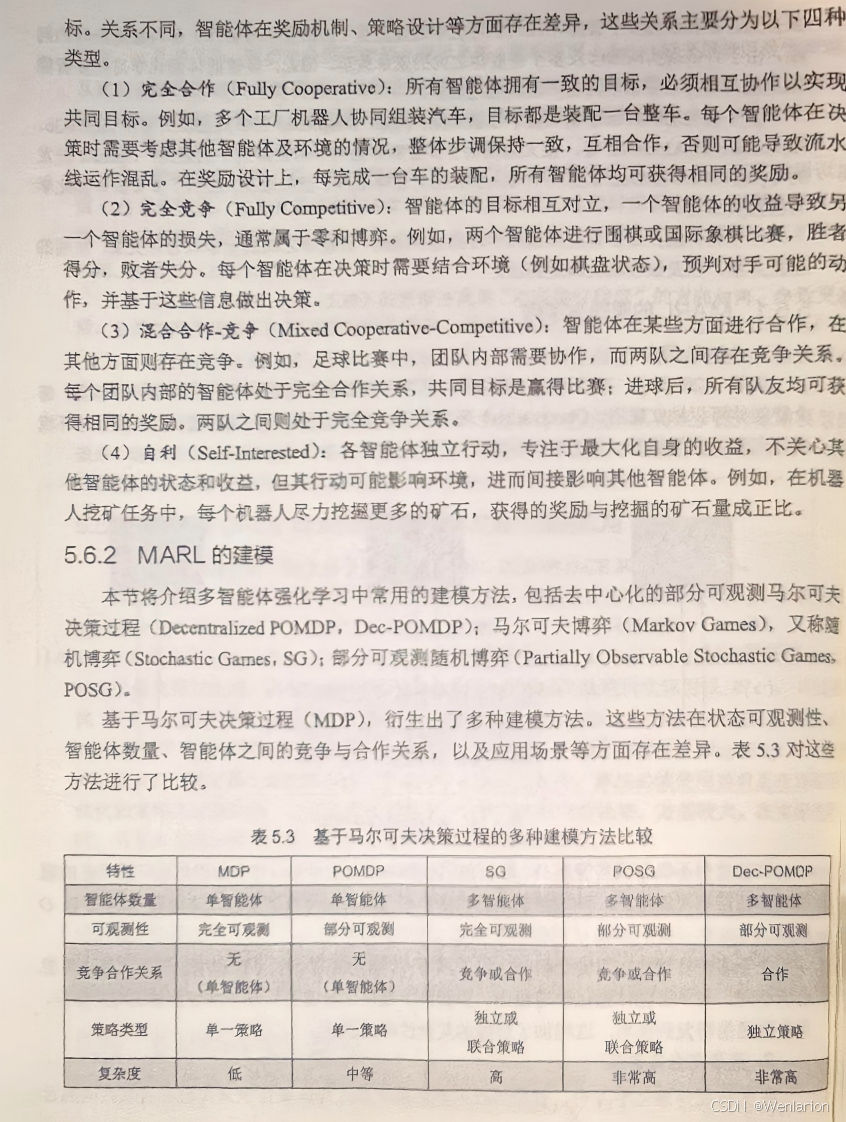
适配多个智能体交互的场景,核心解决环境非平稳性和信用分配问题,分为合作 / 竞争 / 混合三大类,主流框架为CTDE(中心化训练 / 去中心化执行)。
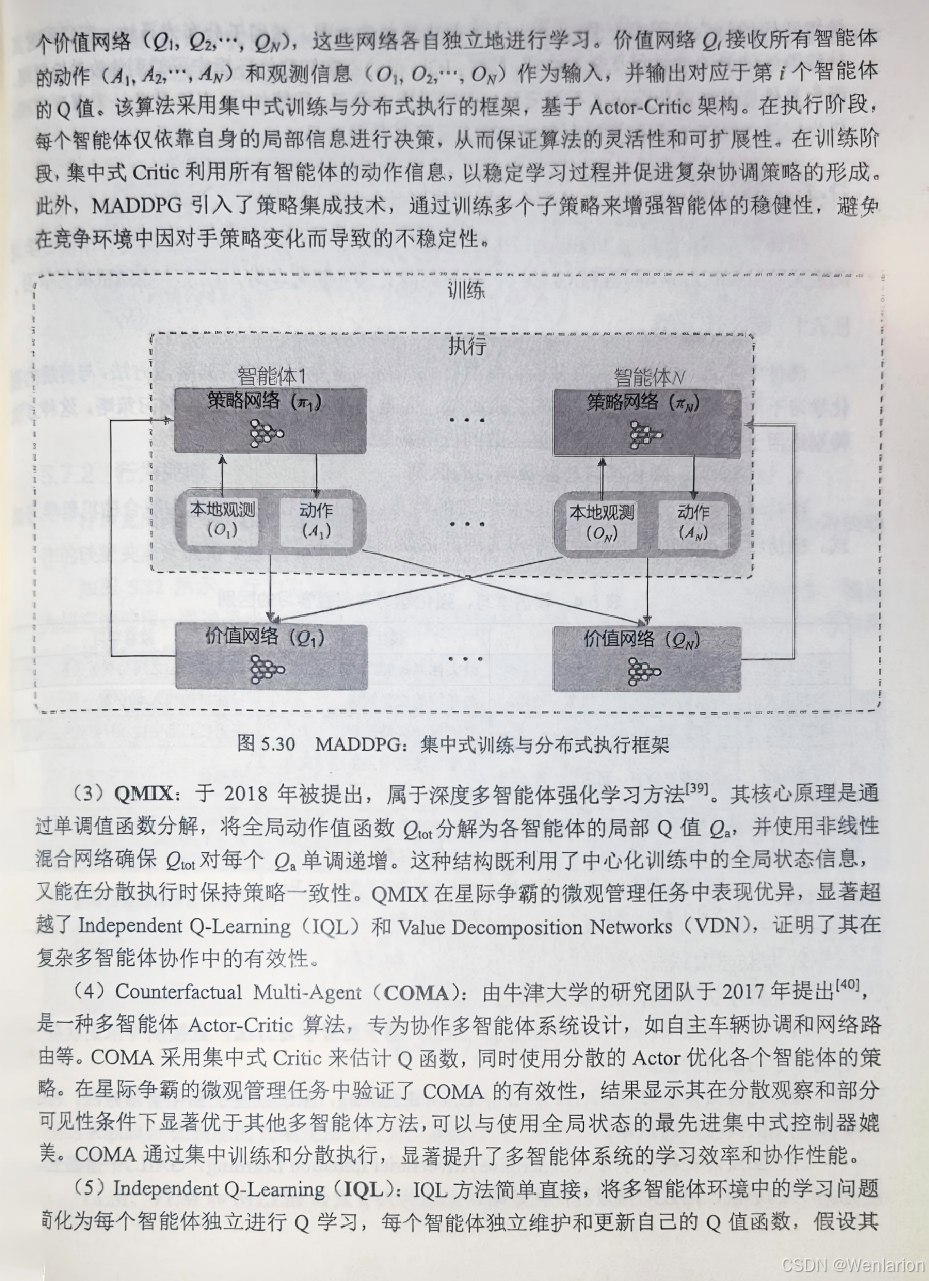
60. MADDPG(Multi-Agent DDPG):经典多智能体 AC 算法,CTDE 框架,中心化 Critic 评估全局状态,去中心化 Actor 输出动作,适用于合作 / 混合场景。
61. MAPPO(Multi-Agent PPO):目前最主流 MARL 算法,PPO 的多智能体版本,CTDE 框架,兼顾性能、效率、通用性,适配所有 MARL 场景。
62. QMIX(Q-Mixing Network):合作型 MARL 价值基算法,通过混合网络将个体 Q 值融合为全局 Q 值,完美解决合作场景的信用分配问题。
63. QTRAN(Q-Transformation):QMIX 的改进,突破 QMIX 的单调性约束,适配更复杂的合作任务。
64. COMA(Counterfactual Multi-Agent Policy Gradient):合作型 MARL 策略基算法,通过反事实推理解决信用分配问题,适用于离散动作合作场景。
65. MAAC(Multi-Agent Actor-Critic):通用多智能体 AC 算法,支持多智能体间的通信,适用于需要协作通信的场景(如多机器人编队)。
66. VDN(Value-Decomposition Network):QMIX 的基础,将全局 Q 值分解为个体 Q 值的和,实现简单,适用于简单合作任务。67. Self-Play(自博弈):竞争型 MARL 核心范式,智能体与自身的不同版本对弈,实现策略自提升,是 AlphaGo/AlphaZero 的核心。68. League Training(联赛训练):自博弈的改进,多个不同策略的智能体组成联赛对弈,避免策略收敛到局部最优,适用于复杂竞争场景(如星际争霸)。
1.8、强化学习前沿拓展算法
覆盖分层、分布式、最大熵、鲁棒、多任务等前沿方向,解决传统 RL 的长程任务、大规模训练、鲁棒性差等问题。
分层强化学习(HRL,长程任务核心)
-
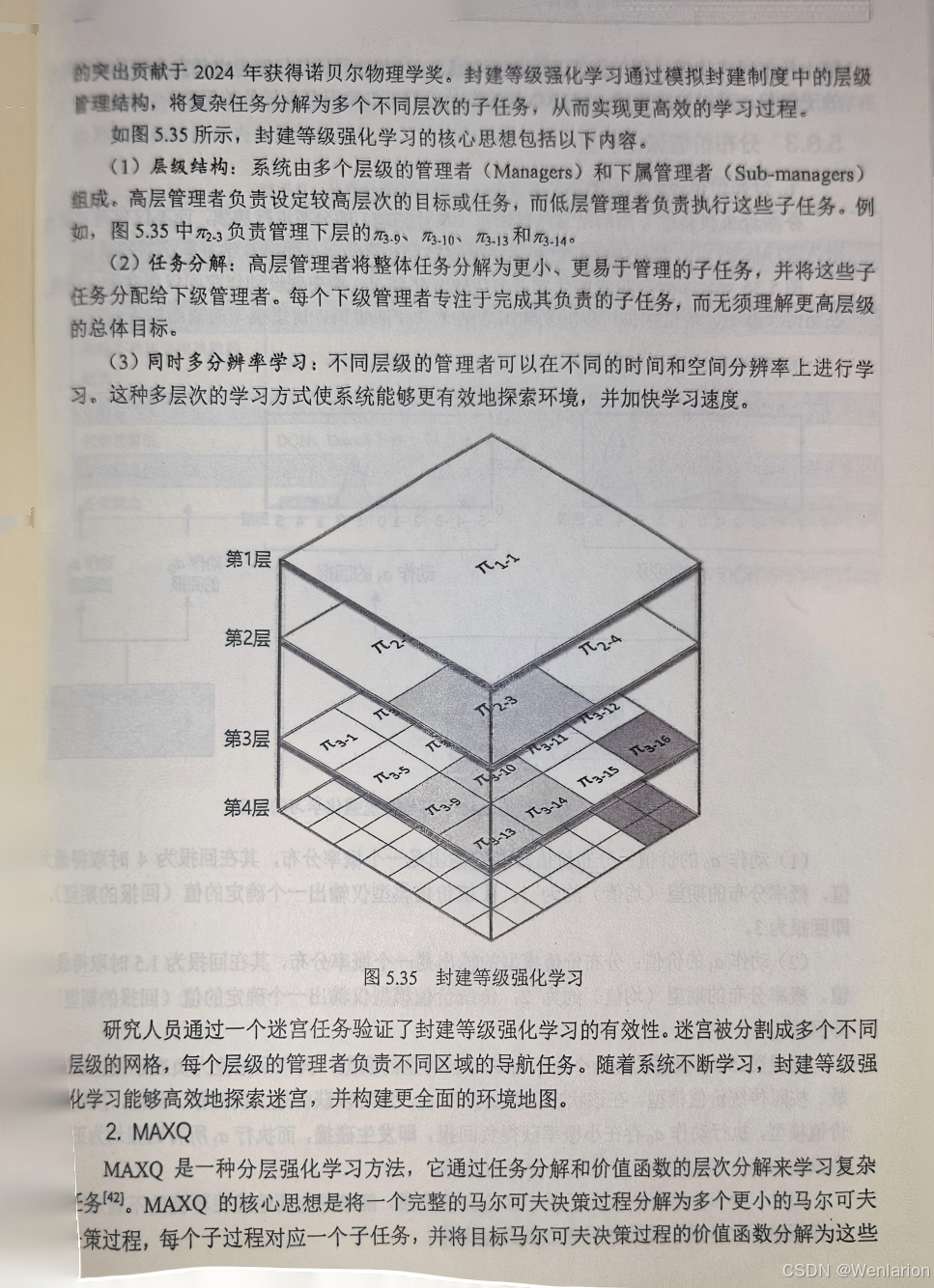
MAXQ:经典分层 RL 算法,将任务拆分为子任务层级,每个子任务学习独立的策略,解决长程任务的信用分配问题。
-
Feudal RL(FRL,封建 RL):将智能体分为高层管理者(选子任务)和低层执行者(执行动作),适用于复杂长程任务(如机器人自主导航)。
-
HAC(Hierarchical Actor-Critic):分层 AC 算法,每层均为独立的 AC,高层输出子目标,低层输出动作,工程落地主流。
最大熵强化学习(探索 + 鲁棒核心)
-
Soft Q-Learning(SQL):最大熵价值基算法,是 SAC 的基础,兼顾奖励和熵,探索性强。
-
MPO(Maximum a Posteriori Policy Optimization):最大熵策略基算法,适用于对鲁棒性要求高的场景。
分布式 / 鲁棒 / 多任务 RL
-
IMPALA(Importance Weighted Actor-Learner Architecture):分布式 RL 经典框架,Actor 异步探索 + Learner 同步训练,引入重要性加权解决样本分布问题,大规模训练首选。
-
R2D2(Recurrent Experience Replay in Distributed RL):IMPALA 的改进,引入循环网络 + 经验回放,适用于部分可观测、长序列任务。
-
Robust RL(鲁棒强化学习):针对环境噪声 / 模型偏差的改进,代表算法TRPO-Robust,适用于实际工业场景(环境存在不确定性)。
-
Multi-Task RL(多任务强化学习):同时学习多个相关任务,实现知识迁移,代表算法MTPPO,适用于需要泛化到不同任务的场景(如机器人多动作执行)。
-
Meta-RL(元强化学习):“学习如何学习”,快速适应新任务,代表算法MAML-RL,适用于少样本、快速适配的场景。
-
Curiosity-Driven RL(好奇心驱动 RL):基于内在奖励(好奇心)实现自主探索,解决稀疏奖励问题,代表算法ICM(Intrinsic Curiosity Module)。
1.9、LLM 对齐特化强化学习算法(大模型落地核心)
针对大语言模型(LLM) 的超大动作空间(token 级)、文本状态、偏好奖励做特化适配,是目前 AI 领域的研究热点,核心目标是实现 LLM 的人类对齐。
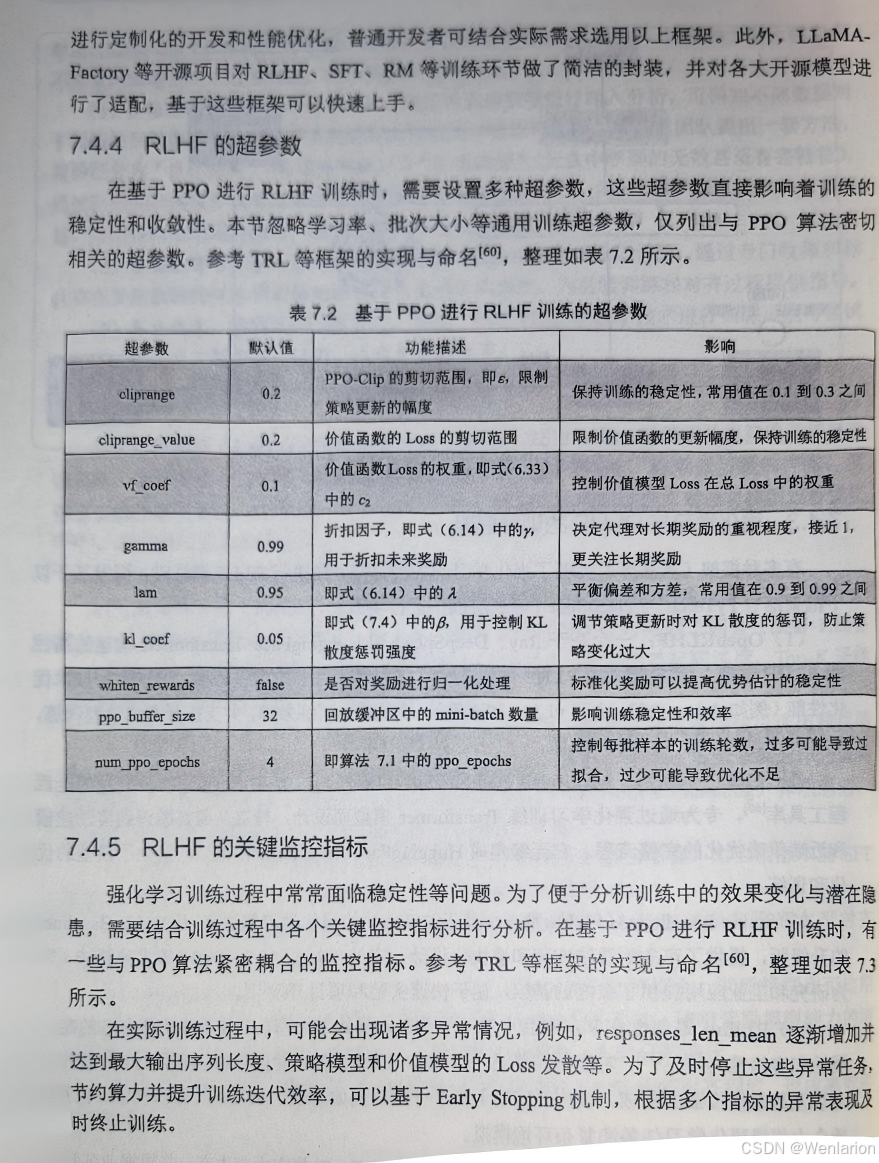
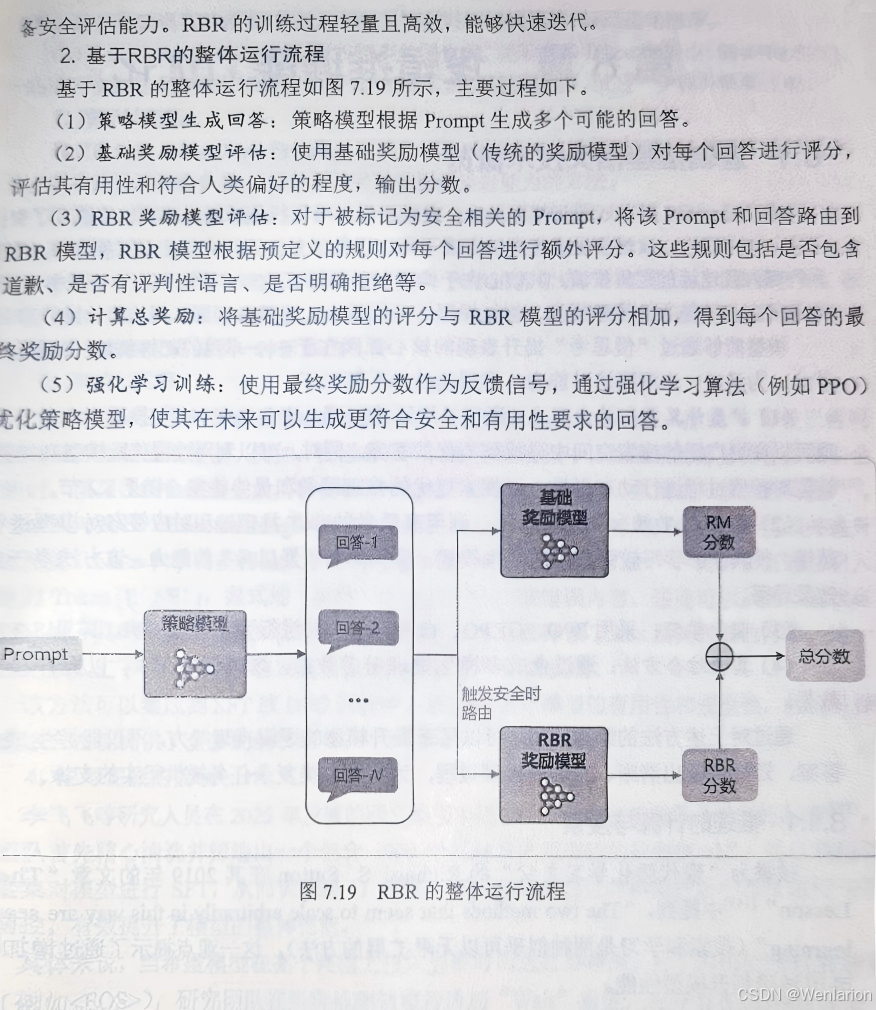
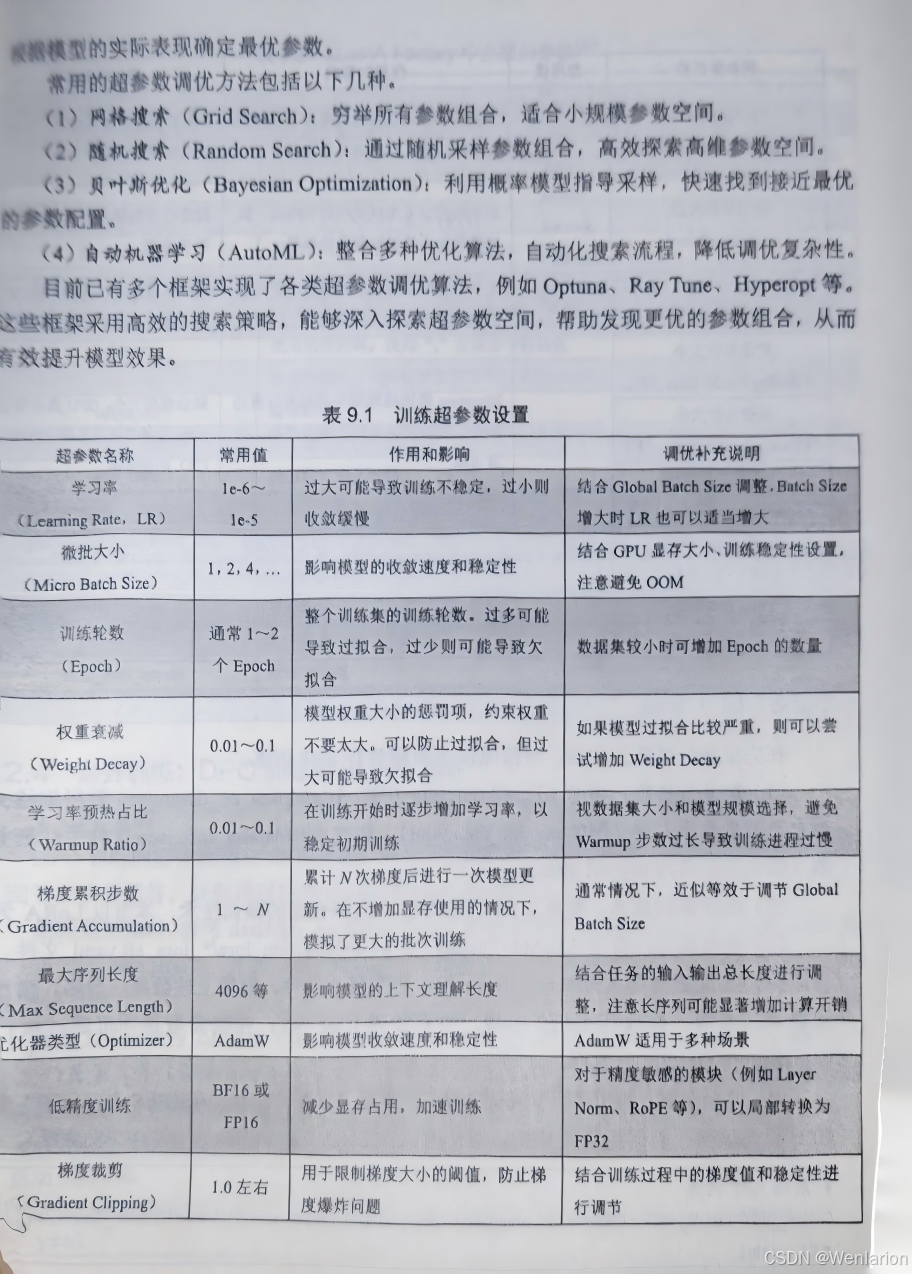
80. RLHF(Reinforcement Learning from Human Feedback,从人类反馈中学习的 RL):LLM 对齐经典范式,SFT(有监督微调)+RM(奖励模型)+PPO三阶段,是 InstructGPT/GPT-4/LLaMA2 的核心对齐算法。
81. DPO(Direct Preference Optimization,直接偏好优化):目前LLM 对齐主流算法,无需训练 RM 和 PPO,直接通过偏好数据(优 / 劣回答对)优化 LLM,简化流程、训练稳定、效率高。82. GRPO(Generalized Reward Preference Optimization,广义奖励偏好优化):DPO/PPO 统一框架,支持多偏好、多奖励、混合反馈,适配复杂对齐需求。
83. IPO(Implicit Preference Optimization,隐式偏好优化):DPO 的改进,通过隐式约束实现更保守的优化,鲁棒性更高。
84. SDPO(Smooth Direct Preference Optimization,平滑 DPO):引入平滑项解决 DPO 的策略突变问题,提升生成文本的流畅性。
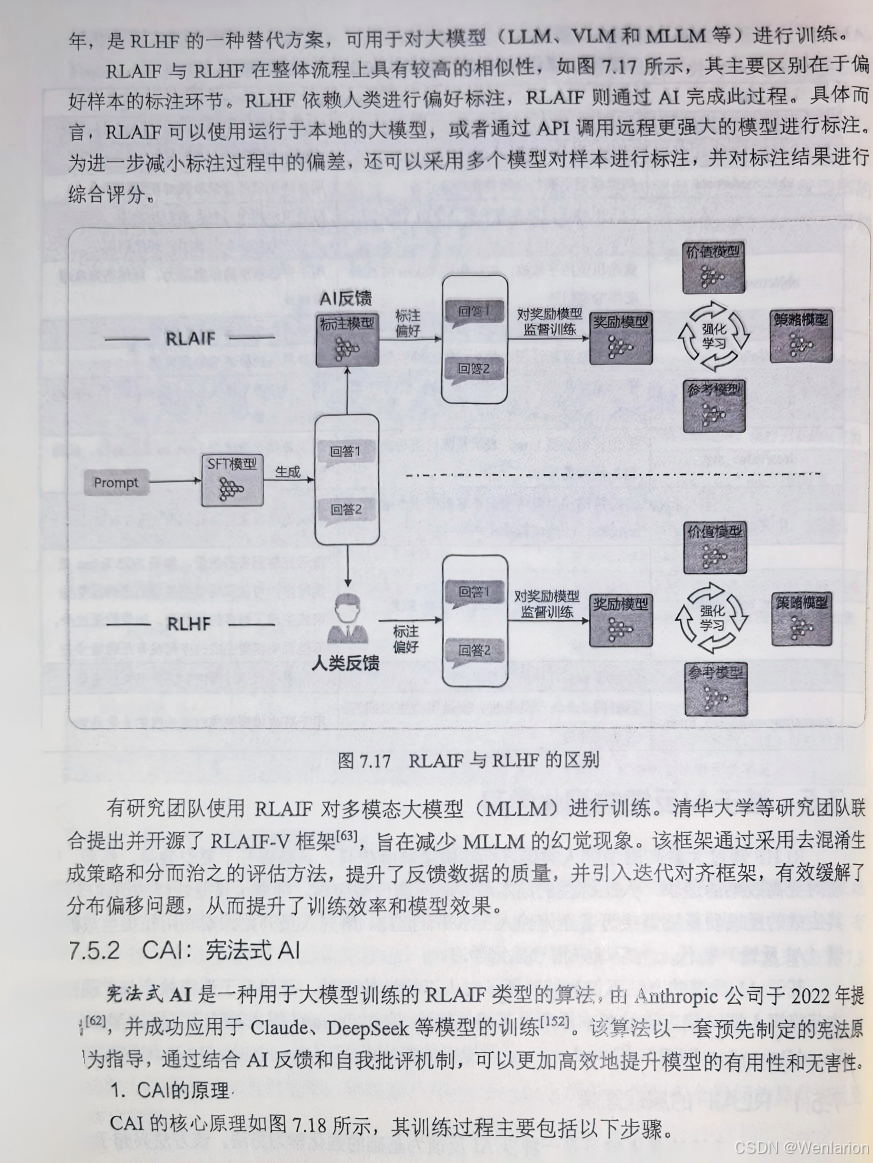
85. RLAIF(Reinforcement Learning from AI Feedback,从 AI 反馈中学习的 RL):RLHF 的轻量化变种,用大模型 AI 反馈替代人类反馈,大幅降低标注成本,实现规模化对齐。
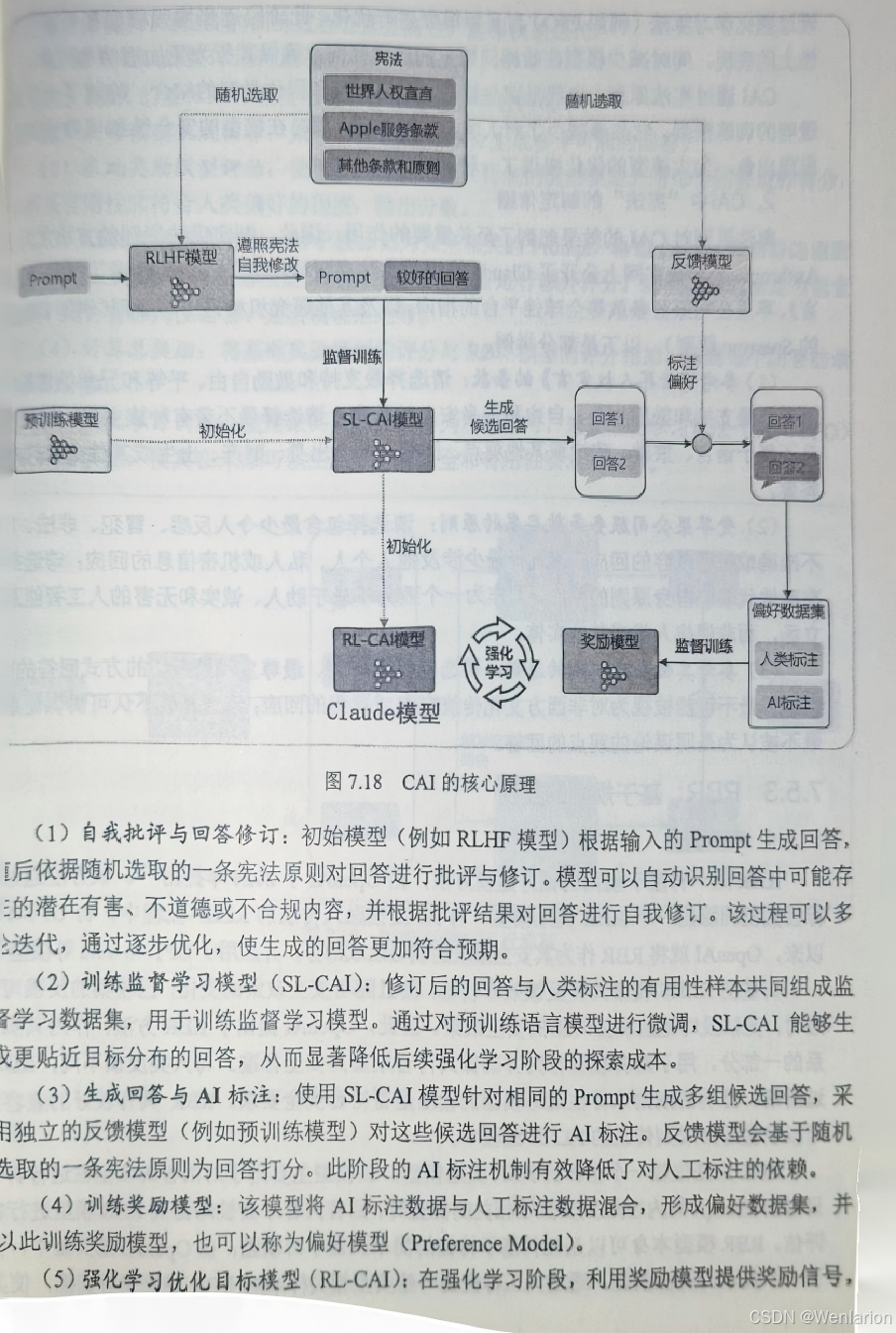
86. Constitution AI(宪法 AI):Anthropic 提出的 RLAIF 变种,基于规则 / 宪法让 AI 自我评估、修正,实现安全对齐。
87. Self-Rewarding RL(自奖励 RL):LLM 对齐前沿,无需外部(人类 / AI)反馈,LLM自身生成奖励信号实现自对齐,是未来终极方向。
2、RL学习路径和资源
2.1 RL 算法学习路径
1. 入门学习(必学)
Q-Learning → SARSA → DQN → REINFORCE → AC → A2C → PPO → TD3 → SAC → MAPPO
2. 工程落地(按场景选)
-
离散动作:PPO / Rainbow / DQN
-
连续动作:PPO / SAC / TD3
-
多智能体:MAPPO / MADDPG / QMIX
-
工业离线场景:BC / CQL / IQL / TD3+BC
-
环境交互成本高:MBPO / MuZero / Dyna-Q
-
LLM 对齐:DPO / GRPO / RLHF / RLAIF
3. 前沿研究(按需学)
分层 RL(HAC/MAXQ)→ 分布式 RL(IMPALA/R2D2)→ 元 RL(MAML-RL)→ 自奖励 RL → 鲁棒 RL
2.2 RL论文和代码
一、基础强化学习(RL)核心算法
|
论文名称 |
简介 |
论文地址 |
代码地址 |
|
|---|---|---|---|---|
|
Q-Learning |
经典的无模型时序差分(TD)算法,基于价值迭代,是 DQN 的基础,核心是学习动作价值函数 Q(s,a) |
|||
|
DQN (Deep Q-Network) |
将深度学习与 Q-Learning 结合,引入经验回放和目标网络解决稳定性问题,是深度强化学习的里程碑 |
|||
|
Policy Gradient & REINFORCE |
直接对策略函数 $\pi (a |
s)$ 求导优化,是策略梯度方法的基础,解决连续动作空间问题 |
http://people.cs.umass.edu/~barto/courses/cs687/williams92simple.pdf |
|
|
PPO (Proximal Policy Optimization) |
目前最主流的强化学习算法,通过裁剪目标函数限制策略更新幅度,兼顾稳定性和样本效率,是 LLM 对齐的核心算法 |
|||
|
TRPO (Trust Region Policy Optimization) |
PPO 的前身,通过信任域限制策略更新,保证优化稳定性,但计算复杂度更高 |
|||
|
SAC (Soft Actor-Critic) |
基于最大熵强化学习的离线算法,兼顾探索和收益,适合连续控制任务 |
|||
|
DDPG (Deep Deterministic Policy Gradient) |
针对连续动作空间的 Actor-Critic 算法,结合 DQN 的思想优化确定性策略 |
二、大语言模型对齐(RLHF/RLAIF/DPO)
|
论文名称 |
简介 |
论文地址 |
代码地址 |
|---|---|---|---|
|
RLHF (Deep Reinforcement Learning from Human Preferences) |
首次提出从人类偏好中学习的强化学习框架,是 InstructGPT/GPT-4 对齐的核心方法 |
||
|
InstructGPT |
将 RLHF 落地到大语言模型,通过 SFT+RM+PPO 三阶段实现模型对齐,奠定 LLM 对齐范式 |
||
|
DPO (Direct Preference Optimization) |
无需训练奖励模型和 PPO,直接通过偏好数据优化语言模型,简化 RLHF 流程,效率更高 |
||
|
GRPO (Generalized Reward Preference Optimization) |
统一 DPO/PPO 框架,支持多偏好、多奖励场景,适配复杂对齐需求 |
||
|
RLAIF (Reinforcement Learning from AI Feedback) |
用 AI 反馈替代人类反馈,降低标注成本,是 RLHF 的轻量化替代方案 |
||
|
Fine-Tuning Language Models from Human Preferences |
早期 LLM 偏好对齐的探索,验证了 RLHF 在小模型上的可行性 |
三、多智能体强化学习(MARL)
|
论文名称 |
简介 |
论文地址 |
代码地址 |
|---|---|---|---|
|
MADDPG (Multi-Agent DDPG) |
为多智能体场景设计的 Actor-Critic 算法,引入中心化训练、去中心化执行 |
||
|
MAPPO (Multi-Agent PPO) |
多智能体版本的 PPO,是目前 MARL 的主流算法,兼顾性能和易用性 |
||
|
QMIX (Q-Mixing Network) |
基于价值分解的多智能体算法,解决信用分配问题,适合合作型任务 |
四、强化学习工具库 / 框架
|
名称 |
简介 |
地址 |
|---|---|---|
|
Stable Baselines3 (SB3) |
轻量级、易扩展的强化学习库,支持 PPO/DQN/SAC 等主流算法,适合新手 |
https://stable-baselines3.readthedocs.io/en/master/ GitHub: https://github.com/DLR-RM/stable-baselines3 |
|
RLlib |
工业级强化学习库,支持分布式训练,适配大规模任务 |
https://docs.ray.io/en/latest/rllib/index.html GitHub: https://github.com/ray-project/ray |
|
TRL (Transformer Reinforcement Learning) |
专为大语言模型设计的 RL 库,支持 RLHF/DPO/GRPO 等对齐算法 |
|
|
OpenRLHF |
开源的 RLHF 训练框架,支持分布式训练,适配大模型 |
https://openrlhf.readthedocs.io/en/latest/ GitHub: https://github.com/OpenRLHF/OpenRLHF |
3、DPO

