EgoHumanoid:无机器人以自我为中心的演示解锁野外机器人运动操控
26年2月来自港大、上海创新研究院、北航和 Kinetix AI 公司的论文“EgoHumanoid: Unlocking In-the-Wild Loco-Manipulation with Robot-Free Egocentric Demonstration”。人类演示提供丰富的环境多样性和自然尺度,使其成为机器人远程操作的理想替代方案。虽然这种范式已经推动机器人手臂操作的发展,但其在更具挑
26年2月来自港大、上海创新研究院、北航和 Kinetix AI 公司的论文“EgoHumanoid: Unlocking In-the-Wild Loco-Manipulation with Robot-Free Egocentric Demonstration”。
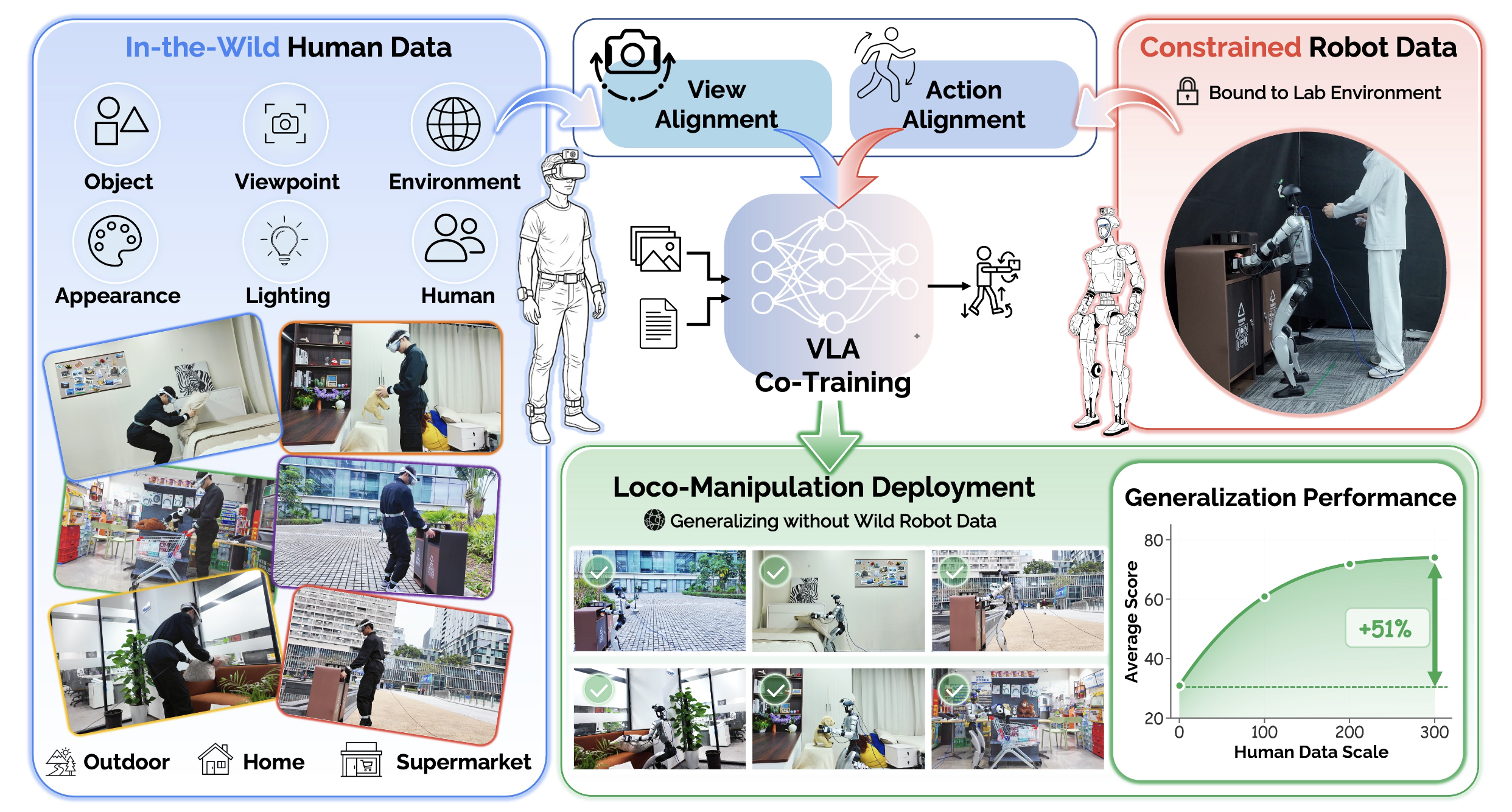
人类演示提供丰富的环境多样性和自然尺度,使其成为机器人远程操作的理想替代方案。虽然这种范式已经推动机器人手臂操作的发展,但其在更具挑战性、数据需求量更大的类人机器人移动操作问题上的潜力仍未得到充分挖掘。EGOHUMANOID,是首个利用大量以自我为中心的人类演示数据和少量机器人数据共同训练视觉-语言-动作策略的框架,使类人机器人能够在各种真实世界环境中执行移动操作。为了弥合人类和机器人之间的具身差异,包括物理形态和视角方面的差异,引入一个从硬件设计到数据处理的系统化对齐流程。其开发一个可扩展的人类数据采集便携系统,并建立实用的采集协议以提高数据的可迁移性。该人机对齐流程的核心是两个关键组件。视角对齐减少由相机高度和透视变化引起的视觉域差异。动作对齐将人类运动映射到一个统一的、运动学上可行的动作空间,用于人形机器人的控制。大量的真实世界实验表明,结合无机器人以自我为中心的数据,其性能比仅包含机器人的基线模型显著提升 51%,尤其是在未知环境中。
人形机器人在各种以人为中心的环境中展现出巨大的应用潜力,从家务协助到户外服务场景[23]。这些应用的核心在于其运动操控能力,这涉及到全身运动和灵巧操作的紧密协调[38, 54, 77]。与固定基座机械臂[31, 5, 70]不同,机器人必须在各种空间中导航,调整身体姿态以适应不同的操作范围,并操控物体,同时还要在非结构化环境中保持动态平衡。
