GLM-4.7接入实战:蓝耘元生代云MaaS平台×Dify工作流搭建笔记
蓝耘MaaS与Dify平台的组合,大幅降低了复杂AI应用的构建门槛,提升开发效率,为AI项目快速落地与持续创新提供了有力支撑。实践中通过调用新闻API完成数据自动获取,利用LLM节点实现内容结构化处理与提炼,并结合语音合成节点,最终形成从数据采集到多模态输出的完整应用示例。)逐条列出,每条要点聚焦一个独立的核心信息(可包括关键论据、重要事件、核心建议、数据结论等),要求条理清晰、逻辑分明,不重复已
在AI技术飞速发展的当下,搭建高效、稳定的工作流是实现AI应用快速落地的关键。本文将基于蓝耘元生代云MaaS平台与主流集成工具,介绍如何构建集大语言模型(LLM)推理、文本生成、图像生成及音频处理于一体的智能化工作流。文章以GLM-4.7模型与Dify平台为核心展开实践演示,从模型接入、环境配置、流程设计到功能一体化整合,完整呈现全流程实施步骤与落地效果。旨在通过可复用的实践方案与示例代码,为读者提供清晰、可直接参考的落地指南,助力快速搭建属于自己的AI驱动型工作流。
以下内容来源于CSDN,作者Lethehong
GLM-4.7 模型简介与适用场景
蓝耘MaaS平台以卓越的性能和高度可定制的架构,为大规模语言模型(LLM)提供了坚实的计算资源和部署支持。在国内部署中文 AI 应用时,平台中的 GLM-4.7 模型备受青睐。该模型拥有出色的中文理解和生成能力,并支持最高 4096 字 的上下文长度,能够满足复杂对话和长文生成的场景需求。
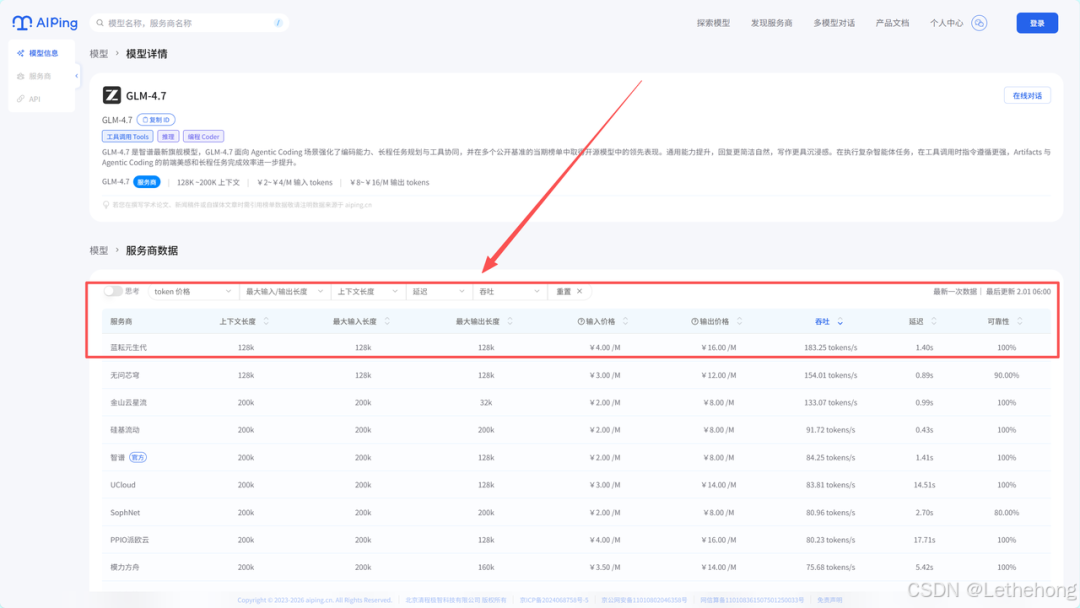