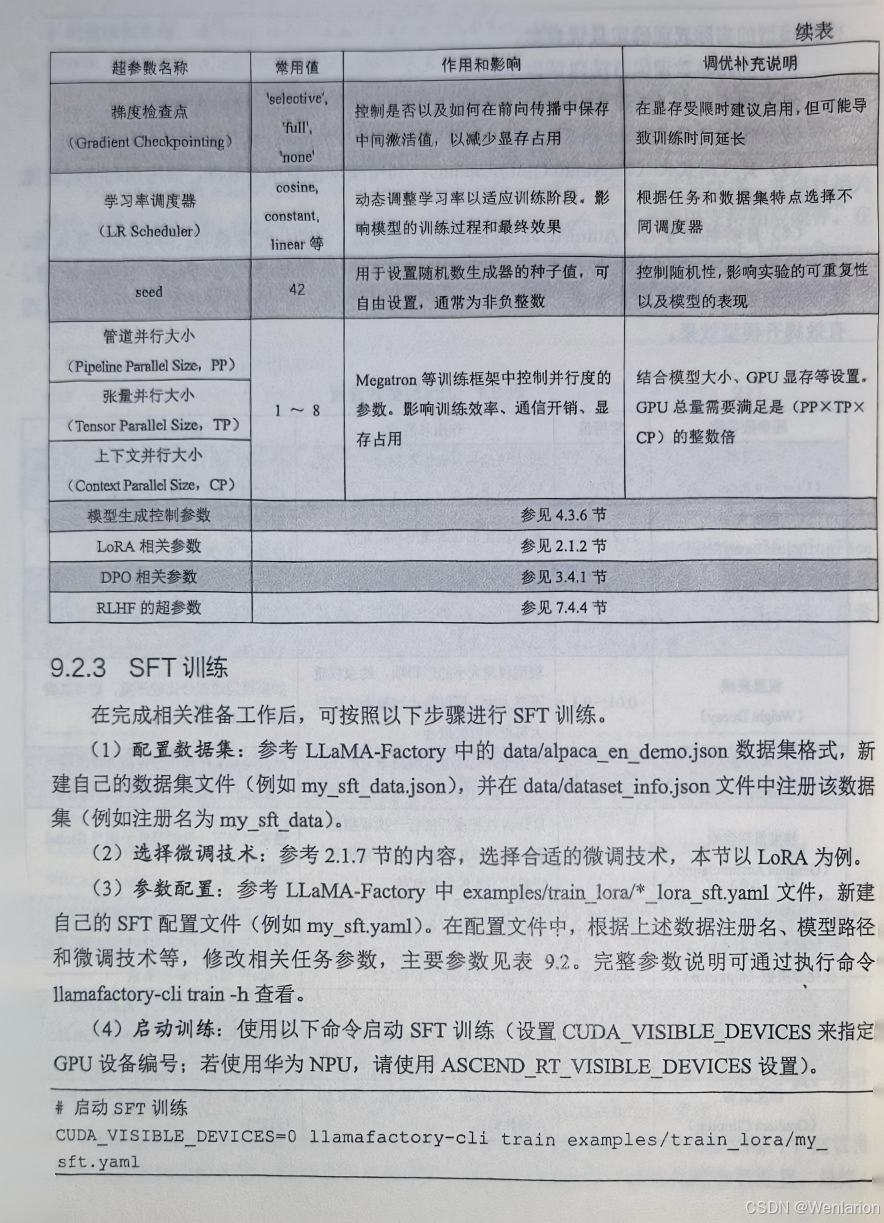
考模型,可以将其输出结果预先录制好,这样在训练时就不需要加载),算力开销更低,更易于落地实践。
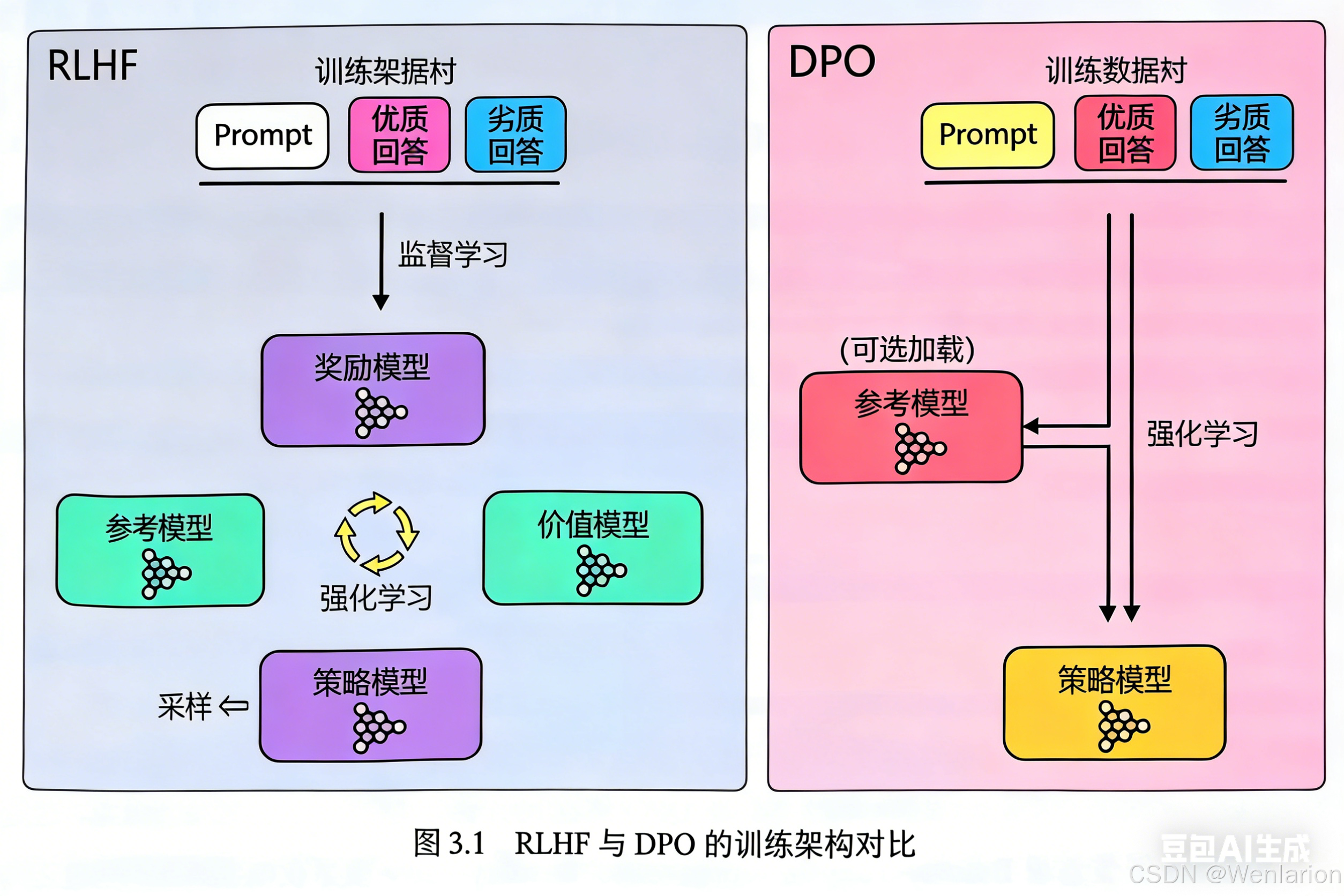





