N8N工作流详解① | 打造你的专属 AI 知识库对话助手(实现RAG检索增强)
本工作流是一个 AI 驱动的多意图客户支持聊天机器人,基于 n8n LangChain 节点构建。系统通过 Webhook 接收用户消息,经 LangChain Agent 进行意图识别后,自动路由到对应的处理模块。无论是查询订单状态、寻求产品推荐,还是提交售后工单,均可在一个工作流中完成闭环。
本系列的第一篇,来拆解一个用N8N打造AI知识库对话助手的案例,详细地址见:https://www.n8nzh.com/workflows/
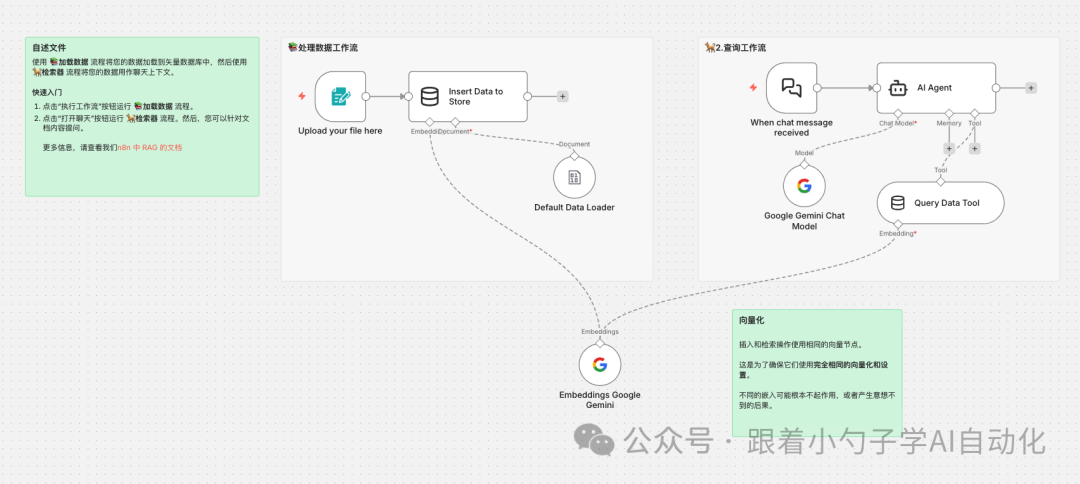
架构概览
这是一个基于 n8n + LangChain 构建的 个人知识库 RAG(检索增强生成)系统,采用双工作流设计:数据处理流程(📚 加载数据)与查询流程(🐕 检索问答)共用同一个 In-Memory 向量存储,确保向量化一致性。
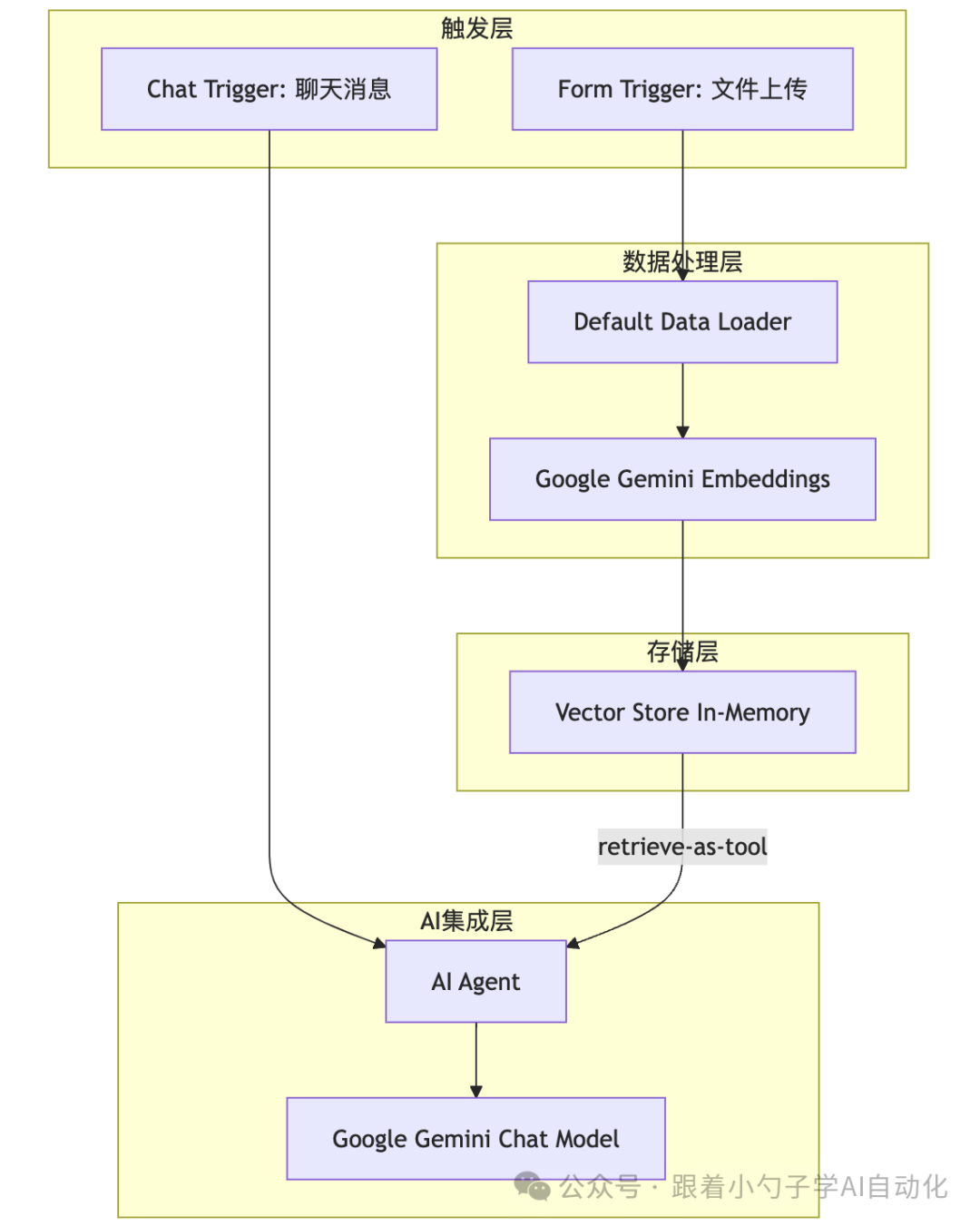
技术层级划分
|
层级 |
节点组成 |
功能描述 |
|---|---|---|
| 触发层 |
Form Trigger / Chat Trigger |
接收用户上传的文件或聊天消息 |
| 数据处理层 |
Default Data Loader / Embeddings |
文档加载、文本分块、向量嵌入 |
| 存储层 |
Vector Store In-Memory |
向量数据库存储与检索 |
| AI 集成层 |
AI Agent / Gemini Chat Model |
LLM 推理与工具调用 |
复杂度量化
-
技术难度:⭐⭐⭐☆☆(3 星)
-
涉及 LangChain 节点封装,无复杂 Code 节点或正则匹配
-
核心逻辑已由 LangChain 节点内部处理
-
-
配置耗时:约 30-45 分钟
- 主要耗时在 API 凭证配置与向量存储理解
-
适用人群:n8n 初学者 / 需要私有知识库的個人用户
痛点反向推导
该工作流解决了两个核心痛点:
-
私有数据无法被 LLM 访问 — 通过向量存储将文档转化为可检索的语义片段
-
问答系统搭建繁琐 — LangChain 节点封装了 RAG 全链路,降低了技术门槛
数据流转审计
文件输入 (PDF/CSV/TXT)
→ Default Data Loader (文档解析)
→ Google Gemini Embeddings (向量嵌入)
→ Vector Store In-Memory (插入模式)
用户聊天消息
→ Chat Trigger
→ Vector Store In-Memory (检索模式,as-tool)
→ AI Agent (上下文增强回答)
→ Google Gemini Chat Model (LLM 生成)
场景还原
在企业知识管理、个人笔记归档、内容创作辅助等场景中,用户积累了大量 PDF、CSV、TXT 格式的私有文档。传统的 LLM 仅能基于训练数据作答,无法直接访问这些私有内容。RAG(Retrieval-Augmented Generation)技术的出现完美解决了这一困境 — 将文档向量化的同时保留语义检索能力,让 AI 在回答时“看到”用户的私有知识库。