整体工作流目标与效果预览
工作流设计目标说明
在本文演示的 AI 工作流中,我们的主要目标包括:
-
接入 GLM-4.7 模型:在 Dify 平台中配置并调用高性能的 GLM-4.7 模型。
-
工作流设计与部署:借助 Dify 平台进行流程设计,将模型推理、数据处理等节点串联成完整的自动化流程。
-
多功能集成:在工作流中同时实现文本摘要生成、图像生成和音频转换等功能,打造一个可交互的多模态应用。
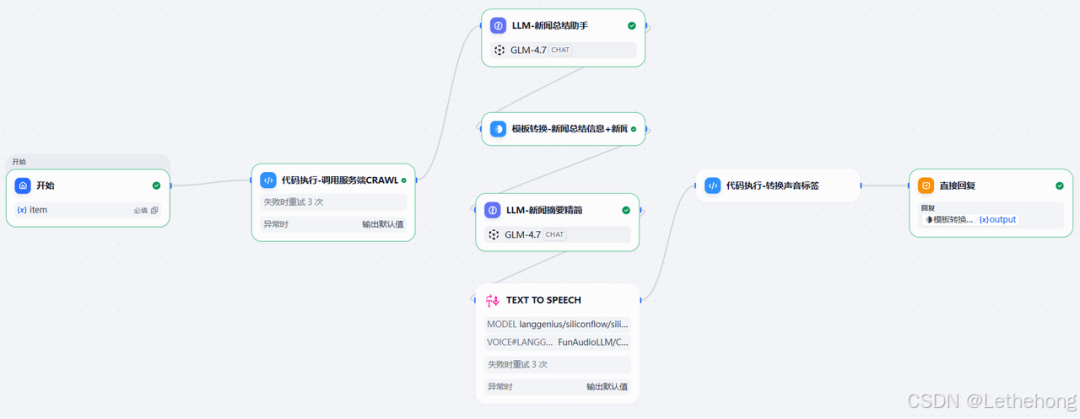
以下是完成后工作流运行界面的示例:

前期准备与环境配置
模型选择说明:为什么使用 GLM-4.7
-
具备卓越的中文处理能力,适用于各类中文 NLP 任务。
-
支持4096 字的上下文长度,可生成连贯的长文本。
Dify 中配置 GLM-4.7 模型的完整流程
1、登录 Dify 平台,点击右上角的用户头像,在下拉菜单中选择“设置”进入配置页面。
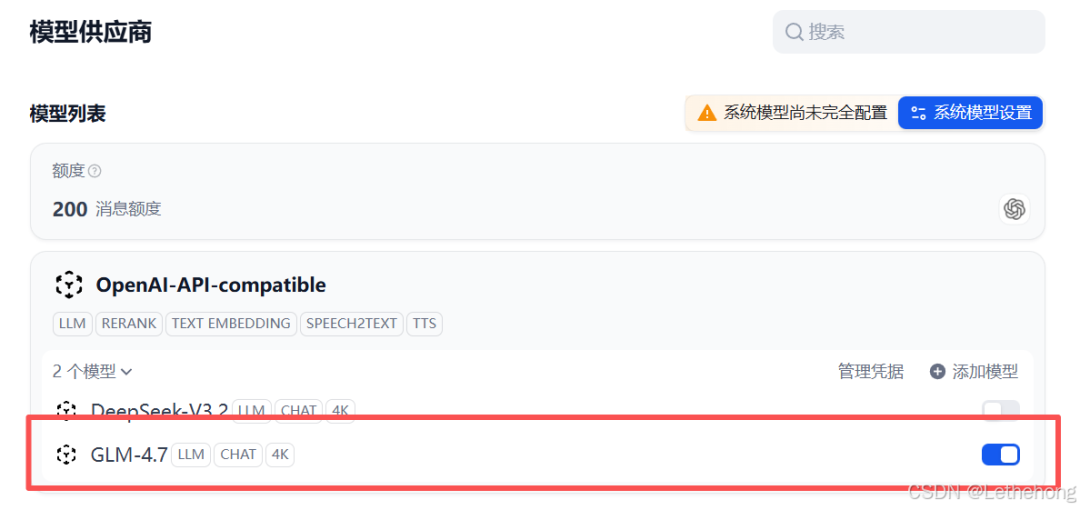
2、在设置页面中,找到“模型提供商(Model Provider)”选项,选择 OpenAI-API-compatible,然后点击保存以完成基本配置。
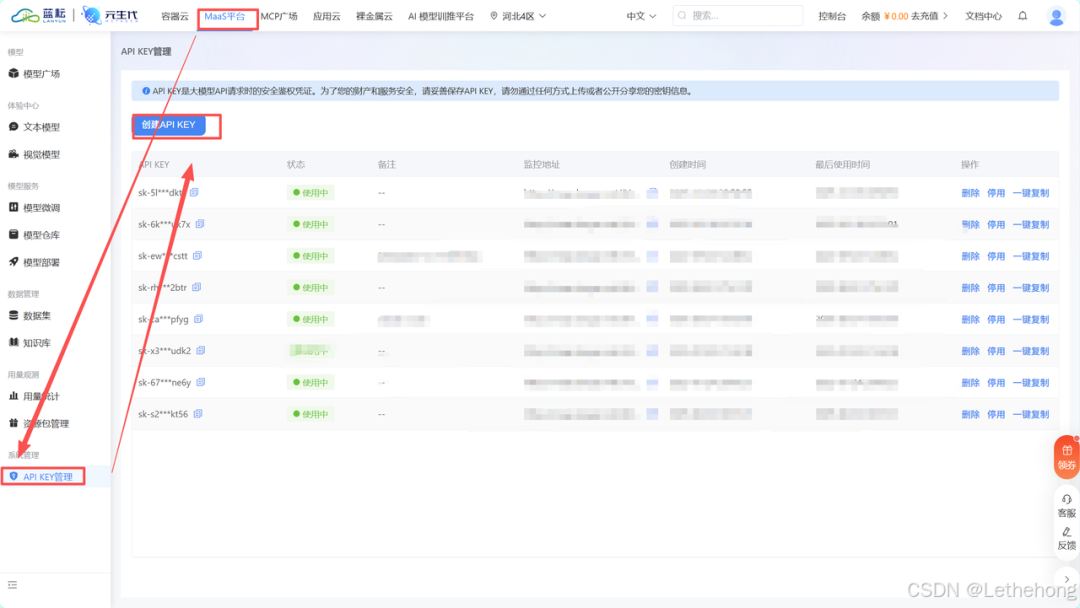
3、登录蓝耘 MaaS 平台,进入“API Key 管理”页面,复制您已生成的有效 API Key。
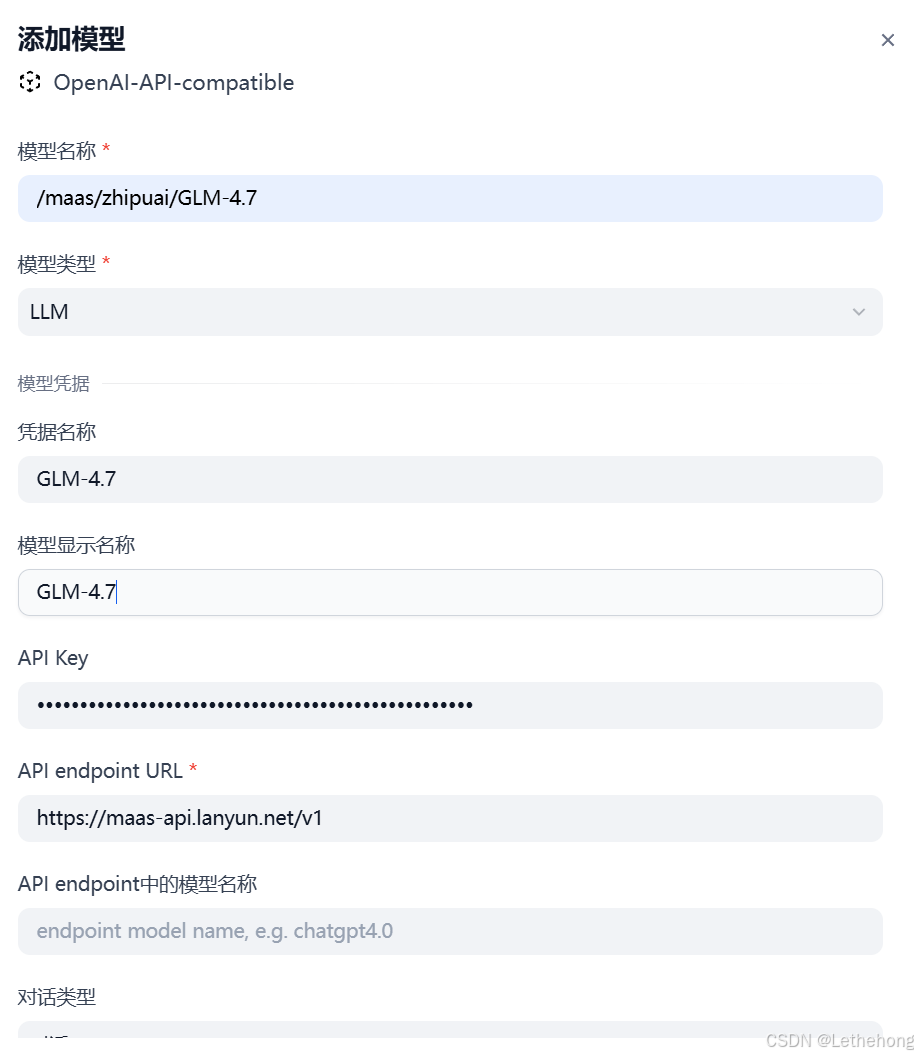
