RAG系统评估全指南:从三元组框架到实操落地
摘要: 检索增强生成(RAG)技术已成为企业级AI应用的核心方案,但其落地效果依赖科学评估。本文提出基于RAG三元组的评估框架,从上下文相关性(检索质量)、忠实度(生成可靠性)、答案相关性(用户价值)三个维度构建全链路评估体系。通过分层评估(检索评估聚焦精确率/召回率等指标,响应评估量化端到端表现)精准定位问题根源,如检索噪声或生成幻觉。该框架为开发者提供标准化评估方法,确保RAG系统在金融、医疗
在大语言模型(LLM)驱动的智能应用浪潮中,检索增强生成(RAG)技术凭借缓解模型幻觉、适配私有知识库、支持动态信息更新三大核心优势,已成为企业级AI应用落地的标配方案,广泛应用于智能客服、企业知识库、金融研报分析、医疗文献解读等关键领域。然而,RAG系统的落地效果参差不齐,多数团队在开发过程中都会陷入一个核心困境:如何科学、量化地评估系统表现?
不同于传统软件的功能测试,RAG系统的评估需贯穿“检索-生成-用户体验”全链路,既要关注技术指标的合理性,也要兼顾业务场景的适配性。一套完善的评估体系不仅能帮助开发者精准定位问题根源(是检索漏检关键信息,还是生成环节过度发散),更能为系统迭代提供明确方向,同时为决策者提供客观的价值判断依据。本文将围绕业界公认的RAG三元组(RAG Triad)核心框架,系统拆解RAG评估的理念、维度、工作流程与实操方法,助力开发者实现RAG系统的高质量落地。
第一节:评估介绍
构建RAG系统后,下一个关键问题是:如何科学地评估其表现?
评估之所以成为RAG开发全流程中的“关键一环”,核心在于它能精准回应开发与应用中的两大核心诉求,为RAG系统的价值验证提供量化支撑:
- **对于开发者:**如何量化地追踪、迭代并提升RAG应用的性能?当系统出现“幻觉”或答非所问时,如何快速定位问题根源(是检索环节的问题,还是生成环节的缺陷)?
- **对于用户或决策者:**面对两个不同的RAG应用,如何客观地评判孰优孰劣?如何判断系统是否满足业务场景的核心需求(如金融场景的信息准确性、客服场景的响应效率)?
