初遇Open AI,深入了解大语言模型训练范式
2025年标志着大模型训练哲学的历史性跨越——传统的"预训练+SFT+RLHF"三段式训练法已被RLVR(可验证奖励强化学习)彻底改写。本文以GPT-3模型和Llama 3.1模型为典型案例,深入探究LLM模型训练范式的核心差异与演进路径。
核心范式转移:从"概率模仿"到"逻辑推理"
2025年标志着大模型训练哲学的历史性跨越。OpenAI的卡帕西在年度回顾中指出,传统的"预训练+SFT+RLHF"三段式训练法已被RLVR(可验证奖励强化学习) 彻底改写。
以下用GPT 3模型与Llama 3.1模型为例,探究LLM模型训练范式:
LLM大语言模型的训练过程
| GPT 3 范式:闭源路径的激进创新 | Llama 3.1 范式:开源路径的效率革命 |
|---|---|
| (pre-train阶段) 1、Pretrain |
(pre-train阶段) 1、Pretrain |
| (post-train阶段) 2、SFT(Supervised Fine-Tuning) 3、RM(Reward Model) 4、PPO(Proximal Policy Optimization) |
(post-train阶段) 2、RM(Reward Model) 3、RS(Rejection Sampling) 4、SFT(Supervised Fine-Tuning) 5、DPO(Direct Preference Optimization) |
后续的Llama 4模型、qwen模型、DeepSeek V3、使用的范式框架跟GPT 3范式大同小异。
GPT 3 模型训练阶段
从普通人到国家级运动员:用成长视角读懂GPT-3的训练智慧
上一章[[初探AI世界-CSDN博客]]说到了,学习AI最快的方法就是把AI当人看。
当我们把LLM(大语言模型)的训练过程,想象成"一个成年人成长为国家级运动员"的成长历程,那些看似复杂的深度学习技术突然变得鲜活起来。今天,就让我们通过这个生动的比喻,真正理解GPT-3的训练架构。
第一阶段:从普通人到运动员——预训练(Pretraining)
想象一个成年人,他可能会简单的跑步、打球,但没有接受过任何专业训练。就像刚初始化的LLM模型,有基本的计算能力,但没有任何专业知识。
LLM模型内部是大量数学公式,最开始的参数是随机初始化的。
这个阶段是整个阶段中,消耗时间最长、最大量级的数据、服务器显卡算力、花钱最多的阶段。
预训练阶段就像是"海量基础训练":
在这个阶段,模型会"阅读"海量文本数据——相当于运动员进行大量的基础体能训练:
- (大规模无监督学习)每天学习识别文字中的模式和规律 ----> 运动员每天跑步、跳高、打篮球等;
- (自回归生成目标训练)理解语言的基本结构和语法 ----> 运动员对于每个运动都设立目标进行训练,如每天跑50公里、跳高100次等;
- (建立语言理解的基础能力)积累各个领域的常识性知识 ----> 运动员对运动拉伸、饮食、负重、跑步、篮球、足球、羽毛球、长短跑等运动都会进行了解,并且去相应训练。
这就像是运动员每天跑100公里,不是为了提高某个专项技能,而是为了让身体适应运动的节奏,建立基本的体能储备。
LLM模型,最开始什么都不会,怎么学?
训练数据的级别:
m(百万):1000000
b(十亿):1000000000
t(万亿):1000000000000
GPT 3 使用了 500B Tokens,现代模型Llama 3.1 使用了15t Tokens。
中国常用汉字为3000 ~ 5000字
全部汉字为80000 ~ 100000字
并且大部分字都会有词的组合,如:人的词(人民、人类)相似度就高,“人空”这样的词相似度就低。
比如预训练数据是一段话,让LLM去学:
人类简史:从动物到上帝
尤瓦尔·赫拉利创作的历史类著作
《人类简史:从动物到上帝》是[以色列] 尤瓦尔·赫拉利创作的历史类著作,于2012年首次出版,林俊宏 译。
作者讲述了人类从石器时代至21世纪的演化与发展史,并将人类历史分为四个阶段:认知革命、农业革命、人类的融合统一与科学革命。
内容简介
《人类简史:从动物到上帝》以演化生物学的角度介绍了人类的历史。赫拉利认为生物学限定了人类活动的极限,而文化则塑造了在极限以内
所发生的事情,历史学科则是对文化变迁的记录。《人类简史:从动物到上帝》将从石器时代至今天智人的演化历史分为了四个阶段:认知革
命(约公元前70000年,智人演化产生了想象力,出现能够描述故事的语言)、农业革命(约公元前12000年,农业开始发展,智人开始驯化
动植物)、人类的融合统一(人类政治组织逐渐融合统一为一个“全球帝国”)、科学革命(约公元1500年至今,出现了现代科学)。
预训练阶段:模型不需要真的输出“下一个字” ,而是输出所有“候选字”的概率清单:
人 人类
的:13% 的:15%
在:12% 在:11%
家:12% 是:10%
类:10% 对:10%
工:9% 不:8%
力:8% 社:6%
多:8% 和:6%
与:6% 历:6%
是:5% 可:5%
不:4% 最:4%
和:3% 文:3%
... ...
