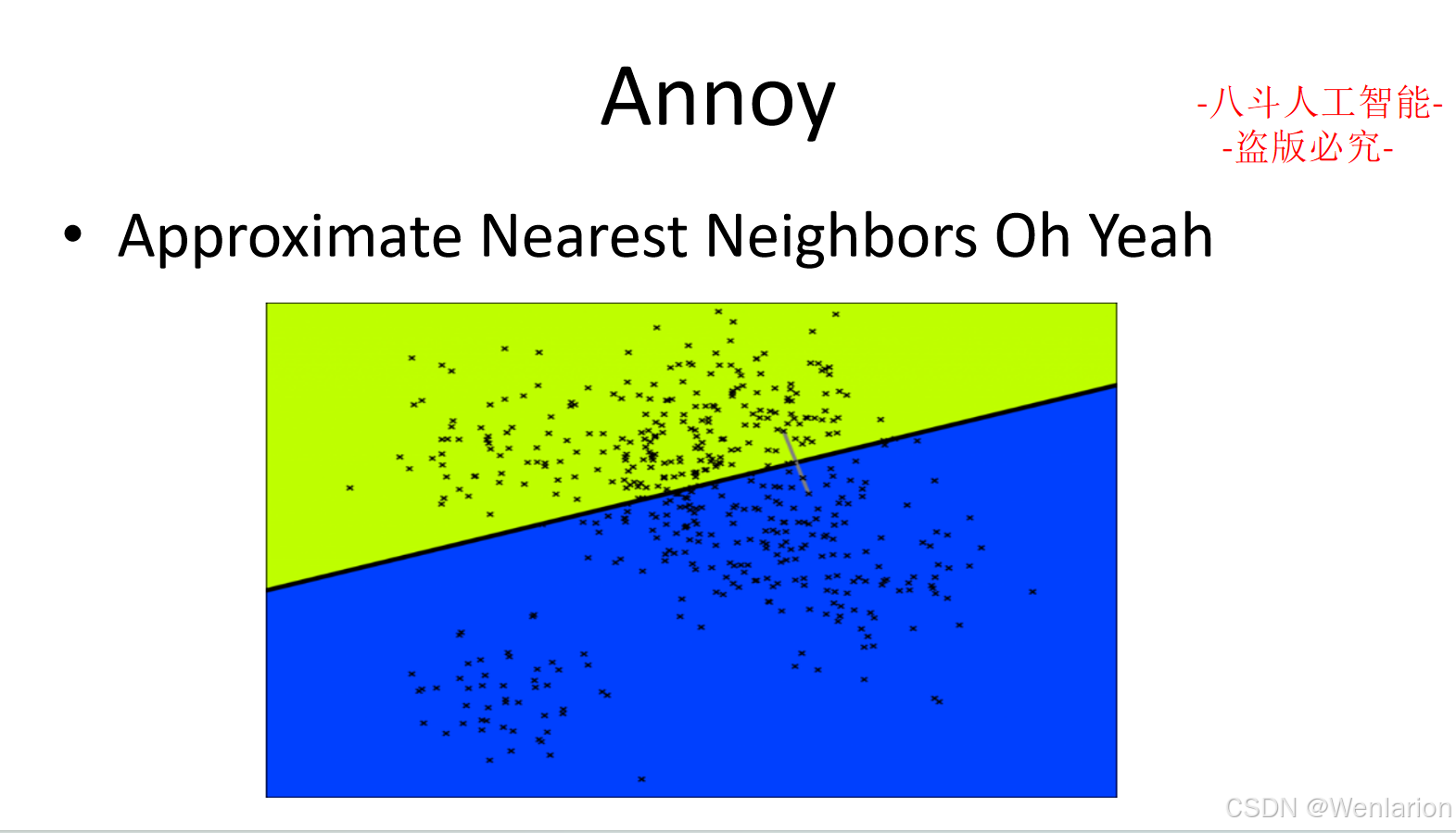
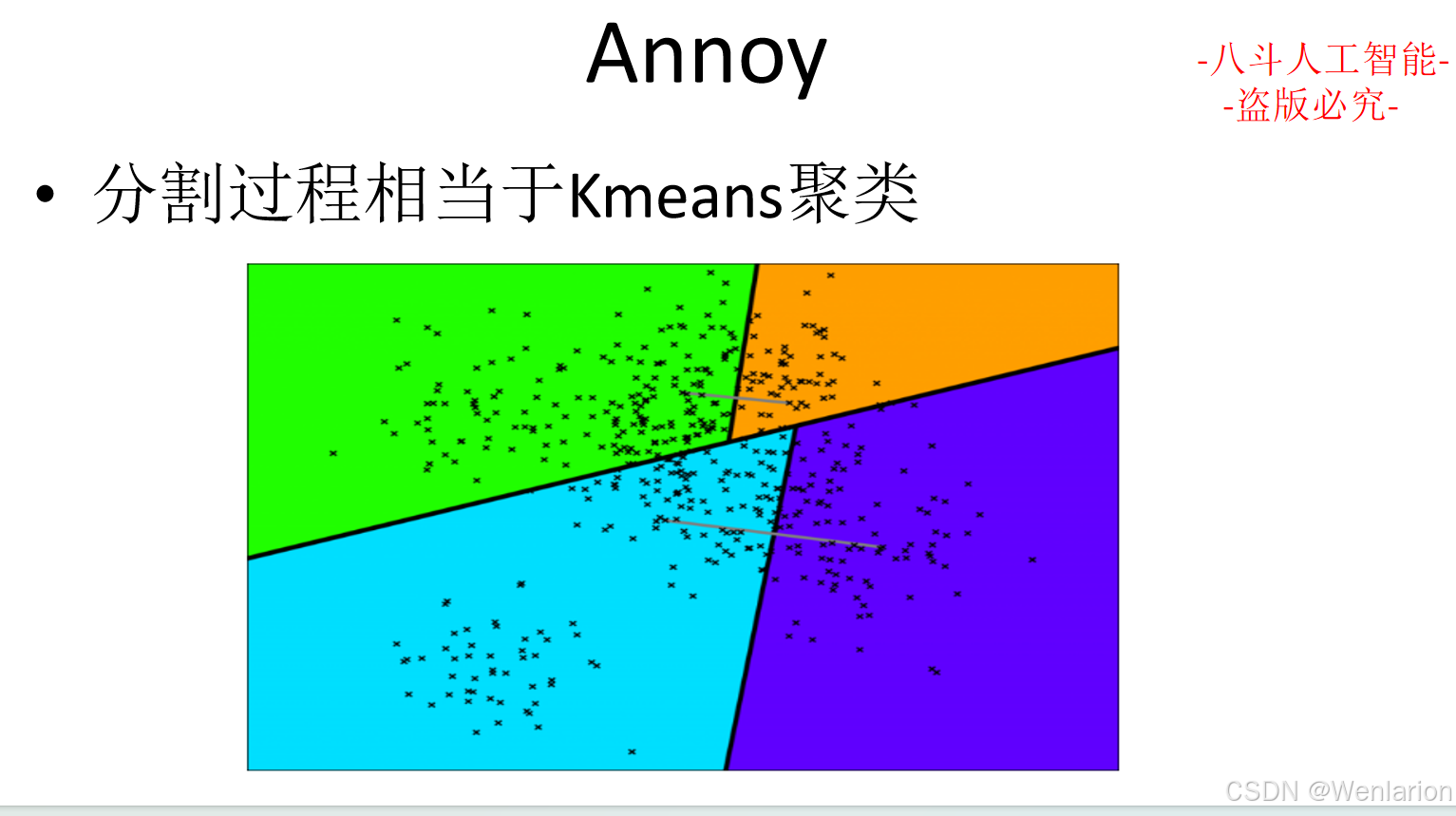
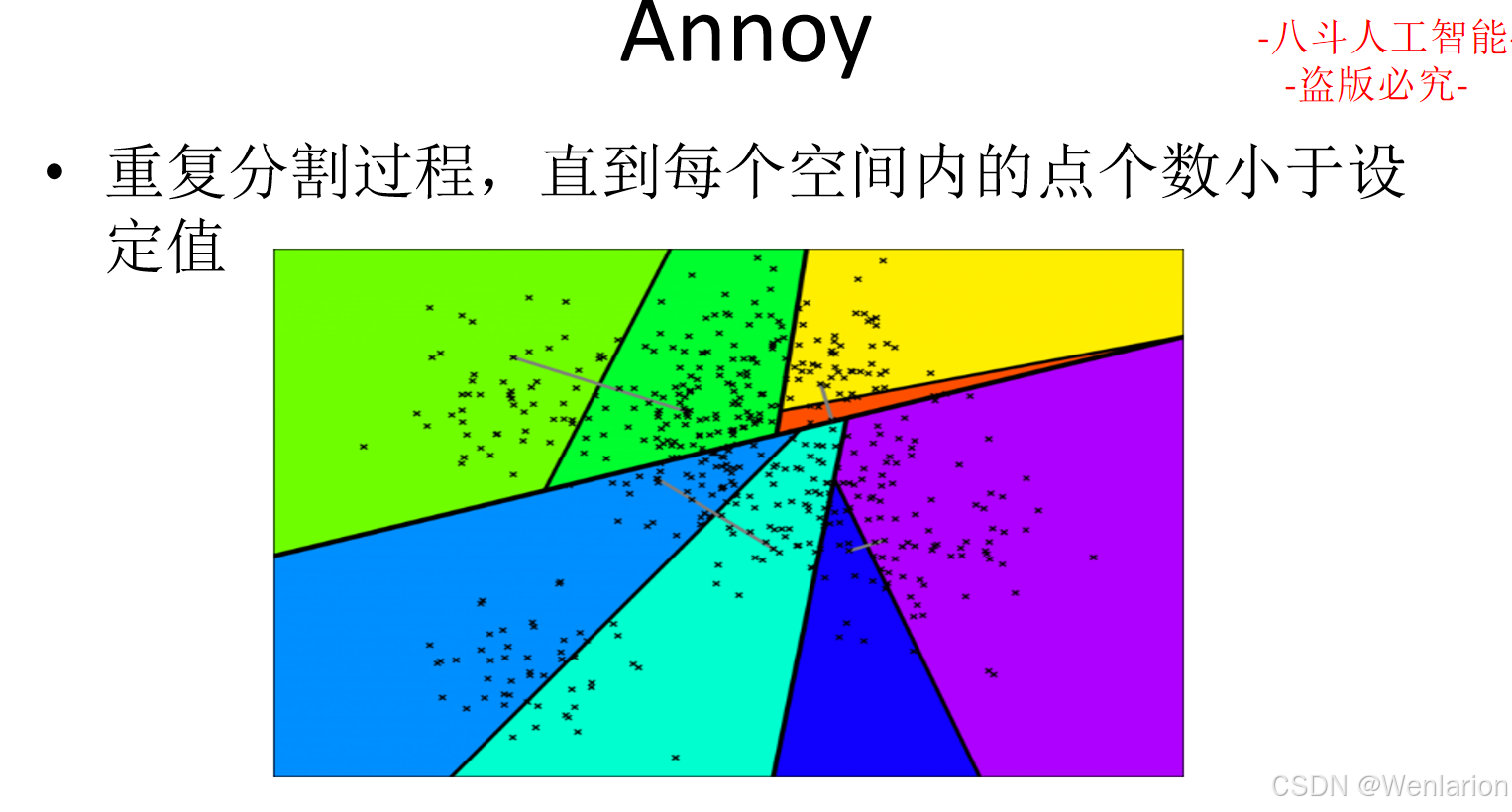
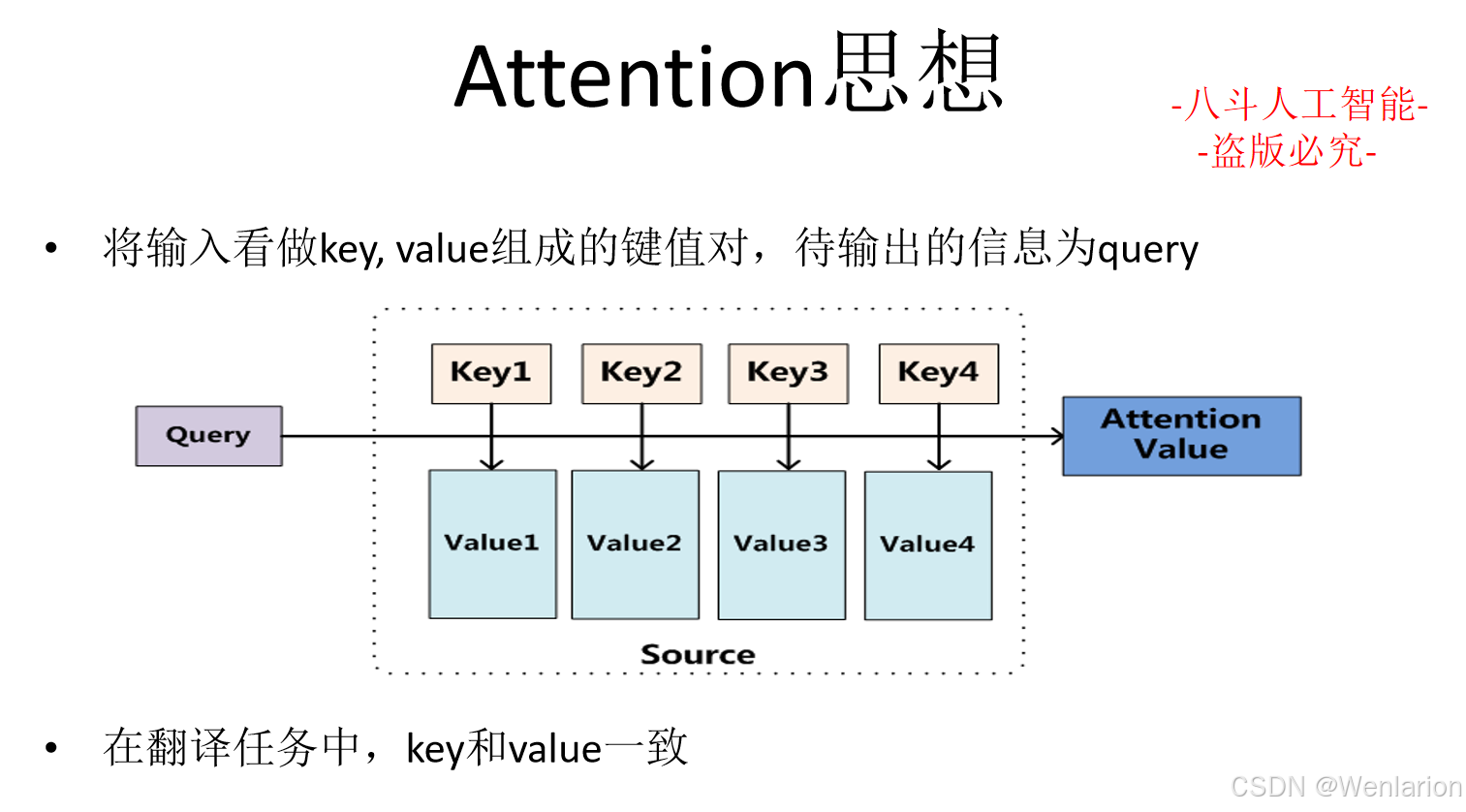
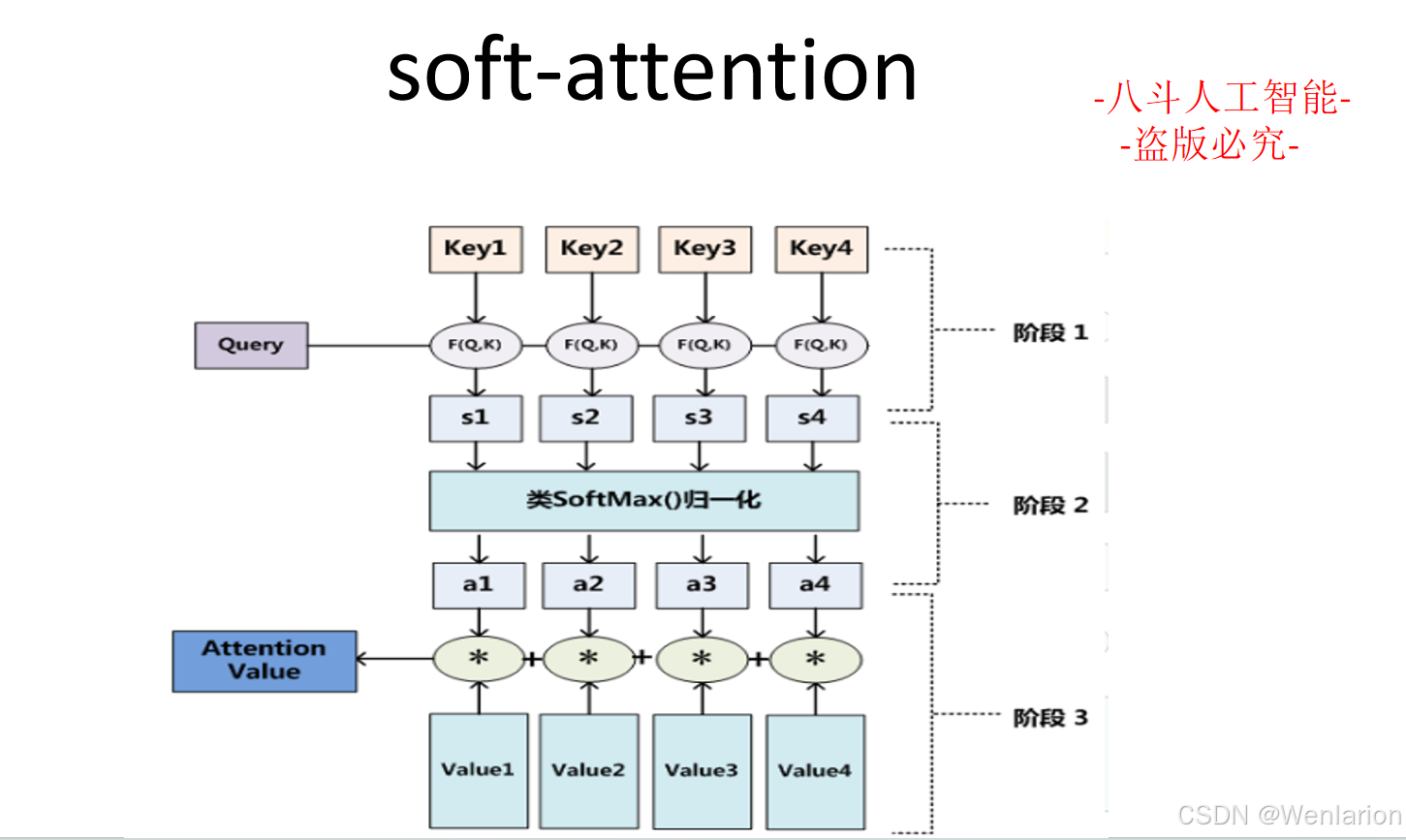
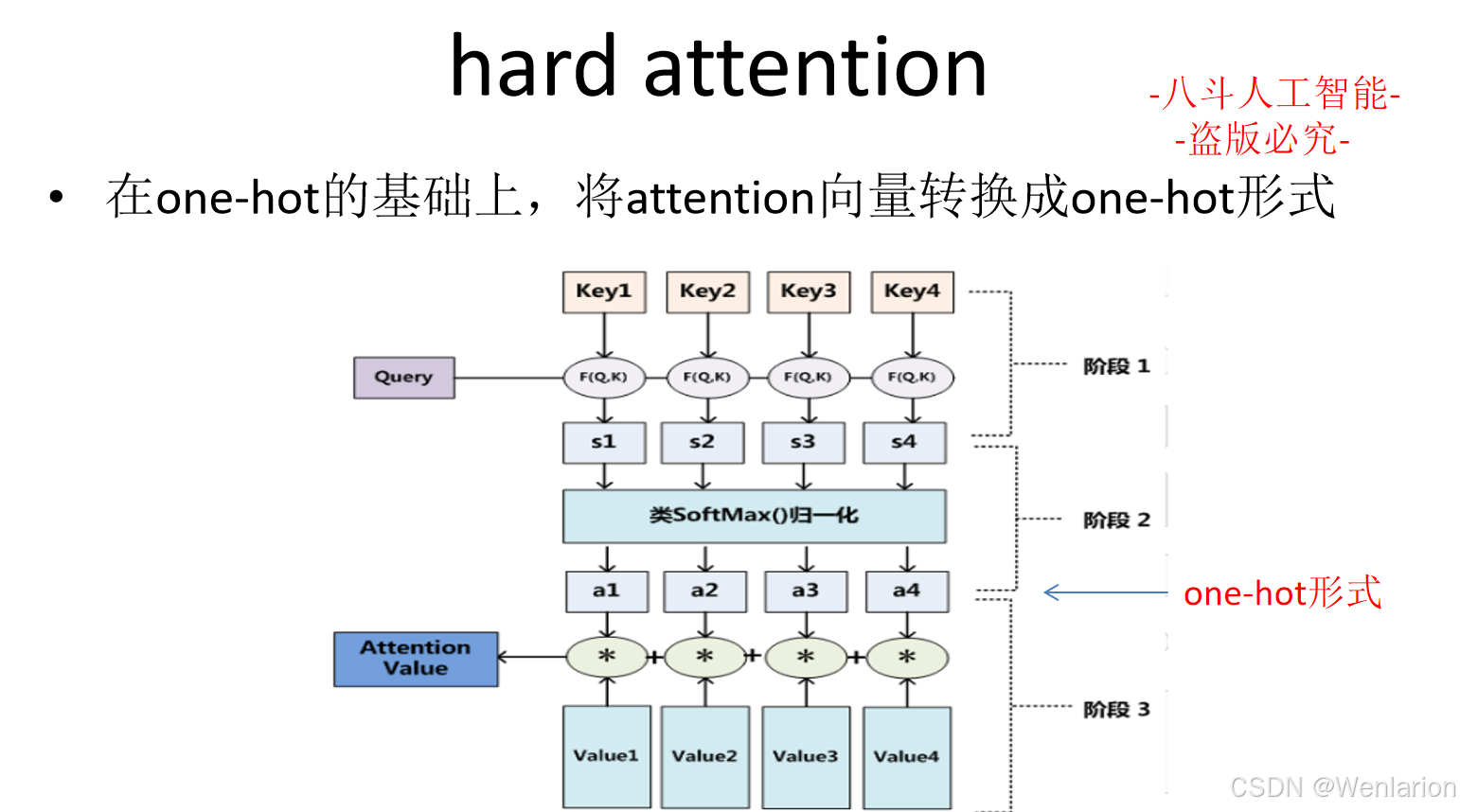
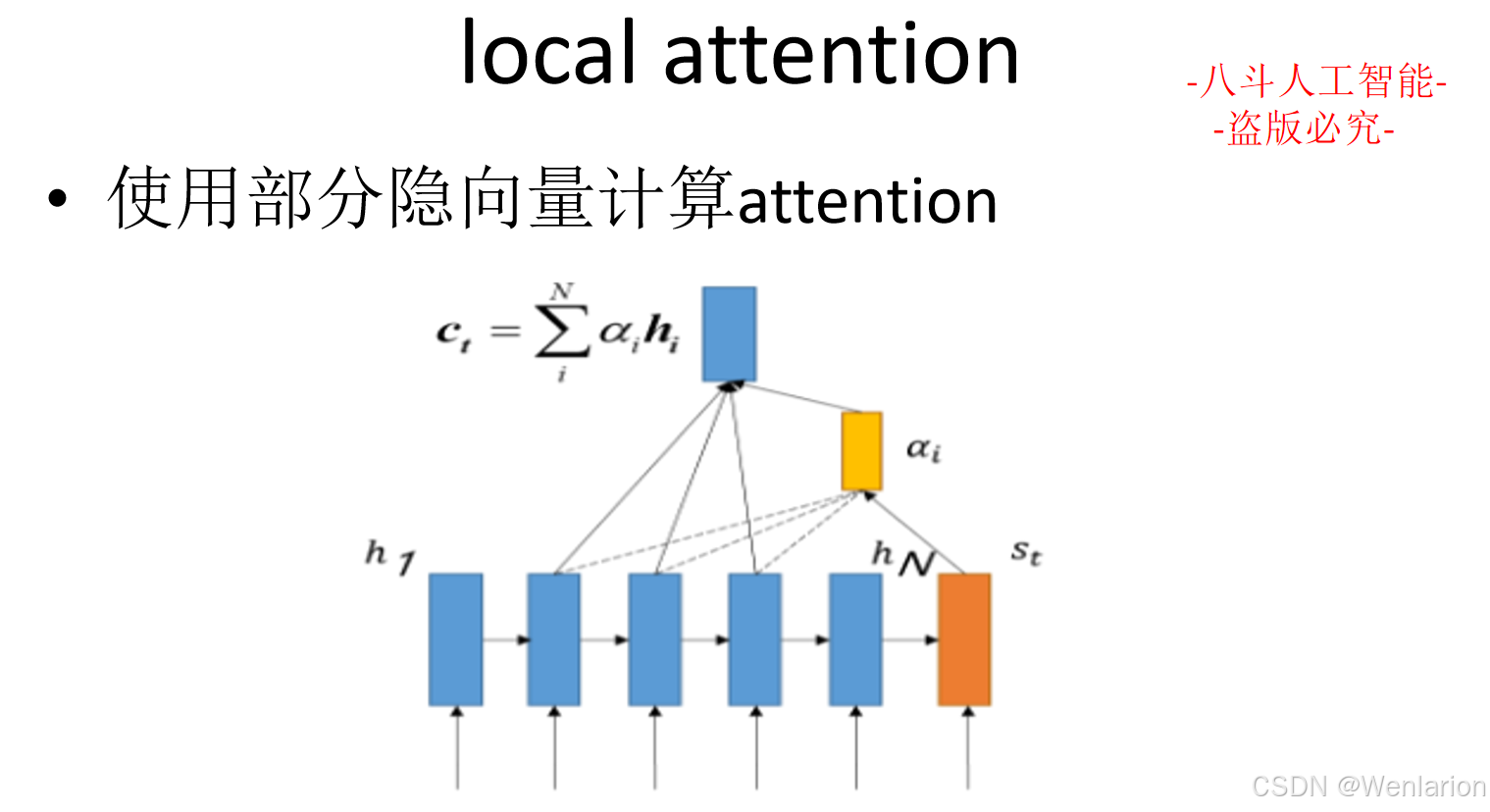
大模型算法(四):自然语言处理
1、自然语言处理基础
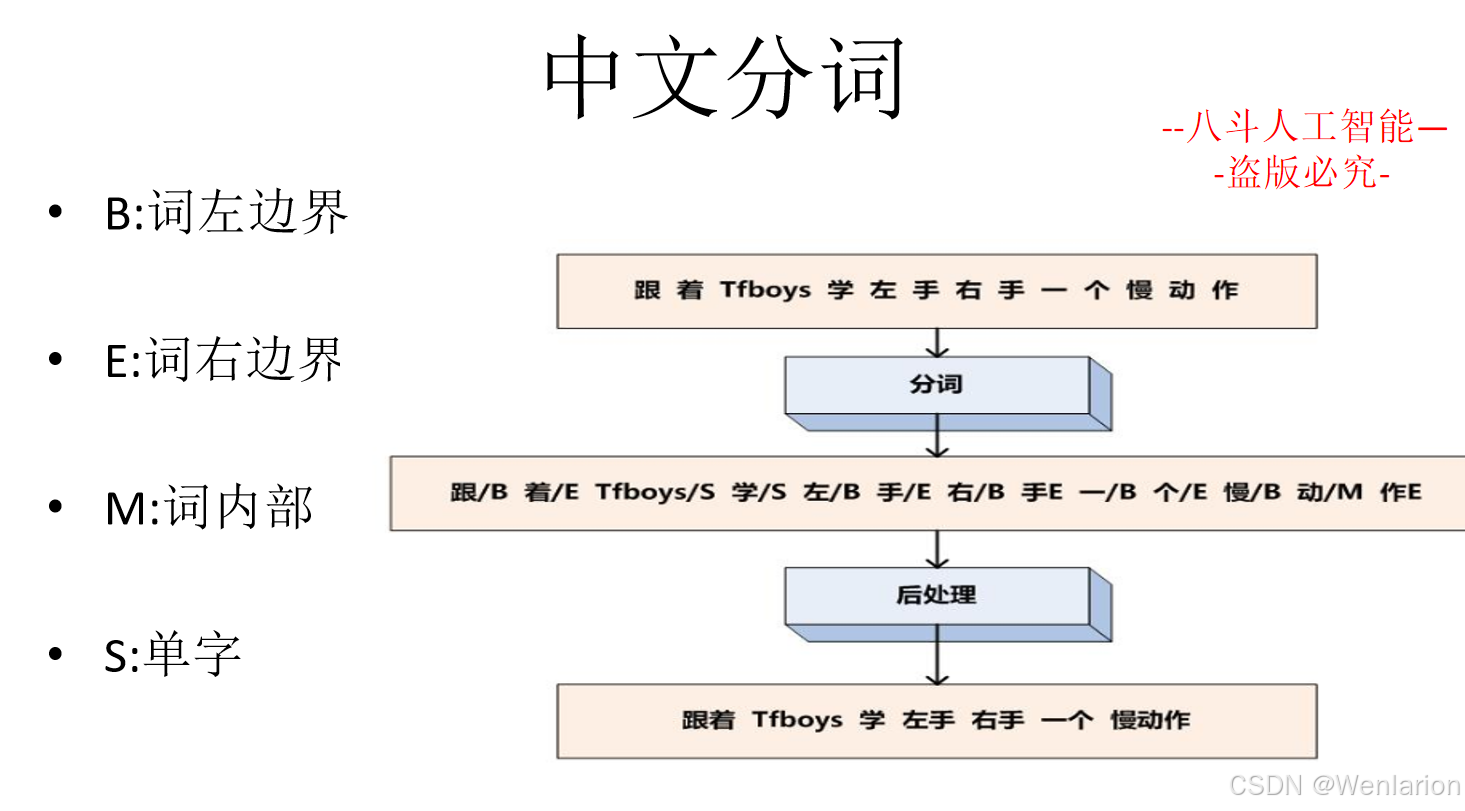
1.1 中文分词









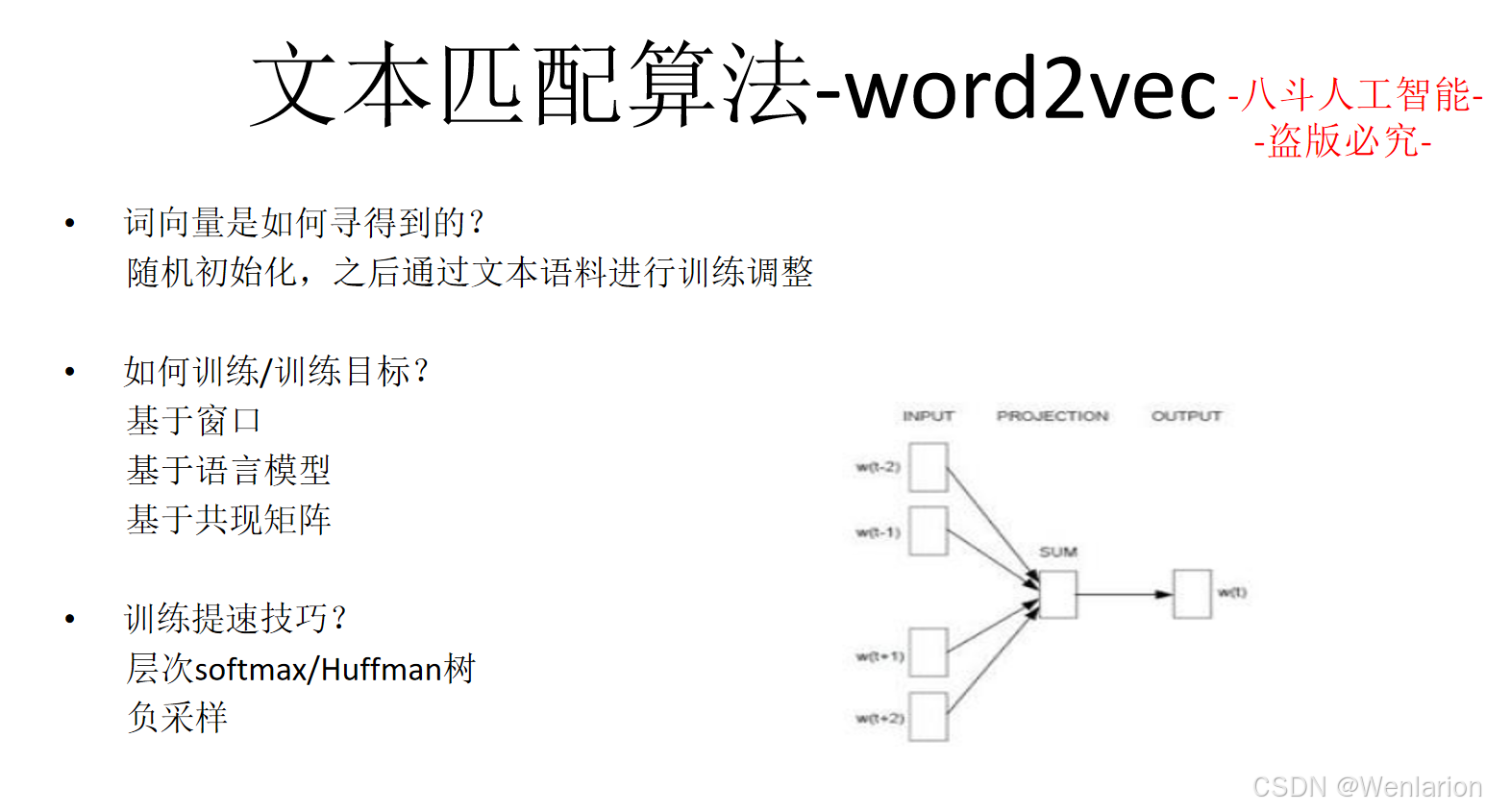
1.2 词向量训练



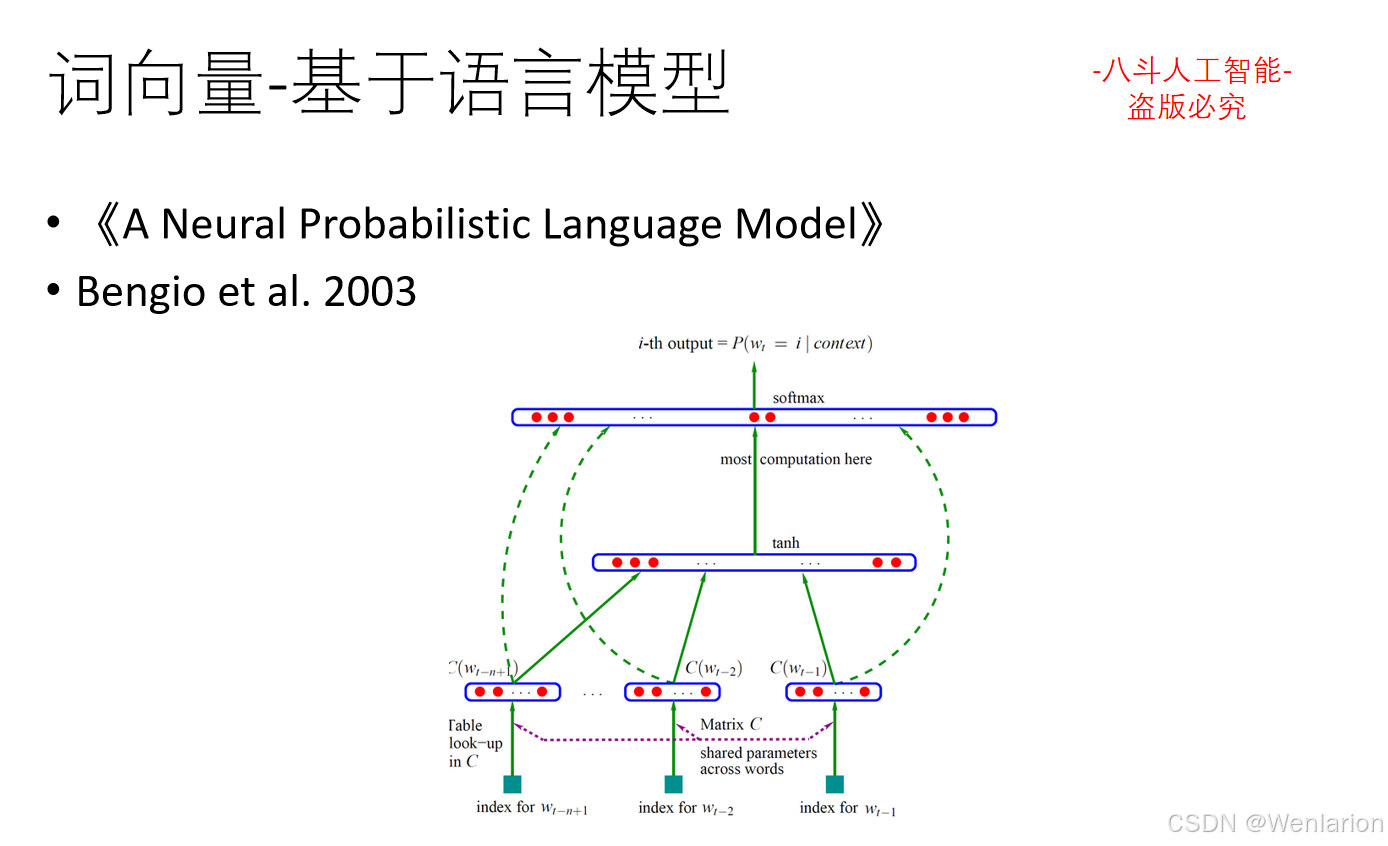


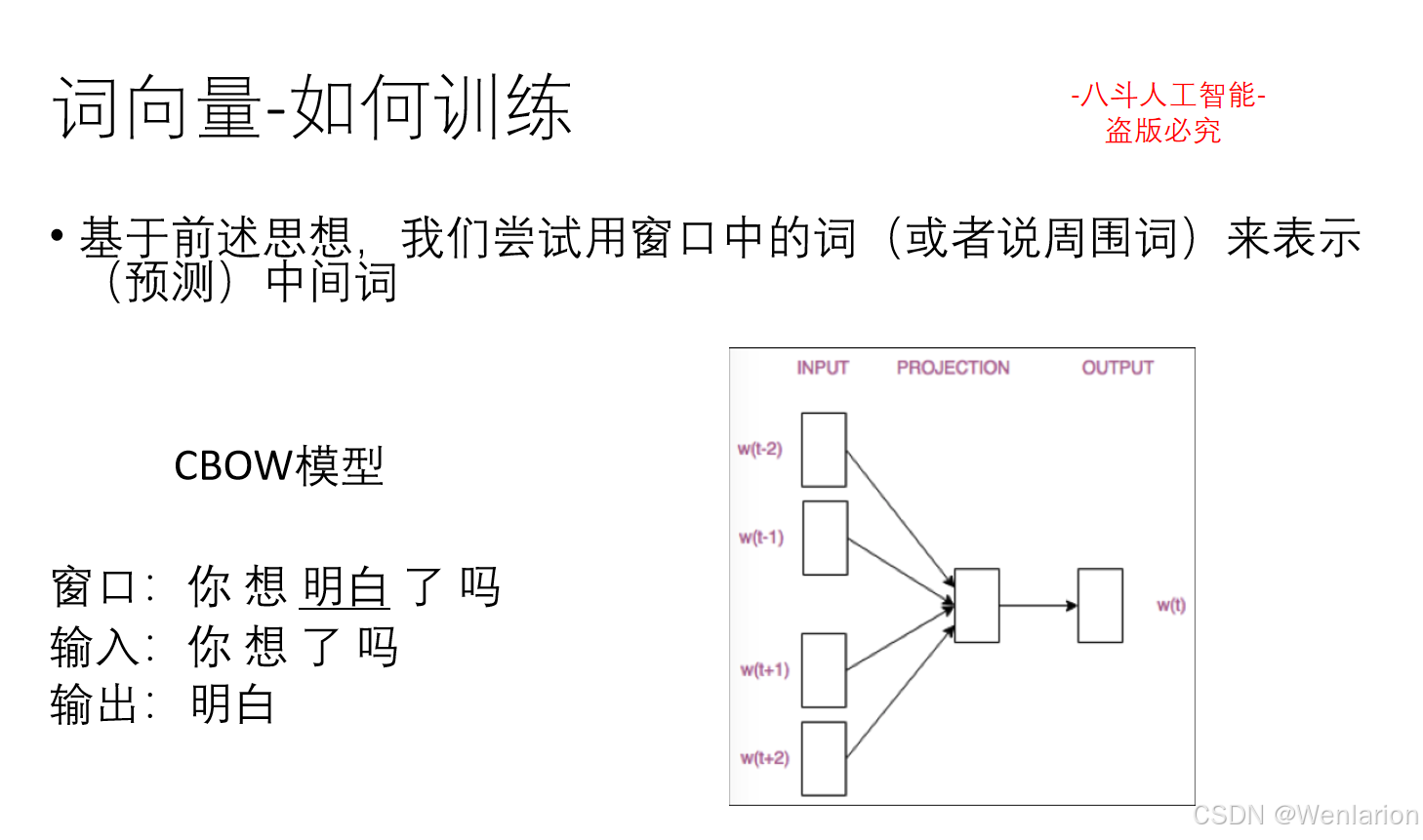
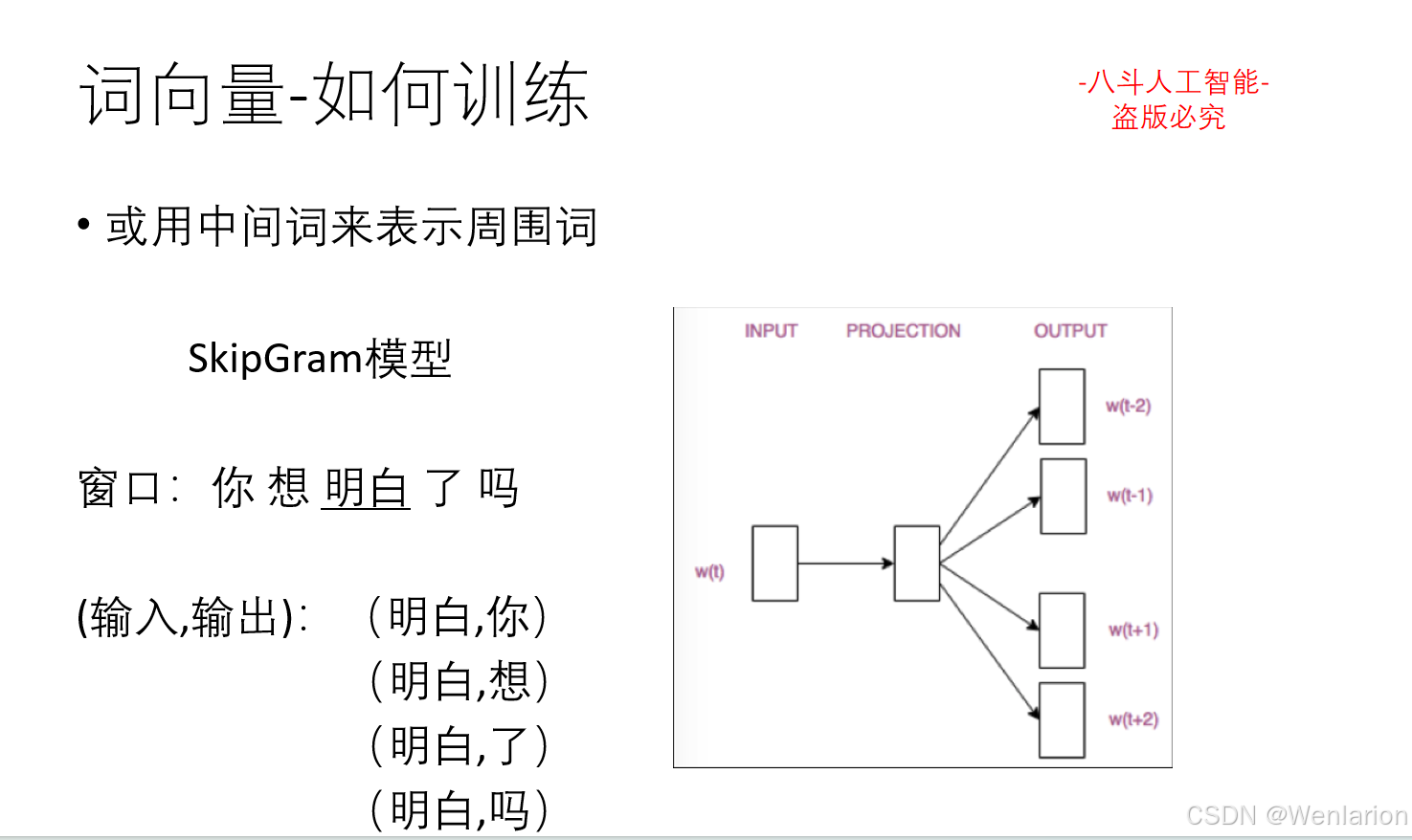

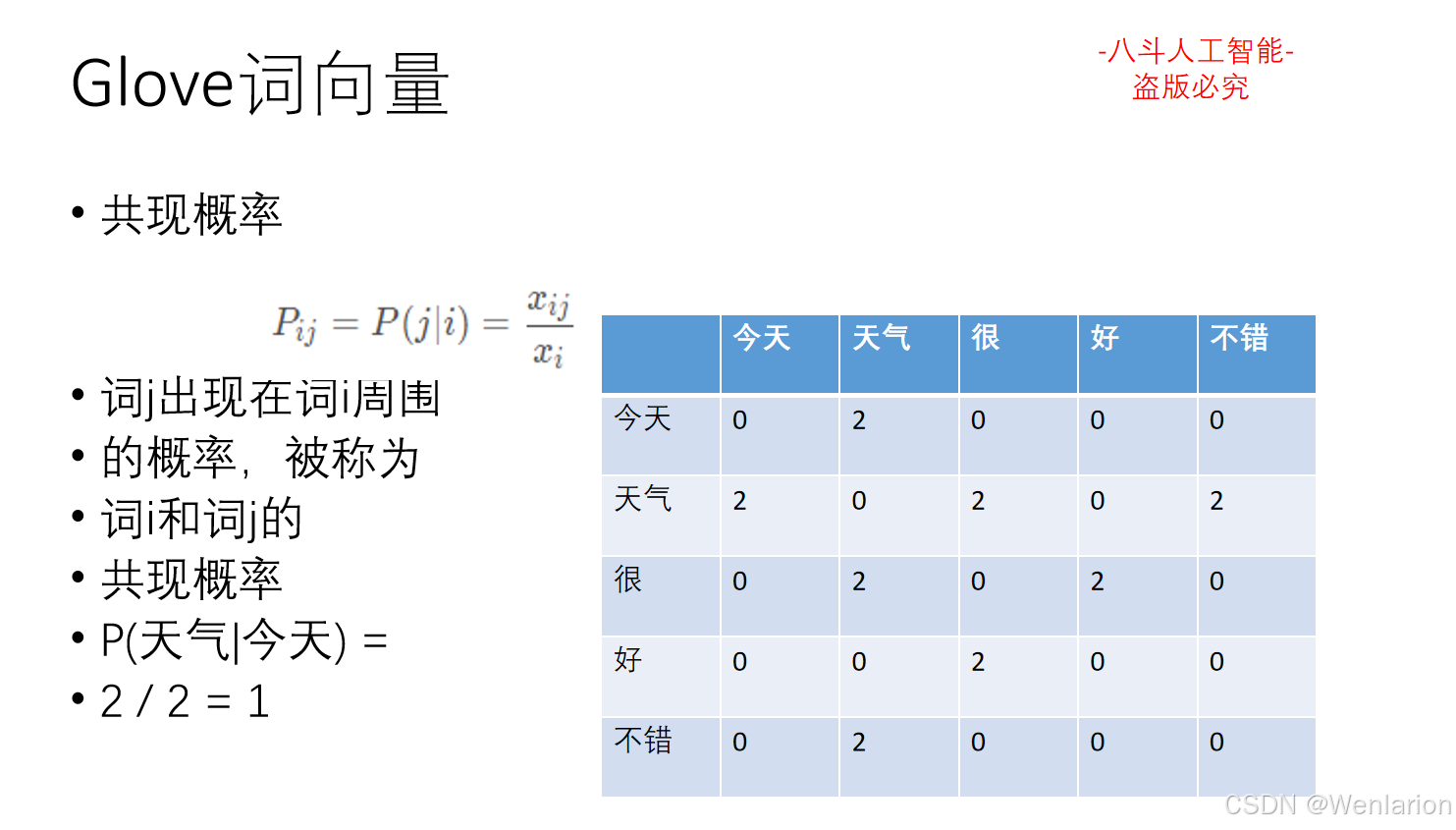


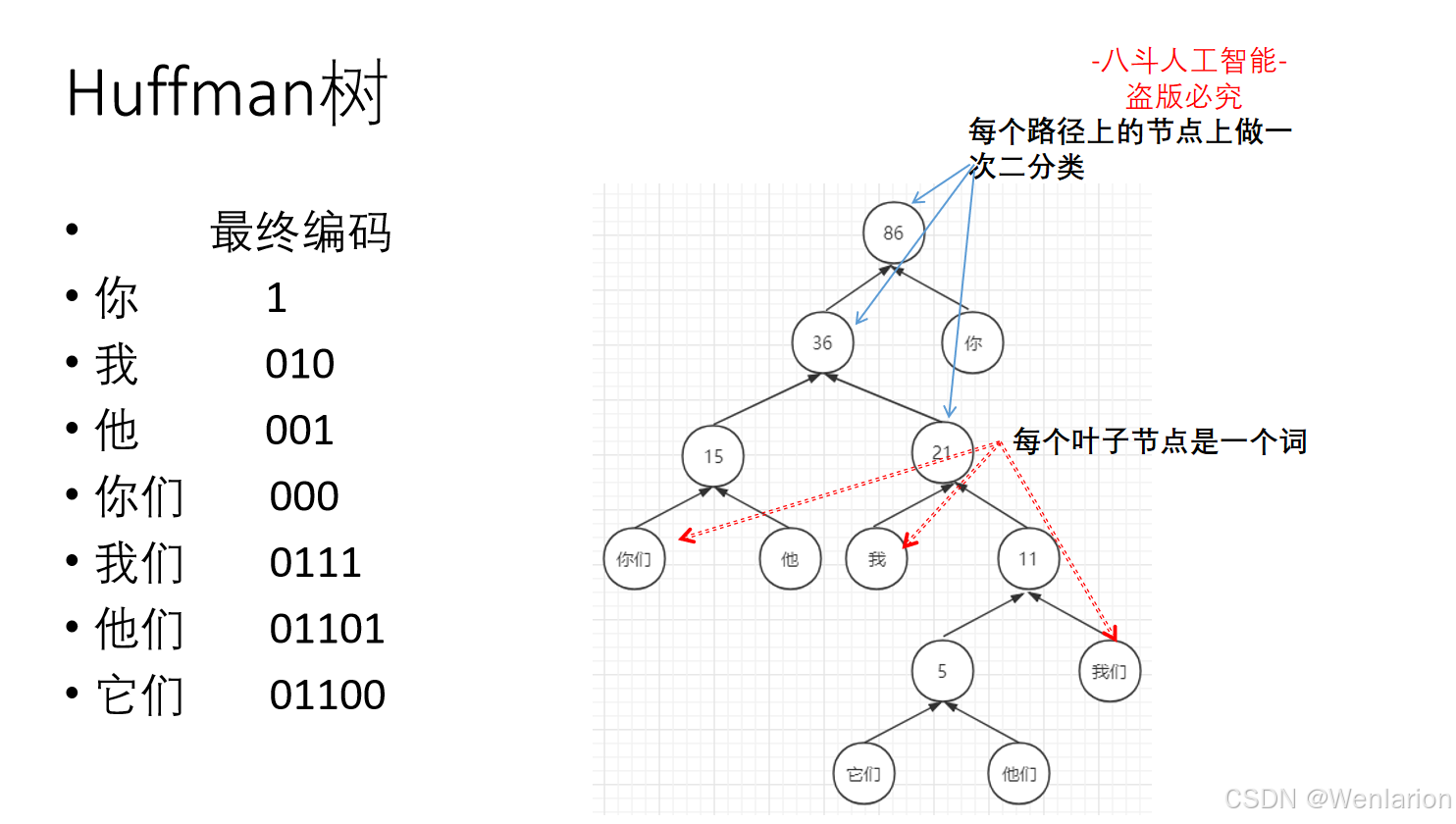

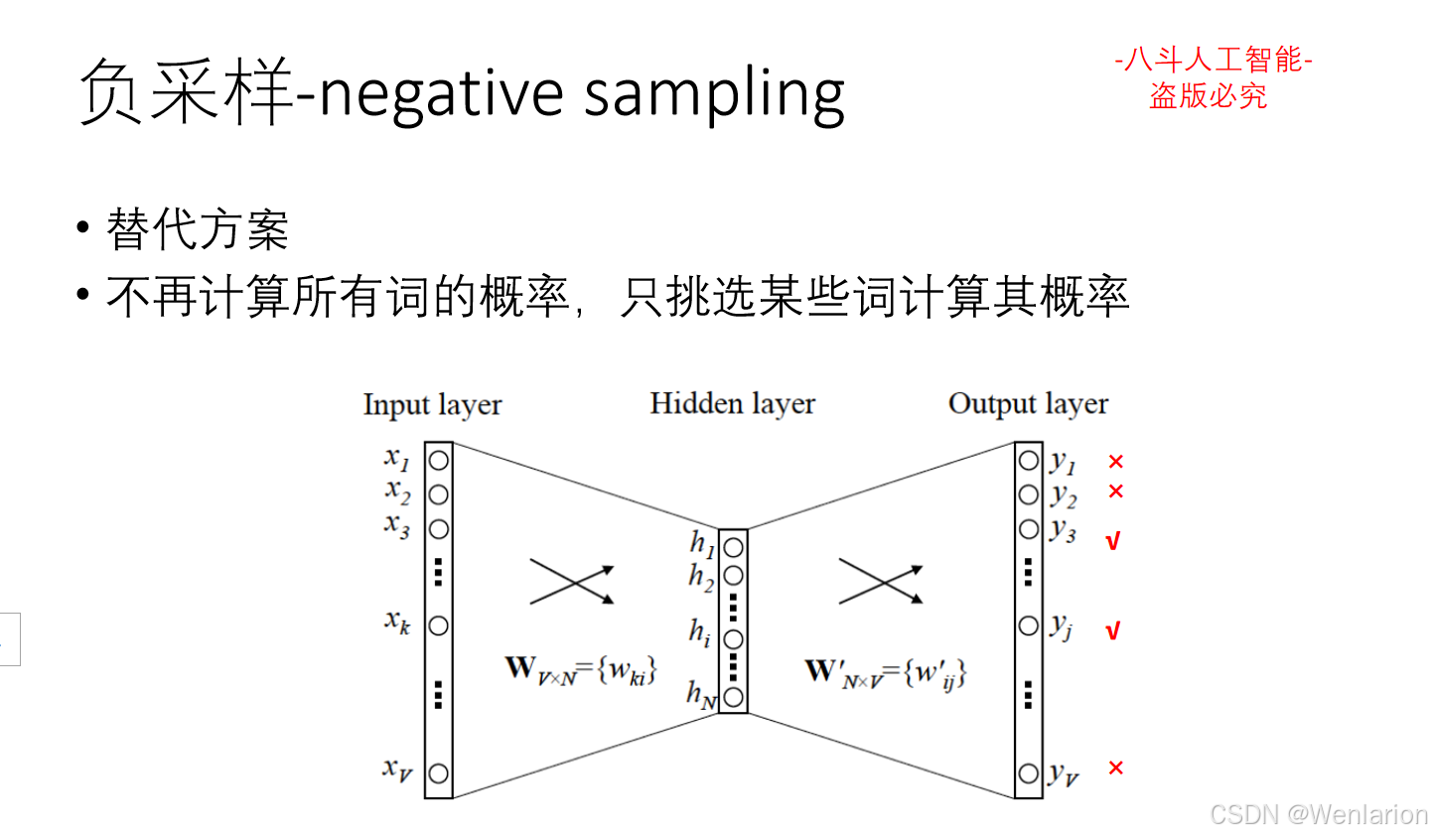
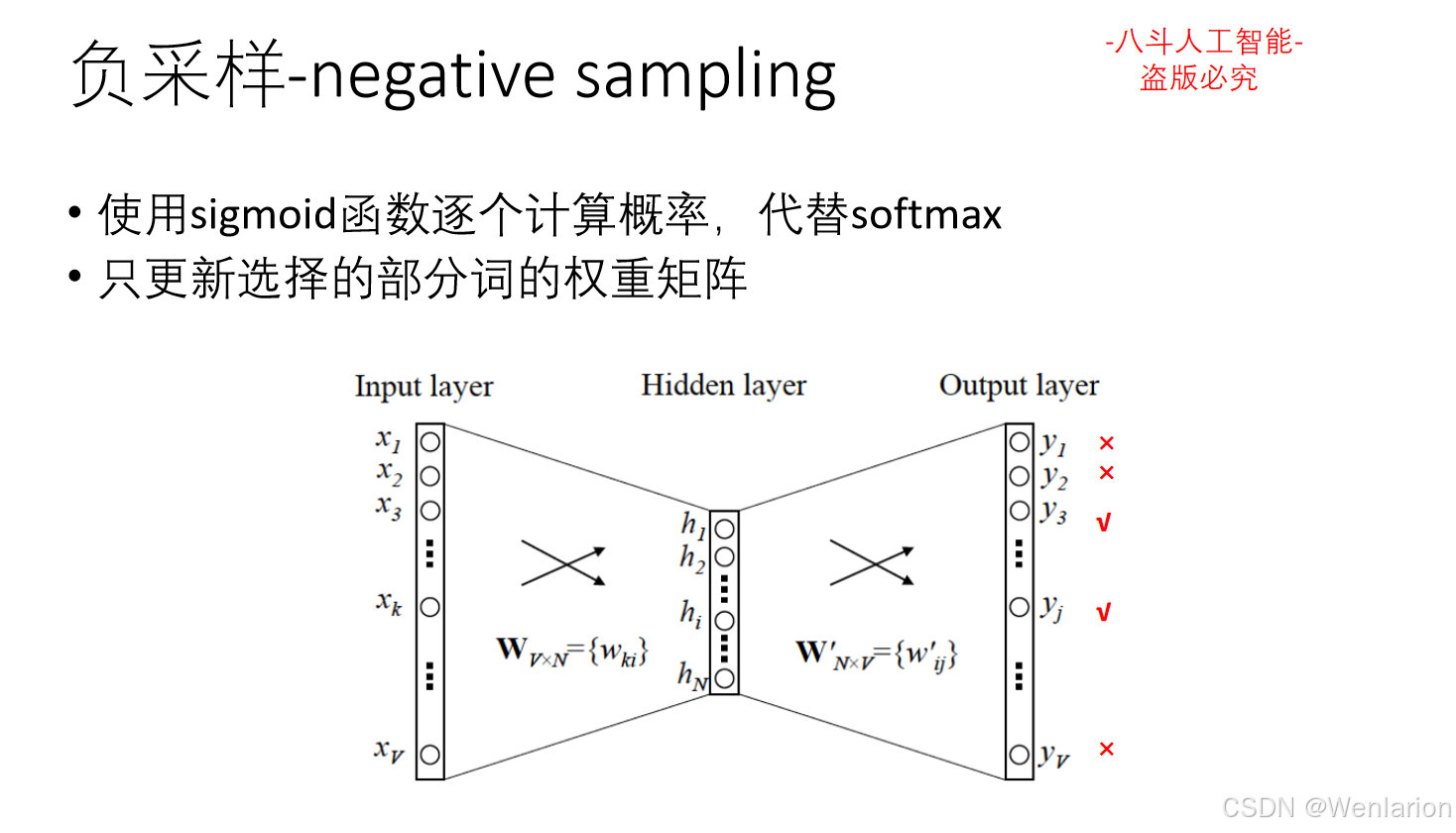