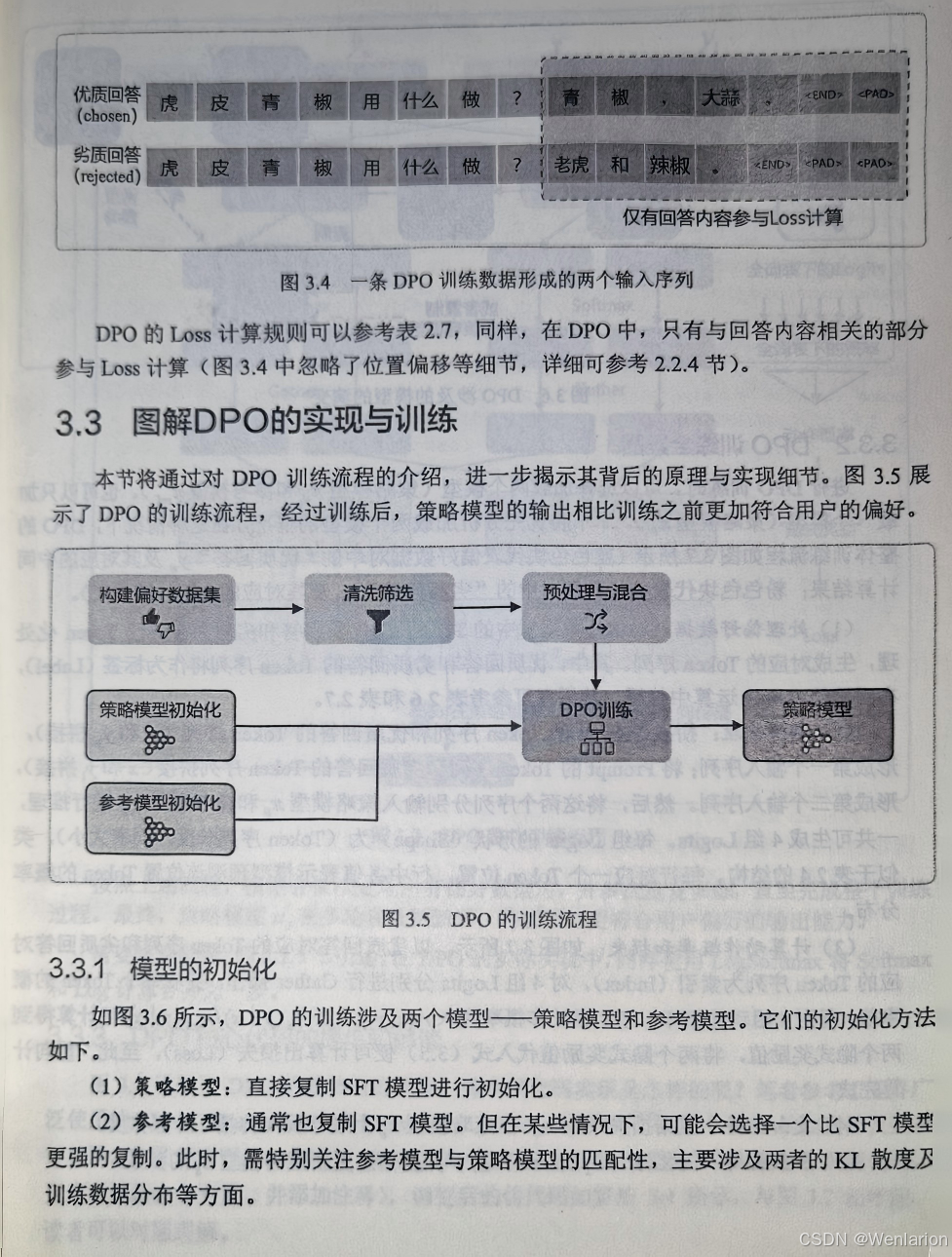
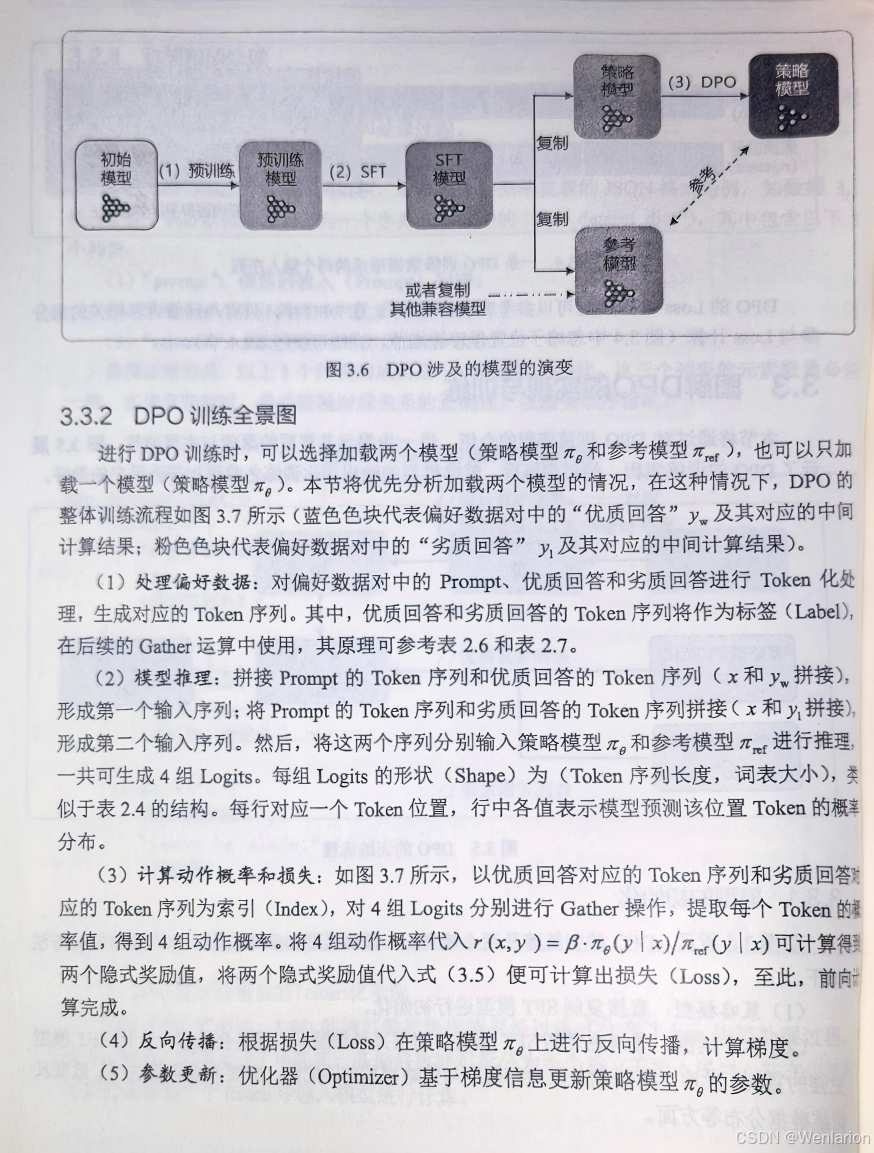
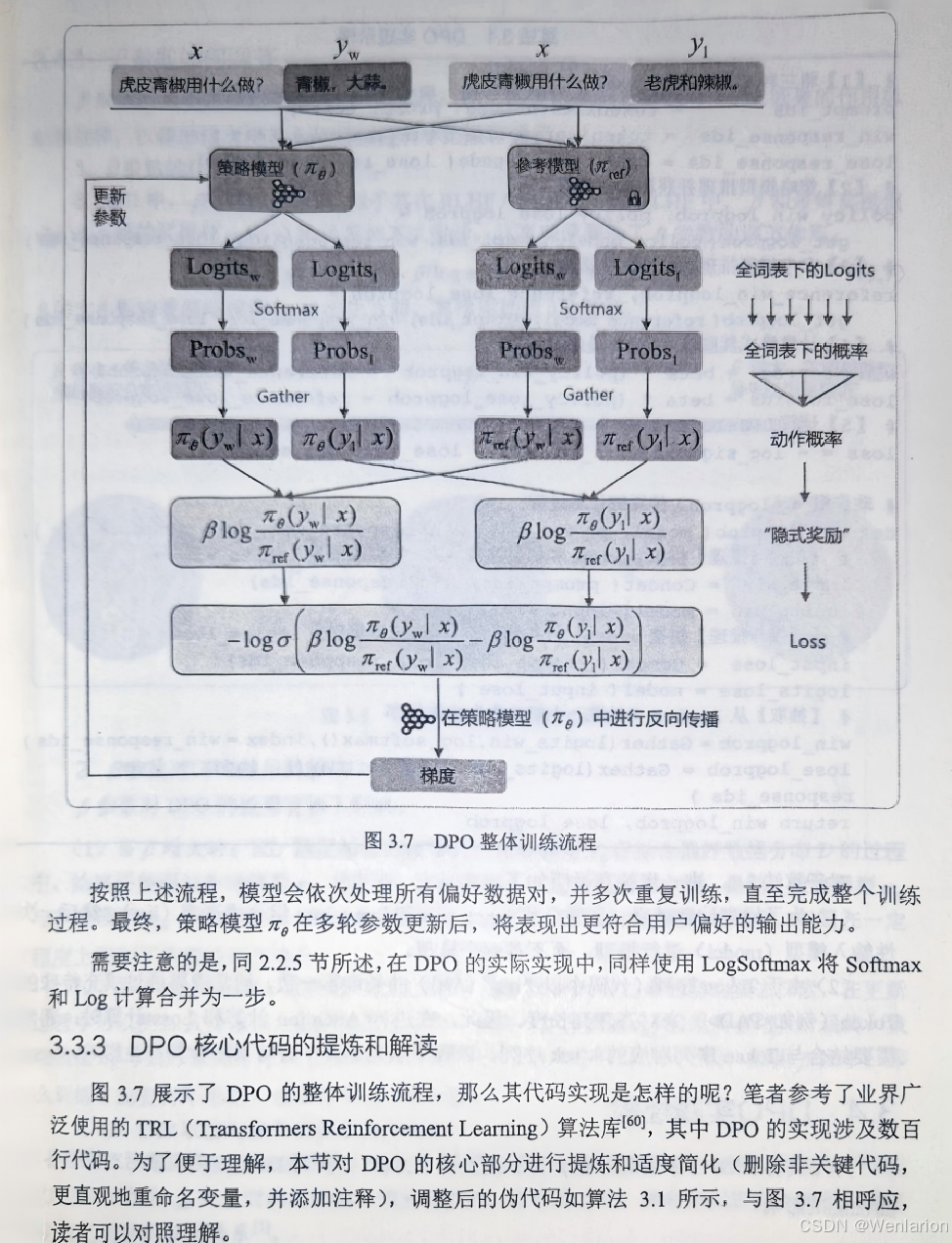



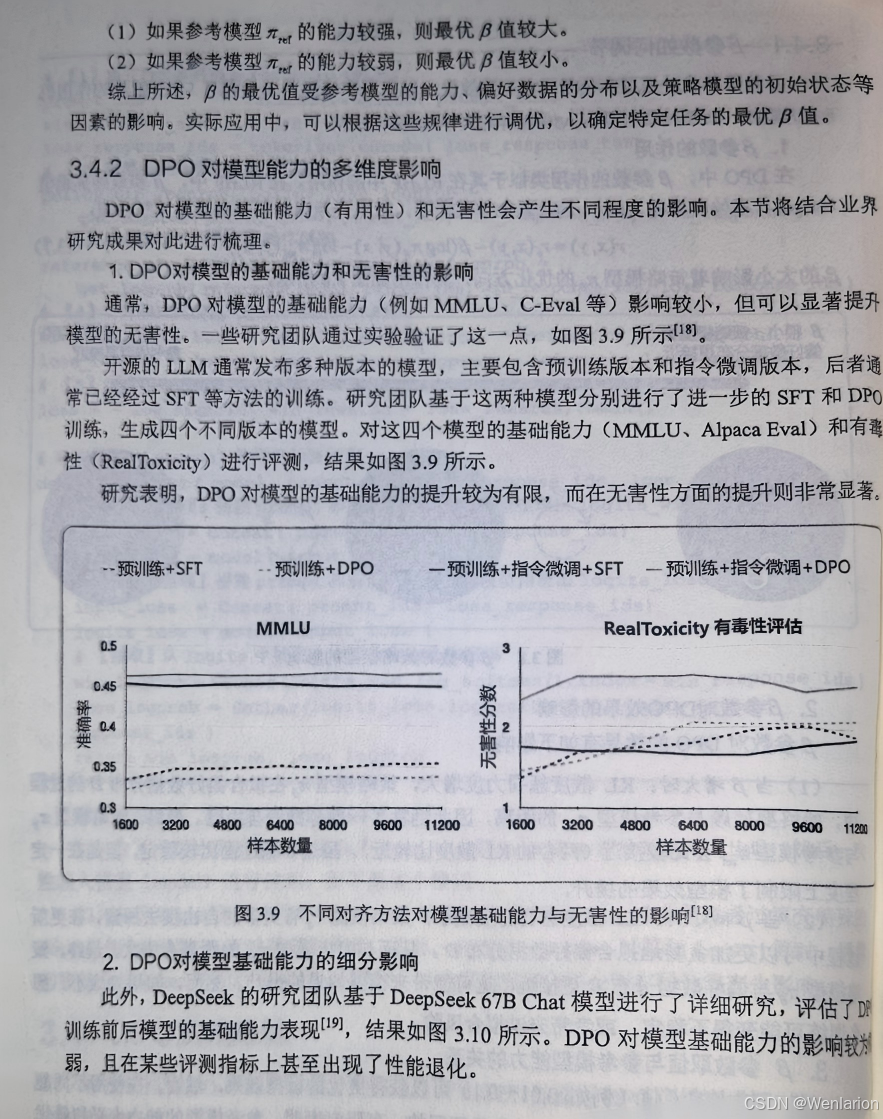
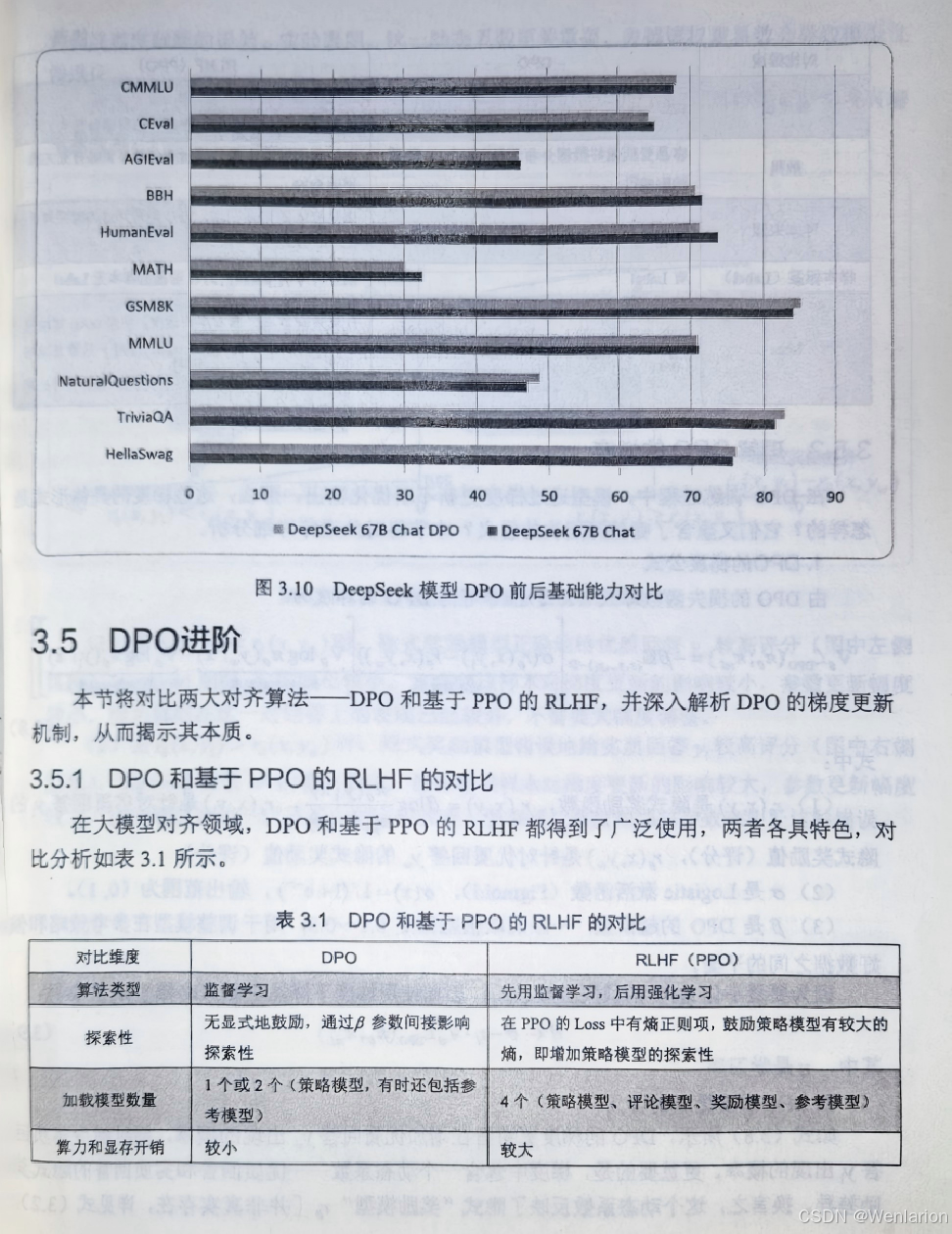


