什么是幻觉?大模型为什么会“一本正经地胡说八道“?
幻觉不是程序的 bug,而是模型工作方式带来的副作用。大模型为什么会"一本正经地胡说八道"?如果让你设计一个"防幻觉"的AI系统,你会怎么做?为什么大模型有时候会"一本正经地胡说八道"?大模型没有"真假"的概念,只有"概率"的概念。问题来了:它不是在"查资料",而是在"创作"4.1 根本原因:大模型不知道什么是"真"大家先思考思考,欢迎在评论区说说你的想法!3.3 幻觉不是"Bug",是"特性"提
什么是幻觉?大模型为什么会"一本正经地胡说八道"?
目录:
-
前文回顾 -
背景引入:AI 咋也会"骗人"? -
核心概念一:什么是幻觉 -
核心概念二:幻觉是怎么产生的 -
核心概念三:幻觉的类型 -
核心概念四:幻觉和撒谎的区别 -
核心概念五:如何减轻幻觉 -
幻觉的"正面"作用 -
本文小结 -
今日思考题
一、前文回顾
在前面几篇文章中,咱们聊了:
-
大模型的"思考"原理是 预测下一个词 -
训练过程是 从海量数据中学习模式 -
分词器把文本变成 Token 和词向量
但是!有一个问题咱们一直没深入讲:
为什么大模型有时候会"一本正经地胡说八道"?
比如:
你:"鲁迅写过哪首《咏梅》?"
AI:"鲁迅的《咏梅》写于1932年,是一首著名的现代诗,
全诗如下:风雨送春归,飞雪迎春到..."
(其实这首诗是毛泽东写的)
这种自信满满但完全错误的现象,就是今天要讲的主题——幻觉(Hallucination)。
二、背景引入:AI 咋也会"骗人"?
先来听几个真实的例子:
案例一:编造不存在的论文
用户:"给我找几篇关于深度学习的论文"
AI:"推荐以下几篇:
1. 'Deep Learning for NLP' by Zhang et al., 2022
2. 'Attention Mechanisms in CNN' by Li & Wang, 2023
..."
(这些论文标题听起来很专业,作者也像那么回事,
但事实上根本不存在!)
案例二:虚构历史事件
用户:"讲讲明朝的万历年间发生了什么"
AI:"万历年间,明朝发生了一件著名的事件:
'万历三十八年,利玛窦在北京开设了第一家西餐厅'..."
(完全是编造的!)
案例三:代码里的"幻觉"
用户:"Python 里怎么把列表转成字符串?"
AI:"可以使用 list_to_string() 函数:
result = list_to_string(my_list)"
(Python 里根本没有这个函数!)
这些例子有一个共同特点:说得跟真的一样,但全是错的。
这就是大模型的幻觉。
三、核心概念一:什么是幻觉
3.1 幻觉的定义
幻觉(Hallucination)是指:
大模型生成的看似合理、流畅、自信,但事实上不正确或不存在的内容。
3.2 关键特征
大模型产生的幻觉有三个明显特征:
| 特征 | 说明 | 例子 |
|---|---|---|
| 看似合理 | 符合语言习惯和逻辑 | "Python的list_to_string()函数"听起来像真有 |
| 流畅自然 | 语法正确、表达连贯 | 文本读起来很顺畅 |
| 自信满满 | 语气确定、没有犹豫 | "确实是"、"毫无疑问" |
| 内容错误 | 事实不存在或不准确 | 但其实根本没有这个函数 |
这种"自信的错误"最具有迷惑性。
3.3 幻觉不是"Bug",是"特性"
这句话可能听起来很奇怪,但:
幻觉不是程序的 bug,而是模型工作方式带来的副作用。
为什么这么说?咱们接着往下看。
四、核心概念二:幻觉是怎么产生的
这是本文的核心!咱们要深入理解幻觉产生的根本原因。
4.1 根本原因:大模型不知道什么是"真"
首先,一个关键的认识:
大模型没有"真假"的概念,只有"概率"的概念。
咱们来回忆一下大模型是怎么工作的:
输入:"鲁迅写过哪首《咏梅》?"
大模型的思考过程:
1. 理解问题:鲁迅、《咏梅》、诗歌
2. 搜索模式:训练数据中关于鲁迅、咏梅、诗歌的模式
3. 预测下一个词:根据概率预测
"鲁迅" → "的" → "《咏梅》" → "是" → "一首" → ...