该工作流正是 n8n 生态中 RAG 方案的经典实现:用户上传文档 → 系统自动向量化存储 → 聊天提问时实时检索相关上下文 → LLM 基于上下文生成答案。
架构全景图
节点技术详解
节点 1:Upload your file here(Form Trigger)
-
节点类型:
n8n-nodes-base.formTrigger -
技术实现:通过网页表单接收用户上传的文件,支持
.pdf、.csv、.txt格式。表单数据以二进制形式传递给下游节点。 -
关键配置:
-
接受文件类型:
.pdf, .csv, .txt
-
-
配置建议:表单触发器需手动点击“执行工作流”按钮运行,适合批量导入场景。生产环境可考虑改为 Webhook 触发实现自动化。
节点 2:Default Data Loader
-
节点类型:
@n8n/n8n-nodes-langchain.documentDefaultDataLoader -
技术实现:n8n 封装的 LangChain Document Loader,支持解析多种文件格式并转换为标准 Document 对象(含 page_content 和 metadata)。
-
关键配置:
dataType:binary(处理二进制文件)
-
配置建议:默认配置即可满足 PDF/TXT/CSV 需求。如需处理更多格式(如 Markdown、HTML),需更换为对应的 Loader 节点。
节点 3:Embeddings Google Gemini
-
节点类型:
@n8n/n8n-nodes-langchain.embeddingsGoogleGemini -
技术实现:调用 Google Gemini 的 embedding 模型将文本转换为 768 维向量(具体维度取决于 gemini-embedding-001 模型规格)。这是整个 RAG 系统的核心引擎,向量质量直接决定检索精度。
-
关键配置:
- 凭证:
googlePalmApi(需配置 Google API Key)
- 凭证:
-
配置建议:
-
Gemini 免费额度有限,生产环境建议设置用量告警
-
嵌入向量维度固定,无法自定义调优
-
节点 4:Insert Data to Store(向量存储 - 插入模式)
-
节点类型:
@n8n/n8n-nodes-langchain.vectorStoreInMemory -
技术实现:将嵌入后的文档片段存储到内存向量数据库。使用
memoryKey标识向量存储实例,确保插入和检索操作指向同一个存储空间。 -
关键配置:
-
mode:insert -
memoryKey:vector_store_key
-
-
配置建议:
-
In-Memory 特性:数据存储在内存中,n8n 实例重启后数据丢失
-
如需持久化存储,应替换为
vectorStorePinecone、vectorStoreMilvus等持久化方案