4、免训练的效果优化技术








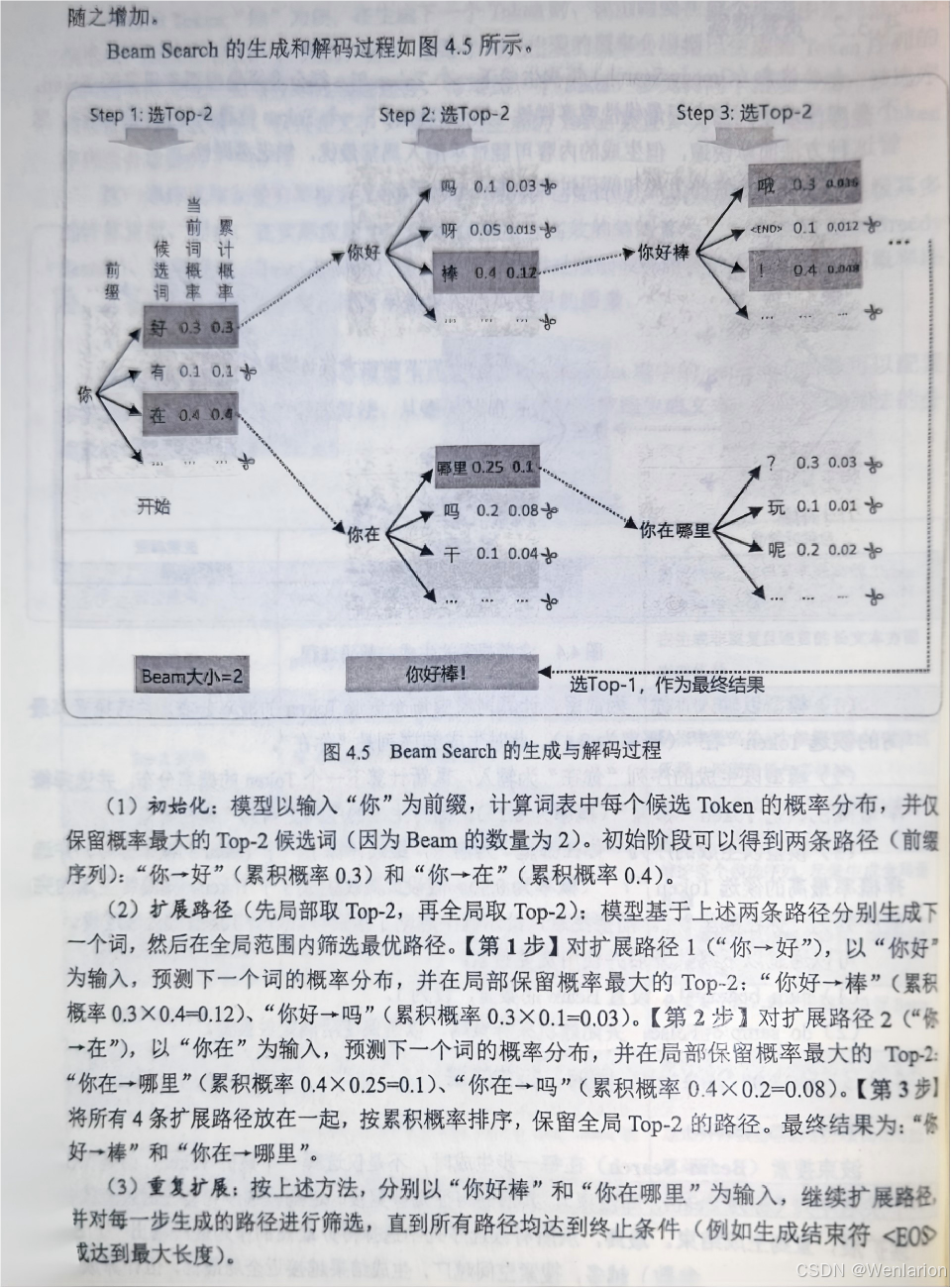

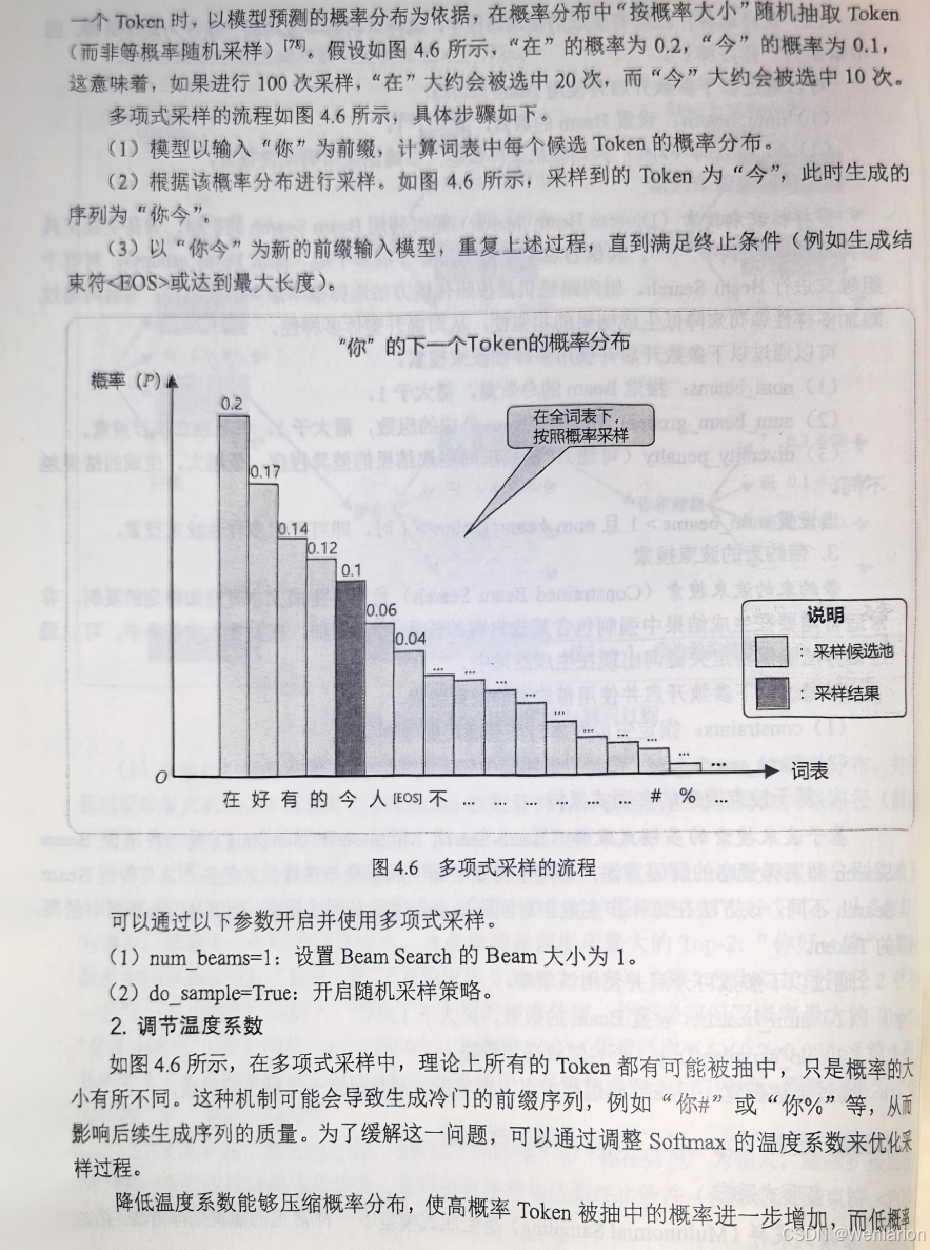
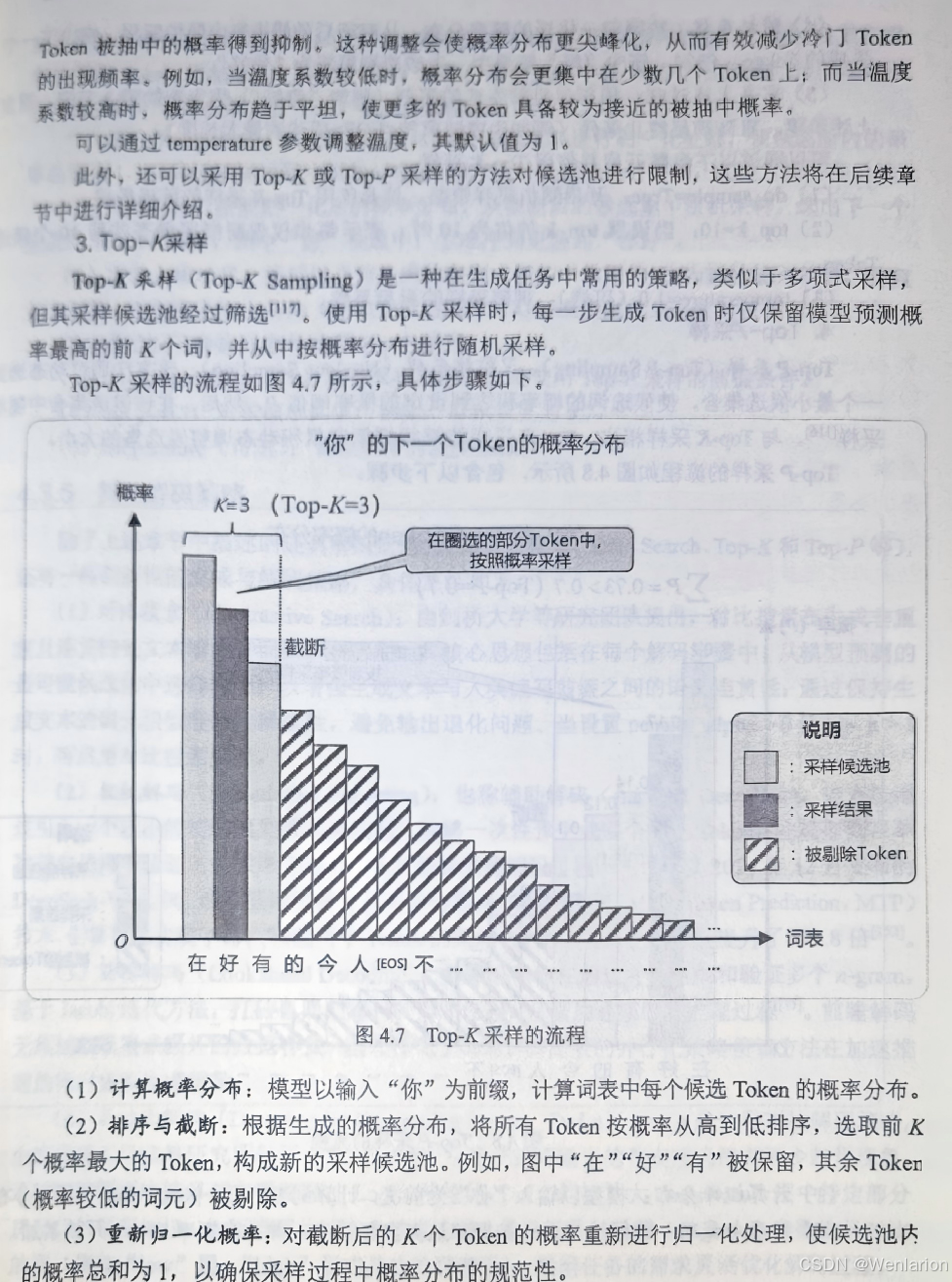
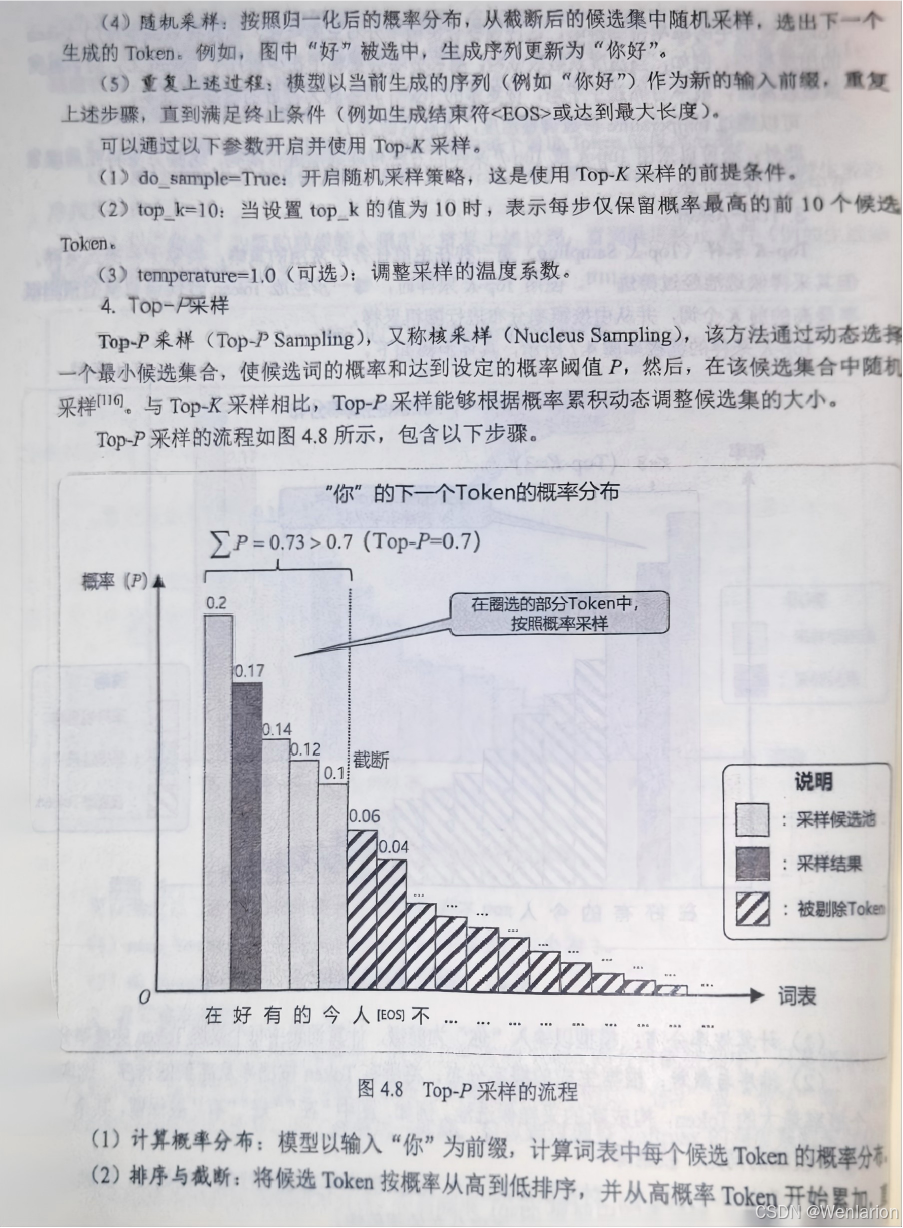