4. 生成回答:"鲁迅的《咏梅》写于..."
问题来了:它不是在"查资料",而是在"创作"!
4.2 详细分析:幻觉的产生过程
咱们用一个具体的例子来分析:
用户:"谁发明了电灯?"
正确的知识:爱迪生
大模型的预测过程:
Step 1:理解输入
"谁"(疑问词)
"发明"(动作)
"了"(助词)
"电灯"(物品)
"?"(标点)
Step 2:在训练数据中找模式
大模型的参数里"记住"了训练数据中的模式:
模式1:"谁发明了X" → 回答一个人名
模式2:"电灯"经常和"爱迪生"一起出现
模式3:发明X的句式是"X发明了..."
Step 3:根据概率预测
可能的下一个词:
"爱迪生" → 概率 85%
"特斯拉" → 概率 5%
"富兰克林" → 概率 3%
...
Step 4:生成回答
"爱迪生"(正确!)
但是!如果训练数据中有噪声,或者模式被混淆了:
用户:"鲁迅写过《咏梅》吗?"
大模型的预测:
1. "鲁迅" → 经常和"诗歌"、"文章"一起出现
2. "咏梅" → 经常和"毛泽东"、"诗词"一起出现
3. 这两个概念在训练数据中都很多
4. 模型可能"混淆"了
5. 预测出:"鲁迅的《咏梅》..."(错误!)
幻觉 = 模式混淆 + 概率预测。
4.3 产生幻觉的几个主要原因
| 原因 | 说明 | 例子 |
|---|---|---|
| 训练数据有误 | 错误的信息被学习了 | 网上有人误传,模型学到了 |
| 模式混淆 | 不同概念的模式混在一起 | 鲁迅和毛泽东的诗词混淆 |
| 知识缺失 | 训练数据中没有这个知识 | 编造不存在的论文 |
| 过度生成 | 模型喜欢"创造性"地生成 | 虚构历史事件 |
| 上下文误解 | 误解了用户意图 | 答非所问但很自信 |
五、核心概念三:幻觉的类型
幻觉不是只有一种,咱们来分类讲讲。
5.1 按内容分类
类型一:事实性幻觉
编造不存在的事实。
例子:
"李白的《静夜思》写于1998年"
(时间完全错误)
"爱因斯坦发明了电灯泡"
(人物错误)
类型二:逻辑性幻觉
推理过程有漏洞。
例子:
"所有鸟都会飞,企鹅是鸟,所以企鹅会飞"
(前提就错了)
"如果今天下雨,我就不带伞。今天下雨了,
所以我带了一把大伞"
(逻辑矛盾)
类型三:数值性幻觉
数字算错或编造。
例子:
"123 × 456 = 56088"
(正确答案是 56088,但模型可能算成其他数)
"地球的周长是 10000 公里"
(错误,实际约 40000 公里)
类型四:引用性幻觉
编造文献、链接、来源。
例子:
"根据《自然》杂志2023年的一项研究..."
(根本没有这项研究)
"更多信息请访问 https://example-ai-research.com/paper"
(这个网站根本不存在)
5.2 按意识程度分类
类型一:无意识幻觉
模型真的不知道自己在胡说。
模型:基于概率预测,认为是对的
实际上:完全错误
这是最常见的幻觉类型。
类型二:有意识"幻觉"
模型**知道不确定,但还是生成**。
用户:"具体的数据是多少?"
模型(内心):我不太确定...
模型(输出):"根据数据显示,大约是 76.3%"
(为了"回答"问题而编造)
六、核心概念四:幻觉和撒谎的区别
这个问题很关键!
6.1 什么是撒谎?
**撒谎需要"故意"和"知道真相"**。
撒谎的要素:
1. 知道真相
2. 故意说假话
3. 有欺骗的意图
6.2 大模型会撒谎吗?
不会!