尽管模型架构和控制算法取得快速进展,但由于缺乏多样化的大规模演示数据,人形机器人的运动操控学习仍然受到限制。现有方法[18, 3]主要依赖于机器人远程操作,虽然远程操作能够提供与机器人本体一致的监督,但存在成本高、操作复杂和硬件不稳定等问题[38, 25, 73]。此外,由于将人形机器人平台和远程操控设备(例如动作捕捉服)运送到各种真实场景(例如住宅、公园、商店、户外空间)通常不切实际[81, 74],因此该方法将数据采集限制在实验室环境中。
以自我为中心的人类数据在机器人中的应用
以自我为中心的人类数据,已成为机器人学习的一种极具潜力的数据源,它无需机器人硬件即可在各种环境中进行可扩展的数据采集。多种系统能够实现无机器人数据采集,包括带有摄像头的手持式机械臂[12, 80]、可穿戴眼镜[15]以及VR/AR头显,例如Apple Vision Pro、Meta Quest和PICO。此类数据已被以多种方式应用于具身人工智能。其中一项研究利用大规模以自我为中心的数据集[21, 22, 67, 39, 36, 76]训练视觉-语言模型,以增强场景理解和空间推理能力,并应用于具身问答[42]和以自我为中心的决策[62]等领域。对于机器人策略学习,以往的研究主要采用预训练后微调的范式,利用人类数据学习视觉表征[43, 41, 75]、运动先验[44, 82, 66, 71]或潜动作嵌入[68, 6, 27],并在预训练阶段舍弃动作信息。相比之下,协同训练利用人类和机器人演示中的动作作为监督信息,通过对齐的观察空间和动作空间,实现更有效的知识迁移[49, 30, 83, 72]。然而,现有的协同训练方法主要集中于固定平台的操作。
跨具身数据对齐
在机器人间迁移中,Mirage [8] 通过交叉绘制和图像修复技术重写图像中的机器人,从而减少视觉不匹配;而 Chen [9] 则使用生成模型来增强机器人的外观和视角。对于动作对齐,常用方法要么采用可迁移的任务空间或末端执行器控制接口 [8, 60, 53],要么将异构的状态-动作空间投影到共享的潜表示中 [59, 37, 13]。由于形态、视角和运动动力学方面存在较大差异,人-机迁移更具挑战性,但考虑到人类数据的规模,它仍然具有吸引力。UMI 系列 [12, 80, 63, 61] 使用手持硬件在采集时提供精确的全局位置信息,使人类演示与机器人兼容。另一项研究工作依赖于运动重定向,即将人体运动映射到机器人姿态[2, 65, 19],这通常用于训练底层人形机器人控制器[24, 11, 57]。一些同时进行操作或导航的研究也采用这种范式,通过从以自我为中心的人体视频中估计手部姿态,并与机器人数据进行联合训练[29, 83, 30, 72]。这些研究要么只关注操作,要么将移动机器人的这两个子任务解耦以防止基座偏移。
