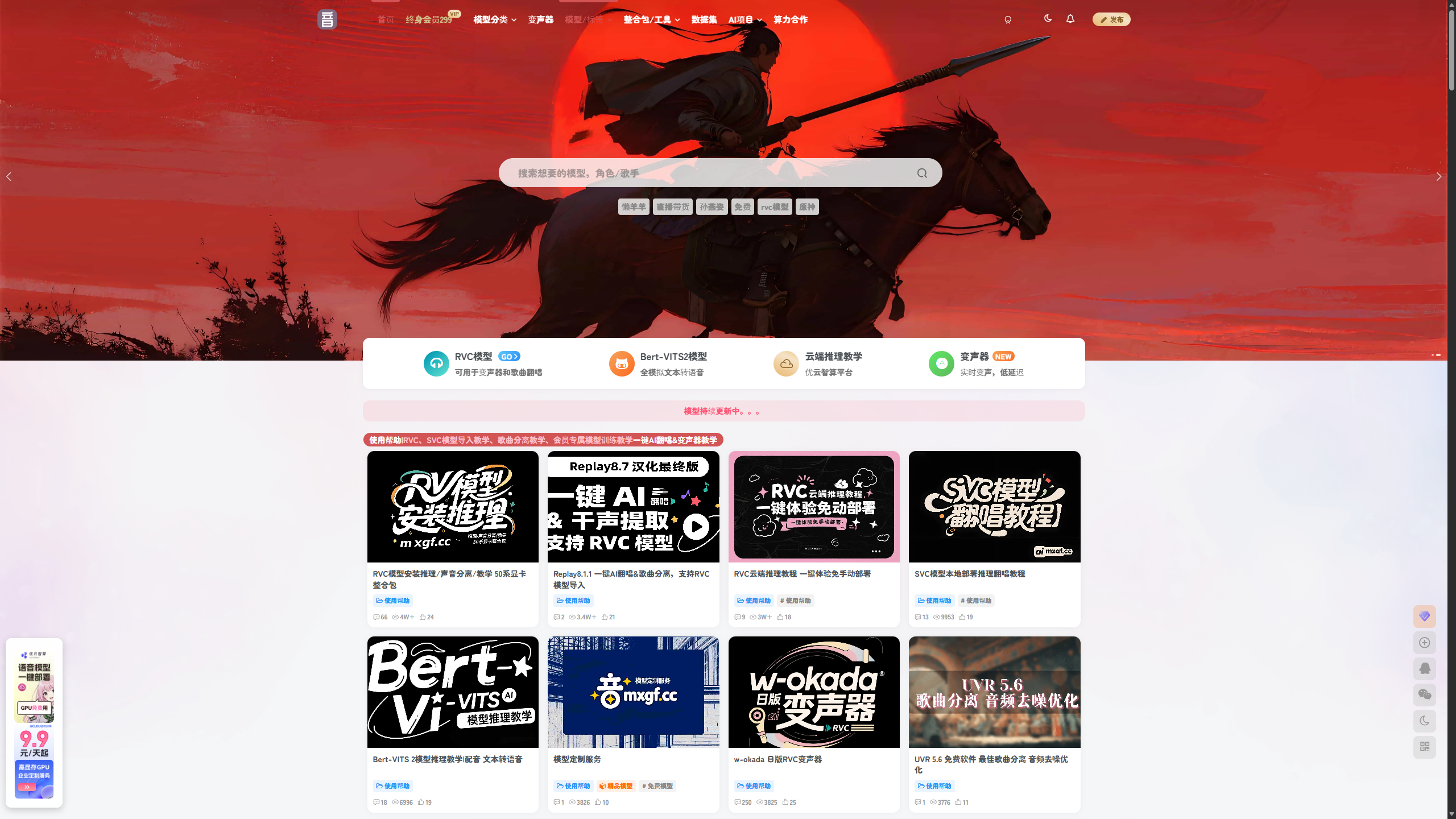
热门 IP 全收录!RVC/SVC 模型下载就上这个站,附完整教程
AI翻唱和实时变声技术正风靡全网,RVC/SVC作为核心技术让动漫角色翻唱、游戏变声成为可能。模型工坊(mxgf.cc)提供600+高质量音色模型,覆盖动漫、影视、网红等热门IP,并配套保姆级教程和全套工具包。文章详解了AI翻唱四步流程:歌曲分离、音色转换、后期合成,以及实时变声配置方法,帮助零基础用户轻松玩转AI语音创作。站点所有模型均经过专业优化,避免电音、底噪等问题,持续更新热门IP模型,是
如今 AI 翻唱、实时变声早已不是技术圈的小众玩法,不管是短视频平台爆火的动漫角色二创翻唱、游戏陪玩圈的百变声线,还是影视解说的定制配音,背后都离不开 RVC/SVC 这两大核心技术。但对绝大多数新手来说,最大的门槛从来不是软件操作,而是找不到高质量、高还原度的音色模型,更没有一套完整、不踩坑的全流程教程。

今天就给大家揭秘一个圈内公认的宝藏模型站点 ——模型工坊(mxgf.cc),全网热门 IP 模型一站式收录,同时附上保姆级的 AI 翻唱、实时变声完整教程,零基础也能从零上手,轻松玩转 AI 语音创作