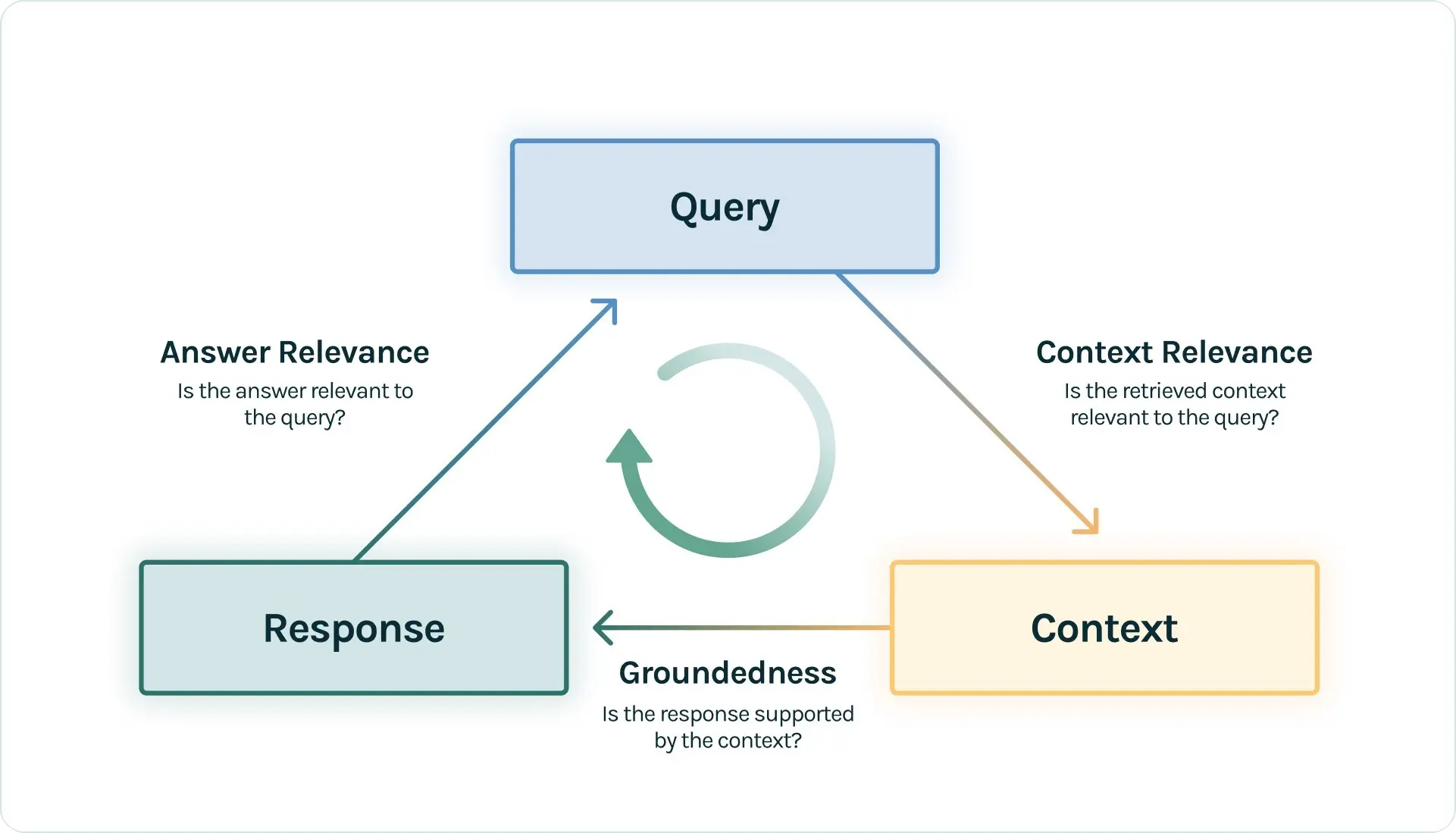
本节将聚焦RAG评估的核心理念与方法,围绕“RAG三元组(RAG Triad)”这一核心框架展开深入解析。该框架从“检索质量、生成可靠性、用户价值”三个关键维度构建了RAG系统的评估体系,已被TruLens、LangSmith等主流RAG开发工具深度集成,成为业界评估RAG系统的标准范式。
一、RAG评估三元组:全链路评估的核心维度
RAG三元组框架的核心逻辑的是:RAG系统的最终性能由检索器获取有效信息的能力,生成器基于信息创作的可靠性,最终输出对用户需求的满足度三个环节共同决定。只有对这三个维度进行全面评估,才能实现对RAG系统的完整认知。该架构已在TruLens等专业评估工具中得到深入应用,为开发者提供了标准化的评估基准。
1. 上下文相关性 (Context Relevance)
- 评估目标: 聚焦RAG系统的“检索器(Retriever)”模块,核心衡量检索器从知识库中筛选与用户查询(Query)高度相关信息的能力。
- 核心问题: 检索到的上下文内容,是否与用户的查询(Query)高度相关?是否包含回答用户问题所需的关键信息?是否存在大量无关的噪声信息?
- 重要性: 检索是RAG应用响应用户查询的“第一步”,也是后续生成环节的基础。在实际落地场景中,约60%的RAG系统失效问题源于检索环节——如果检索回来的上下文充满噪声或无关信息,那么无论后续的生成模型多么强大,都无法生成符合需求的正确答案。例如,在企业知识库场景中,用户查询“2025年公司年假政策”,若检索器返回2023年的政策文档或其他无关的考勤制度,后续生成的答案必然偏离用户需求。
2. 忠实度 / 可信度 (Faithfulness / Groundedness)
- 评估目标: 聚焦RAG系统的“生成器(Generator)”模块,核心衡量生成答案与检索上下文的一致性,本质是量化LLM的“幻觉”程度。
- 核心问题: 生成的答案是否完全基于所提供的上下文信息?答案中的每一个事实、数据或观点,是否都能在上下文中找到明确依据?