3、返回 Dify 平台的模型配置页面,点击“编辑模型凭据”按钮,在弹出的表单中填写以下信息:
-
-
凭据名称:自定义名称(例如“GLM-4.7”)以便区分不同模型。
-
显示名称:填写“GLM-4.7”,这是在界面中显示的名称。
-
API Key:粘贴从蓝耘 MaaS 平台复制的 API Key。
-
API 地址:输入
https://maas-api.lanyun.net/v1,这是蓝耘 MaaS 固定的接口地址。 -
对话类型:选择“对话”类型。
-
上下文长度/最大 token 限制:设置为 4096,与模型支持的最大长度保持一致。
-
通过以上步骤,你就成功将 GLM-4.7 模型接入到 Dify 平台中,为后续的工作流设计打下了基础。
完整工作流节点拆解
开始节点:输入变量配置
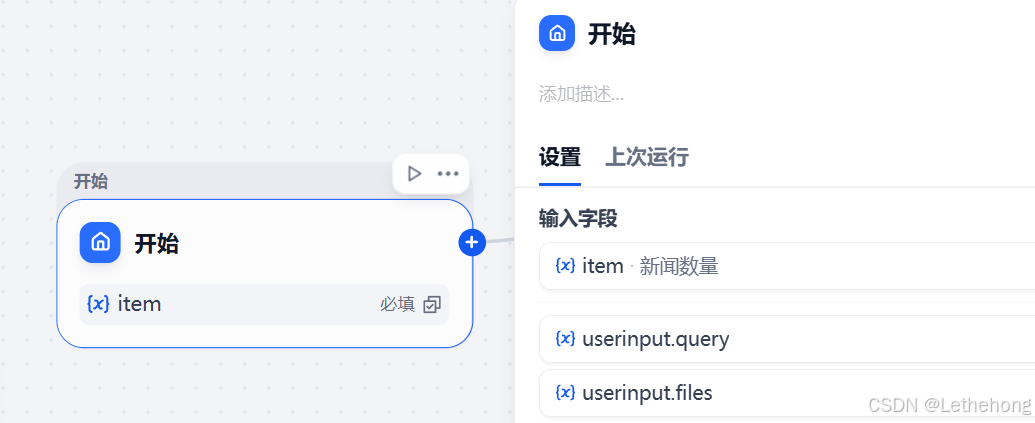
在 Dify 平台的工作流编辑器中,首先配置工作流的输入变量,确保后续节点能够接收到正确的上下文信息。具体操作如下:
-
在工作流编辑页面中,选中“开始”节点(触发节点)。
-
在右侧的输入设置面板中,添加一个新的变量:
-
变量名称:
item(用于指定要获取的新闻数量)。 -
将新增的输入变量标记为 必填,这样用户在触发流程时必须提供此参数。
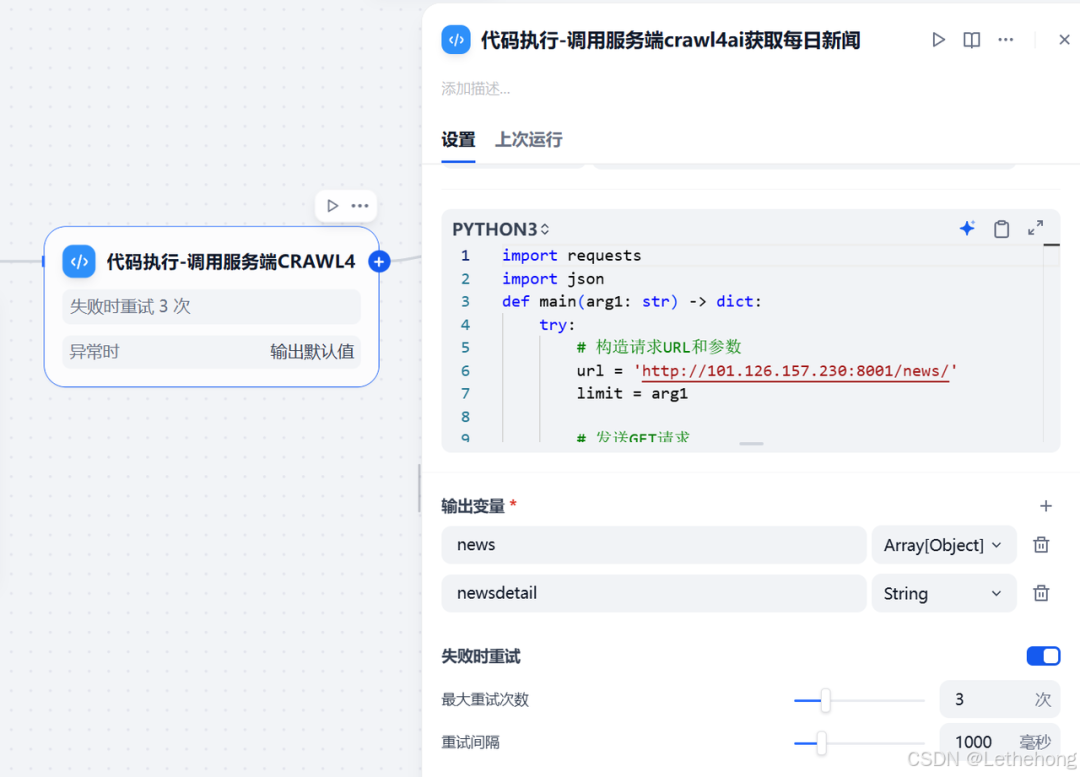
代码节点:调用服务端 crawl4ai 获取新闻数据
在完成变量配置后,添加一个代码节点,用于向后端服务发起请求并获取新闻数据。
-
输出变量:
-
-
news: Array(Object)(新闻列表)