先搞懂!RVC/SVC 到底是什么?
在开始之前,先把新手最容易混淆的概念讲清楚,避免选错工具、下错模型:
- RVC(Retrieval-based-Voice-Conversion-WebUI)
目前最主流的语音转换框架,核心优势是低延迟实时变声、高还原度歌曲翻唱,也是游戏直播、开黑变声、短视频 AI 翻唱的首选技术。它的核心能力是「音色转换」,能把一段人声 / 歌声无缝替换成目标音色,不支持直接文本转语音。
- SVC(So-VITS-SVC)
主打歌声转换 / 合成,对歌唱的气息、转音、音准细节还原更优,更适合专业的 AI 翻唱二创创作,和 RVC 模型互不通用,需要搭配对应的推理工具使用。
- 补充区分
GPT-SoVITS 等工具主打 TTS 文本转语音,核心是「文字生成配音」,和 RVC/SVC 的「音色转换」功能定位完全不同,新手别搞混。
宝藏站点揭秘!热门 IP 全收录的模型工坊 mxgf.cc
网上零散的模型资源不仅质量参差不齐,还常常伴随缺文件、有底噪、还原度低的问题,而模型工坊能成为圈内首选,核心优势集中在这 3 点:
1. 海量 IP 全覆盖,模型库全品类无死角
站点累计上线超 600 款高质量训练模型,几乎覆盖了全网所有热门 IP,真正做到 “想找的模型这里都有”:
- 二次元动漫:懒羊羊、蜡笔小新、名侦探柯南、赛马娘全角色、原神 / 崩坏星穹铁道全角色、蔚蓝档案、鬼灭之刃等热门动漫 IP,从主角到配角的模型一应俱全;
- 影视游戏:新三国全角色、86 版西游记孙悟空、三角洲行动系列、王者荣耀 / 英雄联盟热门角色,还有麦克阿瑟等网红梗专属配音模型;
- 网红与人声:丁真、旺仔小乔、孙燕姿等热门人声模型,还有 48K 高采样率的陪玩专属变声模型,御姐、萝莉、正太、播音腔全品类声线覆盖,彻底告别传统变声器的电流音、机械感;
- 技术全适配:模型严格区分 RVC/SVC/GPT-SoVITS 三大类,分别适配翻唱、实时变声、配音三大场景,下载就能直接用,无需二次格式转换。
2. 新手极致友好,从入门到精通全免费
对零基础玩家最友好的是,这个站完全不是 “只卖模型”,而是把学习门槛降到了最低:
- 在线试听零盲盒:所有模型都提供干声样本、翻唱效果在线试听,效果好不好一听便知,不用下载后才发现踩坑;