5、强化学习基础



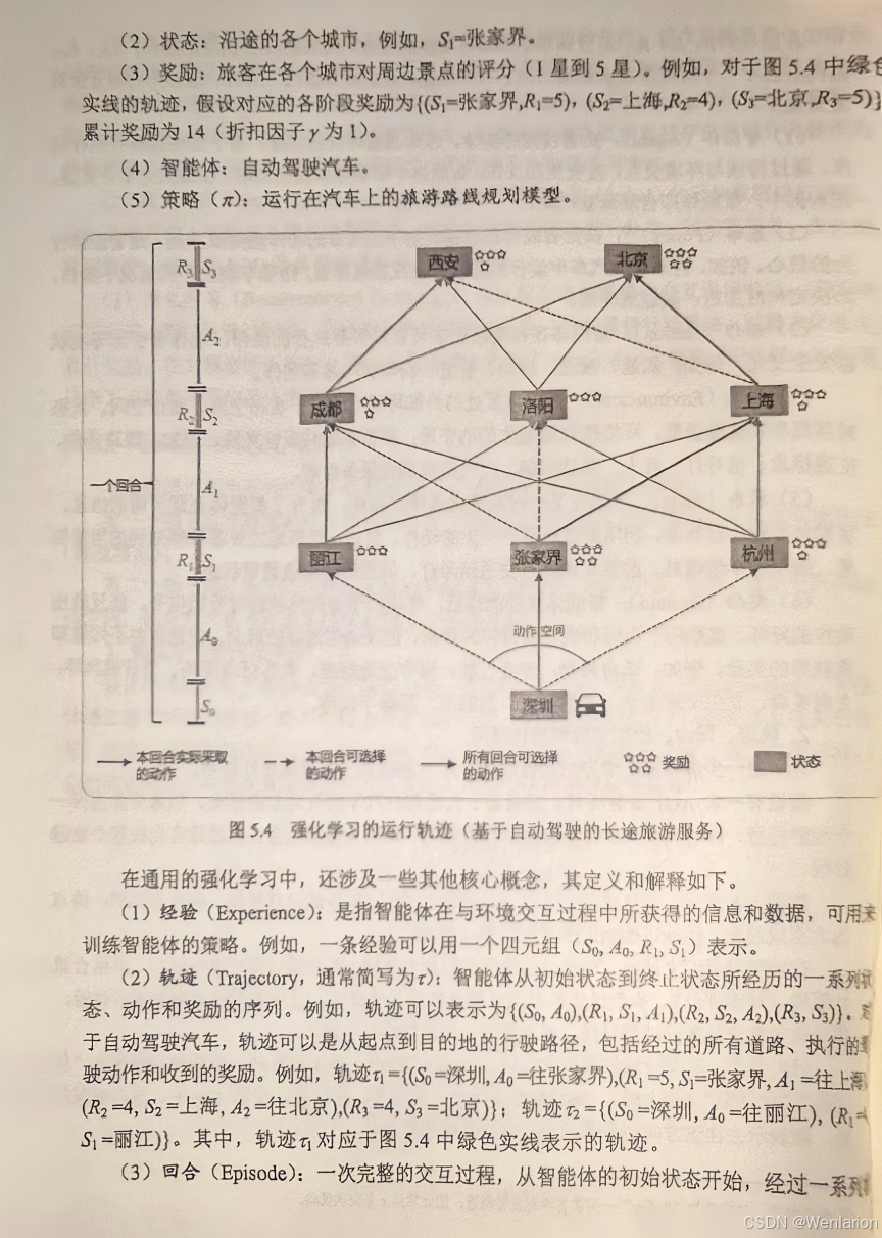


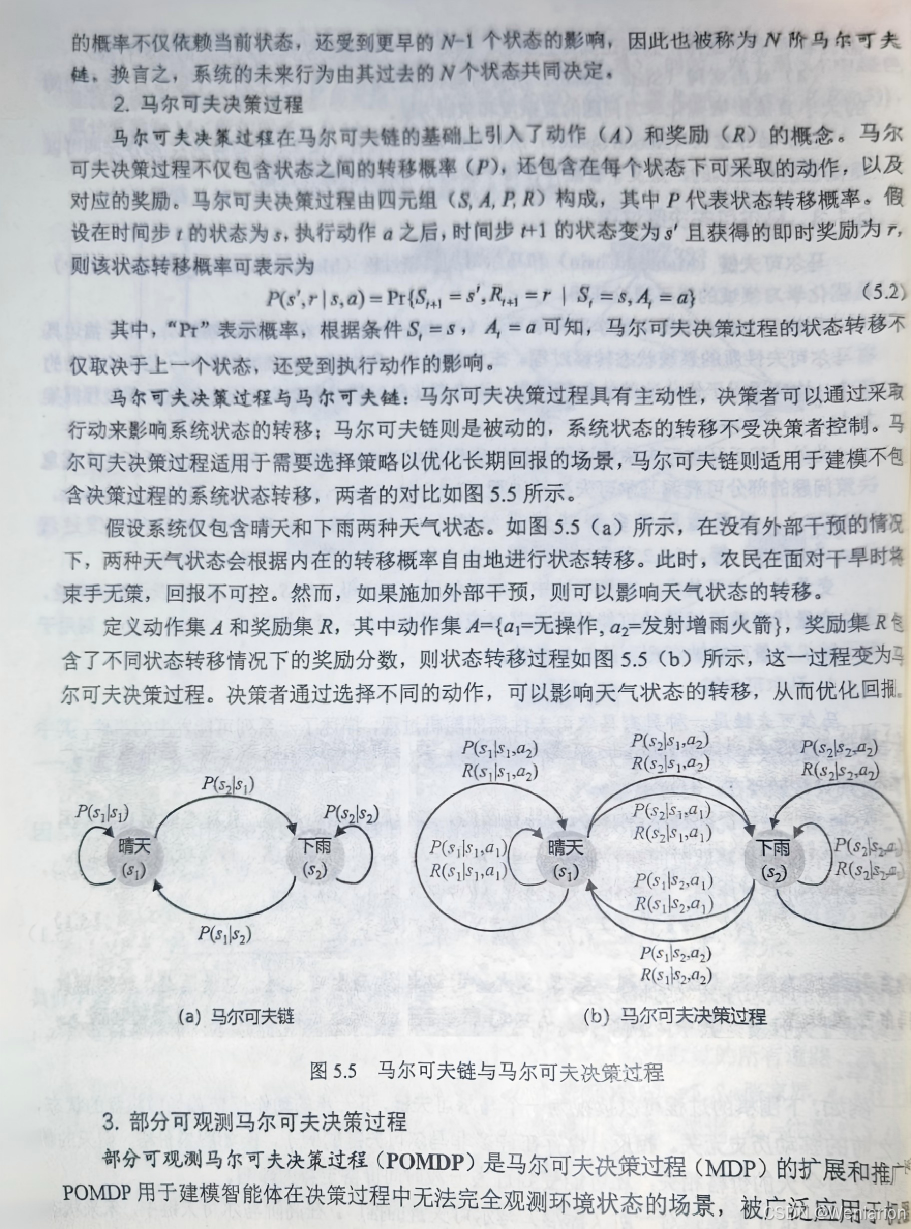


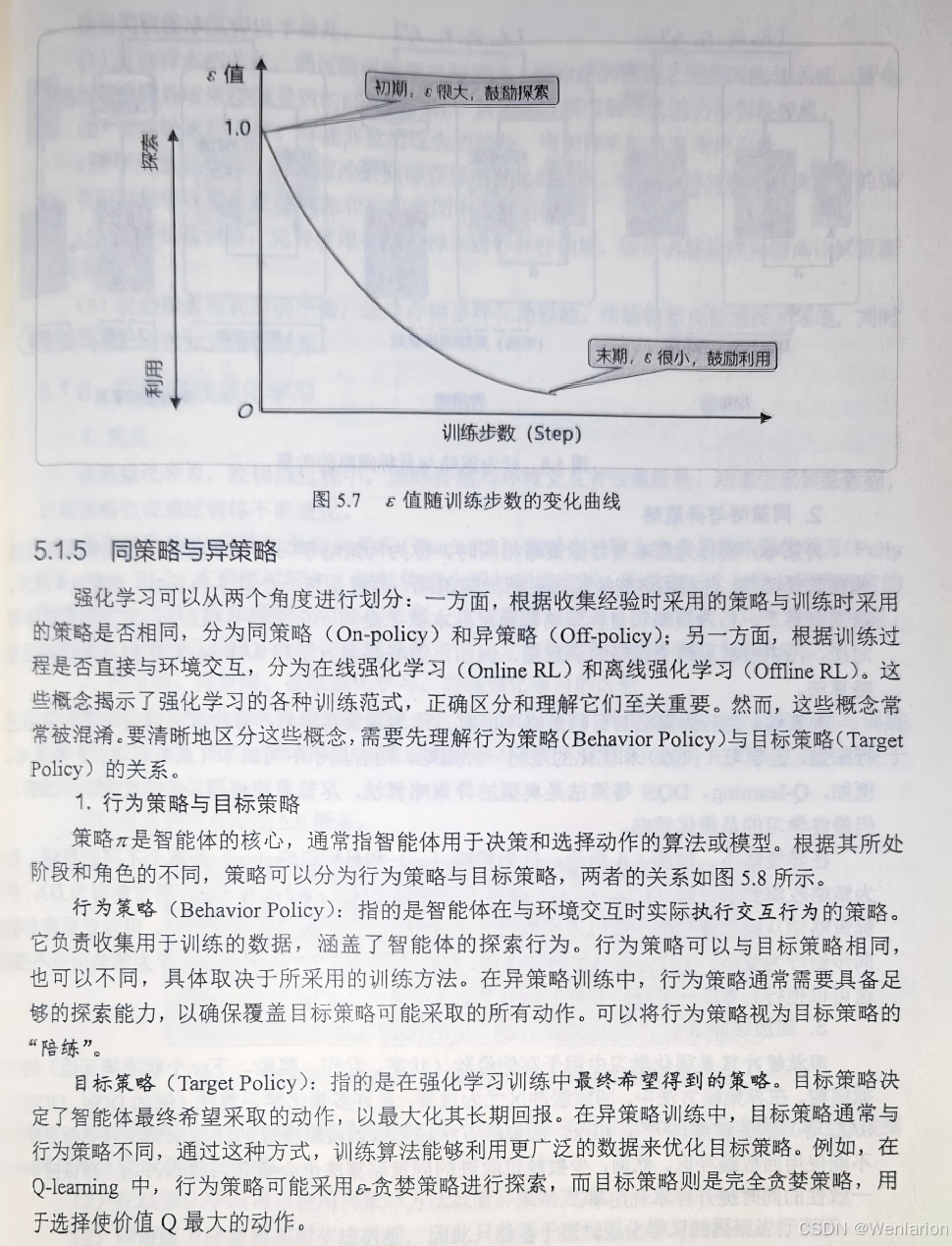








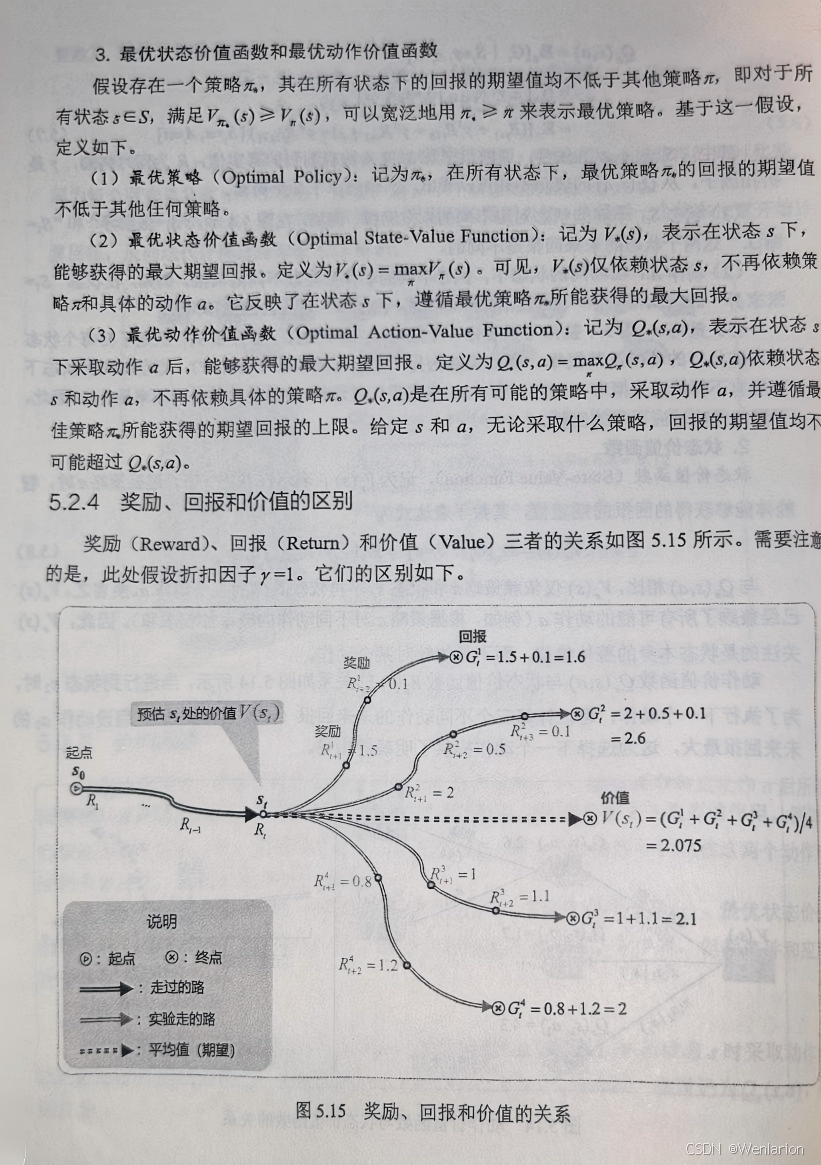
















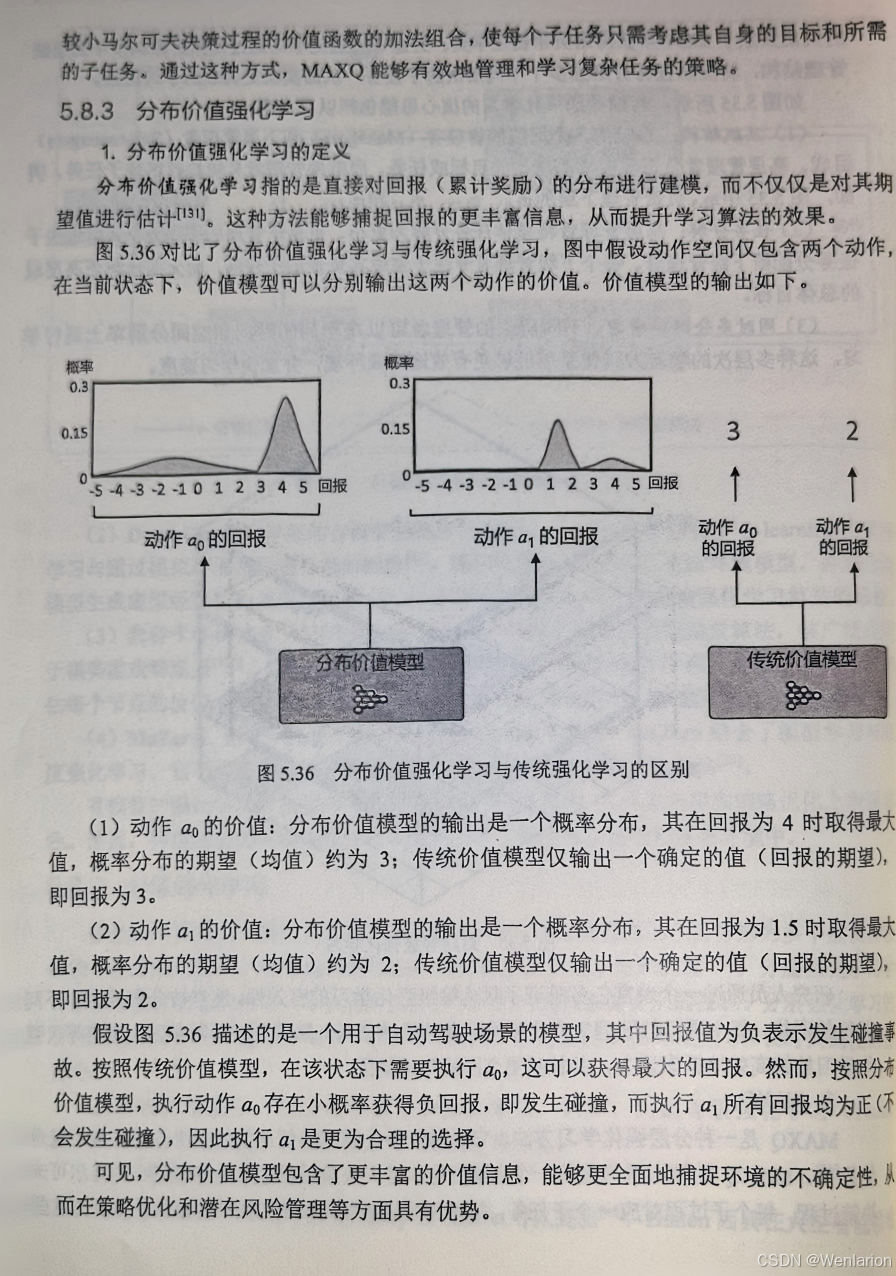
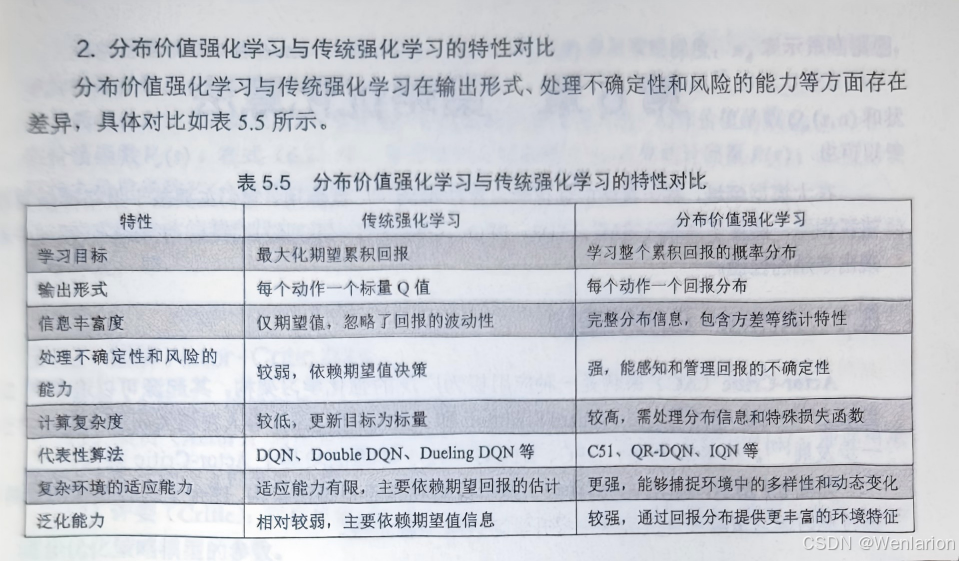
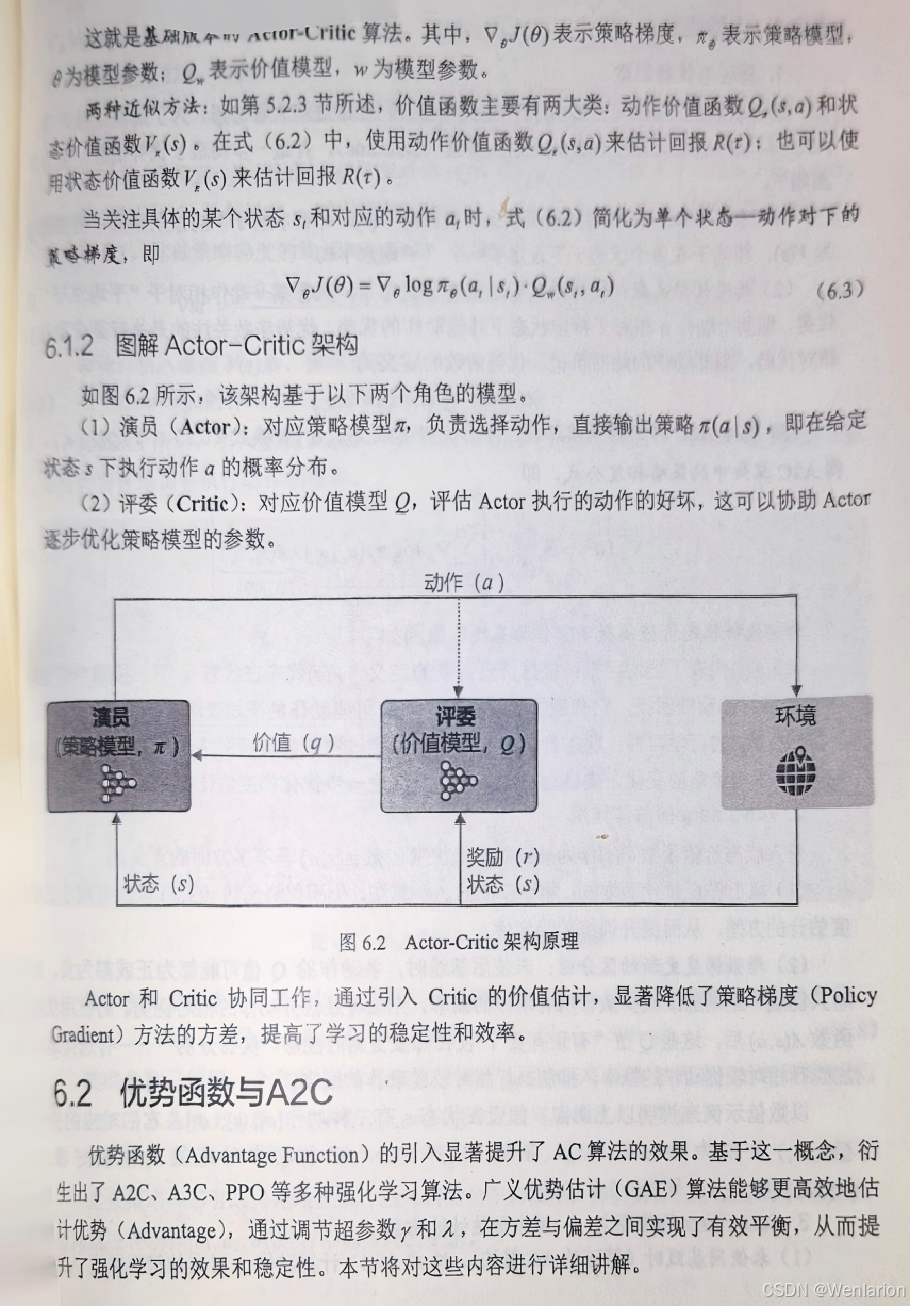
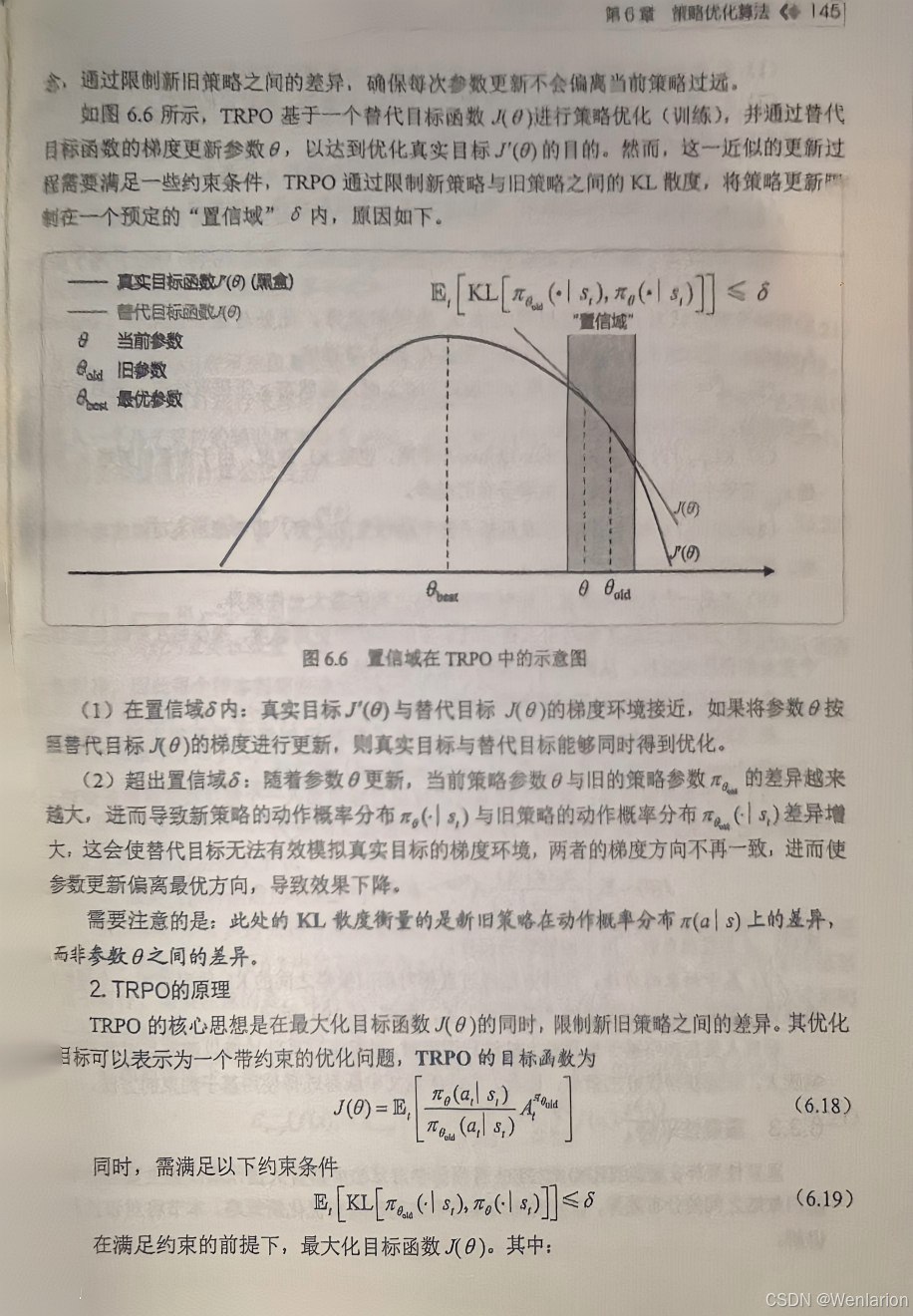
6、策略优化算法