-
newsdetail: String(新闻详情文本)
-
以下是示例 Python 代码:
-
import requests -
import json -
defmain(arg1: str) -> dict: -
try: -
# 构造请求URL和参数 -
url = 'http://101.126.157.230:8001/news/' -
limit = arg1 -
# 发送GET请求 -
response = requests.get(url, params={'limit': limit}) -
# 检查响应状态码 -
if response.status_code == 200: -
# 请求成功,处理结果 -
result = response.json() -
# 提取新闻数据和新闻详情字符串 -
news_list = result.get('news', []) -
newsdetail = result.get('newsdetail', "") -
# 确保 news_list 是一个列表 -
ifnotisinstance(news_list, list): -
return {"error": "服务端返回的新闻数据格式不正确,'news' 字段应为列表。"} -
# 格式化新闻数据(如果需要) -
formatted_news = [] -
for news_item in news_list: -
ifisinstance(news_item, dict): # 如果是字典,直接添加 -
formatted_news.append(news_item) -
elifisinstance(news_item, str): # 如果是字符串,尝试解析为字典 -
try: -
news_dict = json.loads(news_item) # 使用 json.loads 解析字符串 -
formatted_news.append(news_dict) -
except Exception as e: -
print(f"解析新闻数据时出错: {e}") -
else: -
print("无效的新闻数据格式") -
# 返回格式化的新闻数据和新闻详情字符串 -
return {"news": formatted_news, "newsdetail": newsdetail} -
else: -
# 请求失败,返回错误信息 -
return {"error": f"请求失败,状态码: {response.status_code}"} -
except requests.exceptions.RequestException as e: -
# 捕获请求异常 -
return {"error": f"请求出错: {str(e)}"}
python运行
执行上述代码节点后,我们可以获取到格式化后的新闻列表和新闻详情文本供后续处理使用。
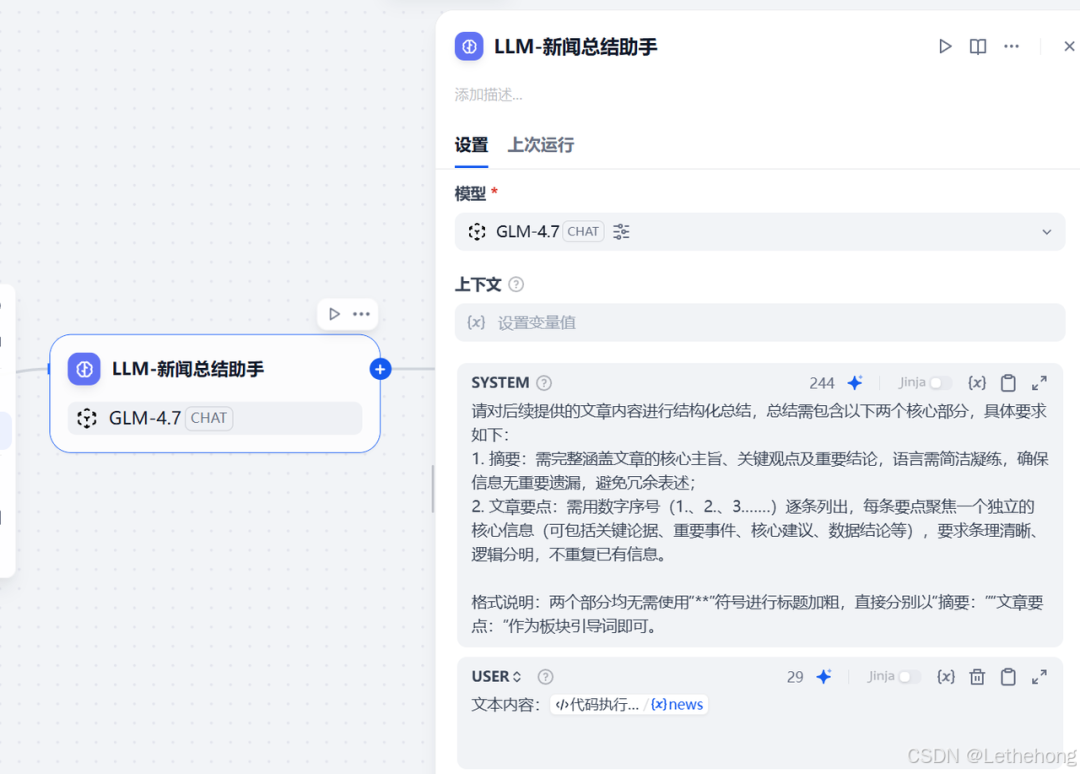
LLM 节点:新闻内容结构化总结
在获取到新闻列表和详情后,接下来使用 LLM 节点对新闻进行结构化总结。本例中我们选择调用前面配置的 GLM-4.7 模型。请向模型提供如下提示词(prompt):