- 保姆级免费教程:首页置顶了全流程免费教程,从 RVC/SVC 软件安装、模型导入、干声分离,到云端推理、本地模型训练,甚至是后期音频处理,图文 + 视频双教学,小白跟着步骤走就能学会;
- 零成本工具包:免费提供 RVC 全版本整合包、UVR5.6 音频分离工具、w-okada 实时变声客户端、音频切片工具等全套创作软件,不用再全网找资源,一站式备齐。
3. 模型质量过硬,专业级优化无坑
站内所有模型都经过了深度优化,从数据集提纯到多轮训练校准,全程手工处理:
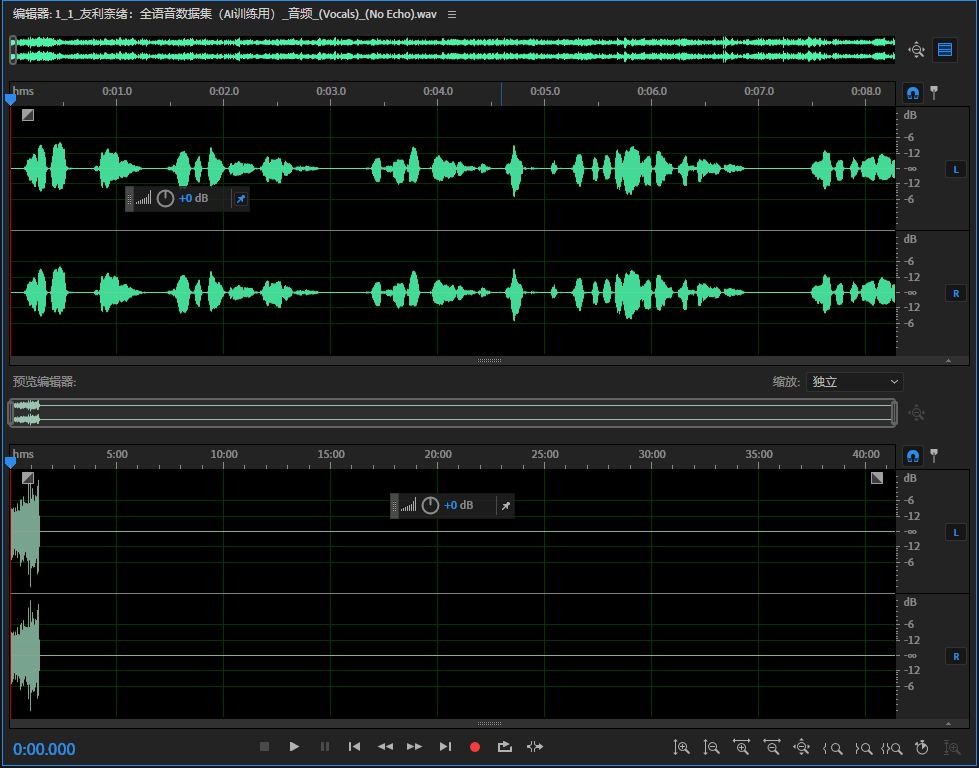
- 音频数据集经过 UVR 去混响、去噪、切片提纯,避免了训练出的模型出现电音、底噪、吐字不清的问题;
- 所有模型均经过多轮效果测试,适配歌曲翻唱、实时变声等不同场景,参数都做了对应优化,新手导入就能直接用,不用反复调参;
- 模型持续更新,紧跟网络热门 IP,第一时间上线新模型,不用自己耗费大量时间和算力训练。
保姆级完整教程!零基础玩转 AI 翻唱 / 实时变声