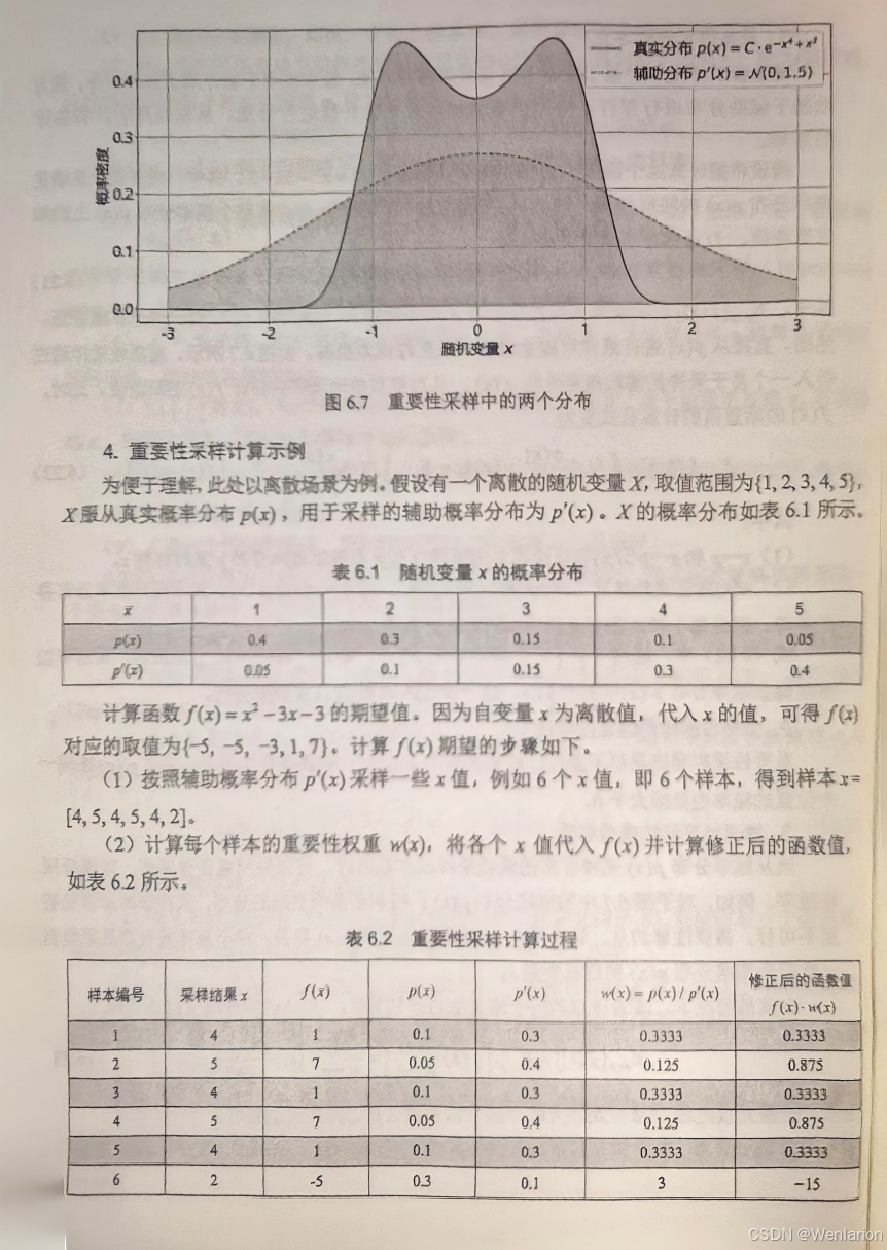
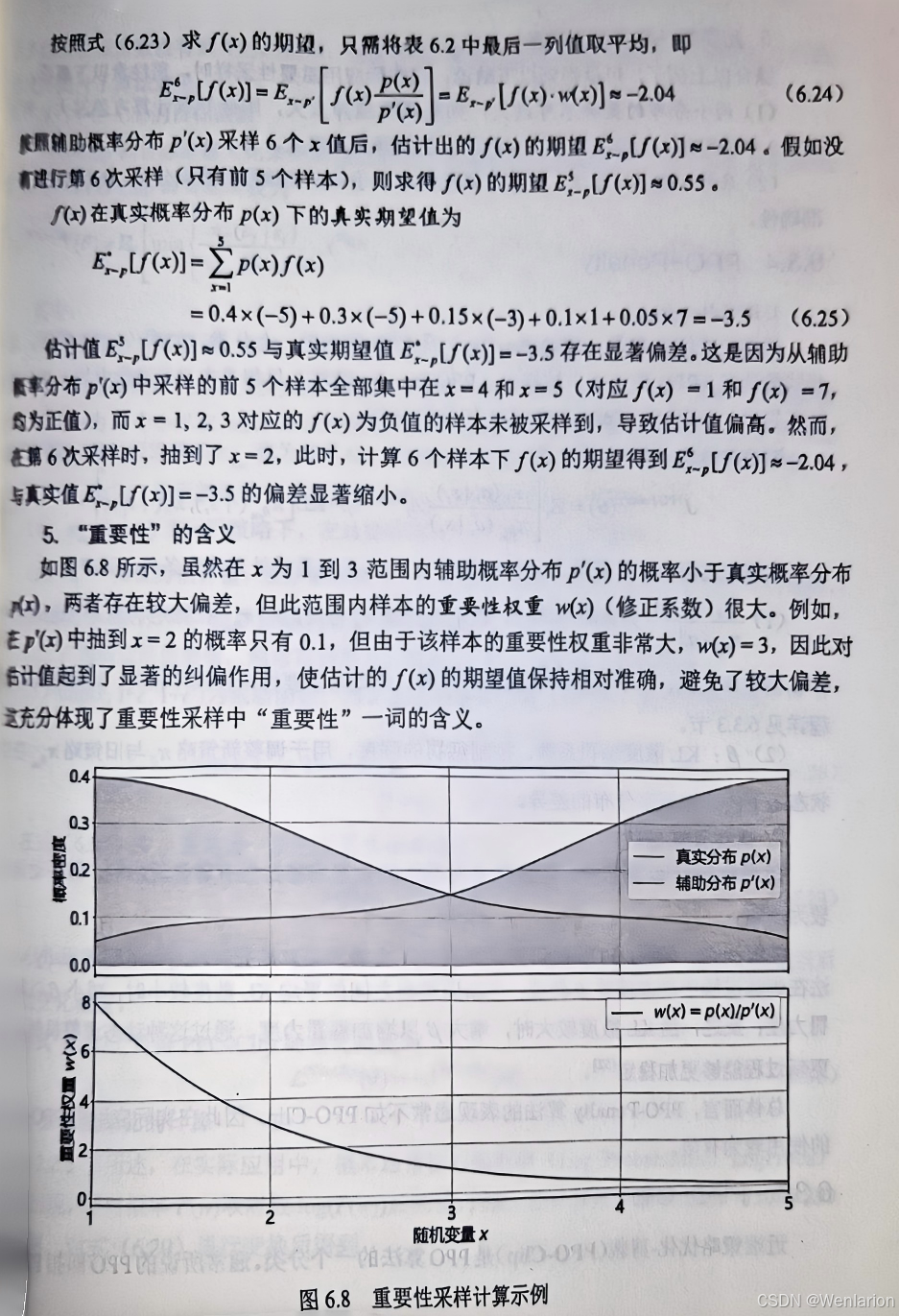


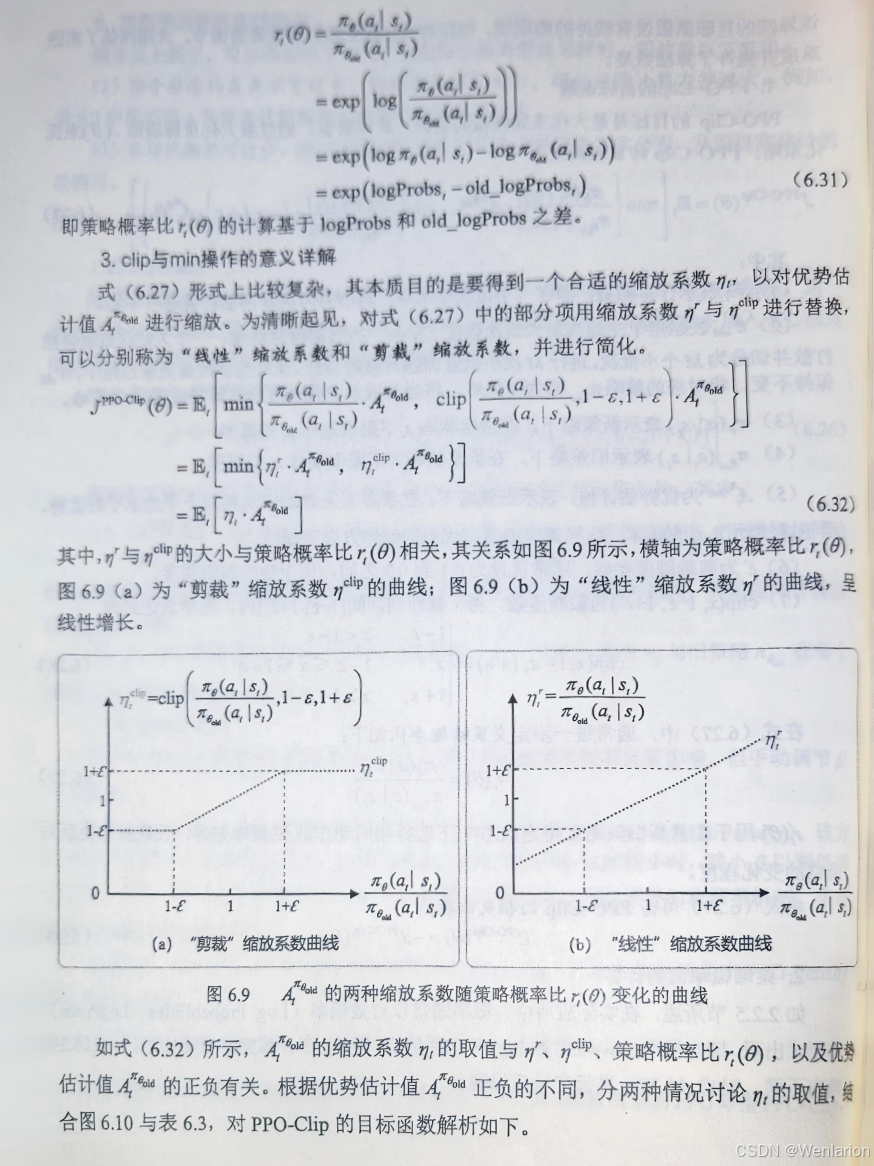
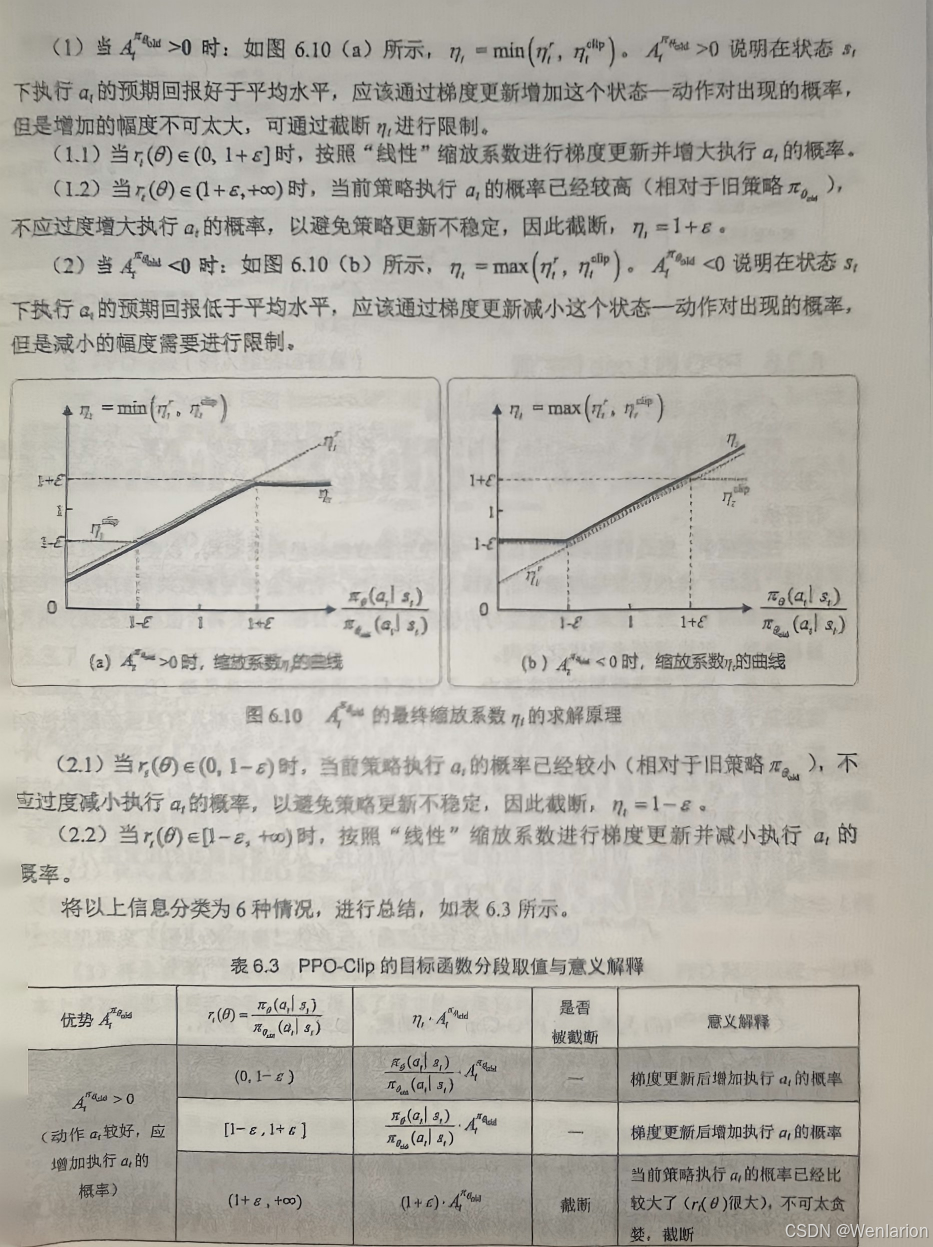