- 重要性: 忠实度是RAG系统可靠性的核心保障,尤其在金融、医疗、法律等对信息准确性要求极高的领域,低忠实度可能引发严重的业务风险。一个高忠实度的回答意味着模型严格遵守了上下文,没有捏造或歪曲事实;如果忠实度得分低,说明LLM在回答时“自由发挥”过度,引入了外部知识或不实信息。例如,在医疗文献解读场景中,上下文仅提及“某药物可缓解感冒症状”,但生成答案却声称“该药物可治愈感冒”,这就是典型的忠实度缺失,可能误导用户。
3. 答案相关性 (Answer Relevance)
- 评估目标: 衡量RAG系统的端到端(End-to-End)表现,核心聚焦最终生成答案与用户原始查询的适配程度。
- 核心问题: 最终生成的答案是否直接、完整且有效地回答了用户的原始问题?是否存在答非所问、信息冗余或关键信息缺失的情况?
- 重要性: 这是用户最直观的体验维度,也是RAG系统价值的最终体现。需要注意的是,高忠实度不等于高相关性——一个答案可能完全基于上下文(高忠实度),但如果它答非所问,或者只回答了问题的一部分,那么这个答案的相关性就很低。例如,当用户问“法国在哪里,首都是哪里?”,如果答案只是“法国在西欧”,那么虽然忠实度高,但未回应“首都”这一核心诉求,答案相关性依然很低。
关键区分:忠实度与答案相关性的核心差异 你可能觉得忠实度和答案相关性很相似,但它们的侧重点截然不同:忠实度更关注“答案是否严格遵循上下文”(即“说的是真的吗”),聚焦生成环节与检索上下文的一致性;而答案相关性更关注“答案是否直接、完整且有效地回答问题”(即“解决问题了吗”),聚焦最终输出与用户需求的适配性。一个优质的RAG系统,必须同时具备高忠实度和高答案相关性。
通过对这三个维度进行系统评估,开发者可以对RAG系统的表现形成全面而细致的认知,并精准定位问题所在:若上下文相关性得分低,需优化检索器(如调整嵌入模型、优化向量数据库检索策略);若忠实度得分低,需优化生成器(如优化提示词、增加“严格基于上下文作答”的约束);若答案相关性得分低,则需从端到端角度优化检索与生成的协同逻辑。
二、评估工作流:从检索到响应的分层评估闭环
虽然RAG评估涵盖三个核心维度,但在实际实操中,为了精准定位问题环节、提升评估效率,通常将评估过程拆解为两个主要环节:检索评估和响应评估。这种分层评估模式遵循“先局部后整体、先量化后定性”的原则,能帮助开发者快速锁定问题根源,避免盲目优化。
2.1 检索评估:聚焦上下文相关性的白盒测试
检索评估专门针对RAG三元组中的“上下文相关性”维度,本质上是一次白盒测试——评估过程中需要知晓检索器的输出结果(即检索到的上下文)。此阶段的评估核心是验证检索器能否精准召回与用户查询相关的文档,而评估的前提是构建一个高质量的标注数据集,其中需包含一系列查询以及每个查询对应的“真实相关文档”(即人类标注的、能有效回答该查询的文档集合)。
检索评估的指标体系借鉴了信息检索领域的经典理论,核心指标如下,这些指标能从不同角度量化检索器的性能:
核心评估指标
- 上下文精确率 (Context Precision): 衡量检索结果的准确性,即检索到的前k个文档中相关文档所占的比例。其中k是一个预设的数字(行业常用k=3或k=5,具体需根据业务场景调整:客服场景需快速获取核心信息,k=3更合适;学术检索场景需全面覆盖信息,k=5更优)。 公式:Precision@k=检索到的k个结果中的相关文档数k\text{Precision}@k = \frac{\text{检索到的}k\text{个结果中的相关文档数}}{k}Precision@k=k检索到的k个结果中的相关文档数 解读:高精确率意味着检索结果的噪声较少。例如,k=3时,若检索到的3个文档均为相关文档,精确率@3=1.0;若仅2个相关,则精确率@3≈0.67。