下面就给大家带来两套最常用的完整教程,一套是短视频爆款 AI 翻唱制作全流程,一套是游戏 / 直播用的实时变声配置教程,全程跟着操作,零基础也能一次成功。
模块一:AI 翻唱全流程教程(RVC 版,零门槛制作爆款作品)
步骤 1:工具与模型准备(一次准备,永久使用)
- 必备工具下载:
- RVC 整合包:在模型工坊内根据自己的显卡(N 卡 / A 卡 / CPU)下载对应版本,解压即用,无需手动配置 Python 环境;

-
- UVR5.6:站点内免费下载,用于分离歌曲的人声和伴奏,是 AI 翻唱的核心工具;
-
- 目标模型:在 mxgf.cc 搜索你想要的 IP,下载对应 RVC 模型文件(.pth 格式)和 index 索引文件。
步骤 2:歌曲分离,提取纯净干声与伴奏
AI 翻唱的核心前提,是拿到无伴奏、无混响的纯净人声干声,这一步用 UVR5 就能完成:
- 先安装 UVR5.5 基础安装包,再安装 5.6 升级补丁,将模型工坊内提供的「UVR-MDXNET_Main」「UVR-De-Echo-Aggressive」两个分离模型,放入软件根目录的
Ultimate Vocal Remover\models文件夹中;
