大模型评测内幕:数据集、测评维度与榜单猫腻全解析!
本文系统探讨了大语言模型的评测方法,指出当前评测体系包含MMLU、C-Eval等核心数据集,覆盖自然语言理解、知识推理等关键维度。文章揭示了厂商"刷榜"现象,建议应关注模型实际能力而非榜单排名。同时详细介绍了少样本/零样本测试方法及SOTA概念,强调评测应以应用效果为导向。作者认为,当前大模型评测存在过度优化指标的问题,需警惕为追求榜单排名导致模型能力失衡的风险。
文章主要探讨了大型语言模型的评测方法,包括常用的数据集(如MMLU、C-Eval)和测评维度(如自然语言理解、知识、数学计算等)。同时,文章揭示了当前大模型评测中普遍存在的“刷榜”现象,指出厂商公布的榜单往往存在水分,建议关注模型本身能力而非单纯追求榜单排名。此外,还介绍了少样本和零样本测评方法,以及SOTA(state-of-the-art)的概念,强调评测应以实际应用能力为重。
@ 目录
- 一、背景
- 二、数据集
- 三、测评维度
- 四、基准测试
- 五、榜单猫腻
- 六、少样本和零样本
- 七、SOTA
一、背景
-
一方面,不论是软件还是大模型,厂商都需要对其功能有效性进行测试,通过业界相对标准的方式去测,可以看清楚自己产品的真正实力以及和其他竞争产品的差距。