1.3 语言模型
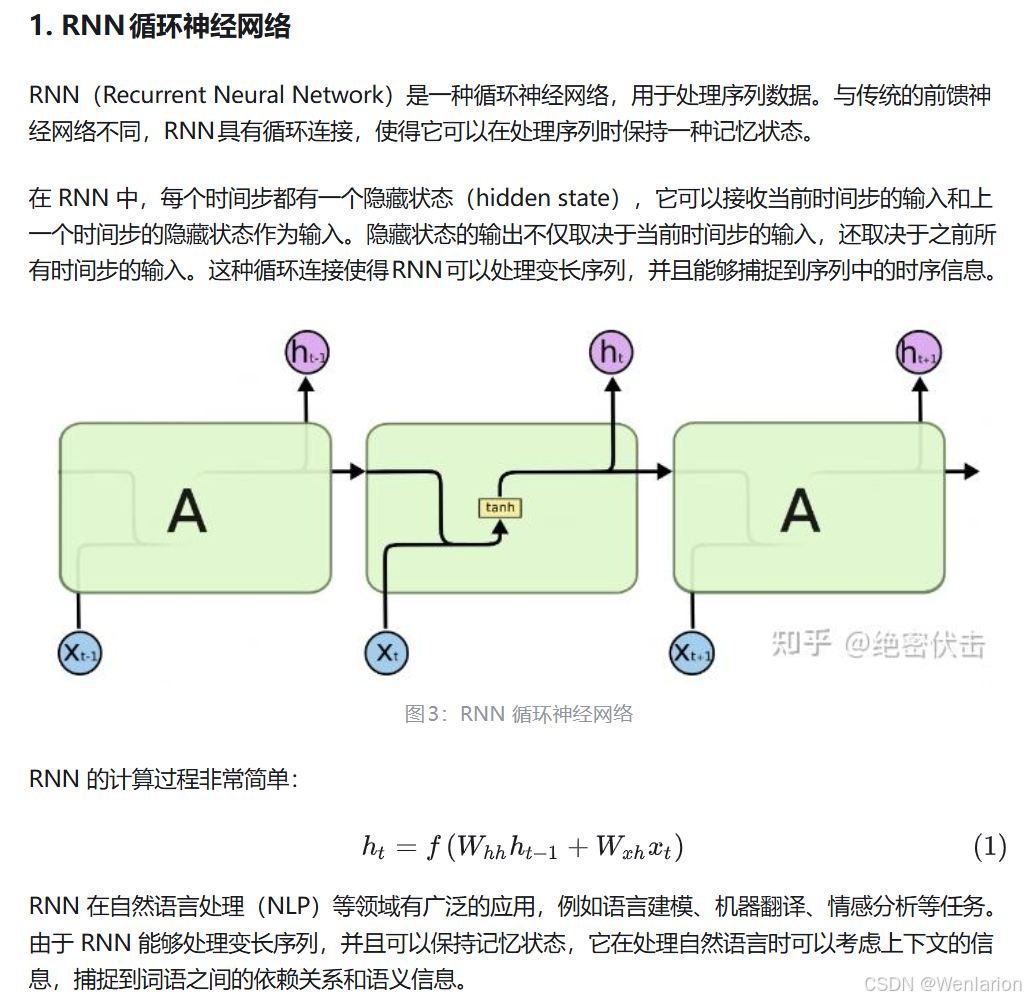
1.3.1 RNN
1.3.2 LSTM
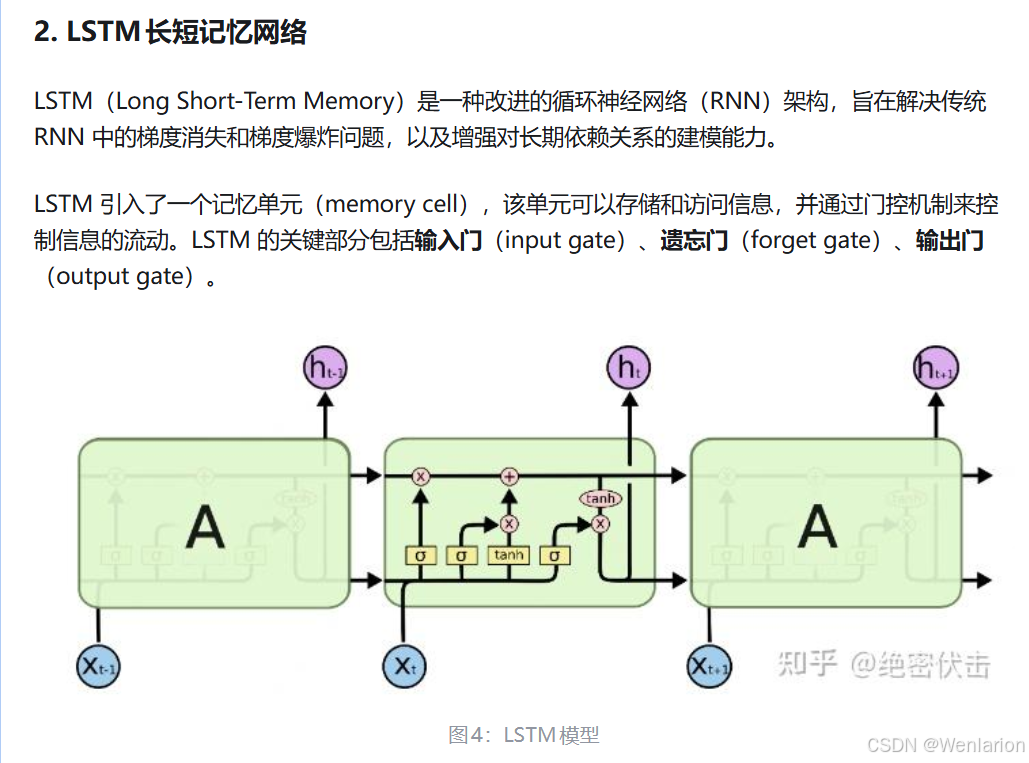
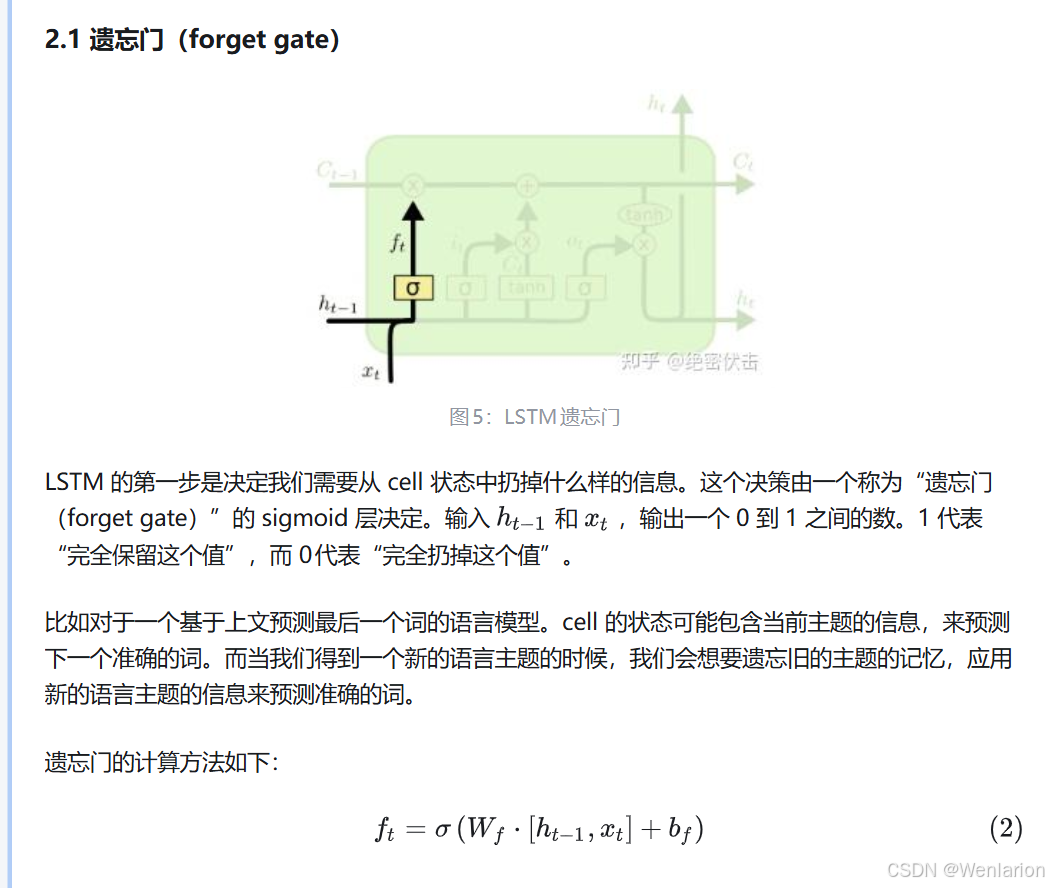

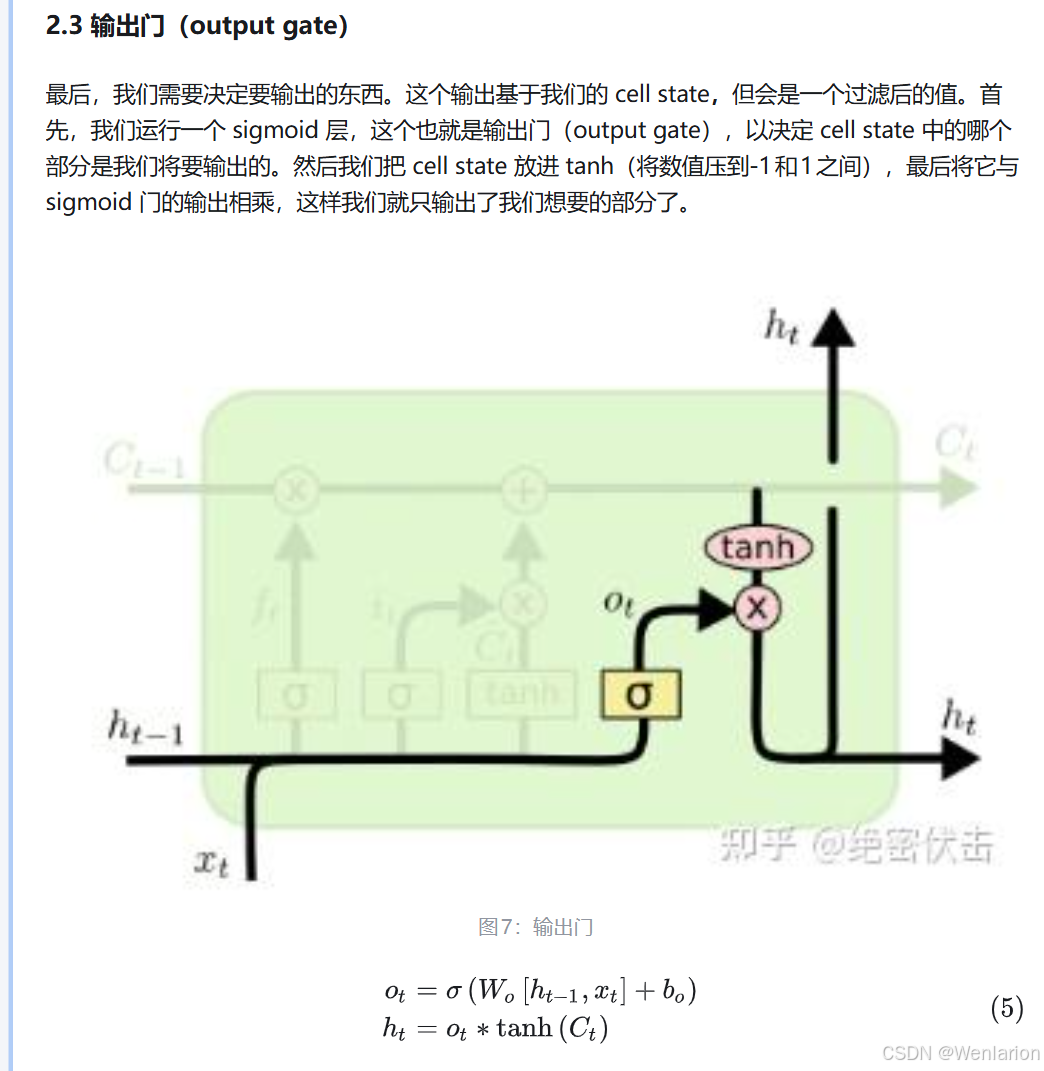
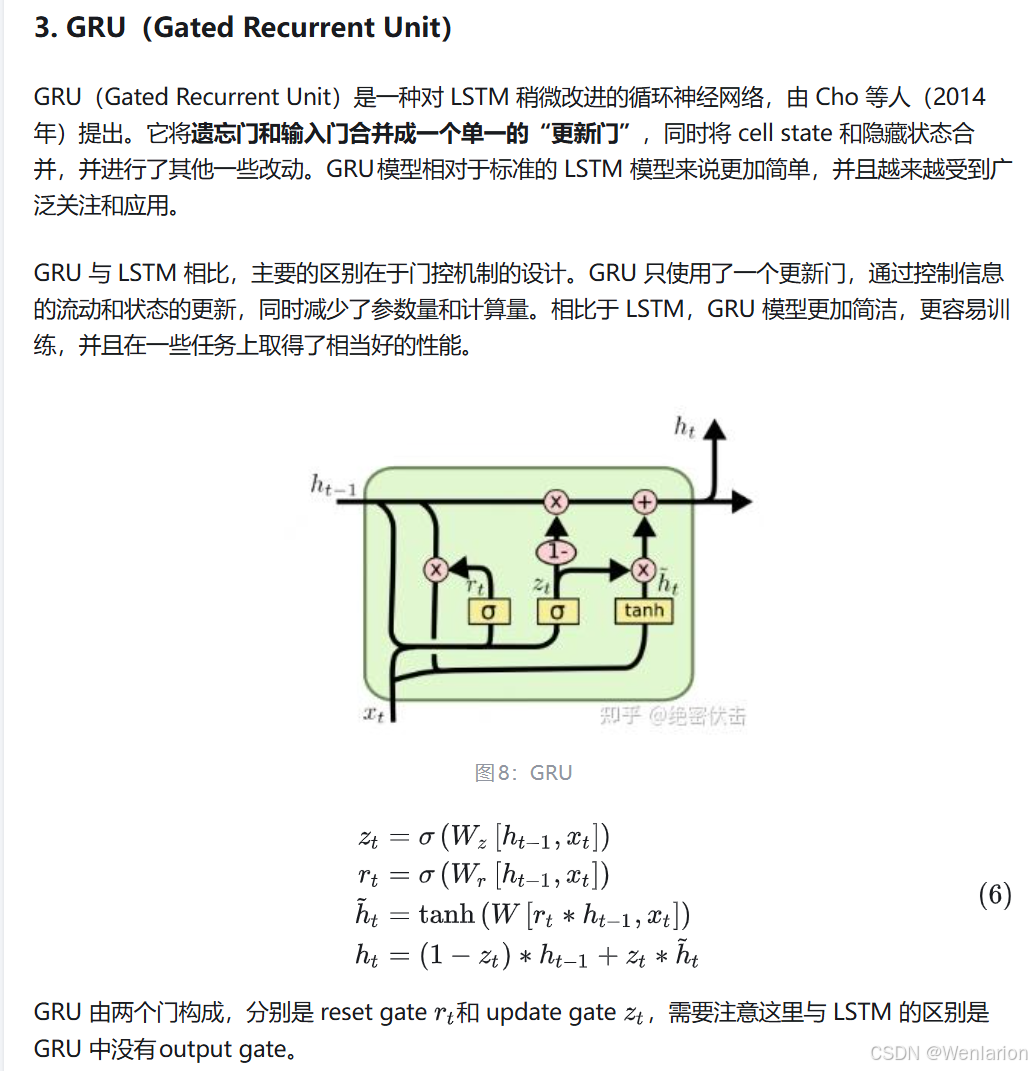
1.3.3 GRU
1.3.4 Transformer
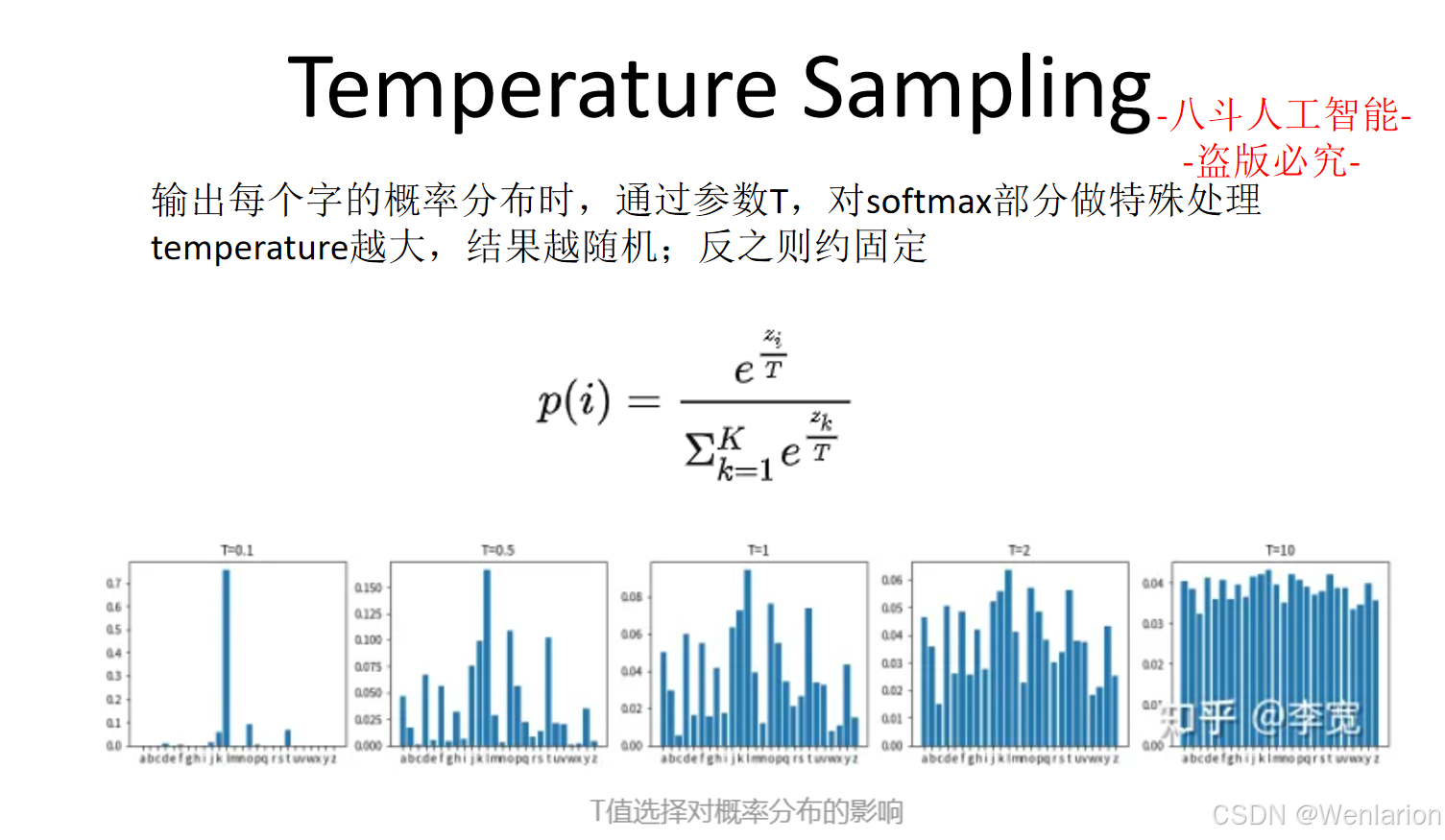
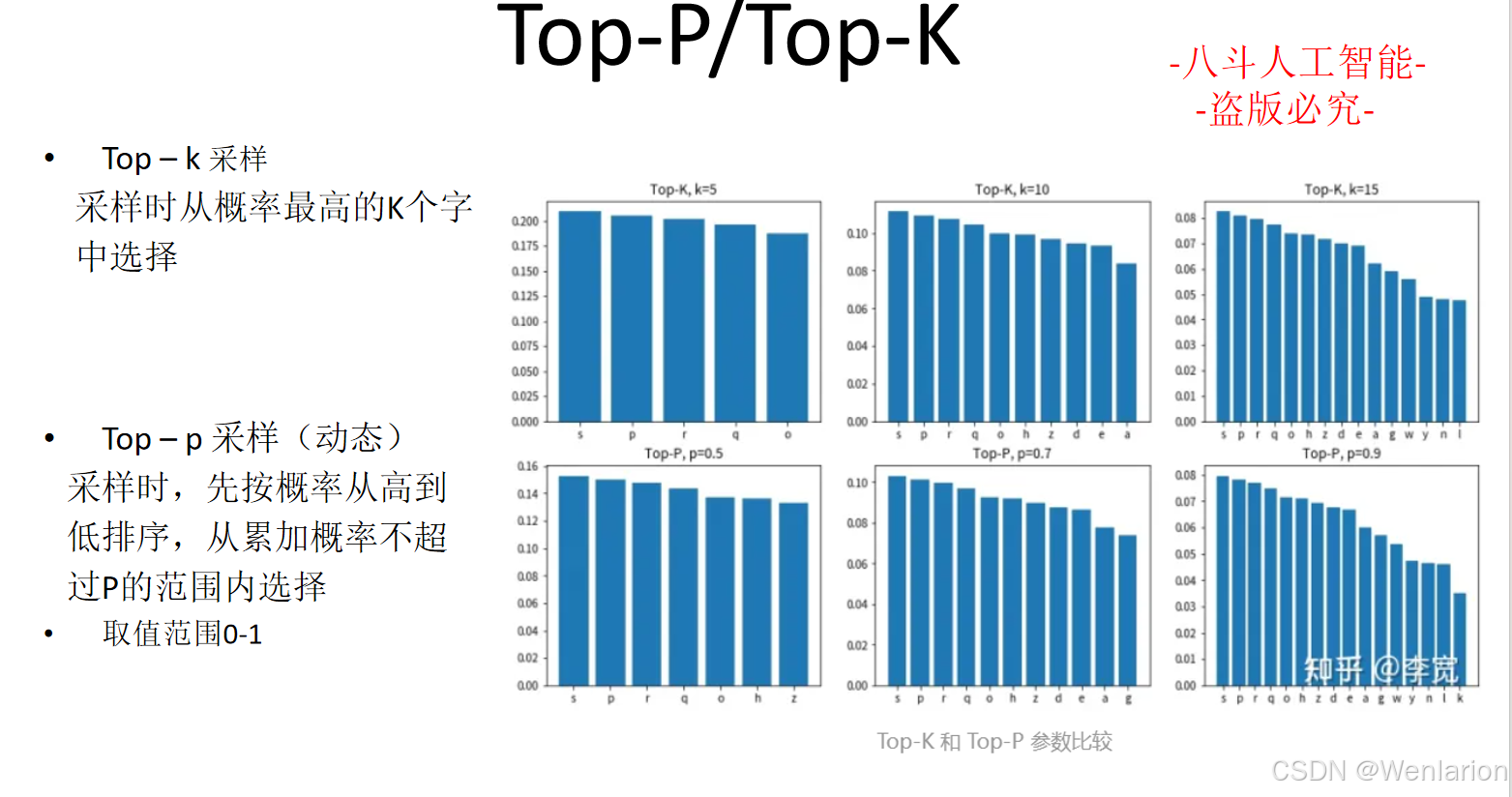
在大语言模型(LLM)中,Transformer Block 是最核心、也是最常被提及的计算单元。无论是 GPT、LLaMA,还是各种衍生模型,本质上都是在不断堆叠同一种 Block。
需要先澄清的是,Transformer Block 本身只是“一层如何计算”的问题;而我们通常所说的 Transformer 模型或大模型架构,则是在此基础上,围绕 Block 的堆叠方式、信息流动方式以及训练与推理范式所形成的整体设计。
本文将围绕一个问题展开:
Transformer Block 到底在“做什么”,以及围绕这一计算单元的设计,如何一步步演进成今天的大模型架构?
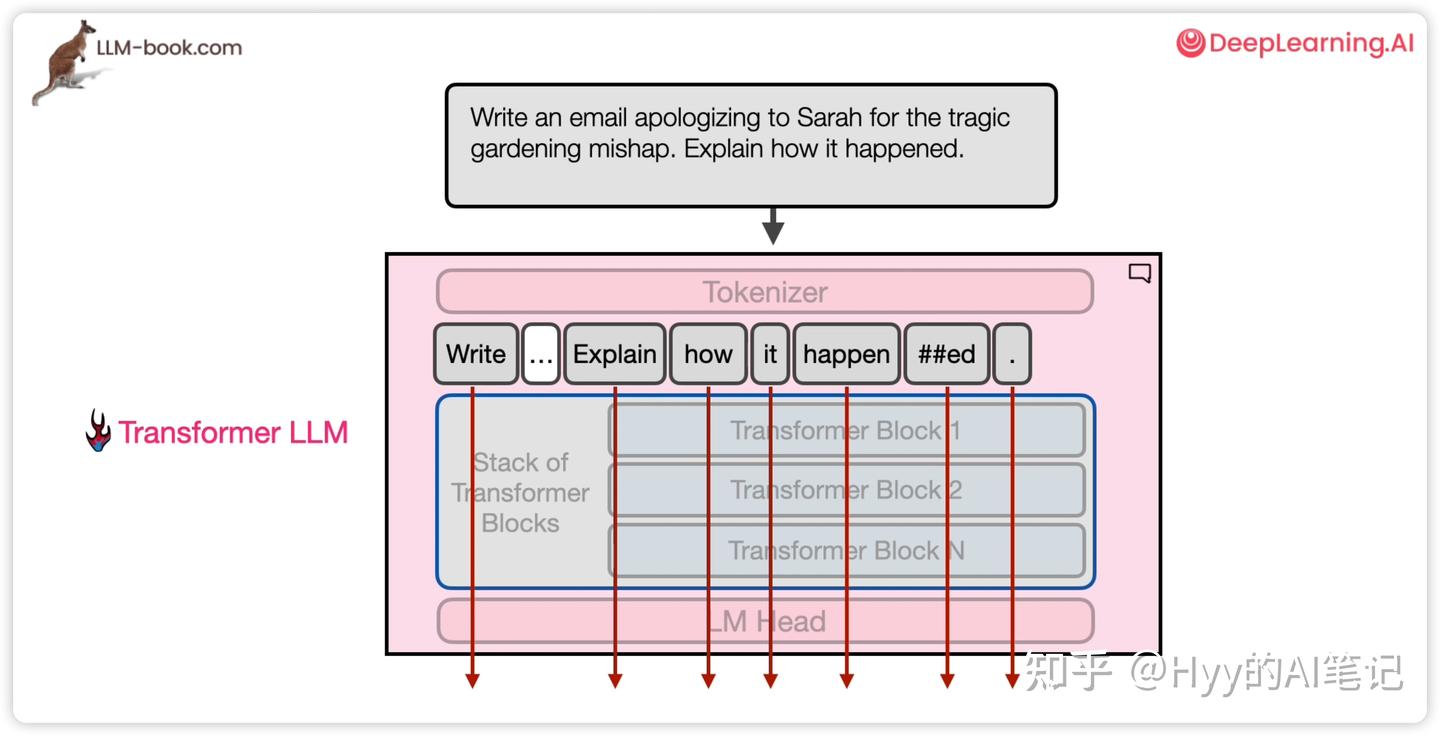
Transformer Block 的整体流程
Transformer 模型首先通过 分词(Tokenization)将文本拆分为一系列 token,并将每个 token 映射为向量表示(Embedding)。
例如,文本:
“the Shawshank”
Tokenizer 会将其拆分为两个 token:the 和 Shawshank,模型通过 embedding 查表,得到对应的向量表示。这些向量随后被送入由多个 Transformer Block 组成的堆栈中逐层处理。
每一层 Transformer Block 都会:
-
接收上一层输出的向量
-
对每个 token 进行一次完整的上下文建模
-
输出与输入维度相同的新向量表示
在 Decoder-only Transformer(如 GPT 系列)中,所有 Block 的结构和计算顺序是完全一致的。最终,prompt 中最后一个 token 的向量 会被送入语言建模头(Language Modeling Head),用于预测下一个 token。
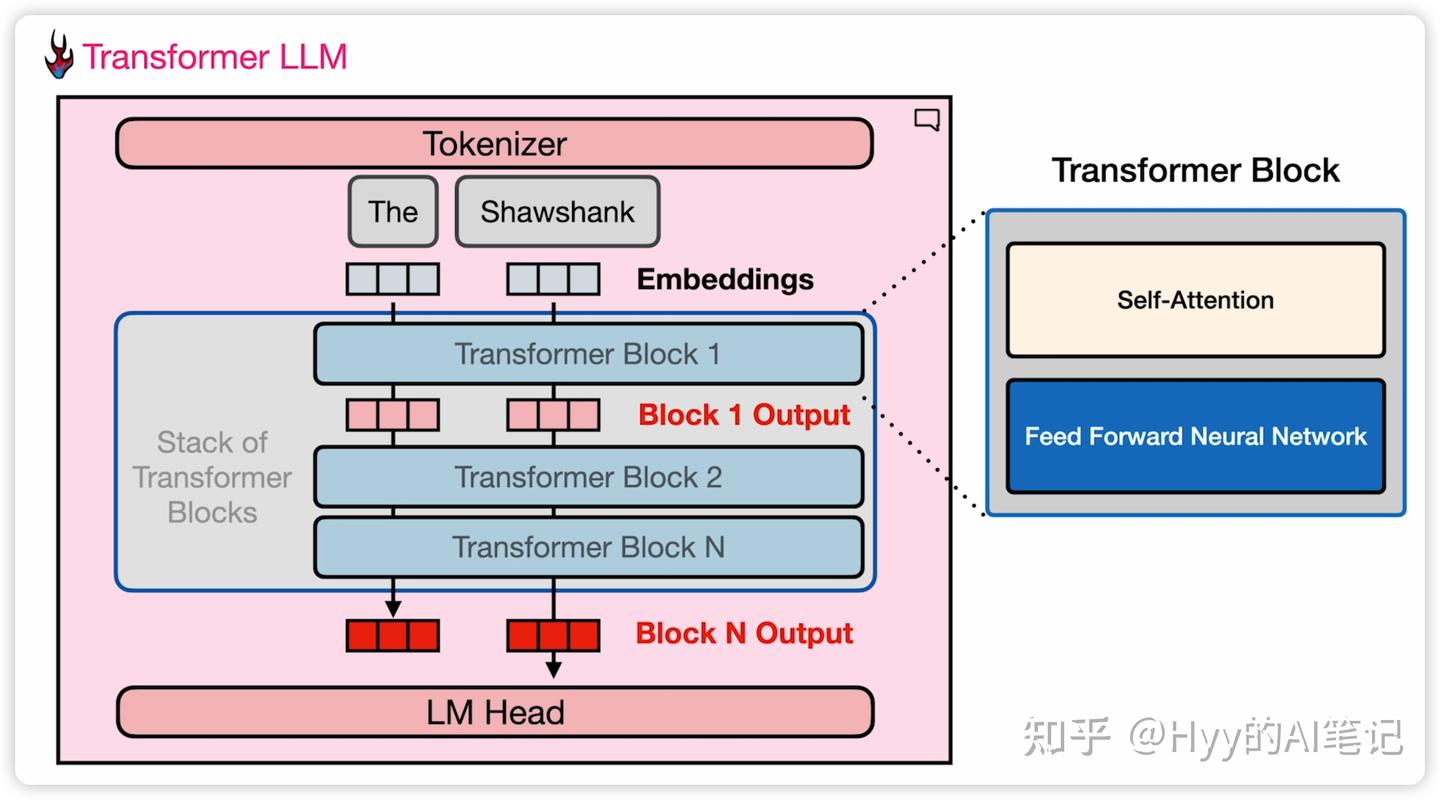
Transformer Block 的两个核心组件
在 Decoder-only Transformer 中,每一个 Transformer Block 主要由两个模块组成:
-
Self-Attention(自注意力)
它们共同构成了一个稳定的计算单元。
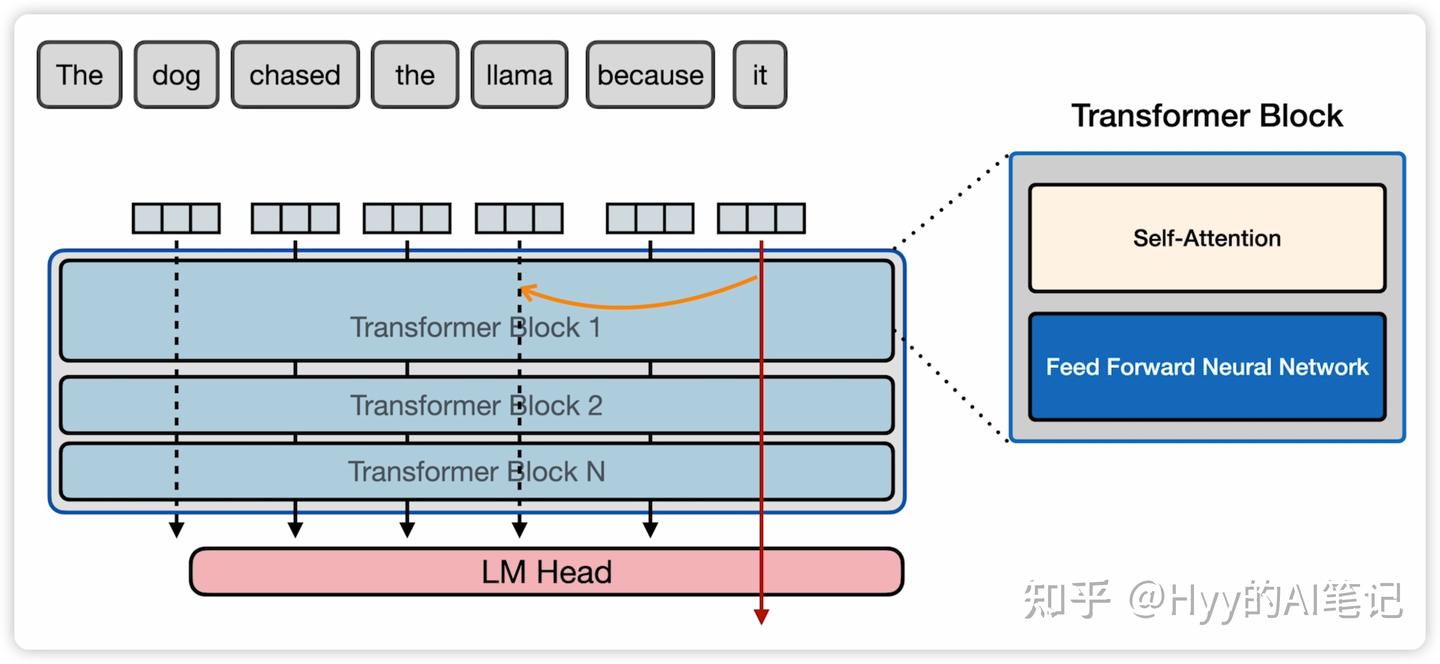
Self-Attention:上下文是如何被“看见”的
在《大模型发展史:一篇文章读懂语言模型演进》中我们提到过,自注意力机制的核心目标,是让模型能够在上下文中 动态选择并聚焦关键信息,从而解决长距离依赖和歧义理解的问题。
例如,句子:
“the dog chased the llama because it”
当模型处理到 “it” 这个 token 时,需要判断它指代的是 dog 还是 llama。如果上下文语义表明更可能指向 llama,那么在处理 “it” 时,自注意力机制就会将 llama 相关的信息更强地融入当前 token 的表示中。
这种能力在自然语言处理中被称为 指代消解(Coreference Resolution),而自注意力正是实现这一能力的关键机制之一。
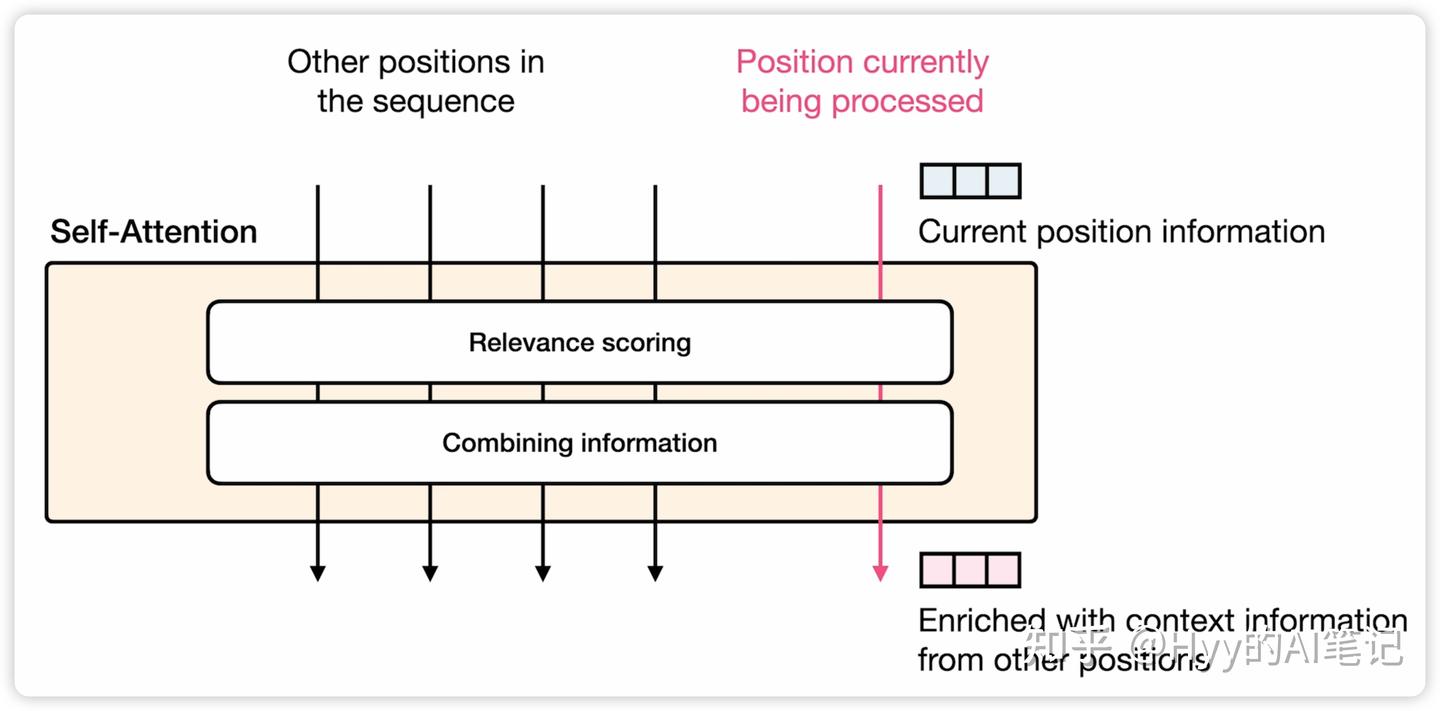
自注意力的两个核心步骤
从计算流程上看,自注意力可以拆解为两个阶段:
-
相关性打分(Relevance Scoring):判断当前 token 与上下文中其他 token 的相关程度
-
信息融合(Information Aggregation):将高相关性的 token 信息按权重融合进当前表示
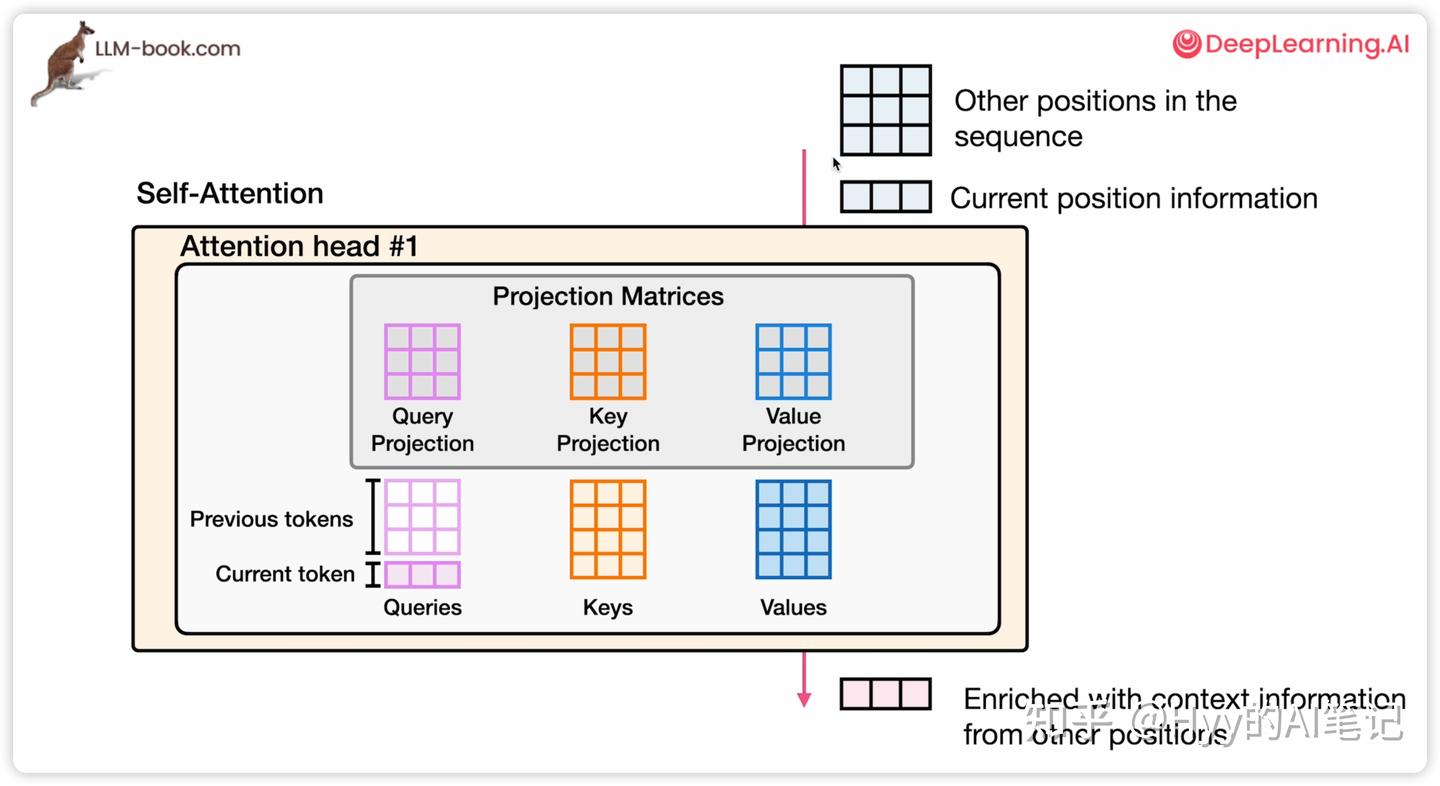
Q/K/V:相关性打分与信息融合
自注意力并不是直接作用在输入向量上,而是先通过三组线性投影矩阵:
-
Query Projection Matrix(查询投影矩阵)
-
Key Projection Matrix(键投影矩阵)
-
Value Projection Matrix(值投影矩阵)
将每个 token 映射为三种不同用途的向量:
-
Query(Q):当前 token 想从上下文中获取什么信息
-
Key(K):当前 token 能为其他 token 提供什么样的匹配线索
-
Value(V):当该 token 被关注时,真正参与信息融合的内容
可以将自注意力类比为一次“向量化检索”:
-
Query:查询条件
-
Key:索引
-
Value:数据本身
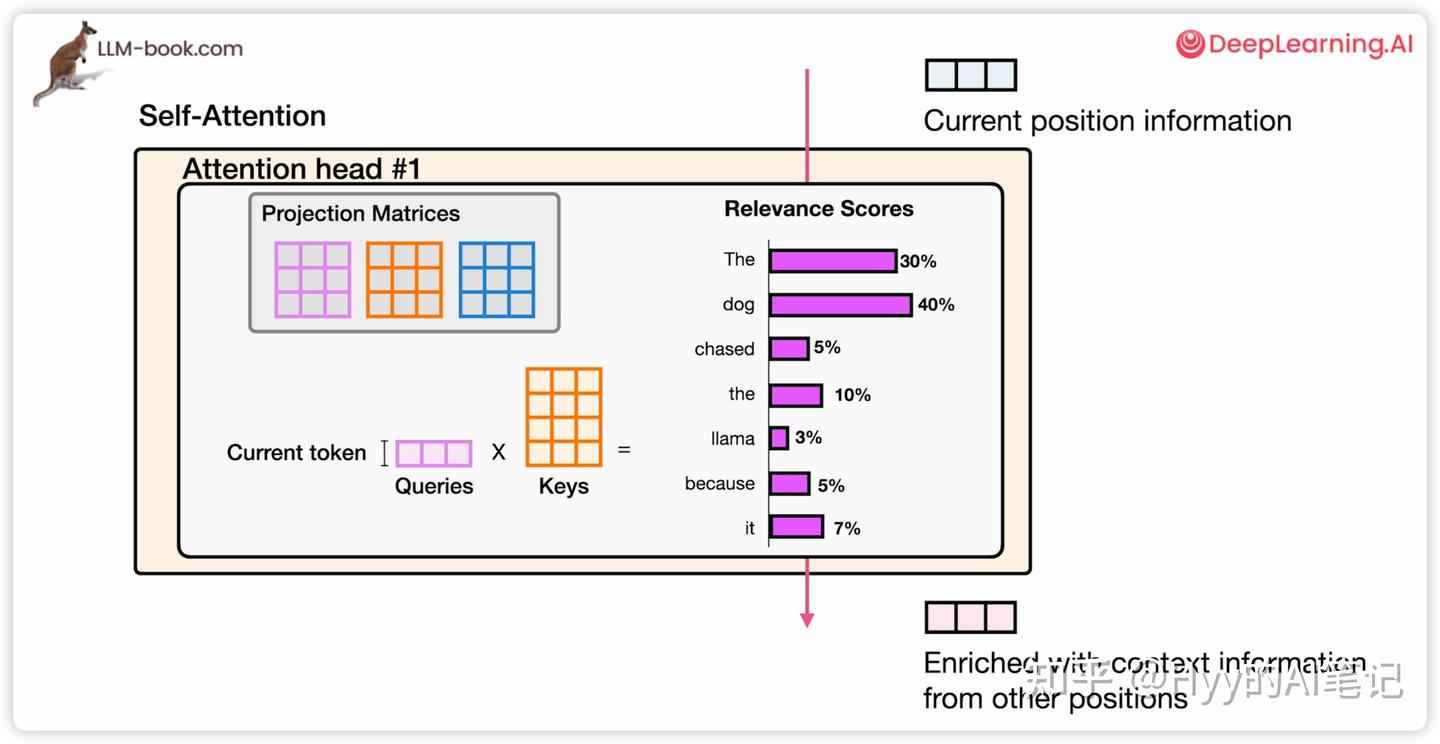
在相关性打分阶段,模型会对 Query 与所有 Key 做点积计算,并经过归一化(通常是 softmax),得到一组注意力权重。
随后,每个 Value 向量会与对应权重相乘,所有加权后的 Value 相加,形成自注意力层的输出。
例如:
-
“the”、“dog” 的权重最高
-
那么它的 Value 向量在最终结果中占比最大
-
其他 token 的贡献会因为权重较小而被弱化
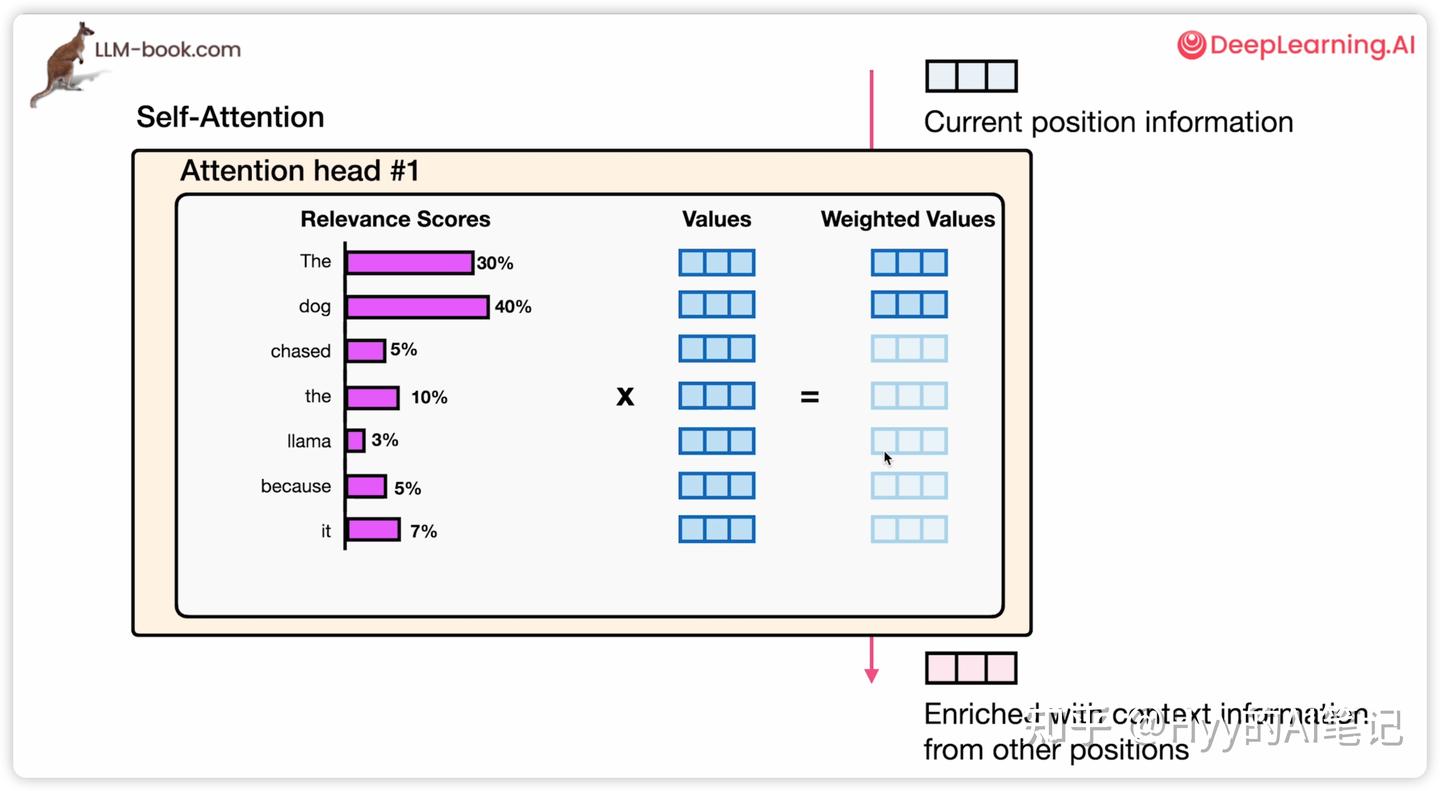
通过这种方式,自注意力机制实现了对上下文信息的动态选择与融合:不仅决定“看谁”,还决定“怎么把看到的信息整合到当前 token 表示中”。
详细公式展开可以阅读 《Attention 并不是“理解”:从公式角度拆解注意力机制》
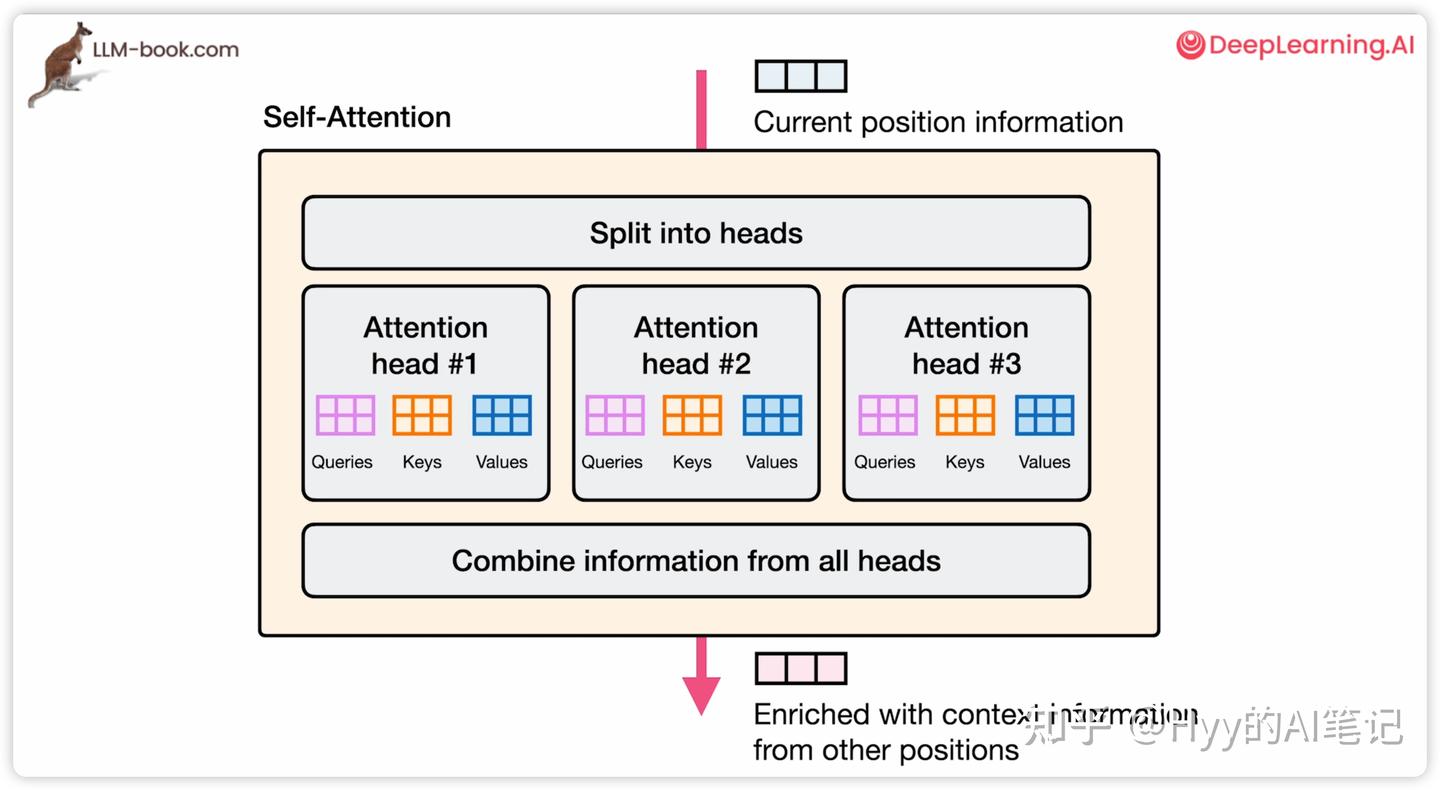
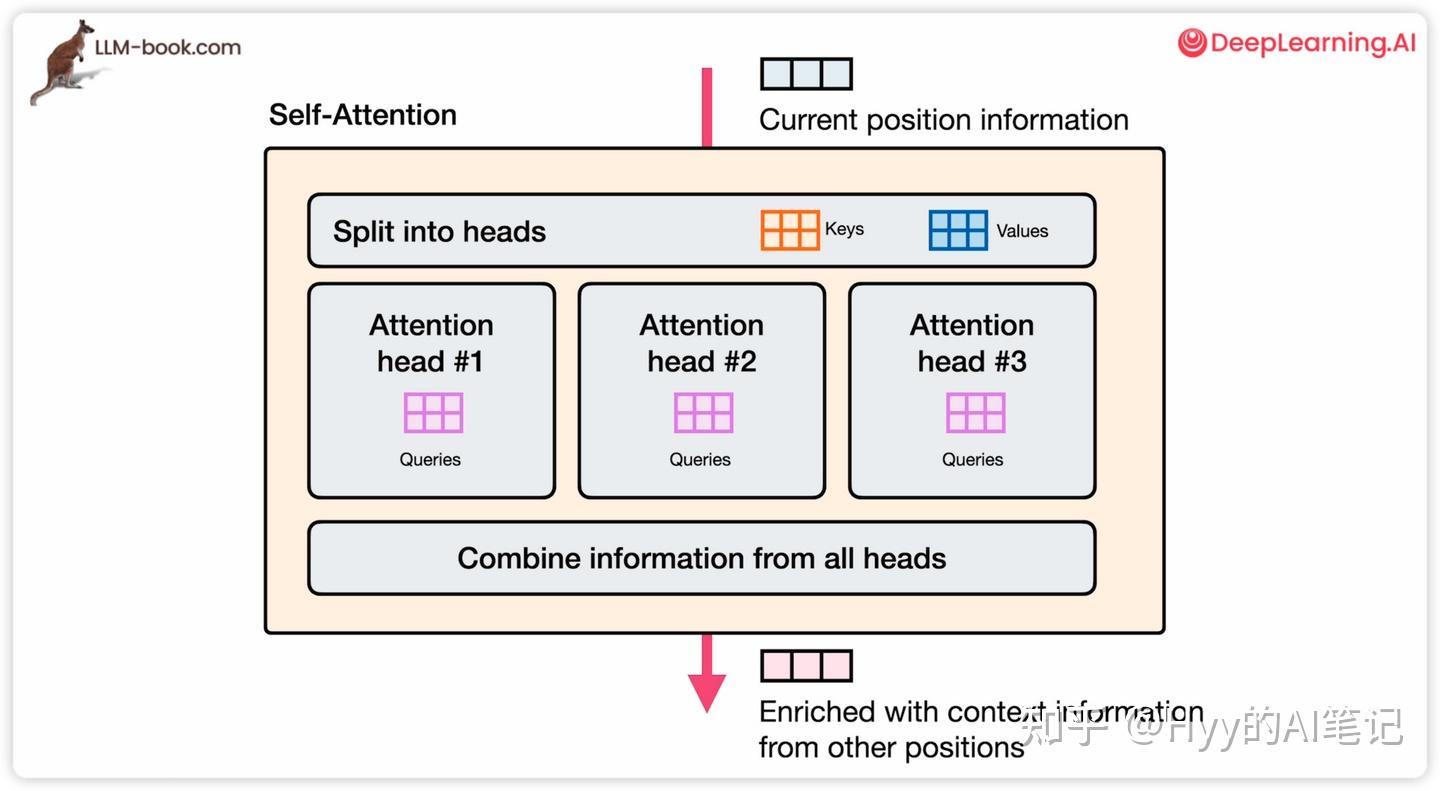
多头自注意力(Multi-Head Self-Attention)
多头自注意力的核心思想是:
让模型在多个不同的子空间中,并行关注不同类型的上下文关系。
每个子空间通过独立的 Q/K/V 投影矩阵形成,每个注意力头只在自己对应的子空间计算注意力权重。
最终,所有注意力头的输出会被拼接,并通过线性映射得到自注意力层的输出,然后送入后续的前馈神经网络(FFN)或残差连接中。
Self-Attention 的工程化优化
在工程实践中,自注意力通常是计算和显存开销最大的部分,因此出现了多种优化方案。这些方法并不是替代自注意力原理,而是在效率与效果之间做权衡。
Multi-Query Attention(MQA,多查询注意力)
所有注意力头共享同一组 Key / Value 投影矩阵,以减少参数量和计算成本,可以理解为一种 参数压缩 技术。
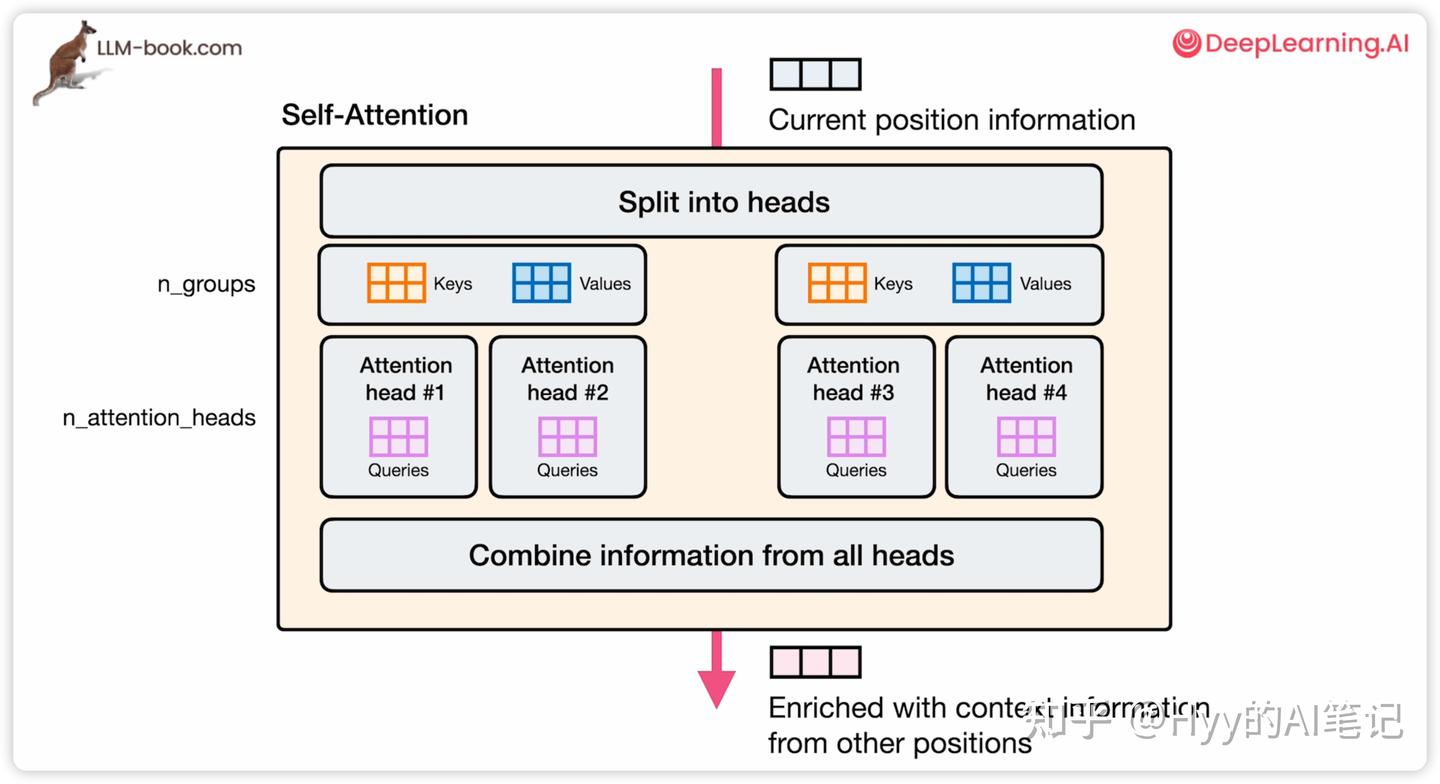
Grouped Query Attention(GQA,分组查询注意力)
将注意力头分组,每组共享一组 Key / Value,在效率和表达能力之间取得平衡。许多现代大模型都采用了这种方案。
通常用以下参数描述:
-
n_groups:分组数量
-
n_attension_heads:注意力头总数
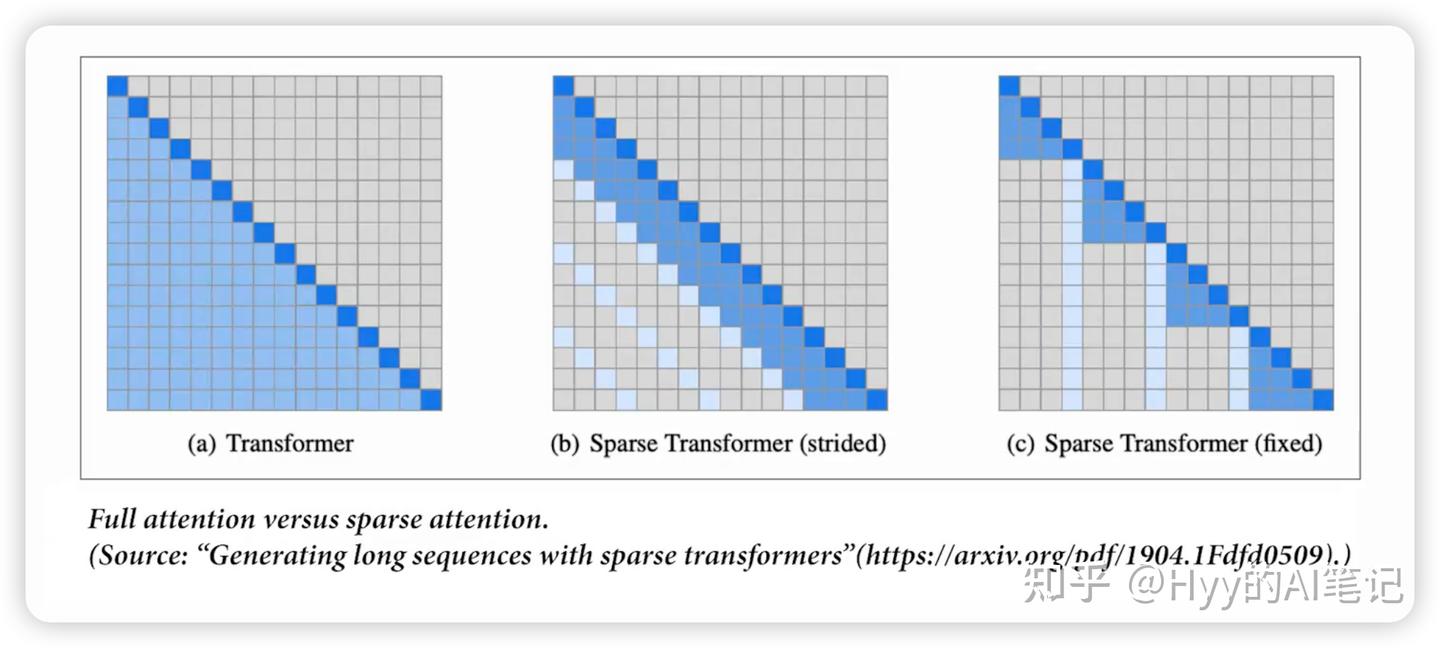
Sparse Attention(稀疏注意力)
对比 Full Attention(完整自注意力,每个 token 可以关注它允许看到的所有 token)而言,稀疏注意力通过限制每个 token 的关注范围,在降低计算和显存开销的同时,尽量保留对关键上下文的捕获能力。
常见策略包括:
-
Strided / Pattern-based Sparse Attention:关注最近几个 token,同时也关注某些固定位置
-
Fixed Window Attention:超过某个位置后,只能关注固定窗口内的 token
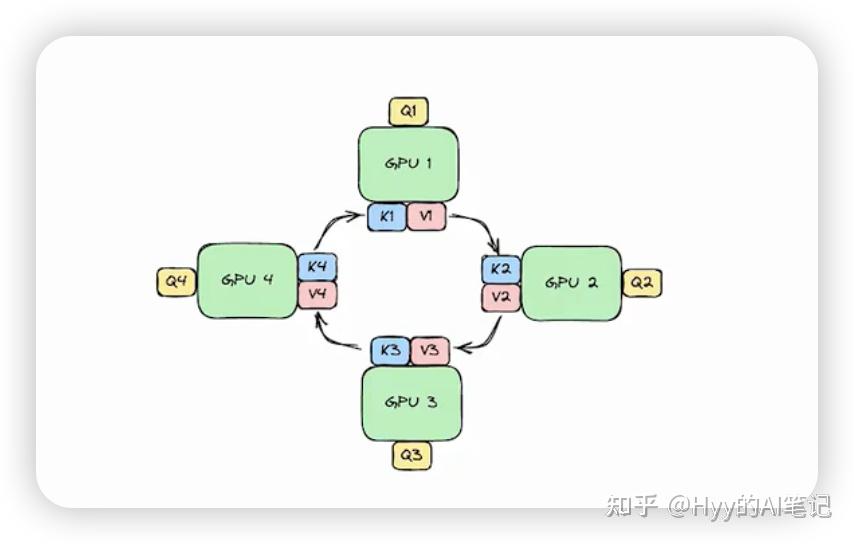
Ring Attention(超长上下文)
用于支持十万级甚至百万级 token 的上下文建模,是近年来长上下文模型的重要方向。
具体可以查看:
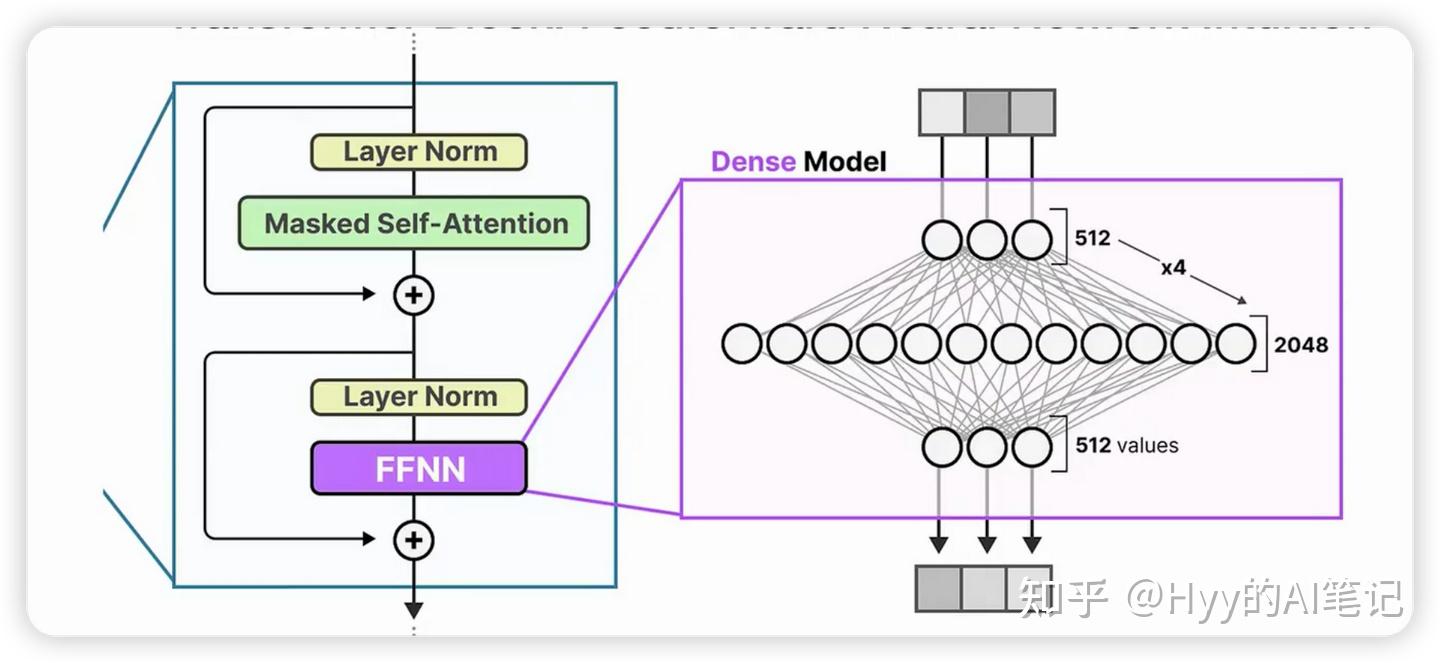
Feed-Forward Neural Network(FFN):对信息进行“加工”
如果说自注意力负责 让 token 看见上下文,那么 FFN 的作用是:
在此基础上,对每个 token 的表示进行非线性变换和增强。
换句话说,FFN 并不负责建模 token 之间的关系,而是负责 “加工”已经包含上下文信息的 token 表示。
举个例子,输入是:
“the Shawshank”
自注意力机制会让模型意识到 Shawshank 在当前上下文中具有强语义指向性;而在大量训练数据中(如互联网或维基百科),Shawshank 往往和 redemption 一起出现。
在这种情况下,FFN 会将已经捕获到的上下文关系,转化为更有利于预测下一个 token 的内部特征表示。最终,这些特征会被送入语言建模头(Language Modeling Head),用于生成下一个 token(例如 redemption)。
前馈神经网络的结构特点
在结构上,FFN 通常采用:
-
第一层:将输入向量的维度扩展到更高的维度
-
中间部分:通过非线性激活函数对信息进行变换
-
最后一层:再将向量维度压缩回原来的大小
这种“先扩展、再压缩”的结构,并不是为了改变序列长度,而是为了:
在更高维的空间中,对信息进行重组、组合和抽象。
FFN 与模型能力的关系
从工程和经验角度来看:
-
FFN 通常是 Transformer 中参数量最大的部分,尤其在大模型中,占据了大部分计算和存储资源。
-
它是模型内部编码和组合抽象特征的核心模块。通过大规模训练,FFN 会将各种语言模式、事实关联、统计规律以 分布式方式写入网络参数中,而不是存储在单独的“知识库”里。
这意味着:
-
代码生成能力:模型可以理解和生成符合语法结构的代码
-
知识记忆与推理能力:模型能够在推理中利用大量事实关联和统计模式
-
语言风格和连贯表达:模型可以保持上下文一致的风格和逻辑
换句话说,FFN 负责将自注意力捕获到的上下文信息 加工、抽象、强化,为后续的语言建模输出提供“高阶特征”。
这也是为什么现代工程优化,如 Mixture of Experts(MoE),通常针对 FFN 进行稀疏化处理,而不是替换自注意力结构:FFN 承载了大模型的核心能力。
现代 Transformer 的结构变化
随着模型规模不断增大,Transformer Block 的设计逐渐围绕一个核心目标展开:
更深、更稳、更高效地训练和推理
现代 Transformer 在结构上做出了一系列关键调整。
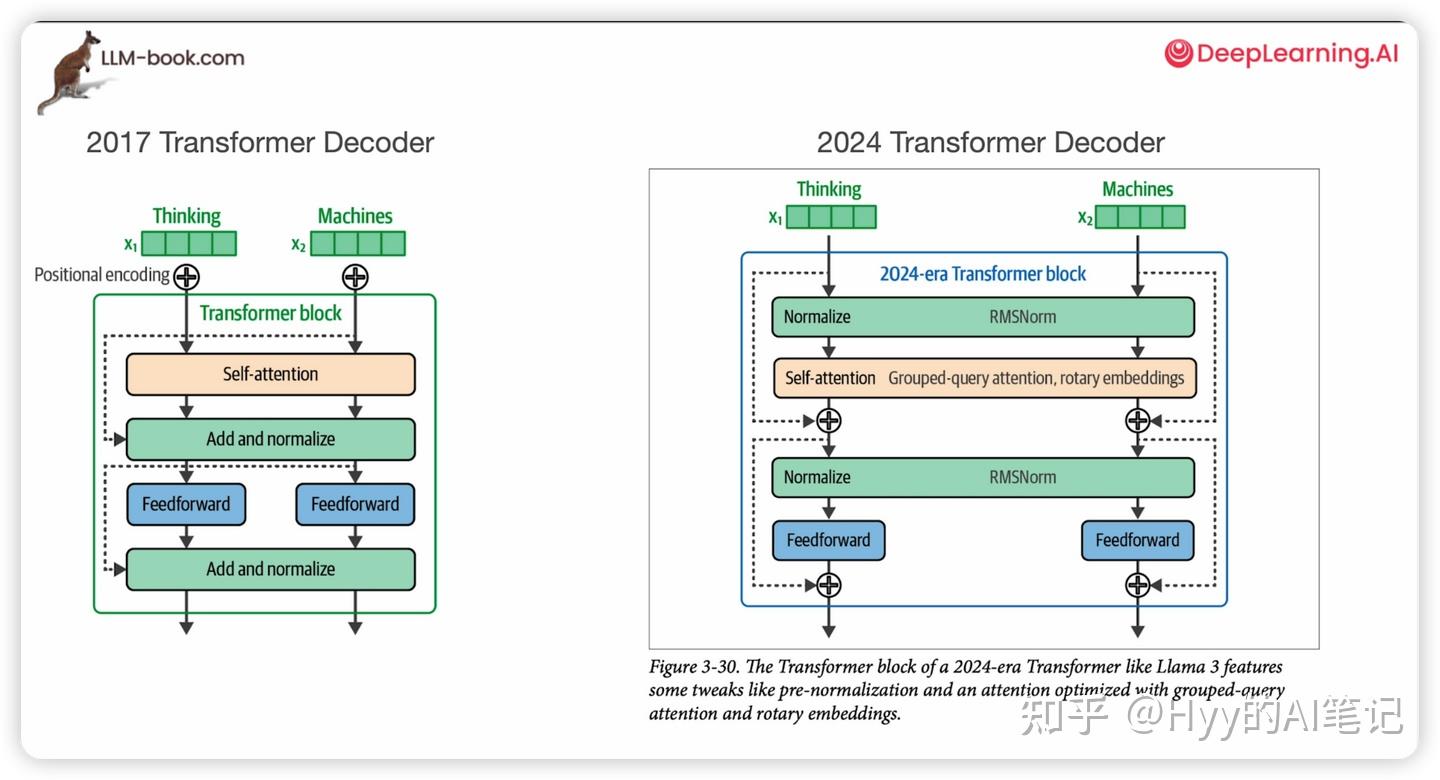
Pre-LayerNorm(Pre-LN)
首先是 Layer Normalization 位置的变化。
在现代大模型中,LayerNorm 通常被移动到自注意力层(Self-Attention)和前馈神经网络(FFN)之前,即采用 Pre-LayerNorm(Pre-LN) 结构。
这种设计可以直观地理解为:
先将输入“整理好”,再交给复杂模块处理,而不是等模块计算完成后再去纠正数值分布。
从工程角度来看,Pre-LN 的一个重要优势在于:残差连接路径上的信号不再被 LayerNorm 干扰,从而使梯度能够更加稳定、直接地在深层网络中传播。
大量实践表明,Pre-LN 结构可以显著改善深层 Transformer 的训练稳定性,使模型能够可靠地堆叠到数十甚至上百层。因此,Pre-LN 已经成为当前主流大模型的标准配置。
注意力机制的工程化改进
变化不仅发生在结构层面,也体现在 注意力机制本身的工程优化 上。
在保证模型效果的前提下,现代模型通常会在自注意力中采用 分组查询注意力(Grouped Query Attention, GQA)。这种设计在实践中可以显著降低计算量和显存占用,尤其是在模型参数规模和上下文长度不断增大的场景下,成为一种性价比极高的工程优化方案。
与此同时,大多数现代 Transformer 还会使用 旋转位置编码(Rotary Position Embeddings, RoPE)。
与传统的绝对位置编码不同,RoPE 将位置信息直接融入到自注意力的计算过程中,使模型能够以更自然的方式建模 相对位置信息。这使得模型在面对更长上下文时,通常具备更好的泛化能力,也更符合实际推理场景的需求。
残差连接:始终存在但同样关键的设计
最后,还有一个从 Transformer 诞生之初就存在、但在深层模型中尤为关键的设计:残差连接(Residual Connections)。
残差连接可以理解为为信息在网络中保留了一条“直达通道”。即使中间层的表示学习得不充分,输入信息仍然可以直接传递到后续层。
在模型层数不断加深的背景下,这种设计有效缓解了梯度消失和信息衰减问题,使 Transformer 能够稳定地向更深层扩展,是大规模模型能够成功训练的重要基础之一。
旋转位置编码(RoPE)
语言建模(Language Modeling)的核心目标,是通过大规模语料进行基础训练(Base Training),也就是我们常说的 “下一个 token 预测”。模型通过不断预测下一个 token,逐步学会语言的统计规律和上下文依赖关系。
正是这种训练方式,决定了位置编码在大模型中的重要性。
在实际训练中,现代大模型往往支持很长的上下文长度(例如 8K、16K 甚至更长)。但单个文档通常很难填满完整上下文,如果简单地使用 padding 补齐,会造成大量无效计算。因此,工业界常见的做法是 将多个较短的文档拼接到同一个序列中进行训练,以提高 GPU 利用率。
这种训练方式通常不会显式告诉模型“这里是一个新文档”,而是通过特殊的边界 token(如 [SEP])以及注意力机制本身,让模型去学习上下文结构的变化。这也对位置编码提出了更高的要求:模型不仅需要知道“我在第几个位置”,更重要的是能够理解 token 之间的相对顺序和距离关系。
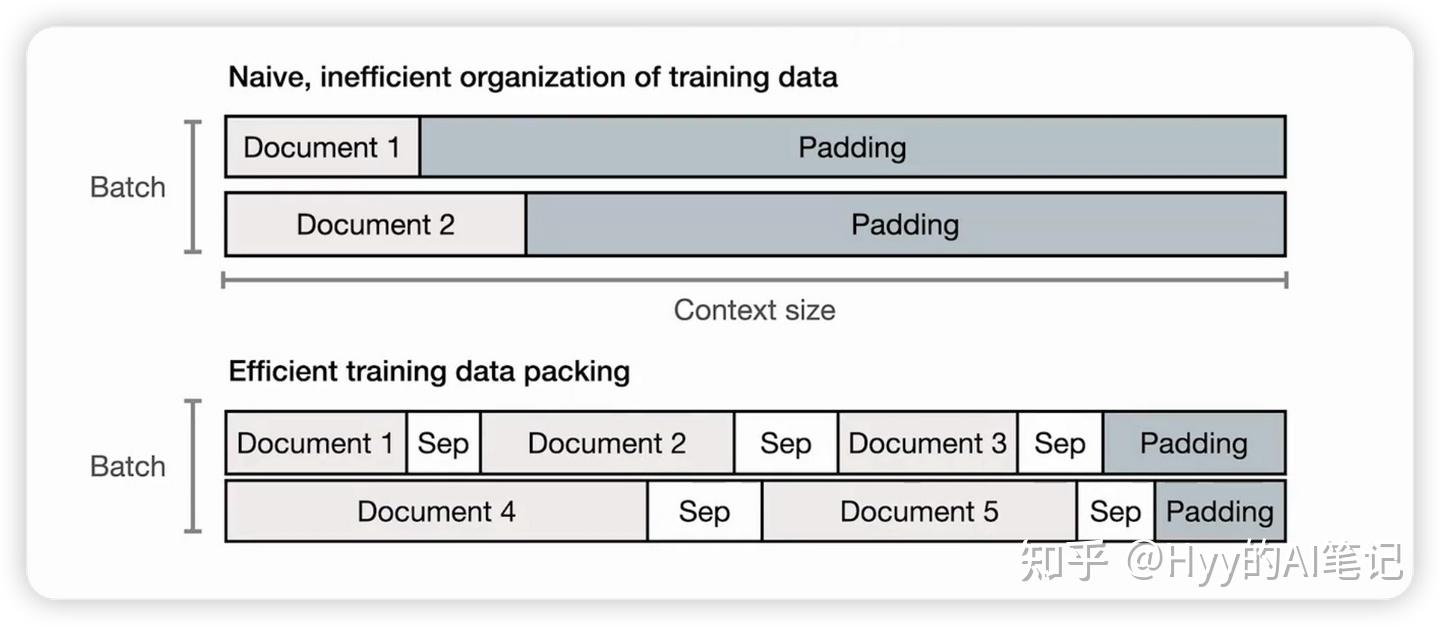
早期模型普遍采用 绝对位置编码,即为每个 token 分配一个固定的 position embedding,并与 token embedding 相加。这种方式只能表达“第 N 个位置”,难以自然建模 token 之间的相对距离,同时在长文本场景下的外推能力也较弱。
RoPE(Rotary Positional Embedding,旋转位置编码) 则采用了不同的思路。它并不是在 embedding 层直接叠加位置信息,而是在注意力计算之前,将位置信息通过“旋转”的方式注入到 Query 和 Key 向量中。这样一来,在计算注意力分数(Q·K)时,不同 token 之间的 相对位置差 会自然地体现在相关性结果中。
可以从一个直观的角度来理解:
RoPE 通过“旋转角度的差值”来编码 token 之间的相对位移。模型无需显式知道“距离是多少”,就能在注意力计算中感知谁在前、谁在后,以及它们之间相隔多远。
也正因为如此,RoPE 在长上下文建模以及多文档拼接训练等场景下表现得尤为稳定,并逐渐成为现代主流大模型中广泛采用的位置编码方案。
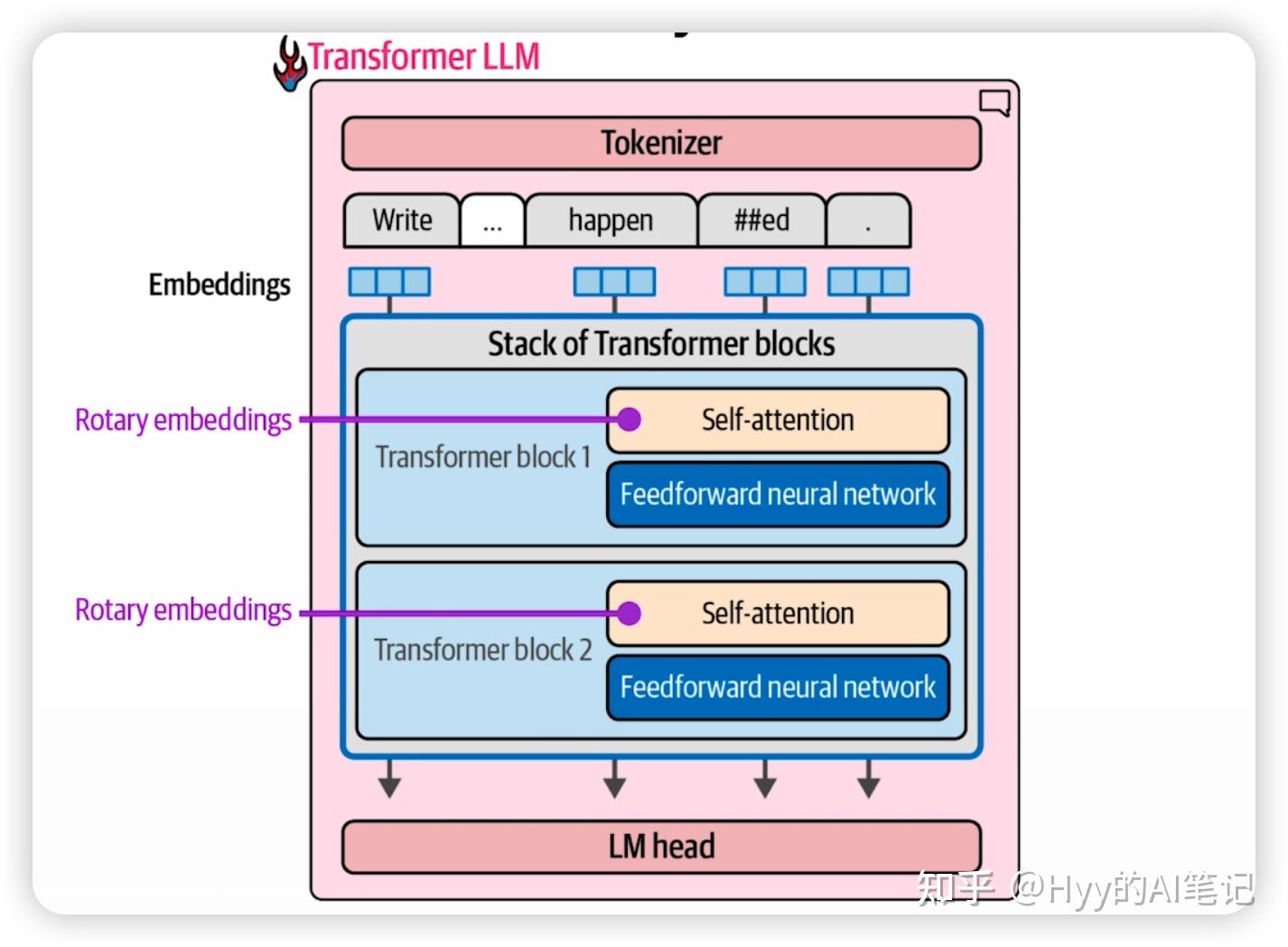
Mixture of Experts(MoE,专家混合)
近年来,大语言模型的一个重要发展方向是 Mixture of Experts(MoE)。它主要针对 Transformer 中 前馈神经网络 这一参数量最大的模块进行优化。
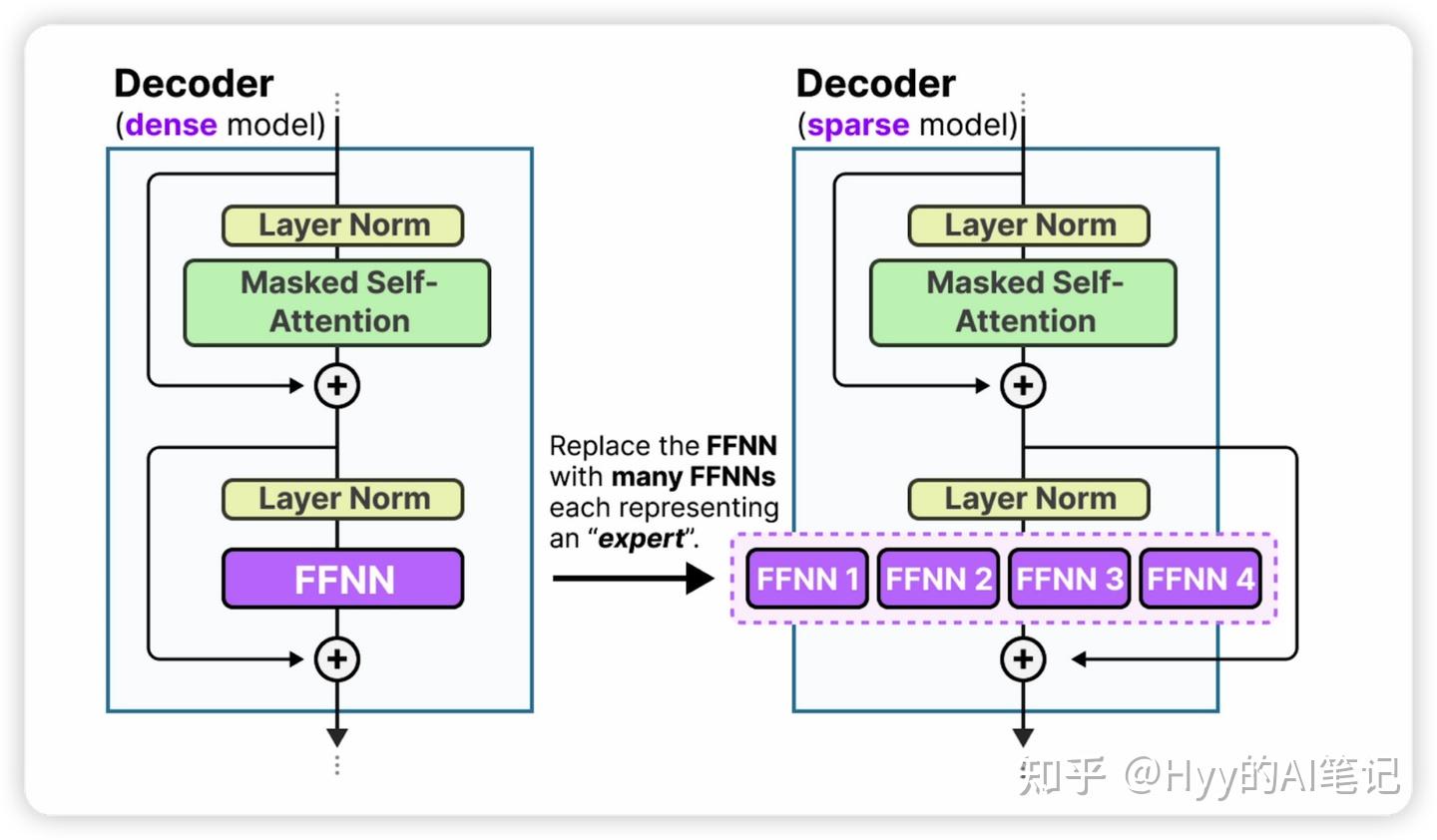
在传统 Transformer 中,FFN 是一个 稠密网络(Dense Network),也就是说,每个输入 token 都会激活网络中的全部参数。随着模型规模不断扩大,FFN 往往会比自注意力层更早成为 计算量和显存占用的主要瓶颈。
MoE 的核心思想是:将原本的一个大 FFN,拆分为多个专家网络(Experts),并让每个 token 只激活其中一小部分专家,从而实现稀疏计算(Sparse Computation)。
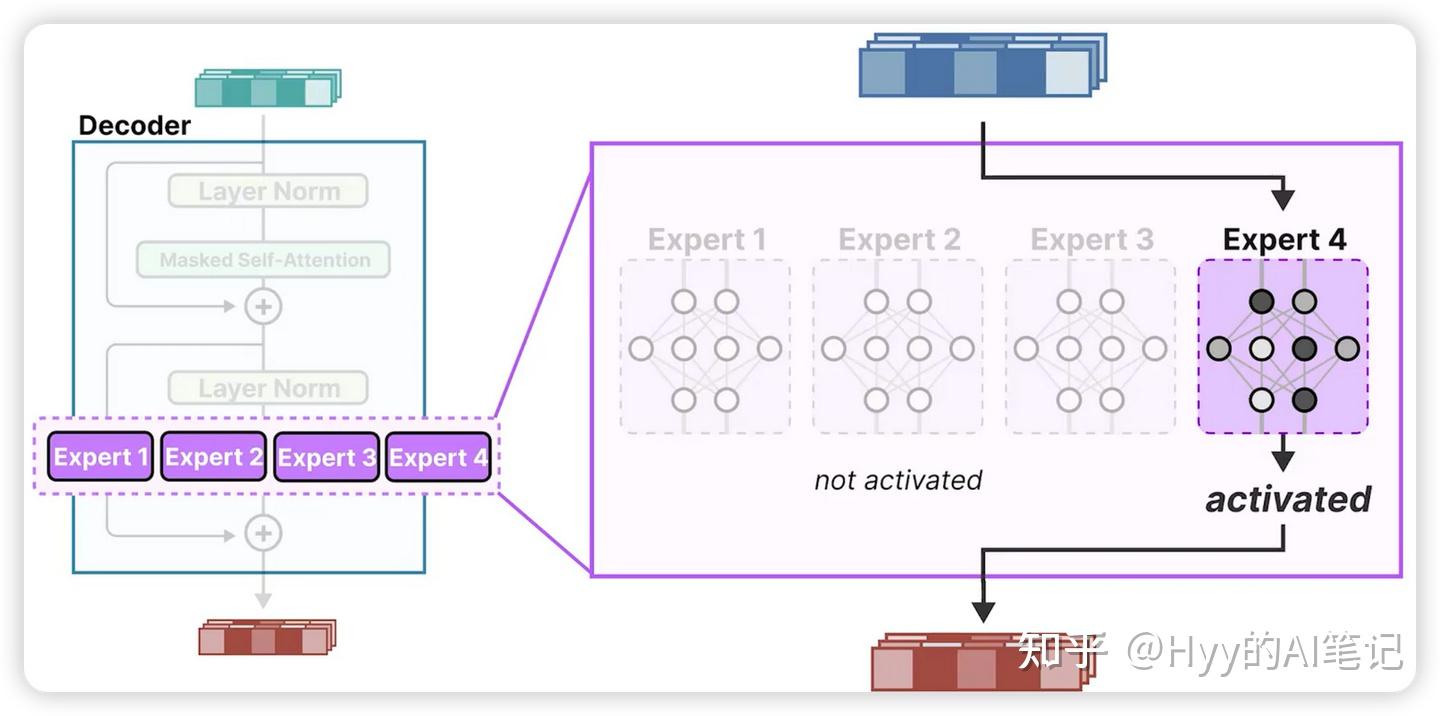
专家网络(Experts)
每个专家本质上都是一个完整的前馈网络,结构上与普通 FFN 类似。不同之处在于:它们不会在每个 token 上同时被激活。
在训练过程中,不同专家会逐渐对不同类型的 token 分布或上下文模式产生偏好,例如常见词、长依赖结构、特定语义模式等。这种分工并不是人工指定的,而是通过训练过程自然形成的。