- 上下文召回率 (Context Recall):衡量检索结果的完整性,即检索到的前k个文档中,找到的相关文档占所有真实相关文档总数的比例。 公式:Recall@k=检索到的k个结果中的相关文档数数据集中所有相关的文档总数\text{Recall}@k = \frac{\text{检索到的}k\text{个结果中的相关文档数}}{\text{数据集中所有相关的文档总数}}Recall@k=数据集中所有相关的文档总数检索到的k个结果中的相关文档数 解读:高召回率意味着系统能够成功找回大部分关键信息。例如,数据集中与某查询相关的文档共有4篇,前k=3个检索结果召回了3篇,则召回率@3=0.75。需要注意的是,召回率会随k值的增大而提升,因此在对比不同系统的召回率时,必须明确k值。
- F1分数 (F1-Score): 精确率和召回率的调和平均数,用于平衡两者之间的矛盾(例如,某些检索策略会通过扩大检索范围提升召回率,但同时会降低精确率,反之亦然)。当精确率和召回率都高时,F1分数才会高。 公式:F1=2⋅Precision×RecallPrecision+RecallF_1 = 2 \cdot \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}}F1=2⋅Precision+RecallPrecision×Recall 解读:F1分数是检索器综合性能的核心衡量指标,适合作为检索环节优化的核心目标。
- 平均倒数排名 (MRR - Mean Reciprocal Rank): 评估系统将第一个相关文档排在靠前位置的能力。对于一个查询,倒数排名是第一个相关文档排名的倒数;MRR是所有查询的倒数排名的平均值。 公式:MRR=1∣Q∣∑q=1∣Q∣1rankq\text{MRR} = \frac{1}{|Q|} \sum_{q=1}^{|Q|} \frac{1}{\text{rank}_q}MRR=∣Q∣1q=1∑∣Q∣rankq1 其中
|Q|是查询总数,rank_q是第q个查询的第一个相关文档的排名。 解读:该指标适用于用户通常只关心第一个正确答案的场景(如搜索引擎、智能问答机器人的首屏响应)。例如,某查询的第一个相关文档排名第2,则倒数排名为1/2=0.5;若排名第1,则倒数排名为1.0,MRR的最大值为1.0。 - 平均准确率均值 (MAP - Mean Average Precision): 一个综合性指标,同时评估了检索结果的精确率和相关文档的排名。它先计算每个查询的平均精确率(AP)——即每个相关文档被检索到时的精确率的平均值,然后对所有查询的AP取平均值。 公式:MAP=1∣Q∣∑q=1∣Q∣AP(q)\text{MAP} = \frac{1}{|Q|} \sum_{q=1}^{|Q|} \text{AP}(q)MAP=∣Q∣1q=1∑∣Q∣AP(q) 其中
|Q|是查询总数,AP(q)是第q个查询的平均精确率(Average Precision)。 解读:MAP适合评估多相关文档场景的检索性能,能反映检索结果的“整体质量”。例如,两个检索器的精确率@k和召回率@k相同,但一个将相关文档排在前面,另一个排在后面,则前者的MAP更高。
实操关键:高质量标注数据集的构建要点 要准确计算上述所有指标,前提是拥有一个高质量的标注数据集。构建此类数据集需注意三点:① 覆盖核心场景:需包含业务中的高频查询、边缘查询(如歧义查询、长尾查询)和异常查询,避免以偏概全;② 明确标注标准:统一“相关文档”的判断规则(如“包含查询核心关键词且能支撑答案生成的文档即为相关”),确保标注一致性;③ 动态更新:当知识库内容迭代或业务场景变化时,需同步更新标注数据集,避免评估指标失真。
2.2 响应评估:聚焦端到端表现的全维度评估
响应评估覆盖了RAG三元组中的“忠实度”和“答案相关性”两个核心维度,此环节通常采用端到端的评估范式——无需关注检索器和生成器的中间输出,仅衡量最终生成答案的质量,因为这直接对应了用户的感知体验。无论采用何种评估方法,都主要围绕“忠实度”和“答案相关性”两个核心维度展开。