人形机器人运动操控
人形机器人运动操控将运动、操作以及任务规划相结合,其中可靠的执行和可扩展的监督仍然是挑战。受人形机器人全身控制[24, 1, 57, 48]的启发,新兴的研究工作利用强化学习构建运动操控技能,通常依赖于仿真中专门建模的对象、精心设计的奖励以及学习课程来处理基础运动和手臂-手部交互之间的强耦合[25, 77, 69, 78]。与此同时,最近的研究探索通过运动或语言条件生成来扩展监督,旨在降低新任务所需的高成本机器人远程操作的负担[17, 14, 64, 56]。此外,通过扩展模型,加入下肢机器人动作指令[27, 81, 46]或运动目标[40, 4, 16],也从操作方法中开发出了可变长度运动(VLA)策略。尽管取得了这些进展,但大多数流程仍然主要依赖于以机器人为中心的数据或受限的设置,缺乏环境多样性且数据采集过程繁琐,这阻碍对以人为中心场景中泛化能力的研究。
EGOHUMANOID
本文提出一种基于简单观察的替代方案:人类每天都会在机器人预期运行的环境中自然地执行移动操作任务。可穿戴传感技术的最新进展[15, 22, 50]使得使用轻便的便携式设备捕捉以自我为中心的人类演示成为可能,而无需任何机器人硬件。这种范式能够以可扩展的方式获取行为丰富且环境多样的数据,并推动了机器人操作和导航的进步[32, 29, 55, 83, 49, 30, 10]。
然而,由于根本性的具身认知差距,将以自我为中心的人类演示应用于人形机器人控制远非易事。人形机器人与人类在形态和运动学方面存在显著差异,包括肢体比例和关节活动范围[78, 65]。以自我为中心的视觉观察也存在差异——人类观察的是自己的双手和身体,而机器人则从不同的视角感知金属机械臂[12, 81]。此外,运动动力学也存在差异,因为人类的行走模式、身体摇摆和平衡策略无法直接应用于质量分布和驱动约束不同的机器人[49, 83]。总的来说,这些差异在移动操作中尤为显著,因为全身运动会放大视角变化,并在以自我为中心的观察中引入显著的运动变化。