通过点乘把字的概率(P),计算成每个段落联合概率。
段落联合概率:让一个模型,能一字不落的生成整个段落的概率
P(人)、P(类)、P(简)、P(史)、P(:)、P(从)、P(动)、P(物)、P(到)、P(上)、P(帝)、P(\n)、P(尤)、P(瓦)、
P(尔)、P(·)、P(赫)、P(拉)、P(创)、P(作)、P(的)、P(历)、P(史)、P(类)、P(著)、P(作)、P(\n)......
LLM模型是基于预训练数据的文字,进行瞎蒙,看哪个字概率高,会给出多个段落,每个段落都有联合概率,说简单点,就是LLM模型会把概率高的段落续写出来。
但是段落联合概率都比较低,就会叫LLM模型进行调整。
段落少的话,LLM模型可以直接处理,会如下图所示: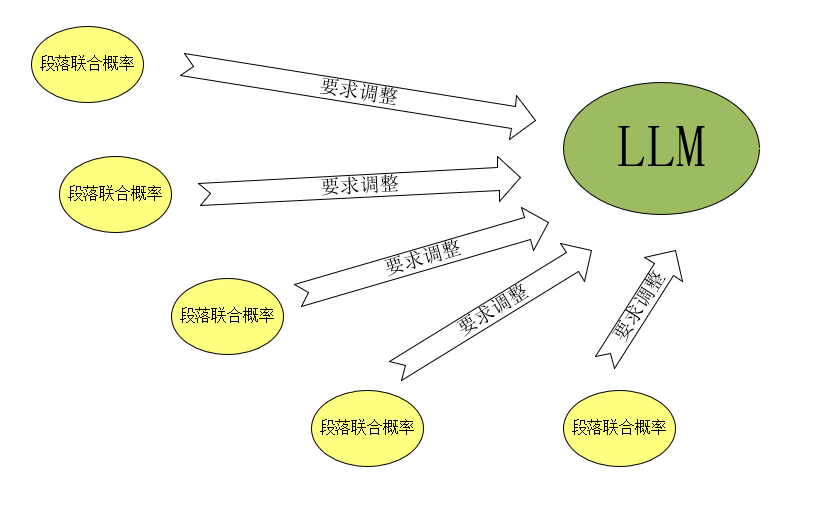
但是通常一个模型都有上十亿、甚至上百亿的段落概率,如下图所示: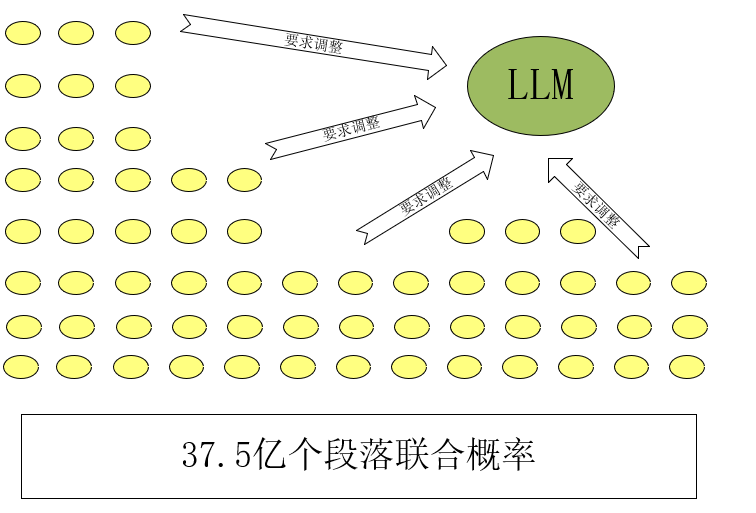
LLM模型肯定是处理不过来的,所以每次LLM都会进行迭代,可以更好的去适应调整段落联合概率,把平均的值提高,这就会出现以前A段落联合概率高的值会降低,B段落联合概率低的值会增加。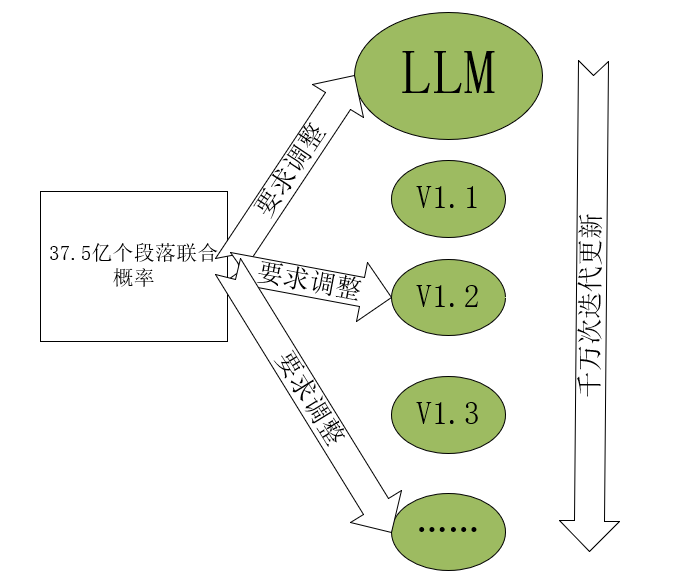
核心结论:预训练模型(Pretrain)说起话来非常像“接话茬” ,并不是在“做任务”。
第二阶段:专业化技能训练——SFT监督微调(Supervised Fine-Tuning)
有了基础体能后,这个"运动员"开始接受专业指导。教练会告诉他正确的跑步姿势、如何合理分配体力、比赛中的战术安排等。