输入 token 首先会经过路由器(Router),由路由器选择一个或多个专家进行计算,其余专家在该 token 上保持“休眠”。在层级上,每一层的专家选择是相互独立的,同一个 token 在不同层中可能会被分配给不同的专家。
当选择多个专家时,通常会对它们的输出进行加权求和或加权平均,由路由器分配更高权重的专家在最终结果中占据更大比例。
⚠️ 注意:专家本身不具备“知识库”或人类专家的语义,它们只是通过训练学习不同的向量模式和语言统计规律。
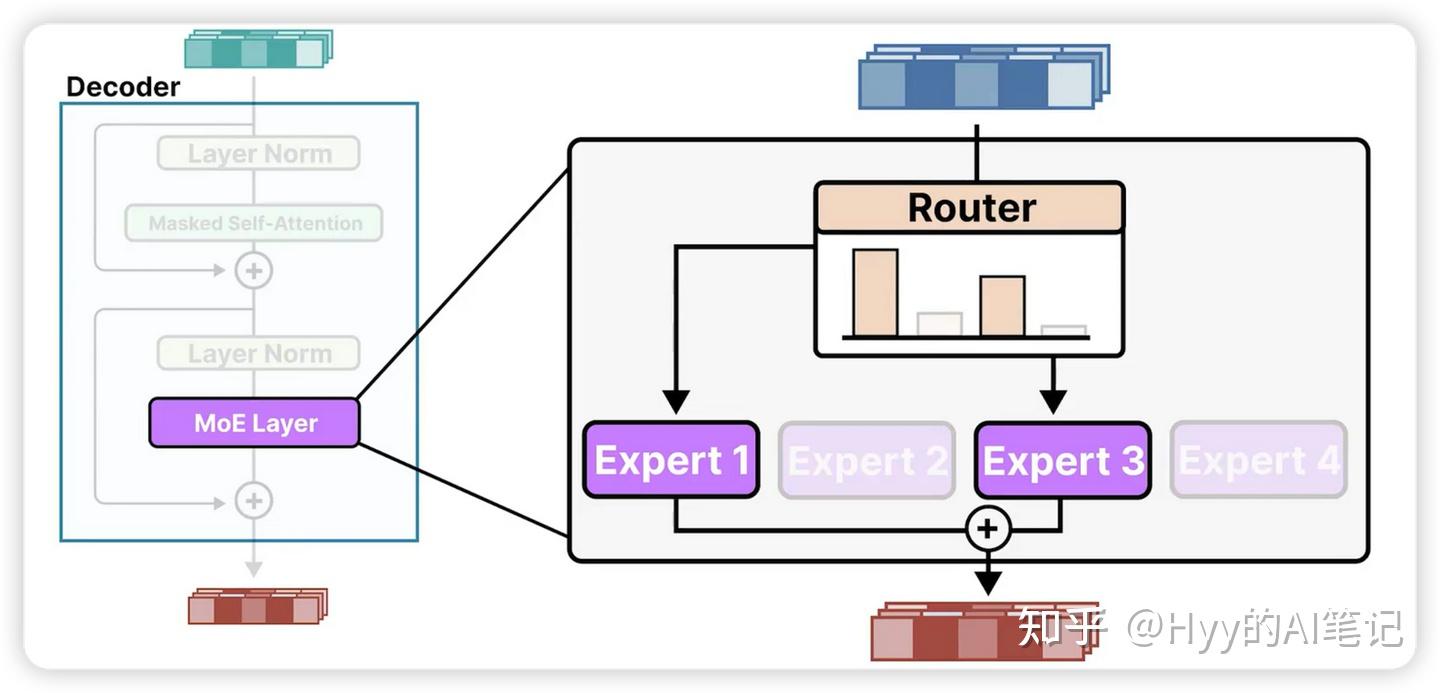
路由器(Router)
路由器的职责是:判断当前 token 更适合由哪些专家来处理。
在实现上,路由器通常是一个计算开销很小的网络(例如线性层或轻量 MLP),用于为每个专家打分,表示该专家对当前 token 的适配度。常见的路由策略包括:
-
Top-1 Routing:只选择得分最高的一个专家,计算效率最高
-
Top-K Routing:选择得分最高的 K 个专家,在效果和稳定性上更灵活
路由器的设计和训练是 MoE 中最具挑战性的部分之一。一方面,需要避免少数专家被频繁激活、其余专家长期闲置;另一方面,也要保证路由决策本身不会引入过高的额外开销。
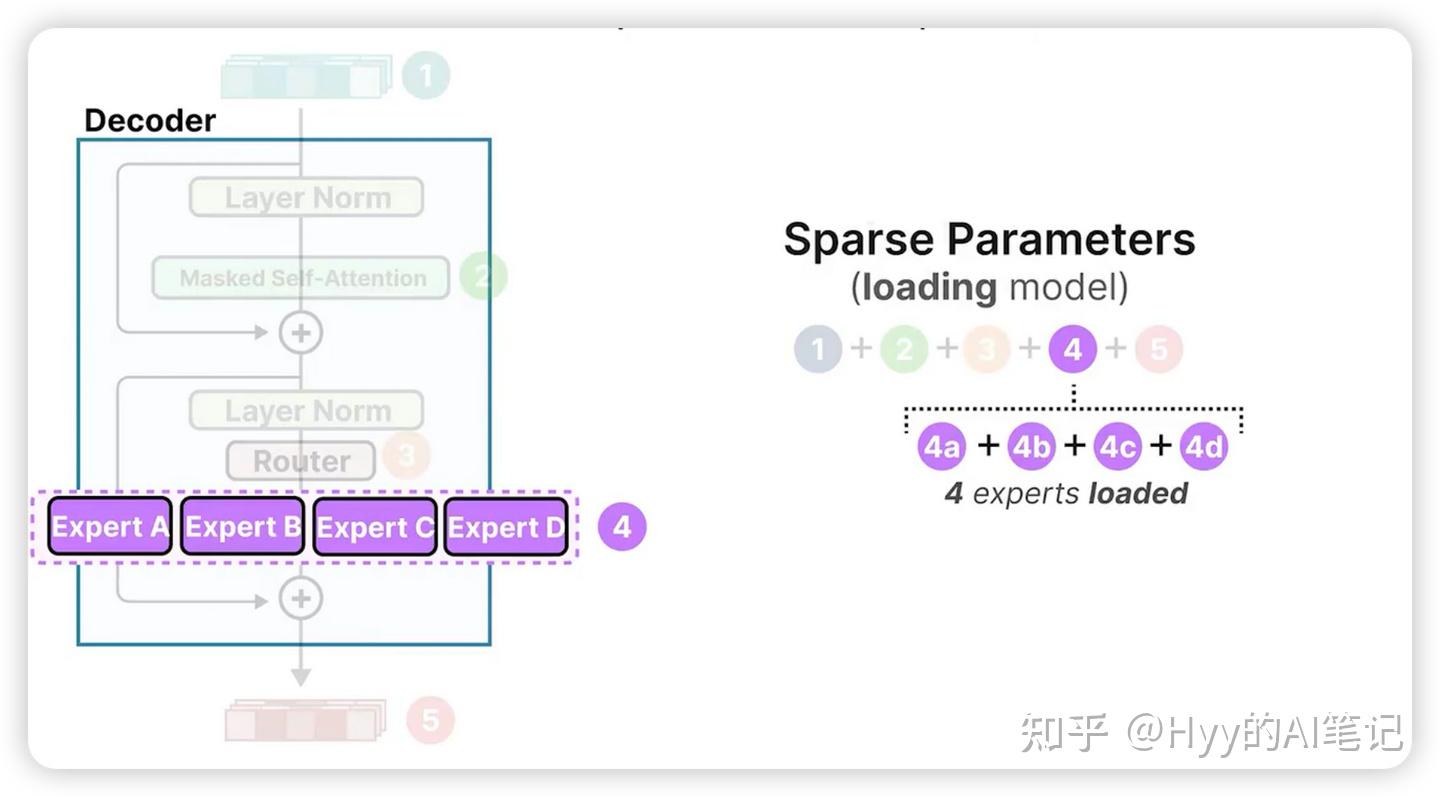
稀疏参数与活跃参数
在 MoE 模型中,通常会区分两类参数:
-
稀疏参数(Sparse Parameters)
-
活跃参数(Active Parameters)
稀疏参数(Sparse Parameters):模型加载时需要占用内存,但并非所有参数在推理阶段都参与计算
活跃参数(Active Parameters):在当前 token 上实际参与计算的参数数量
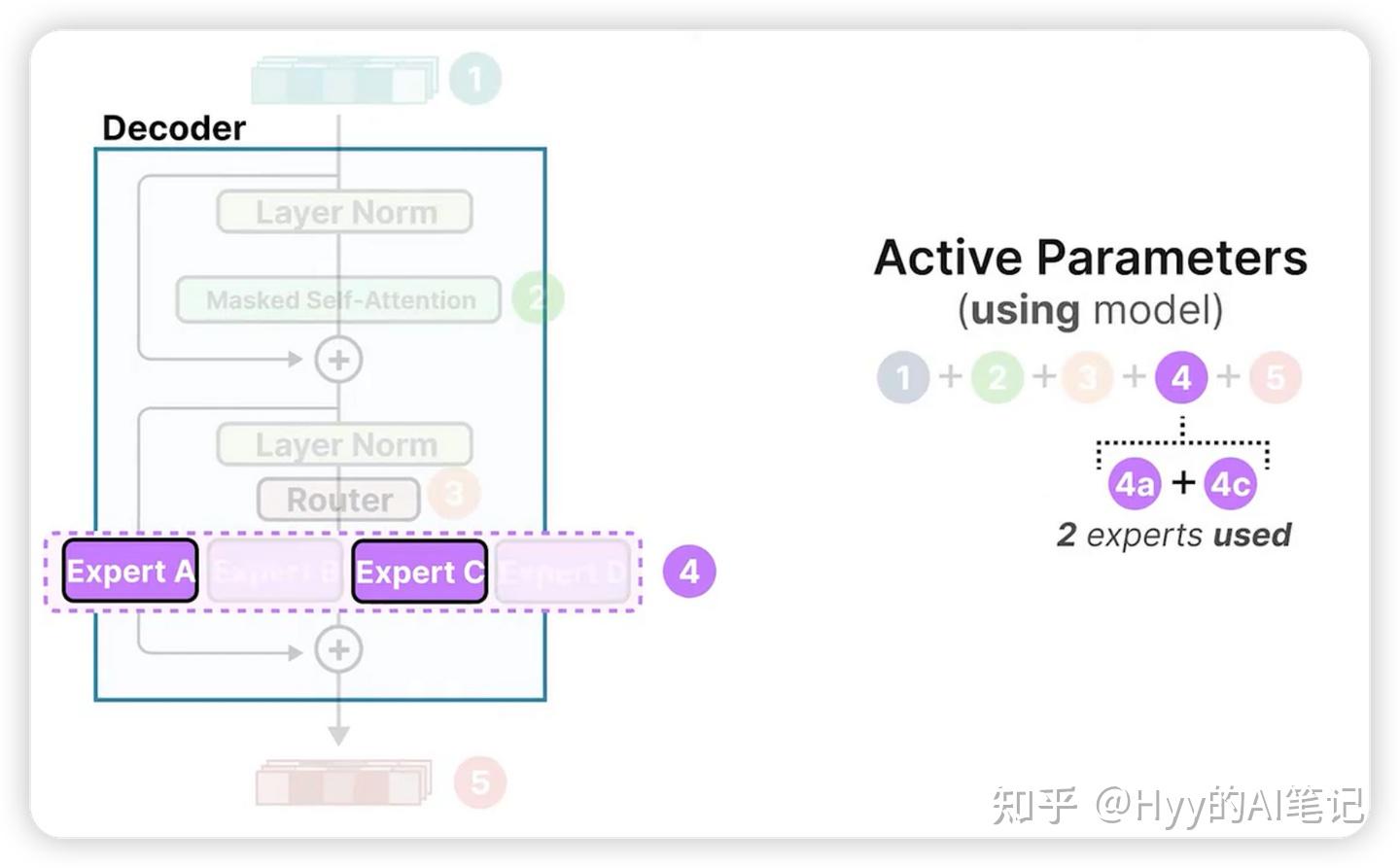
由于每个 token 只激活少量专家,MoE 模型在推理阶段的 活跃参数规模通常远小于总参数规模。这使得模型可以在保持极大参数容量的同时,将实际计算成本控制在可接受范围内。
1.4 自然语言处理基础相关论文和代码
一、词向量表示(NLP 表示学习基石,2013-2018)
解决传统独热编码稀疏、无语义的问题,将单词映射为低维稠密的实值向量,实现语义相似性量化,是所有深度学习 NLP 模型的输入基础,分静态词向量(单一词义)和动态词向量(上下文相关)两类。
1. Word2Vec:Efficient Estimation of Word Representations in Vector Space(ICLR 2013)
-
简介:词向量奠基之作,提出CBOW(连续词袋)和Skip-gram(跳字)两种高效训练方法,通过浅层神经网络学习词向量,首次实现低维词向量的高效生成,且向量满足语义相似性(如 king-man+woman≈queen),开启 NLP 表示学习时代,至今仍是轻量场景的标配。
-
代码地址:https://github.com/tmikolov/word2vec(官方,C/Python);https://github.com/RaRe-Technologies/gensim(Python 封装,易用)
2. GloVe:Global Vectors for Word Representation(EMNLP 2014)
-
简介:基于全局词共现统计的静态词向量,结合 Word2Vec 的局部上下文优势和 LSA 的全局统计优势,词向量的语义 / 句法相似度更优,在文本分类、匹配等任务中性能优于普通 Word2Vec,是静态词向量的强基线。
-
代码地址:https://github.com/stanfordnlp/glove(官方,C/Python);gensim 内置实现
3. FastText:Enriching Word Vectors with Subword Information(ACL 2017)
-
简介:Facebook 提出的静态词向量改进版,将字符级 n-gram融入词向量训练,解决OOV(未登录词)和生僻词问题(如 “unhappiness” 可拆分为 “un-”“happy”“-ness”),支持多语言,训练速度极快,是低资源 / 多语言场景的词向量首选。
-
代码地址:https://github.com/facebookresearch/fastText(官方,C++/Python)
4. ELMo:Deep Contextualized Word Representations(NAACL 2018)
-
简介:首个动态词向量(上下文相关词向量),基于双向 LSTM 语言模型预训练,为每个单词生成随上下文变化的词向量(如 “银行” 在 “银行取钱” 和 “河边银行” 中向量不同),解决静态词向量一词多义问题,开启 NLP预训练 + 微调范式的序幕。
-
代码地址:https://github.com/allenai/allennlp(官方,ELMo 实现);https://github.com/huggingface/transformers(轻量调用)
二、经典语言模型(NLP 序列建模基础,1997-2018)
语言模型核心是计算文本序列的概率,捕捉单词间的上下文依赖关系,是生成式 NLP 的基础,分传统统计语言模型和深度学习语言模型,后者为 Transformer 预训练模型奠定序列建模基础。
1. N-gram Language Model(经典统计模型,1997)
-
简介:最基础的统计语言模型,通过前 n-1 个单词预测第 n 个单词,基于语料中 n 元组的出现频率计算概率,实现简单、可解释性强,是所有语言模型的基线,至今仍用于低资源 / 轻量场景的文本补全、纠错。
-
参考论文:https://mitpress.mit.edu/books/statistical-methods-speech-recognition(经典著作)
-
代码地址:https://github.com/nltk/nltk(NLTK 内置实现);https://github.com/rsennrich/n-gram-lm(轻量实现)
2. RNN-LM:Recurrent Neural Network Language Model(ICML 2003)
-
简介:首个深度学习语言模型,用 RNN 捕捉序列的长距离上下文依赖,解决 N-gram 的上下文窗口有限问题,实现端到端的语言模型训练,开启深度学习序列建模时代,是后续 LSTM/GRU 语言模型的基础。
-
代码地址:https://github.com/pytorch/examples/tree/main/word_language_model(PyTorch RNN-LM 实现)
3. LSTM-LM:Long Short-Term Memory(NeurIPS 1997 + 2001)
-
简介:LSTM奠基之作,针对 RNN 的梯度消失 / 爆炸问题,加入输入门、遗忘门、输出门和细胞状态,能有效捕捉超长序列的上下文依赖(如数百个单词的文本),是 Transformer 出现前最主流的序列建模模型,广泛用于语言模型、机器翻译、生成等任务。
-
论文地址:https://arxiv.org/abs/1402.1128(经典综述);https://www.bioinf.jku.at/publications/older/2604.pdf(原论文)
-
代码地址:https://github.com/pytorch/examples/tree/main/word_language_model(PyTorch LSTM-LM);https://github.com/tensorflow/tensorflow(TensorFlow 内置 LSTM)
4. GRU-LM:Gated Recurrent Unit(2014)
-
简介:LSTM 的轻量改进版,将输入门 / 遗忘门合并为更新门,移除细胞状态,简化模型结构,训练速度比 LSTM 快 30% 以上,性能与 LSTM 接近,是资源受限场景的序列建模首选,广泛用于工业界轻量 NLP 模型。
-
代码地址:PyTorch/TensorFlow 均内置 GRU,可直接替换 LSTM 使用
三、注意力与 Transformer(现代 NLP 核心架构,2014-2017)
注意力机制解决了 RNN 类模型并行计算效率低、长序列建模能力弱的问题,Transformer基于纯注意力机制构建,成为所有现代 NLP 模型(BERT/GPT/T5)的核心基础,彻底改变 NLP 的技术格局。
1. Seq2Seq+Attention:Neural Machine Translation by Jointly Learning to Align and Translate(ICLR 2015)
-
简介:首个将注意力机制融入 Seq2Seq 框架的论文,解决传统 Seq2Seq固定长度上下文向量的信息丢失问题,让模型在解码时自动聚焦输入序列的相关部分(如翻译时聚焦对应单词),大幅提升机器翻译性能,开启注意力机制在 NLP 的广泛应用。
-
代码地址:https://github.com/tensorflow/nmt(官方,带注意力的 Seq2Seq);https://github.com/pytorch/examples/tree/main/seq2seq(PyTorch 实现)
2. Self-Attention:Attention Is All You Need(NeurIPS 2017)
-
简介:Transformer 原论文,NLP 领域的里程碑之作,提出纯自注意力机制的 Transformer 架构,包含多头自注意力、前馈网络、层归一化、残差连接四大核心组件,支持全并行计算(效率远超 RNN),能建模超长序列的长距离依赖,同时提出位置编码解决注意力机制无序列感知的问题。Transformer 是 BERT、GPT、T5、ChatGLM 等所有现代预训练模型的底层架构,彻底取代 RNN 成为 NLP 主流。
-
代码地址:https://github.com/tensorflow/models/tree/master/official/nlp/transformer(官方);https://github.com/huggingface/transformers(经典复现,易用);https://github.com/pytorch/pytorch(PyTorch 内置 Transformer 层)
3. Multi-Head Attention(NeurIPS 2017)
-
简介:Transformer 的核心组件之一,将自注意力机制拆分为多个头,每个头学习不同的语义 / 句法特征(如一个头关注词性,一个头关注语义,一个头关注上下文依赖),大幅提升注意力机制的特征表达能力,是 Transformer 性能优于单头注意力的关键。
-
论文地址:融合于《Attention Is All You Need》(同上)
-
代码地址:所有 Transformer 实现均包含多头注意力,参考上述 Transformer 代码
四、基础优化方法(NLP 模型训练必备,2014-2020)
涵盖优化器、正则化、初始化、学习率调度等 NLP 模型训练的核心基础方法,解决模型训练不稳定、收敛慢、过拟合等问题,是所有 NLP 深度学习模型的训练标配,直接决定模型的训练效率和最终性能。
1. Adam:A Method for Stochastic Optimization(ICLR 2015)
-
简介:最主流的自适应优化器,结合 SGD 的动量和 RMSprop 的自适应学习率,收敛速度快、训练稳定,对学习率超参数不敏感,是所有 NLP 深度学习模型的默认优化器(BERT/GPT/Transformer 均使用 Adam/AdamW),彻底取代 SGD 成为 NLP 训练首选。
-
代码地址:PyTorch/TensorFlow/JAX 均内置 Adam 实现,直接调用
2. AdamW:Decoupled Weight Decay Regularization(ICLR 2018)
-
简介:Adam 的改进版,将权重衰减(L2 正则化)与 Adam 的自适应梯度更新解耦,解决 Adam 原生权重衰减效果不佳的问题,能有效防止模型过拟合,是预训练语言模型(BERT/GPT)训练的标配优化器,工业界和学术界均广泛使用。
-
代码地址:https://github.com/pytorch/pytorch(PyTorch 内置 AdamW);https://github.com/huggingface/transformers(所有预训练模型均默认使用)
3. Dropout:Improving Neural Networks by Preventing Co-adaptation of Feature Detectors(NeurIPS 2014)
-
简介:最经典的正则化方法,训练时随机丢弃部分神经元(按一定概率),防止神经元之间的共适应,有效解决模型过拟合问题,是所有深度学习 NLP 模型的必备组件(词向量、LSTM、Transformer、预训练模型均使用 Dropout)。
-
代码地址:PyTorch/TensorFlow 均内置 Dropout 层,直接调用
4. Layer Normalization:Layer Normalization(ICML 2016)
-
简介:针对批量归一化(BN)在 NLP 中效果不佳(NLP 序列长度不固定、批量小)的问题,提出按层归一化,对每个样本的每个层的特征进行归一化,训练稳定、不依赖批量大小,是Transformer、预训练模型的核心组件(与残差连接配合,解决深度模型训练不稳定问题)。
-
代码地址:PyTorch/TensorFlow 均内置 LayerNorm 实现,Transformer 默认使用
5. Xavier Initialization:Understanding the Difficulty of Training Deep Feedforward Neural Networks(AISTATS 2010)
-
简介:经典的模型参数初始化方法,根据输入 / 输出神经元数量设置初始化方差,保证模型训练时梯度不消失 / 爆炸,是 ** 浅层 NLP 模型(CNN / 简单 RNN)** 的标配初始化方法;后续的 He 初始化是其针对 ReLU 激活函数的改进版。
-
代码地址:PyTorch/TensorFlow 均内置 Xavier/He 初始化,直接调用
6. Learning Rate Scheduling:Cyclical Learning Rates for Training Neural Networks(ICLR 2017)
-
简介:学习率调度的经典方法,提出周期性调整学习率(先升后降),让模型在不同学习率下探索最优解,提升模型收敛速度和最终性能。衍生的余弦退火学习率(Cosine Annealing)是预训练语言模型训练的标配,HuggingFace Transformers 默认使用。
-
代码地址:https://github.com/huggingface/transformers(内置所有学习率调度器);PyTorch/TensorFlow 均内置学习率调度实现
五、NLP 基础工具包(必备,覆盖全流程)
1. 基础数据处理 / 分词
-
NLTK:https://github.com/nltk/nltk(英文 NLP 基础工具,分词、词性标注、语料处理)
-
SpaCy:https://github.com/explosion/spaCy(工业级英文 NLP 工具,高效分词、命名实体识别、词向量)
-
Jieba:https://github.com/fxsjy/jieba(中文分词标配,轻量高效、支持自定义词典)
-
THULAC:https://github.com/thunlp/THULAC-Python(哈工大中文分词 / 词性标注,准确率更高)
2. 模型训练 / 推理核心框架
-
PyTorch:https://github.com/pytorch/pytorch(NLP 主流训练框架,动态图、易用、生态丰富)
-
TensorFlow/Keras:https://github.com/tensorflow/tensorflow(工业界常用,静态图、部署友好)
-
Hugging Face Transformers:https://github.com/huggingface/transformers(NLP 预训练模型标配,内置所有基础架构 + 预训练模型)
3. 词向量 / 表示学习工具
-
Gensim:https://github.com/RaRe-Technologies/gensim(Word2Vec/GloVe/FASTTEXT 一站式实现,易用)
-
FastText:https://github.com/facebookresearch/fastText(官方,多语言词向量 + 文本分类)
1.5 时序预测问题
当前时序预测领域已进入“基础模型(Foundation Models)”与“高效Transformer/MLP”并行的时代。研究热点从单纯的精度提升转向了零样本泛化能力(Zero-shot)、长序列建模效率以及多变量耦合关系的处理。
一、核心开源资源库 (强烈推荐)
在深入研究具体算法前,建议先收藏以下汇总资源库,它们包含了绝大多数主流算法的统一实现和评测基准。
-
Time-Series-Library (清华大学开源)
-
简介: 目前最权威的时序预测代码库之一(由iTransformer, PatchTST等作者维护)。集成了DLinear, iTransformer, PatchTST, Informer, Autoformer等20+种SOTA模型。提供了统一的数据加载器、训练流程和评测标准,是复现论文的首选。
-
-
NeuralForecast (Nixtla开源)
-
简介: 工业界友好的高性能库,不仅包含深度学习模型(如NHITS, TFT),还集成了传统统计学模型(ARIMA, ETS)。支持分布式训练和概率预测,文档极其完善。
-
-
GluonTS (AWS开源)
-
简介: 亚马逊推出的概率时序预测库,是Chronos等大模型的底层框架之一。擅长处理不确定性估计和复杂分布建模。
-
二、SOTA 基础模型 (Foundation Models) - 当前最热
这类模型通过在海量异构数据上预训练,具备强大的零样本(Zero-shot)或少样本(Few-shot)泛化能力,无需针对新任务重新训练即可直接推理。
1. Chronos (Amazon, 2024) - 通用性标杆
-
论文标题: Chronos: Learning the Language of Time Series
-
简介: 亚马逊推出的基于T5语言模型架构的时序基础模型。核心创新是将时间序列数值通过缩放和量化转换为离散的“Token”,从而将预测问题转化为语言模型的下一个Token预测问题。它在多个基准测试中展现了惊人的零样本泛化能力,甚至优于针对特定数据集训练的监督模型。
-
论文地址: arXiv:2403.07815
-
特点: 支持概率预测,开箱即用,适合缺乏标注数据的场景。
2. TimesFM (Google, 2024/2025)
-
论文标题: Large Foundation Models for Long Time Series Forecasting (及相关系列工作)
-
简介: 谷歌推出的时序基础模型。采用Decoder-only Transformer架构,结合了频域分解思想。TimesFM在长序列预测和跨域泛化上表现优异,能够处理从分钟级到年级别的不同频率数据。最新版本(2.5+)进一步扩展了上下文窗口长度。
-
论文地址: arXiv:2402.02592 (参考相关系列)
-
特点: 对长序列支持好,推理速度快,已集成到HuggingFace和Vertex AI。
3. Moirai (Salesforce, 2024)
-
论文标题: Moirai: Efficient and Generalizable Time Series Foundation Model
-
简介: 提出了一种多尺度补丁投影(Multi-scale Patch Projection)机制,能够自适应地处理不同分辨率和长度的时间序列。其核心优势在于“任意变量注意力”机制,使其能灵活处理单变量和多变量混合的场景。
-
论文地址: arXiv:2402.03885
三、高效 Transformer 与 MLP 模型 (Supervised SOTA)
如果您有特定领域的标注数据需要微调(Fine-tuning),以下模型在精度和效率上达到了目前的最佳平衡(SOTA)。
1. iTransformer (ICLR 2024) - Transformer改进标杆
-
论文标题: iTransformer: Inverted Transformers Are Effective for Time Series Forecasting
-
简介: 颠覆了传统Transformer在时序中的应用方式。它反转了输入维度:将每个变量的整个时间序列作为一个Token(而不是每个时间步作为一个Token),利用Attention机制捕捉多变量之间的相关性(Variates Correlation),利用Feed-Forward网络捕捉时间依赖。解决了传统Transformer在处理长序列多变量时的痛点。
-
论文地址: arXiv:2310.06625
-
地位: 目前在许多长序列预测基准(如ETT, Weather)上霸榜。
2. PatchTST (ICLR 2023) - 分块策略开创者
-
论文标题: A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
-
简介: 提出了分段(Patching)策略。将时间序列切分成重叠的子序列(Patch)作为Transformer的输入Token。这不仅保留了局部语义信息,还大幅减少了Token数量,降低了计算复杂度,同时缓解了分布漂移(Distribution Shift)问题。
-
论文地址: arXiv:2211.14730
3. DLinear / Simple Linear (AAAI 2023) - 极简主义震撼
-
论文标题: Are Transformers Effective for Time Series Forecasting?
-
简介: 一篇“反思”性质的论文。作者发现,简单的线性层(Linear Layer)在去除了趋势和季节性后,其表现往往优于复杂的Transformer模型。它提醒研究者不要过度迷信复杂架构,强调了分解(Decomposition)的重要性。常作为强Baseline使用。
-
论文地址: arXiv:2205.13504
-
代码地址: 包含在 Time-Series-Library 中。
4. TimeMixer++ (ICLR 2025) - 最新多尺度融合
-
论文标题: TimeMixer++: A General Time Series Pattern Machine for Universal Predictive Analysis
-
简介: 2025年的最新力作。不仅用于预测,还统一了分类、异常检测等任务。核心是通过多尺度下采样提取不同分辨率的时间模式,并进行可学习的融合。在多个任务上刷新了SOTA记录。
-
论文地址: OpenReview (ICLR 2025)
-
代码地址: 通常会在 Time-Series-Library 或作者主页更新,关注相关Repo。
四、经典与特定场景模型
表格
|
模型名称 |
年份 |
特点 |
适用场景 |
代码/论文 |
|---|---|---|---|---|
|
Informer |
2021 |
引入ProbSparse Attention,降低复杂度至O(L log L)。 |
长序列预测奠基之作 |
|
|
Autoformer |
2021 |
引入深度分解架构和自相关机制(Auto-Correlation)。 |
具有明显季节性的序列 |
|
|
NHITS |
2022 |
基于层级插采样的纯MLP架构,可解释性强。 |
需要长 horizon 预测且追求速度 |
|
|
LAG-LLaMA |
2024 |
基于LLaMA架构的时序基础模型,专注于单变量泛化。 |
零样本单变量预测 |
五、常用数据集
研究和测试通常使用以下基准数据集(上述代码库通常内置了下载脚本):
-
ETT (Electricity Transformer Temperature): 电力变压器温度数据,分为ETTh1, ETTh2 (小时级), ETTm1, ETTm2 (15分钟级)。长序列预测的“Hello World”。
-
Weather: 德国气象站数据,包含21个气象指标。
-
Traffic: 加州高速公路占用率数据。
-
Electricity: 美国某公用事业公司的每小时电力消耗数据。
-
M4 / M5: 竞赛数据集,涵盖零售、金融等多领域,主要用于评估泛化能力。
六、总结与建议
-
想要快速落地/零样本预测: 首选 Chronos 或 TimesFM。不需要训练,直接加载预训练权重即可推理,特别适合冷启动项目。
-
有充足数据/追求极致精度: 使用 Time-Series-Library 复现 iTransformer 或 PatchTST。这两个模型目前在监督学习设定下表现最稳健。
-
资源受限/边缘设备: 尝试 DLinear 或 NHITS。它们的参数量极小,推理速度极快,且精度往往不输大模型。
-
最新科研方向: 关注 TimeMixer++ 等多任务统一模型,以及结合 LLM (大语言模型) 进行时序推理的交叉研究(如利用LLM的常识辅助预测)。
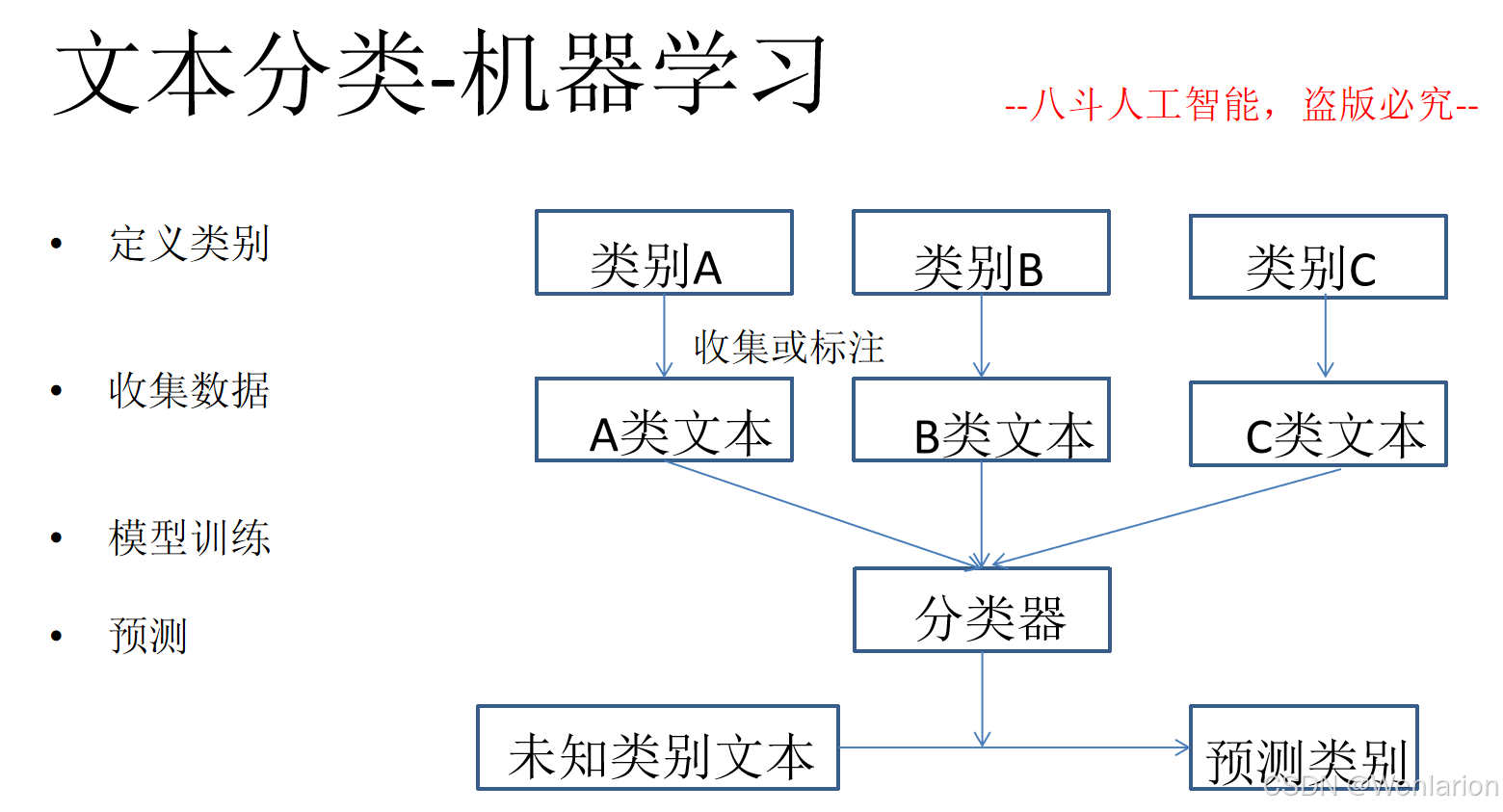
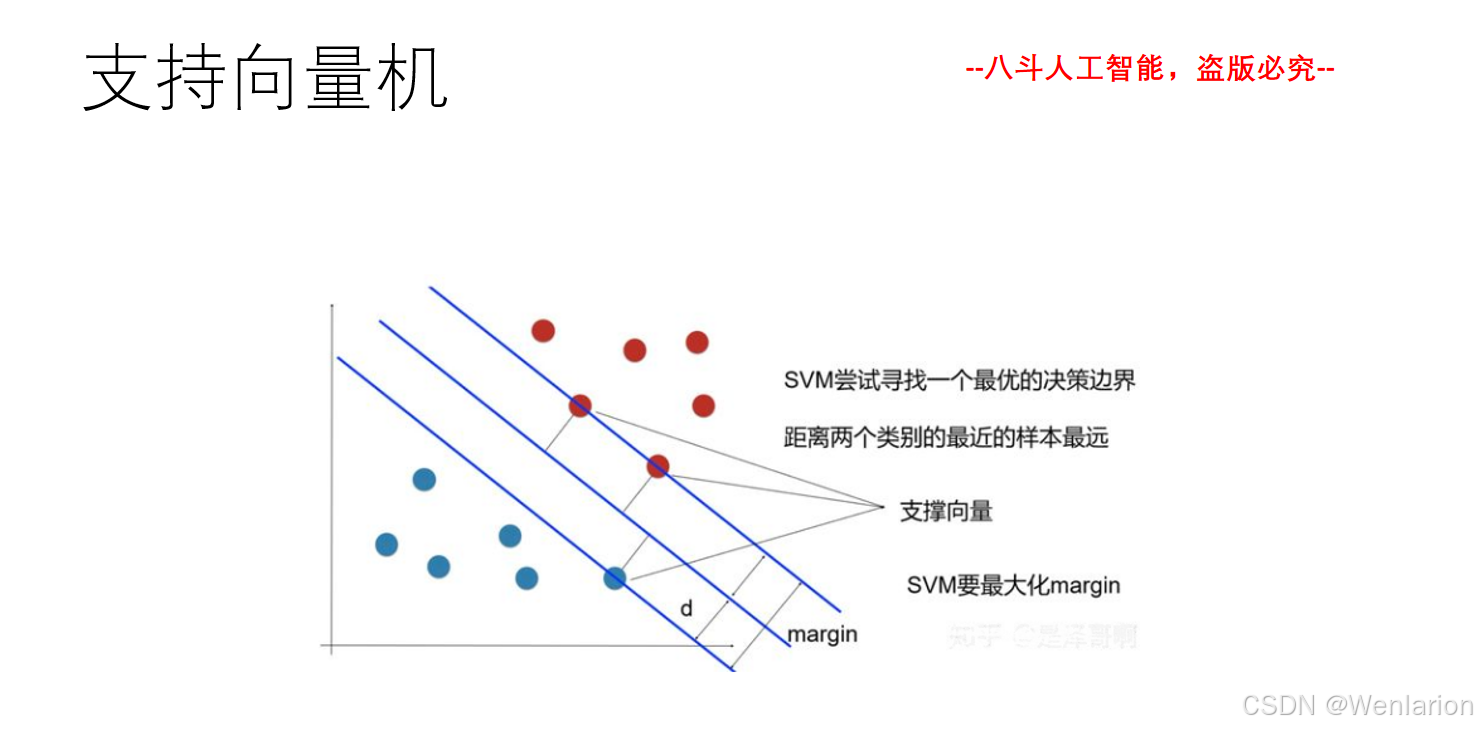
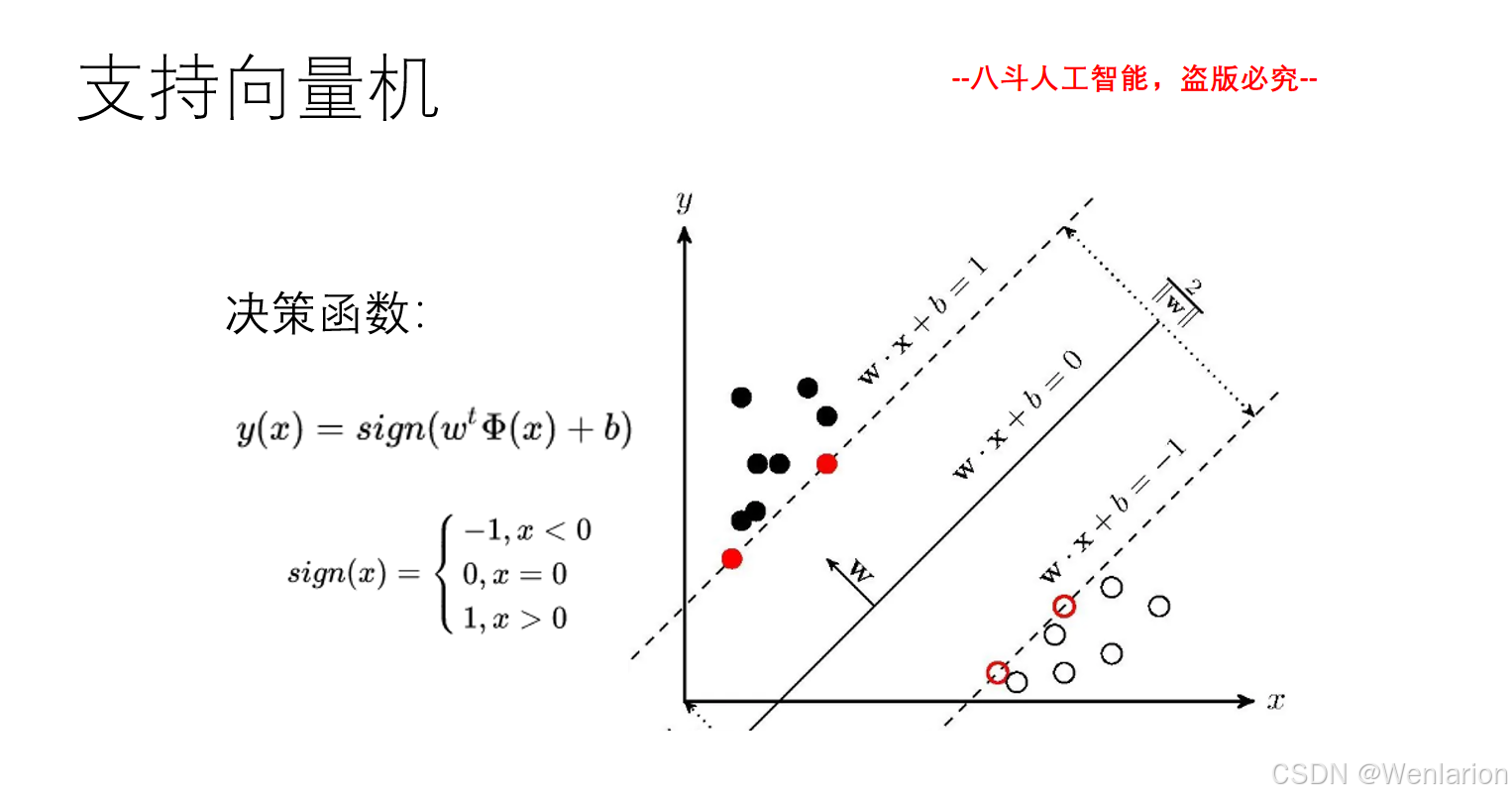
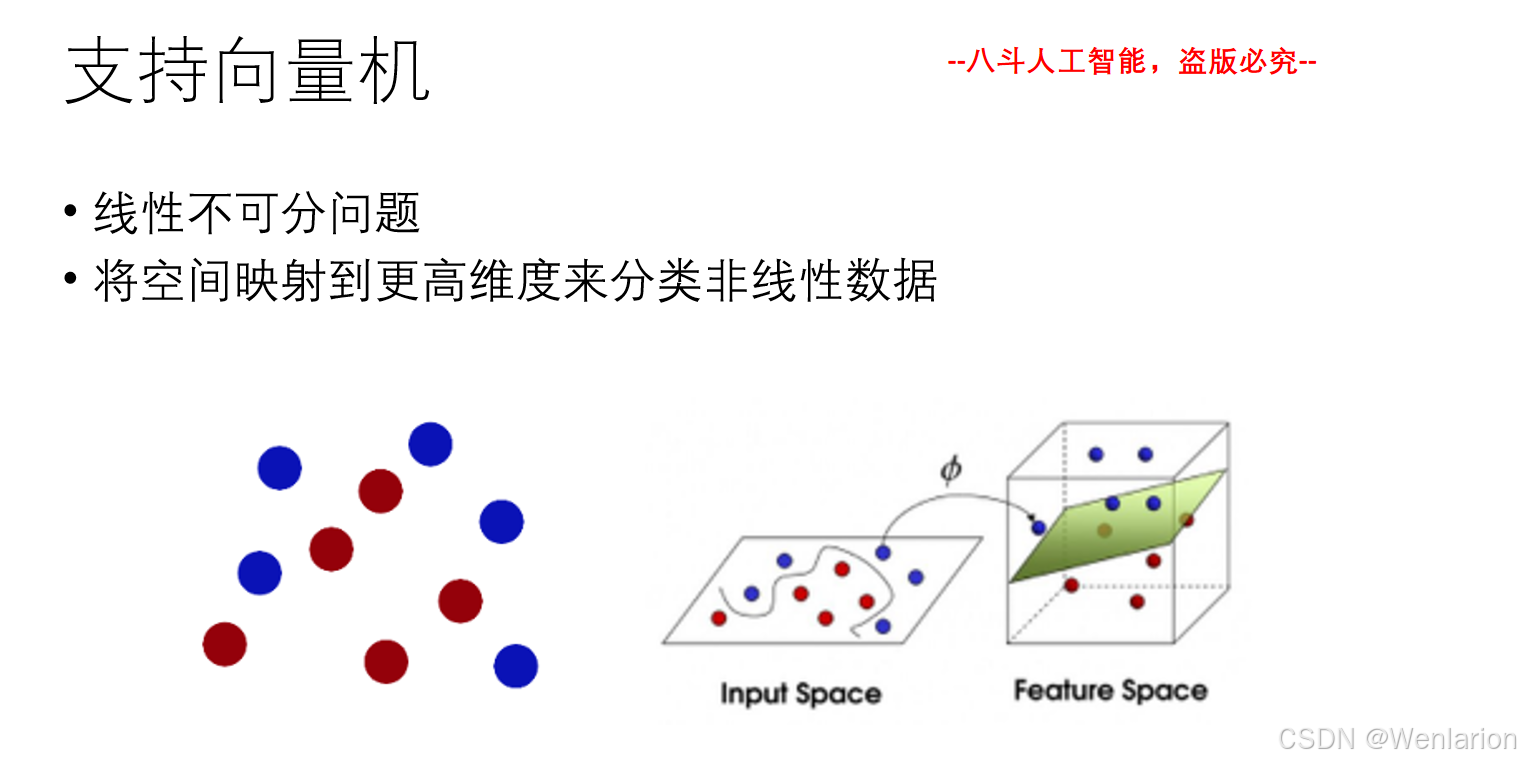
2、自然语言处理问题(文本分类、文本匹配、序列标注、文本生成)
2.1 文本分类