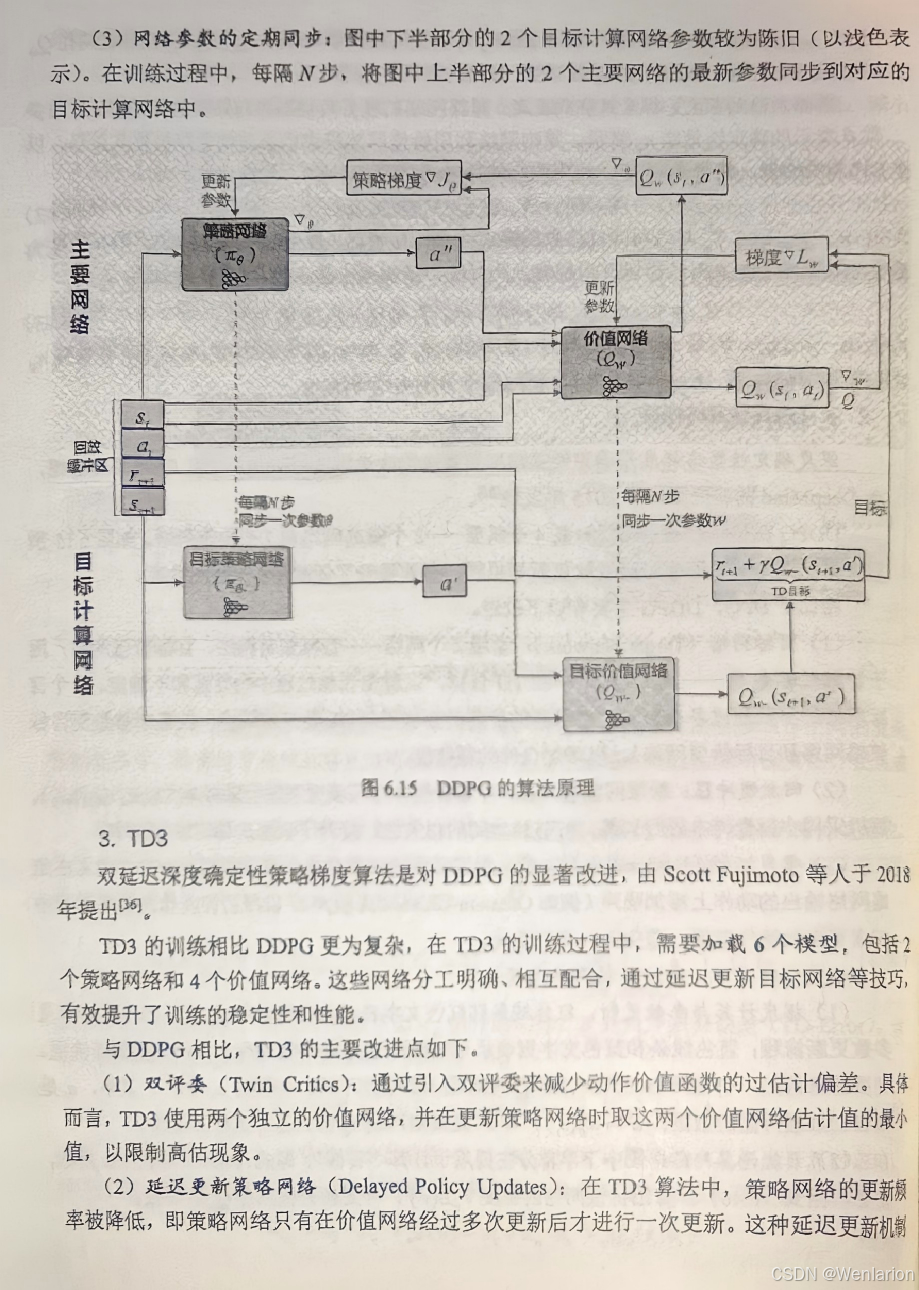

7、RLHF与RLAIF




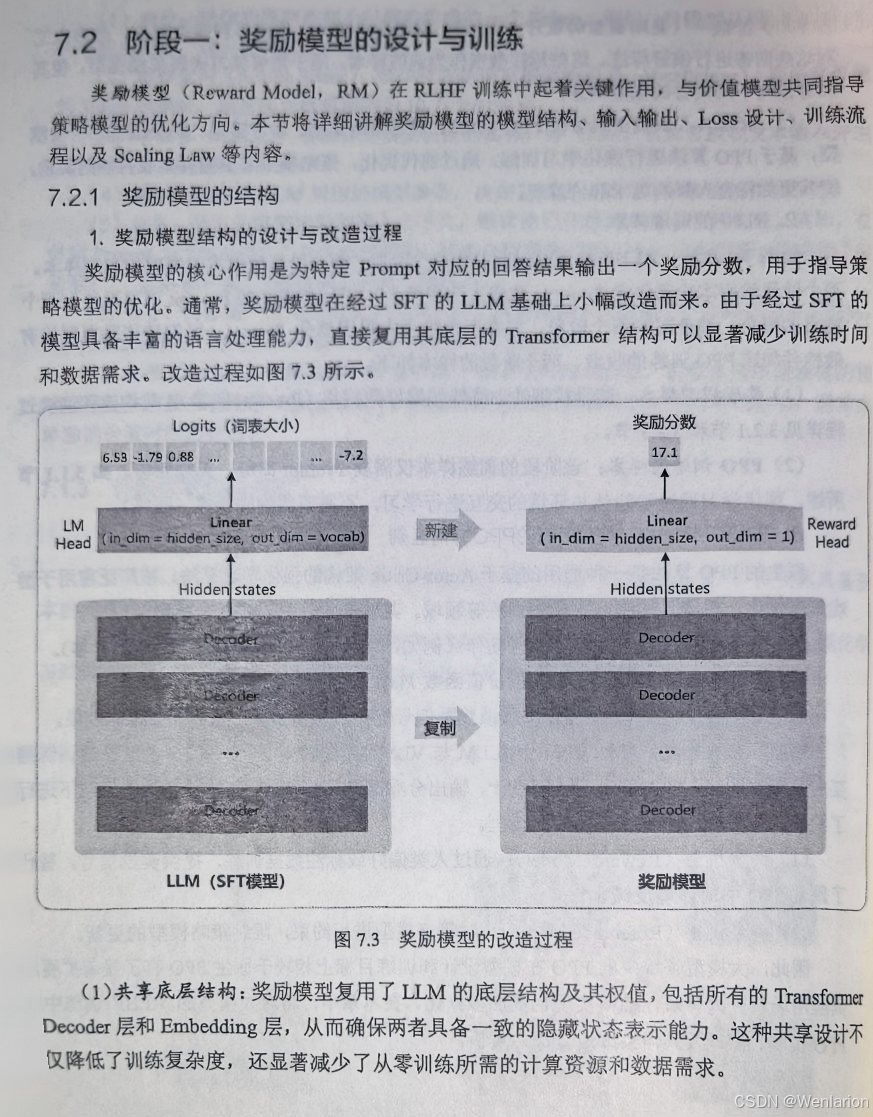



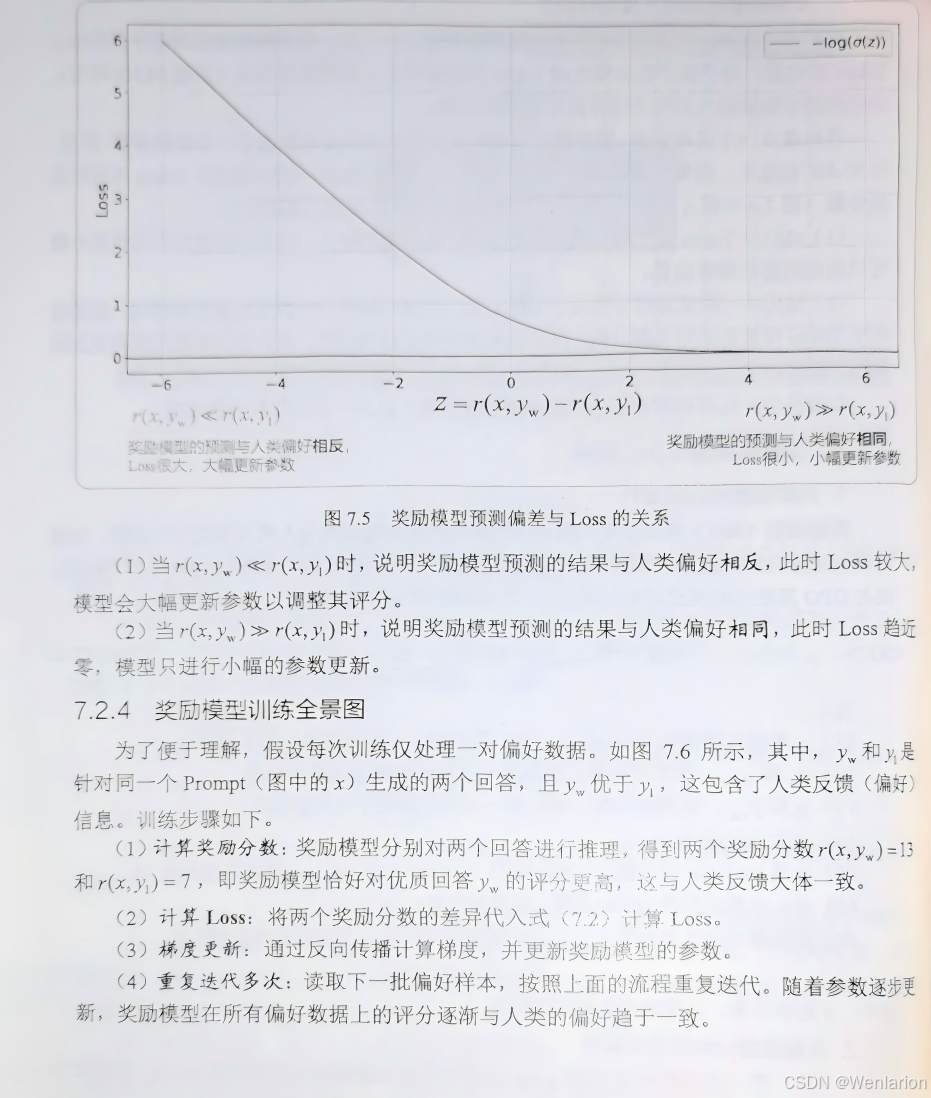
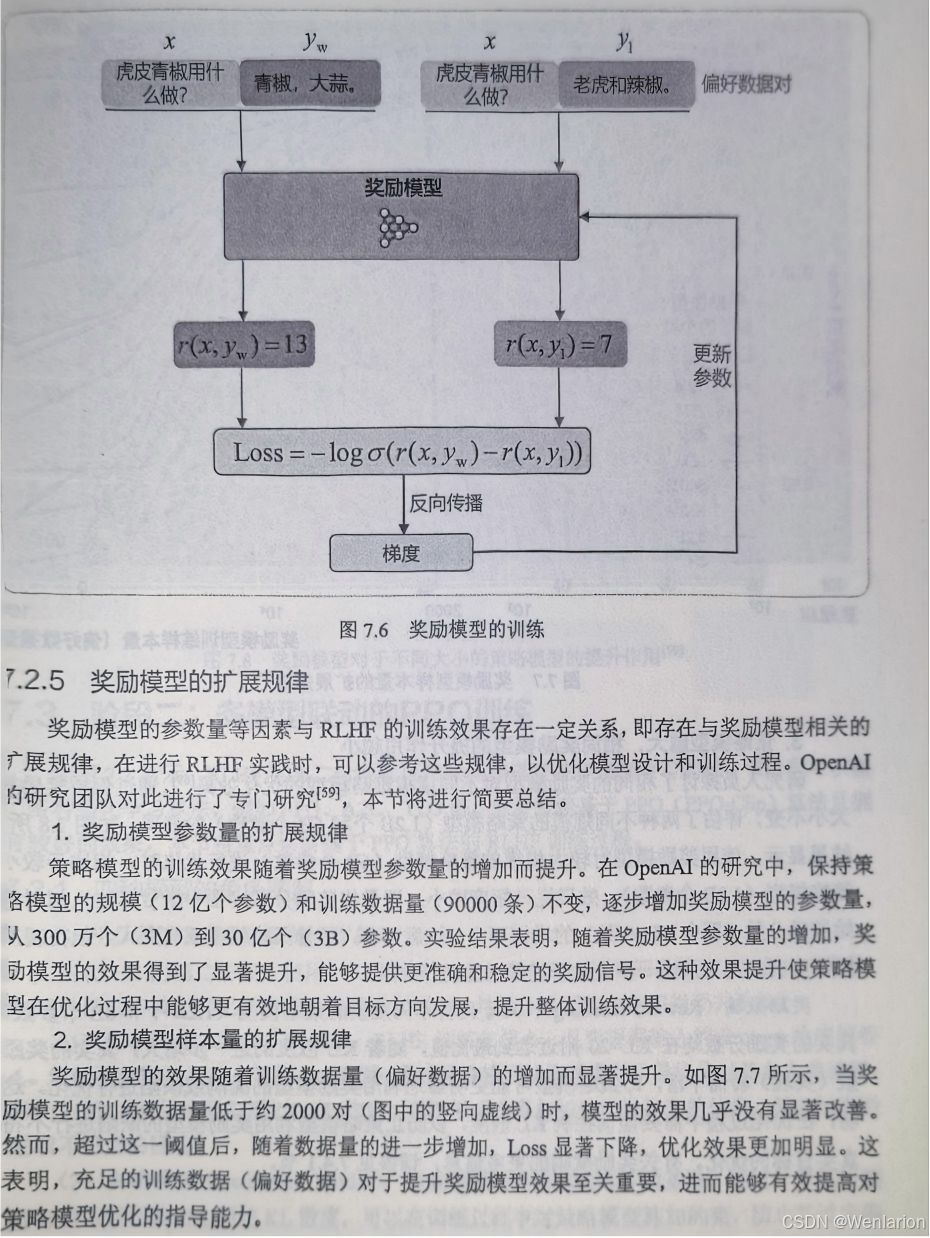
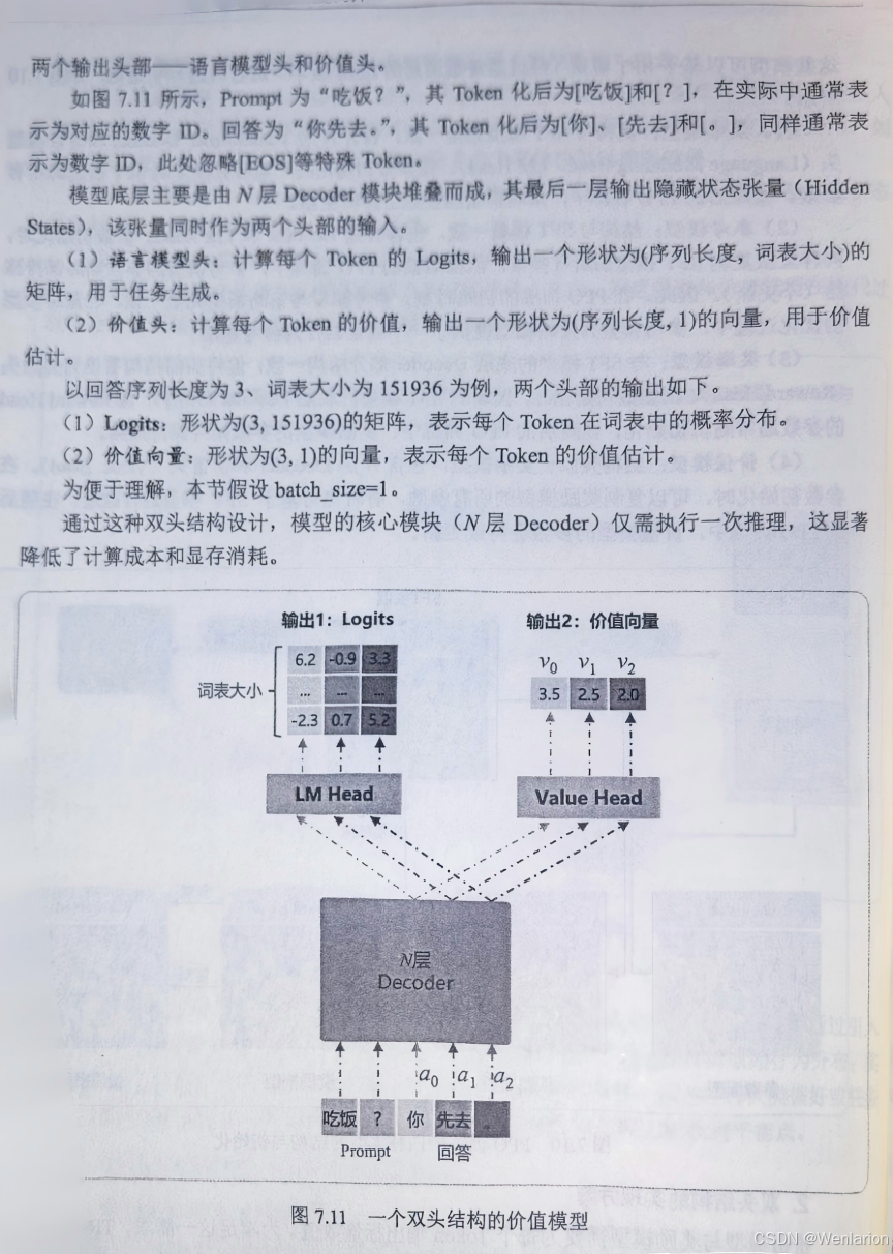
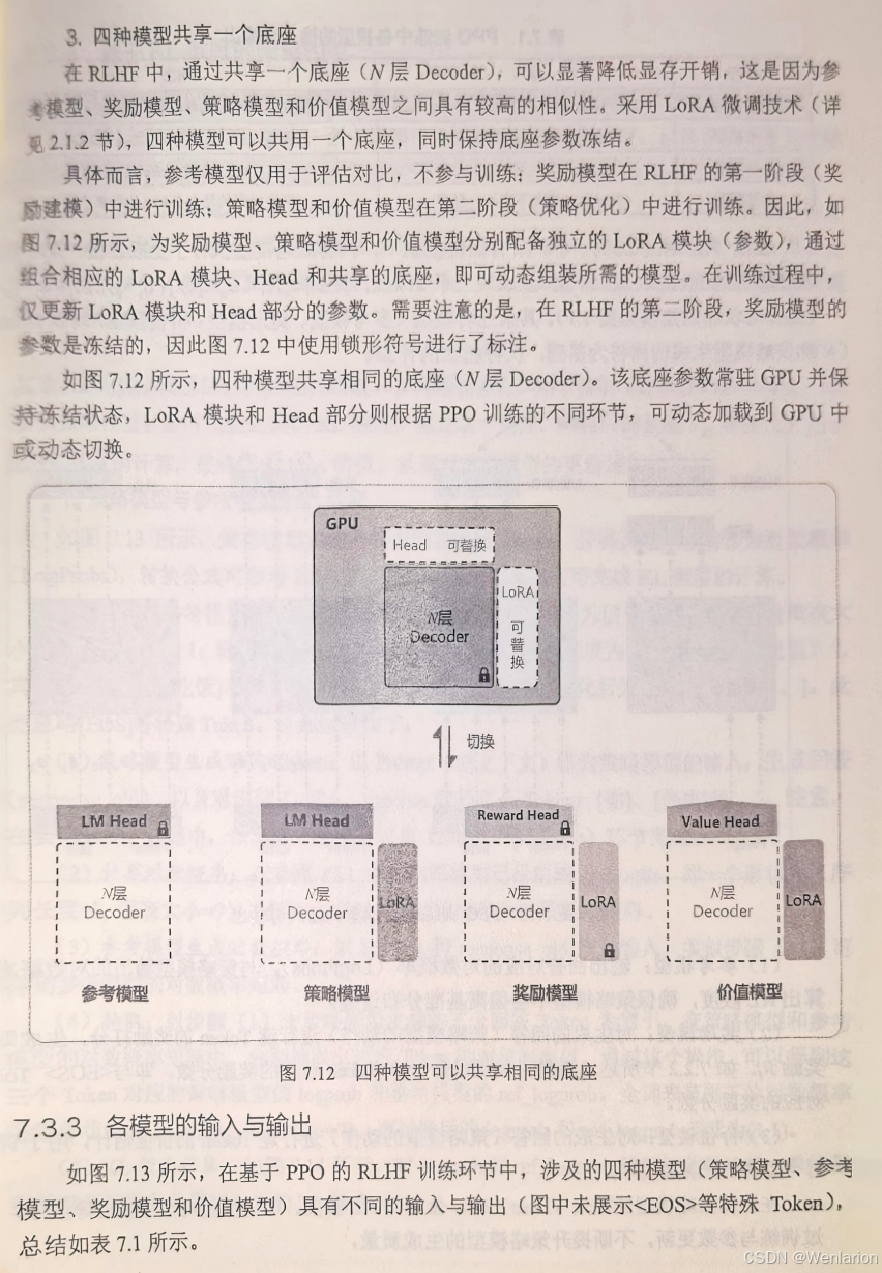