因为:
| 撒谎需要的条件 | 大模型是否有 |
|---|---|
| 知道真相 | ❌ 没有真假概念 |
| 故意行为 | ❌ 只是根据概率生成 |
| 欺骗意图 | ❌ 没有意识和意图 |
幻觉 ≠ 撒谎。
6.3 对比表格
| 对比项 | 幻觉 | 撒谎 |
|---|---|---|
| 本质 | 模式混淆、概率预测 | 故意欺骗 |
| 是否知道真相 | 不知道(没有真假概念) | 知道 |
| 是否有意图 | 无 | 有 |
| 是否可避免 | 可以减轻,难完全避免 | 可以选择不说 |
| 例子 | 把鲁迅的诗说成毛泽东的 | 明知道答案但故意说错 |
七、核心概念五:如何减轻幻觉
虽然幻觉很难完全避免,但可以减轻。
7.1 从模型角度
方法一:提高训练数据质量
清洗训练数据:
- 去除错误信息
- 标注可靠来源
- 增加高质量数据
方法二:加入检索能力(RAG)
RAG = Retrieval-Augmented Generation(检索增强生成)
不是只靠模型记忆,而是:
1. 先去检索可靠资料
2. 基于检索到的资料回答
咱们用一张图来感受一下:
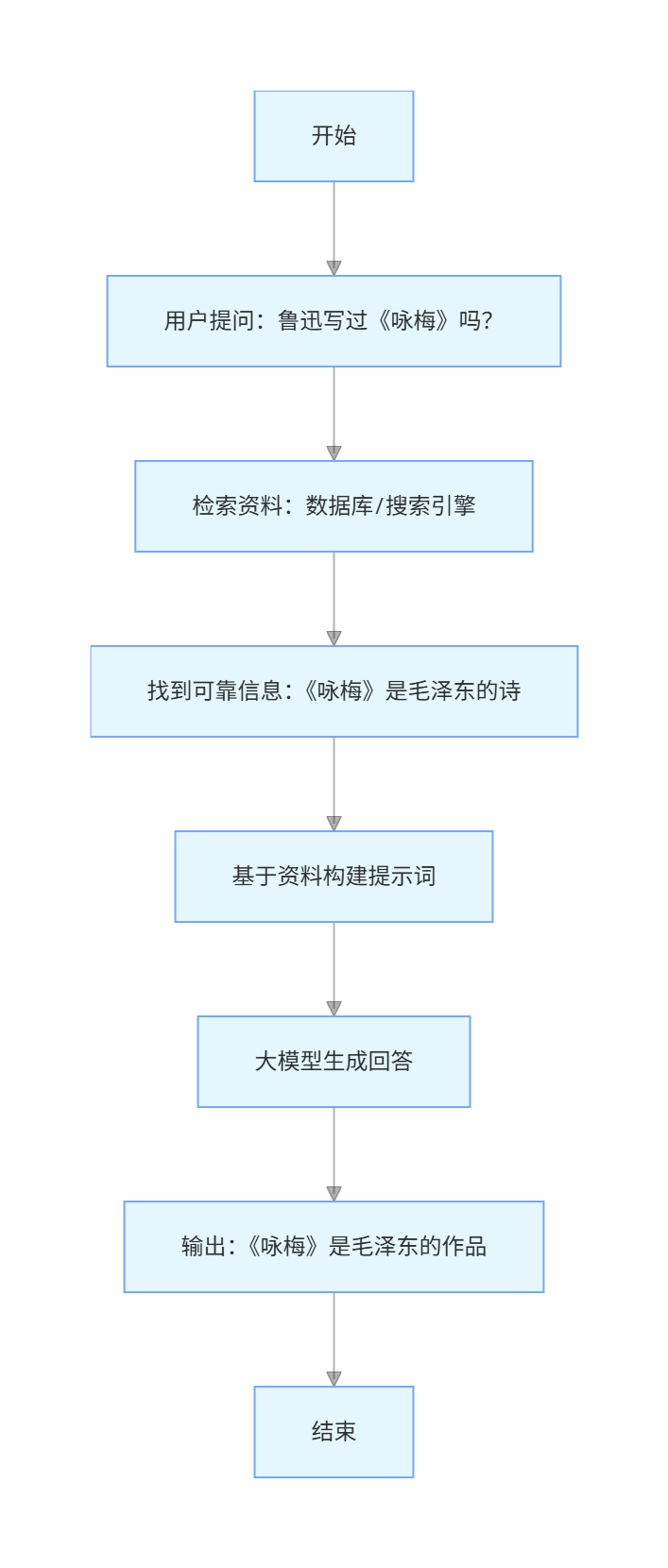
有了外部知识源,幻觉大大减少。
方法三:调整训练目标
让模型学会表达不确定性:
没有调整:
"鲁迅写过《咏梅》,这首诗写于..."