另一方面,一些大厂希望通过刷新一些著名榜单,来提升自己产品的知名度和竞争力,比如在大模型之前,比较出名的就是各个数据库厂商,像 TiDB、阿里云的 PolarDB 等等,都会在自己的官方网站上介绍其性能指标,比较出名的基准像 TPC-C、TPC-C、Sysbench 等,最后结论就是比 MySQL 性能提升多少多少这种。不可否认,这确实是一种好的方式。
-
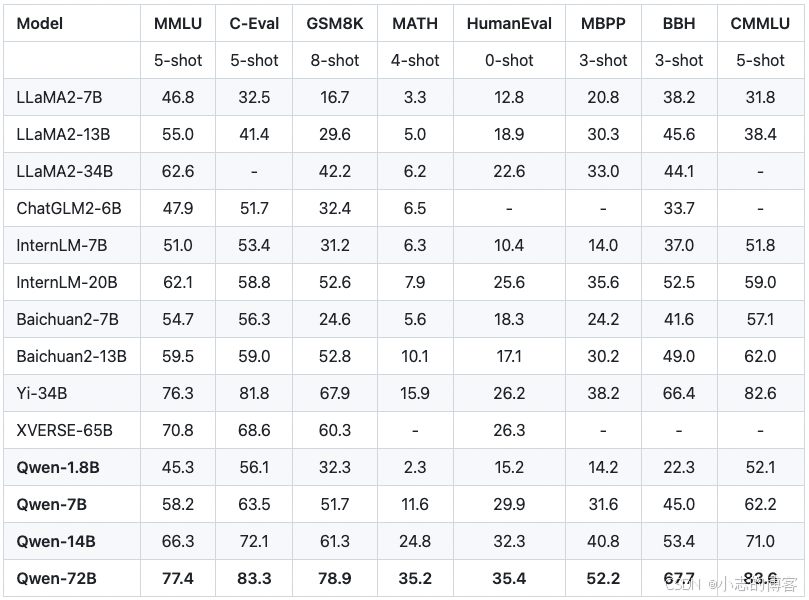
如果你关注各个大模型厂商的网站,一定会经常看到下面这样的评测数据,这是阿里云通义千问介绍页面上放出的一组评测数据。
-
以下是原文内容
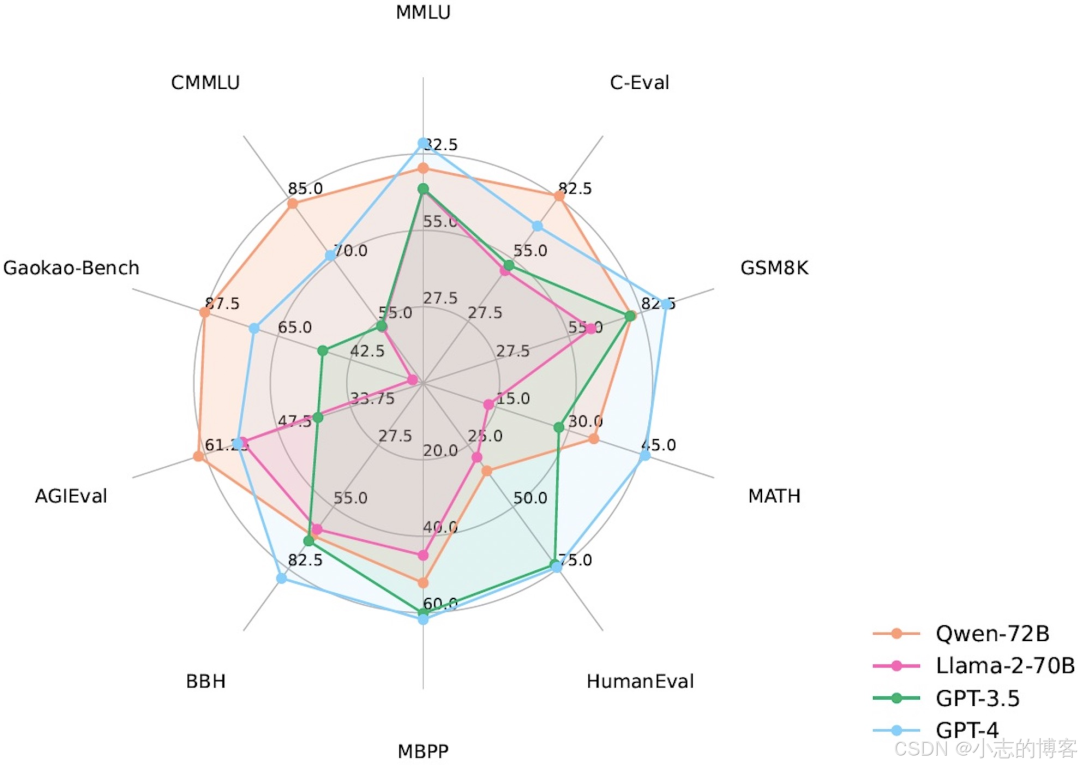
Qwen 系列模型相比同规模模型均实现了效果的显著提升。我们评测的数据集包括 MMLU、C-Eval、 GSM8K、 MATH、HumanEval、MBPP、BBH 等数据集,考察的能力包括自然语言理解、知识、数学计算和推理、代码生成、逻辑推理等。Qwen-72B 在所有任务上均超越了 LLaMA2-70B 的性能,同时在 10 项任务中的 7 项任务中超越 GPT-3.5。
在这里插入图片描述
-
这段描述基本涵盖了大模型评测非常重要的几个方面:数据集、测评维度、测评任务,接下来我们就重点看一下这几个方面。
二、数据集
-
下面是一些常见的数据集,在各个大模型的测评说明里几乎都有它们的身影。