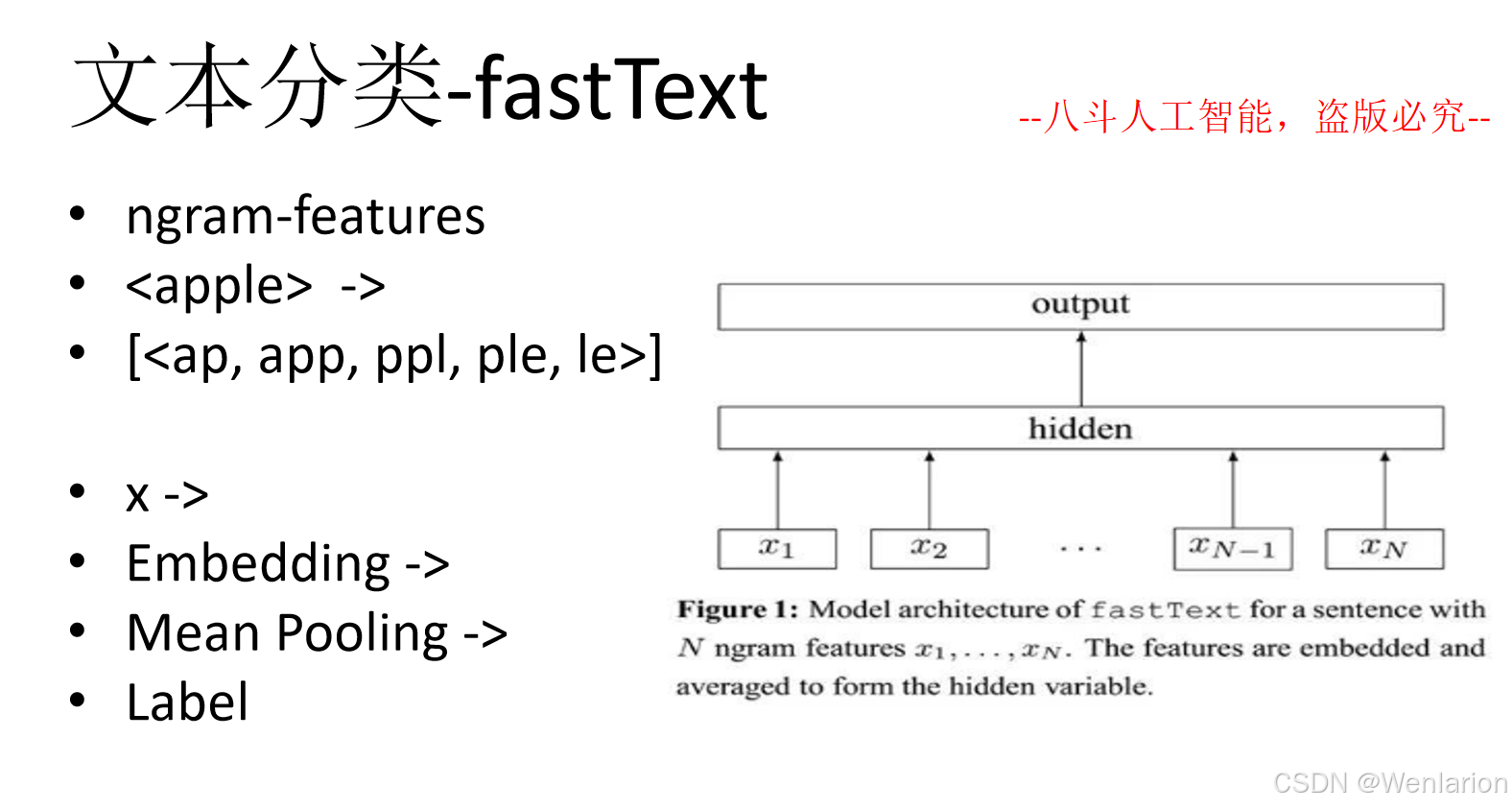
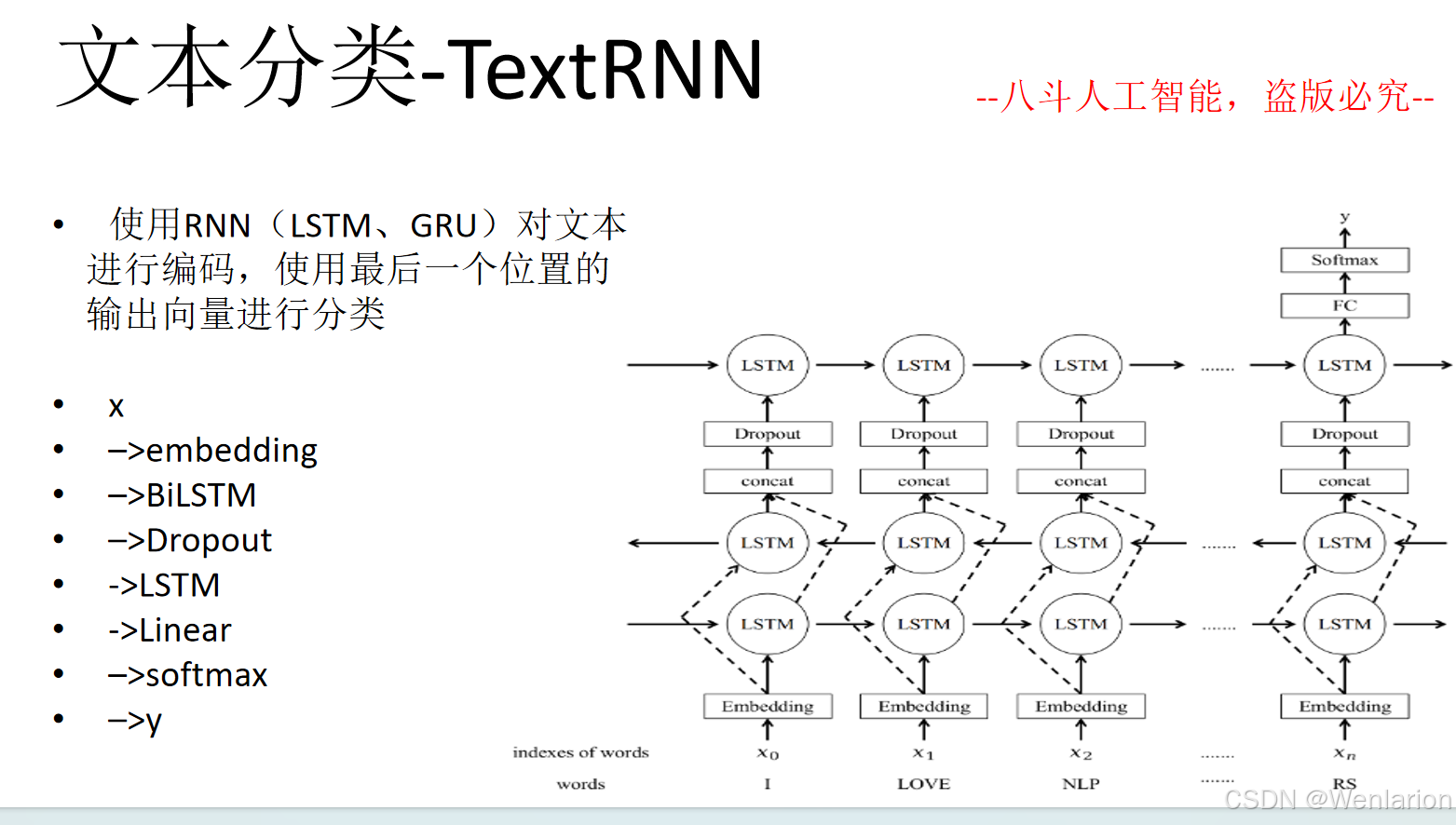
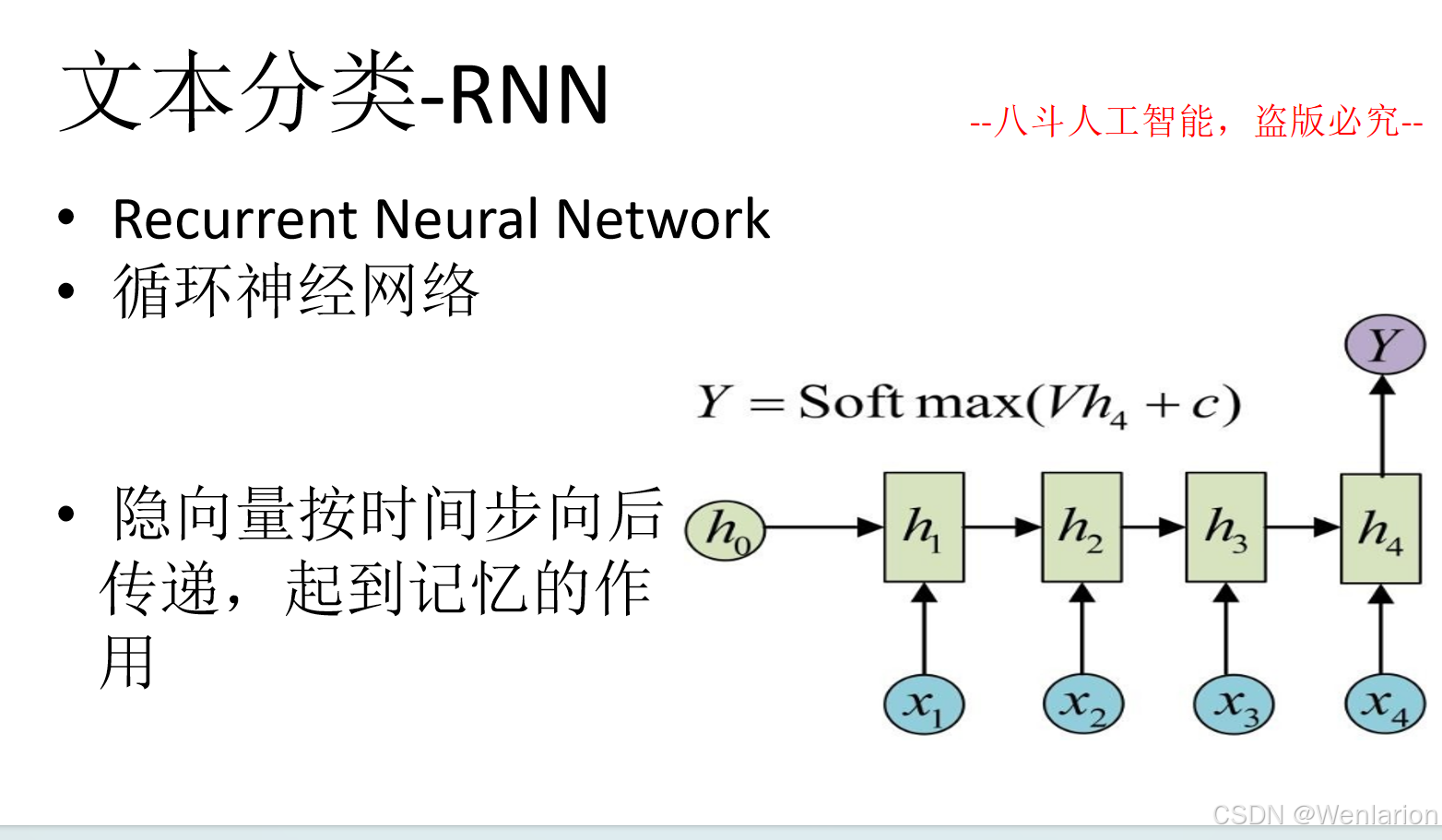
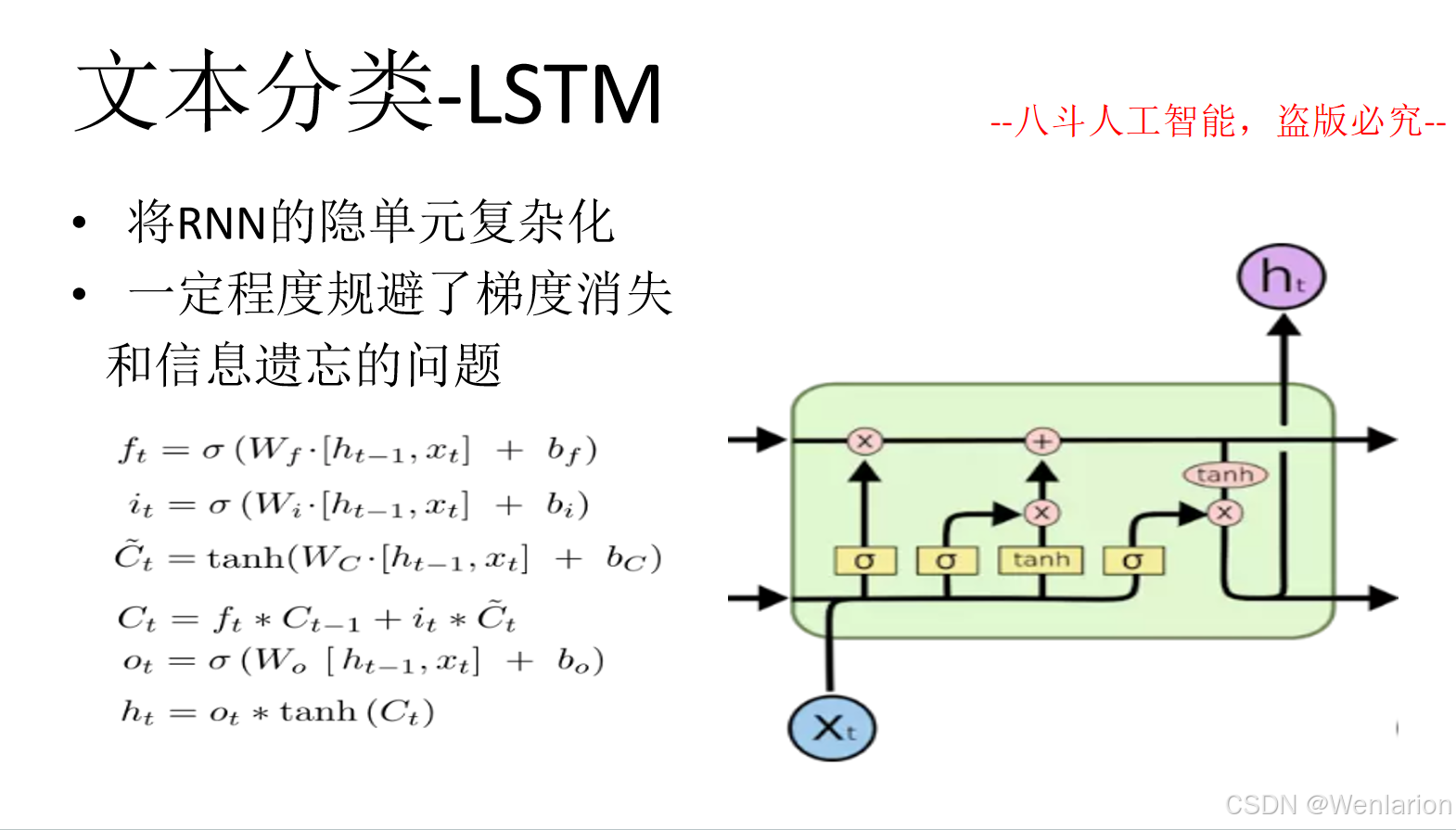
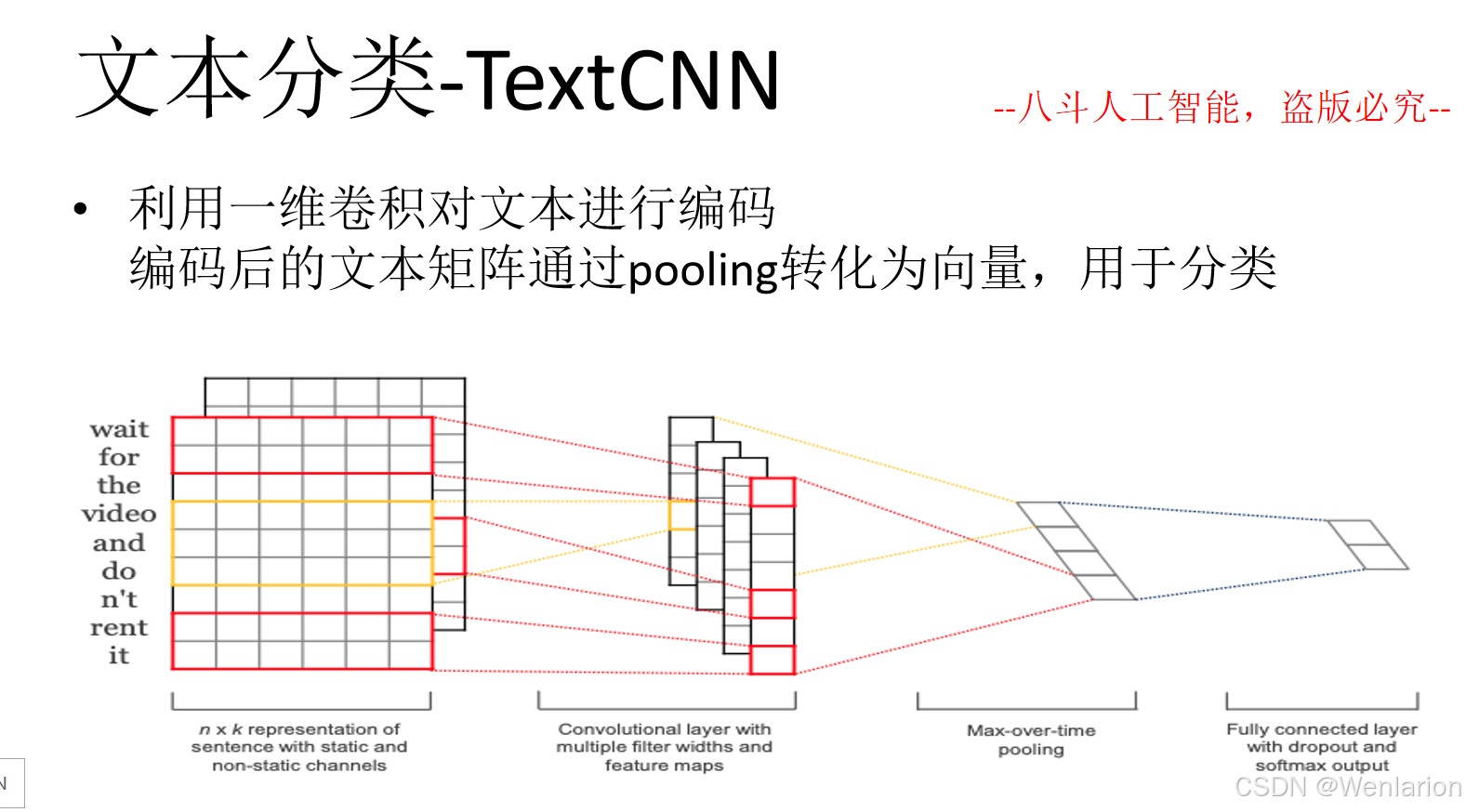
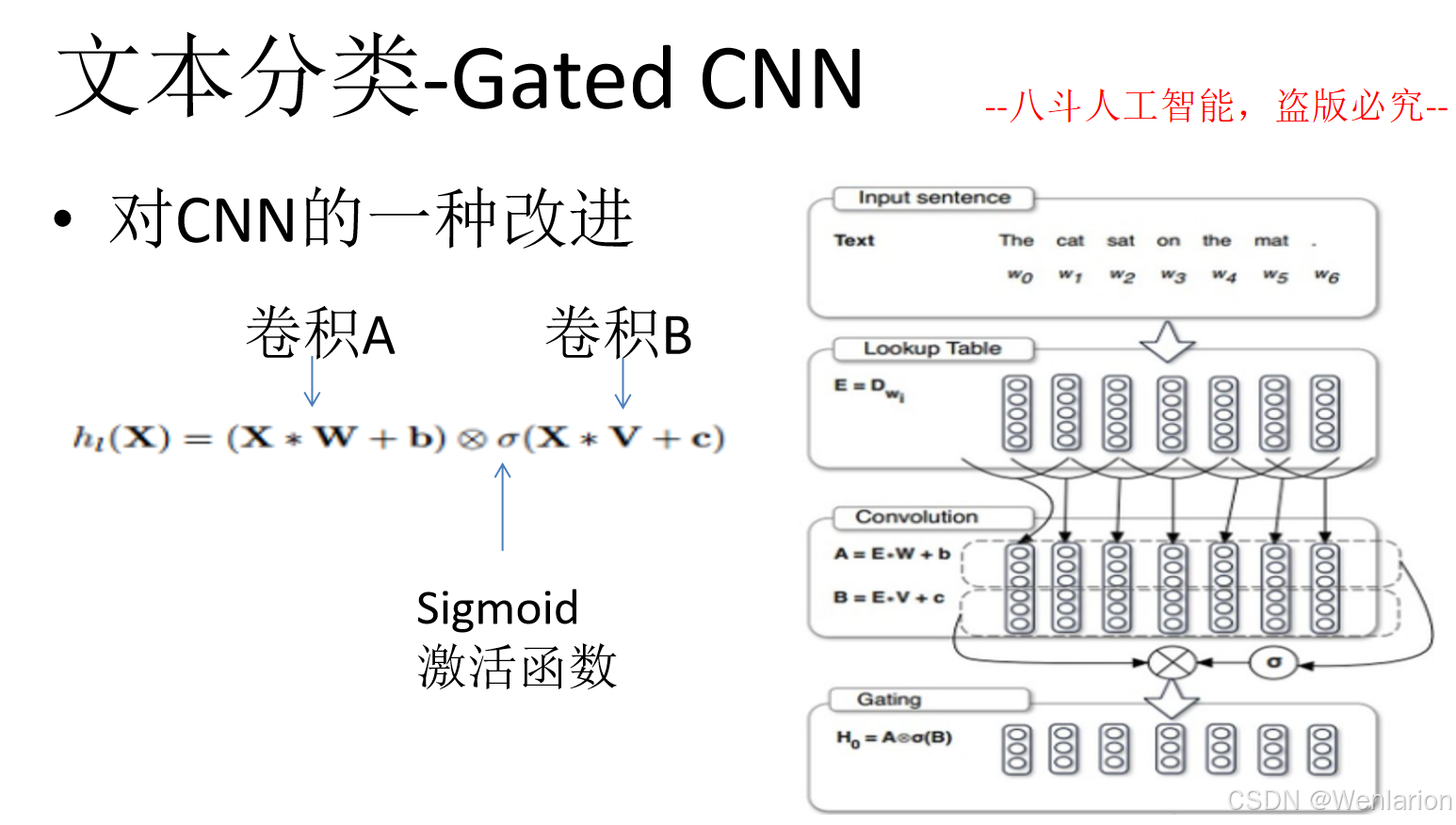
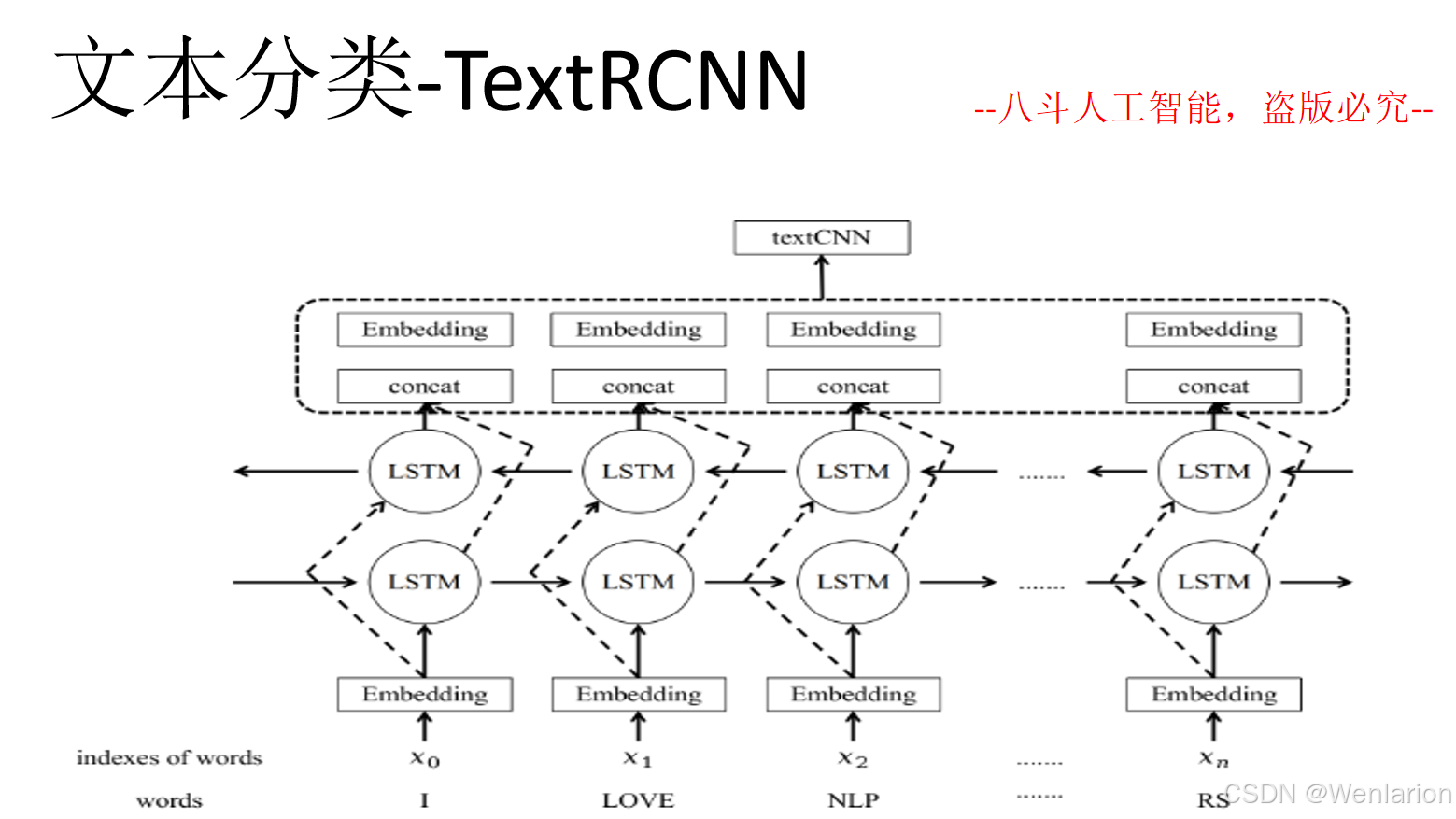
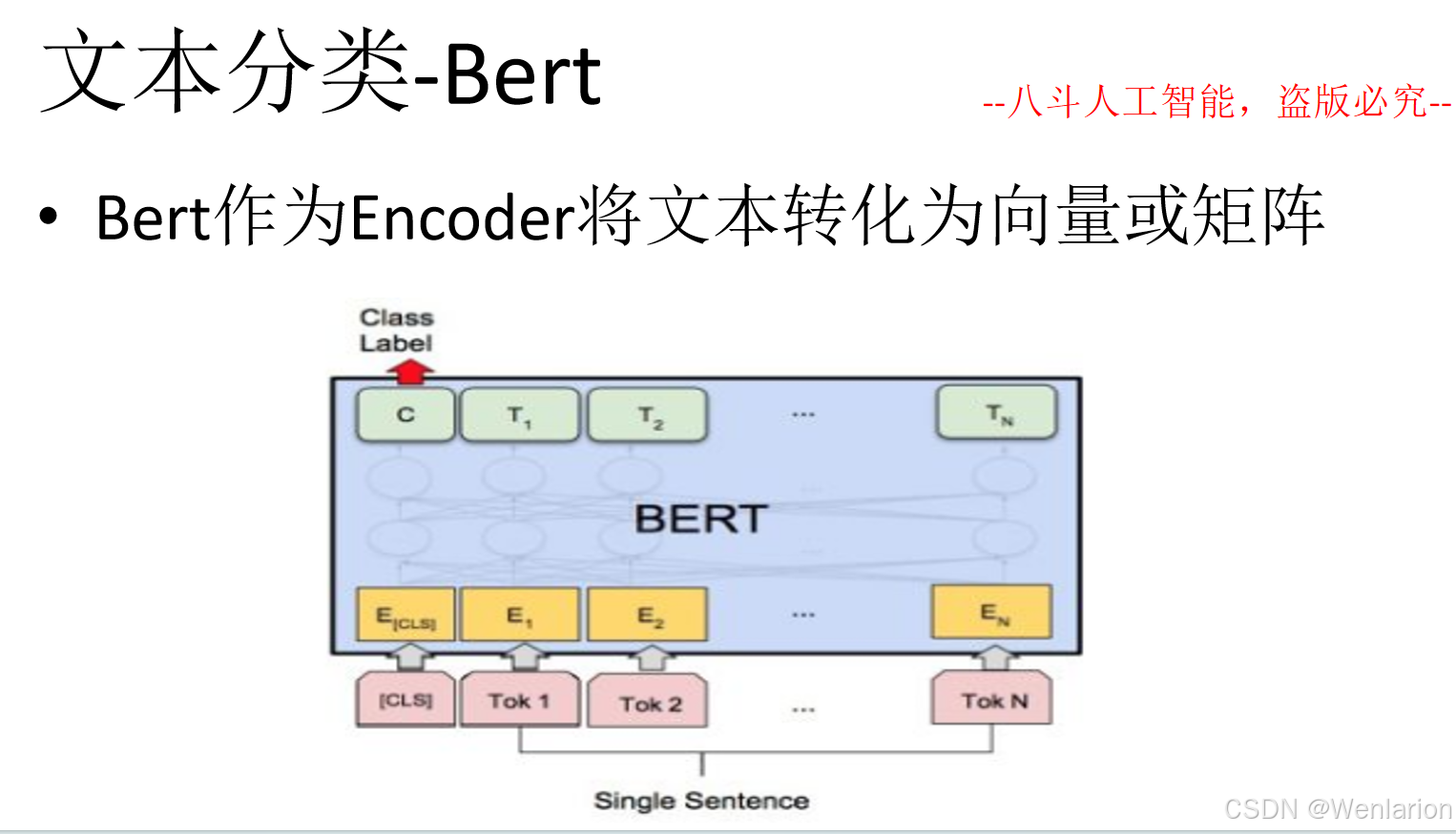


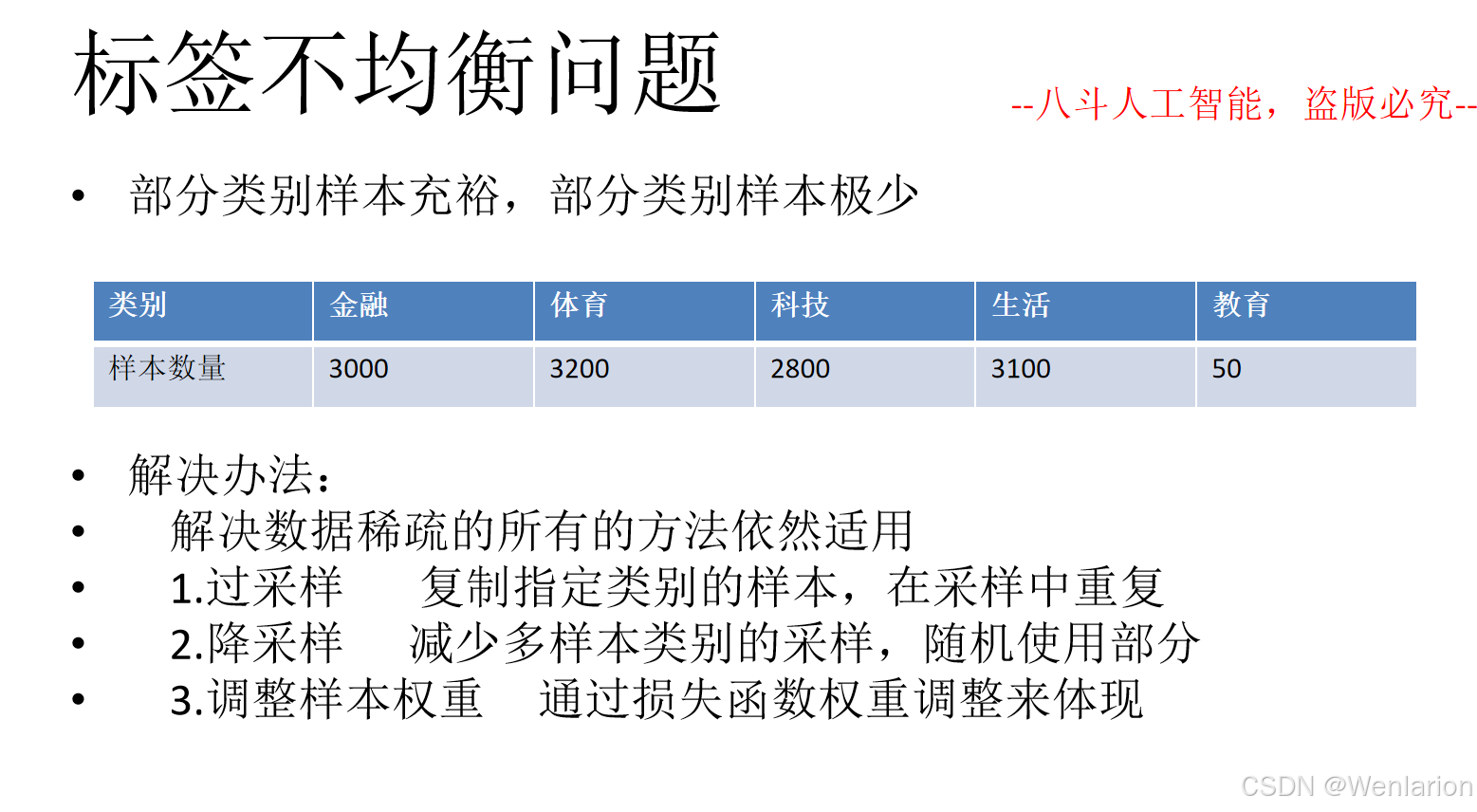
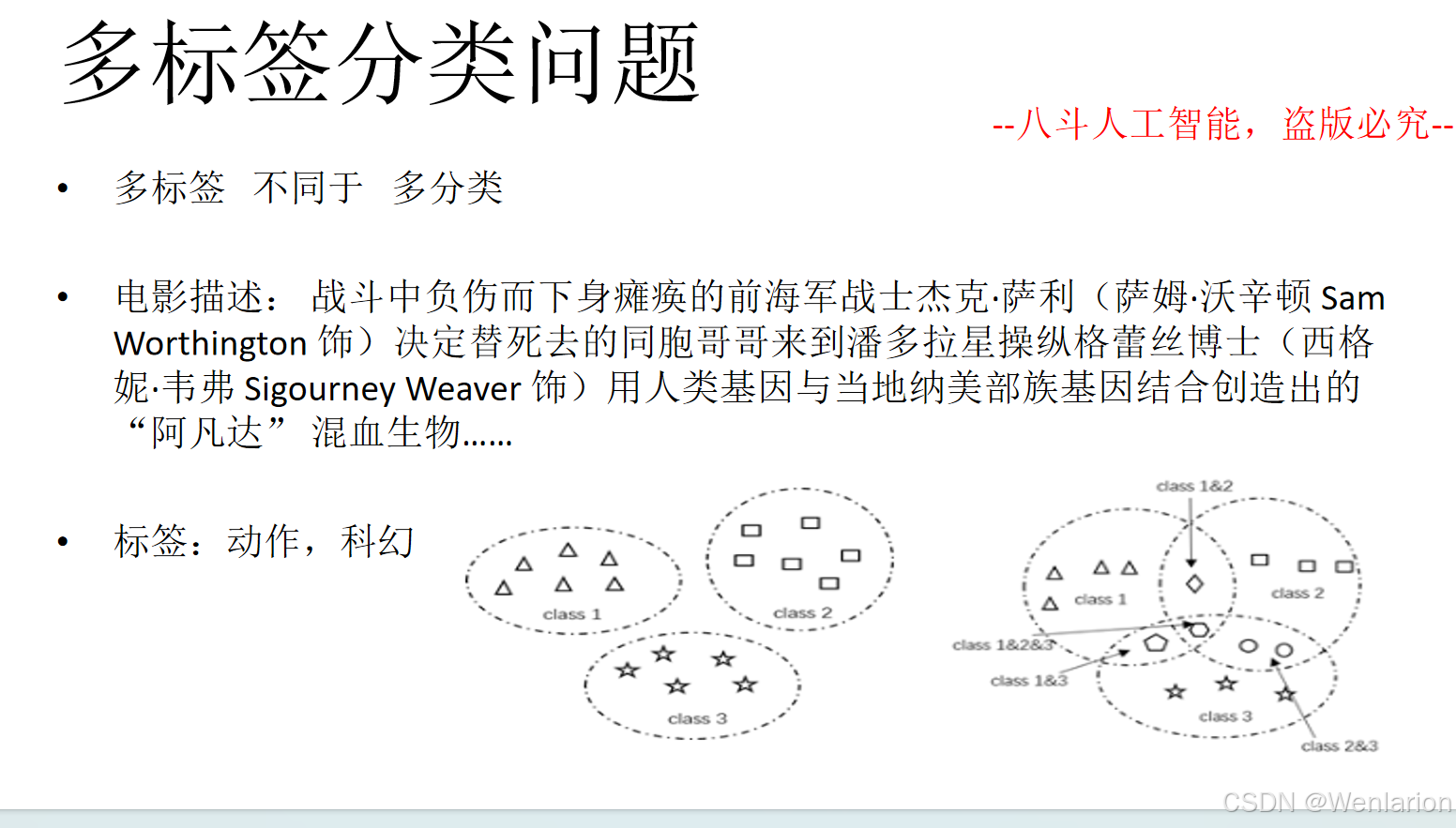

文本分类相关论文和代码
一、传统基线(经典统计 / 线性模型)
1. Linear Classifier: An Often-Forgotten Baseline for Text Classification(ACL 2023)
-
简介:重新强调线性分类器(如 Linear SVM、Logistic Regression)在文本分类中的强大基线能力,在多个数据集上性能接近甚至超越部分复杂深度学习模型,为实验提供可靠对比基准。
-
代码地址:https://github.com/jameslyc88/text_classification_baseline_code
二、深度学习经典模型(2014-2019)
1. TextCNN:Convolutional Neural Networks for Sentence Classification(EMNLP 2014)
-
简介:文本分类 CNN 开山之作,用一维卷积 + 池化提取 n-gram 局部特征,结构简洁高效,奠定 CNN 在 NLP 分类任务的基础。
2. CharCNN:Character-level Convolutional Networks for Text Classification(NIPS 2015)
-
简介:直接在字符级做卷积,无需分词与预训练词向量,对拼写错误、生僻词鲁棒性强,适合短文本 / 多语言场景。
3. FastText:Bag of Tricks for Efficient Text Classification(EACL 2017)
-
简介:Facebook 提出的轻量级模型,用词袋 + n-gram 特征 + 线性分类,训练极快、参数量小,工业界广泛用于快速分类。
4. DPCNN:Deep Pyramid Convolutional Neural Networks for Text Categorization(ACL 2017)
-
简介:在 TextCNN 基础上堆叠多层等长卷积 + 池化,捕获长距离语义,复杂度不随网络加深增加,解决 CNN 长文本建模短板。
5. TextRCNN:Recurrent Convolutional Neural Networks for Text Classification(AAAI 2015)
-
简介:结合 RNN(捕获序列上下文)与 CNN(提取局部关键特征),兼顾全局语义与局部信息,性能优于单一 CNN/RNN。
-
论文地址:https://www.aaai.org/ocs/index.php/AAAI/AAAI15/paper/view/9745
-
代码地址:https://github.com/roomylee/rcnn-text-classification(TensorFlow)
6. HAN:Hierarchical Attention Networks for Document Classification(NAACL 2016)
-
简介:分层注意力模型(词级→句级→文档级),自动聚焦关键内容,适合长文档 / 多句文本分类,可解释性强。
7. TextGCN:Graph Convolutional Networks for Text Classification(AAAI 2019)
-
简介:构建 “文档 - 单词” 异构图,用 GCN 学习节点表示,无需预训练词向量,在小样本 / 低资源数据集表现优异。
三、预训练语言模型(2018 至今,SOTA 主流)
1. BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding(NAACL 2019)
-
简介:基于 Transformer 的双向预训练模型,在文本分类等下游任务微调后大幅刷新 SOTA,成为 NLP 分类任务标配基线。
2. RoBERTa:A Robustly Optimized BERT Pretraining Approach(ACL 2019)
-
简介:优化 BERT 预训练策略(更大数据、更长训练、移除 NSP 任务),性能全面超越 BERT,是文本分类常用强基线。
-
代码地址:https://github.com/facebookresearch/fairseq/tree/main/examples/roberta
3. ALBERT:A Lite BERT for Self-supervised Learning of Language Representations(ICLR 2020)
-
简介:通过参数共享、因式分解嵌入减少参数量,训练更快、内存占用更低,性能接近 BERT,适合资源受限场景。
四、一站式复现仓库(多模型集合)
-
SentenceClassification(PyTorch):https://github.com/unikcc/SentenceClassification包含 TextCNN、FastText、BERT 等主流模型,统一接口,支持快速切换与对比。
-
Text-Classification-PyTorch:https://github.com/Doragd/Text-Classification-PyTorch实现 TextCNN、TextAttnBiLSTM、HAN 等,附带 SST 等基准数据集测试脚本。
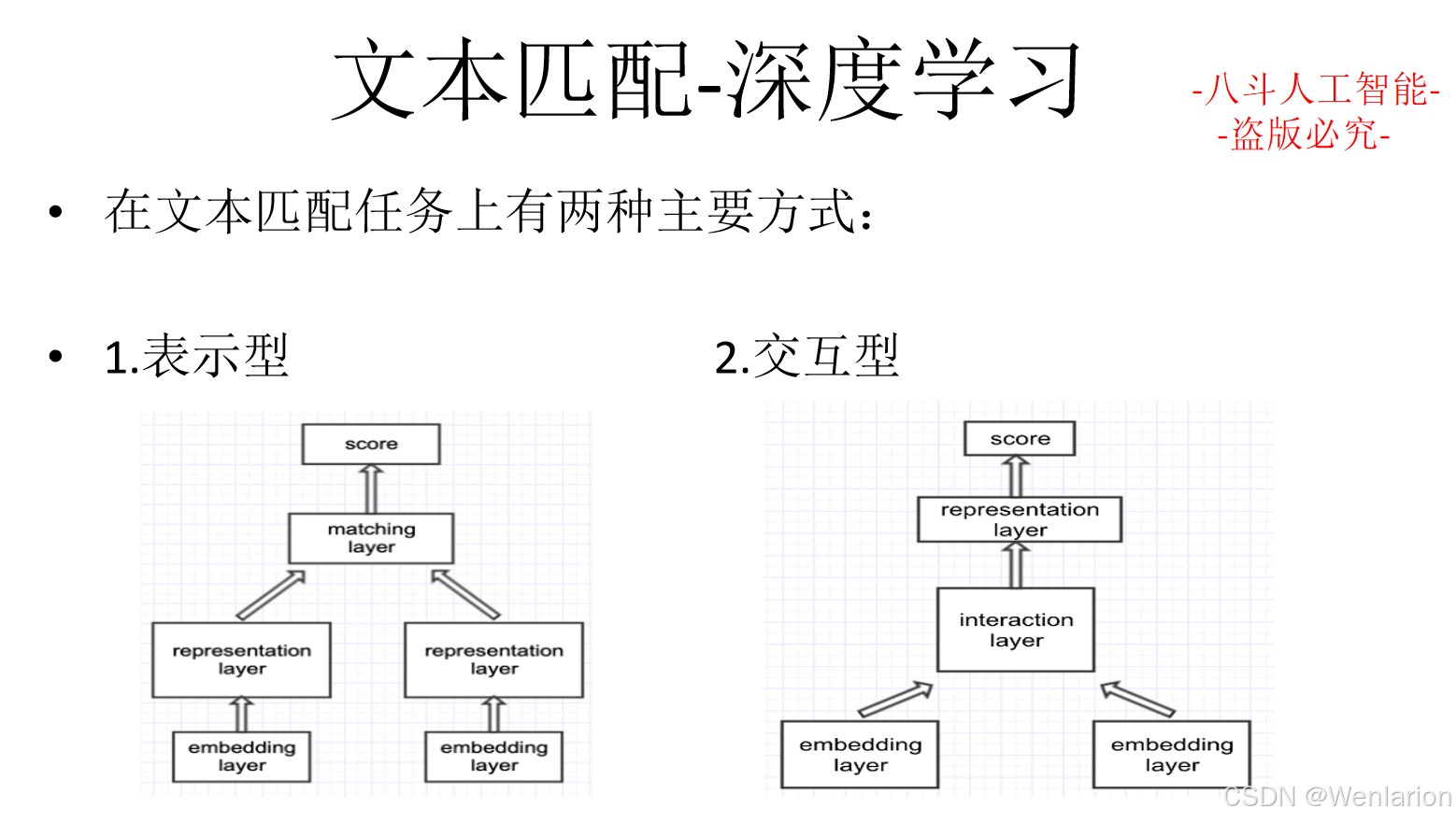
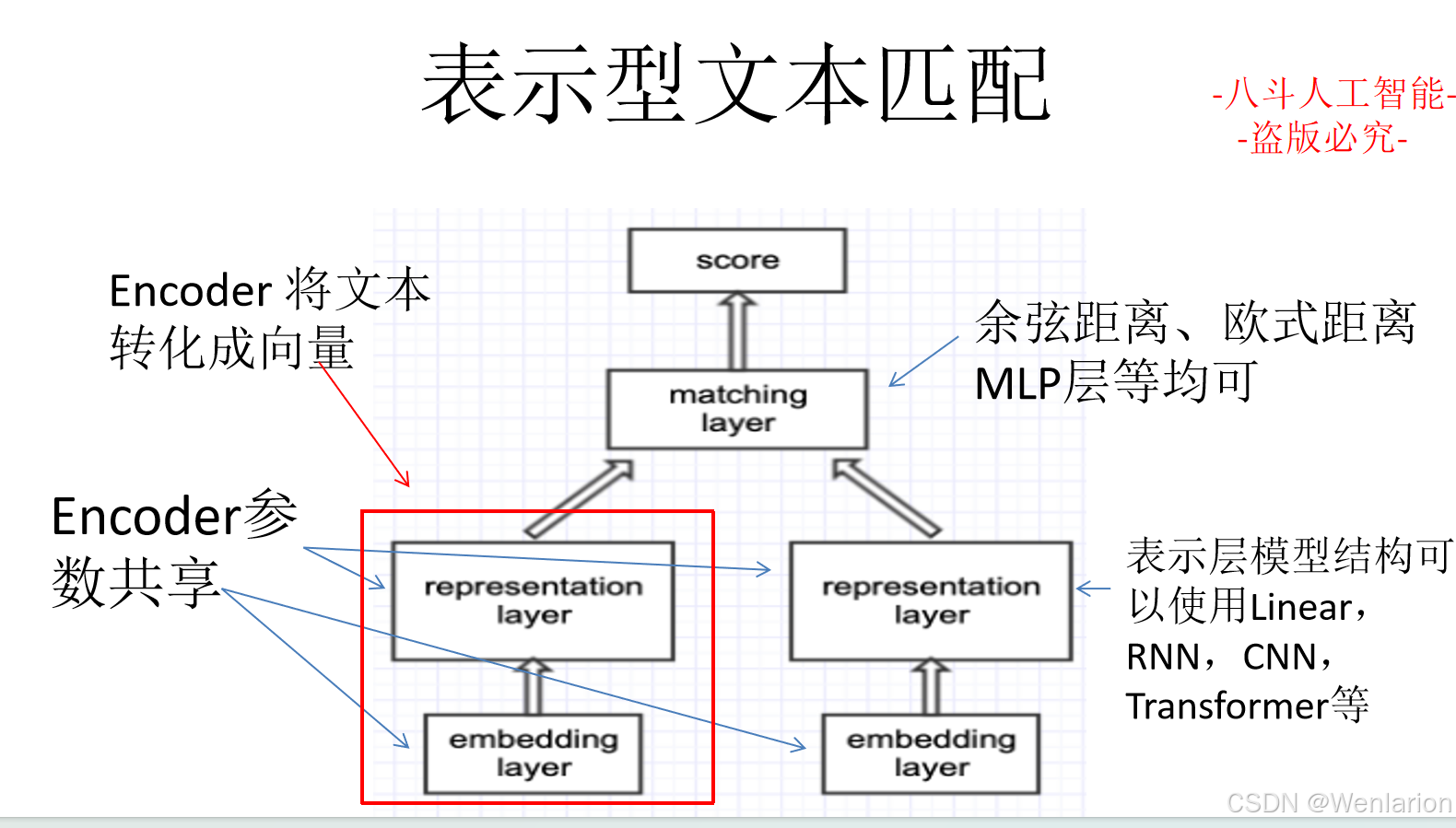
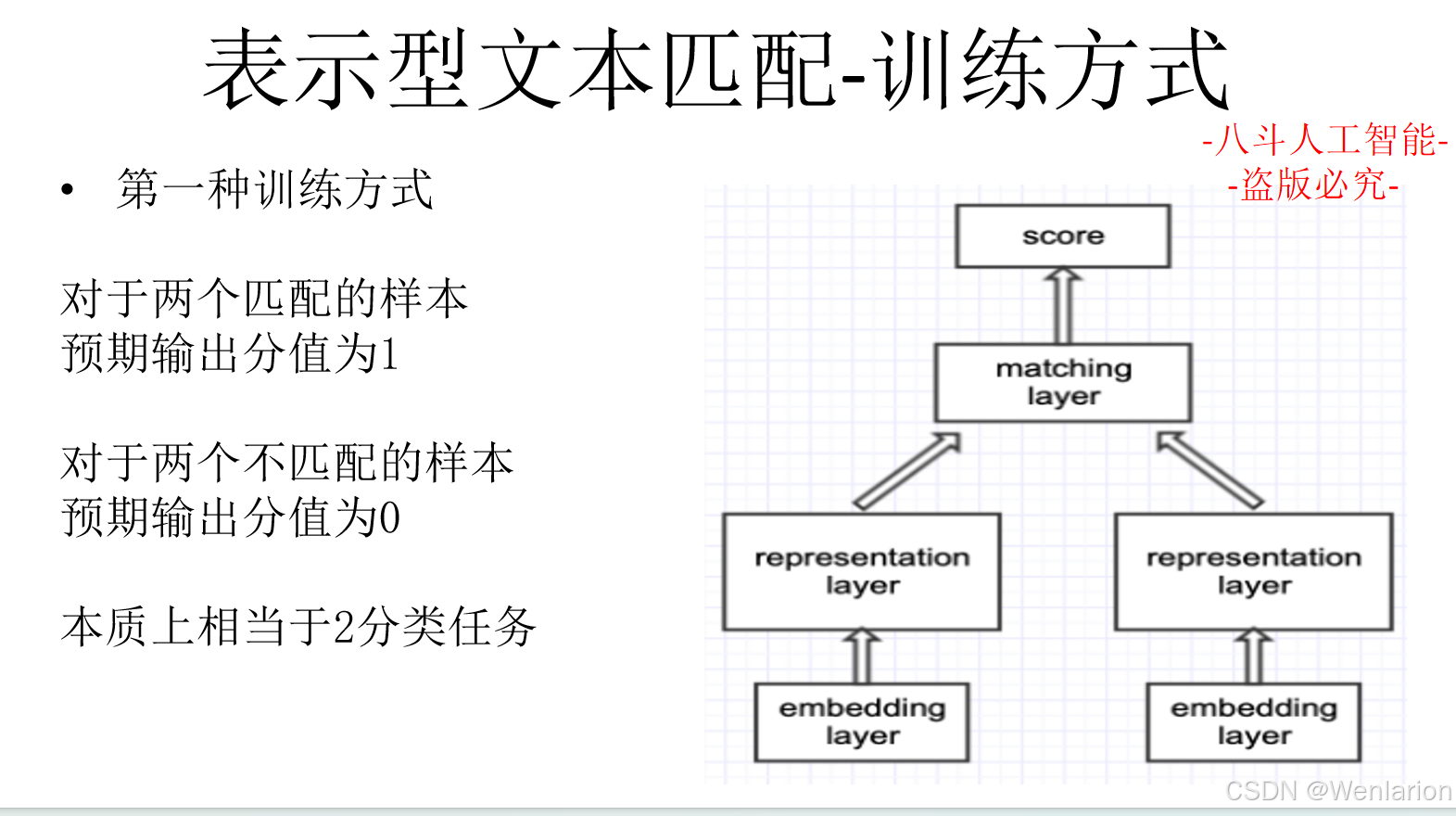
2.2 文本匹配