提示词: 请对后续提供的文章内容进行结构化总结,总结需包含以下两个核心部分,具体要求如下:
摘要: 需完整涵盖文章的核心主旨、关键观点及重要结论,语言需简洁凝练,确保信息无重要遗漏,避免冗余表述;
文章要点: 需用数字序号(1.、2.、3.……)逐条列出,每条要点聚焦一个独立的核心信息(可包括关键论据、重要事件、核心建议、数据结论等),要求条理清晰、逻辑分明,不重复已有信息。
格式说明: 两个部分均无需使用“**”符号进行标题加粗,直接分别以“摘要:”“文章要点:”作为板块引导词即可。
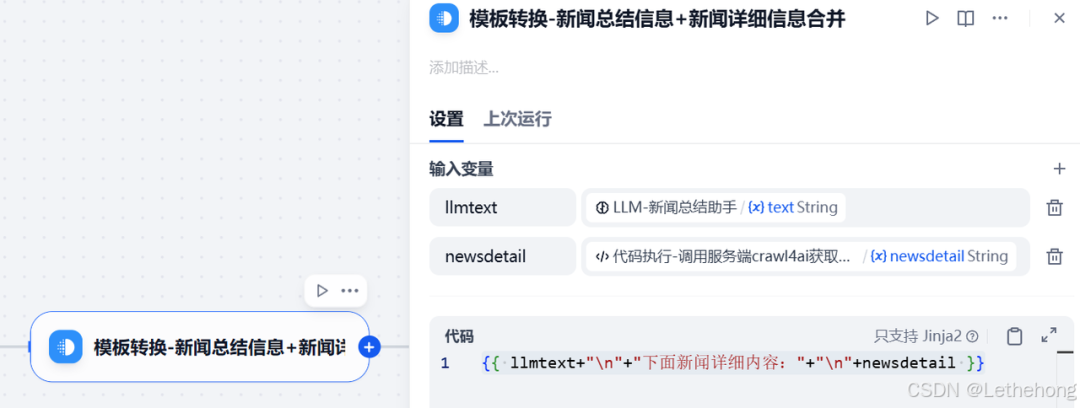
模板节点:合并摘要与新闻原文
使用模板转换节点(或文本拼接)将 LLM 生成的摘要和之前获取的新闻详细内容合并,以便后续流程使用。假设我们有两个变量 llmtext(LLM 输出的总结文本)和 newsdetail(详细新闻文本),可以构造如下模板表达式:
{{ llmtext+"\n"+"下面新闻详细内容:"+"\n"+newsdetail }}python运行
这一操作将把结构化的新闻摘要与完整的新闻内容按顺序组合在一起,方便用户查看或作为后续节点的输入。
LLM 节点:新闻摘要二次精简
在获得合并后的内容后,我们可以再次调用 LLM 节点对总结文本进行精简,控制字数并提高表述质量。例如,给予模型以下提示词:
提示词: 你是一名资深新闻播报员,请对用户输入的新闻摘要内容进行优化,使其表述更流畅,并将总体字数控制在 1000 字以内。