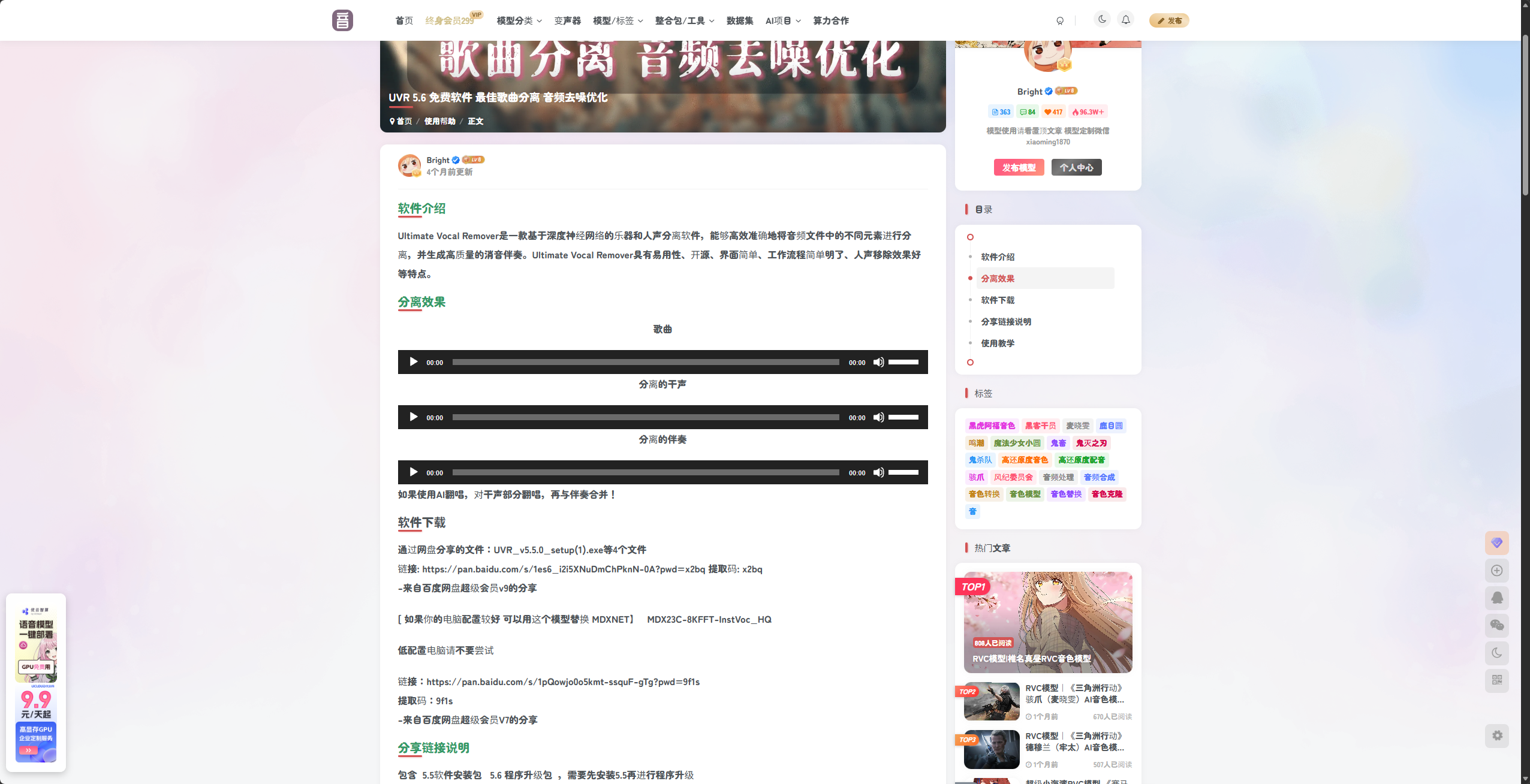
- 打开 UVR 软件,选择「MDX-Net」处理模式,加载「UVR-MDXNET_Main」模型,导入要翻唱的歌曲,勾选「GPU Conversion」加速,选择「Vocals Only」,点击「Start Processing」,处理完成后会得到歌曲的纯净人声干声和伴奏两个文件;
- 再切换到「VR Architecture」模式,加载「UVR-De-Echo-Aggressive」模型,导入刚提取的人声干声,选择「No Echo Only」,再次处理去除干声里的混响和回声,得到最终用于 RVC 推理的纯净干声,伴奏文件妥善保存备用。

步骤 3:RVC 模型导入与音色转换
这一步就是把原唱的人声,转换成目标 IP 的音色,也是整个流程的核心:
- 解压 RVC 整合包,将下载好的.pth 格式模型文件,放入整合包根目录的
assets/weights文件夹;index 索引文件放入logs文件夹内; - 双击整合包内的
go-web.bat启动程序,等待终端加载完成,会自动在浏览器弹出 RVC WebUI 操作界面;