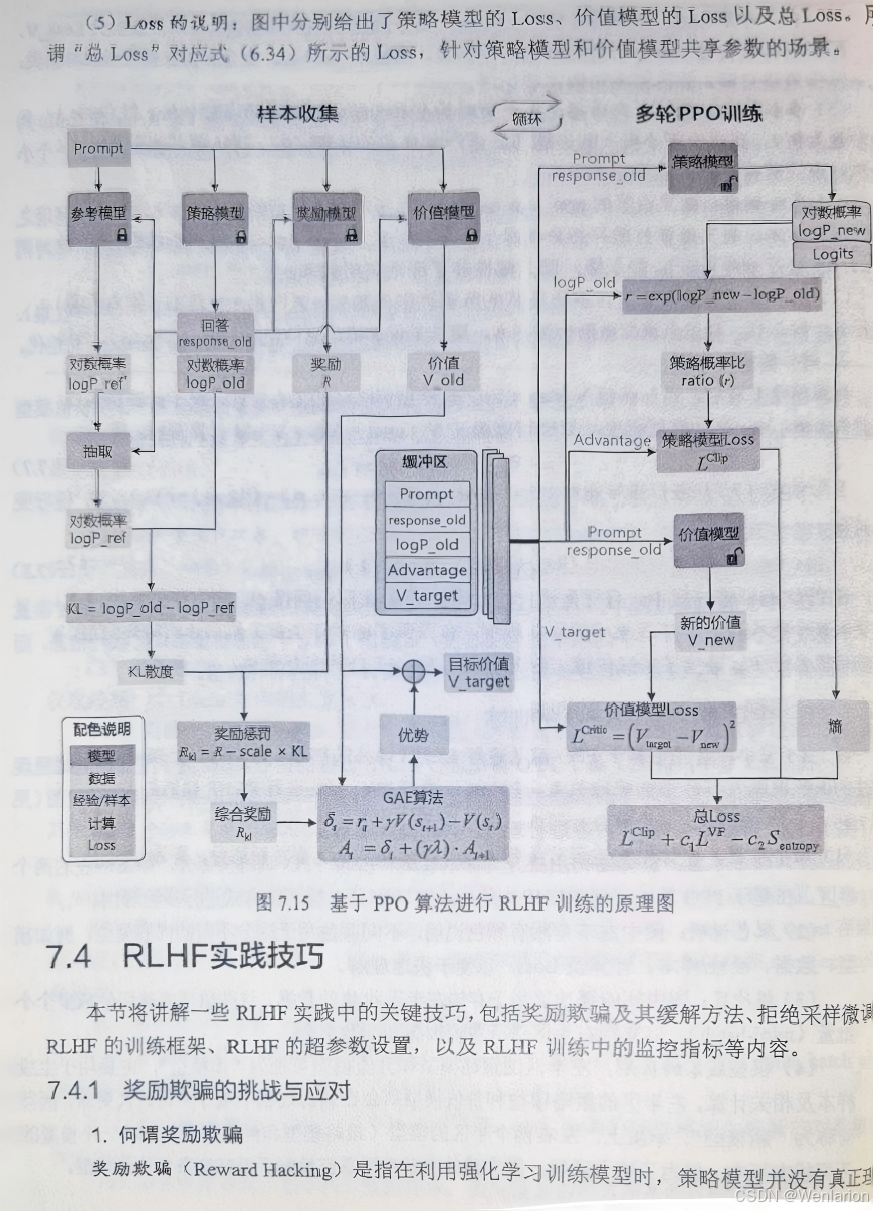


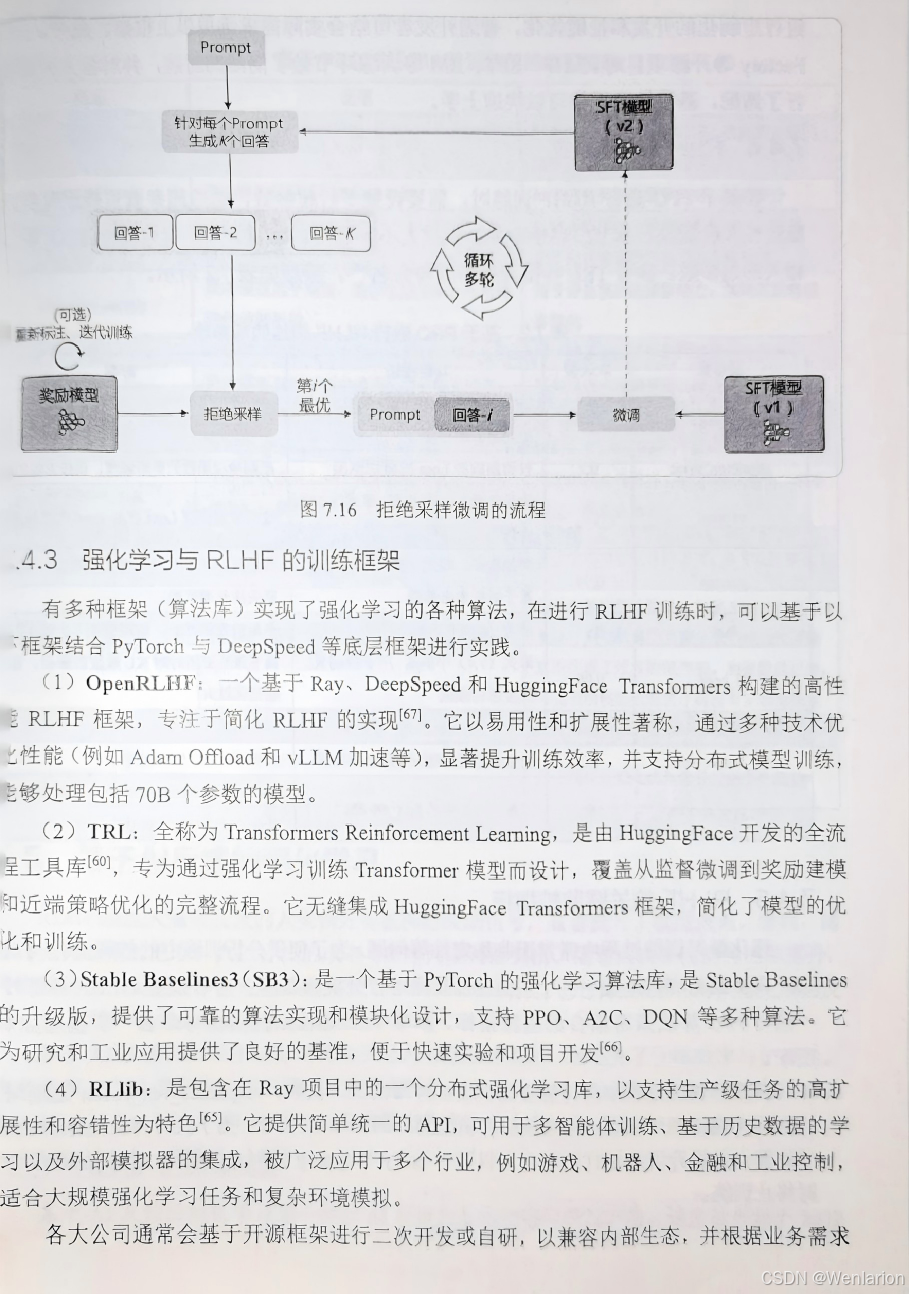


8、逻辑推荐优化











9、综合实践和性能优化













参考文献
[1] Understanding Reference Policies in Direct Preference Optimization: https://arxiv.org/pdf/2407.13709
[2] Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study: https://arxiv.org/pdf/2404.10719v2
[3] Prefix-Tuning: https://arxiv.org/pdf/2101.00190
[4] P-Tuning: https://arxiv.org/pdf/2103.10385
[5] Prompt Tuning: https://arxiv.org/pdf/2104.08691
[6] P-Tuning v2: https://arxiv.org/pdf/2110.07602
[7] LoRA: https://arxiv.org/pdf/2106.09685
[8] AdaLoRA: https://arxiv.org/pdf/2303.10512
[9] PiSSA: https://arxiv.org/abs/2404.02948
[10] OLoRA: https://arxiv.org/pdf/2406.01775
[11] LoHa: https://arxiv.org/pdf/2108.06098
[12] LoKr: https://arxiv.org/pdf/2309.14859
[13] QLoRA: https://arxiv.org/abs/2305.14314
[14] LofQ: https://arxiv.org/pdf/2310.08659
[15] DoRA: https://arxiv.org/pdf/2402.09353
[16] Adapter Tuning: https://arxiv.org/pdf/1902.00751
[17] LLM Finetuning: https://arxiv.org/pdf/2402.17193
[18] DPO SFT: https://arxiv.org/pdf/2406.04879
[19] DEEPSEEK DPO: https://arxiv.org/pdf/2401.02954
[20] LLaMA Factory: https://github.com/hiyouga/LLaMA-Factory
[21] Qwen: https://huggingface.co/Qwen/Qwen2-0.5B-Instruct
[22] LIMA: https://arxiv.org/pdf/2305.11206
[23] InsTag: https://arxiv.org/pdf/2308.07074
[24] IFD: https://arxiv.org/pdf/2308.12032v5
[25] WizardLM: Empowering Large Language Models to Follow Complex Instructions: https://arxiv.org/pdf/2304.12244
[26] LESS: Selecting Influential Data for Targeted Instruction Tuning: https://arxiv.org/pdf/2402.04333
[27] DEITA: https://arxiv.org/pdf/2312.15685
[28] DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model: https://arxiv.org/pdf/2405.04434
[29] Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?: https://arxiv.org/pdf/2405.05904
[30] Knowledge Verification to Nip Hallucination in the Bud: https://arxiv.org/pdf/2401.10768
[31] OpenAI, Parameter Space Noise for Exploration: https://arxiv.org/pdf/1706.01905
[32] Reinforcement Learning: An Introduction, 2nd Edition, Richard S. Sutton: http://incompleteideas.net/book/the-book-2nd.html
[33] MuZero: https://arxiv.org/pdf/1911.08265
[34] DPG: https://proceedings.mlr.press/v32/silver14.pdf
[35] DDPG: https://arxiv.org/pdf/1509.02971
[36] TD3: https://arxiv.org/pdf/1802.09477
[37] Dec-POMDP: https://arxiv.org/pdf/1301.3836
[38] MAPPO: https://arxiv.org/pdf/2103.01955
[39] QMIX: https://arxiv.org/pdf/1803.11485
[40] COMA: https://arxiv.org/pdf/1705.08926
[41] MADDPG: https://arxiv.org/pdf/1706.02275
[42] MAXQ: https://www.jair.org/index.php/jair/article/view/10266/24463
[43] Feudal Reinforcement Learning: https://www.cs.toronto.edu/~fritz/absps/dlh93.pdf
[44] Dyna-Q: http://www.incompleteideas.net/papers/sutton-90.pdf
[45] POMDP: Optimal control of Markov processes with incomplete state information, https://core.ac.uk/download/pdf/82498456.pdf
[46] DPO: https://arxiv.org/pdf/2305.18290
[47] AC 架构: http://www.derongliu.org/adp-cdrom/Barto1983.pdf
[48] SAC: https://arxiv.org/pdf/1801.01290
[49] A3C: https://arxiv.org/pdf/1602.01783
[50] GAE: https://arxiv.org/pdf/1506.02438
[51] TRPO: https://arxiv.org/pdf/1502.05477
[52] PPO: https://arxiv.org/abs/1707.06347
[53] John Schulman: https://www.technologyreview.com/2023/03/03/1069311/inside-story-oral-history-how-chatgpt-built-openai/
[54] Deep reinforcement Learning from Human Preferences: https://arxiv.org/pdf/1706.03741
[55] Fine-Tuning Language Models from Human Preferences: https://arxiv.org/pdf/1909.08593
[56] InstructGPT: Training language models to follow instructions with human feedback: https://arxiv.org/pdf/2203.02155
[57] LLaMA2: https://arxiv.org/pdf/2307.09288
[58] LLaMA3: https://arxiv.org/abs/2407.21783
[59] Scaling Laws for Reward Model Overoptimization: https://arxiv.org/pdf/2210.10760
[60] TRL: https://github.com/huggingface/trl
[61] 吴恩达 IRL, Algorithms for Inverse Reinforcement Learning: https://ai.stanford.edu/~ang/papers/icml100-irl.pdf
[62] CAI: https://arxiv.org/pdf/2212.08073
[63] RLAIF-V: https://arxiv.org/pdf/2405.17220
[64] Claude's Constitution: https://www.anthropic.com/news/claudes-constitution
[65] RLlib: https://docs.ray.io/en/latest/rllib/index.html
[66] Stable Baselines3 (SB3) : https://stable-baselines3.readthedocs.io/en/master/
[67] OpenRLHF: https://openrlhf.readthedocs.io/en/latest/
[68] lilianweng: https://lilianweng.github.io/posts/2024-11-28-reward-hacking/
[69] SEAL:https://arxiv.org/abs/2408.10270
[70] Reward hacking: https://arxiv.org/abs/2201.03544
[71] Anthropic, Rejection Sampling: https://arxiv.org/pdf/2204.05862
[72] GRPO: https://arxiv.org/pdf/2402.03300
[73] OpenAI RBR: https://openai.com/index/improving-model-safety-behavior-with-rule-based-rewards/
[74] Contrastive Search: https://arxiv.org/pdf/2202.06417
[75] Lookahead Decoding: https://arxiv.org/pdf/2402.02057
[76] Phi-4: https://arxiv.org/pdf/2412.08905
[77] DoLa: https://arxiv.org/abs/2309.03883
[78] Transformers: https://huggingface.co/docs/transformers/index
[79] Prompt Engineering Guide: https://www.promptingguide.ai/
[80] OpenAI Prompt: https://help.openai.com/en/articles/6654000-best-practices-for-prompt-engineering-with-the-openai-api
[81] OpenAI Prompt: https://platform.openai.com/docs/guides/prompt-engineering/six-strategies-for-getting-better-results
[82] CoT: https://arxiv.org/pdf/2201.11903
[83] ToT: https://arxiv.org/pdf/2305.10601
[84] Auto-CoT: https://arxiv.org/pdf/2210.03493
[85] Self-Consistency with CoT: https://arxiv.org/pdf/2203.11171
[86] XoT: https://arxiv.org/pdf/2311.04254
[87] GoT: https://arxiv.org/pdf/2308.09687
[88] MoT: https://arxiv.org/pdf/2305.05181
[89] Multimodal CoT: https://arxiv.org/pdf/2302.00923
[90] VLM CoT: https://arxiv.org/pdf/2410.16198
[91] Zero-shot-CoT: https://arxiv.org/pdf/2205.11916
[92] langchain: https://python.langchain.com/docs/
[93] Contextual RAG: https://www.anthropic.com/news/contextual-retrieval
[94] RAGFlow: https://ragflow.io/
[95] TD: http://incompleteideas.net/papers/sutton-88-with-erratum.pdf
[96] HuggingFace PEFT: https://huggingface.co/docs/peft/index
[97] Byte Latent Transformer: https://arxiv.org/pdf/2412.09871
[98] OpenAI Scaling Law: https://arxiv.org/pdf/2001.08361
[99] DeepMind Chinchilla Scaling Law: https://arxiv.org/pdf/2203.15556
[100] OpenAI o1 Scaling Law: https://openai.com/index/learning-to-reason-with-llms/
[101] VLMEvalKit: https://github.com/open-compass/VLMEvalKit
[102] opencompass: https://github.com/open-compass/opencompass
[103] ollama: https://github.com/ollama/ollama
[104] mlc-llm: https://github.com/mlc-ai/mlc-llm
[105] llama.cpp: https://github.com/ggerganov/llama.cpp
[106] text-generation-inference: https://github.com/huggingface/text-generation-inference
[107] langgraph: https://github.com/langchain-ai/langgraph
[108] Qwen2.5: https://arxiv.org/pdf/2412.15115
[109] DQN: https://arxiv.org/pdf/1312.5602
[110] Q-learning: https://www.cs.rhul.ac.uk/~chrisw/new_thesis.pdf
[111] Policy Gradient&REINFORCE: http://people.cs.umass.edu/~barto/courses/cs687/williams92simple.pdf
[112] Policy Gradient Theorem: https://proceedings.neurips.cc/paper_files/paper/1999/file/464d828b85b0bed98e80ade0a5c43b0f-Paper.pdf
[113] HuggingFace: https://huggingface.co/
[114] Diverse Beam Search: https://arxiv.org/pdf/1610.02424
[115] Constrained Beam Search: https://arxiv.org/pdf/1612.00576
[116] Top-P: https://arxiv.org/pdf/1904.09751
[117] Top-K: https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
[118] Speculative Sampling: https://arxiv.org/pdf/2302.01318
[119] UCB: https://homes.di.unimi.it/~cesabian/Pubblicazioni/ml-02.pdf
[120] Rainbow: https://arxiv.org/pdf/1710.02298
[121] Prioritized Experience Replay: https://arxiv.org/pdf/1511.05952
[122] Dueling DQN: https://arxiv.org/pdf/1511.06581
[123] Double DQN: https://arxiv.org/pdf/1509.06461
[124] DQN + Target Network: https://web.stanford.edu/class/psych209/Readings/MnihEtAlHassibis15NatureControlDeepRL.pdf
[125] POSG: https://www.khoury.northeastern.edu/home/camato/publications/aaai-SS-04.pdf
[126] IQL: http://web.media.mit.edu/~cyinthiab/Readings/tan-MAS-reinfLlearn.pdf
[127] BC: https://proceedings.neurips.cc/paper/1988/file/812b4ba287f5ee0bc9d43bbf5bbe87fb-Paper.pdf
[128] GAIL: https://arxiv.org/pdf/1606.03476
[129] MCTS: https://www.davidsilver.uk/wp-content/uploads/2020/03/pomcp.pdf
[131] Distributional RL: https://arxiv.org/pdf/1707.06887
[132] Chatbot Arena: https://www.lmarena.ai/
[133] Teacher Forcing: https://gwern.net/doc/ai/nn/rnn/1989-williams-2.pdf
[134] GPT-1: https://cdn.openai.com/research-covers/language-understanding-unsupervised-language_understanding_paper.pdf
[135] Attention Is All You Need: https://arxiv.org/pdf/1706.03762
[136] Ilya Sutskever, seq2seq, LSTM: https://arxiv.org/pdf/1409.3215
[137] MoE, Switch Transformers: https://arxiv.org/pdf/2101.03961
[138] RoPE, 苏剑林: https://arxiv.org/pdf/2104.09864
[139] ResNet, 何恺明: https://arxiv.org/pdf/1512.03385
[140] DriveVLM, 清华, 理想汽车: https://arxiv.org/pdf/2402.12289
[141] ELMo: https://arxiv.org/pdf/1802.05365
[142] Generative Verifiers: https://arxiv.org/pdf/2408.15240
[143] rStar: https://arxiv.org/pdf/2408.06195
[144] Scaling LLM Test-Time Compute: https://arxiv.org/pdf/2408.03314v1
[145] LoRA: https://github.com/microsoft/LoRA
[146] GPT-3: https://arxiv.org/pdf/2005.14165
[147] RAG: https://arxiv.org/pdf/2005.11401
[148] Richard S. Sutton: http://incompleteideas.net/
[149] The Bitter Lesson: http://incompleteideas.net/IncIdeas/BitterLesson.html
[150] Yarn: https://arxiv.org/pdf/2309.00071
[151] Qwen2.5: https://arxiv.org/pdf/2412.15115
[152] DeepSeek-V3: https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf
[153] Speculative Decoding: https://arxiv.org/pdf/2211.17192
[154] MCTS: https://inria.hal.science/inria-00116992/document
[155] UCT: http://ggp.stanford.edu/readings/uct.pdf
[156] AlphaGo: https://www.davidsilver.uk/wp-content/uploads/2020/03/unformatted_final_mastering_go.pdf
[157] About BoN: https://arxiv.org/pdf/2009.01325
[158] BOND: https://arxiv.org/pdf/2407.14622
[159] DVTS: https://huggingface.co/spaces/HuggingFaceH4/blogpost-scaling-test-time-compute
[160] A Survey on KD of LLM: https://arxiv.org/pdf/2402.13116
[161] Investigating Mysteries of CoT-Augmented Distillation: https://arxiv.org/pdf/2406.14511
[162] TTT: https://ekinakyurek.github.io/papers/ttt.pdf
[163] RESET: https://arxiv.org/pdf/2409.14586
[164] OpenAI, Let's Verify Step by Step: https://arxiv.org/pdf/2305.20050
[165] DeepMind, Google, OmegaPRM: https://arxiv.org/pdf/2406.06592
[166] DeepMind, PRM: https://arxiv.org/pdf/2211.14275
[167] Epoch AI, Will we run out of data: https://arxiv.org/pdf/2211.04325v2
[168] Epoch AI: https://epoch.ai/blog/will-we-run-out-of-data-limits-of-llm-scaling-based-on-human-generated-data
[169] A Survey on Data Synthesis and Augmentation: https://arxiv.org/pdf/2410.12896
[170] OLMo 2: https://arxiv.org/pdf/2501.00656
[171] TÜLU 3: https://arxiv.org/pdf/2411.15124
[172] ReFT: https://arxiv.org/pdf/2401.08967
[173] Reinforcement Fine-Tuning: https://openai.com/12-days/
[174] rStar-Math: https://arxiv.org/pdf/2501.04519
[175] A* search: https://ai.stanford.edu/~nilsson/OnlinePubs-Nils/PublishedPapers/astar.pdf
[176] Meta-CoT: https://arxiv.org/pdf/2501.04682
[177] Best-first: https://arxiv.org/pdf/2407.01476
[178] AlphaZero: https://arxiv.org/pdf/1712.01815
[179] AlphaGo Zero: https://discovery.ucl.ac.uk/id/eprint/10045895/1/agz_unformatted_nature.pdf
[180] Self-Rewarding: https://arxiv.org/pdf/2401.10020
[181] Meta, Meta-Rewarding: https://arxiv.org/pdf/2407.19594
[182] DeepMind, SCoRe: https://arxiv.org/pdf/2409.12917
[183] OpenAI , Deliberative Alignment: https://arxiv.org/pdf/2412.16339
[184] Distillation: https://arxiv.org/pdf/1503.02531
[185] DeepSeek-R1: https://arxiv.org/pdf/2501.12948
[186] Approximating KL Divergence: http://joschu.net/blog/kl-approx.html
[187] Li Fei-Fei, s1: https://arxiv.org/pdf/2501.19393
[188] BitNet b1.58: https://arxiv.org/pdf/2402.17764
[189] Unsloth: https://unsloth.ai/
[190] GRPO Trainer: https://huggingface.co/docs/trl/main/en/grpo_trainer

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 3
3 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)