2.2.1 评估维度
- 忠实度 / 可信度: 衡量生成的答案在多大程度上可以由给定的上下文所证实。一个完全忠实的答案,其所有内容都必须能在上下文中找到依据,以此避免模型产生“幻觉”。在实际评估中,需重点关注答案中的事实、数据、观点是否与上下文完全一致。
- 答案相关性: 衡量生成的答案与用户原始查询的对齐程度。一个高相关性的答案必须满足三个条件:① 直接切题,不偏离用户核心诉求;② 信息完整,覆盖用户查询的所有关键要点;③ 无冗余信息,不包含与问题无关的内容。
2.2.2 主要评估方法
1. 基于大语言模型的评估(主流优选方案)
这是一种强大的语义级评估方法,正逐渐成为工业界的主流选择。其核心逻辑是利用一个高性能、中立的LLM(如GPT-4、Claude 3)作为“评估者”,对答案的忠实度和相关性进行深度的语义理解和打分。该方法能突破词汇表面匹配的限制,精准判断答案与上下文、查询之间的语义一致性。
- 忠实度评估流程: 首先,将生成的答案分解为一系列独立的声明或断言(Claims),例如将“2025年公司年假为15天,需提前3天申请”拆解为“2025年公司年假为15天”“年假需提前3天申请”两个断言;然后,对于每一个断言,在提供的上下文中进行逐一验证,判断其“有依据”“无依据”或“存疑”;最终的忠实度分数是所有被上下文证实的断言所占的比例。
- 答案相关性评估流程: 评估者需要同时分析用户查询和生成的答案,先明确用户的核心诉求(如事实查询、方案咨询、对比分析等),再判断生成答案是否覆盖核心诉求、是否存在信息缺失或冗余;评分时通常采用1-5分制,对答非所问、信息严重缺失的答案给予低分,对精准、完整回应需求的答案给予高分。
值得注意的是,最新研究(如2025年arXiv发布的RAGElo框架)已证明,LLM-as-a-judge的评估结果与领域专家评分在相关性、准确性、完整性等维度存在显著的正相关关系,能有效降低人工评估的成本。目前,TruLens、LangSmith等工具已内置该评估模式,支持开发者快速实现自动化评估。
2. 基于词汇重叠的经典指标
这类指标需要在数据集中包含一个或多个“标准答案”(即人工标注的最优答案),核心逻辑是通过计算生成答案与标准答案之间n-gram(连续的n个词)的重叠程度来评估质量。其优势是计算速度快、结果客观、成本低,适合大规模的初步筛选;劣势是无法理解语义,可能误判同义词、释义或语序调整等情况。
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation): ROUGE关注的重点是召回率,即标准答案中的词语有多少被生成答案所覆盖,因此常用于评估内容的完整性。其常用变体包括计算n-gram的
ROUGE-N(N通常取1或2,分别对应单字和双字重叠)和计算最长公共子序列的ROUGE-L(更能反映句子结构的一致性)。 公式:ROUGE-N=匹配的 n-gram 数量参考答案中 n-gram 的总数\text{ROUGE-N} = \frac{\text{匹配的 } n\text{-gram 数量}}{\text{参考答案中 } n\text{-gram 的总数}}ROUGE-N=参考答案中 n-gram 的总数匹配的 n-gram 数量 - BLEU (Bilingual Evaluation Understudy): BLEU侧重于评估精确率,衡量生成的答案中有多少词是有效的(即在标准答案中出现过)。它还引入了长度惩罚机制(BP),避免模型生成过短的句子来规避错误,因此更适合评估答案的流畅度和准确性。 公式:BLEU=BP×exp(∑n=1Nwnlogpn)\text{BLEU} = \text{BP} \times \exp\left(\sum_{n=1}^{N} w_n \log p_n\right)BLEU=BP×exp(n=1∑Nwnlogpn) 其中,