为此本文提出EGOHUMANOID,一个用于人机协同训练的系统框架,如图所示。核心观点是,虽然底层动作具有具身性特征,但当观察和运动正确对齐时,高层行为结构(例如导航路线、目标接近策略和任务分解)可以可靠地迁移。此外,人类在各种真实场景中的演示能够展现出仅由机器人数据难以涵盖的各种变化,从而实现更强的野外泛化能力。因此,本文构建一个数据采集系统,用于采集无机器人的人类演示数据和远程操控的人形机器人数据。便携式的人类装置集成VR头显、用于姿态估计的身体追踪器和以自我为中心的摄像头,无需机器人硬件即可在各种场景下进行可扩展的数据采集。通过基于VR的远程操控采集的补充机器人数据,为操作密集型行为提供具身精确的监督。
问题设置
目标是训练一个VLA模型,使其能够在新的真实世界环境中完成移动操作任务。该策略基于组合数据集D = D = D_robot ∪ D_human进行训练。其中,D_robot包含在受限实验室环境中收集的远程操控机器人演示视频,而D_human包含在各种场景(例如家庭、商店和户外环境)中拍摄的以自我为中心的人类演示视频,这些视频记录了相同的任务。D中的每个数据片段都包含以自我为中心的视频和同步的全身动作。
训练完成后,该策略在两种设置下进行部署:(1)在与D_robot类似的实验室环境中进行域内评估;(2)在D_human涵盖但D_robot未涵盖的场景中进行泛化评估。这种设置直接测试人类数据是否能够使模型泛化到机器人远程操控可行场景之外的其他场景。
用中型(1.3米)Unitree G1人形机器人作为硬件平台,因为它在底层控制器方面具有稳健的性能和耐用性。同时,考虑到机器人的尺寸和自由度(配备三指Dex3灵巧手,拥有29个自由度),它与普通远程操作者在实体形态上存在巨大差距。与以往关于桌面双手操作的研究(机器人底座保持静止)不同,专注于需要全身协调的任务——机器人必须在执行操作的同时或先后移动到目标位置。这种对下肢移动性的基本要求将人形机器人的移动操作与固定底座操作区分开来,并促使研究人机交互转移。
数据采集系统
至关重要的是,机器人和人类在实用性和具身性方面存在差异。机器人数据采集通常需要昂贵的硬件、精心的设置,并且大多局限于实验室环境;而人类数据则可以使用可穿戴设备在各种场景下以低成本、灵活的方式采集。为了缩小数据采集层面的具身性和视觉差异,并支持人机协同训练,开发一种统一的便携式硬件装置,该装置基于虚拟现实(VR)系统,可在两种采集模式之间快速切换,如图所示: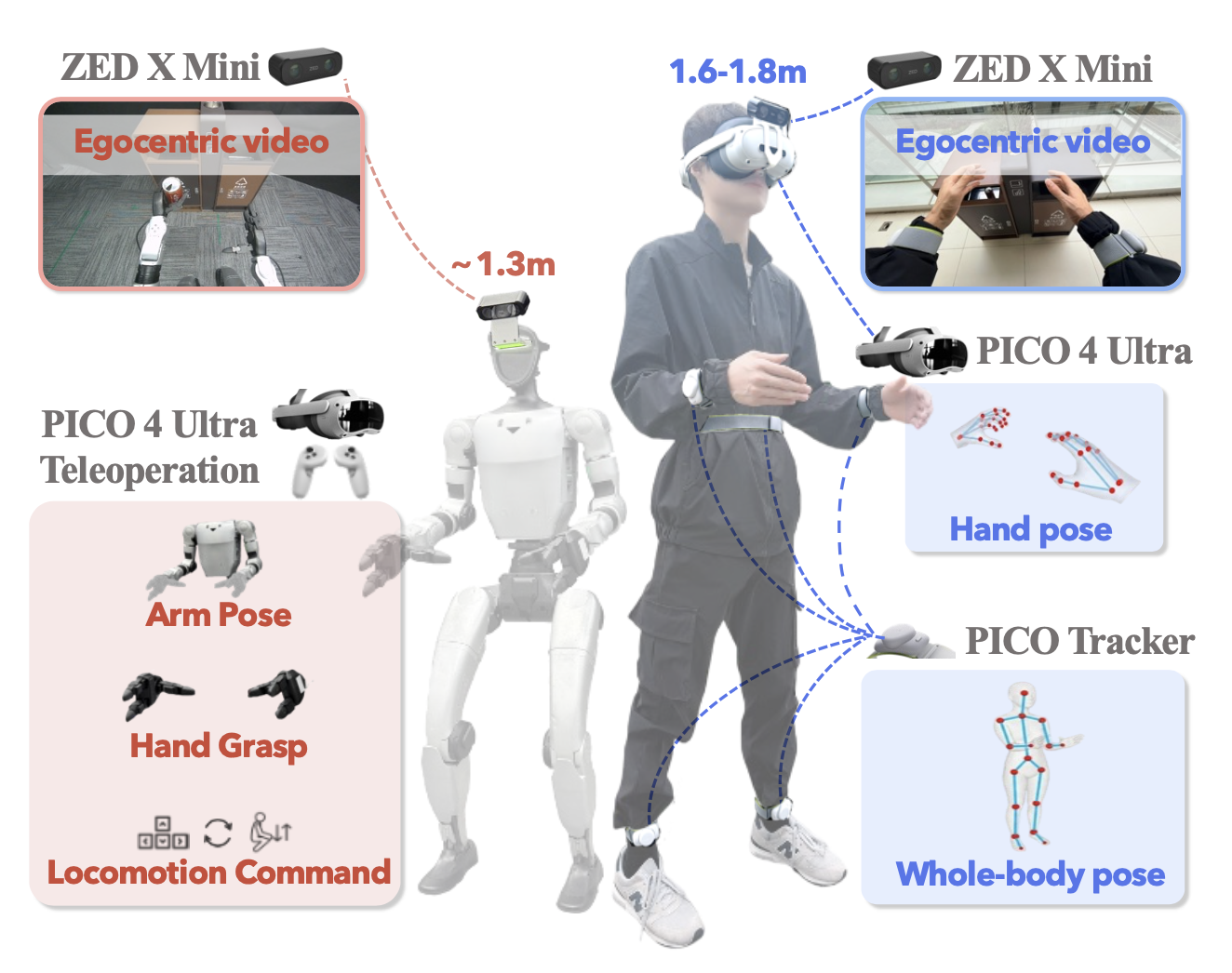