SFT阶段就像是"专项技能培训":
在这个阶段,模型会"微调参数",达到理解问题,以及正确回复——相当于运动员开始接受专业教练的指导,学习正确的技术动作:
- (高质量的示范数据)人工标注指令数据训练 ----> 专业教练提供高质量的训练方法与数据
- (模型学习如何准确响应指令)学习人类偏好的回答方式 ----> 运动员了解训练计划,并且按照专业教练员的计划进行执行
- (提升模型的对齐能力)掌握对话的基本礼仪和逻辑 ----> 运动员按照训练计划进行,并且理解计划中每项的作用。
这相当于运动员开始接受专业教练的指导,学习正确的技术动作,而不是自己随意训练。
但是人都是懒得,所以SFT(有监督得微调训练)应运而生。
自监督:有监督、无监督
使用有标签的数据进行训练,学习过程叫做有监督(Supervised)学习:
商家送货速度棒棒哒! -> 正向
送货速度可太慢了,差评。 -> 负向
“这可太好吃了” “味道确实是真不错” -> 相似
“多吃水果对身体有好处” “痛风病人不要吃海鲜” -> 不相似
使用无标签的数据进行训练,学习过程叫做无监督(Unsupervised)学习。
上面讲过的Pretrain阶段的处理方式,就叫做自监督
为什么有半监督:
Pretrain + SFT 两个阶段组合起来就叫做半监督(不缺数据,但缺标签)
首先预训练模型(Pretrain)说起话来非常像“接话茬” ,并不是在“做任务”。
SFT能让模型学会理解用户想要什么,判断这是对话、分类、推理还是代码生成任务,然后按照任务要求输出合适格式的回答,并且可以在在多轮对话中保持任务连贯性。
