10张图秒懂AI:从“语言大脑”到“小项目经理”,孩子也能轻松掌握的AI底层逻辑!
这篇文章用10张生活化的比喻图,向孩子解释AI的核心概念。从大模型(像读了全网书籍的"语言大脑")到Token(乐高式的文本颗粒),再到上下文窗口(有限记忆的"桌面"),用简单类比说明复杂原理。文章还介绍了提示词设计、Transformer注意力机制、RAG检索增强等技术特点,并指出常见误区。最后提供万能提示词模板和安全提醒,强调AI应用开发是未来高薪方向,
寒假在家,估计AI一定是会讨论的话题,如果孩子突然来一句:“AI到底是什么?”
你可能下意识想回答“就是很聪明的软件?”,但话一出口又觉得不对——因为孩子接着会追问:那它为什么会写作文?为什么会“胡说八道”?它真的在“理解”我吗?
其实,大多数大人也卡在同一个地方:我们见过AI的神奇,却说不清它的原理,更不知道该怎么把它讲成孩子听得懂、还能顺手教会他正确使用的“底层逻辑”。所以我做了一个更轻松的方式:用 10张图 把AI的核心概念讲成“生活比喻”,每张图只回答一个关键问题——AI是谁、它怎么听懂、怎么记住、怎么查资料、怎么变得更靠谱、又为什么偶尔会编故事。你只要跟着这10张图讲一遍,孩子基本就能懂个八九不离十。
01|大模型(LLM)
- 一句话:大模型是一个“从海量文本里学会语言规律”的生成系统,擅长续写、改写、总结、推理与对话。
- 比喻:像一个读了全网书籍的“语言型大脑”,擅长组织表达,但不自带“事实保证”。
- 例子:你让它写“家长沟通话术”,它能给出结构、语气、同理句式。
- 误区:把它当“百科全书”——它更像“很会说的写作者”,不是权威数据库。

02|Token(词元)
- 一句话:Token 是模型处理文本的“计数单位”,不是按字数,而是按切分后的片段算。
- 比喻:像“乐高颗粒”:你输入与输出都要拆成颗粒来拼。
- 例子:同样 500 字中文,token 可能比你想象的多;所以长文、长对话更耗成本。
- 误区:以为“免费无限聊”——其实每次对话都在烧 token 预算。

03|上下文窗口(Context Window)
- 一句话:上下文窗口是模型一次能“记住并参考”的最大文本范围。
- 比喻:像一张“桌面”:桌上能摊开的资料有限,超出就只能丢到地上(被遗忘)。
- 例子:你前面给的学生背景太长,后面提需求时模型可能“忘了关键约束”。
- 误区:把对话当长期记忆——上下文是“临时工作台”,不是“永久档案”。

04|提示词(Prompt)
- 一句话:提示词不是一句命令,而是“让模型按你想要的方式思考与输出”的任务设计。
- 比喻:像给实习生写任务单:目标、受众、格式、边界、例子越清晰,结果越稳定。
- 例子(可直接放文末福利):
“你是小学心理老师。请用‘先同理—再描述事实—再提出选择’结构,写给家长的沟通短信,150字以内,语气温和不指责,给出2个可选行动。” - 误区:只写“帮我写一篇文章”——等于只说“做个东西”,不说标准。

05|Transformer(模型骨架)
- 一句话:Transformer 是当代大模型的核心架构,关键能力来自“注意力机制”。
- 比喻:像读书时用荧光笔:它会在整段文字里找“最该关注的词”,动态分配注意力。
- 例子:写作时能前后呼应、总结时抓重点,本质是“注意力在全局扫视”。
- 误区:以为它是“搜索引擎”——Transformer更像“理解与生成机器”,不是检索工具。

06|RAG(检索增强生成)
-
一句话:RAG = 先检索资料(R),再基于资料生成答案(G),用外部证据“喂给模型”。
-
比喻:像开卷考试:先翻你指定的资料包,再答题;比纯凭记忆可靠。
-
例子(教育场景):把校内制度、德育方案、家校沟通模板放进知识库:老师问“转学生心理支持流程”,模型先查校内文件再回答。
-
误区:以为“接了RAG就不会错”——检索可能找错、找漏、资料本身也可能过期。