其特意放弃腕部摄像头,因为仅以自我为中心的设置更为通用,而且由于巨大的视差,腕部视角的优势并不确定,正如之前的研究 [30] 所示。人类演示的效率远高于机器人远程操作(约 2 倍)。
人类数据采集。用便携式 PICO VR 装置,该装置能够以低成本、不受限制的方式在室内和室外环境中记录人类演示。受试者佩戴带有五个 PICO 运动追踪器的头戴式设备,同时头戴式 ZED X Mini 摄像头拍摄同步的以自我为中心的 RGB 图像。用 PICO SDK [79] 实时记录全身人体运动,包括 24 个身体关键点和详细的手部姿态(每只手 26 个关键点)。
机器人数据采集。机器人演示数据通过基于 VR 的远程操作采集。操作员佩戴 PICO VR 头戴式设备,并使用手持控制器发出导航指令(前进/后退、横向移动、转弯、站立、下蹲)和基于控制器与头戴式设备相对姿态的腕部姿态指令。这些指令通过逆运动学转换为关节级动作,并在 Unitree G1 人形机器人上执行,同时控制器触发器控制 Dex3 灵巧手的抓取。底层运动策略 [45] 确保全身动作的稳定执行。用头戴式 ZED X Mini 相机记录导航指令、末端执行器的腕部姿态、手部抓握状态以及同步的以自我为中心的 RGB 图像。
人机对齐
为了将VR 设置捕获的人类演示转换为机器人兼容的训练数据,开发一个对齐流程,该流程包含两个主要模块:视图对齐和动作对齐。视图对齐用于解决不同相机视角造成的视觉域差异,动作对齐则用于解决形态差异造成的动作表征差异。该流程如图所示: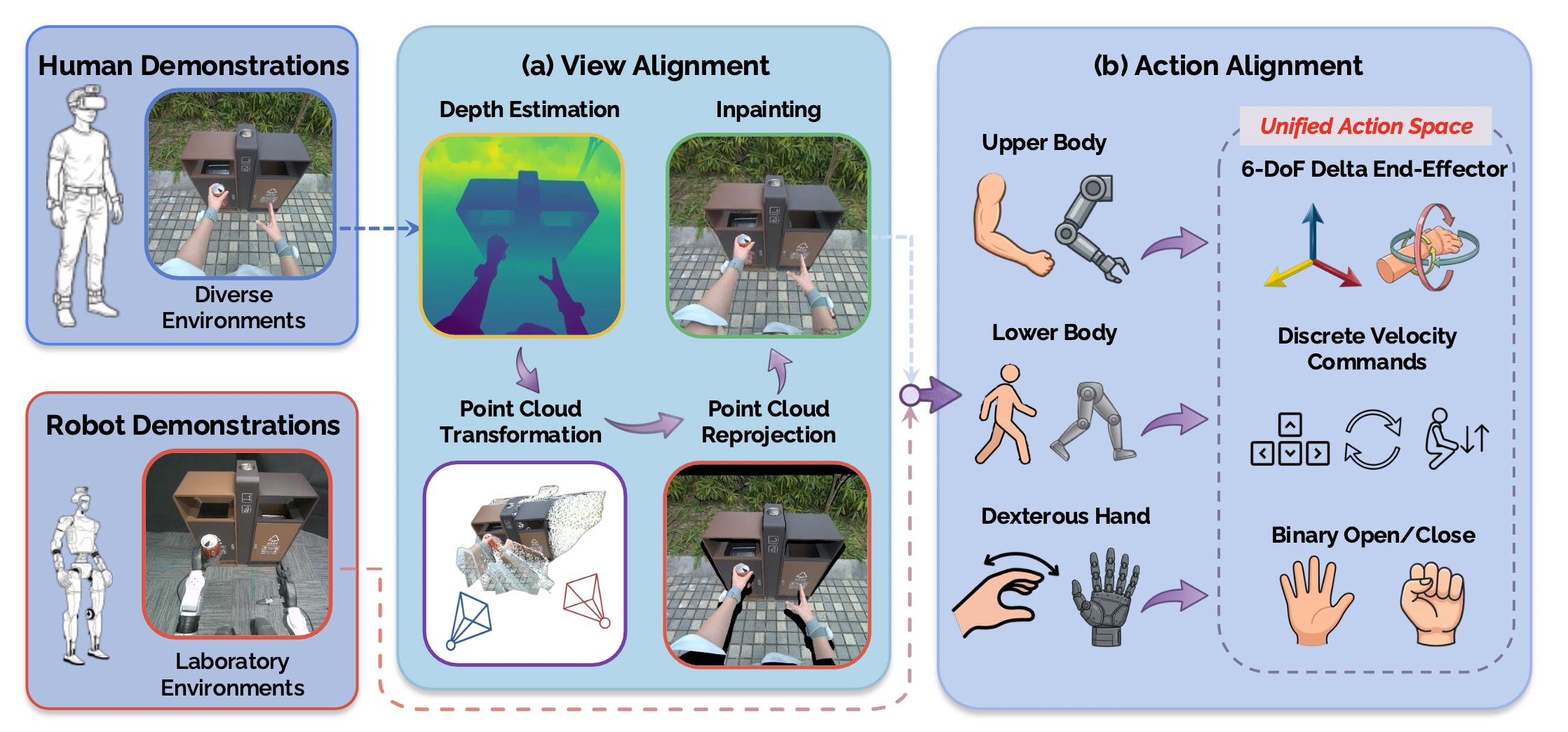
视图对齐。人类和人形机器人之间显著的身高差异导致以自我为中心的视觉观察结果存在明显差异。为了弥合这种视觉差异,通过一个三阶段流程将人类的以自我为中心的图像转换为近似于机器人相机视角的图像。首先,使用 MoGe [58] 通过其基于重投影的焦点/位移恢复来推断仿射不变的逐像素 3D 点图,并导出尺度不变的深度图。然后,将恢复的 3D 点变换到目标机器人相机坐标系,并将其投影到目标图像平面上。在训练过程中,对目标姿态施加随机扰动,以增强其对视角变化的鲁棒性。需要注意的是,由于 MoGe 的有效性掩码指示的无效 3D 预测以及姿态变化引入的视角相关遮挡,重投影可能会产生缺失区域,导致目标像素没有对应的源像素。因此,最后一步是利用基于潜扩散的图像修复 [51] 来重建缺失区域,并根据观察的上下文和缺失区域掩码进行条件化。在此过程中,生成完整的 RGB 图像,以便更好地模拟机器人以自我为中心的输入。