-
节点 5:When chat message received(Chat Trigger)
-
节点类型:
@n8n/n8n-nodes-langchain.chatTrigger -
技术实现:创建一个可交互的聊天界面,接收用户消息并触发工作流。Web 界面通过 n8n 的 external hook 暴露。
-
关键配置:
-
public:true(允许外部访问)
-
-
配置建议:首次使用需点击“打开聊天”按钮激活聊天界面。
节点 6:Query Data Tool(向量存储 - 检索模式)
-
节点类型:
@n8n/n8n-nodes-langchain.vectorStoreInMemory -
技术实现:将向量存储作为 LangChain Tool 暴露给 AI Agent。当用户提问时,Agent 自动判断是否需要调用知识库检索。
-
关键配置:
-
mode:retrieve-as-tool -
toolName:knowledge_base -
toolDescription: “Use this knowledge base to answer questions from the user” -
memoryKey:vector_store_key(必须与插入模式一致)
-
-
配置建议:
-
Tool 描述会影响 Agent 何时调用检索,建议描述清晰
-
检索结果数量可通过配置调整(默认返回 top-k 条)
-
节点 7:AI Agent
-
节点类型:
@n8n/n8n-nodes-langchain.agent -
技术实现:LangChain ReAct Agent,负责意图判断、工具调度和答案生成。Agent 会根据用户问题决定是否调用
knowledge_base工具检索上下文。 -
关键配置:
-
工具列表:已接入
Query Data Tool -
语言模型:
Google Gemini Chat Model
-
-
配置建议:如需更可控的回答风格,可替换为
LinearAgent或添加 System Message 约束。
节点 8:Google Gemini Chat Model
-
节点类型:
@n8n/n8n-nodes-langchain.lmChatGoogleGemini -
技术实现:调用 Google Gemini Pro/Flash 模型进行对话推理。接收 Agent 生成的上下文提示,输出最终回答。
-
关键配置:
- 凭证:
googlePalmApi(与 Embeddings 共用)
- 凭证:
-
配置建议:
-
推荐使用
gemini-1.5-flash以平衡速度与成本 -
确保与 Embeddings 模型来源一致,避免跨模型兼容性問題
-
国内外服务替代方案
|
国外原服务 |
工作流位置 |
推荐国内替代方案 |
技术差异说明 |
|---|---|---|---|
|
Google Gemini API |
Embeddings 节点 + Chat Model 节点 |
智谱 AI (GLM-4)
/ DeepSeek |