简而言之,SFT的核心价值就是任务对齐。
核心结论:通过Pretrain+SFT,我们得到了一个,会做各类任务的模型。但是会做任务,和能优秀的做任务,还是有很大差距。
第三阶段:个性化教练系统——RM奖励模型与PPO训练
掌握了基础技能后,运动员需要不断优化自己的表现。教练会根据每次训练和比赛的表现给出反馈,帮助运动员找到最优的训练方案。
奖励模型(RM,Reward Model):
- 每次教练都会对运动员的表现进行打分
- 学习人类的偏好标准,判断什么是"好"的表现
- 为后续优化提供客观的评价依据
PPO优化(Proximal Policy Optimization,强化学习):
- 就像根据裁判反馈不断调整训练方案
- 通过强化学习找到最优的表现策略
- 持续优化直到达到国家级水平
对应到训练过程:
- 训练奖励模型来预测人类偏好
- 使用PPO算法进行策略优化
- 多轮迭代,不断提升性能
但是当运动员成长遇到瓶颈,训练效果停滞不前时,就需要对"教练系统"进行升级换代。
这就意味着要重新回到第二阶段—— 通过更高质量的指令样本和演示数据,重新训练奖励模型(RM),让"专业教练"的评判标准更加精准和科学。
随后再次进入第三阶段—— 用升级后的RM来指导PPO优化,为运动员制定更有效的训练计划,更准确地把控训练质量。
阶段二和阶段三的反复迭代,形成一个不断优化的闭环:
- 第二阶段完善"教练员升级"(RM训练)
- 第三阶段优化"训练计划"(PPO执行)
通过这种"评估→改进→再评估→再改进"的持续循环,运动员才能突破成长瓶颈,最终进化为真正的国家级运动员。
从训练到竞技:完整的成长闭环
整个训练过程形成了一个完美的成长闭环:
基础体能训练(Pretrain预训练)
↓
专业技能指导(SFT监督微调)
↓↑
个性化优化提升(RM奖励模型+PPO)
↓
国家级运动员表现(最终模型)
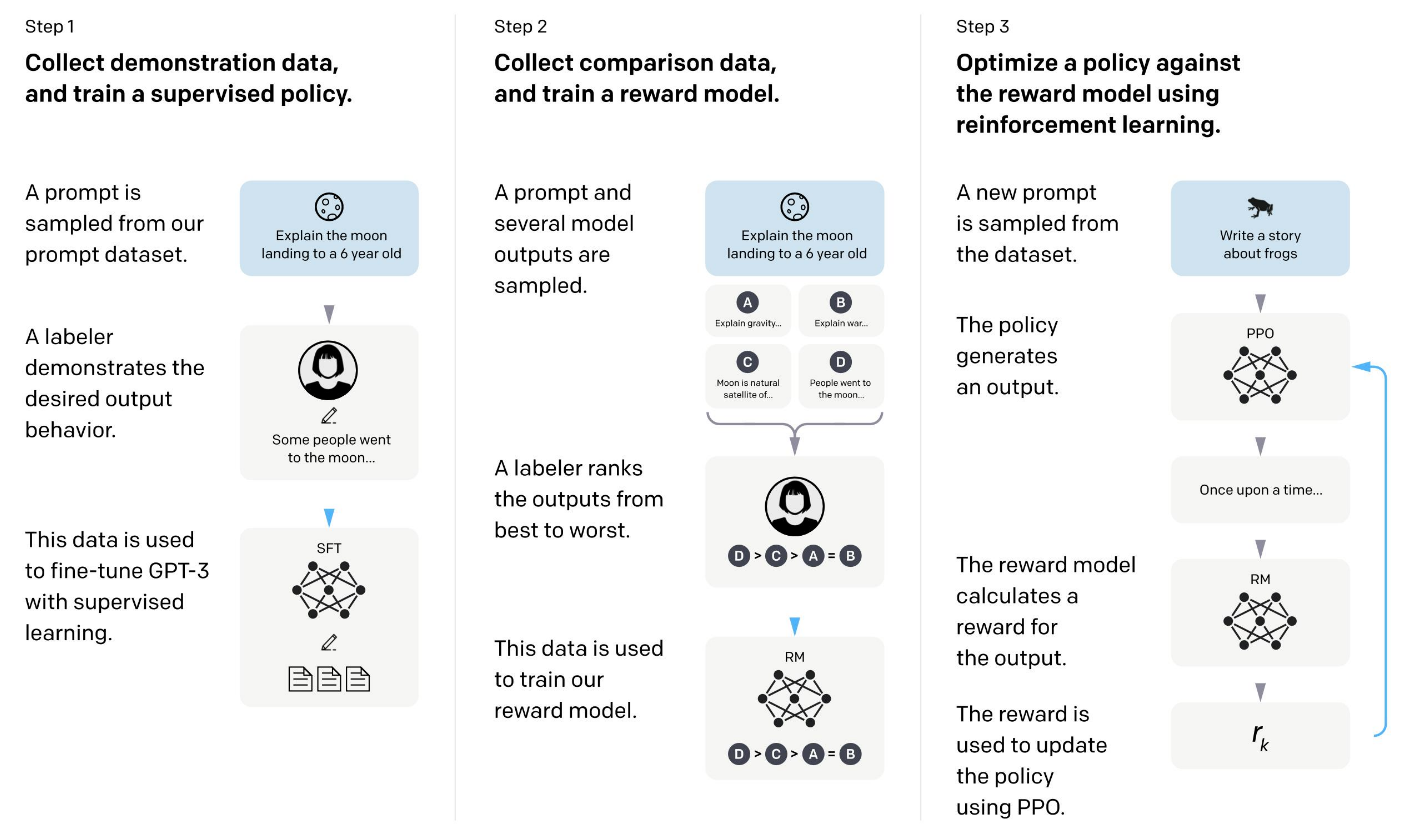
这个闭环对应到GPT-3的训练流程:
- Pretraining:在海量文本上建立语言理解基础
- SFT:学习如何准确响应人类指令
- RM:训练裁判系统来判断回答质量
- PPO:基于反馈持续优化回答策略
下面是OpenAI 对 GPT 3范式训练流程图:
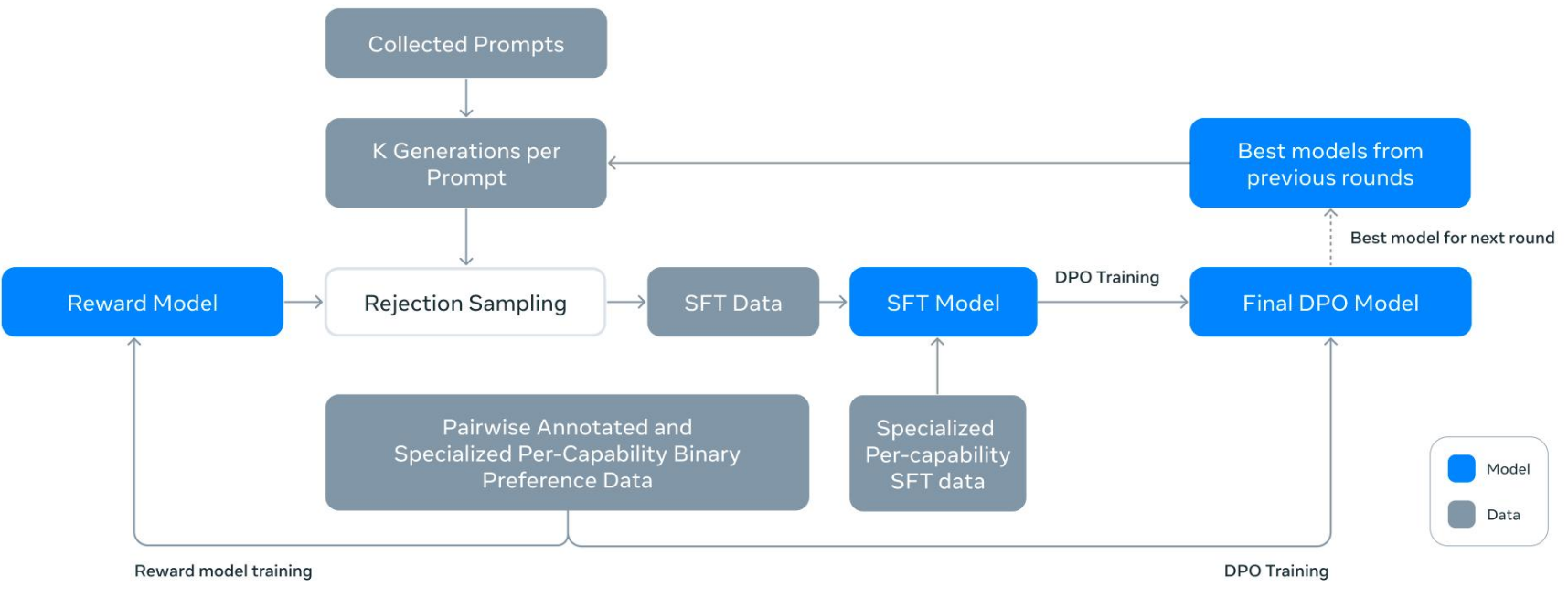
开源模型训练范式
LLM是如何训练出来的

Llama范式训练过程
AI训练与人的成长
理解了GPT-3的训练架构,我们也能获得关于学习的深刻启示:无论是训练AI还是培养人才,核心原理都是相通的
1. 基础决定高度
就像运动员需要扎实的基础体能,AI模型需要大规模的预训练。在学习任何技能时,基础知识的积累决定了你能达到的高度。
2. 指导加速成长
专业教练的价值不在于告诉你"怎么做",而在于纠正你的"错误做法"。SFT阶段的人工指导,让模型快速找到了正确的学习方向。
3. 反馈驱动优化
PPO机制告诉我们:持续改进需要有效的反馈系统。在学习过程中,建立自己的"奖励机制"和"优化策略"至关重要。
4. 循序渐进的科学
从基础到专业再到优化,这是一个科学的成长路径。跳跃式学习往往事倍功半,循序渐进才是王道。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)