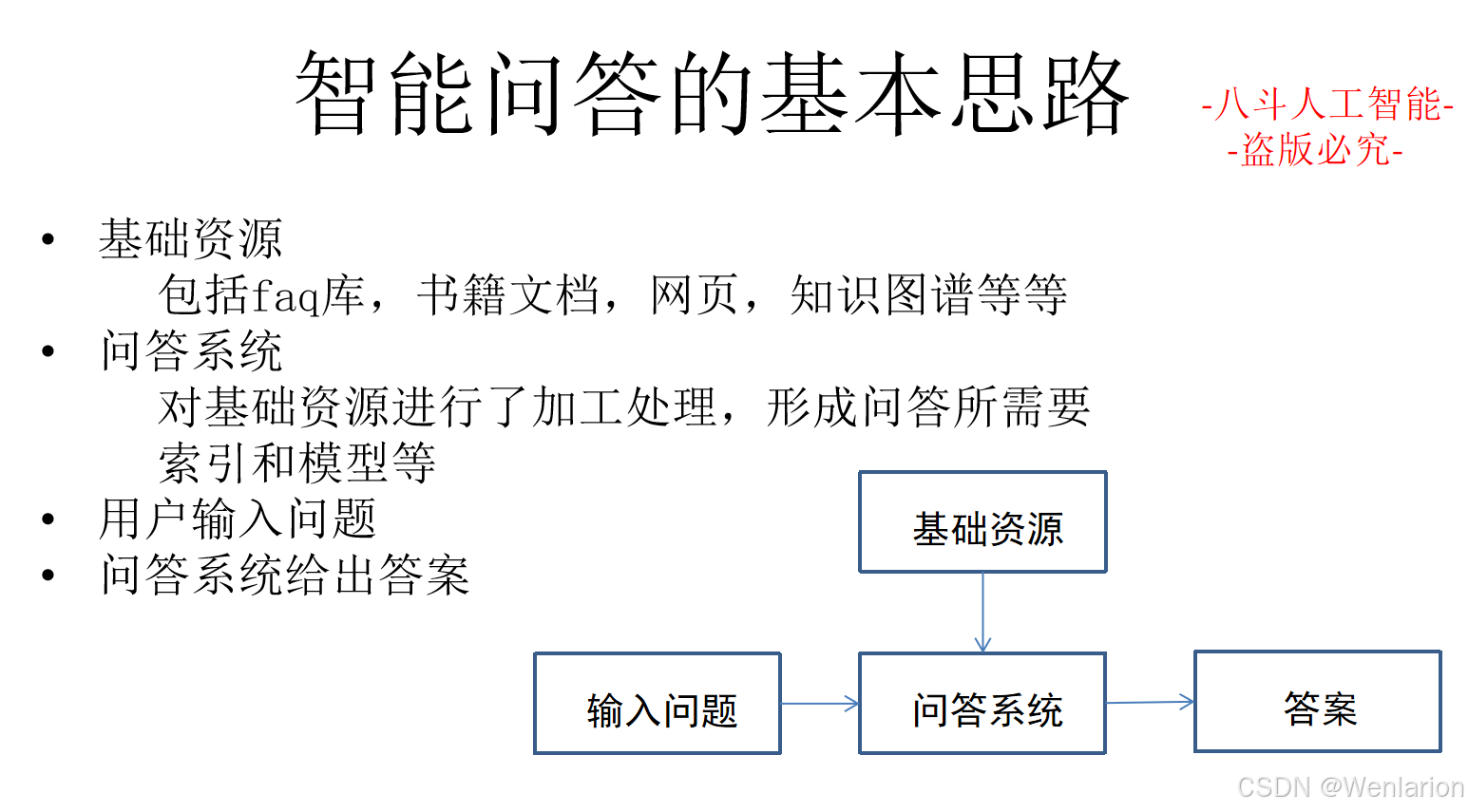
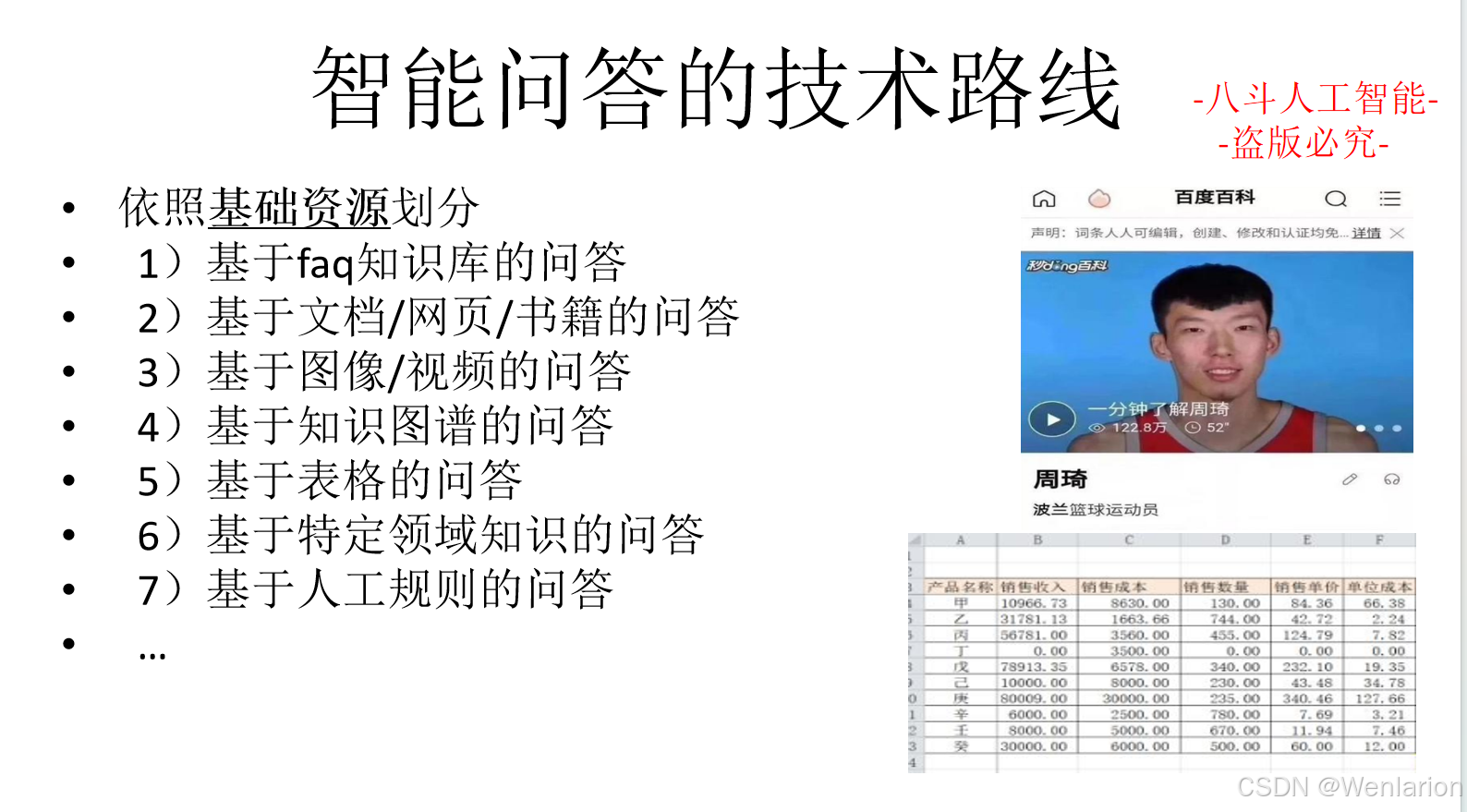
















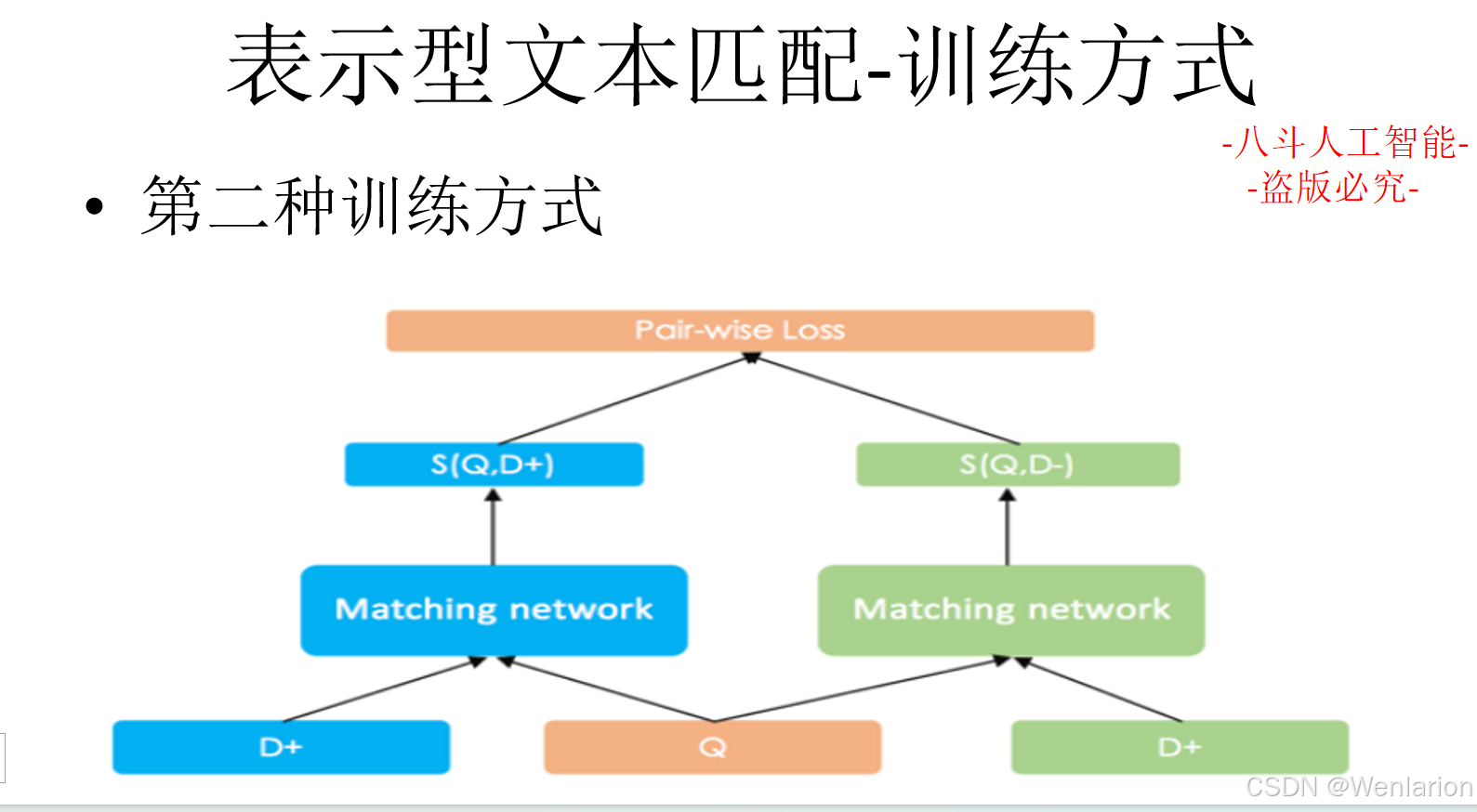
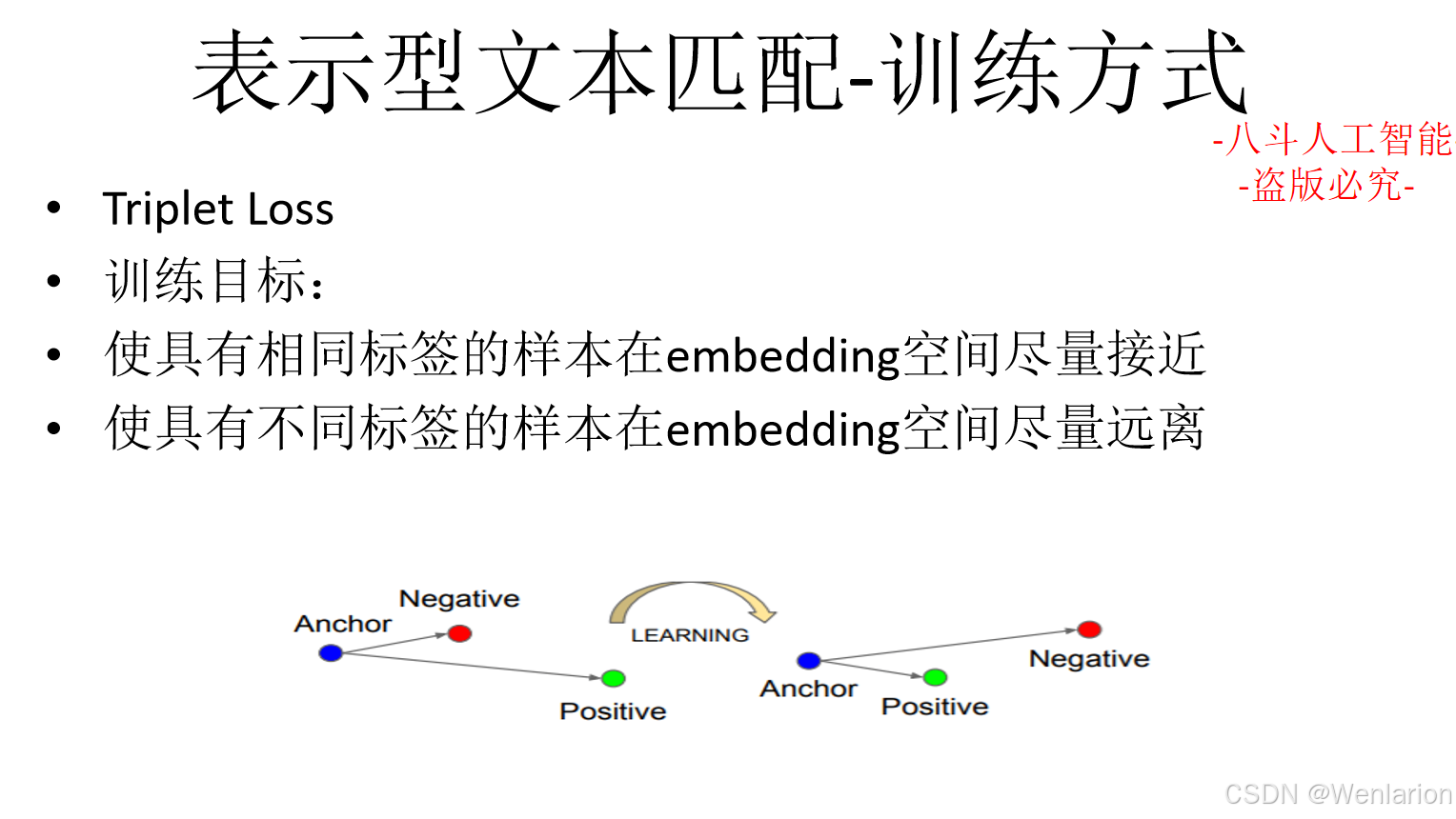

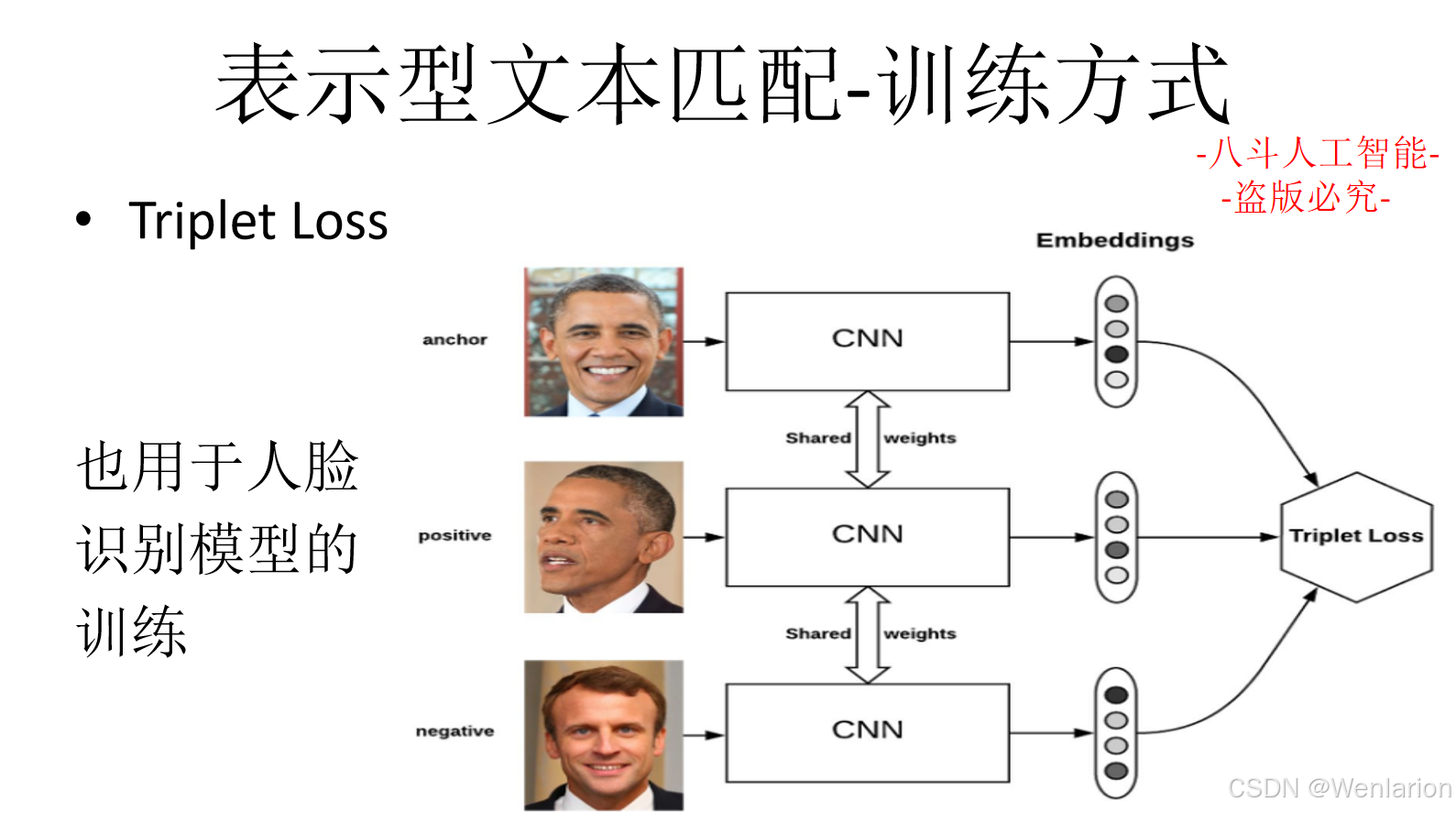
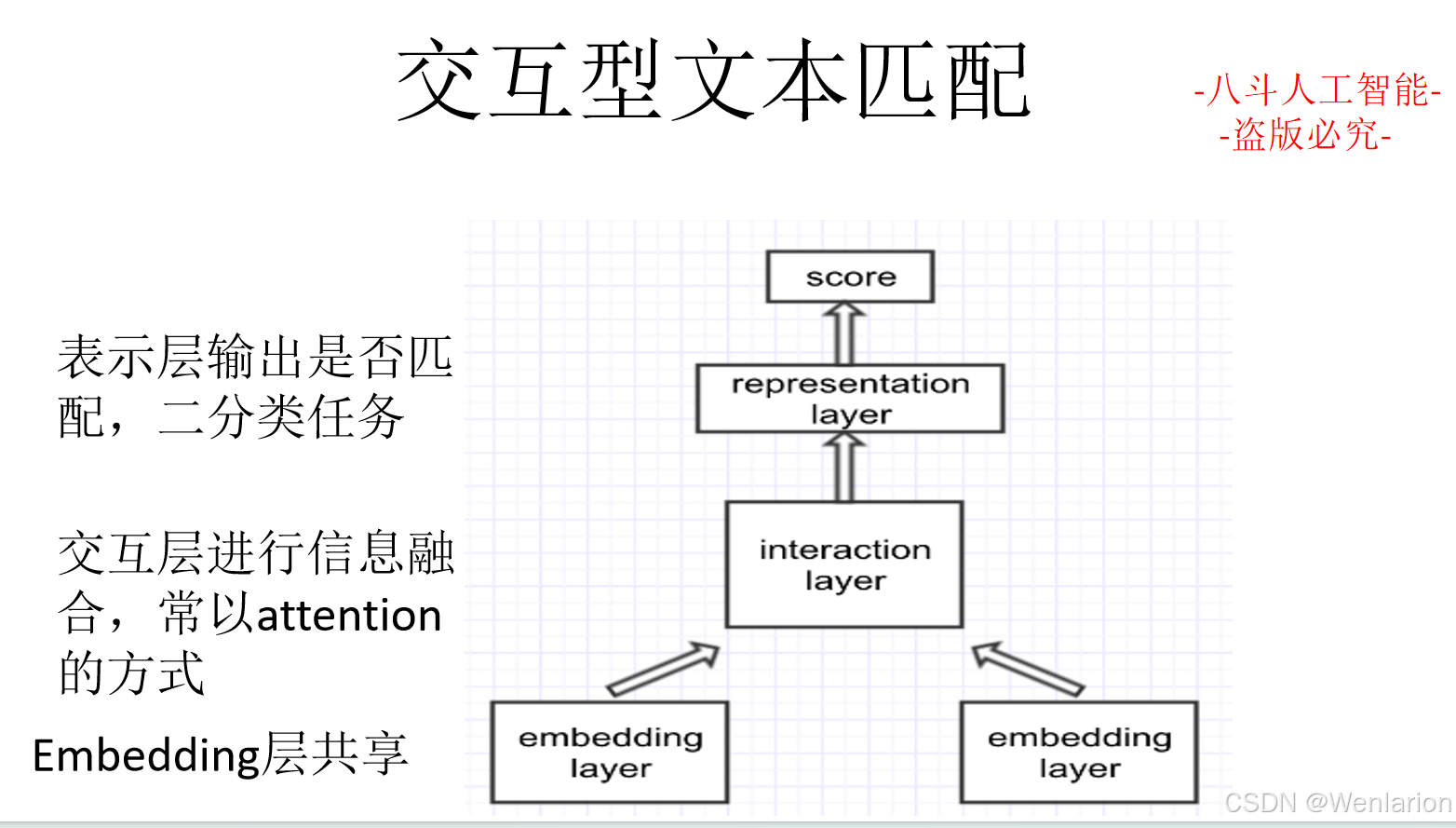

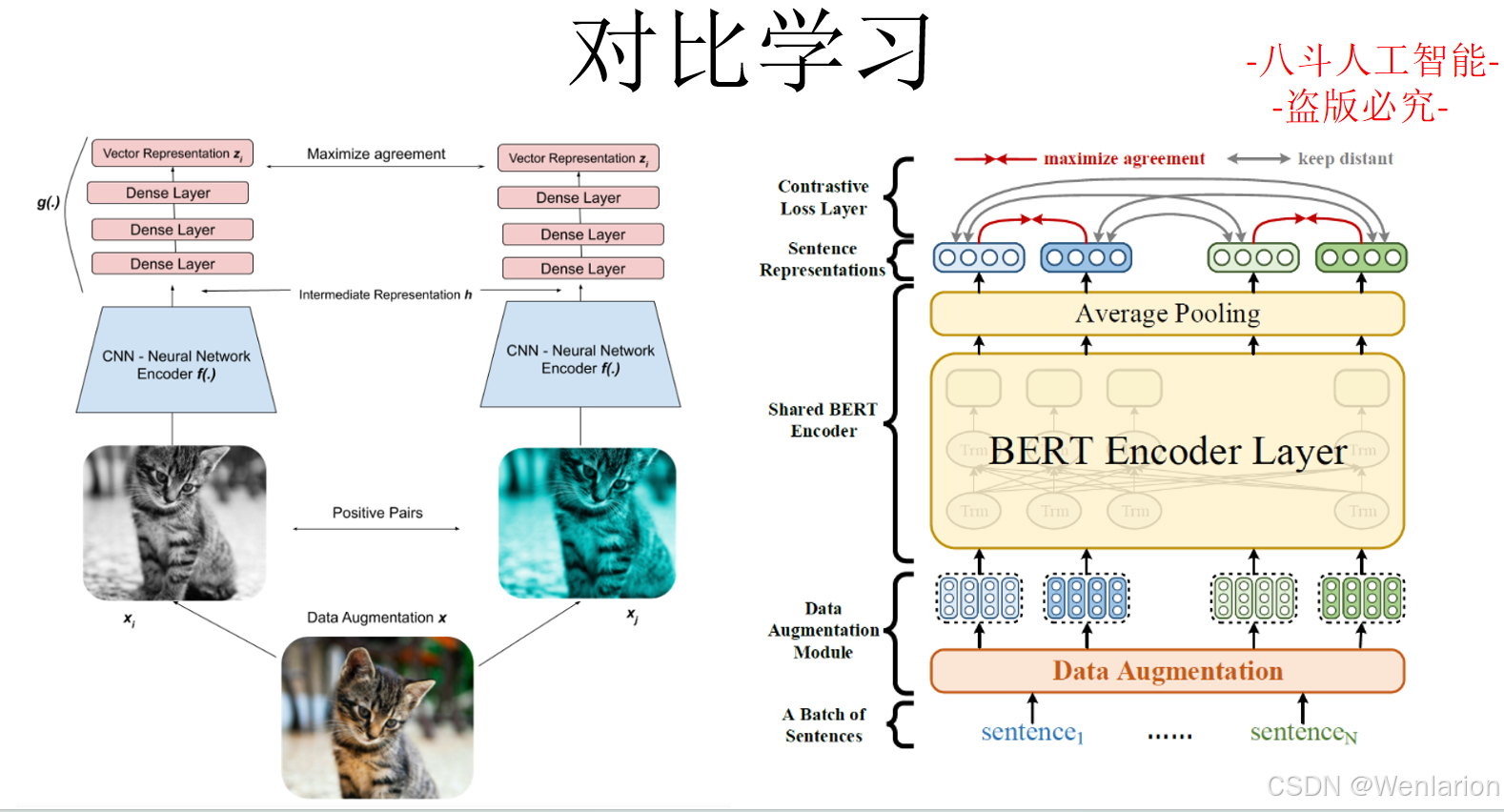

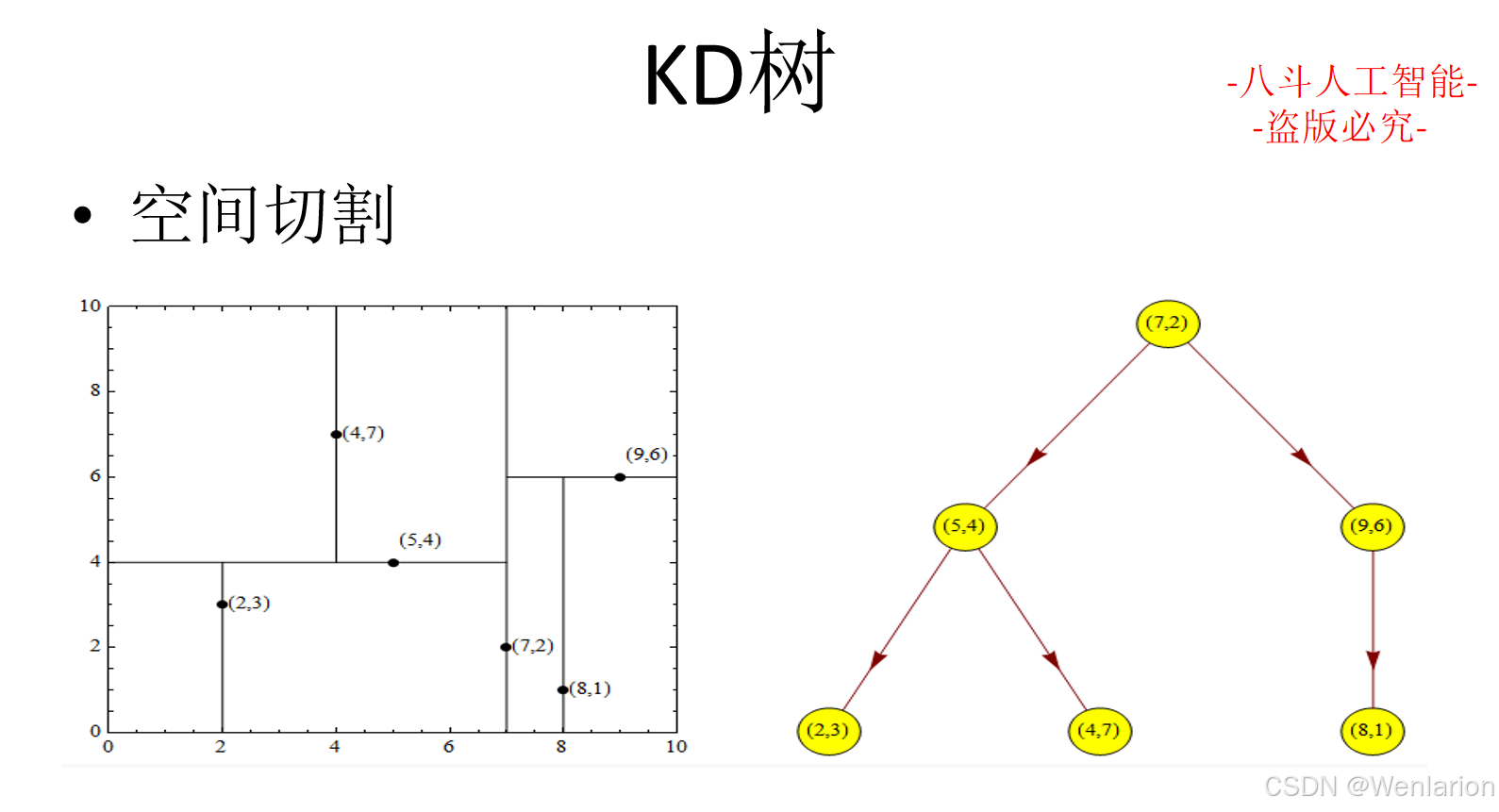
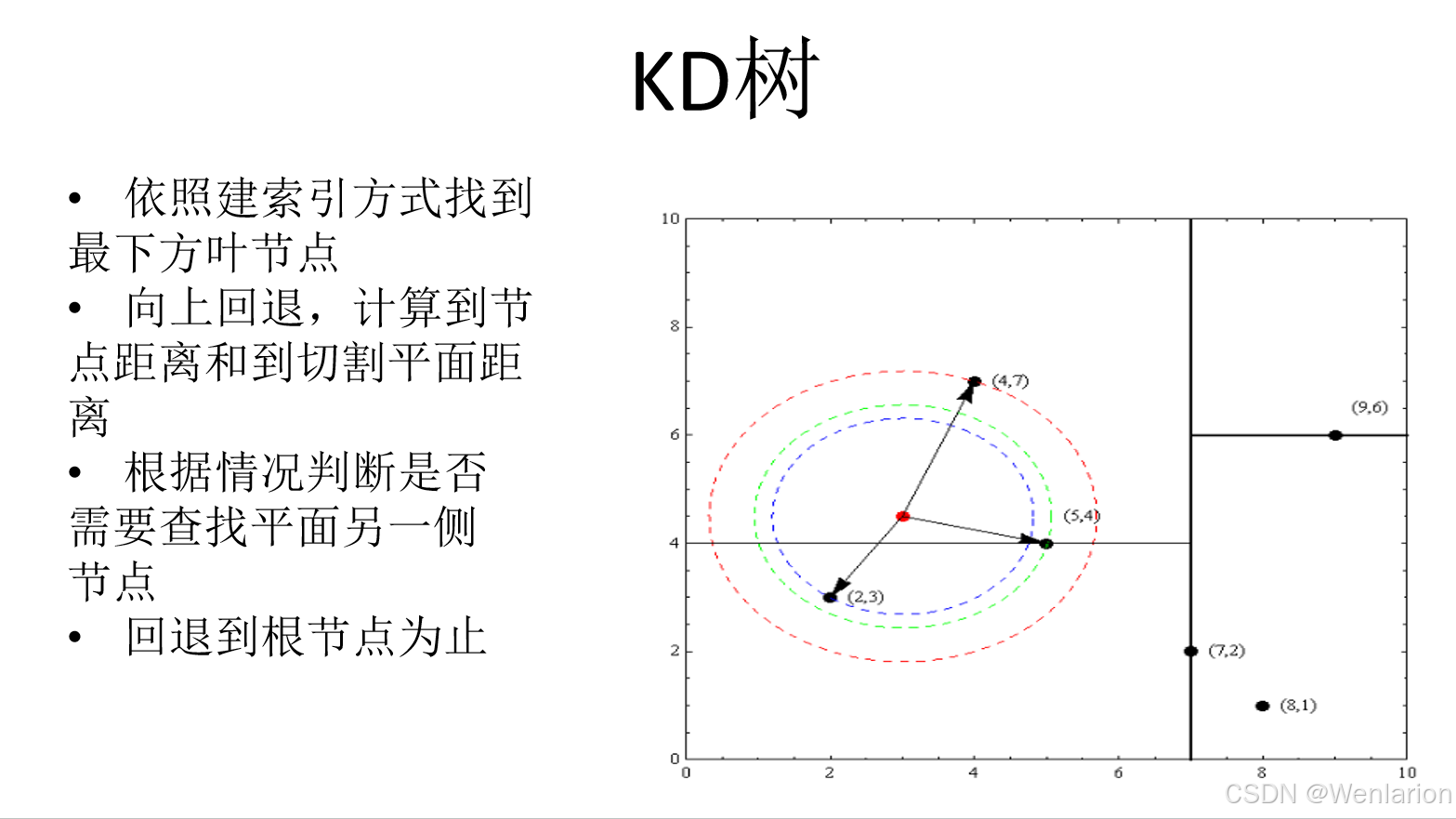

文本匹配相关论文和代码
一、传统基线(统计 / 语义匹配,低资源友好)
1. Word2Vec + Cosine Similarity(NeurIPS 2013)
-
简介:词向量经典方法,将文本转为词向量均值后计算余弦相似度,是文本匹配最基础基线,简单高效、无训练成本,适用于快速验证场景。
-
代码地址:https://github.com/tmikolov/word2vec(官方,C/Python);https://github.com/RaRe-Technologies/gensim(Python 封装,易用)
2. GloVe: Global Vectors for Word Representation(EMNLP 2014)
-
简介:基于全局词共现统计的词向量,比 Word2Vec 更贴合语义匹配场景,文本匹配中作为基线性能优于普通 Word2Vec,常与传统分类器结合使用。
-
代码地址:https://github.com/stanfordnlp/glove(官方,C/Python)
二、深度学习经典模型(2015-2019,Siamese / 交互架构核心)
1. Siamese CNN:Siamese Convolutional Neural Networks for One-Shot Image Recognition(ICML 2015,文本适配主流)
-
简介:孪生网络开山之作,文本匹配中适配为共享权重 CNN,分别编码两个文本得到向量后计算相似度,无需大量标注数据,是小样本文本匹配经典模型,适配短文本(如问句匹配)。
-
代码地址:https://github.com/keon/siamese-networks(PyTorch,文本 / 图像通用);https://github.com/zhangluoyang/SiameseTextCNN(纯文本匹配,TensorFlow)
2. Siamese LSTM:Siamese Recurrent Architectures for Learning Sentence Similarity(AAAI 2016)
-
简介:将孪生网络与 LSTM 结合,捕获文本序列上下文信息,相比 Siamese CNN 更适合长文本匹配,解决了 CNN 对序列语义捕捉不足的问题,是问答匹配、对话匹配的经典基线。
-
代码地址:https://github.com/luozhouyang/python-sentence-similarity(包含 Siamese LSTM/CNN,易用);https://github.com/ematvey/tensorflow-seq2seq-siamese(TensorFlow)
3. ESIM:Enhanced LSTM for Natural Language Inference(ACL 2017)
-
简介:交互型匹配经典模型(非孪生),针对自然语言推理(NLI,文本匹配子任务)设计,通过局部语义对齐 + 注意力交互 + 融合层深度捕捉两个文本的语义关联,性能远超同期孪生模型,成为 NLI / 通用文本匹配的强基线。
-
代码地址:https://github.com/coetaur0/ESIM(官方,PyTorch);https://github.com/huggingface/transformers(内置 ESIM 实现)
4. BiMPM:Bilateral Multi-Perspective Matching for Natural Language Inference(ICLR 2018)
-
简介:在 ESIM 基础上提出多视角双向匹配,从词级 / 短语级 / 句子级多维度对两个文本进行双向交互匹配,引入多视角相似度矩阵,进一步提升复杂语义匹配的准确性,在 NLI、问答匹配数据集上刷新 SOTA。
-
代码地址:https://github.com/zhiguowang/BiMPM(官方,PyTorch/TensorFlow)
5. MatchPyramid:Text Matching as Image Recognition(AAAI 2016)
-
简介:创新将文本匹配转化为二维相似度矩阵的图像识别问题,通过 CNN 对两个文本的词级相似度矩阵进行卷积池化,捕捉局部匹配模式与长距离语义关联,适合短文本精准匹配(如搜索 query-doc 匹配)。
-
代码地址:https://github.com/NTMC-Community/MatchZoo(内置 MatchPyramid,一站式文本匹配工具包)
6. DRMM:Deep Relevance Matching Model for Ad-hoc Retrieval(CIKM 2016)
-
简介:针对检索式文本匹配(ad-hoc IR)设计,基于词级相似度分布构建匹配特征,通过多层感知机建模相似度分布的非线性关系,对长文档与短查询的匹配适配性强,工业界检索场景广泛使用。
-
代码地址:https://github.com/NTMC-Community/MatchZoo(内置 DRMM/DRMM-TKS)
三、预训练模型适配(2018 至今,SOTA 主流,兼顾通用 / 专项)
1. BERT for Sentence Similarity(NAACL 2019,经典适配)
-
简介:BERT 原生适配文本匹配的核心方法,通过 **[CLS] 向量拼接 / 差值 / 点积或句子对直接输入([CLS] 句 1 [SEP] 句 2 [SEP])** 微调,大幅刷新各类文本匹配任务 SOTA,成为通用文本匹配的标配基线。
-
论文地址:https://arxiv.org/abs/1810.04805(BERT 主论文);https://aclanthology.org/W19-4301/(BERT 文本匹配专项)
-
代码地址:https://github.com/google-research/bert(官方,含句子对微调脚本);https://github.com/huggingface/transformers(一键适配,支持所有下游框架)
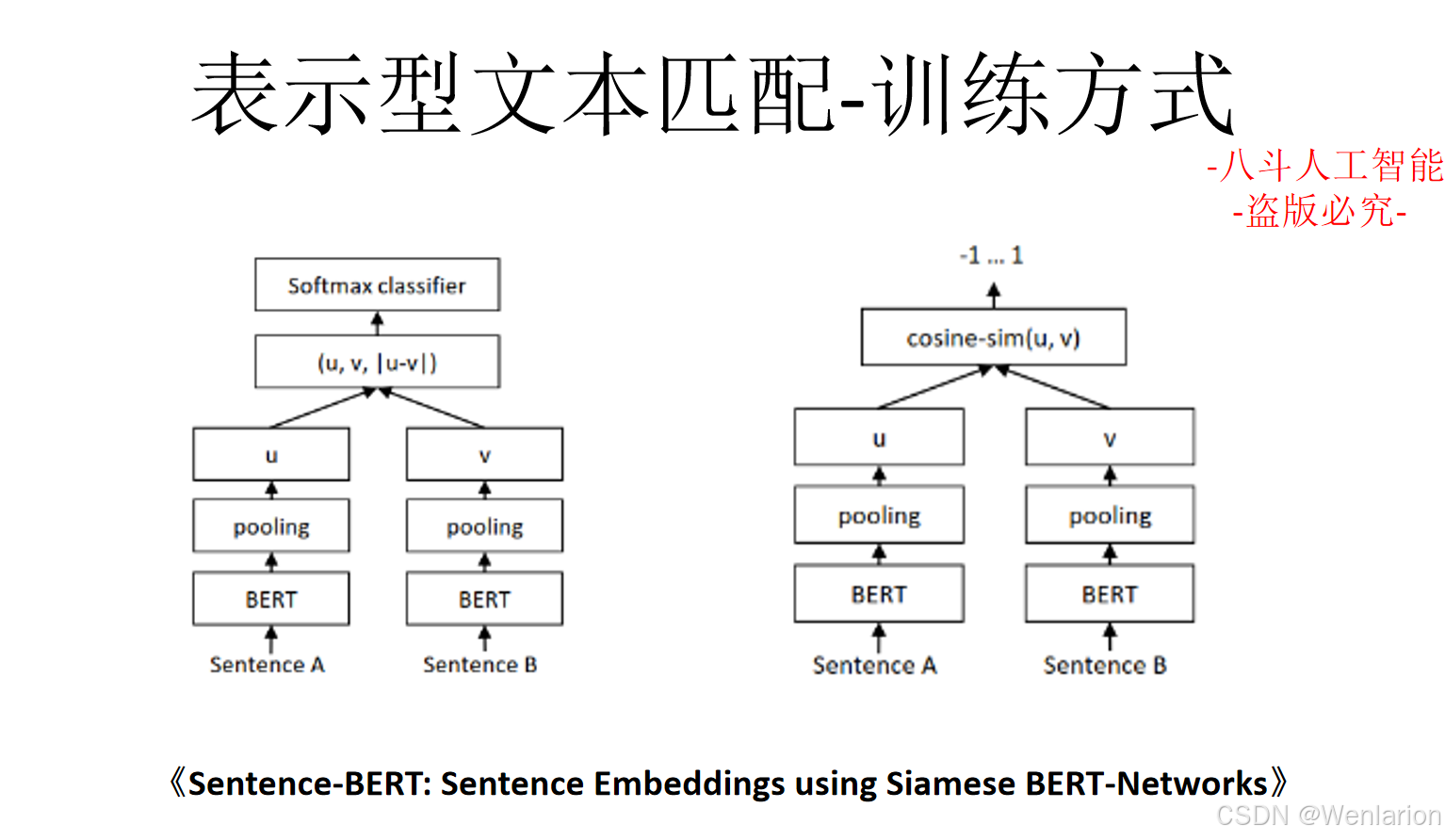
2. Sentence-BERT:Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks(EMNLP 2019)
-
简介:工业界文本匹配首选模型,对 BERT 进行孪生网络改造,通过共享权重编码得到固定长度的句子嵌入,直接计算余弦相似度即可完成匹配,解决了原生 BERT 句子嵌入计算慢、相似度性能差的问题,推理速度提升百倍,兼顾精度与效率。
-
代码地址:https://github.com/UKPLab/sentence-transformers(官方,含预训练模型 + 微调脚本,支持多语言)
3. ERNIE 3.0 for Text Matching(ACL 2021)
-
简介:百度提出的中文预训练模型,针对中文文本匹配优化,融入知识增强 + 句法增强,在中文问答匹配、语义相似度、NLI 等任务上性能优于 BERT/RoBERTa,是中文文本匹配的主流选择。
-
代码地址:https://github.com/PaddlePaddle/PaddleNLP(官方,含 ERNIE 文本匹配专项实现)
4. DeBERTa:DeBERTa: Decoding-enhanced BERT with Disentangled Attention(ICLR 2021)
-
简介:微软提出的 BERT 改进版,通过解耦注意力 + 增强解码器提升语义表示能力,在自然语言推理、语义相似度等文本匹配核心任务上超越 RoBERTa/SBERT,是英文文本匹配的 SOTA 基线之一。
-
代码地址:https://github.com/microsoft/DeBERTa(官方,PyTorch);https://huggingface.co/microsoft(预训练模型直接调用)
四、专项优化模型(对比学习 / 低资源 / 长文本,细分场景 SOTA)
1. SimCSE:Contrastive Learning of Sentence Embeddings(EMNLP 2021)
-
简介:对比学习文本匹配经典,通过自监督对比学习训练句子嵌入,无需标注匹配数据,仅用单句语料即可训练,在无监督 / 半监督文本匹配任务上性能远超传统方法,适配低资源场景,可与 SBERT 结合进一步提升性能。
-
代码地址:https://github.com/princeton-nlp/SimCSE(官方,PyTorch);https://github.com/UKPLab/sentence-transformers(内置 SimCSE 实现)
2. CoSENT:Cosine Sentence Similarity for Contrastive Learning(2022,中文优化)
-
简介:针对 SimCSE 在中文场景的不足优化,将对比损失改为余弦相似度排序损失,解决了 SimCSE 中文训练不稳定、相似度区分度低的问题,是目前中文无监督文本匹配 SOTA,工业界广泛使用。
-
代码地址:https://github.com/bojone/cosent(官方,TensorFlow/PyTorch);https://github.com/UKPLab/sentence-transformers(内置 CoSENT)
3. LongLM for Long Text Matching(NeurIPS 2022,长文本专项)
-
简介:针对长文本匹配(如文档 - 文档、长 query - 长 doc)设计的预训练模型,通过稀疏注意力 + 分段编码解决 Transformer 长文本建模的显存 / 计算问题,在长文本语义相似度、长文档匹配任务上性能远超普通 BERT/SBERT。
-
代码地址:https://github.com/allenai/longlm(官方,PyTorch)
五、一站式文本匹配工具包(多模型集成,快速复现 / 落地)
-
MatchZoo:https://github.com/NTMC-Community/MatchZoo专为文本匹配设计的工具包,内置 MatchPyramid、DRMM、ARC-I/II 等经典深度学习模型,支持快速搭建、训练、评估,适配检索式匹配 / 语义相似度任务。
-
Sentence-Transformers:https://github.com/UKPLab/sentence-transformers文本嵌入 / 匹配一站式工具包,内置 SBERT、SimCSE、CoSENT 等主流模型,支持预训练模型直接调用、自定义数据集微调,输出固定长度句子嵌入,可直接计算相似度,工业界落地首选。
-
PaddleNLP(中文专属):https://github.com/PaddlePaddle/PaddleNLP百度推出的中文 NLP 工具包,内置 ERNIE、SimCSE、CoSENT 等中文优化的文本匹配模型,附带中文基准数据集(如 LCQMC、BQ Corpus),适配中文问答匹配、语义相似度等场景。
六、中文文本匹配专属基准数据集(附论文 / 地址)
文本匹配论文复现常用中文数据集,均为顶会公开,可直接用于模型训练 / 测试:
-
LCQMC(哈工大):https://aclanthology.org/C18-1105/(论文);https://github.com/liuhuanyong/LCQMC(数据)
-
BQ Corpus(百度):https://aclanthology.org/D18-1032/(论文);https://github.com/baidu-research/BQCorpus(数据)
-
CMNLI(中文 NLI):https://aclanthology.org/2020.emnlp-main.396/(论文);https://github.com/CLUEbenchmark/CLUE(数据,CLUE 套件)
2.3 序列标注


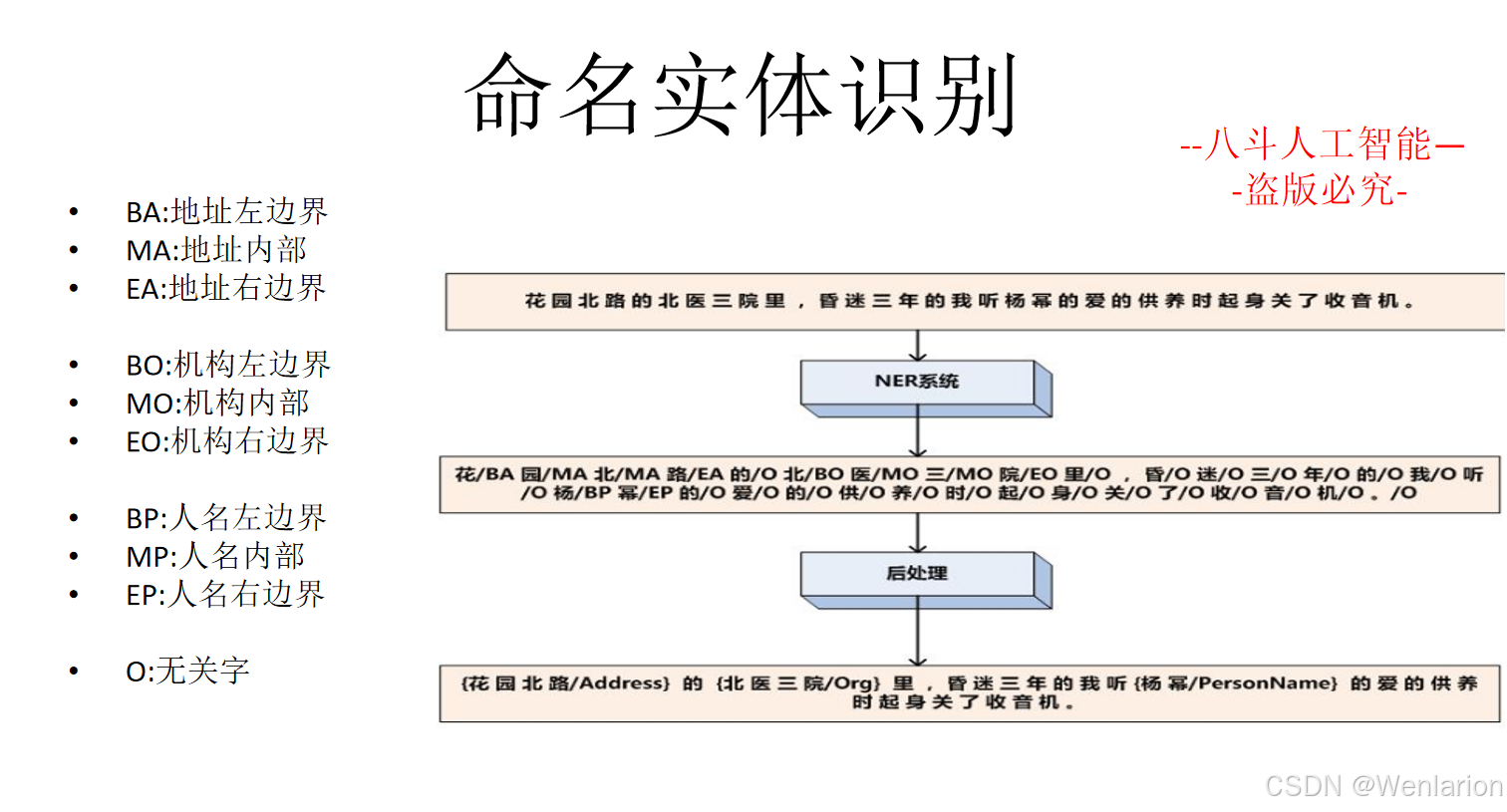
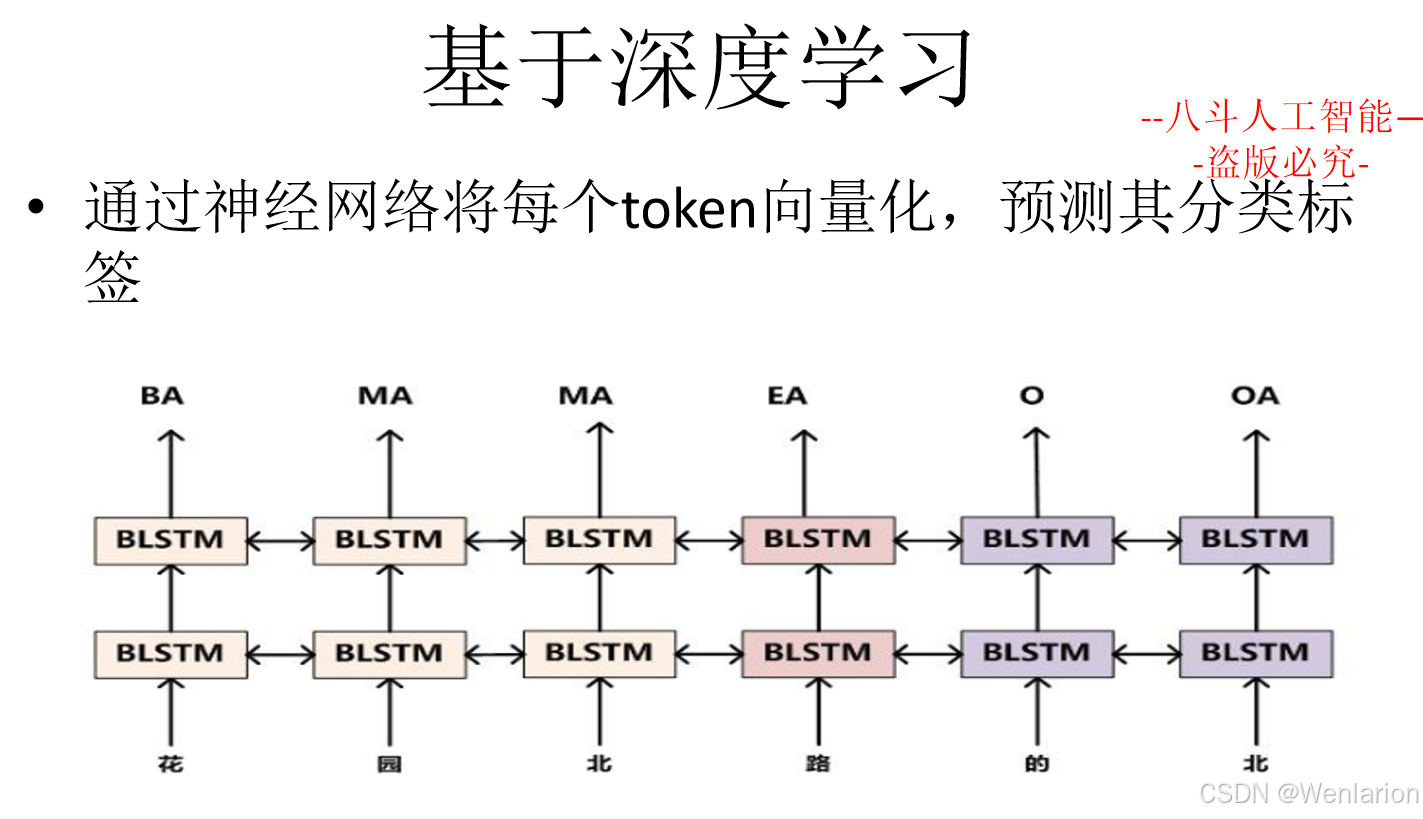
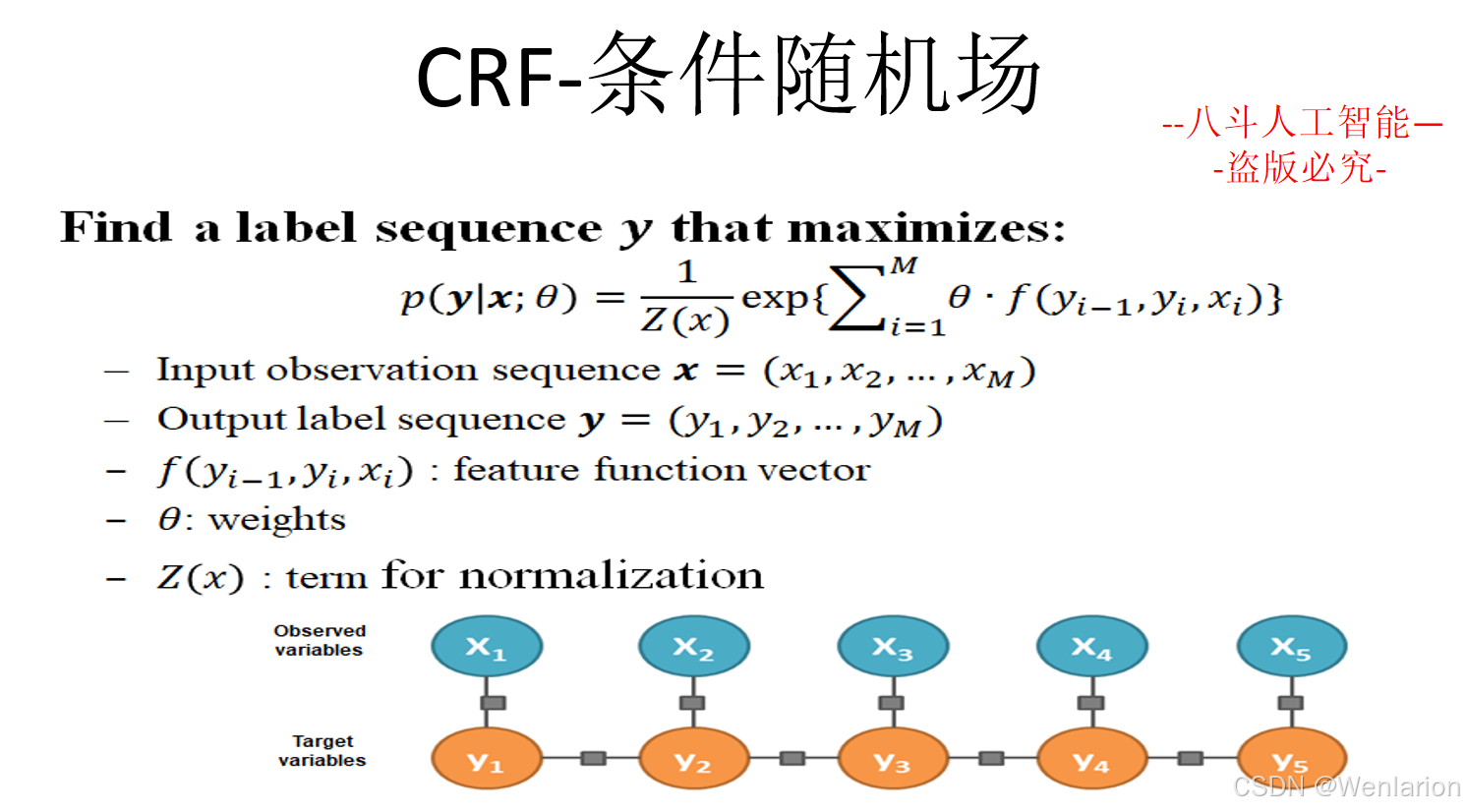