-
我挑选其中支持中文的 C-Eval 来详细介绍下。C-Eval 由上海交大、清华、爱丁堡的几名学生和老师共同完成,是为数不多的中文基础模型评估套件,包含了 13948 个多项选择题,涵盖了 52 个不同的学科和四个难度级别,样本数据如下:
id: 1question: 25 °C时,将pH=2的强酸溶液与pH=13的强碱溶液混合,所得混合液的pH=11,则强酸溶液与强碱溶液 的体积比是(忽略混合后溶液的体积变化)____A: 11:1B: 9:1C: 1:11D: 1:9answer: Bexplanation: 1. pH=13的强碱溶液中c(OH-)=0.1mol/L, pH=2的强酸溶液中c(H+)=0.01mol/L,酸碱混合后pH=11,即c(OH-)=0.001mol/L。2. 设强酸和强碱溶液的体积分别为x和y,则:c(OH-)=(0.1y-0.01x)/(x+y)=0.001,解得x:y=9:1。 -
粗略一看,就是一堆选择题,不过真要做的话,还是有一定难度的,最主要的就是要保证数据质量。要知道像 OpenAI、Google、DeepMind 这些大厂,训练大模型的时候,会重点参考一些数据集,比如 MMLU 和 MATH,所以数据质量对于大模型的训练至关重要。
-
如何保证质量呢?手工处理。尤其是一些 Latex 类型的数学公式及推理过程,因为原始题目大多数来源于 PDF 和 Word 文件,光靠 OCR 来识别准确性肯定有问题,所以很多情况都是作者们手敲整理成章,13000 多道题目,所有和符号相关的内容,一一进行人工验证,不得不感慨那句老话:人工智能这行,有多少人工就有多少智能!
三、测评维度
- 一般来说,通用大语言模型主要关注的就这么几个维度:自然语言理解、知识、数学计算和推理、代码生成、逻辑推理等,当然有的网站分得很细,比如 OpenCompass,评测维度包括基础能力和综合能力两个层级,涵盖了语言、知识、理解、数学、代码、长文本、智能体等 12 个一级能力维度,以及 50 余个二级能力维度,并且根据未来的大模型应用场景还在不断更新和迭代。
四、基准测试
- 基准测试是一种用于评估系统性能的标准化测试方法,不是新概念,前面我讲过,在大模型之前,常见的数据库厂家基本都会对其拳头产品进行基准测试,这是系统比其他竞品厉害的直接证明。说白了就是定义了一套测试方法,当然也配套测试数据集,甚至约定好测试环境、服务器配置,这样能够最大程度地保证公平性,也是这些基准测试最有说服力的地方。
- 在人工智能领域,有几个基准测试网站非常有名,比如 Glue及其增强版 SuperGlue,再比如国产的 Clue、SuperClue,还有OpenCompass。最近发现 OpenCompass 是一个宝藏网站,感兴趣的话你可以研究研究。
五、榜单猫腻
- 一个很有意思的现象,为什么每个大厂公布的榜单都宣称自己的模型是最强的?你可以去看看,大家都会说某某模型在 XXX 能力方面全面超越 GPT-4,或者参数只有 6~8B 的模型,也敢声称能力已经接近 175B 的 GPT-3.5,这么赤裸裸的碰瓷,原因是什么?
- 实际使用下来,不论是用户直接体验还是各种第三方榜单,目前还没有哪个大模型已经超越 GPT-4,所以足以见得这些榜单的水份有多足。所以榜单这东西看看就好了,不要太当真,尤其是厂商自己出的榜单就更不用看了,第三方评测机构出的榜单还是可以参考下的。
- 我个人觉得,不论是数据集还是基准测试,不应该把刷榜单作为目标,而是应该关注模型本身的能力,长期以刷榜单为主,定会造成模型能力的跑偏,因为你会为了榜单指标而过度优化模型,很有可能出现过拟合的情况。
六、少样本和零样本
-
少样本(few-shot)和零样本(zero-shot)是针对 prompt 提出的两种模式,在测评模型能力的时候我们需要考虑这两种情况,针对少样本和零样本我分别举一个例子说明一下。
-
少样本:
以下是中国关于{subject}考试的单项选择题,请选出其中的正确答案。[题目 1]A. [选项 A 具体内容]B. [选项 B 具体内容]C. [选项 C 具体内容]D. [选项 D 具体内容]答案:A ... <- 题目 2 到 4[题目 5]A. [选项 A 具体内容]B. [选项 B 具体内容]C. [选项 C 具体内容]D. [选项 D 具体内容]答案:C[测试题目]A. [选项 A 具体内容]B. [选项 B 具体内容]C. [选项 C 具体内容]D. [选项 D 具体内容]答案:<模型从此处生成> -
就是让模型在推理前,先学习一下回答的模型,相当于给模型打个样。
-
零样本:
[测试题目]A. [选项 A 具体内容]B. [选项 B 具体内容]C. [选项 C 具体内容]D. [选项 D 具体内容]答案:<模型从此处生成> -
实际就是把示例去掉,直接问答。一般来说,预训练阶段的模型 few-shot 的效果总是会比 zero-shot 好一些,但是经过指令微调之后的模型,且指令微调没有 few-shot 数据的话,很可能 zero-shot 会更好。few-shot 面向开发者,可以增强模型上下文学习的能力,zero-shot 面向用户,因为用户很少会去写样本。
七、SOTA
- 最后说一个有意思的词 SOTA,全称「state-of-the-art」,用于描述机器学习中取得某个任务上当前最优效果的模型。例如图像分类任务,某个模型在常用的数据集(如 ImageNet)上取得了当前最先进的性能表现,我们就可以说这个模型达到了 SOTA,所以这是一个很有意思的词,我感觉就像 yyds 一样,可以用在各种场合,不论是技术还是方法,你能形容得出来,并且在某一方面达到业界领先,你就可以说达到了 SOTA。
2026年AI行业最大的机会,毫无疑问就在应用层!
字节跳动已有7个团队全速布局Agent
大模型岗位暴增69%,年薪破百万!
腾讯、京东、百度开放招聘技术岗,80%与AI相关……
如今,超过60%的企业都在推进AI产品落地,而真正能交付项目的 大模型应用开发工程师 **,**却极度稀缺!
落地AI应用绝对不是写几个prompt,调几个API就能搞定的,企业真正需要的,是能搞定这三项核心能力的人:
✅RAG:融入外部信息,修正模型输出,给模型装靠谱大脑
✅Agent智能体:让AI自主干活,通过工具调用(Tools)环境交互,多步推理完成复杂任务。比如做智能客服等等……
✅微调:针对特定任务优化,让模型适配业务
目前,脉脉上有超过1000家企业发布大模型相关岗位,人工智能岗平均月薪7.8w!实习生日薪高达4000!远超其他行业收入水平!
技术的稀缺性,才是你「值钱」的关键!
具备AI能力的程序员,比传统开发高出不止一截!有的人早就转行AI方向,拿到百万年薪!👇🏻👇🏻