经过调整:
"我不太确定鲁迅是否写过《咏梅》。
根据《咏梅》这首词的记载,它是毛泽东的作品。
训练数据中没有找到鲁迅写过《咏梅》的记录。"
7.2 从用户角度
技巧一:明确要求来源
❌:"告诉我关于XX的事实"
✅:"告诉我关于XX的事实,并给出来源"
技巧二:提供上下文
❌:"总结这篇文章"
✅:"根据以下内容总结:[文章内容]"
技巧三:要求验证
❌:"这个信息对吗?"
✅:"请验证这个信息,并告诉我你是如何验证的"
技巧四:分步确认
❌:"写一段关于XX的历史"
✅:
"XX是真实存在的历史人物吗?"
"如果存在,他的主要成就是什么?"
"请基于可靠来源提供这些信息"
7.3 从应用角度
| 方法 | 说明 |
|---|---|
| 事实核查 | 输出后用其他工具验证 |
| 置信度标记 | 标出模型不确定的部分 |
| 多模型验证 | 用多个模型交叉验证 |
| 人工审核 | 重要内容必须有人工审核 |
八、幻觉的"正面"作用
说到这里,大家可能觉得幻觉完全是个坏事。
但!幻觉也有它的"正面"作用。
8.1 创造性任务的"幻觉"
在创意写作中,"幻觉"就是创造力:
用户:"写一个科幻故事,关于人类第一次接触外星人"
AI生成的"幻觉":
- 虚构的外星文明
- 不存在的科技
- 想象的对话和情节
这些在现实世界中"不存在",但在故事中很合理。
这种"幻觉" = 创造力。
8.2 头脑风暴的"幻觉"
在头脑风暴中,模型可以提出"不切实际"的想法:
问题:"如何解决交通拥堵"
AI的"幻觉"建议:
- 给每辆车装翅膀
- 建立地下管道网络
- 开发瞬间传送技术
虽然不现实,但可能启发真正的创新思路。
这种"幻觉" = 突破思维定式。
8.3 总结:幻觉的两面性
| 场景 | 幻觉的作用 | 好坏 |
|---|---|---|
| 事实查询 | 编造错误信息 | ❌ 坏 |
| 创意写作 | 创造新内容 | ✅ 好 |
| 科学研究 | 虚假数据 | ❌ 坏 |
| 头脑风暴 | 新奇想法 | ✅ 好 |
| 编程 | 不存在的函数 | ❌ 坏 |
| 艺术创作 | 创新表达 | ✅ 好 |
**关键在于:你用什么场景,需要什么样的输出**。
九、本文小结
咱们今天主要讲了以下几点:
1. 什么是幻觉
-
大模型生成的看似合理但实际错误的内容 -
有三个特征:合理、流畅、自信但错误
2. 幻觉是怎么产生的
-
根本原因:大模型没有真假概念,只有概率概念 -
产生过程:模式混淆 + 概率预测 -
主要原因:数据错误、模式混淆、知识缺失等
3. 幻觉的类型
-
按内容:事实性、逻辑性、数值性、引用性 -
按意识:无意识幻觉、有意识"幻觉"
4. 幻觉 vs 撒谎
-
幻觉:无意图、无真假概念 -
撒谎:有意图、知道真相 -
大模型不会撒谎,只会产生幻觉
5. 如何减轻幻觉
-
模型侧:提高数据质量、加入RAG、调整训练目标 -
用户侧:要求来源、提供上下文、要求验证 -
应用侧:事实核查、置信度标记、人工审核
6. 幻觉的两面性
-
坏事:事实查询、科学研究、编程 -
好事:创意写作、头脑风暴、艺术创作
十、今日思考题
今天留一个思考题:
如果让你设计一个"防幻觉"的AI系统,你会怎么做?
提示:从数据、模型、应用三个层面思考。
大家先思考思考,欢迎在评论区说说你的想法!
如果这篇文章对你有帮助,欢迎点赞关注,我会持续用大白话讲解复杂的技术概念!
系列文章进度:
-
✅ 微调 -
✅ Transformer -
✅ 思考原理 -
✅ 训练流程 -
✅ Token -
✅ 幻觉(本文)
下一期预告: 什么是提示词工程?如何写出更好的提示词?
本文由 mdnice 多平台发布

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)