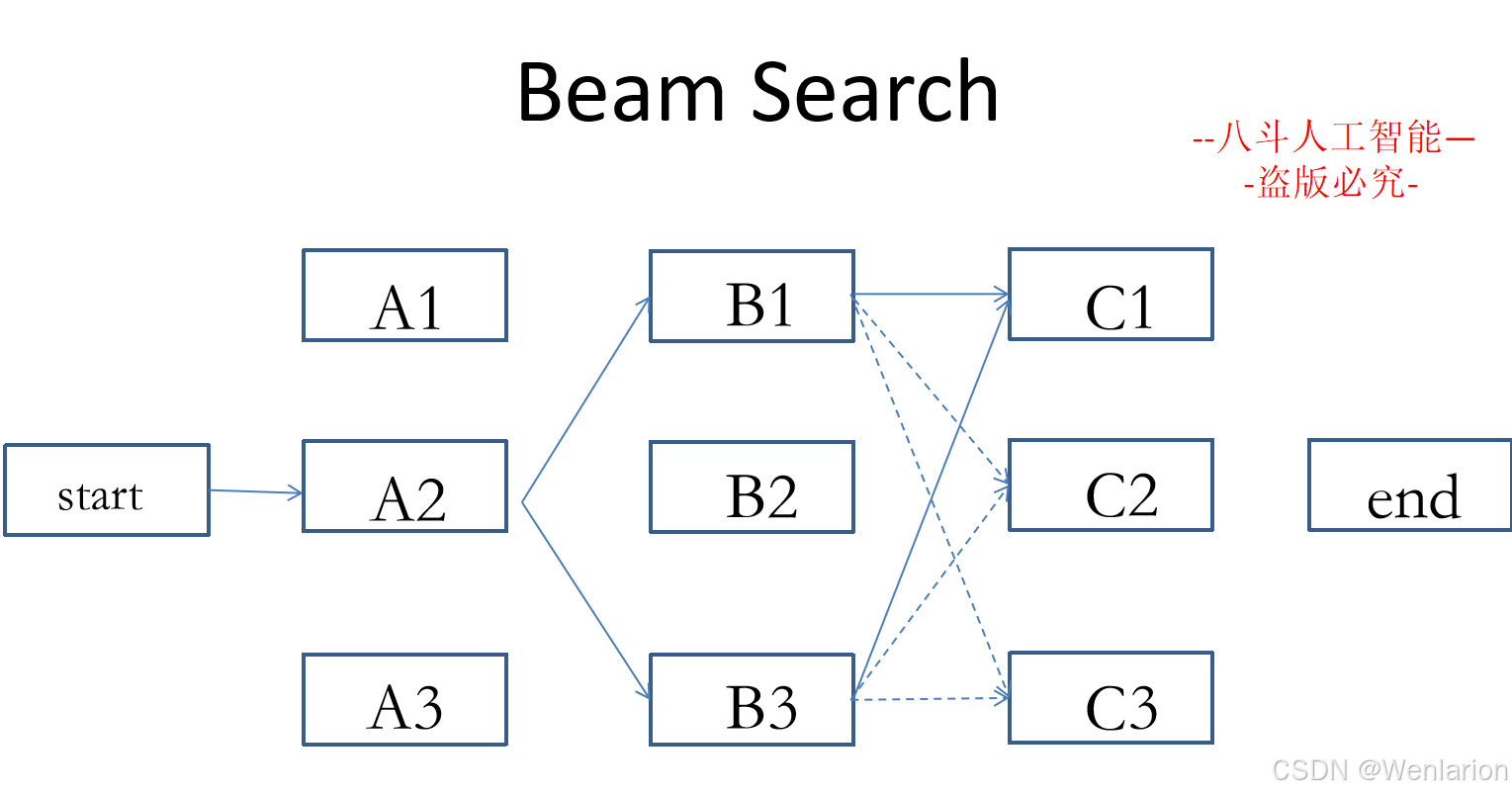
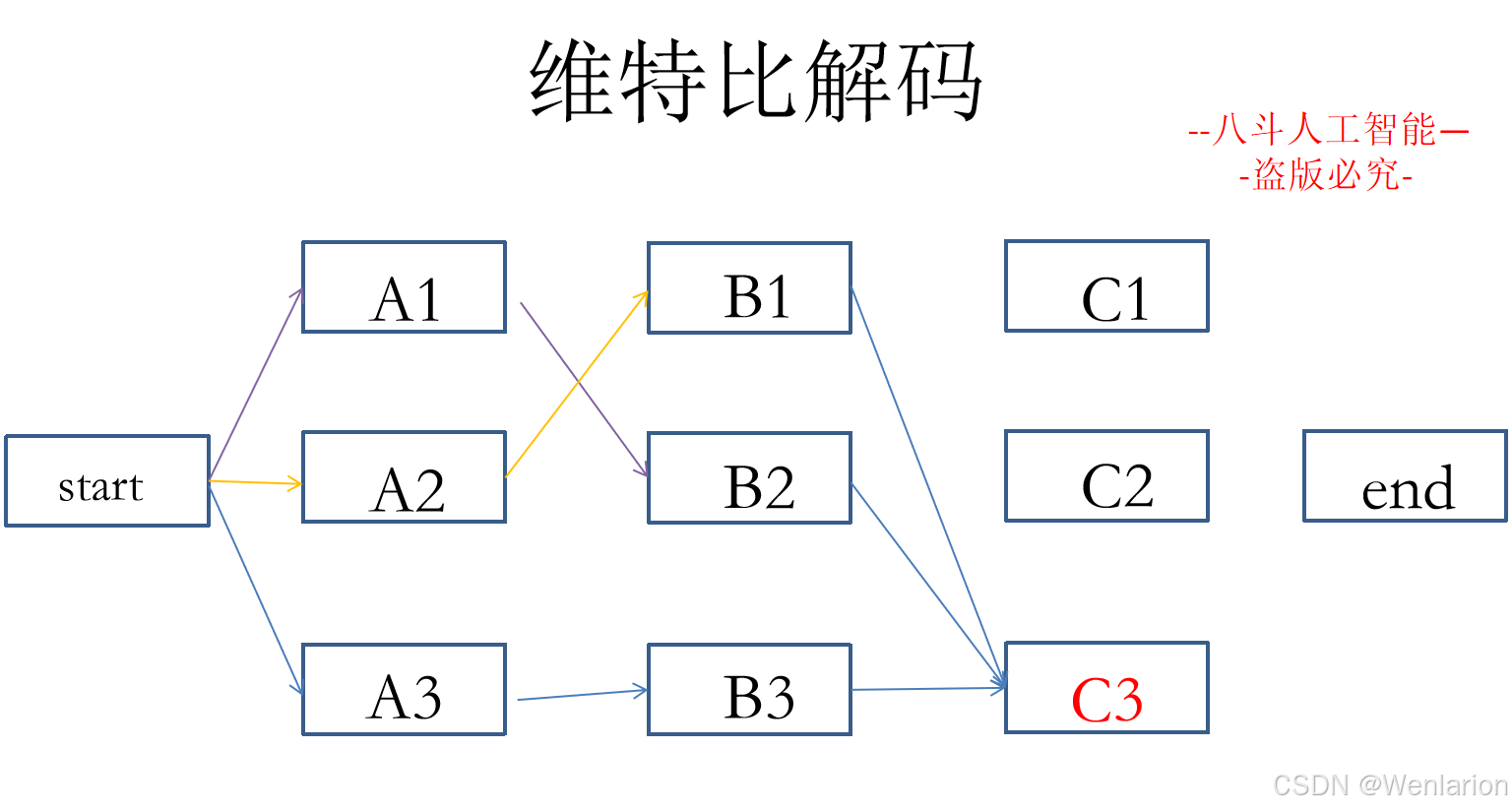


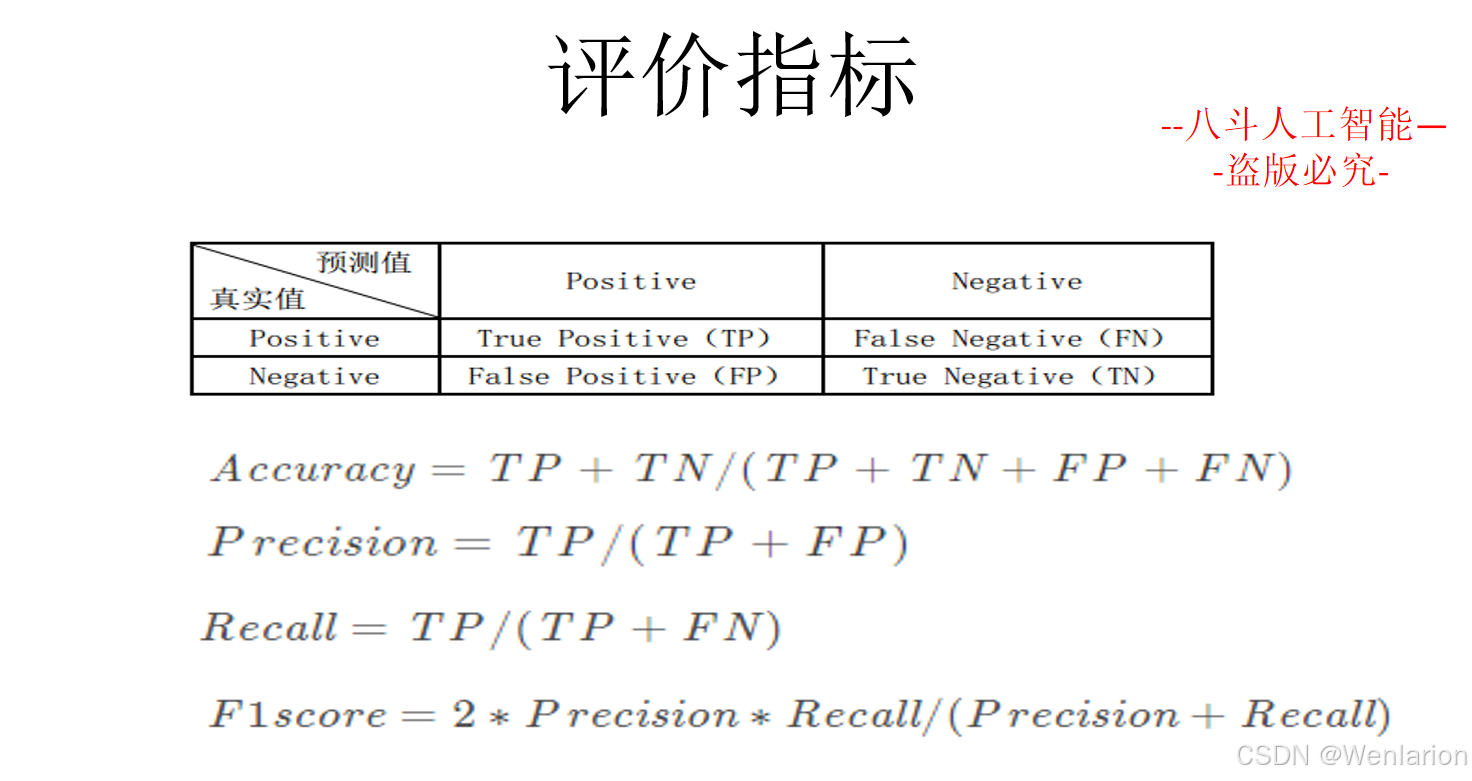







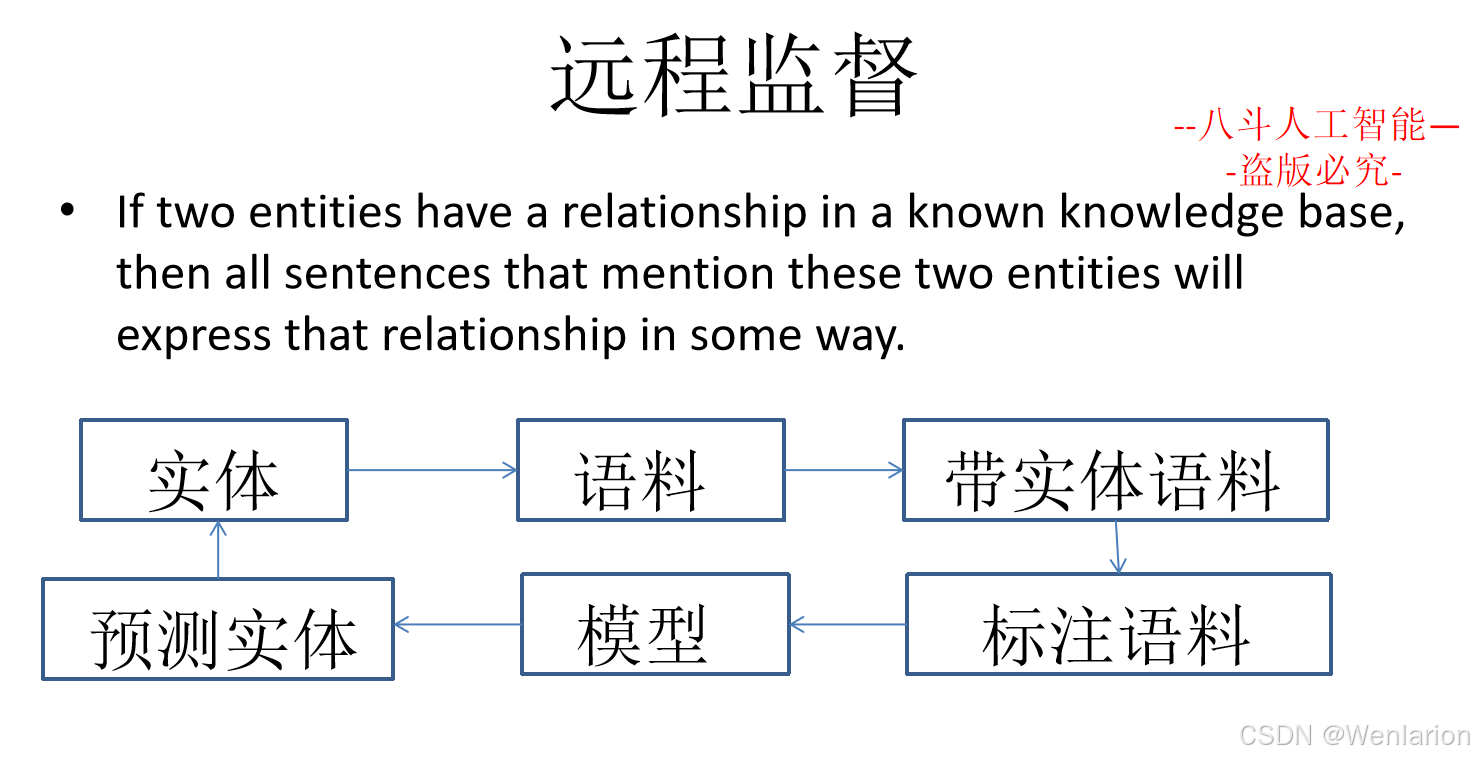
序列标注相关论文和代码
一、传统统计基线(2000-2015,序列标注基础)
该类是序列标注的经典基线,奠定概率图模型在序列建模的核心框架,至今仍是低资源、小样本场景的可靠对比基准,其中 CRF 是后续深度学习模型的标配组件。
1. CRF:Conditional Random Fields (2001,经典顶刊)
-
简介:条件随机场奠基之作,基于概率图模型的判别式模型,能建模标签间的依赖关系(如 NER 中 “B-PER” 后大概率是 “I-PER”),解决朴素分类器(如 SVM)忽略序列上下文的问题,是词性标注、NER 的传统 SOTA,后续深度学习模型均以CNN/RNN+CRF为经典架构。
-
论文地址:https://www.jmlr.org/papers/volume1/lafferty01a/lafferty01a.pdf
-
代码地址:https://github.com/larsmans/seqlearn(Python 轻量实现);https://github.com/scikit-learn-contrib/crfsuite(工业界主流 CRFsuite)
2. BiLSTM-CRF 基线(2015,ACL 配套经典实现)
-
简介:非单篇论文,是深度学习序列标注的首个经典基线,由 BiLSTM 捕获文本双向上下文语义,CRF 建模标签序列依赖,首次将深度学习与概率图模型结合,大幅超越传统 CRF,成为 NER/POS 的标配基线(后续所有模型均以此为对比)。
-
参考论文:https://arxiv.org/abs/1508.01991(BiLSTM+CRF 经典应用)
-
代码地址:https://github.com/guillaumegenthial/sequence_tagging(经典实现);https://github.com/chakki-works/seqeval(序列标注评估工具)
二、深度学习经典模型(2015-2019,非预训练时代 SOTA)
该类模型基于CNN/RNN/ 注意力优化特征提取,解决 BiLSTM-CRF 的长距离依赖、局部特征捕捉不足等问题,是预训练模型出现前的主流序列标注方法,轻量高效,适合资源受限场景。
1. LSTM-CNNs-CRF:Neural Architectures for Named Entity Recognition(ACL 2016)
-
简介:NER 经典模型,在 BiLSTM-CRF 基础上加入CNN 提取字符级特征,解决词向量未覆盖的生僻词、OOV(未登录词)问题,同时融合词级 + 字符级特征,在英文 NER(CoNLL-2003)上刷新 SOTA,中文适配后同样提升分词 / NER 性能。
-
代码地址:https://github.com/kyzhouhzau/BERT-NER(含该模型实现);https://github.com/glample/tagger(官方思路复现)
2. IDCNN-CRF:Fast and Accurate Entity Recognition with Iterated Dilated Convolutions(ACL 2017)
-
简介:针对 BiLSTM 速度慢的优化,用空洞卷积(IDCNN)替代 BiLSTM,通过多层空洞卷积捕获长距离上下文,同时保持 CNN 的并行计算优势,推理速度比 BiLSTM 快 5-10 倍,性能接近 BiLSTM-CRF,是工业界低延迟序列标注的首选轻量模型。
-
代码地址:https://github.com/baidu-research/idlcnn-ner(官方思路复现);https://github.com/zhanzecheng/IDCNN-CRF-NER(PyTorch 实现)
3. Attention-Based BiLSTM-CRF:Attention-Based Bidirectional LSTM-CRF Model for Relation Extraction(EMNLP 2016,序列标注适配)
-
简介:将自注意力机制融入 BiLSTM-CRF,让模型自动聚焦序列中的关键 token(如 NER 中的实体核心词),增强特征提取能力,在 NER/POS/ 事件抽取上均优于基础 BiLSTM-CRF,是注意力机制在序列标注的经典应用。
-
代码地址:https://github.com/yuhaozhang/sentence-attention-ner(PyTorch 实现);https://github.com/xiangrongzeng/attention-bilstm-crf(TensorFlow 实现)
4. Chinese NER with Lattice LSTM:Chinese NER Using Lattice LSTM(ACL 2018)
-
简介:中文 NER 专属经典模型,解决中文分词歧义导致的 NER 误差问题,将 ** 词汇格子(Lattice)** 融入 LSTM,直接建模 “字 - 词” 双层信息,无需提前分词,在中文 NER(MSRA/ONTONOTE)上大幅超越传统 BiLSTM-CRF,是中文序列标注的里程碑。
-
代码地址:https://github.com/jiesutd/LatticeLSTM(官方,PyTorch);https://github.com/liangliangyy/LatticeLSTM(中文适配优化版)
5. FLAT:Chinese NER Using Flat-Lattice Transformer(ACL 2020)
-
简介:Lattice LSTM 的优化版,解决 Lattice LSTM显存占用高、并行性差的问题,将词汇格子转化为扁平的注意力矩阵,融入 Transformer 架构,兼顾 “字 - 词” 特征与并行计算,是中文非预训练序列标注的 SOTA。
-
代码地址:https://github.com/LeeSureman/Flat-Lattice-Transformer(官方,PyTorch)
三、预训练模型适配(2019 至今,通用序列标注 SOTA)
基于BERT/XLNet 等预训练语言模型微调,是目前序列标注的标配主流方法,预训练模型已捕获海量语义信息,仅需简单微调 + CRF 即可刷新所有数据集 SOTA,分通用适配和中文专属优化两类,覆盖中英文 NER/POS/ 分词。
1. BERT-CRF:BERT for Named Entity Recognition(NAACL 2019,经典适配)
-
简介:预训练模型序列标注的首个经典基线,将 BERT 作为特征提取器,输出的 token 嵌入送入 CRF 层建模标签序列,在英文 CoNLL-2003、中文 MSRA 等 NER 数据集上大幅超越所有深度学习模型,成为通用序列标注的 SOTA 基线(后续所有预训练模型均以此为基础)。
-
参考论文:https://arxiv.org/abs/1810.04805(BERT 主论文)+ https://aclanthology.org/N19-1090/(BERT-NER 专项)
-
代码地址:https://github.com/kyzhouhzau/BERT-NER(经典实现);https://huggingface.co/bert-base-uncased(预训练模型直接调用)
2. XLNet-CRF:XLNet: Generalized Autoregressive Pretraining for Language Understanding(NeurIPS 2019)
-
简介:BERT 的改进版,采用自回归预训练,解决 BERT 的掩码歧义问题,捕获更全面的上下文依赖,XLNet-CRF 在 NER/POS 上性能略优于 BERT-CRF,是英文序列标注的强基线。
-
代码地址:https://github.com/zihangdai/xlnet(官方);https://github.com/namisan/mt-dnn(含 XLNet-NER 实现)
3. ERNIE 1.0/2.0:Enhanced Language Representation with Informative Entities(ACL 2019/2020)
-
简介:百度中文预训练模型,ERNIE 1.0 融入知识图谱实体信息,ERNIE 2.0 加入持续预训练 + 多任务学习,针对中文语料优化,ERNIE-CRF 在中文 NER / 分词 / 词性标注上远超 BERT-CRF,是中文序列标注的主流基线。
-
论文地址:https://aclanthology.org/P19-1139/(ERNIE 1.0);https://aclanthology.org/2020.emnlp-main.519/(ERNIE 2.0)
-
代码地址:https://github.com/PaddlePaddle/PaddleNLP(官方,含 ERNIE-NER / 分词);https://huggingface.co/ernie-1.0-base-zh(预训练模型)
4. RoBERTa-CRF:A Robustly Optimized BERT Pretraining Approach(ACL 2019)
-
简介:BERT 的优化版,通过更大训练数据、更长训练时间、移除 NSP 任务提升预训练效果,RoBERTa-CRF 是英文序列标注的 SOTA 基线,性能全面超越 BERT-CRF/XLNet-CRF,工业界落地首选。
-
代码地址:https://github.com/facebookresearch/fairseq(官方);https://github.com/huggingface/transformers(RoBERTa-NER 实现)
5. ALBERT-CRF:A Lite BERT for Self-supervised Learning of Language Representations(ICLR 2020)
-
简介:轻量版 BERT,通过参数共享、因式分解嵌入减少参数量(仅为 BERT 的 1/10),训练 / 推理速度更快,显存占用更低,ALBERT-CRF 性能接近 BERT-CRF,是资源受限场景(如边缘设备)的序列标注首选。
-
代码地址:https://github.com/google-research/albert(官方);https://huggingface.co/albert-base-v2(预训练模型)
6. MacBERT:Masked Aligned Cross Entropy for BERT Pre-training(ICLR 2021)
-
简介:中文轻量预训练模型,由哈工大讯飞联合提出,针对 BERT 中文适配的不足优化,参数量小、性能优,MacBERT-CRF 在中文 NER / 分词上性能与 ERNIE 相当,且训练 / 推理更快,是中文轻量序列标注的首选。
-
代码地址:https://github.com/ymcui/MacBERT(官方);https://huggingface.co/hfl/macbert-base-chinese(预训练模型)
四、专项优化模型(2020 至今,细分场景 SOTA)
针对序列标注的细分痛点(低资源、长文本、嵌套实体、轻量部署)设计,覆盖中文专属、低资源、嵌套 NER 等核心场景,是当前序列标注的研究热点。
1. Nested NER:Nested Named Entity Recognition with Flat-Lattice Transformer(ACL 2021)
-
简介:嵌套 NER 专属模型,解决传统 NER 无法识别重叠 / 嵌套实体的问题(如 “北京大学第一医院” 中包含 “北京大学” 和 “北京大学第一医院” 两个实体),基于 FLAT 架构加入层级标签机制,在嵌套 NER 数据集(ACE2005)上刷新 SOTA。
-
代码地址:https://github.com/LeeSureman/Flat-Lattice-Transformer(扩展实现);https://github.com/ShannonAI/ner-grokking(嵌套 NER 通用框架)
2. Low-Resource NER:Few-Shot Named Entity Recognition with Self-Supervision and Contrastive Learning(EMNLP 2021)
-
简介:低资源 NER 经典模型,结合自监督学习 + 对比学习,利用未标注数据增强特征,仅需少量标注样本即可实现高精度 NER,解决低资源 / 小样本场景的序列标注问题,适配中英文低资源 NER。
-
代码地址:https://github.com/voidism/Few-Shot-NER(官方思路复现);https://github.com/huggingface/transformers(对比学习适配)
3. Long Text NER:Longformer for Long-Document NER(EMNLP 2020)
-
简介:长文本序列标注专属模型,基于 Longformer 的稀疏注意力机制,解决传统 Transformer/BERT 的固定上下文长度限制(512token),可建模超长篇文本(如 1024/2048token),在长文档 NER / 事件抽取上性能远超 BERT-CRF。
-
代码地址:https://github.com/allenai/longformer(官方);https://github.com/ibeltagy/ner-longformer(Longformer-NER 实现)
4. Chinese Word Segmentation:BERT for Chinese Word Segmentation(ACL 2020,专项)
-
简介:中文分词经典预训练适配,将中文分词转化为序列标注任务(B/M/E/S 标签),用 BERT/MacBERT/ERNIE 做特征提取,结合 CRF 建模标签序列,在中文分词数据集(PKU/CTB)上刷新 SOTA,是中文分词的工业界标配。
-
代码地址:https://github.com/PaddlePaddle/PaddleNLP(官方中文分词);https://github.com/hfl/chinese-roberta-wwm-ext(中文预训练模型 + 分词实现)
5. Lightweight NER:DistilBERT-CRF:Distilling the Knowledge in a Pre-trained Transformer(NeurIPS 2019)
-
简介:轻量序列标注模型,通过知识蒸馏将 BERT 的知识迁移到小模型 DistilBERT,参数量减少 40%,推理速度提升 60%,性能保持 BERT 的 97%,是边缘设备 / 低延迟场景的序列标注首选。
-
代码地址:https://github.com/huggingface/transformers(DistilBERT 官方);https://github.com/amaiya/ktrain(DistilBERT-NER 快速实现)
五、序列标注一站式工具包 / 框架(快速复现 / 工业落地)
通用框架(中英文适配)
-
Hugging Face Transformers:https://github.com/huggingface/transformers主流 NLP 框架,内置 BERT/RoBERTa/XLNet 等所有预训练模型,提供序列标注专用微调接口,支持一键加载模型、自定义数据集、训练 / 推理,附带 seqeval 评估工具,适配 PyTorch/TensorFlow。
-
AllenNLP:https://github.com/allenai/allennlp专为 NLP 设计的框架,内置 BiLSTM-CRF/IDCNN-CRF/BERT-CRF 等所有序列标注模型,支持可视化、自定义组件,适合学术研究与快速原型开发。
-
seqeval:https://github.com/chakki-works/seqeval序列标注专用评估工具,支持 Precision/Recall/F1 计算,适配 NER/POS/ 分词等所有序列标注任务,是工业界与学术界的标配评估库。
中文专属框架(分词 / NER 优化)
-
PaddleNLP:https://github.com/PaddlePaddle/PaddleNLP百度推出的中文 NLP 框架,内置 ERNIE/MacBERT/FLAT 等中文优化的序列标注模型,附带中文 NER / 分词 / 词性标注专用数据集(MSRA/PKU/ONTONOTE)和预训练模型,中文序列标注落地首选。
-
THULAC:https://github.com/thunlp/THULAC-Python哈工大推出的中文分词 / 词性标注工具,基于 CRF + 深度学习,轻量高效、准确率高,支持自定义训练,适合中文基础序列标注落地。
-
jieba+CRF:https://github.com/fxsjy/jieba + https://github.com/scikit-learn-contrib/crfsuite工业界轻量中文分词组合,jieba 做基础分词,CRF 做优化,速度快、易部署,适合低资源中文分词场景。
六、序列标注经典基准数据集(中英文,附地址)
英文数据集
-
CoNLL-2003(NER):https://www.clips.uantwerpen.be/conll2003/ner/
-
Penn Treebank(POS):https://catalog.ldc.upenn.edu/LDC99T42
-
ACE2005(嵌套 NER / 事件抽取):https://catalog.ldc.upenn.edu/LDC2006T06
中文数据集
-
ONTONOTE 4.0(NER / 分词 / POS):https://github.com/zhanzecheng/Chinese-NER-Dataset
-
PKU/CTB(中文分词):https://github.com/rockyzhengwu/Chinese-Word-Segmentation-Datasets
2.4 文本生成




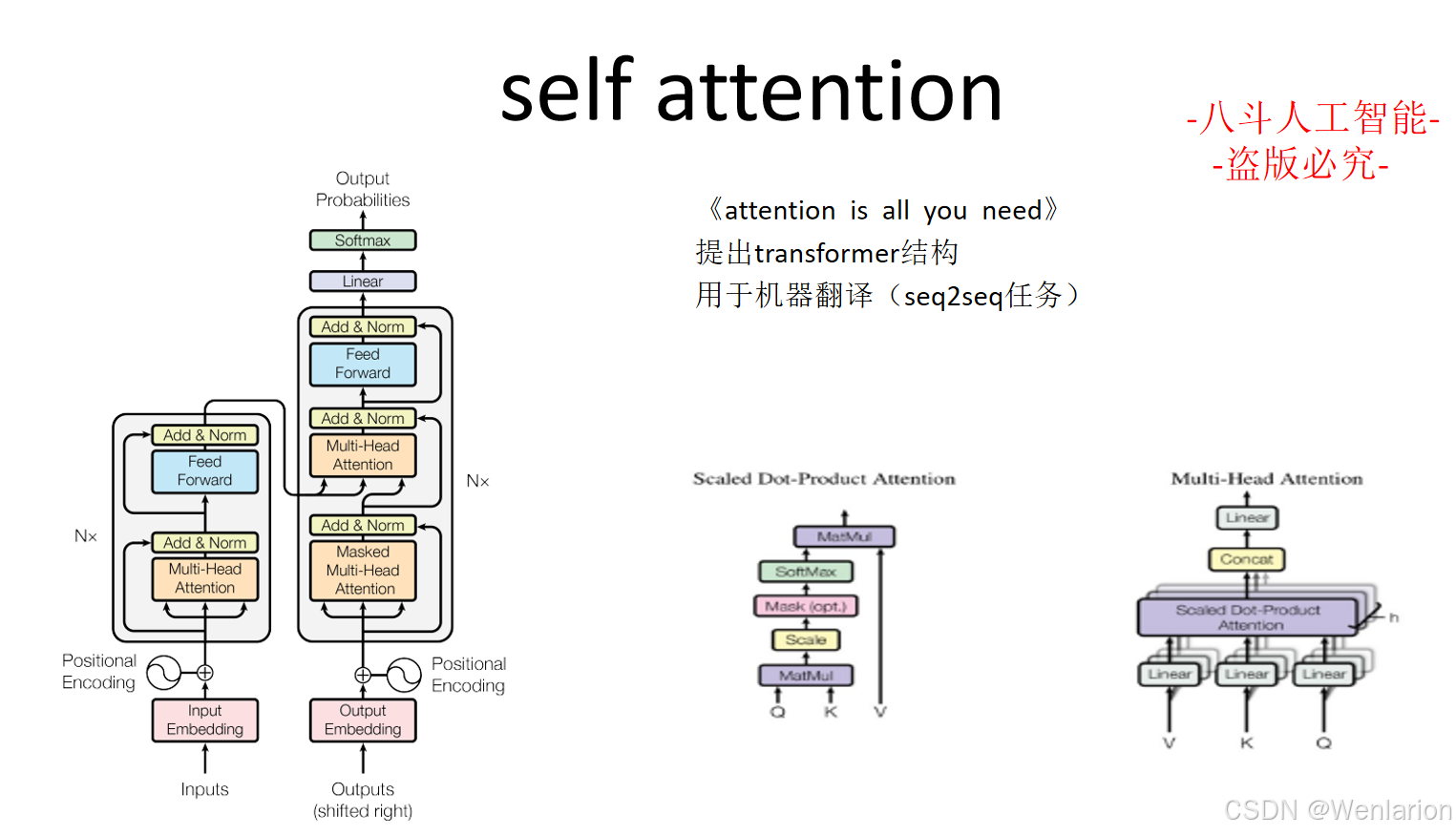
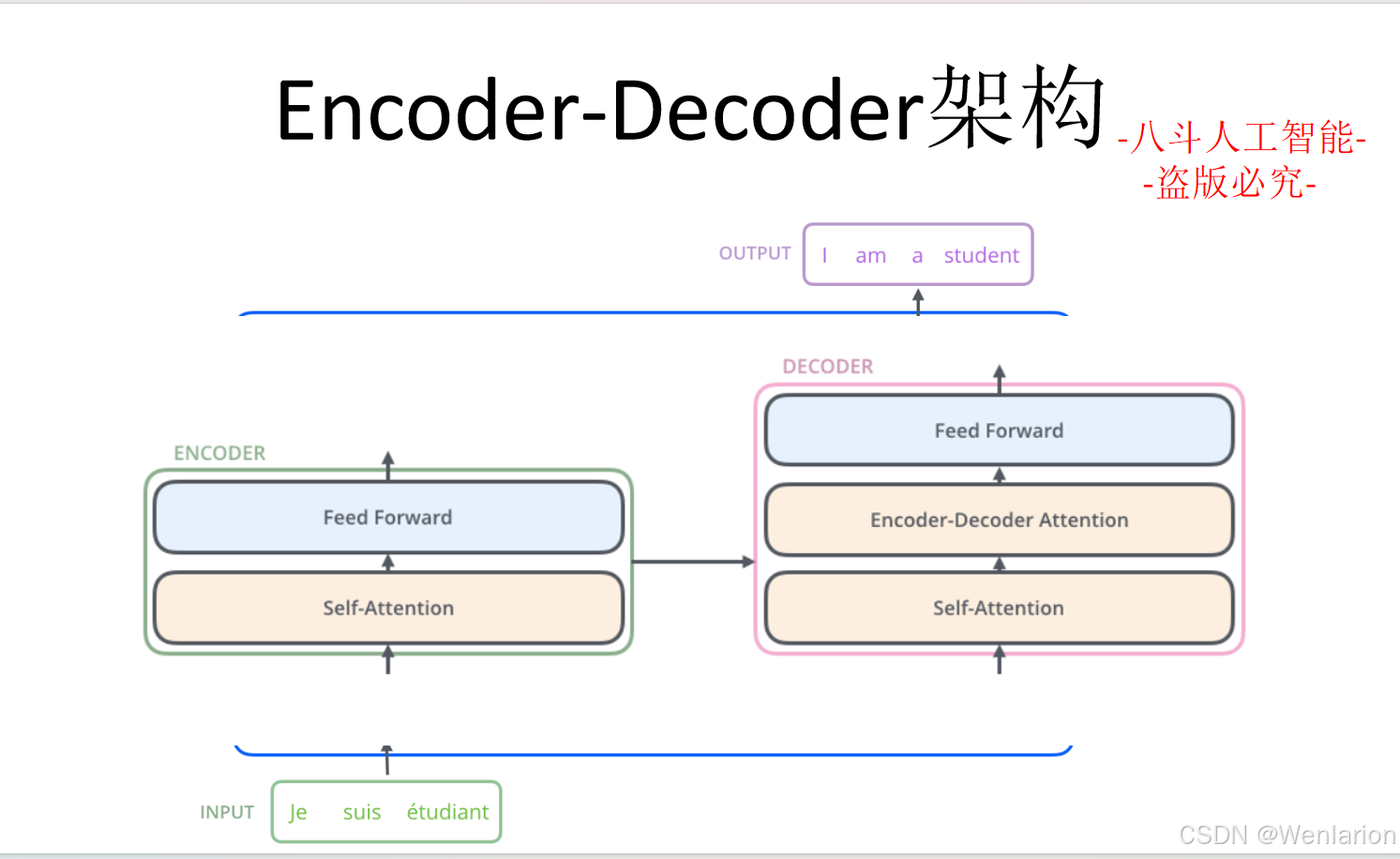
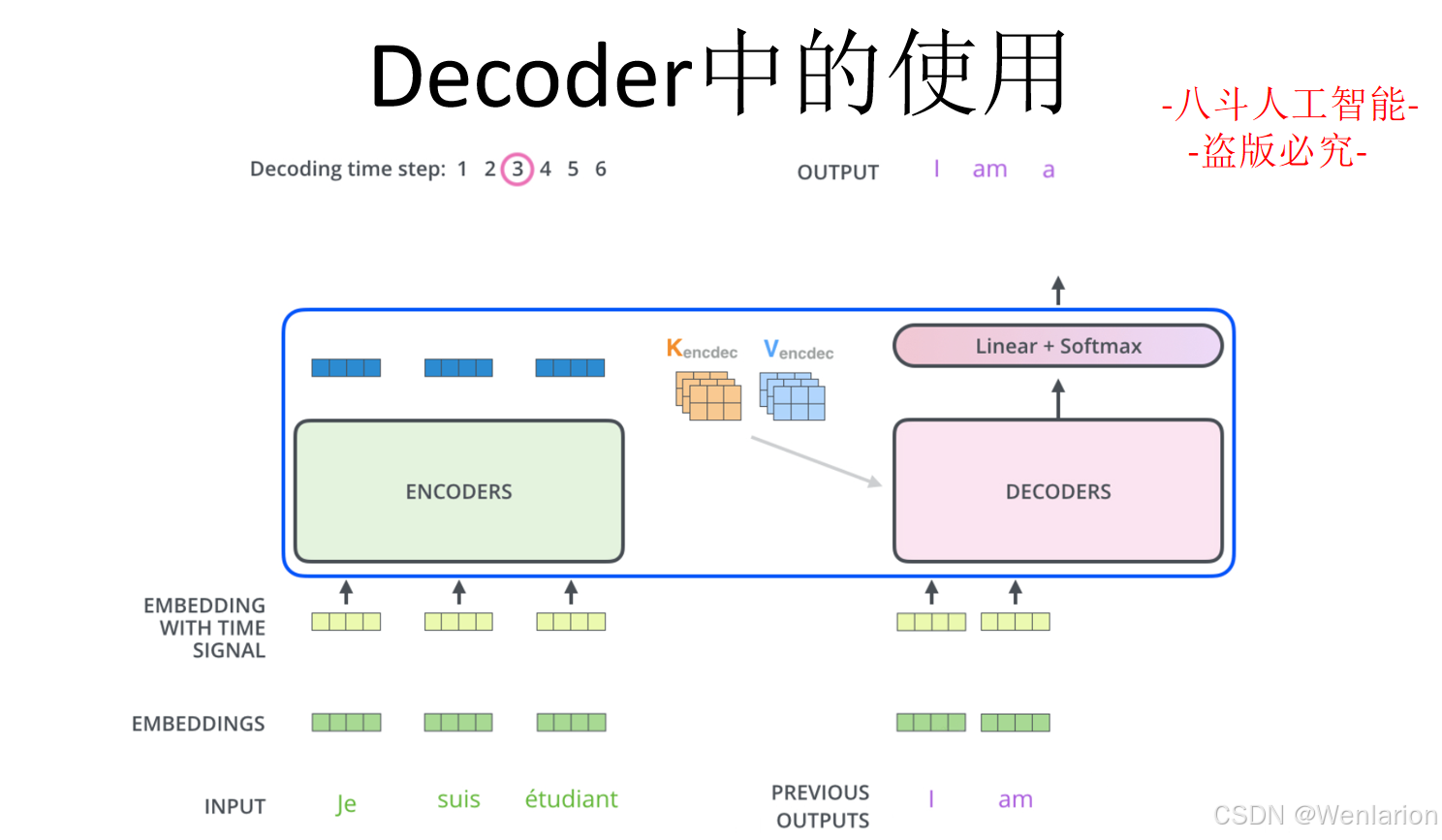
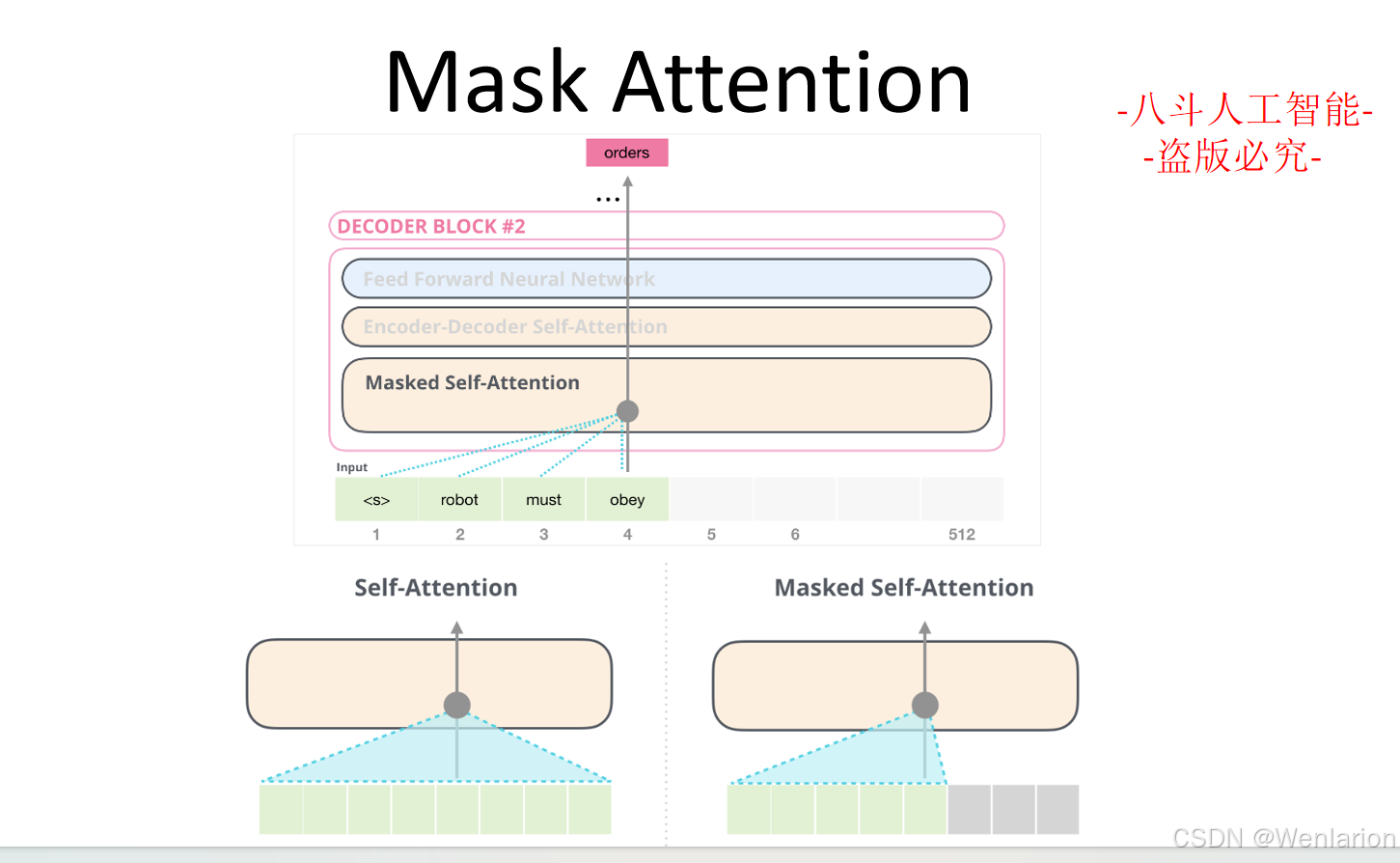





文本生成相关论文和代码
一、经典序列生成模型(2014-2018,序列生成基础)
该类是文本生成的开山基线,奠定自回归生成、注意力机制、编码器 - 解码器(Encoder-Decoder)核心框架,是后续所有生成模型的基础。
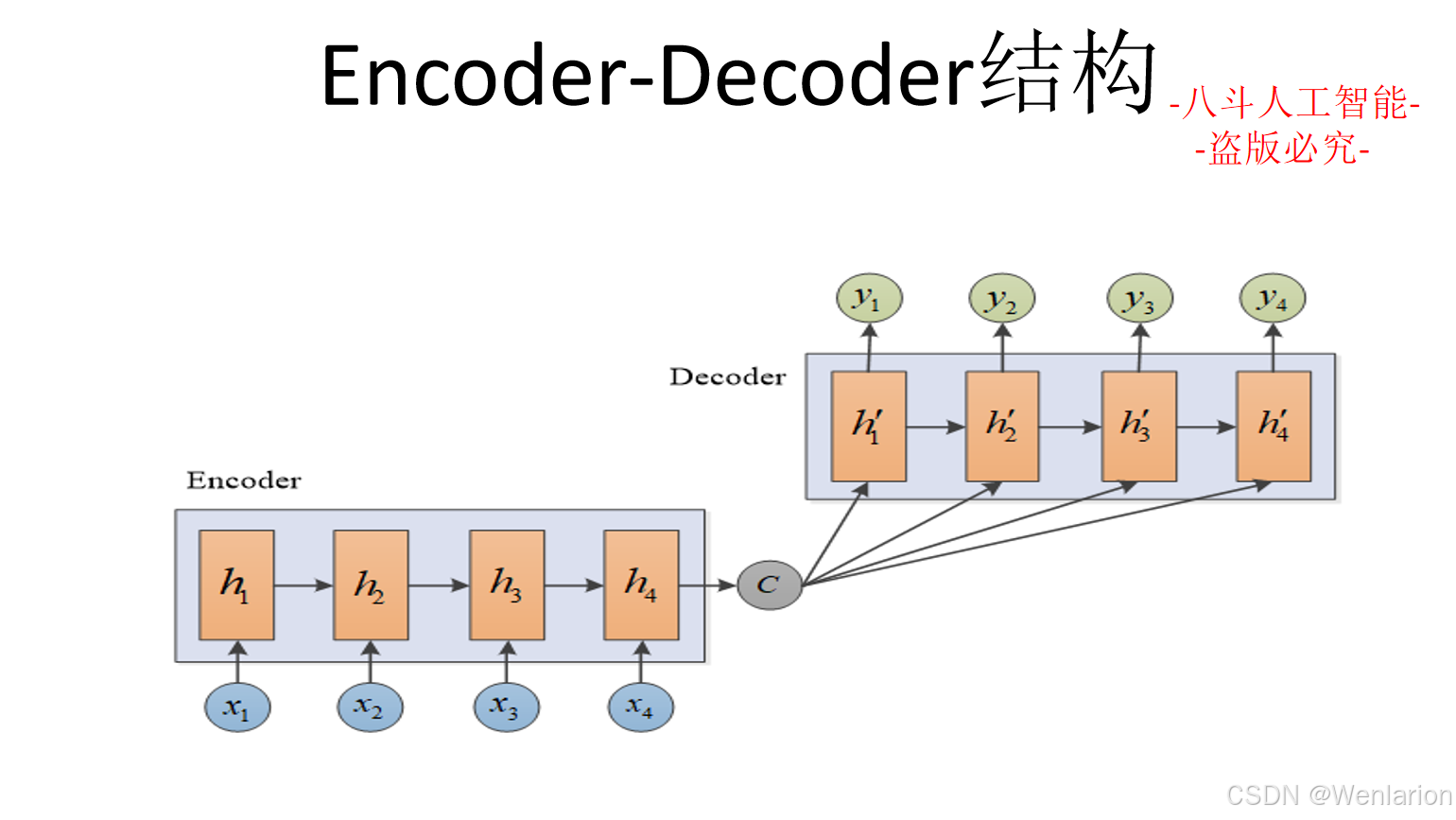
1. Seq2Seq:Sequence to Sequence Learning with Neural Networks(NeurIPS 2014)
-
简介:序列生成奠基之作,提出 Encoder-Decoder 框架(双 RNN 结构),将任意长度输入序列映射为固定长度向量,再解码为目标序列,首次实现端到端的序列生成,适配机器翻译、摘要等所有 seq2seq 任务。
-
代码地址:https://github.com/karpathy/char-rnn(经典实现);https://github.com/tensorflow/nmt(TensorFlow 官方 Seq2Seq)
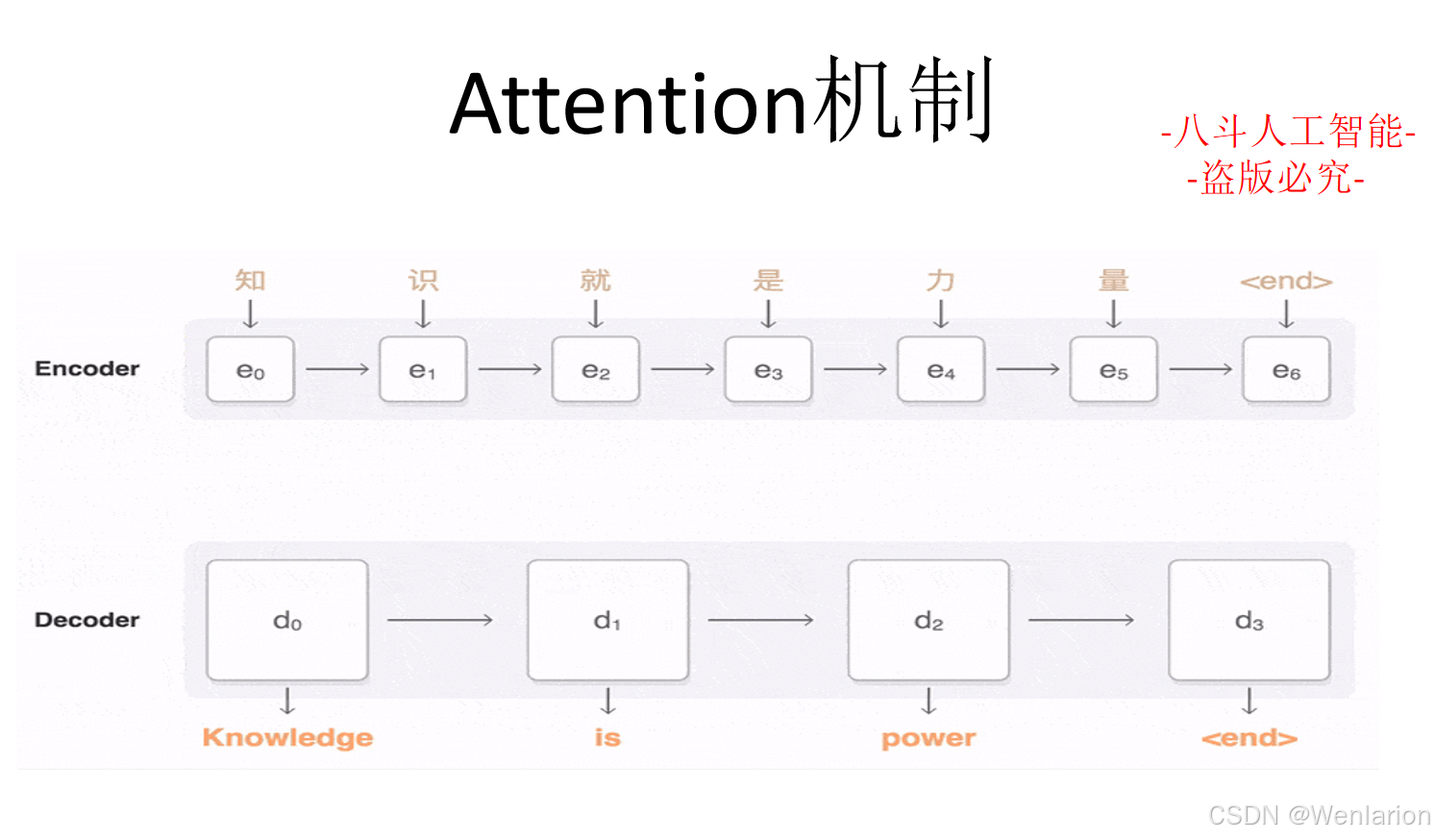
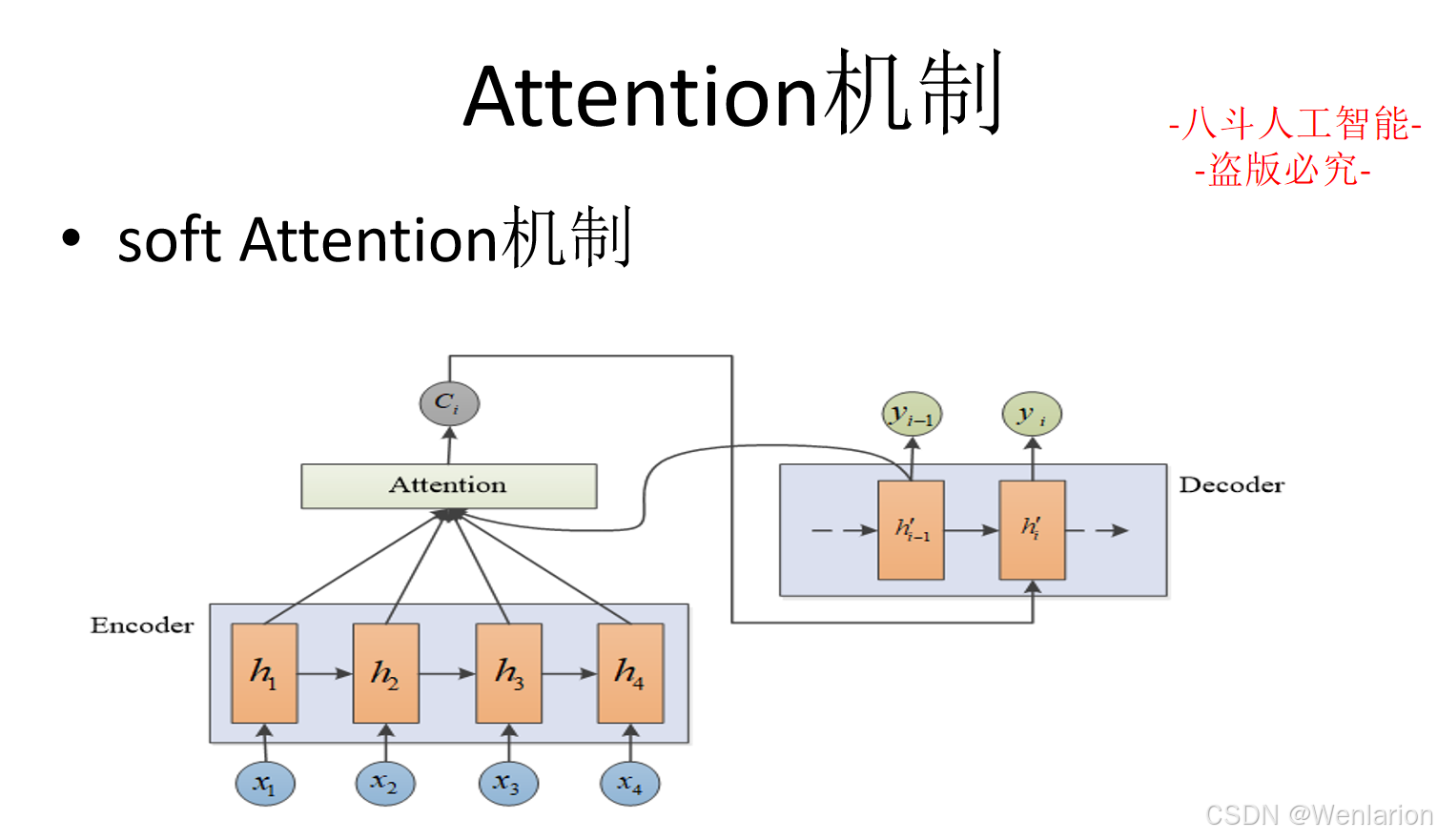
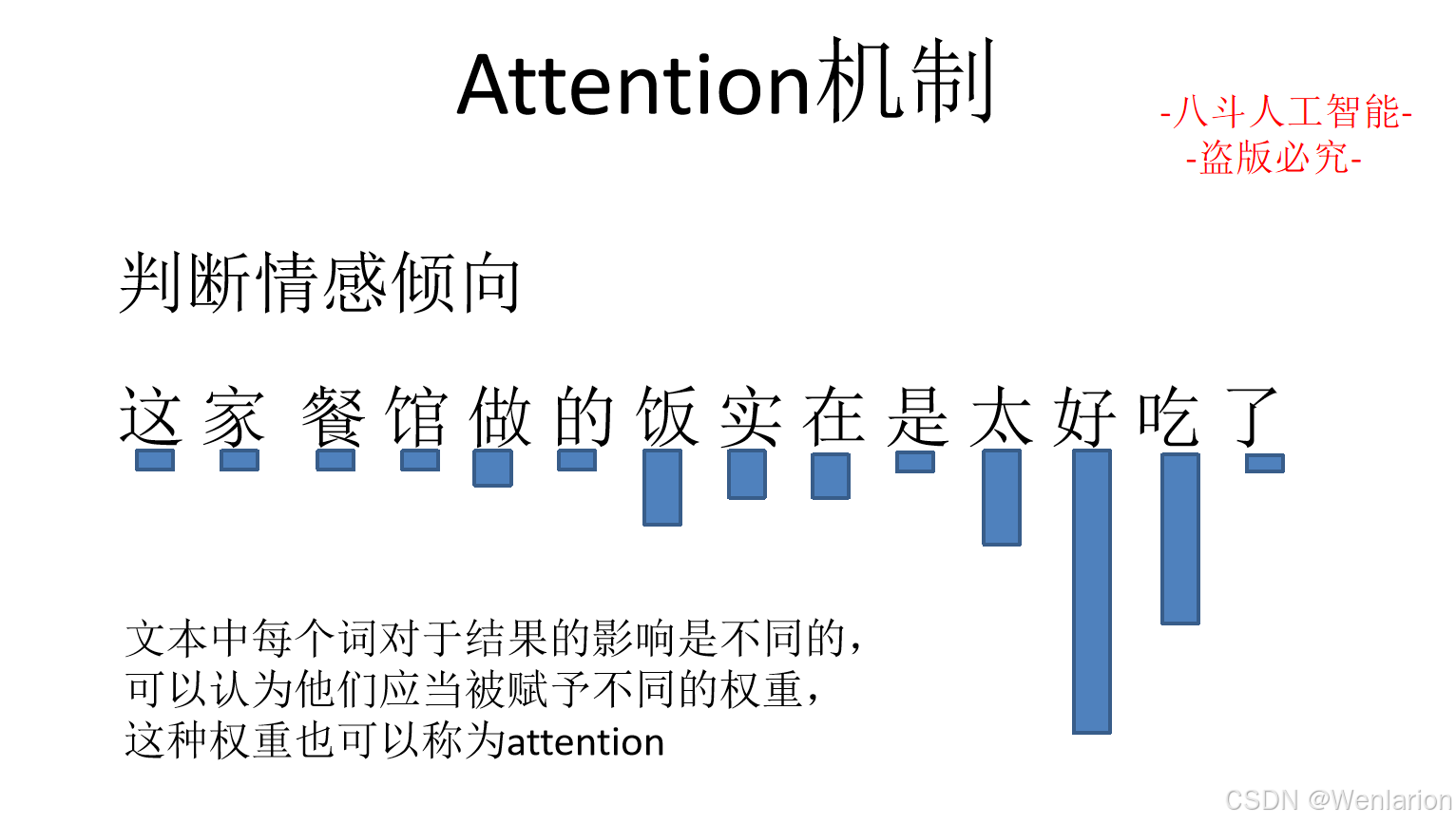
2. Attention Is All You Need(NeurIPS 2017)
-
简介:Transformer原论文,提出纯注意力机制的 Transformer 架构,替代 RNN 解决长序列建模的梯度消失问题,并行计算效率远超 RNN,成为所有现代文本生成模型的核心基础(BERT/GPT/T5 均基于此)。
-
代码地址:https://github.com/tensorflow/models/tree/master/official/nlp/transformer(官方);https://github.com/huggingface/transformers(经典复现)
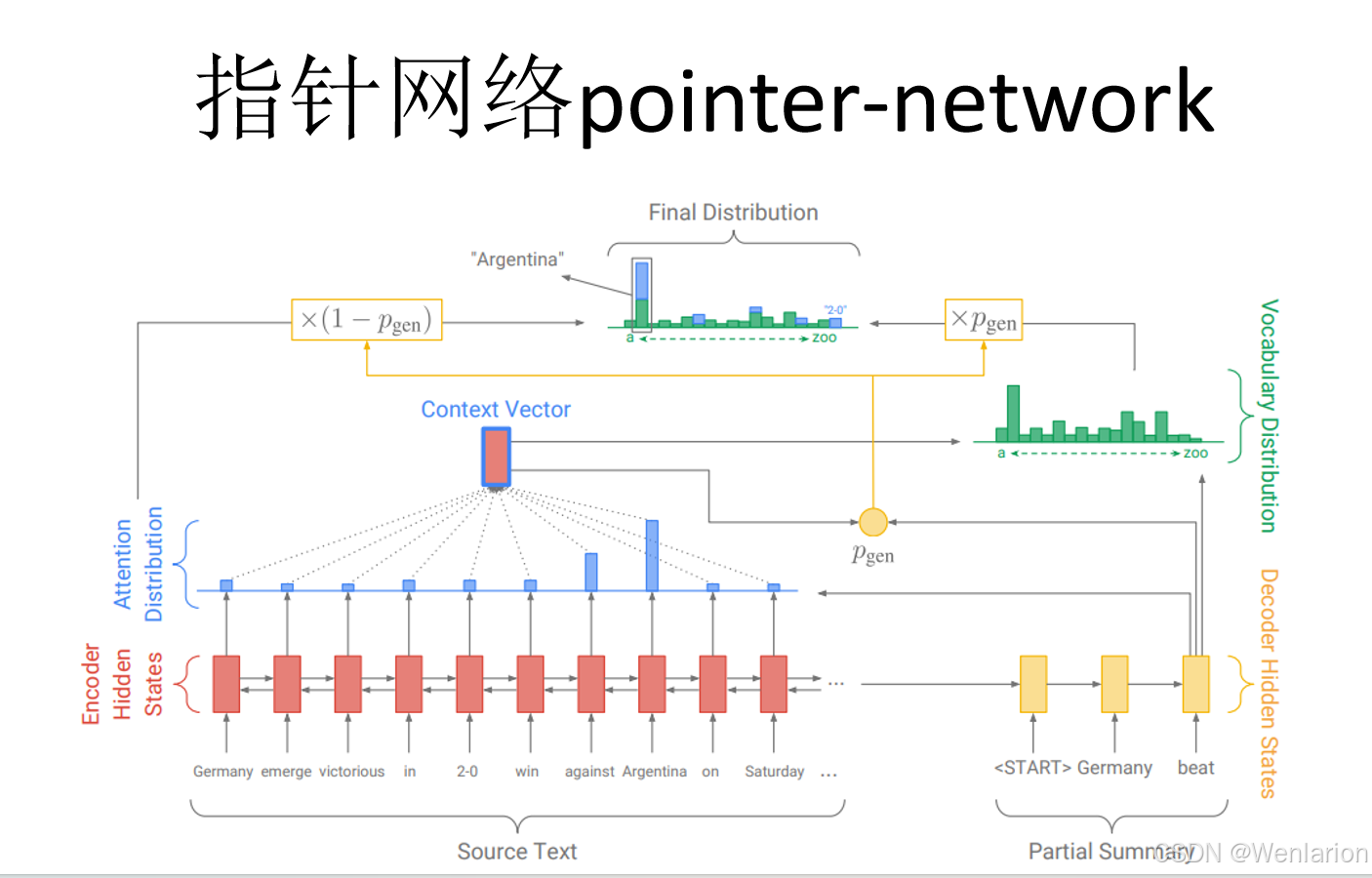
3. Pointer-Generator Network(ACL 2017)
-
简介:针对文本摘要生成的经典改进,在 Seq2Seq 基础上加入指针网络(Pointer Network),解决生成过程中的OOV(未登录词)和重复生成问题,可从原文中复制关键词汇,成为抽取式 + 生成式混合摘要的基线模型。
-
代码地址:https://github.com/abisee/pointer-generator(官方,TensorFlow);https://github.com/huggingface/transformers(内置适配)
4. Non-Autoregressive Transformer(ICLR 2019)
-
简介:非自回归生成(NAT)开山作,打破自回归生成 “逐词生成、串行计算” 的限制,实现目标序列并行生成,推理速度提升 10-100 倍,适用于工业界低延迟生成场景(如机器翻译、实时对话),后续 NAT 模型均基于此改进。
-
代码地址:https://github.com/facebookresearch/nonautoregressive-ntm(官方);https://github.com/hyunwoongko/nonautoregressive-transformer(PyTorch 轻量实现)
5. GPT-1:Improving Language Understanding by Generative Pre-Training(2018,非顶会但经典)
-
简介:GPT 系列首作,提出Decoder-only Transformer预训练范式,通过无监督自回归语言建模预训练,再对下游生成任务微调,首次验证 Decoder-only 架构在生成任务的优势,为 GPT-2/3/4 奠定基础。
-
代码地址:https://github.com/openai/finetune-transformer-lm(官方);https://github.com/huggingface/transformers(复现)
二、经典预训练生成模型(2019-2021,主流工业落地基线)
基于 Transformer 的预训练 + 微调范式,是文本生成的标配基线,兼顾精度与落地性,其中 Decoder-only(GPT 系列)适配开放式生成(对话、文生文),Encoder-Decoder(T5/BART)适配有监督生成(摘要、翻译、改写)。
1. GPT-2:Language Models are Unsupervised Multitask Learners(2019,OpenAI)
-
简介:GPT-1 的升级版本,扩大模型参数量与训练数据,提出零样本 / 少样本生成能力,移除下游任务特定设计,实现通用文本生成,可直接完成对话、摘要、翻译、续写等任务,是开放式生成的经典基线。
-
代码地址:https://github.com/openai/gpt-2(官方);https://github.com/huggingface/transformers(一键调用)
2. BART:Denoising Sequence-to-Sequence Pre-training for Natural Language Generation(ACL 2020)
-
简介:Facebook 提出的Encoder-Decoder 预训练模型,基于 Transformer,通过去噪自编码预训练(对输入做打乱 / 删除 / 替换等噪声处理,再还原),适配所有有监督文本生成任务(摘要、翻译、改写、文本纠错),性能全面超越 T5 在部分任务,是目前有监督生成的强基线。
-
代码地址:https://github.com/facebookresearch/fairseq(官方,Fairseq 框架);https://github.com/huggingface/transformers(适配调用)
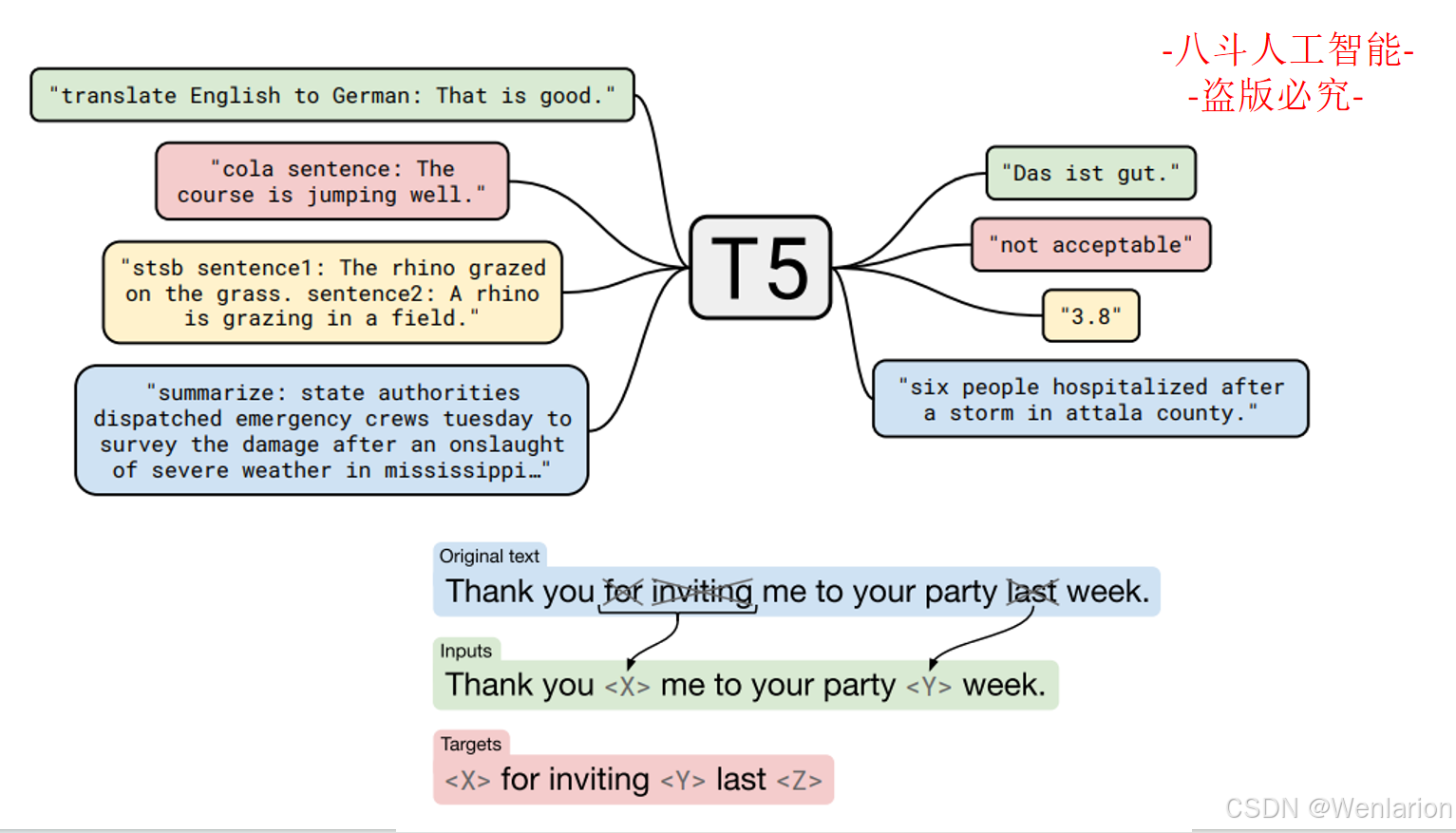
3. T5:Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer(JMLR 2020)
-
简介:Google 提出的统一文本到文本预训练模型,将所有 NLP 任务(分类 / 生成 / 翻译)统一为文本生成任务,采用 Encoder-Decoder 架构,基于 **Colossal Clean Crawled Corpus(C4)** 训练,参数量从基础版到 11B 全覆盖,是多任务生成的经典模型。
-
代码地址:https://github.com/google-research/text-to-text-transfer-transformer(官方);https://github.com/huggingface/transformers(轻量化调用)
4. GPT-3:Language Models are Few-Shot Learners(NeurIPS 2020)
-
简介:大模型里程碑之作,将 Decoder-only Transformer 参数量扩大至175B,通过海量文本预训练,实现 ** 超强的少样本 / 零样本 / 一次性(One-shot)** 生成能力,无需下游任务微调,仅通过自然语言提示(Prompt)即可完成各类文本生成任务,开启大模型时代。
-
代码地址:无官方开源代码;https://github.com/huggingface/transformers(小参数量版本复现);https://github.com/EleutherAI/gpt-neo(开源替代)
5. UniLM v2:Unified Language Model Pre-training for Natural Language Understanding and Generation(NeurIPS 2020)
-
简介:微软提出的中文适配性极强的预训练模型,支持单向 / 双向 / 序列到序列三种注意力机制,统一理解与生成任务,在中文文本生成(摘要、对话、改写)上性能优于 BART/T5,是中文有监督生成的主流基线。
-
代码地址:https://github.com/microsoft/unilm(官方);https://github.com/huggingface/transformers(中文适配)
6. CPM-1:A Large-Scale Chinese Pre-trained Language Model(2020,清华 / 智源)
-
简介:国内首个大尺度中文预训练生成模型,Decoder-only 架构,针对中文语料优化,参数量 2.6B,适配中文开放式生成(对话、文生文、续写),为后续中文大模型(CPM-2/3、ChatGLM)奠定基础。
三、大模型与对齐优化(2022 至今,大模型生成核心,含 RLHF / 对齐 / 高效微调)
该类是 ** 现代大语言模型(LLM)** 文本生成的核心,解决预训练大模型 “生成内容无意义、不贴合人类意图、有毒性” 等问题,同时提出大模型高效微调方法,适配工业落地,是当前研究热点。
1. InstructGPT:Training Language Models to Follow Instructions with Human Feedback(NeurIPS 2022)
-
简介:RLHF(基于人类反馈的强化学习) 核心论文,OpenAI 提出通过 “人类标注指令微调→训练奖励模型(RM)→强化学习微调(PPO)” 三步,让大模型生成贴合人类指令、符合人类偏好的内容,解决 GPT-3 生成内容与人类意图脱节的问题,是 ChatGPT 的核心技术基础。
-
代码地址:无官方开源;https://github.com/lvwerra/trl(HuggingFace TRL,主流 RLHF 实现);https://github.com/CarperAI/trlx(工业级 RLHF)
2. ChatGLM-6B:An Efficient Billion-Scale Chinese Chat Model(2022,清华 / 智谱 AI)
-
简介:国内首个开源可商用的中文对话大模型,基于 GLM 架构(Decoder-only 改进),针对中文优化,参数量 6B,支持低资源设备部署(单卡 GPU 即可运行),是中文对话生成、开放式文生文的工业落地首选基线,后续升级为 ChatGLM2-6B/ChatGLM3。
-
代码地址:https://github.com/THUDM/ChatGLM-6B(官方);https://github.com/THUDM/ChatGLM3(最新版)
3. LoRA:Low-Rank Adaptation of Large Language Models(ICLR 2022)
-
简介:大模型高效微调经典方法,通过在 Transformer 的注意力层加入低秩矩阵,仅训练少量参数(约原模型的 0.1%),即可实现与全量微调相当的生成性能,大幅降低显存与计算成本,是工业界大模型定制化生成的标配方法,适配所有 Transformer 类生成模型。
-
代码地址:https://github.com/microsoft/LoRA(官方);https://github.com/huggingface/peft(HuggingFace PEFT,内置 LoRA/QLoRA)
4. QLoRA:Efficient Finetuning of Quantized LLMs(NeurIPS 2023)
-
简介:LoRA 的升级版本,将大模型量化为 4 位 / 8 位后再加入 LoRA 低秩微调,进一步降低显存占用(65B 模型可在单张 24G GPU 上微调),同时通过量化感知训练保证生成性能,是大模型低资源微调的 SOTA 方法。
-
代码地址:https://github.com/artidoro/qlora(官方);https://github.com/huggingface/peft(内置实现)
5. Llama 2:Open and Efficient Foundation Language Models(NeurIPS 2023)
-
简介:Meta 推出的开源大模型,Decoder-only 架构,参数量 7B/13B/70B,基于 RLHF 对齐优化,适配英文开放式生成(对话、文生文、代码生成),是目前英文开源大模型的主流基线,支持商用,后续有 Llama 3(更优性能)。
-
代码地址:https://github.com/meta-llama/llama(官方);https://github.com/huggingface/transformers(适配调用)
6. BLIP-2:Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models(ICML 2023)
-
简介:图文生成经典模型,实现图像到文本的生成(看图说话、图文问答、图像摘要),通过冻结视觉编码器(如 CLIP)+ 轻量视觉 - 语言桥接层 + 冻结大语言模型(如 Flan-T5) 实现高效预训练,性能远超同期图文生成模型,是图文生成的 SOTA 基线。
-
代码地址:https://github.com/salesforce/BLIP-2(官方);https://github.com/huggingface/transformers(适配)
四、专项文本生成任务(经典 SOTA,覆盖细分方向)
针对文本生成的核心细分任务(摘要、对话、机器翻译、代码生成)梳理经典 SOTA 模型,适配特定场景的研究与落地。
(一)文本摘要生成
1. PEGASUS:Pre-training with Extracted Gap-sentences for Abstractive Summarization(ICML 2020)
-
简介:专为抽象式文本摘要设计的预训练模型,Encoder-Decoder 架构,预训练任务为抽取式间隙句预测,完美适配摘要生成的核心逻辑,在多个英文摘要数据集上刷新 SOTA,中文适配版性能同样优异。
-
代码地址:https://github.com/google-research/pegasus(官方);https://github.com/huggingface/transformers(适配)
2. ChatYuan:A Chinese Multitask Dialogue and Summary Model(2022,元语智能)
-
简介:中文摘要 + 对话双任务优化模型,针对中文长文本摘要(新闻、论文、文档)做专项优化,解决中文长文本摘要的 “信息遗漏、逻辑混乱” 问题,同时支持对话生成,是中文工业级摘要生成的主流选择。
-
代码地址:https://github.com/clue-ai/ChatYuan(官方)
(二)对话生成
1. DialoGPT:Large-Scale Generative Pre-training for Conversational Response Generation(ACL 2020)
-
简介:微软提出的开放域对话生成经典模型,基于 GPT-2 改进,针对对话语料预训练,实现多轮对话生成,解决传统对话模型的 “回复单一、无意义” 问题,是开放域对话的经典基线。
-
代码地址:https://github.com/microsoft/DialoGPT(官方);https://github.com/huggingface/transformers(调用)
2. BlenderBot 3:A 175B Parameter Dialog Model with Long-Term Memory and Internet Access(ACL 2022)
-
简介:Meta 推出的智能对话模型,支持长期记忆 + 互联网检索,解决对话生成的 “上下文遗忘、信息过时” 问题,可生成贴合上下文、符合实时信息的回复,是智能对话生成的 SOTA。
-
代码地址:https://github.com/facebookresearch/ParlAI(官方,ParlAI 框架)
(三)机器翻译
1. Transformer-XL:Attentive Language Models Beyond a Fixed-Length Context(ACL 2019)
-
简介:Transformer 的改进版,提出循环段注意力,解决传统 Transformer 的固定上下文长度限制,可建模超长序列(如长文档翻译),在机器翻译、语言建模上性能远超原版 Transformer。
-
代码地址:https://github.com/kimiyoung/transformer-xl(官方);https://github.com/huggingface/transformers(适配)
2. mT5:A Massively Multilingual Pre-trained Text-to-Text Transformer(ACL 2021)
-
简介:T5 的多语言版本,支持100 + 种语言的机器翻译,同时适配多语言摘要、改写,是目前多语言机器翻译的经典基线,中文 - 英文翻译性能优异。
-
代码地址:https://github.com/google-research/multilingual-t5(官方);https://github.com/huggingface/transformers(调用)
(四)代码生成
1. CodeGPT:Code Generation by Pre-training on Multiple Programming Languages(NeurIPS 2020)
-
简介:首个多语言代码生成预训练模型,基于 GPT-2 改进,针对 Python/Java/C++ 等多种编程语言预训练,实现自然语言到代码的生成,是代码生成的经典基线。
-
代码地址:https://github.com/ microsoft/CodeGPT(官方);https://github.com/huggingface/transformers(适配)
2. CodeLlama:Open Foundation Models for Code(2023,Meta)
-
简介:Llama 2 的代码生成专用版本,支持自然语言到代码、代码补全、代码翻译,适配 Python/Java/C++ 等 20 + 种编程语言,是目前开源代码生成的 SOTA 模型,支持商用。
-
代码地址:https://github.com/meta-llama/codellama(官方);https://github.com/huggingface/transformers(调用)
五、文本生成一站式工具包 / 框架(快速复现 / 工业落地)
-
Hugging Face Transformers:https://github.com/huggingface/transformers最主流的 NLP 框架,内置所有经典 / 最新文本生成模型(GPT/BART/T5/ChatGLM/Llama),提供统一 API,支持一键加载预训练模型、微调、推理,适配 PyTorch/TensorFlow/JAX。
-
Fairseq:https://github.com/facebookresearch/fairseqMeta 推出的序列建模框架,专为序列生成设计,内置 Transformer/BART/ 非自回归模型,适配机器翻译、摘要、语言建模,工业界落地常用。
-
PEFT:https://github.com/huggingface/peftHugging Face 推出的大模型高效微调框架,内置 LoRA/QLoRA/IA3 等所有主流高效微调方法,可与 Transformers 无缝结合,大幅降低大模型微调成本。
-
TRL:https://github.com/lvwerra/trl大模型对齐学习框架,内置 RLHF/PPO/DPO 等对齐方法,适配 GPT/Llama/ChatGLM 等所有 Decoder-only 模型,快速实现大模型人类偏好对齐。
-
PaddleNLP:https://github.com/PaddlePaddle/PaddleNLP百度推出的中文 NLP 专属框架,内置 ChatGLM/ERNIE/UniLM 等中文优化的生成模型,附带中文语料与下游任务脚本,中文文本生成落地首选。
3、对话系统
3.1 对话系统
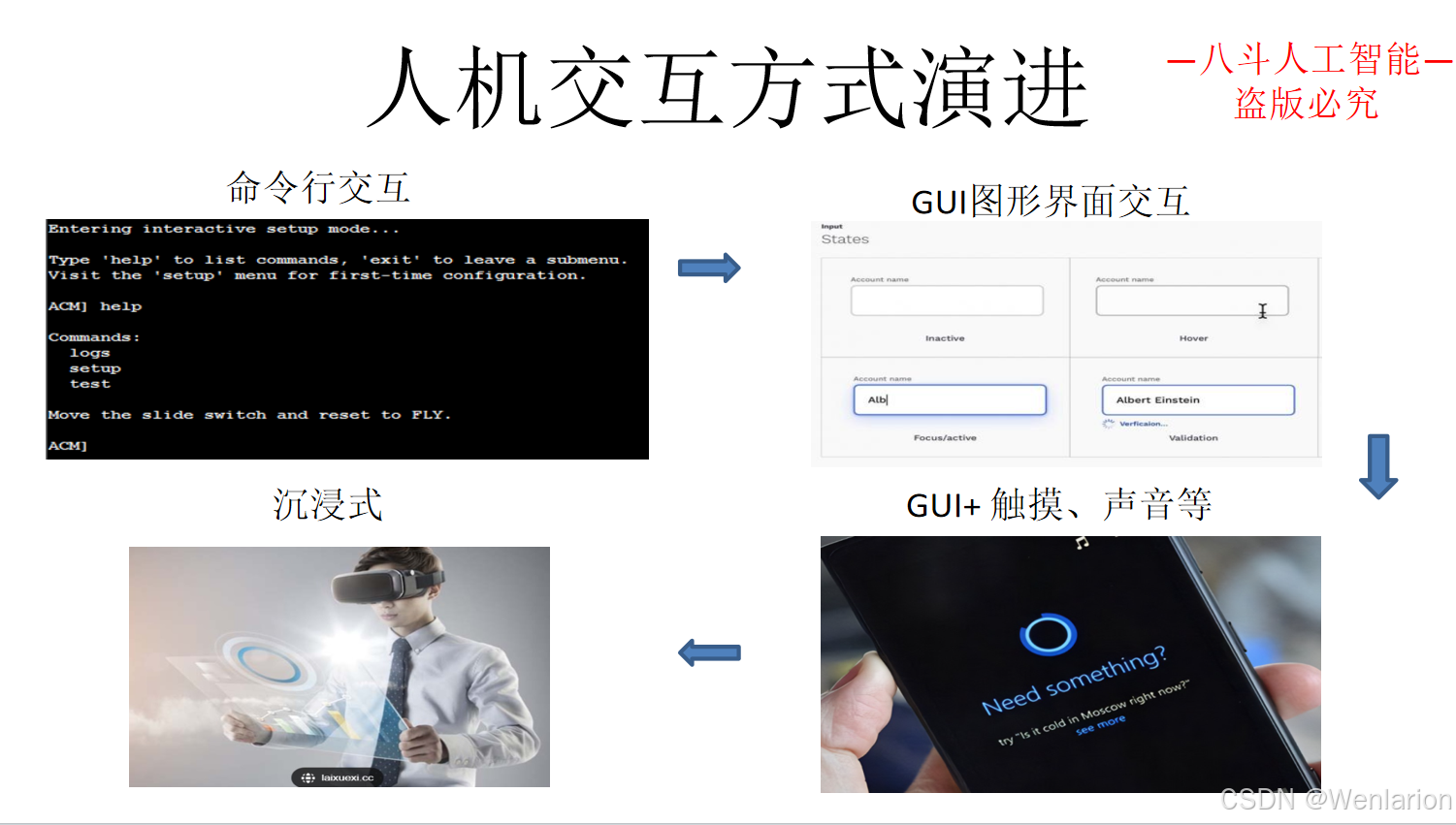