BP是长度惩罚因子(生成答案越短,惩罚越重),p_n是修正后的n-gram精确率。 - METEOR (Metric for Evaluation of Translation with Explicit Ordering): 作为BLEU的改进版,METEOR同时考量精确率和召回率的调和平均,并通过词干匹配(如“run”和“running”)、同义词匹配(如“boat”和“ship”)来更好地捕捉语义相似性。其评估结果通常被认为与人类判断的相关性更高。 公式:Fmean=P×RαP+(1−α)RF_{\text{mean}} = \frac{P \times R}{\alpha P + (1-\alpha)R}Fmean=αP+(1−α)RP×R METEOR=Fmean×(1−Penalty)\text{METEOR} = F_{\text{mean}} \times (1 - \text{Penalty})METEOR=Fmean×(1−Penalty) 其中
P是精确率,R是召回率,Penalty是基于语序的惩罚项(语序越混乱,惩罚越重)。
示例说明:三种经典指标的核心差异
为了更直观地理解ROUGE、BLEU、METEOR的区别,我们通过一个简单的中文案例进行分析:
假设:
- 参考答案:
狗 在 床 上面(共5个词)- 生成答案:
狗 在 床 上(共4个词)
评估分析:
- ROUGE (召回率导向): 从召回率的角度出发:“参考答案里的5个词,生成答案覆盖了多少?”——覆盖了4个。因此,它的召回率很高(ROUGE-1 为 4/5=0.8),得分会不错。ROUGE更关心“说全了没”。
- BLEU (精确率导向): 从精确率的角度进行评判:“生成答案里的4个词,有多少是有效的(在参考答案里)?”——全部有效,精确率很高。但它会发现生成答案比参考答案短,于是通过**长度惩罚(Brevity Penalty)**进行扣分。BLEU更关心“说对了没,以及长度是否合适”。
- METEOR (综合平衡): 同时计算精确率(1.0)和召回率(0.8)的调和平均,并取一个最佳平衡点。在这个例子里,词序是完全正确的,惩罚项为0,因此METEOR得分会介于ROUGE和BLEU之间,更能平衡“说全”和“说对”两个需求。
2.2.3 方法对比和总结
两种评估方法各有优劣,在实际应用中需根据场景灵活组合:
- 基于LLM的评估: 优势是更注重语义和逻辑,评估质量高,能适配复杂的业务场景;劣势是评估成本较高(需调用高性能LLM),且存在一定的评估者偏见(不同LLM的评估标准可能存在差异)。
- 基于词汇重叠的指标: 优势是客观、计算快、成本低,适合大规模的初步筛选;劣势是无法理解语义,可能误判同义词、释义等情况,评估精度有限。
实践中,推荐采用“两阶段评估策略”:第一阶段使用ROUGE、BLEU等经典指标进行快速、大规模的初步筛选,剔除明显不合格的样本(如答非所问、信息严重缺失的答案);第二阶段利用LLM评估者对筛选后的样本进行更精细的评估,重点验证忠实度和答案相关性,以此平衡评估效率与评估质量。
三、参考文献
- [1] The RAG Triad of Metrics. TruLens Official Documentation.
- [2] 如何评估 RAG 应用?. Zilliz Blog.
- [3] system_evaluation. All-in-RAG (DataWhale).
- [4] Zackary Rackauckas, Arthur Câmara, Jakub Zavrel. Evaluating RAG-Fusion with RAGElo: an Automated Elo-based Framework. arXiv, 2025.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)