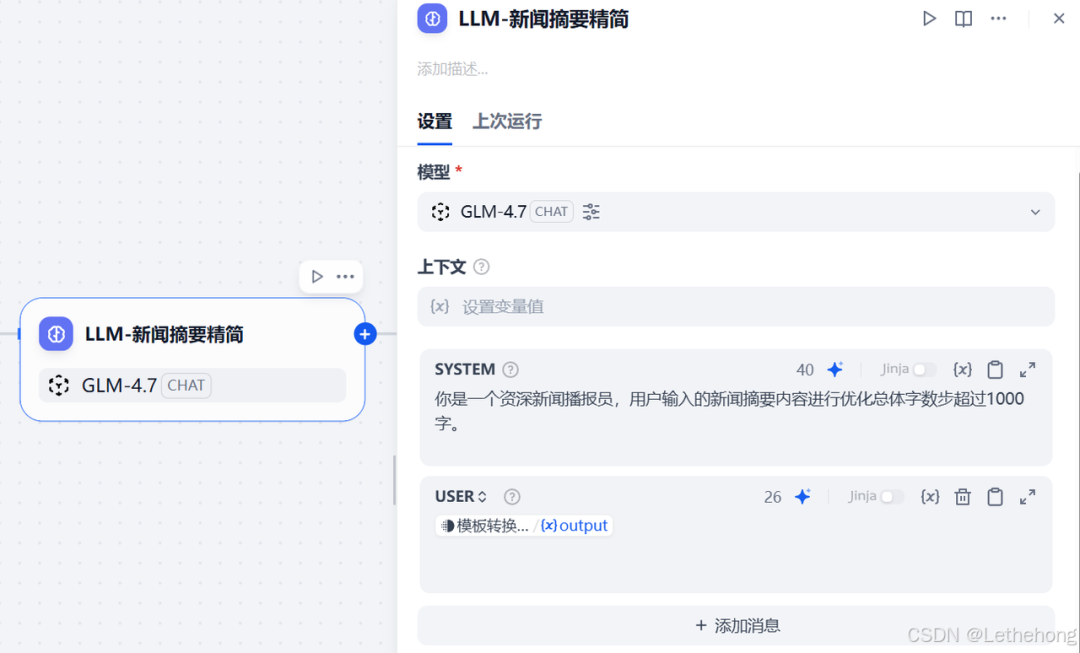
提示词: 你是一名资深新闻播报员,请对用户输入的新闻摘要内容进行优化,使其表述更流畅,并将总体字数控制在1000字以内。
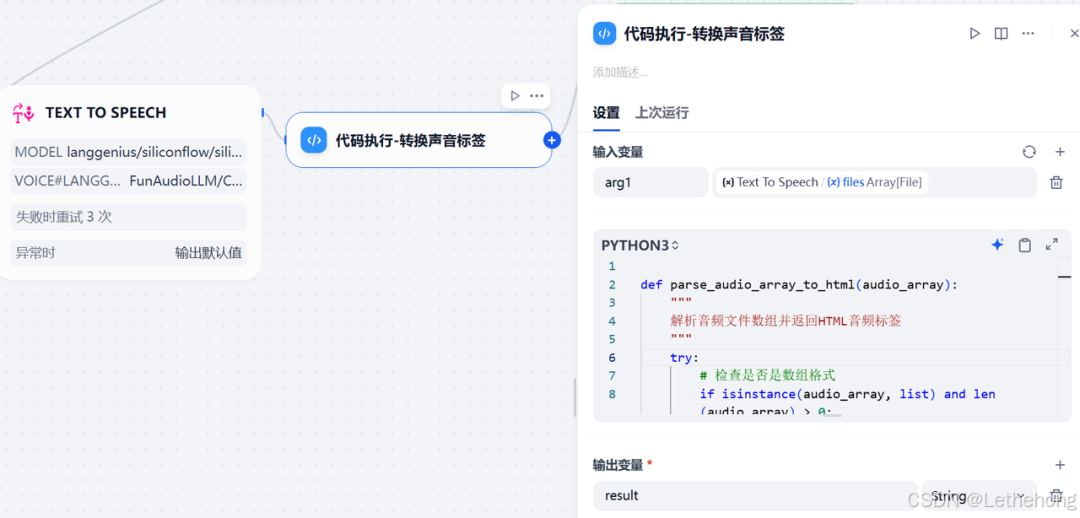
语音节点:Text To Speech 新闻播报
最后,将处理好的文字发送给语音合成服务,实现文字到语音的转换。在 Dify 平台中可以使用语音合成节点。以下提供一个示例 Python 函数,用于将返回的音频文件数组转换为 HTML 音频标签,方便在网页或应用中直接播放:
-
defparse_audio_array_to_html(audio_array): -
""" -
解析音频文件数组并返回HTML音频标签 -
""" -
try: -
# 检查是否是数组格式 -
ifisinstance(audio_array, list) andlen(audio_array) > 0: -
audio_file = audio_array[0] -
# 提取URL和文件名 -
url = audio_file.get('url', '') -
filename = audio_file.get('filename', '') -
# 生成HTML音频标签 -
audio_html = f"<audio controls><source src='{url}' type='audio/x-wav'>{filename}</audio>" -
return audio_html -
else: -