AI浪潮,正在重构程序员的核心竞争力!现在入场,仍是最佳时机!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

⭐️从大模型微调到AI Agent智能体搭建
剖析AI技术的应用场景,用实战经验落地AI技术。从GPT到最火的开源模型,让你从容面对AI技术革新!
大模型微调
-
掌握主流大模型(如DeepSeek、Qwen等)的微调技术,针对特定场景优化模型性能。
-
学习如何利用领域数据(如制造、医药、金融等)进行模型定制,提升任务准确性和效率。
RAG应用开发
- 深入理解检索增强生成(Retrieval-Augmented Generation, RAG)技术,构建高效的知识检索与生成系统。
- 应用于垂类场景(如法律文档分析、医疗诊断辅助、金融报告生成等),实现精准信息提取与内容生成。
AI Agent智能体搭建
- 学习如何设计和开发AI Agent,实现多任务协同、自主决策和复杂问题解决。
- 构建垂类场景下的智能助手(如制造业中的设备故障诊断Agent、金融领域的投资分析Agent等)。

如果你也有以下诉求:
快速链接产品/业务团队,参与前沿项目
构建技术壁垒,从竞争者中脱颖而出
避开35岁裁员危险期,顺利拿下高薪岗
迭代技术水平,延长未来20年的新职业发展!
……
那这节课你一定要来听!
因为,留给普通程序员的时间真的不多了!
立即扫码,即可免费预约
「AI技术原理 + 实战应用 + 职业发展」
「大模型应用开发实战公开课」
👇👇

👍🏻还有靠谱的内推机会+直聘权益!!
完课后赠送:大模型应用案例集、AI商业落地白皮书

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献799条内容
已为社区贡献799条内容

所有评论(0)