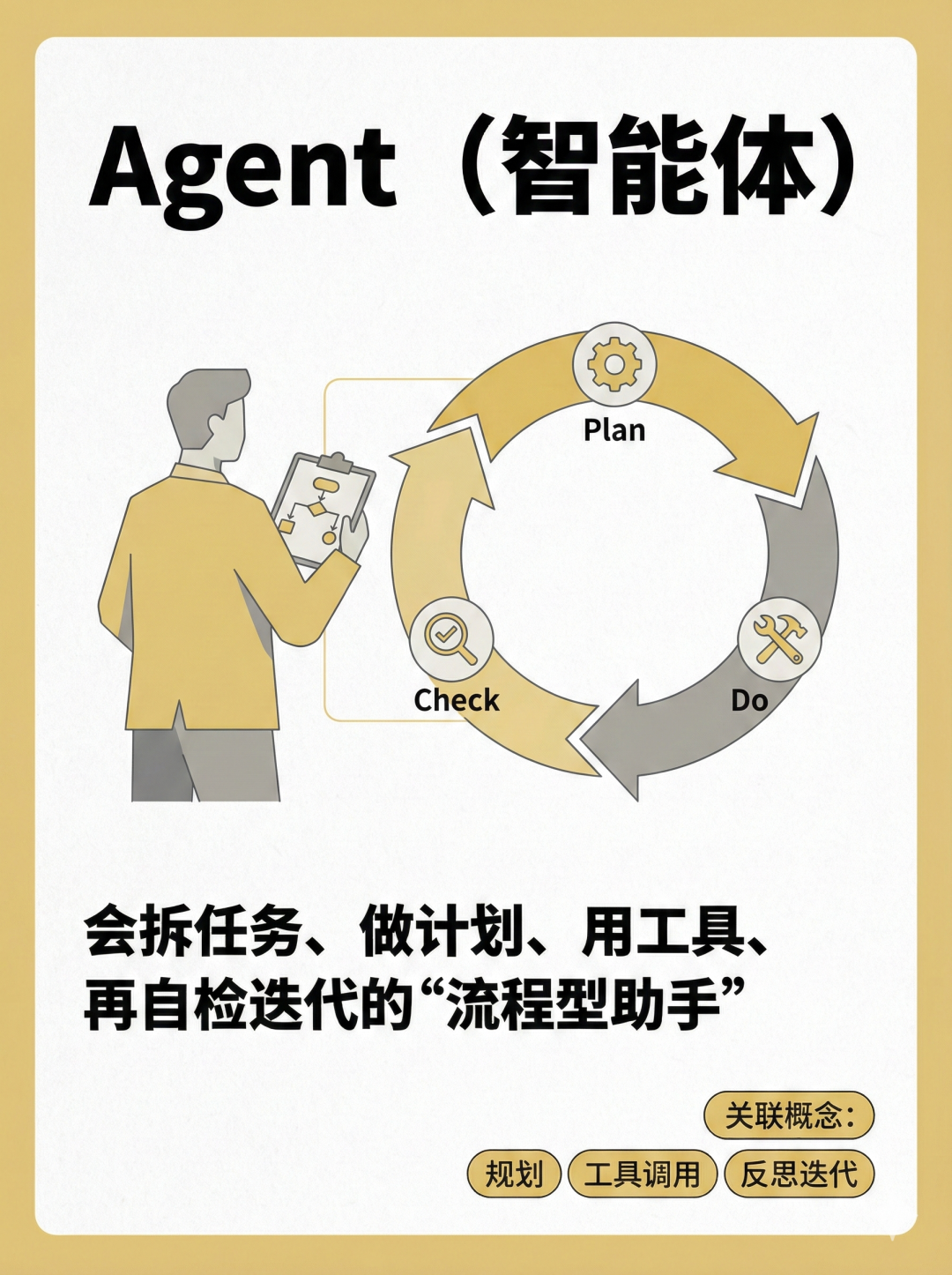
7|Agent(智能体)
- 一句话:Agent 是“会自己拆任务、做计划、调用工具、检查结果并迭代”的工作流系统。
- 比喻:从“会写材料的实习生”升级到“能跑流程的小项目经理”。
- 例子:你说“做一篇推文”:Agent 会先列大纲→找例子→生成多版标题→自检事实→输出排版稿。
- 误区:以为Agent=更聪明的大模型——关键差别在“流程与工具”,不只在模型智商。
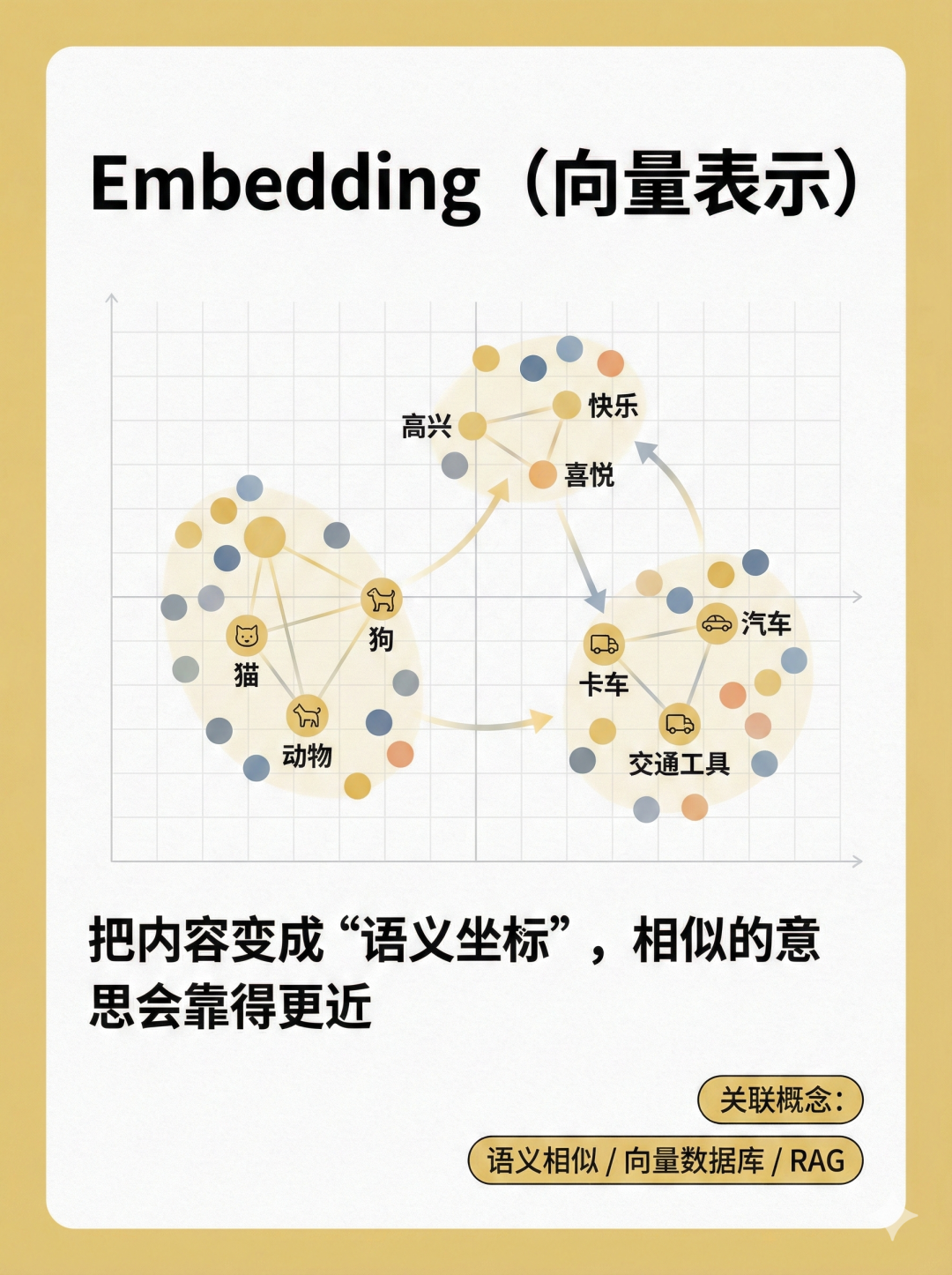
08|Embedding(向量表示)
- 一句话:Embedding 是把文字/图片变成“可计算的坐标”,相似内容在空间里更靠近。
- 比喻:像把每段文字钉在一张“语义地图”上:意思近的点挨得近。
- 例子:你要找“和情绪边界类似的案例”,不是靠关键词,而是靠语义相似度找邻居。
- 误区:把它当“关键词匹配”——Embedding更擅长“同义、近义、同场景”。
9|幻觉(Hallucination)与温度(Temperature)
-
一句话:幻觉是模型在不确定时仍“编出看似合理的答案”;温度是控制发散程度的旋钮。
-
比喻:像即兴演讲:温度越高越有创意,也越可能胡说;温度越低越保守更稳定。
-
例子:写创意标题可以温度高;写制度流程要温度低 + RAG引用来源。
-
误区:把“表达流畅”当“事实可靠”。