智谱 AI 提供 Embedding 和 Chat 完整 API 套餐,DeepSeek 性价比极高,两者均支持 OpenAI 兼容协议 |
|
Google Gemini Embeddings |
Embeddings Google Gemini 节点 |
智谱 AI Text Embedding
/ MiniMax Embedding |
国内 Embedding 服务通常提供 1024-1536 维向量,MiniMax 支持 192 维轻量级嵌入 |
|
Vector Store In-Memory |
向量存储节点 |
Pinecone (国内版)
/ Milvus / Qdrant |
In-Memory 版本仅适合测试,生产环境必须使用持久化向量数据库。Milvus 支持本地部署,数据完全自主可控 |
部署与配置指南
配置要点
-
API 凭证统一管理:Embeddings 和 Chat Model 共用同一个 Google 凭证,确保 API Key 一致
-
memoryKey 必须一致:
Insert Data to Store和Query Data Tool的vector_store_key必须完全匹配,否则检索会失败 -
文件格式限制:当前仅支持
.pdf/.csv/.txt,如需其他格式需更换 Loader 节点
调试策略
-
分段测试:
-
先单独运行“上传文件”分支,验证向量是否成功插入
-
再运行“聊天”分支,观察 Agent 是否正确调用检索工具
-
-
查看执行日志:点击每个节点查看 Input/Output 数据,特别关注:
-
Loader 输出的
page_content是否正确解析 -
Embedding 输出的向量维度是否正确
-
Agent 的 Tool Call 日志确认检索逻辑
-
扩展建议与最佳实践
定制化建议
|
场景 |
修改建议 |
|---|---|
| 电商运营 |
将 CSV 改为商品数据表,Agent 可回答“某 SKU 的库存/价格” |
| 自媒体内容创作 |
接入 Notion 节点同步笔记,Agent 辅助写稿时引用素材 |
| 开发者文档助手 |
接入 Markdown Loader,解答 API 使用问题 |
最佳实践
-
生产环境必做:
-
将
Vector Store In-Memory替换为 Pinecone/Milvus 等持久化方案 -
添加 Error Trigger 节点捕获失败任务并告警
-
-
成本优化:
-
聊天模型切换为
gemini-1.5-flash(免费额度更高) -
限制单次检索结果数量(top_k),减少 Token 消耗
-
-
安全加固:
-
Chat Trigger 改为
public: false,或添加 API Key 验证 -
敏感文档建议私有部署 n8n + 本地向量数据库
-
如果你对该工作流感兴趣,关注本公众号后私信我关键词【工作流解读】获取本系列所有解读的json源文件(持续更新)~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)