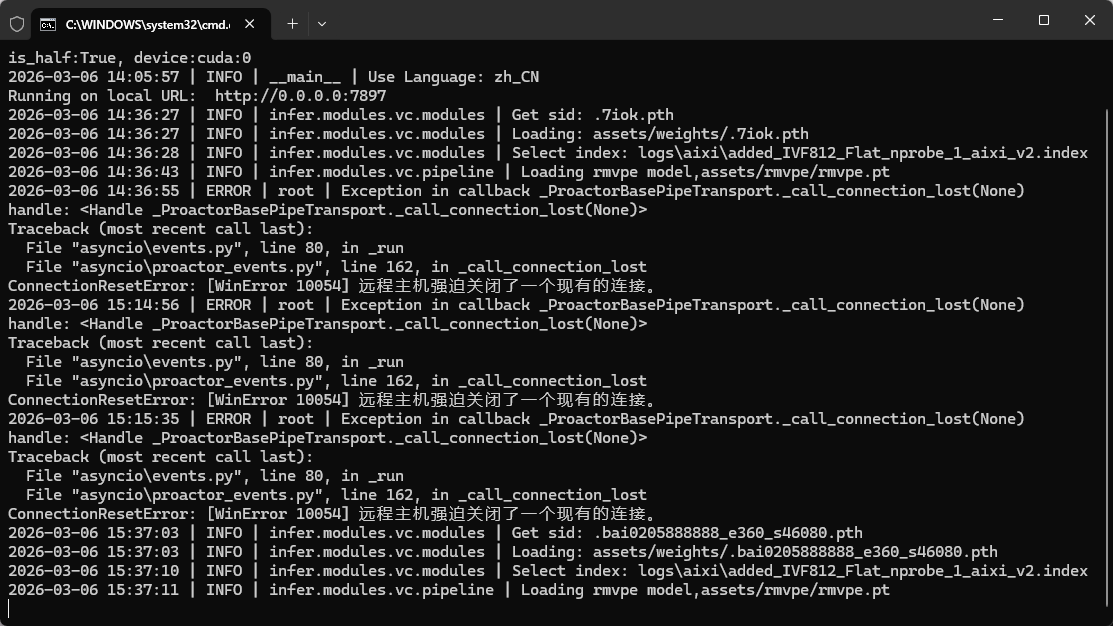
- 进入「模型推理」页面,点击「刷新音色列表」,在下拉菜单中选择你刚刚导入的目标模型;
- 在「输入待处理音频文件路径」中,粘贴上一步处理好的纯净人声干声的本地文件路径;
- 关键参数设置(新手直接抄作业,避坑核心)
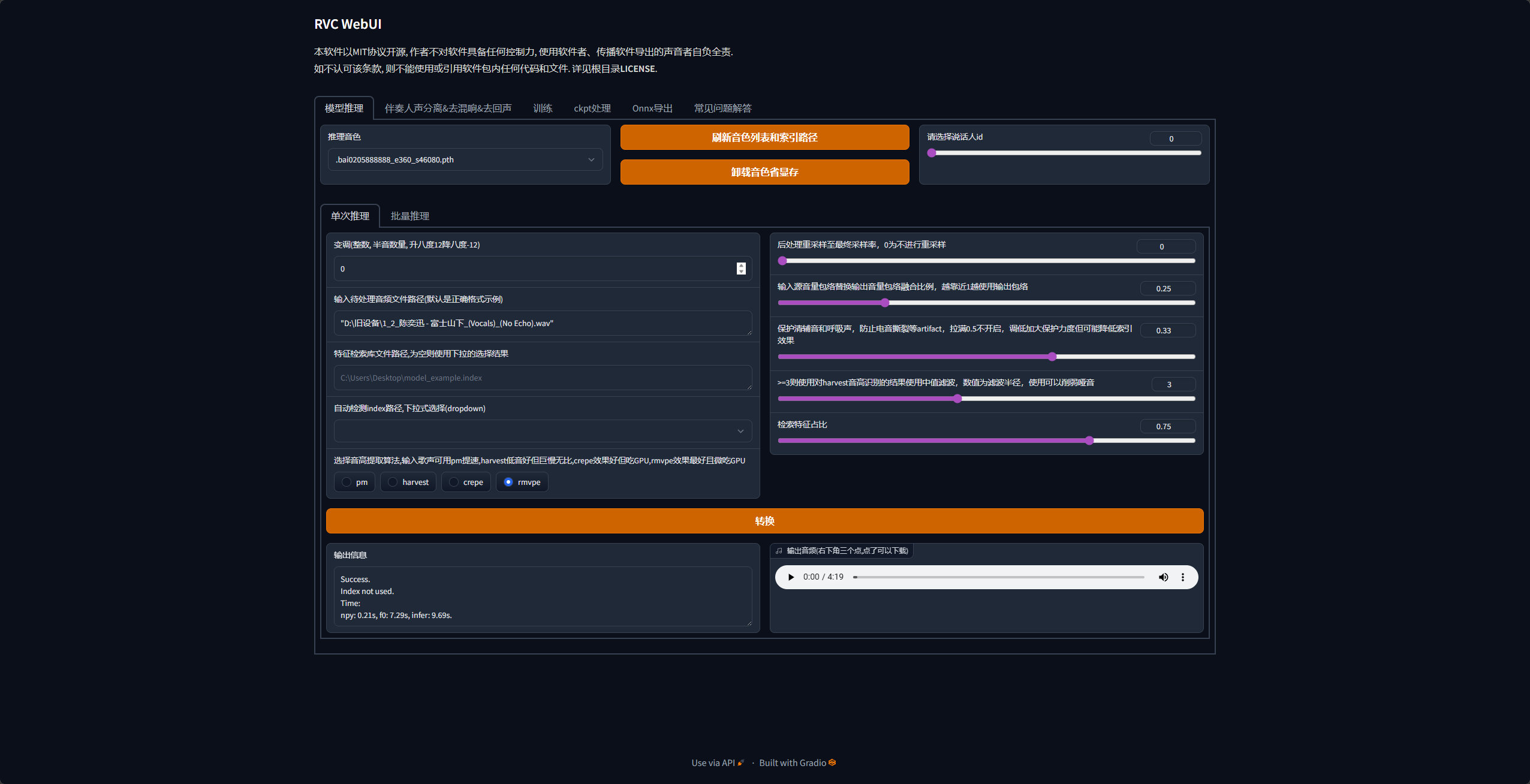
所有参数设置完成后,点击「转换」,等待进度条跑完,即可在线试听转换后的目标音色人声,满意后点击下载保存到本地。
步骤 4:后期合成,生成最终翻唱作品
- 打开剪映、必剪、Adobe Audition 等任意音频剪辑软件,新建多轨项目;
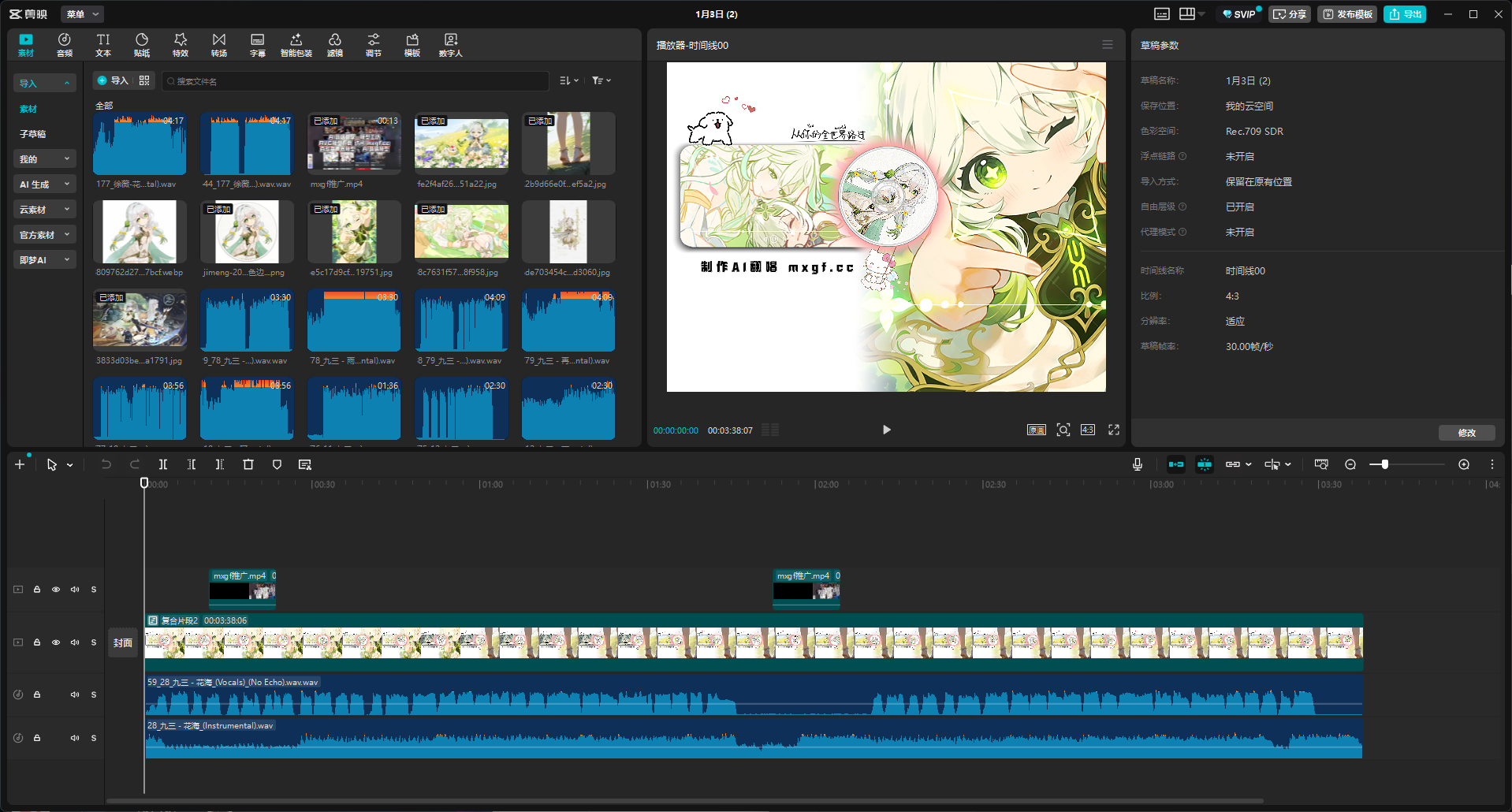
- 将 RVC 转换后的目标人声干声、UVR 分离的原版伴奏导入软件,将两条音轨的时间轴完全对齐;
- 可根据需求做简单的音量平衡、轻微混响、EQ 调节,让人声和伴奏的融合度更高,避免人声和伴奏脱节;
- 导出最终音频 / 视频,一首完整的爆款 AI 翻唱作品就制作完成了!