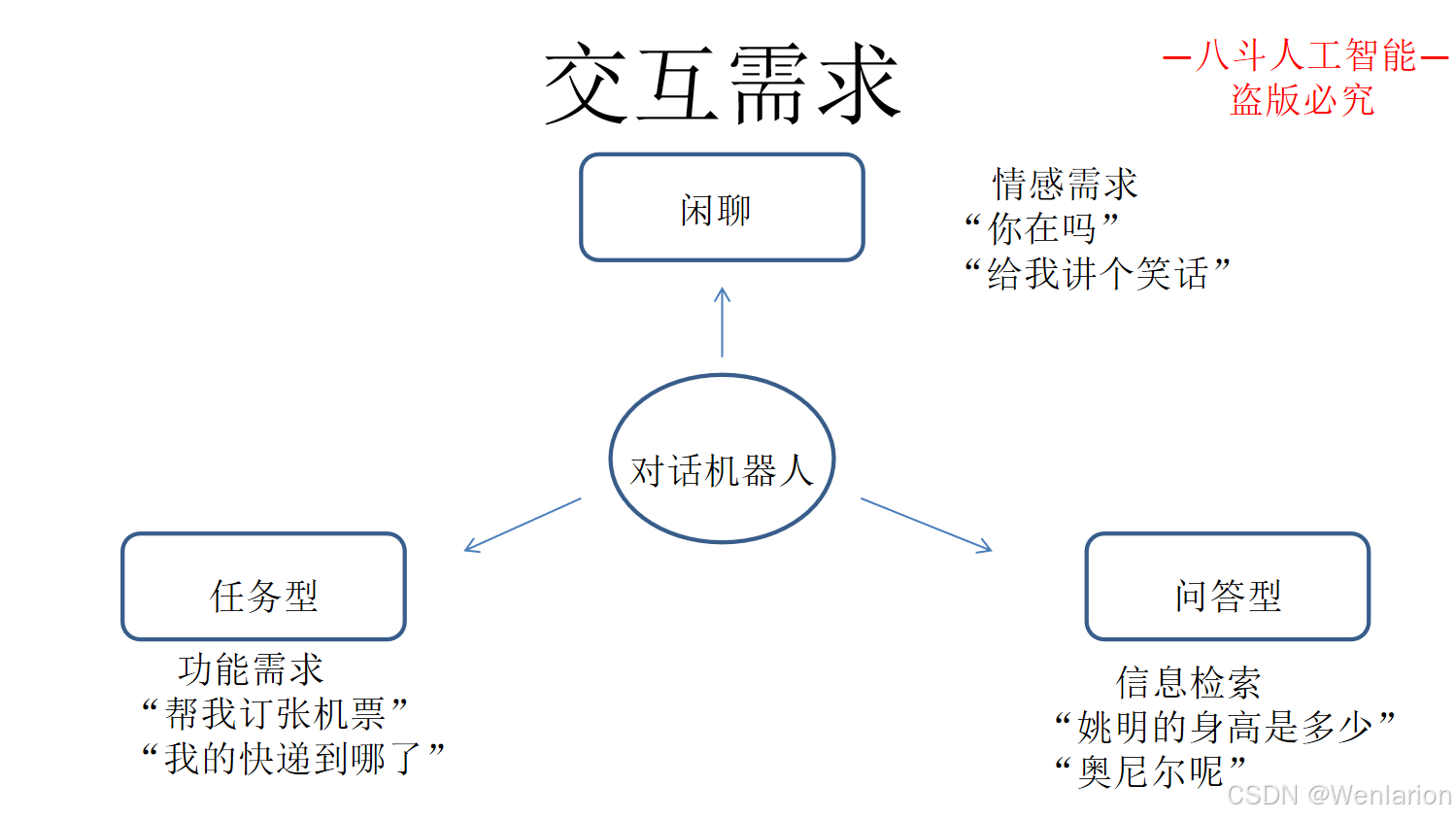
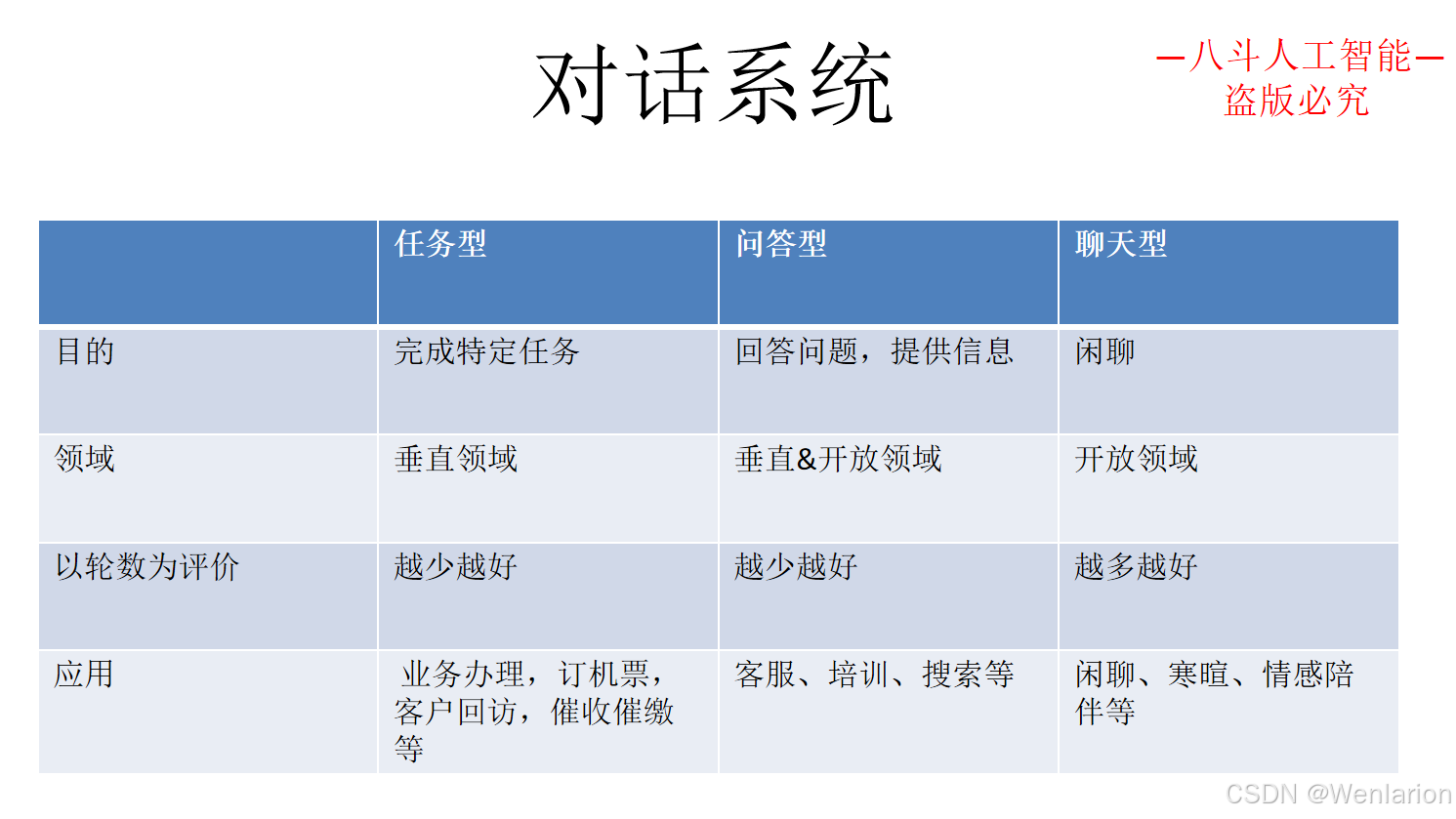
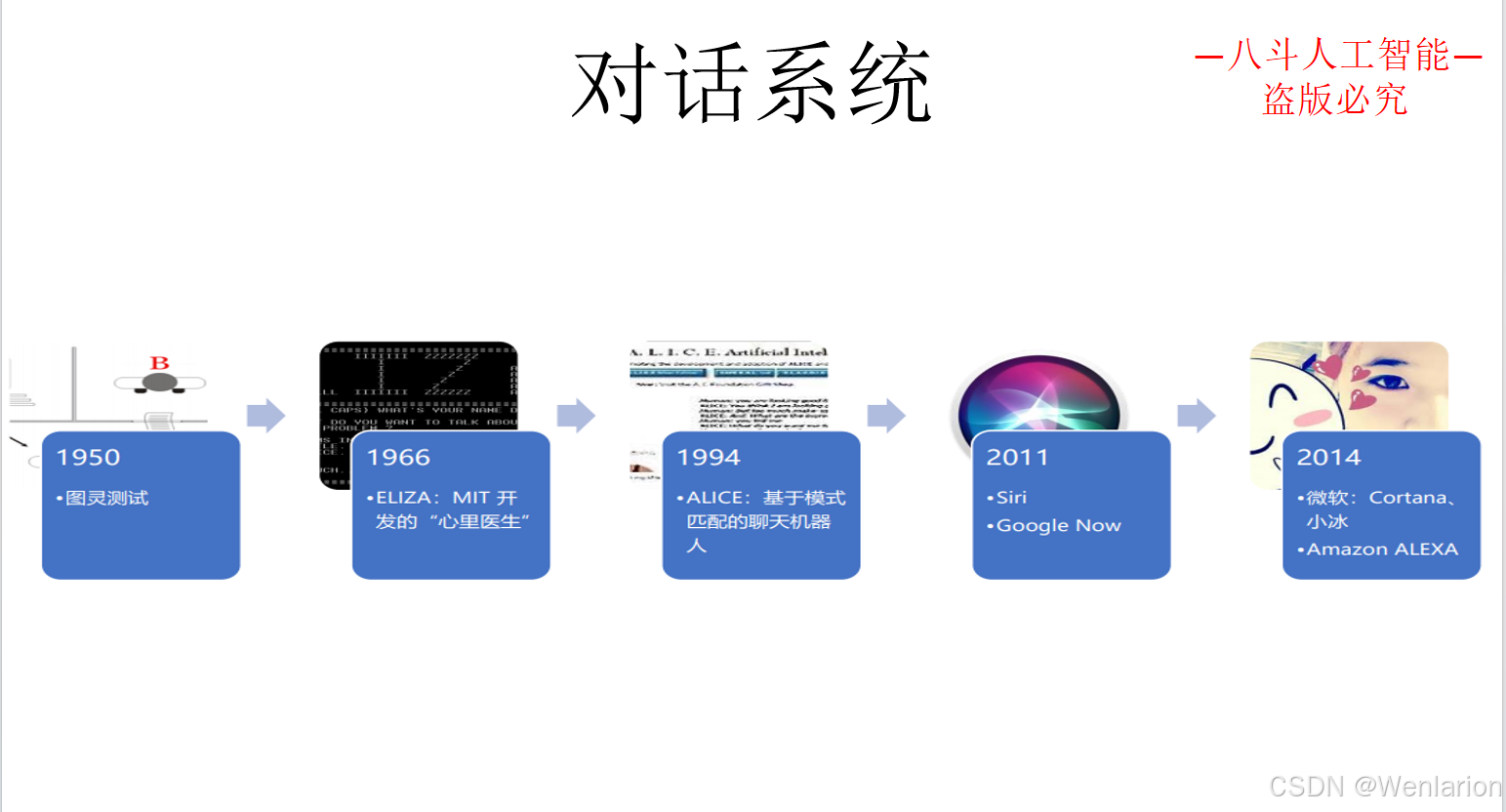
3.2 任务型对话
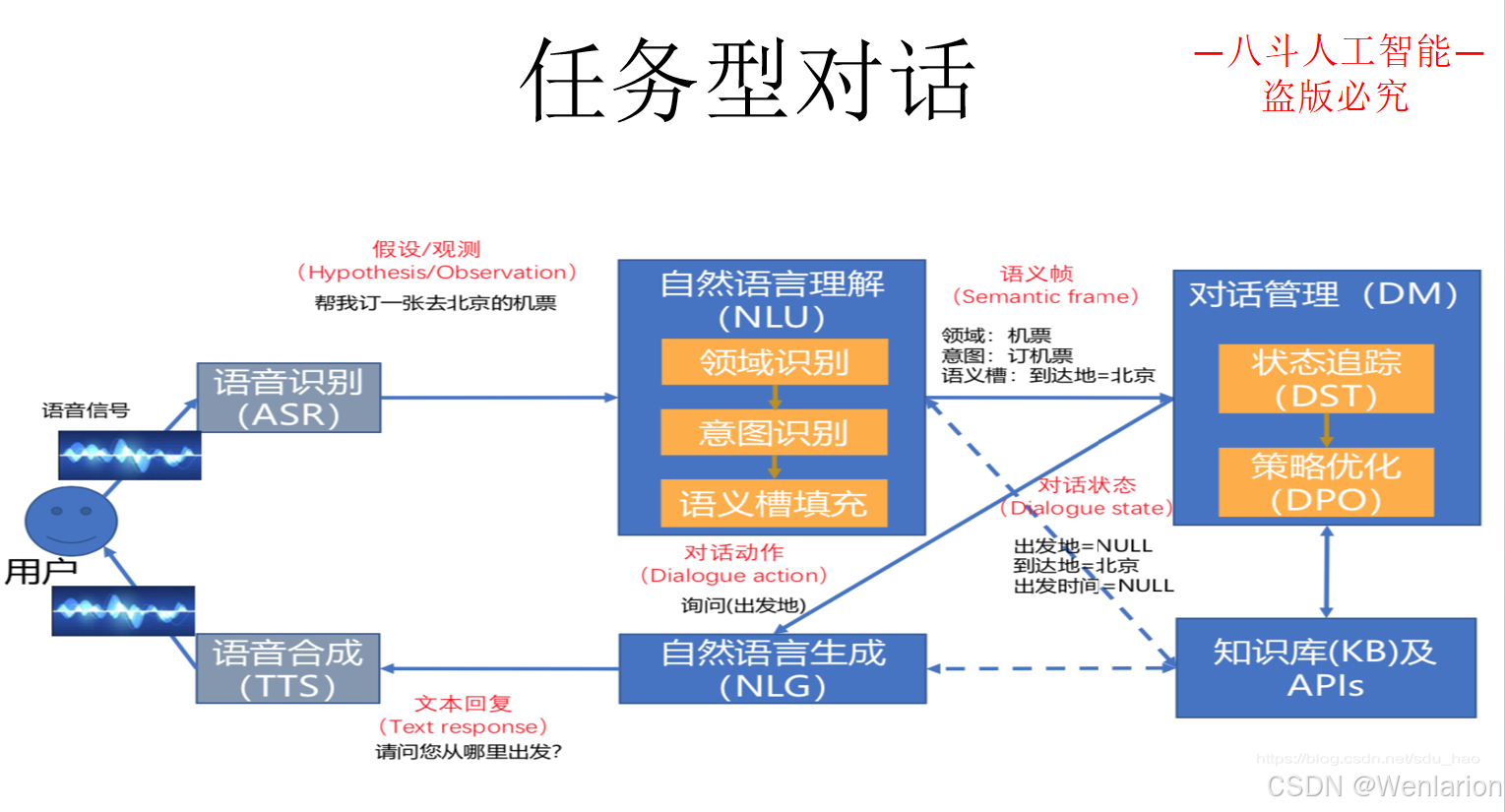

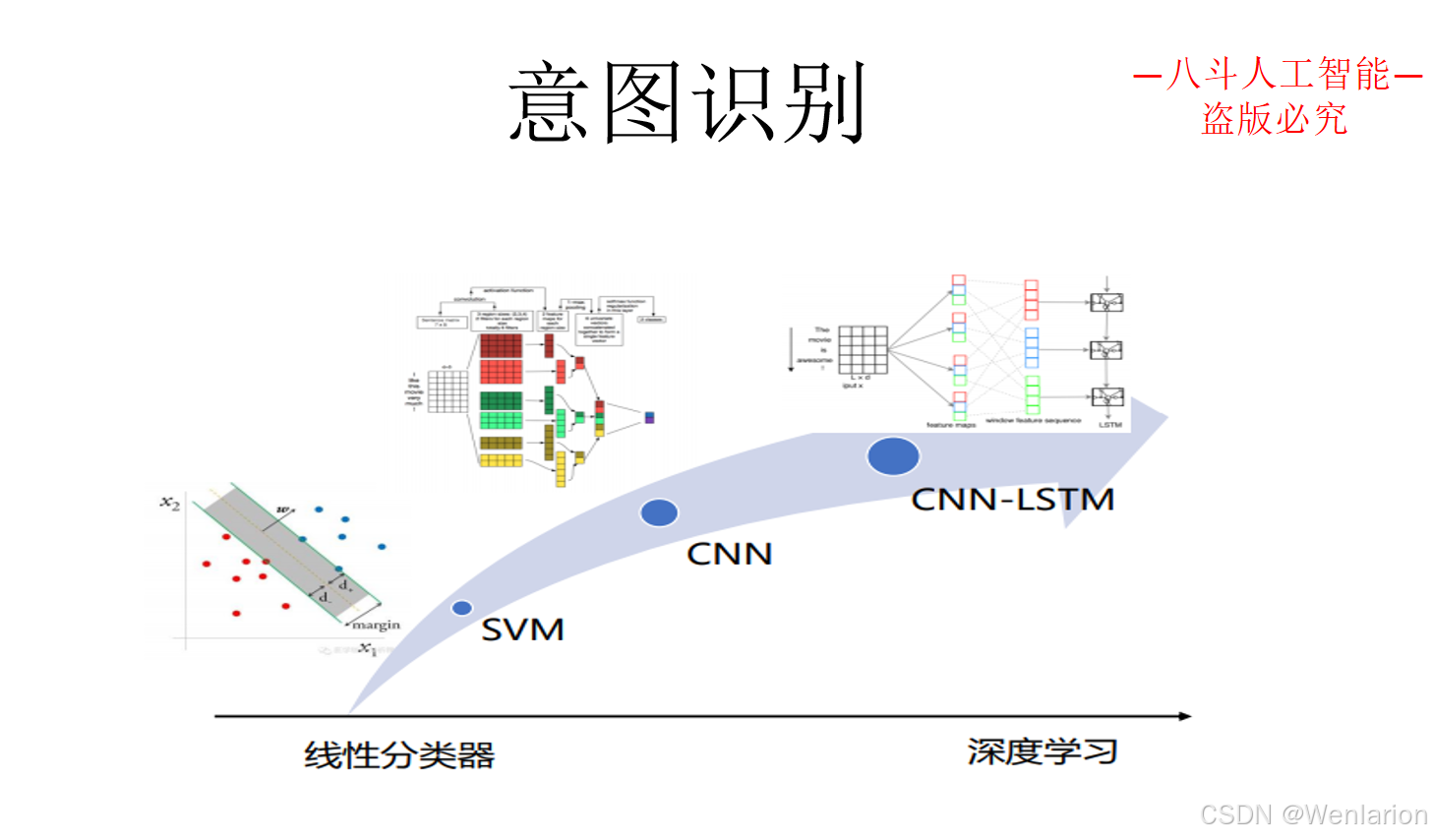
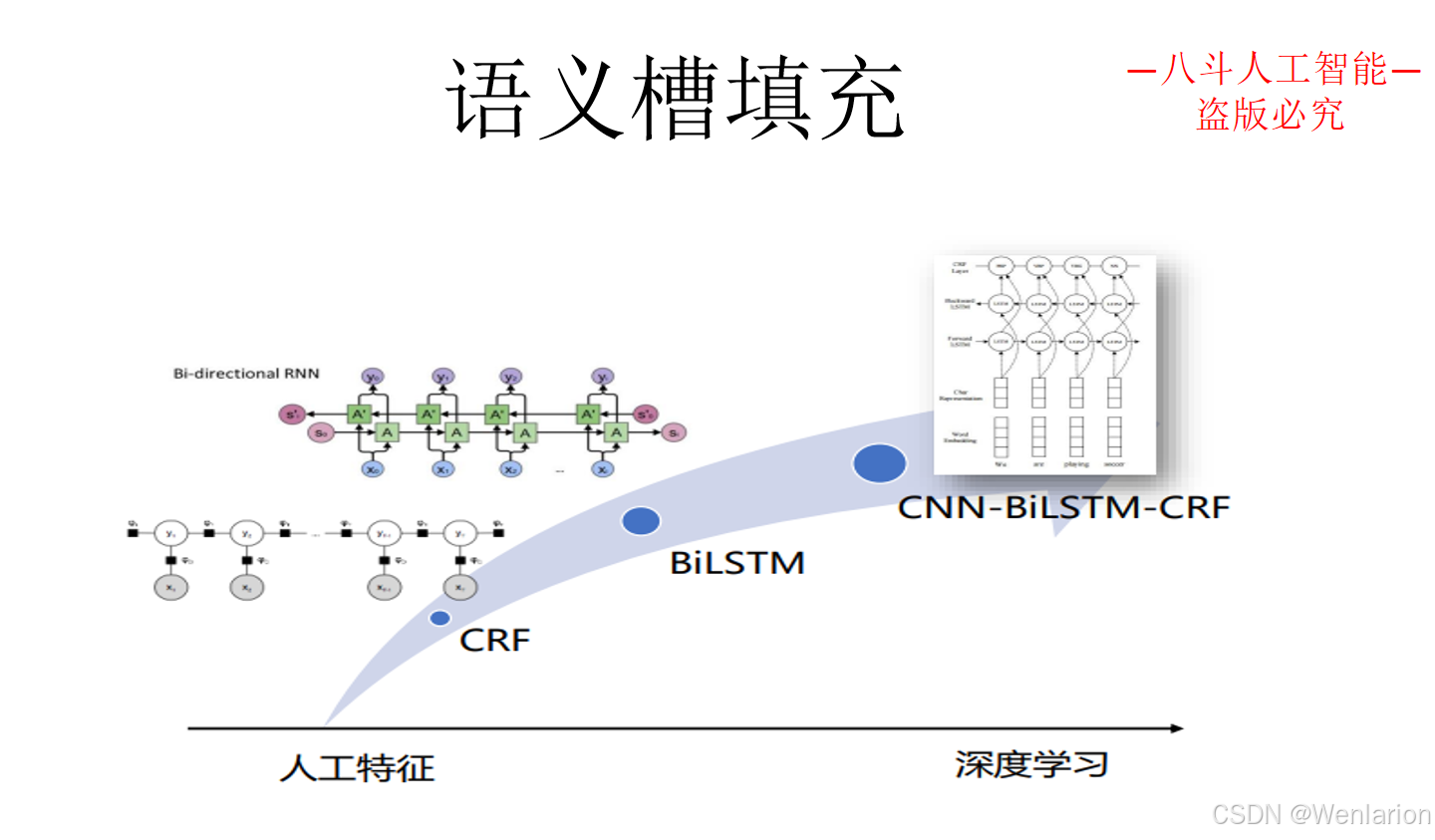

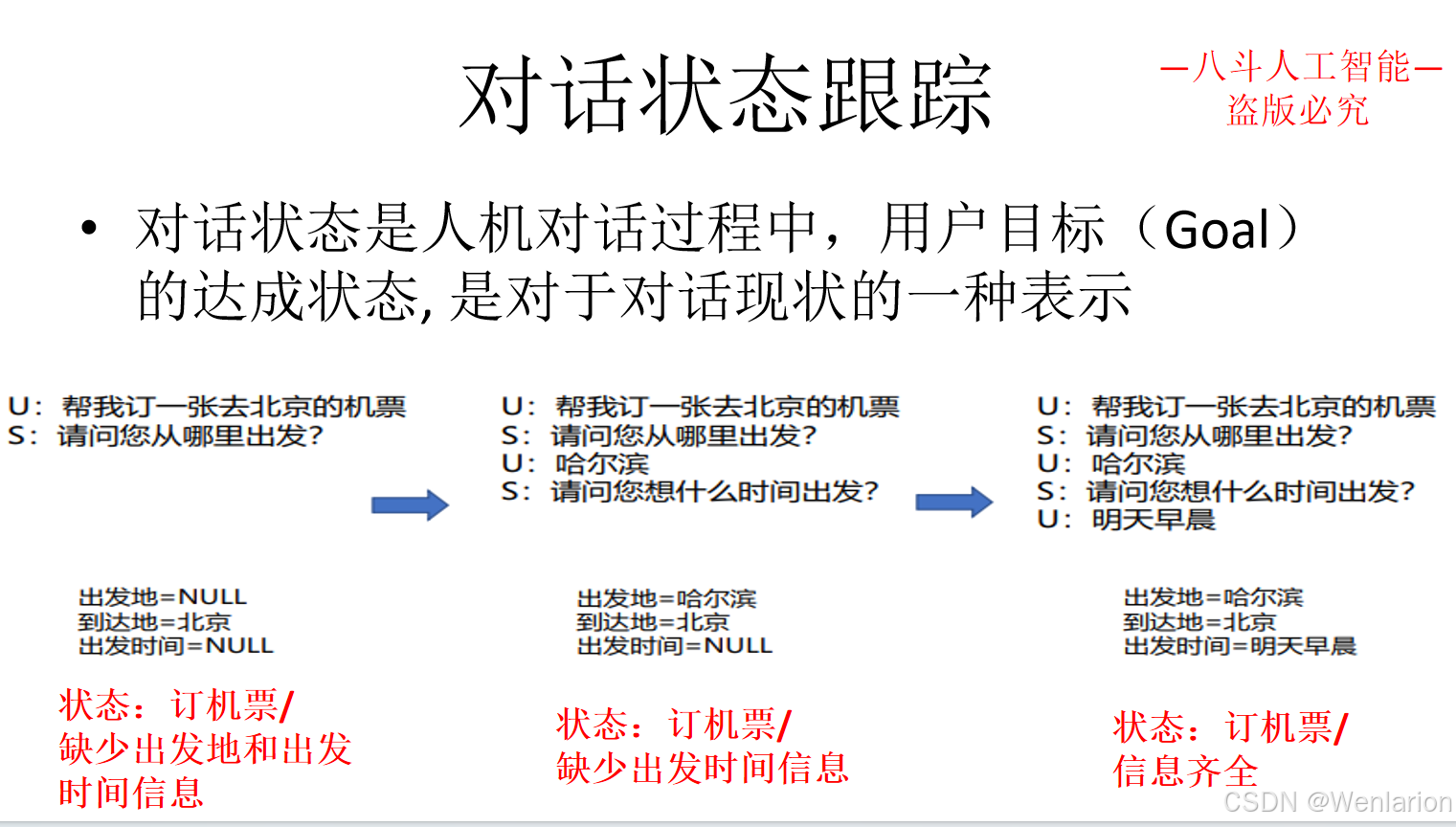
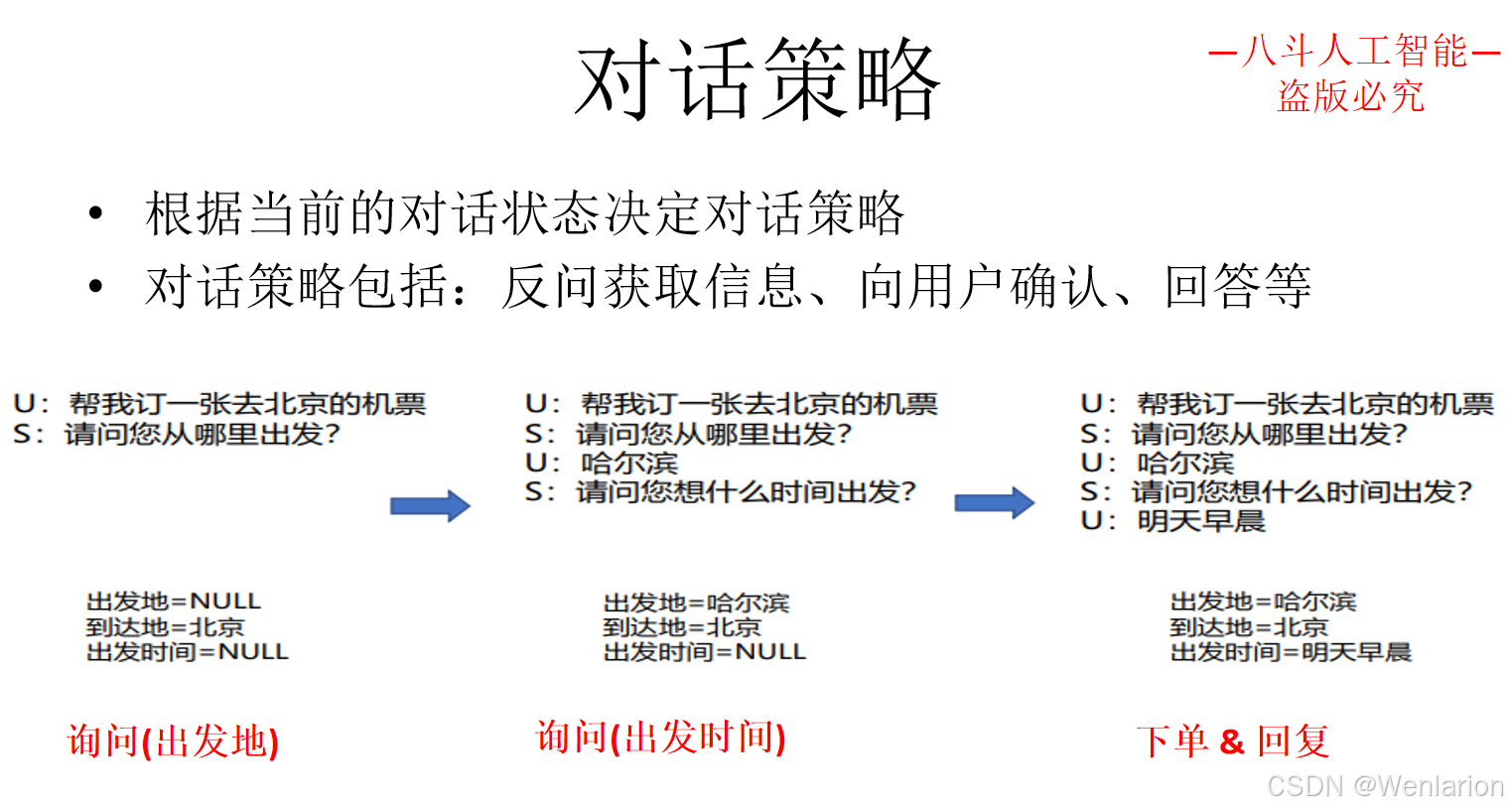
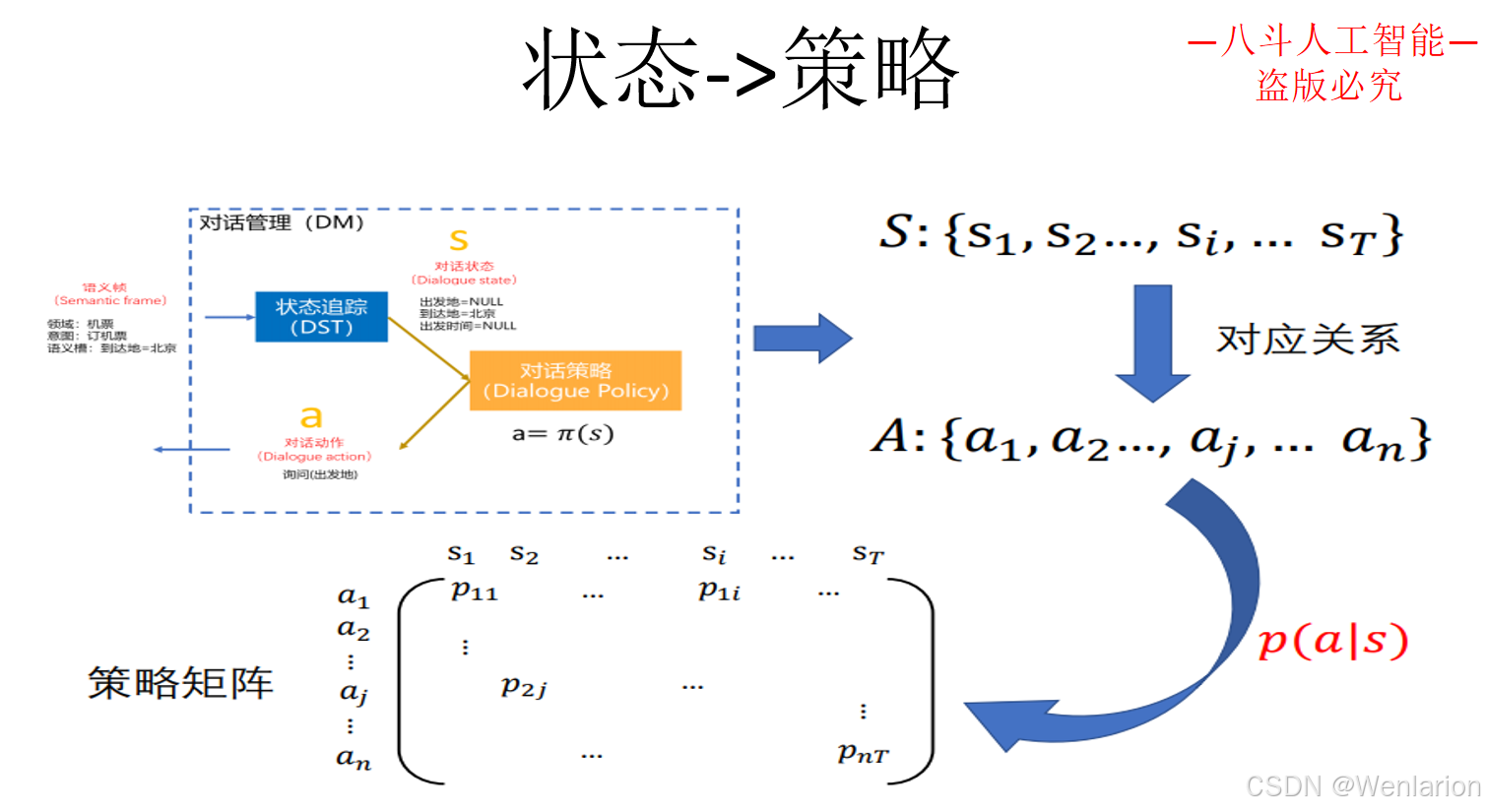
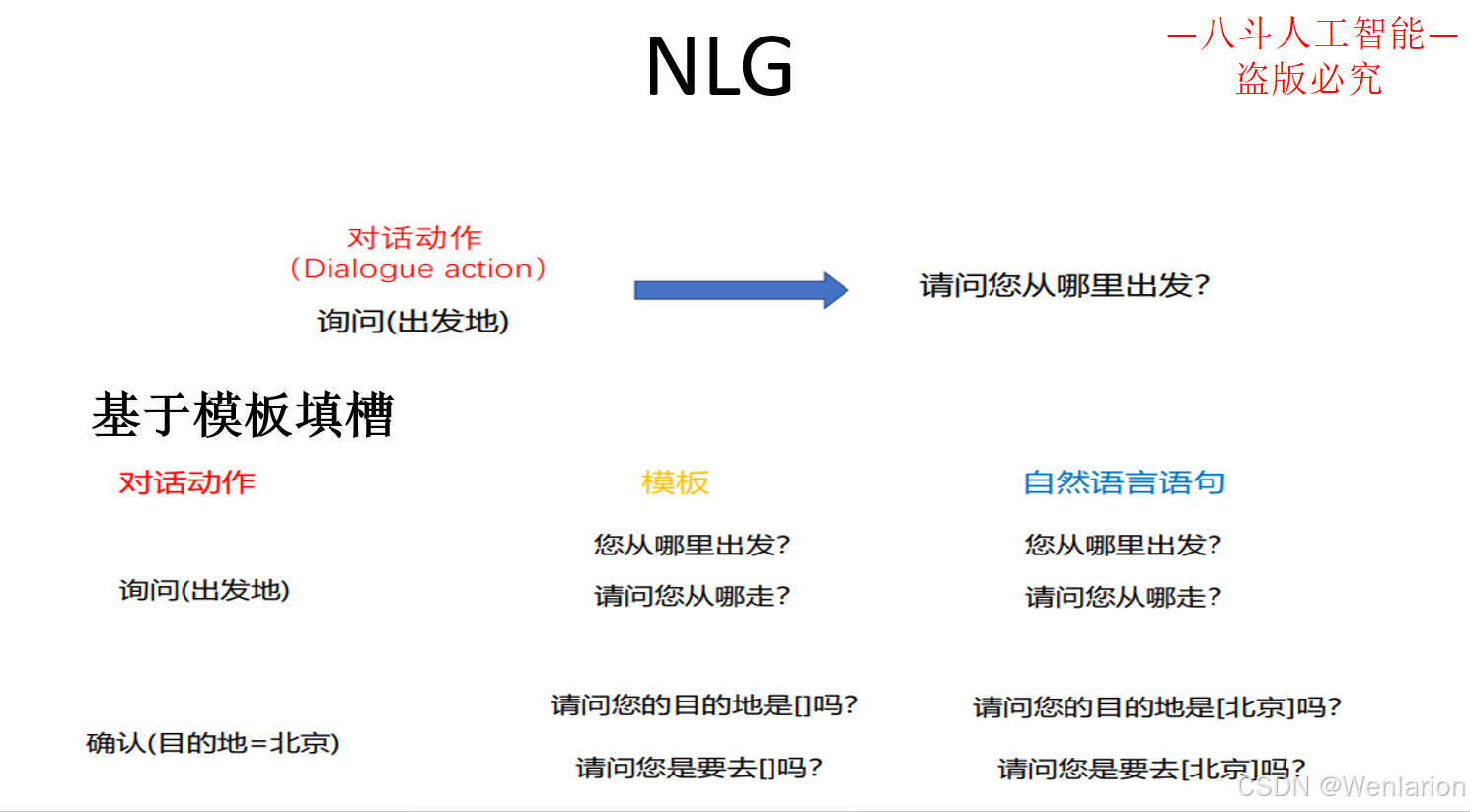
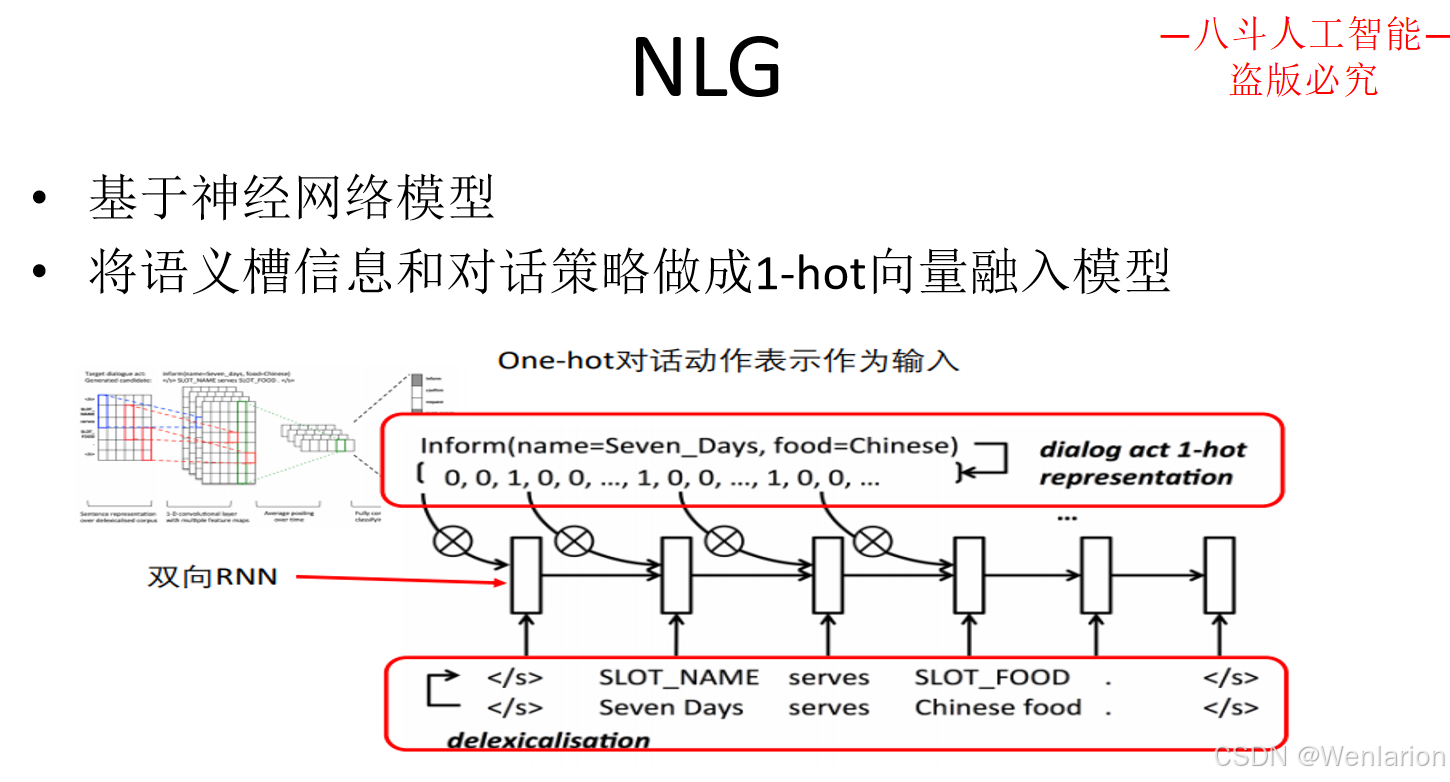