return"No audio files found in array" -
except Exception as e: -
returnf"处理错误: {e}" -
defmain(arg1:str) -> dict: -
markdown_result = parse_audio_array_to_html(arg1) -
# 解析并输出结果 -
return {"result": markdown_result}
python运行
至此,将所有节点串联完成后,接入一个结束节点即可结束工作流。最终,当用户触发该流程时,系统会依次执行新闻爬取、摘要、合并、精炼和语音播报等步骤,实现一个全流程自动化的多功能 AI 工作流。
总结
本文从环境配置、模型接入到工作流设计,完整演示了基于蓝耘元生代云MaaS平台与Dify平台快速搭建高效智能AI工作流的全过程。以高性能中文大模型GLM-4.7为核心,借助Dify可视化流程编辑器,轻松实现文本抓取、结构化总结、内容合并与多模态输出等能力。实践中通过调用新闻API完成数据自动获取,利用LLM节点实现内容结构化处理与提炼,并结合语音合成节点,最终形成从数据采集到多模态输出的完整应用示例。
本文提供了可直接复用的实践步骤与参考思路,读者可根据自身需求替换模型与数据源,灵活扩展工作流。蓝耘MaaS与Dify平台的组合,大幅降低了复杂AI应用的构建门槛,提升开发效率,为AI项目快速落地与持续创新提供了有力支撑。祝愿各位开发者在实践中不断探索,收获更多成果。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)