模块二:实时变声配置教程(游戏 / 直播全平台可用)
想要在游戏开黑、直播、语音通话里实时切换声线,用 w-okada 工具就能实现,低延迟、高还原,告别传统变声器的假声感:
- 前置准备:从模型工坊下载 w-okada 离线整合包、VoiceMeeter Banana 虚拟音频混音器;安装 VoiceMeeter Banana 后重启电脑,确保系统能识别到虚拟音频设备;
- 软件启动与模型导入:解压 w-okada 整合包,右键以管理员身份运行
start_http.bat,等待程序加载完成弹出 GUI 界面;进入 Model 页面,点击「编辑」,上传从站点下载的 RVC 实时变声模型; - 音频通道配置(核心步骤):
- Input 输入:选择你的物理麦克风,用于采集你的原声;
- Output 输出:选择「VoiceMeeter Input」,将变声后的音频送入虚拟混音器;
- 音高设置:转换女性音色推荐 + 6,转换男性音色推荐 - 6 至 - 12,可一边说话一边微调,找到最自然的数值;
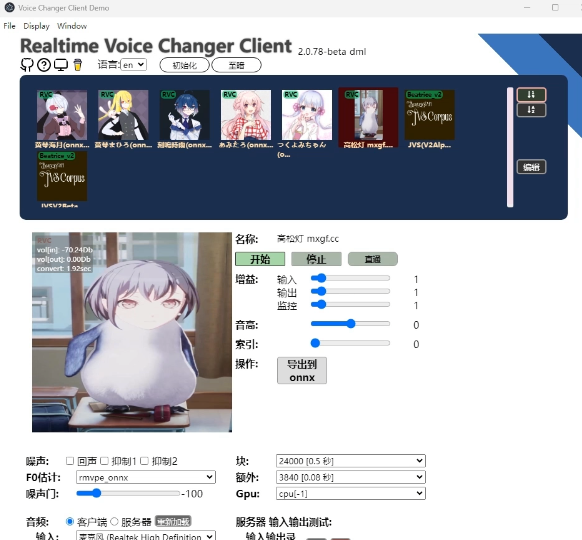
- 启用与系统设置:点击界面「Start」启动实时变声,N 卡可做到 100ms 以内超低延迟,完全不影响交流;打开 Windows 声音设置,将游戏、直播软件、通讯软件的麦克风输入,设置为「VoiceMeeter Output」,即可实现全平台实时变声。
新手避坑指南 & 重要版权声明
常见问题一键解决
- 软件启动 / 转换报错:90% 的问题都是路径包含中文 / 特殊字符,检查所有文件的存放路径,全程用英文和数字命名;
- 转换后有电音、底噪:优先检查人声干声是否纯净,用 UVR 重新做去混响处理,适当降低检索特征占比,调高清辅音保护数值;
- 实时变声延迟高:关闭后台占用显存的程序,选择轻量化的 48K 模型,A 卡 / I 卡用户可降低采样率减少延迟;
- 低配电脑跑不动:模型工坊内提供了免费的 RVC 云端推理教程,无需高性能电脑,浏览器就能完成推理转换。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)