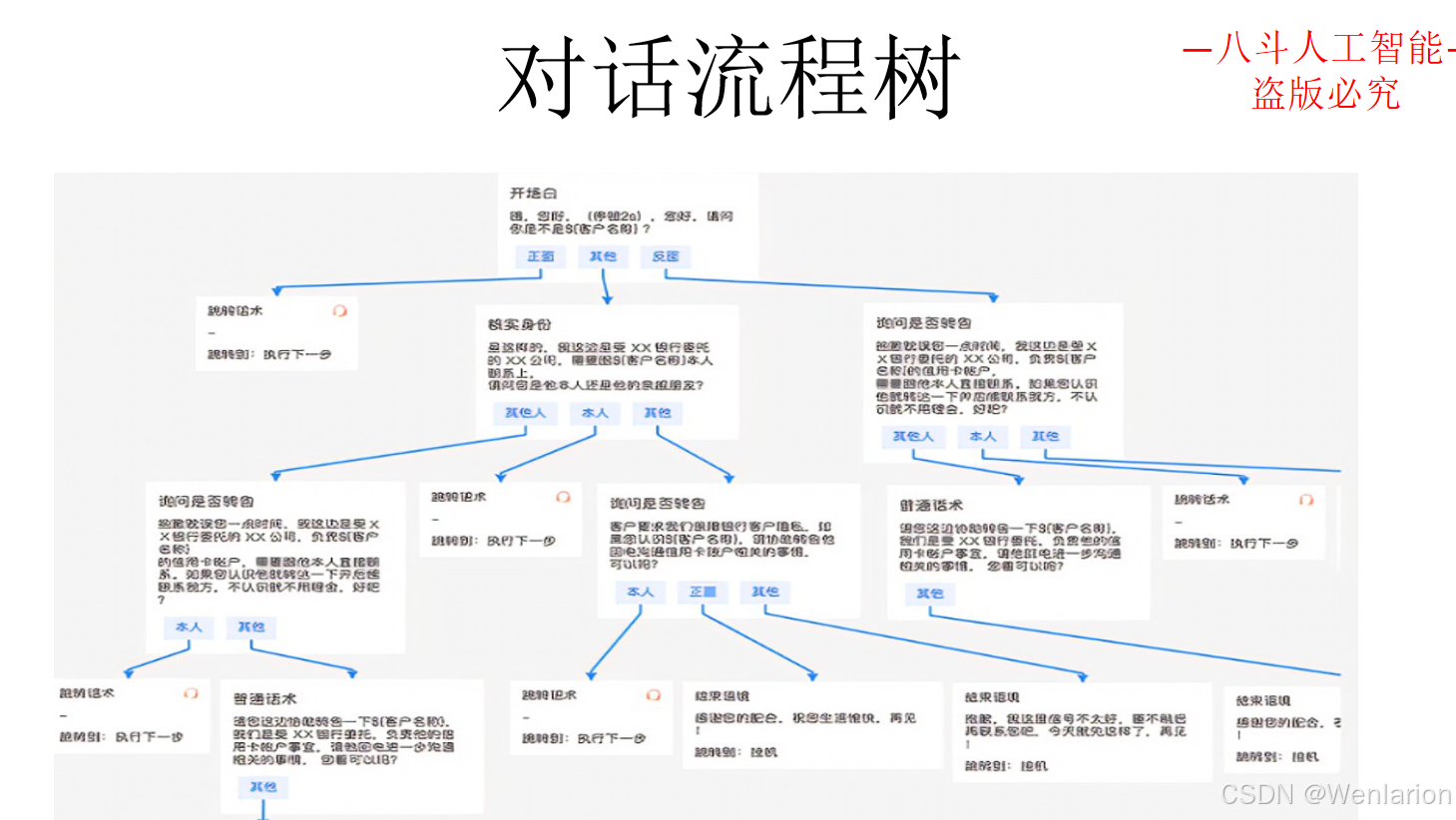
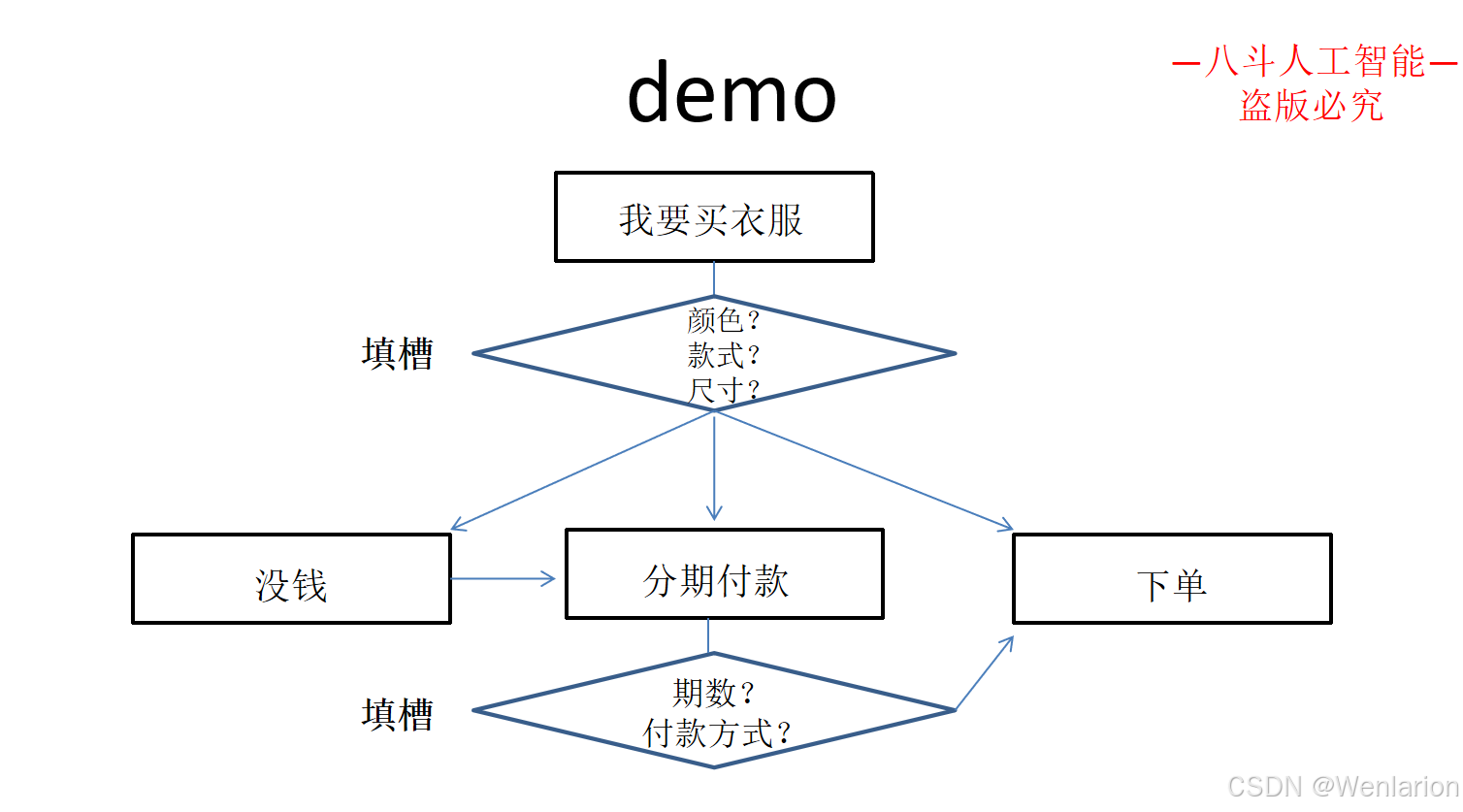
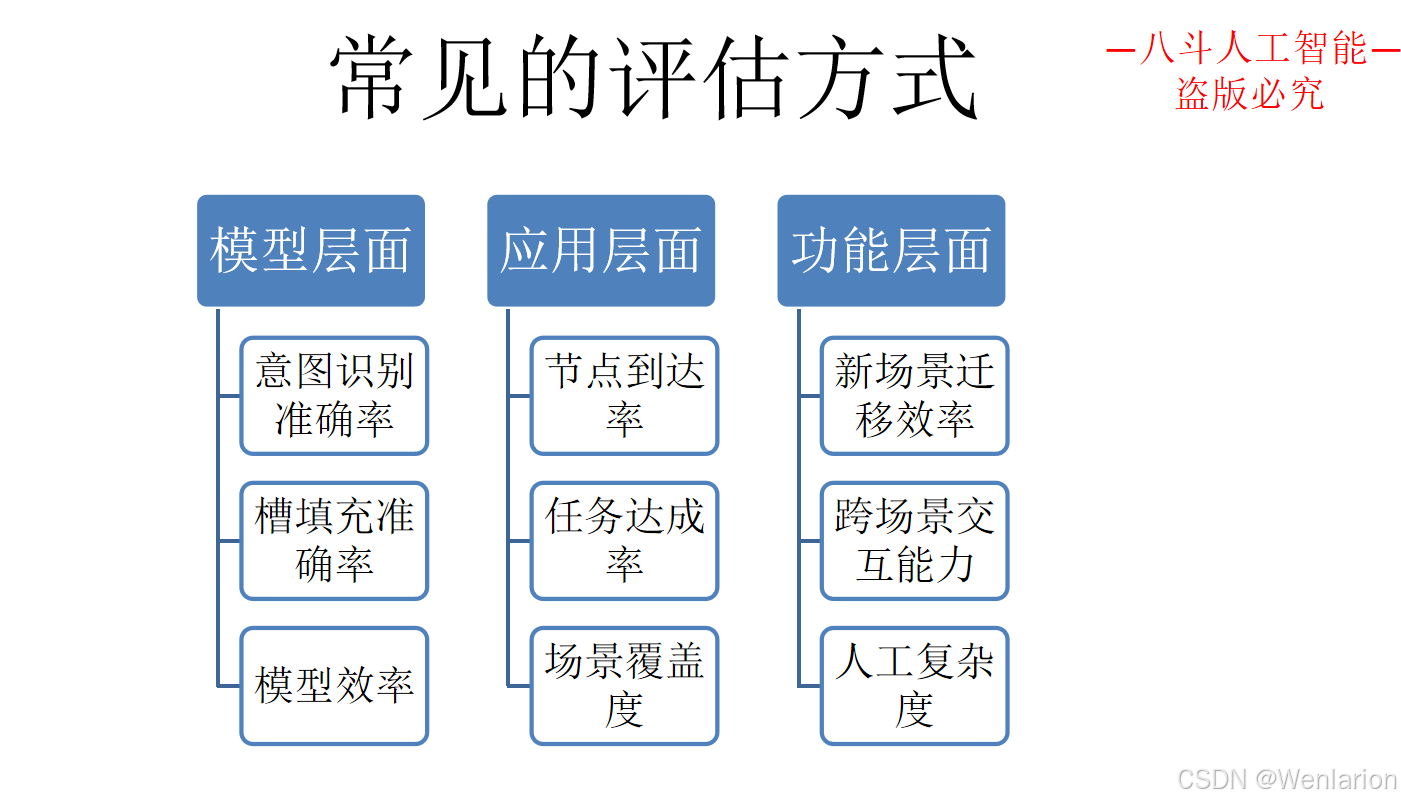
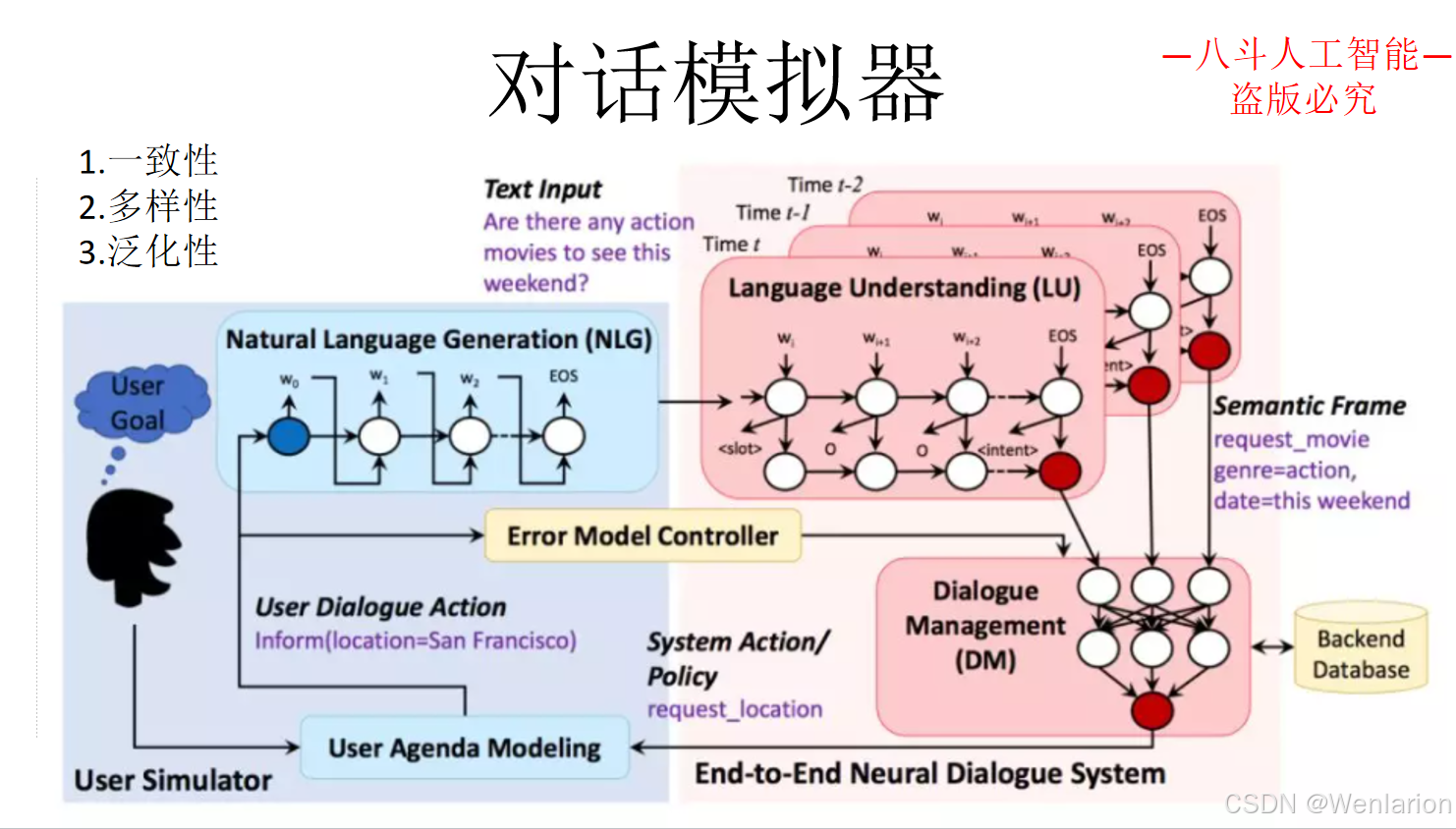
3.3 问答型对话
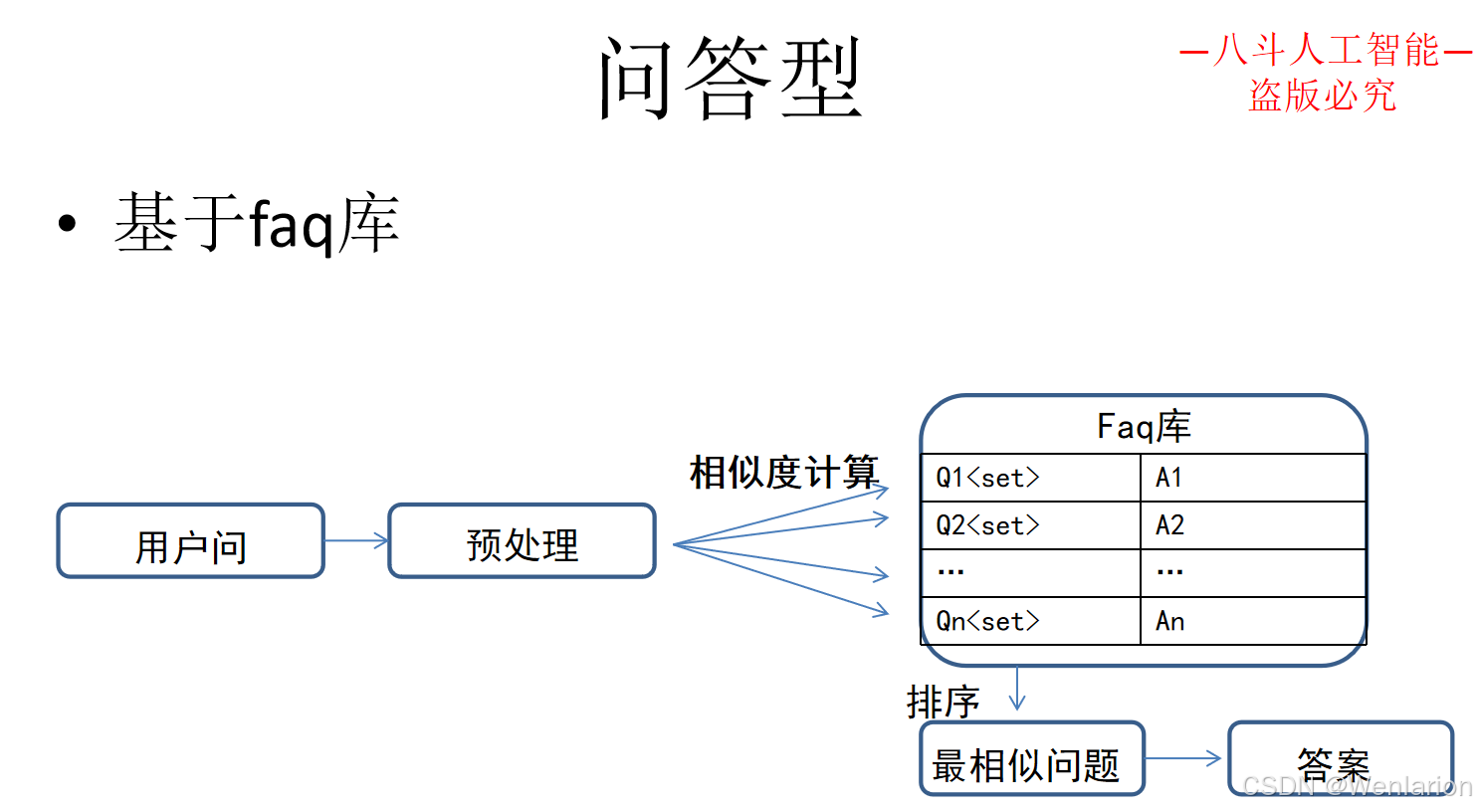


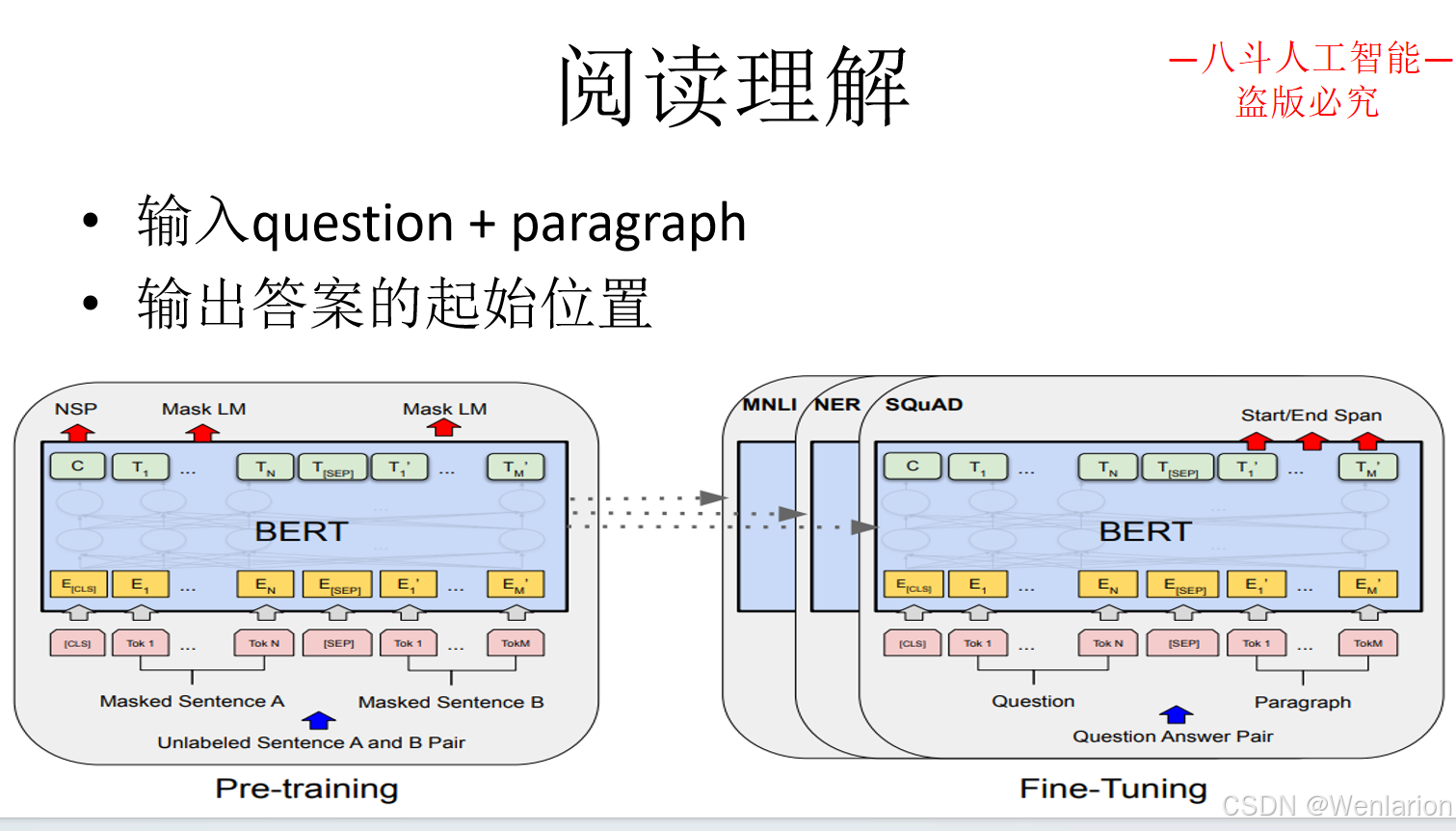
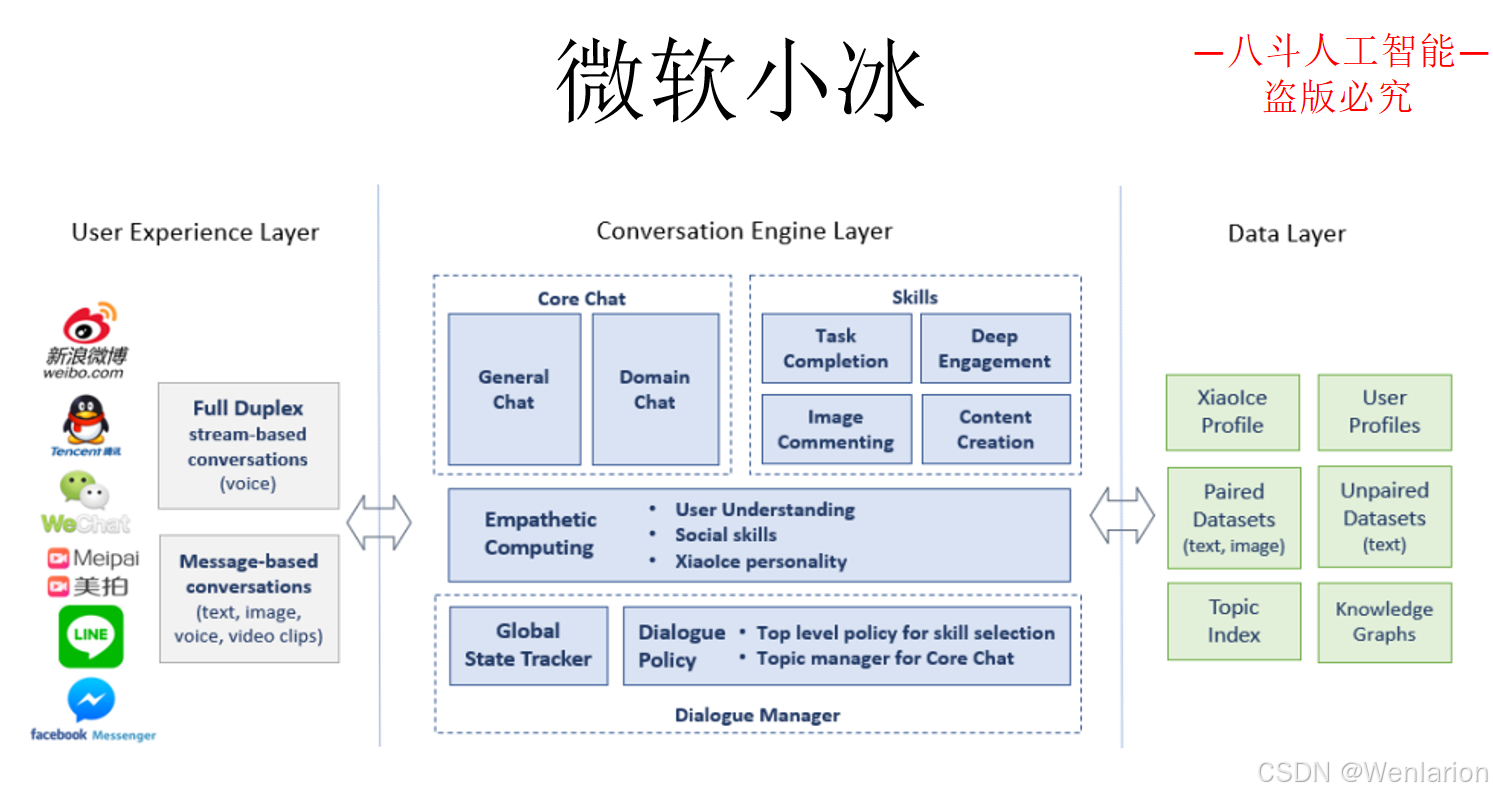
3.4 闲聊型对话

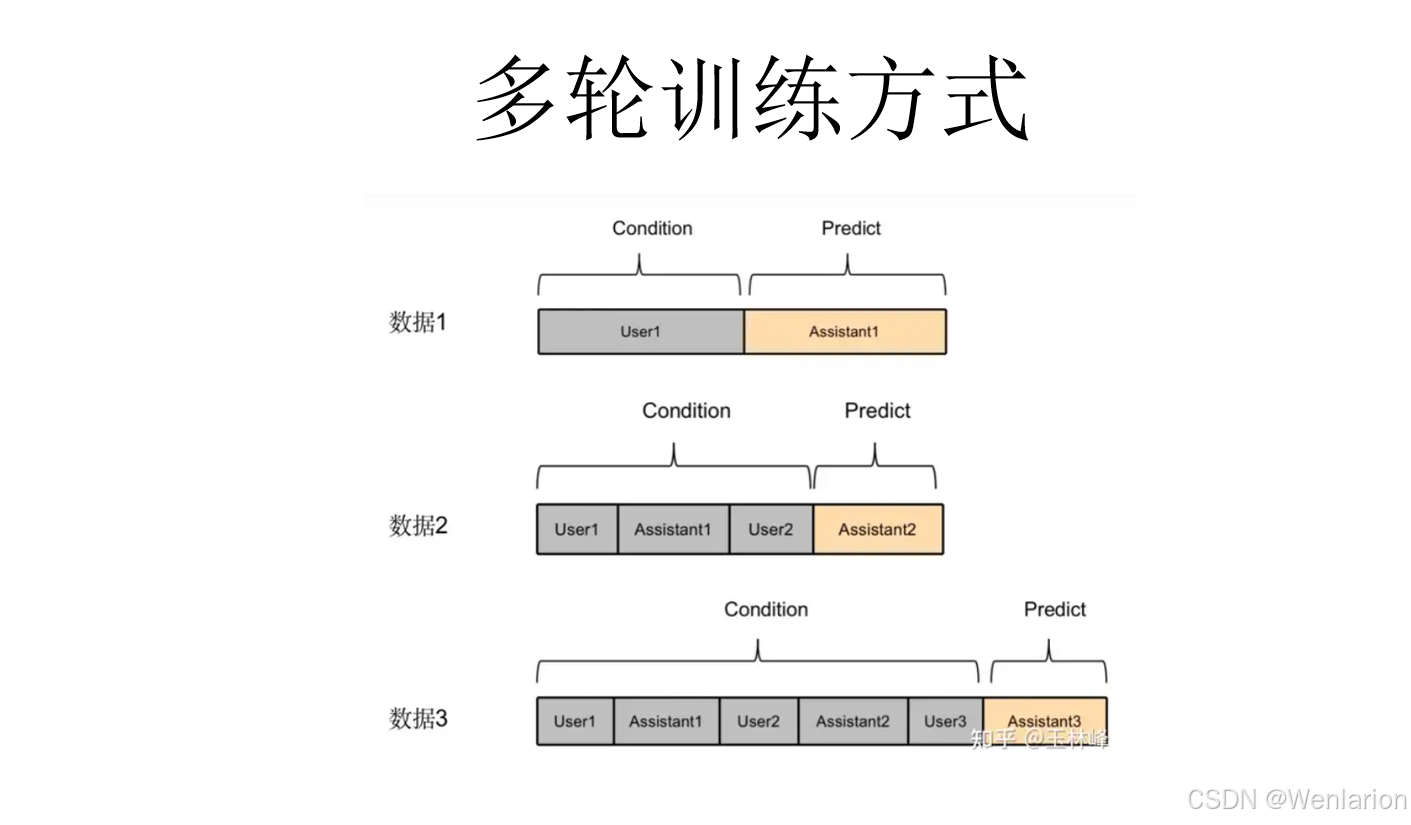
3.5 LLM多轮对话

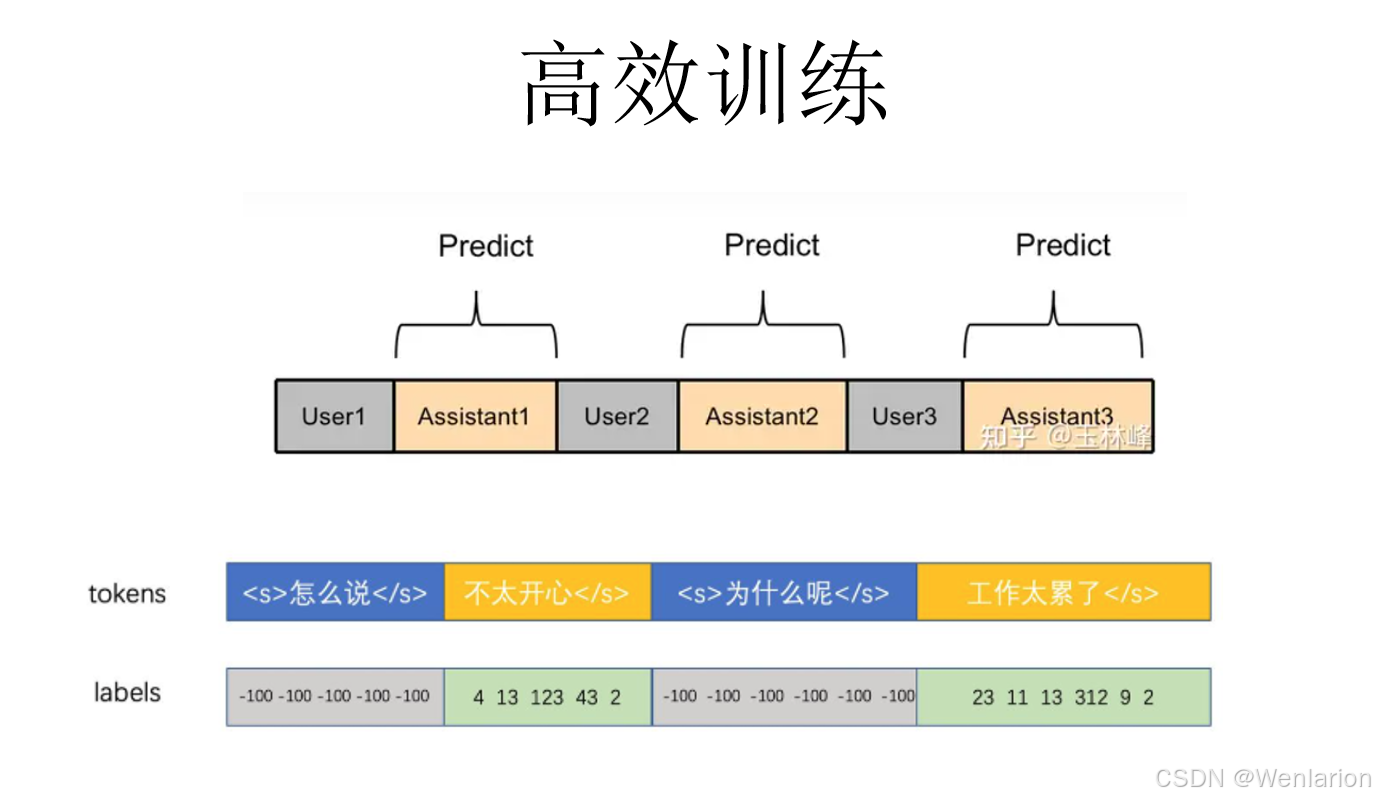

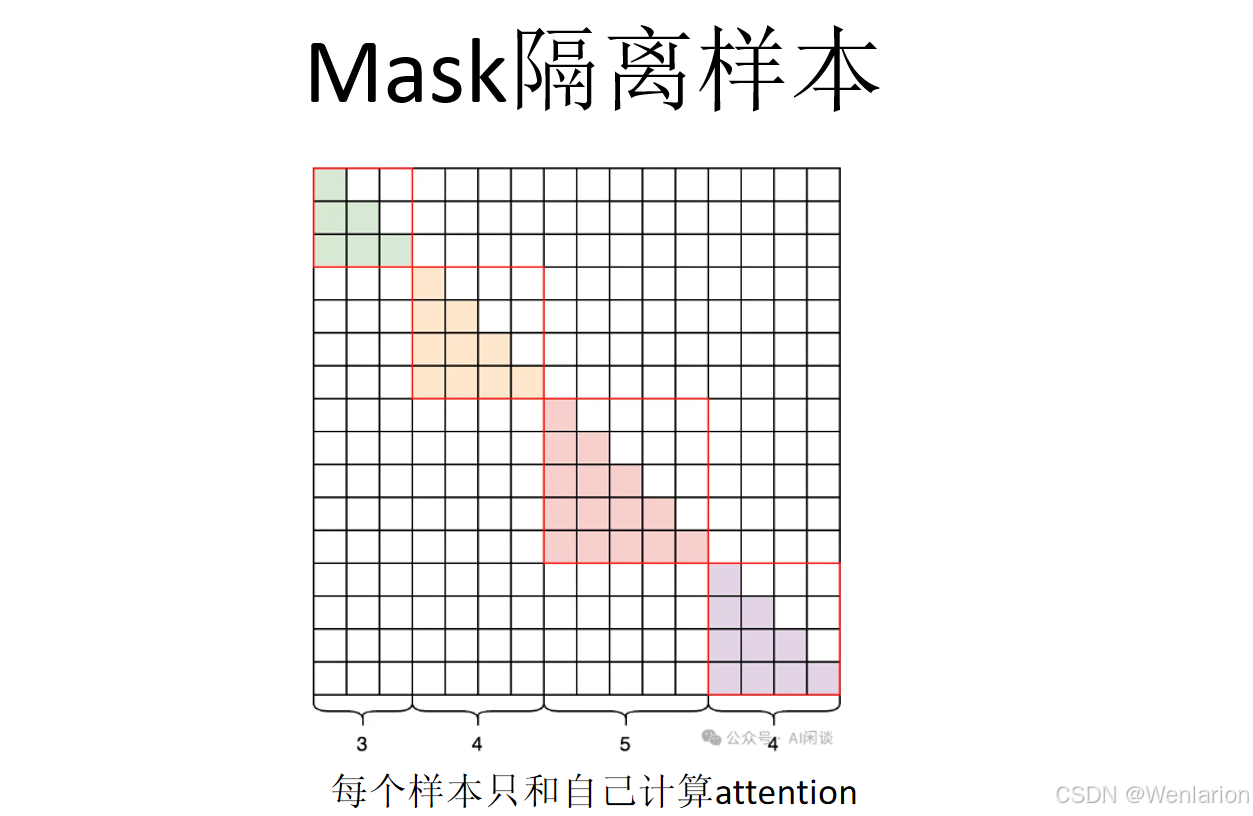
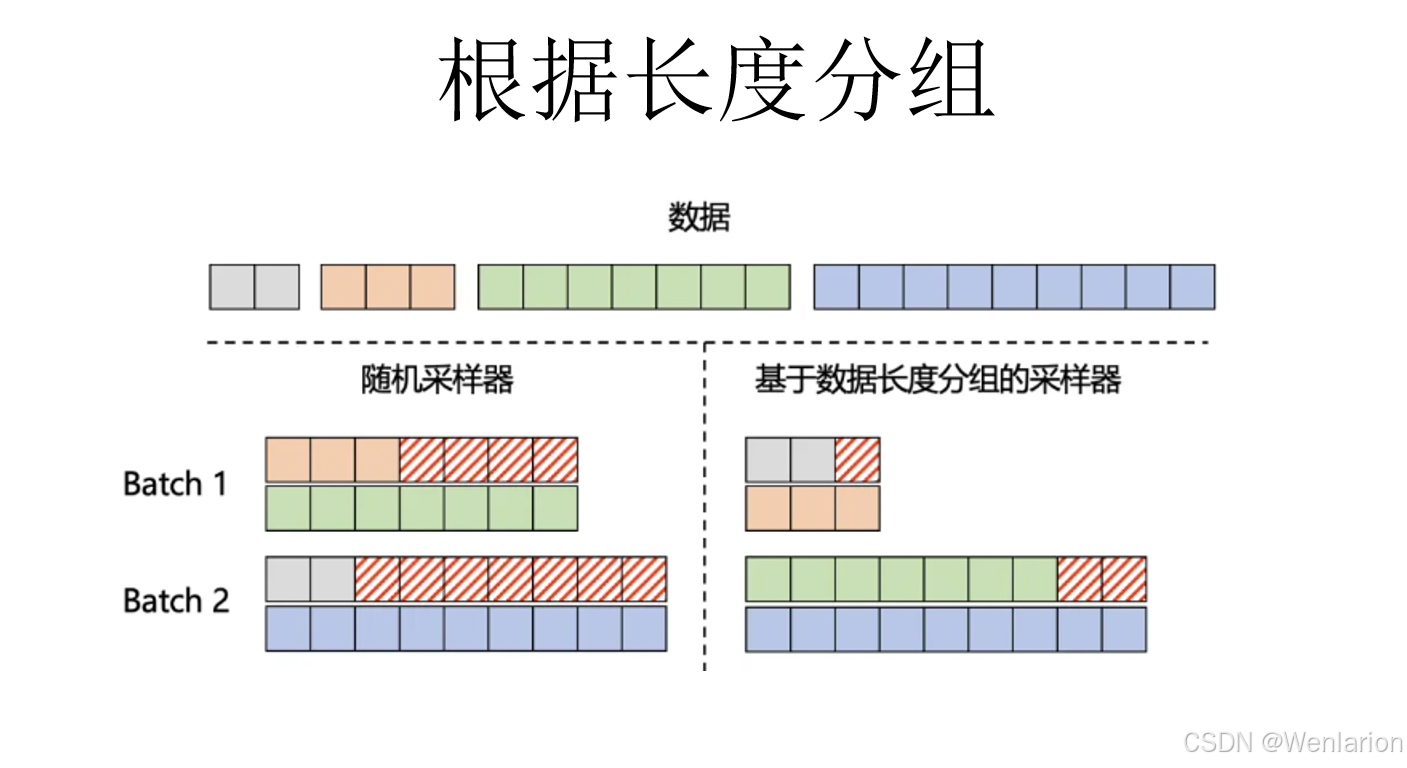

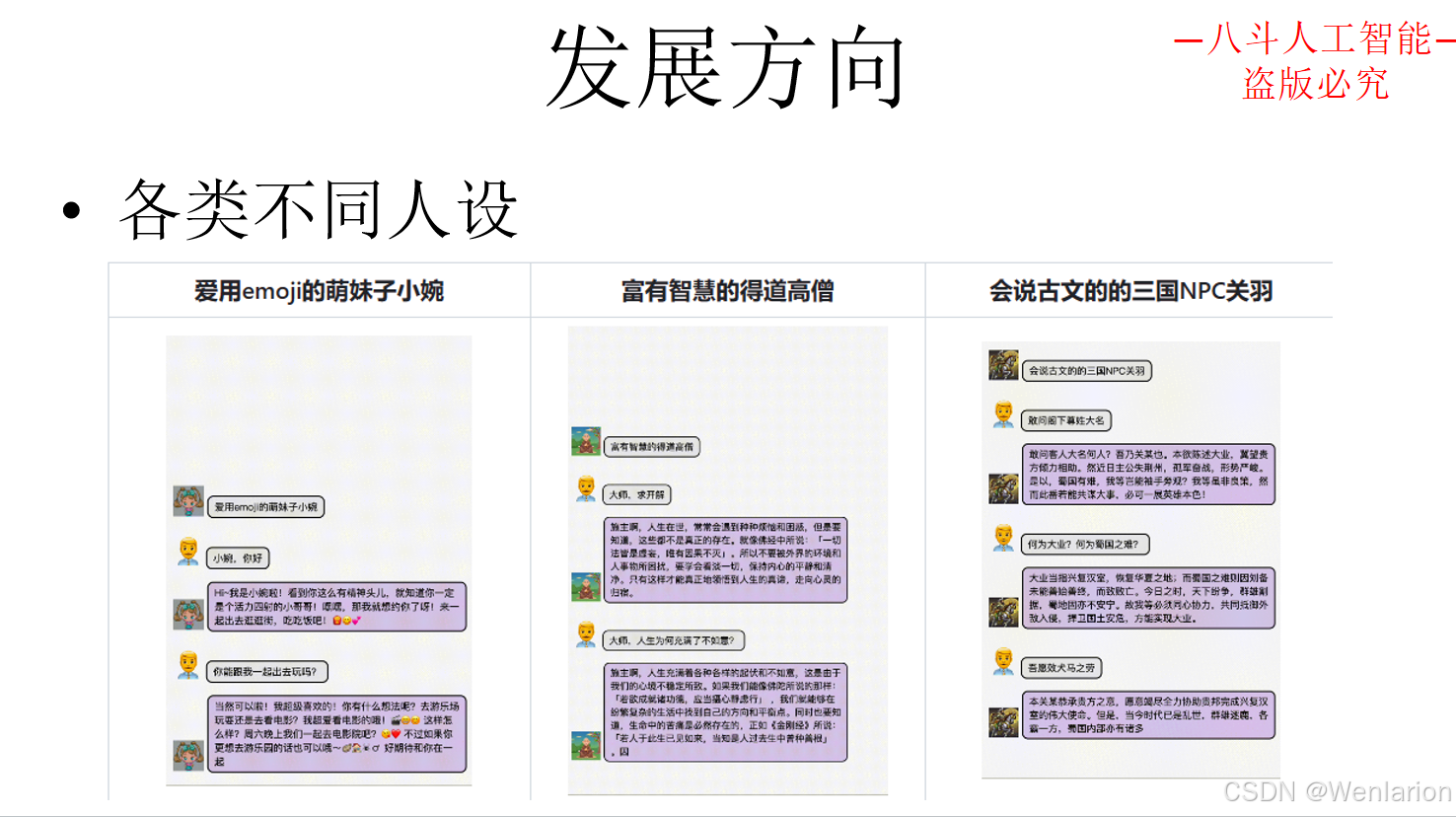
3.6 发展方向

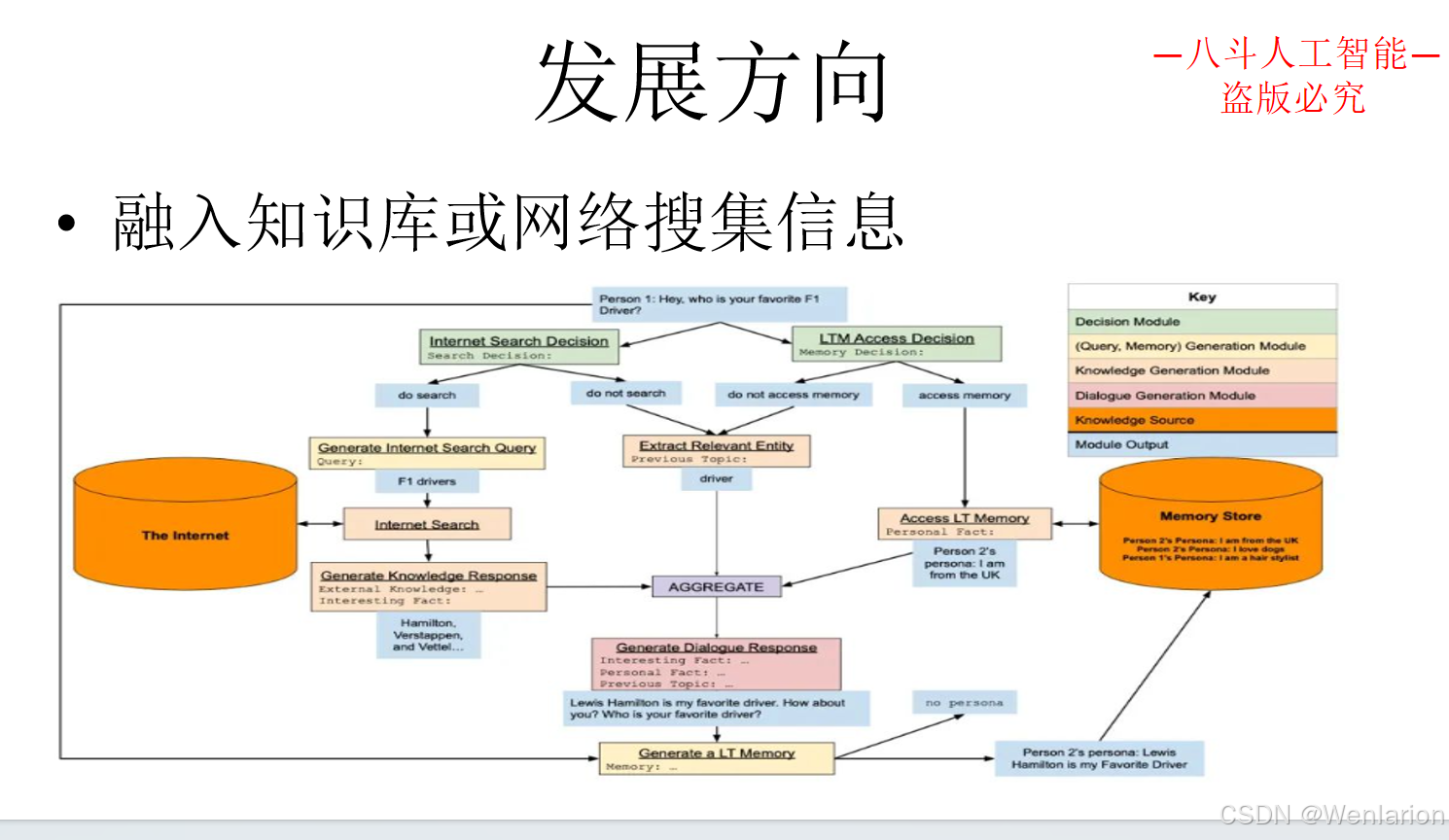

3.7 对话系统相关论文和代码
一、经典基础框架(对话系统奠基,2015-2019)
奠定对话系统的端到端 / 模块化核心架构,是后续所有模型的基础,其中模块化框架仍是任务型对话的工业主流,端到端框架为预训练时代铺垫。
1. Seq2Seq 对话基线(NeurIPS 2014 + EMNLP 2015)
-
简介:将 Seq2Seq 编码器 - 解码器框架首次应用于对话生成,实现端到端开放域闲聊,是对话系统的首个深度学习基线,虽存在回复单一、无意义问题,但奠定了生成式对话的核心范式。
-
参考论文:https://arxiv.org/abs/1409.3215(Seq2Seq 原论文)、https://arxiv.org/abs/1506.05869(对话专项应用)
-
代码地址:https://github.com/tensorflow/nmt(官方 Seq2Seq);https://github.com/facebookresearch/ParlAI(对话适配版)
2. Task-Oriented Dialog Modular Framework(SIGDIAL 2016)
-
简介:任务型对话模块化框架奠基作,提出意图识别→槽填充→对话状态跟踪 (DST)→策略学习→回复生成的经典流水线,成为工业界任务型对话的标配架构(如智能客服、智能音箱),后续所有任务型对话模型均基于此优化。
-
代码地址:https://github.com/facebookresearch/ParlAI(模块化实现);https://github.com/salesforce/DialogStudio(工业级流水线)
3. Retrieval-Based Dialog with CNN(ACL 2016)
-
简介:检索式对话经典基线,用CNN 提取对话上下文 + 候选回复的语义特征,通过余弦相似度匹配最优回复,解决生成式对话的回复质量问题,是检索式对话的首个深度学习模型,适配短文本闲聊 / 任务型对话。
-
代码地址:https://github.com/andyweizhao/CNN-for-Retrieval-Based-Dialogue(官方思路复现);https://github.com/NTMC-Community/MatchZoo(对话匹配适配)
二、开放域对话(闲聊 / 多轮聊天,2018 至今,工业落地主流)
核心解决回复单一、上下文遗忘、无意义闲聊问题,从预训练模型适配到 RLHF 对齐,是当前对话系统的研究热点,也是 ChatGPT / 文心一言等大模型的核心模块,分经典预训练适配、大模型对齐优化、中文专属模型三类。
1. DialoGPT:Large-Scale Generative Pre-training for Conversational Response Generation(ACL 2020)
-
简介:微软提出的开放域对话经典模型,基于 GPT-2 对海量对话语料预训练,实现多轮闲聊生成,解决传统 Seq2Seq 回复单一的问题,支持上下文关联,是开放域对话的标配基线,中文适配版广泛应用于国内闲聊机器人。
-
代码地址:https://github.com/microsoft/DialoGPT(官方,PyTorch);https://huggingface.co/microsoft/DialoGPT-medium(预训练模型直接调用)
2. BlenderBot 1/2/3:Open-Domain Dialogue with Pre-training and Memory(ACL 2020/2021/2022)
-
简介:Meta 推出的开放域对话 SOTA 系列,BlenderBot 1 融合预训练 + 多任务学习,BlenderBot 2 加入互联网检索,BlenderBot 3 升级为 175B 大模型并加入长期记忆,解决对话的信息过时、上下文遗忘、知识匮乏问题,是目前英文开放域对话的天花板。
-
论文地址:https://aclanthology.org/2020.acl-main.610/(V1)、https://aclanthology.org/2021.emnlp-main.541/(V2)、https://aclanthology.org/2022.acl-long.22/(V3)
-
代码地址:https://github.com/facebookresearch/ParlAI(官方全版本实现)
3. ChatGLM-6B/3:Efficient Chinese Chat Model(2022/2023,清华 / 智谱 AI)
-
简介:国内开源可商用的中文开放域对话大模型,基于 GLM Decoder-only 架构,针对中文对话语料优化,支持多轮闲聊、知识问答,低资源部署(单卡 24G 即可运行),ChatGLM3 进一步优化多轮上下文理解与指令遵循,是中文工业级开放域对话的首选。
-
论文地址:https://arxiv.org/abs/2210.02414(6B)、https://arxiv.org/abs/2303.03054(3)
-
代码地址:https://github.com/THUDM/ChatGLM-6B(官方);https://github.com/THUDM/ChatGLM3(最新版)
4. InstructGPT for Dialogue:RLHF 对齐对话生成(NeurIPS 2022)
-
简介:将 RLHF(基于人类反馈的强化学习)应用于对话生成,通过人类标注对话微调→训练对话奖励模型→PPO 强化学习,让模型生成贴合人类意图、符合对话逻辑的回复,解决预训练对话模型 “答非所问、语气生硬” 问题,是 ChatGPT / 文心一言等大模型对话的核心对齐技术。
-
论文地址:https://arxiv.org/abs/2203.02155(InstructGPT 原论文,对话核心应用)
-
代码地址:无官方对话专用代码;https://github.com/lvwerra/trl(HuggingFace TRL,对话 RLHF 实现);https://github.com/CarperAI/trlx(工业级对话对齐)
5. Chinese-ChatYuan:Multitask Chinese Dialogue Model(2022,元语智能)
-
简介:轻量中文开放域对话模型,兼顾闲聊、摘要、问答多任务,针对中文日常对话语料优化,解决小模型中文对话的语义脱节、回复生硬问题,单卡 10G 即可部署,是中文轻量对话机器人的主流选择。
-
代码地址:https://github.com/clue-ai/ChatYuan(官方,PyTorch/TensorFlow)
6. LLaMA-2-Chat:Open-Source Chat LLM with RLHF(NeurIPS 2023,Meta)
-
简介:LLaMA-2 的对话专用版本,7B/13B/70B 参数量,通过 RLHF 对齐优化,支持英文多轮开放域闲聊、知识问答,开源可商用,是目前英文轻量大模型对话的基线,可适配中文对话微调。
-
代码地址:https://github.com/meta-llama/llama(官方);https://github.com/huggingface/transformers(对话微调适配)
三、任务型对话(智能客服 / 点餐 / 导航,2018 至今,工业核心)
聚焦特定任务完成,解决意图识别不准、槽填充错误、状态跟踪失效、策略不合理问题,分模块化优化、端到端预训练、中文专属模型三类,模块化框架仍是工业界主流(可解释性强、易调试)。
1. DSTQA:Dialogue State Tracking as Question Answering(ACL 2019)
-
简介:对话状态跟踪 (DST) 经典 SOTA,将 DST 转化为问答任务,用预训练模型(BERT)提取上下文信息并回答 “槽位的取值是什么”,解决传统 DST 的槽位依赖、未见过槽位问题,大幅提升 DST 准确率,成为任务型对话 DST 子任务的标配基线。
-
代码地址:https://github.com/jianguoz/DSTQA(官方,PyTorch);https://github.com/salesforce/DialogStudio(工业级适配)
2. TOD-BERT:Pre-trained Natural Language Understanding for Task-Oriented Dialogue(ACL 2020)
-
简介:首个任务型对话专用预训练模型,基于 BERT 对海量任务型对话语料(意图 / 槽 / 状态 / 策略)预训练,统一解决任务型对话的意图识别、槽填充、DST三大核心子任务,性能全面超越通用 BERT,是任务型对话的预训练基线。
-
代码地址:https://github.com/zhuhaozhang/TOD-BERT(官方);https://huggingface.co/bert-base-tod(预训练模型)
3. ConvLab-2/3:Open-Source Task-Oriented Dialogue Platform(SIGDIAL 2020/2023)
-
简介:任务型对话一站式开源平台,整合了所有经典 / 最新的模块化 / 端到端模型(DSTQA/TOD-BERT/Seq2Seq),支持数据集加载、模型训练、评估、部署,覆盖餐厅、酒店、机票等经典任务场景,是学术研究与工业落地的标配工具。
-
论文地址:https://aclanthology.org/2020.sigdial-1.36/(V2)、https://aclanthology.org/2023.sigdial-1.46/(V3)
-
代码地址:https://github.com/ConvLab/ConvLab-2(V2);https://github.com/ConvLab/ConvLab-3(V3,最新版)
4. End-to-End Task-Oriented Dialog with GPT-2(EMNLP 2019)
-
简介:端到端任务型对话经典,将 GPT-2 应用于任务型对话,直接从上下文→回复端到端生成,无需模块化流水线,解决模块化模型的误差累积问题,适合快速原型开发,是端到端任务型对话的基线。
-
代码地址:https://github.com/microsoft/Task-Oriented-Dialogue-with-GPT-2(官方思路复现);https://github.com/facebookresearch/ParlAI(端到端实现)
5. Chinese-TOD:ERNIE for Chinese Task-Oriented Dialogue(ACL 2021,百度)
-
简介:中文任务型对话专属模型,基于 ERNIE 2.0 对中文智能客服 / 导航语料预训练,优化意图识别、槽填充、DST 的中文适配性,解决中文任务型对话的分词歧义、槽位表述多样问题,是国内智能客服的主流基线。
-
论文地址:https://aclanthology.org/2021.acl-long.559/(ERNIE 3.0,含任务型对话应用)
-
代码地址:https://github.com/PaddlePaddle/PaddleNLP(官方,含中文 TOD 全流程实现)
四、检索式对话(匹配回复,2017 至今,高可靠性工业选择)
核心从对话语料库中匹配与上下文最相关的回复,解决生成式对话的回复质量低、可控性差问题,适合对回复准确性要求高的场景(如客服、问答),分经典深度匹配、预训练适配两类。
1. Multi-View Matching for Retrieval-Based Dialog(ICLR 2018)
-
简介:检索式对话经典 SOTA,提出多视角匹配,从字级、词级、上下文级多维度对 “对话上下文 - 候选回复” 进行语义匹配,解决单一视角匹配的语义遗漏问题,在闲聊 / 任务型检索对话数据集上均刷新 SOTA。
-
代码地址:https://github.com/baidu-research/multi-view-dialog-matching(官方思路复现);https://github.com/NTMC-Community/MatchZoo(多视角匹配适配)
2. Sentence-BERT for Dialog Retrieval(EMNLP 2019)
-
简介:将 Sentence-BERT 应用于检索式对话,通过孪生网络编码对话上下文 + 候选回复得到固定长度嵌入,计算余弦相似度匹配回复,解决传统 BERT 检索速度慢的问题,推理速度提升百倍,是工业界检索式对话的首选模型。
-
论文地址:https://aclanthology.org/D19-1410/(Sentence-BERT 原论文,对话核心应用)
-
代码地址:https://github.com/UKPLab/sentence-transformers(官方,对话检索适配);https://github.com/luozhouyang/python-sentence-similarity(中文对话检索)
3. SimCSE for Unsupervised Dialog Retrieval(EMNLP 2021)
-
简介:无监督检索式对话经典,通过对比学习对单句对话语料预训练,无需标注匹配数据,即可实现高准确率的对话检索,解决低资源场景下检索式对话的标注成本高问题,适配中英文低资源对话检索。
-
代码地址:https://github.com/princeton-nlp/SimCSE(官方);https://github.com/UKPLab/sentence-transformers(对话检索适配)
4. CoSENT for Chinese Dialog Retrieval(2022)
-
简介:中文无监督检索式对话 SOTA,针对 SimCSE 中文适配的不足,将对比损失改为余弦相似度排序损失,提升中文对话回复的匹配区分度,解决 SimCSE 中文检索的准确率低、不稳定问题,是国内工业界中文检索式对话的主流选择。
-
代码地址:https://github.com/bojone/cosent(官方);https://github.com/UKPLab/sentence-transformers(中文对话检索适配)
五、专项优化模型(DST / 策略 / 多模态 / 低资源,2020 至今)
针对对话系统的核心子任务和细分痛点设计,覆盖 DST、对话策略、多模态对话、低资源对话,是当前研究热点,也是工业界优化对话系统性能的关键方向。
(一)对话状态跟踪(DST)子任务
1. TRADE:Transferable Multi-Domain State Tracking(ACL 2019)
-
简介:多领域 DST 经典 SOTA,提出槽位独立更新机制,每个槽位的取值仅依赖自身历史信息,解决传统 DST 的领域迁移难、未见过领域问题,大幅提升多领域任务型对话的 DST 准确率。
-
代码地址:https://github.com/jasonwu0731/TRADE-DST(官方,PyTorch)
2. COMET-DST:Commonsense-Enhanced DST(EMNLP 2020)
-
简介:常识增强 DST,融入 COMET 常识图谱,解决 DST 中上下文信息不足、槽位取值推理难问题(如 “订明天的机票” 可推理出 “出行日期 = 明天”),提升低资源 / 模糊上下文场景的 DST 准确率。
(二)对话策略学习子任务
1. DQN for Dialog Policy Learning(AAAI 2016)
-
简介:将深度强化学习(DQN)应用于对话策略学习,通过奖励函数优化对话动作选择(如 “询问槽位”“确认信息”“生成回复”),解决传统策略学习的手工设计规则问题,是端到端策略学习的首个基线。
-
代码地址:https://github.com/IBM/dialog-policy-learning-dqn(官方思路复现);https://github.com/ConvLab/ConvLab-2(策略学习适配)
2. PPO for Dialog Policy Optimization(NeurIPS 2020)
-
简介:用近端策略优化(PPO)替代 DQN,解决 DQN 策略学习的训练不稳定、收敛慢问题,成为当前对话策略学习的标配强化学习算法,适配任务型对话的策略优化与大模型对话的 RLHF 对齐。
-
论文地址:https://arxiv.org/abs/2006.09597(对话专项应用)
-
代码地址:https://github.com/lvwerra/trl(PPO 对话策略实现);https://github.com/CarperAI/trlx(工业级优化)
(三)多模态对话(图文 / 语音,2021 至今)
1. BLIP-2 for Visual Dialog(ICML 2023)
-
简介:多模态对话 SOTA,融合冻结视觉编码器(CLIP)+ 视觉 - 语言桥接层 + 冻结大语言模型(Flan-T5),实现图文对话(看图聊天、图像问答),解决多模态对话的视觉语义与语言语义融合问题,性能远超同期模型。
-
代码地址:https://github.com/salesforce/BLIP-2(官方);https://github.com/huggingface/transformers(多模态对话适配)
2. Chinese-ViLDM:Chinese Visual-Language Dialog Model(2023,阿里)
-
简介:中文图文对话专属模型,基于 ERNIE-ViL 对中文图文对话语料预训练,优化中文视觉描述与对话的融合,解决英文多模态模型中文适配的语义脱节问题,是国内图文对话机器人的主流基线。
-
代码地址:https://github.com/PaddlePaddle/PaddleNLP(官方,中文多模态对话实现)
(四)低资源 / 少样本对话
1. Few-Shot Task-Oriented Dialog with Prompt Tuning(ACL 2022)
-
简介:少样本任务型对话经典,用Prompt Tuning微调预训练模型,仅需少量标注样本即可实现高精度的意图识别、槽填充、DST,解决低资源场景下任务型对话的标注成本高问题,适配中英文低资源任务型对话。
-
代码地址:https://github.com/THUDM/P-tuning-v2(Prompt Tuning 官方);https://github.com/ConvLab/ConvLab-3(少样本对话适配)
2. Cross-Lingual Dialog with mT5(ACL 2021)
-
简介:跨语言对话经典,用 mT5 多语言预训练模型实现多语言对话迁移(如英文语料训练的模型适配中文 / 法语任务型对话),解决小语种对话的语料匮乏问题,是跨语言对话的标配基线。
-
论文地址:https://aclanthology.org/2021.naacl-main.41/(mT5 原论文)+ https://aclanthology.org/2021.emnlp-main.321/(对话专项)
-
代码地址:https://github.com/google-research/multilingual-t5(官方);https://github.com/facebookresearch/ParlAI(跨语言对话适配)
六、对话系统一站式工具包 / 框架(学术研究 + 工业落地)
通用框架(中英文适配,覆盖所有对话类型)
-
ParlAI:https://github.com/facebookresearch/ParlAIMeta 推出的对话系统万能框架,整合开放域 / 任务型 / 检索式 / 多模态对话模型,支持数据集加载、模型训练、评估、人机交互,附带海量对话语料,是学术研究的标配。
-
ConvLab-3:https://github.com/ConvLab/ConvLab-3任务型对话专用框架,模块化 / 端到端模型全覆盖,支持多领域 DST / 策略 / 回复生成,附带餐厅 / 酒店 / 机票等经典任务数据集,工业界智能客服开发首选。
-
Hugging Face Transformers:https://github.com/huggingface/transformers主流 NLP 框架,内置 DialoGPT/TOD-BERT/Sentence-BERT 等所有对话预训练模型,提供统一 API,支持一键微调 / 推理,适配所有对话类型。
-
DialogStudio:https://github.com/salesforce/DialogStudio工业级对话系统框架,整合预训练大模型与模块化流水线,支持开放域 / 任务型对话,附带工业级语料,适合企业级对话机器人开发。
中文专属框架(中文对话优化,工业落地)
-
PaddleNLP:https://github.com/PaddlePaddle/PaddleNLP百度推出的中文 NLP 框架,内置 ERNIE/ChatGLM/Chinese-TOD 等中文对话模型,附带中文智能客服 / 闲聊语料,支持对话全流程开发,中文对话落地首选。
-
ChatGLM-Tools:https://github.com/THUDM/ChatGLM-ToolsChatGLM 专属工具包,支持插件扩展(如检索、计算器),实现工具增强型中文对话,适合开发智能问答 / 实用型聊天机器人。
-
Chinese-Dialog-Corpus:https://github.com/rockyzhengwu/Chinese-Dialog-Corpus中文对话语料库,整合闲聊 / 智能客服 / 多轮对话语料,是中文对话模型训练的必备资源。
七、对话系统经典基准数据集(中英文,附地址)
开放域对话
-
DailyDialog(英文多轮闲聊):https://aclanthology.org/I17-1099/
-
Persona-Chat(英文个性化闲聊):https://aclanthology.org/D18-1230/
-
中文闲聊语料(豆瓣 / 微博):https://github.com/rockyzhengwu/Chinese-Dialog-Corpus
任务型对话
-
MultiWOZ 2.1/2.4(英文多领域任务型):https://aclanthology.org/W18-5041/
-
SGD(英文大规模多领域):https://aclanthology.org/2020.emnlp-main.760/
-
中文 MultiWOZ(中文多领域任务型):https://github.com/ConvLab/ConvLab-3/blob/main/data/README.md
-
中文智能客服语料(银行 / 电商):https://github.com/PaddlePaddle/PaddleNLP/tree/develop/datasets
检索式对话
-
Ubuntu Dialogue Corpus(英文检索闲聊):https://aclanthology.org/D15-1299/
-
Douban Conversation Corpus(中文检索闲聊):https://github.com/MarkWuNLP/DoubanConversationCorpus
多模态对话
-
Visual Dialog v1.0/2.0(英文图文对话):https://aclanthology.org/C17-1086/
-
中文图文对话语料:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/datasets/visual_dialog

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 4
4 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)