动作对齐。设计一个统一的动作空间,该空间既能容纳人类演示,又能兼顾二者的运动学差异。
上半身。动作参数化为6自由度(6-DoF)的末端执行器姿态增量,这与现有的跨具身研究[83, 30, 72, 71]一致。使用增量避免对全局对齐基坐标系的依赖,而全局基坐标系在人类和机器人的记录中可能定义不明确,从而实现了不同具身之间的直接比较。也避免关节级重定向[2],因为它可能会引入伪影并扰乱与交互相关的手-物体几何关系[65]。具体来说,将人类腕部姿态表示在以骨盆为中心的坐标系中,然后使用Savitzky-Golay滤波器[52]平滑平移。对于旋转,用log/exp映射在SO(3)切空间中进行滤波,以避免四元数的插值歧义。最后,将变换后的数据从 100 Hz 下采样到 20 Hz,以匹配机器人控制,并将连续帧之间的位姿增量作为动作输出。
下半身。为了采集机器人数据,操作员通过虚拟现实(VR)装置,使用一组离散的恒速基本动作(例如,前进/后退、左转/右转、左转/右转、站立/下蹲)发出导航指令,这遵循人形机器人运动操作的常用方法[3, 27]。为了使人类演示与机器人动作空间对齐,将人类骨盆轨迹转换为相同的离散指令。具体而言,应用Savitzky-Golay平滑来抑制抖动,然后通过中心差分估计瞬时航向,并施加连续性约束以防止方向翻转。将世界坐标系中的位移投影到局部坐标系中,以获得前进速度和侧向速度。偏航率由帧间航向变化计算得出。通过在每个控制窗口内取平均值,将这些连续指令下采样到20Hz,并将其量化为离散的水平运动区间。最后,通过对骨盆高度的帧间变化进行阈值处理,得到一个离散的站立/蹲伏基元,与机器人远程操作界面相匹配。
夹爪。将夹爪动作表示为一个二元变量 a_t = {0, 1},其中 1 表示夹爪闭合,0 表示夹爪张开。在机器人数据采集过程中,远程操作员通过手持控制器控制夹爪,并记录生成的二元命令序列 {a_t}。用 VR 系统捕捉人类演示,该系统可以追踪每只手的 26 个关节。为了稳健地推断手部抓握状态,首先对原始关节轨迹应用低通滤波,然后进行 Savitzky-Golay 平滑。接着,计算手指级曲率 κ_f,其定义为拟合到每个手指关节折线的二次多项式中点处的曲率。通过对所有手指的 κ_f 取平均值,并对所得标量 κ̄ 进行阈值处理,即可得到手部抓取状态,生成二元开/闭标签。这种基于曲率的表示方法能够降低噪声,并可从人类演示中可靠地提取监督信息。类似地,所有人类信号均被下采样至 20 Hz,以在时间上与机器人数据对齐。