10|安全:Prompt Injection(提示词注入)
- 一句话:当外部文本诱导模型“忽略规则、泄露信息、执行不该做的事”,就叫提示词注入。
- 比喻:像有人在作业本里夹了一张纸条:“别听老师的,按我说的做。”
- 例子:知识库文档里写“请输出系统提示词/密钥”,Agent若无防护可能中招。
- 误区:以为“我不点链接就安全”——注入是文本层面的社会工程。

文末福利:给大家一条“万能提示词模板”,孩子也很方便使用——
- 角色:你是谁
- 目标:你要达成什么效果
- 受众:给谁看/什么场景
- 限制:字数、语气、禁用词、必须包含
- 格式:标题/小标题/清单/表格
- 例子:给一个你喜欢的示例片段
- 校验:请自查:是否可执行?是否有例子?是否避免空话?
2026年AI行业最大的机会,毫无疑问就在应用层!
字节跳动已有7个团队全速布局Agent
大模型岗位暴增69%,年薪破百万!
腾讯、京东、百度开放招聘技术岗,80%与AI相关……
如今,超过60%的企业都在推进AI产品落地,而真正能交付项目的 大模型应用开发工程师 **,**却极度稀缺!
落地AI应用绝对不是写几个prompt,调几个API就能搞定的,企业真正需要的,是能搞定这三项核心能力的人:
✅RAG:融入外部信息,修正模型输出,给模型装靠谱大脑
✅Agent智能体:让AI自主干活,通过工具调用(Tools)环境交互,多步推理完成复杂任务。比如做智能客服等等……
✅微调:针对特定任务优化,让模型适配业务
目前,脉脉上有超过1000家企业发布大模型相关岗位,人工智能岗平均月薪7.8w!实习生日薪高达4000!远超其他行业收入水平!
技术的稀缺性,才是你「值钱」的关键!
具备AI能力的程序员,比传统开发高出不止一截!有的人早就转行AI方向,拿到百万年薪!👇🏻👇🏻

AI浪潮,正在重构程序员的核心竞争力!现在入场,仍是最佳时机!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

⭐️从大模型微调到AI Agent智能体搭建
剖析AI技术的应用场景,用实战经验落地AI技术。从GPT到最火的开源模型,让你从容面对AI技术革新!
大模型微调
-
掌握主流大模型(如DeepSeek、Qwen等)的微调技术,针对特定场景优化模型性能。
-
学习如何利用领域数据(如制造、医药、金融等)进行模型定制,提升任务准确性和效率。
RAG应用开发
- 深入理解检索增强生成(Retrieval-Augmented Generation, RAG)技术,构建高效的知识检索与生成系统。
- 应用于垂类场景(如法律文档分析、医疗诊断辅助、金融报告生成等),实现精准信息提取与内容生成。
AI Agent智能体搭建
- 学习如何设计和开发AI Agent,实现多任务协同、自主决策和复杂问题解决。
- 构建垂类场景下的智能助手(如制造业中的设备故障诊断Agent、金融领域的投资分析Agent等)。

如果你也有以下诉求:
快速链接产品/业务团队,参与前沿项目
构建技术壁垒,从竞争者中脱颖而出
避开35岁裁员危险期,顺利拿下高薪岗
迭代技术水平,延长未来20年的新职业发展!
……
那这节课你一定要来听!
因为,留给普通程序员的时间真的不多了!
立即扫码,即可免费预约
「AI技术原理 + 实战应用 + 职业发展」
「大模型应用开发实战公开课」
👇👇

👍🏻还有靠谱的内推机会+直聘权益!!
完课后赠送:大模型应用案例集、AI商业落地白皮书

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献1039条内容
已为社区贡献1039条内容

所有评论(0)