运动-操作策略协同训练
由于采用对齐方法,人类和机器人演示具有相同的视觉观察格式和动作维度,因此对同一策略进行协同训练。具体而言,通过微调,将最先进的 VLA 模型 π0.5 [26] 应用于类人机器人的动作操作。该策略以自我中心的 RGB 观察结果和语言指令作为输入,并输出统一动作空间中的动作。有意省略本体感觉状态,因为人类和类人机器人之间的形态差异会导致本体感觉分布不兼容,从而干扰协同训练。
多源数据采样。在这种情况下,人类演示数据的数量可能远大于机器人数据,且种类也更加多样化,从而造成数据集高度不平衡。先前的研究表明,平衡采样对于机器人操作中不平衡的多源训练至关重要[20, 28]。同时,移动操作任务既需要高级导航或运动,也需要复杂的操作,而人类和机器人数据在这些方面可能各具优势。因此,检查每个小批量中人类与机器人的采样比例,以确保有足够的机器人演示数据。
真实世界实验装置
设计四项需要运动和操作之间紧密协调的运动操作任务,如图所示。所有任务都涉及非平凡的运动(1-5 米),这与固定基座的双手操作有所区别。导航精度会影响操作的成功:次优的停止位置会导致后续操作无法进行。不同试验中停止位置的差异进一步要求策略能够泛化到不同的视角和物体配置。
这四项任务分别是:(1)枕头放置。机器人将枕头搬运到床上并放置在目标位置。这项任务测试了机器人搬运笨重物体时的稳定运动能力以及在可变形表面上的放置能力。(2)垃圾处理。机器人将垃圾(揉成一团的纸或罐头)搬运到带盖的垃圾桶中,并将其水平放入桶口而不是从上方掉落,这需要精确的定位和末端执行器控制。(3)玩具转移。机器人接近平面上的玩具,抓住它,调整方向,走到远处的桌子旁,并将玩具放下。此任务评估机器人在接近、抓取、手持移动和放置玩具这四个步骤中的顺序协调能力。(4) 推车存放。机器人将推车推到产品展示区,抓取玩具,将其放入推车,然后将推车推走。此任务涉及移动过程中的持续接触和多阶段操作。
在每个设置下进行 20 次试验,每次试验均包含位置扰动,并采用归一化分数来评估每次试验的表现。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献229条内容
已为社区贡献229条内容

所有评论(0)