KV缓存管理演进总结
AI推理中的KV缓存管理演进:从连续分配到统一内存 AI推理部署面临的核心挑战是KV缓存(工作记忆)的高效管理,其显存占用往往超过模型权重本身。文章梳理了KV缓存管理的五个发展阶段: 连续分配(2017):简单但内存浪费严重 分页注意力(2023):借鉴操作系统分页思想,显著提升并发能力 异构缓存(2024):支持多模态等复杂场景 分布式缓存(2025+):突破单机限制 统一混合内存(2025+)
核心问题:AI的“记忆”有多贵?
文章开头就点明了关键:部署AI模型时,模型本身的“知识”(权重)只是问题的一半,另一半是它生成内容时的“工作记忆”(KV Cache)。这个记忆极其消耗显存。比如处理一个简单的请求,它的记忆占用的空间,甚至比模型本身还大。如果管理不好,AI就会反应卡顿,无法实际使用。
🏛️ 五个时代:AI“记忆管理”的演进
文章将这项技术的演变分成了五个阶段,就像从手工记账发展到云端数据库:
| 时代 | 核心思路 | 打个比方 | 优点与痛点 |
|---|---|---|---|
| Era 1:连续分配 (2017) | 为每个请求提前预留一整块固定大小的记忆空间。 | 像去图书馆,不管你看几页书,都直接给你一个固定大小的储物柜。 | 优点:实现简单。 痛点:空间浪费严重(内部碎片),能同时服务的人数很少。 |
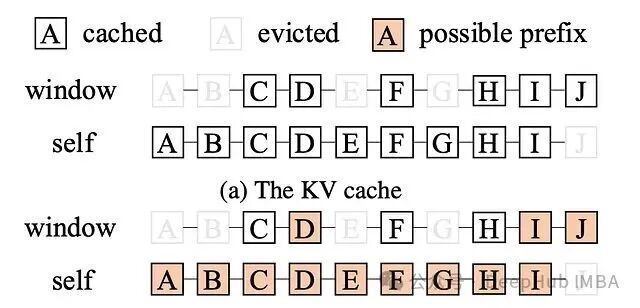
| Era 2:分页注意力 (2023) | 按需分配,像操作系统的内存分页,把记忆切成小页,用多少分配多少。 | 图书馆改用小格子储物架,你看几页书,就给你几个小格子,大家共用大架子。 | 优点:空间利用率极大提升,并发服务人数从几十跃升到上千,还能共享相同的前缀记忆(如开场白)。 痛点:管理变复杂,假设所有记忆都一样大,不够灵活。 |
| Era 3:异构缓存 (2024) | 面对更复杂的模型(如同时处理文字和图片),需要管理不同类型、不同形状的记忆。 | 图书馆不仅要存书(文字),还要存海报(图片),需要设计不同尺寸的格子来分类存放。 | 优点:能支持多模态等复杂模型。 痛点:多个“仓库”分开管理,容易造成新的浪费和混乱。 |
| Era 4:分布式缓存 (2025+) | 当单台机器不够用时,把记忆分散到多台机器的不同部分(如计算专用、记忆专用)。 | 把图书馆扩建到多栋楼:一栋楼专门负责快速办卡(计算),另一栋楼专门负责存放海量书籍(记忆)。 | 优点:突破单机限制,吞吐量大幅提升,可实现“热数据”在高速区、“冷数据”在低速区的分层存储。 痛点:系统极其复杂,网络和运维是巨大挑战。 |
| Era 5:统一混合内存 (2025+) | 将所有类型的记忆统一到一个大池子里管理,彻底消除碎片和浪费。 | 不再分格子,而是用一套智能系统动态调配整个图书馆的立体空间,书和海报可以无缝、紧凑地存放。 | 优点:理论上的终极方案,内存利用率最高,性能提升巨大。 痛点:技术前沿,还在探索和初步落地阶段。 |
💡 如何为你的场景做选择?
文章最后给出了非常实用的建议,你可以根据需求“对号入座”:
-
普通聊天机器人:使用 Era 2 的技术(如vLLM框架)就足够了,开启前缀缓存效果更好。
-
看图说话的模型(多模态):关注 Era 3,看框架能否高效处理图片记忆。
-
混合架构模型(如Gemma 3):Era 5 是为你准备的,能最大发挥模型潜力。
-
大规模、高并发的生产环境:需要 Era 4 的分布式能力,来平衡成本与效率。
-
超长文本处理(如分析整本书):必须使用 Era 4 的分层技术,把部分记忆临时存放到CPU内存或硬盘上。
总结一下,KV缓存管理的演进,就是一部为了在有限、昂贵的显存中,塞下AI飞速增长的“短期记忆”需求,而不断走向精细化和共享化的历史。理解了这些,你就能明白为什么AI服务有时快、有时慢,以及技术人员是如何像“空间管理大师”一样,一点点把AI的效率“榨”出来的。
详细介绍:
在生产环境部署过LLM的人都知道模型权重只是问题的一半,另一半是KV cache:存储注意力状态的运行时内存,让模型在生成token时不必从头开始重算。能不能管好这块内存决定了系统是一个卡顿的demo还是一个可用的推理服务。
本文梳理KV cache管理经历的5个时代,从它根本不存在的阶段,到今天正在成型的统一内存架构。文中会结合多个模型的部署经验,对比vLLM、SGLang和TensorRT-LLM在各阶段的应对思路。读完后应当能建立一套判断框架,为具体场景选择合适的方案。
先从KV cache本身说起。
背景:Prefill、Decode与KV Cache
LLM推理分两个阶段。Prefill阶段并行处理全部输入token,在每个注意力层为每个token计算Key和Value向量,属于计算密集型,GPU并行度越高越好。Decode阶段则以自回归方式逐token生成,每个新token都要对先前所有Key-Value对做注意力计算;GPU大部分时间花在从HBM读取KV cache而非运算上,瓶颈在内存带宽。
KV cache的作用就是把已经算过的Key和Value向量缓存下来,避免每个decode步骤重复计算。没有它每生成一个token就得对整个序列重跑一遍注意力,推理速度完全无法接受。
以Llama-3–70B、8K上下文为例:
KV cache per token = 2 (K+V) x 80 layers x 8 KV heads x 128 head_dim x 2 bytes (FP16) = 2 x 80 x 8 x 128 x 2 = 327,680 bytes ≈ 320 KB per token For 8K tokens: 320 KB x 8,192 = 2.56 GB per request For 32 concurrent requests: 2.56 GB x 32 = 81.9 GB
81.9 GB:一块A100 80GB的全部显存都装不下留给模型权重的空间是零。KV cache管理重要正是因为这一点。
Era 0:Pre-GenAI(2017年之前)
Transformer出现之前深度学习的主力是ResNet、YOLO、VGG、Inception这些无状态前馈架构。每次推理独立处理一个输入步骤之间没有任何持久状态,KV cache的概念自然无从谈起。
ONNX Runtime、TensorRT等推理框架也是为这类无状态负载设计的:加载模型,跑前向传播,返回结果。
如果今天仍然只是服务传统视觉或表格模型,后面这些复杂度都不需要关心。
Era 1:连续KV Cache(2017年)
Transformer原始论文(2017)带来了自注意力机制,也带来了在decode步骤之间缓存Key和Value张量的需求。
早期推理引擎如HuggingFace Transformers用最简单的的方式实现KV cache:为每个请求预分配一个max_seq_len大小的连续张量,单个请求的存储量为2 x num_layers x num_heads x head_dim x max_seq_len。
好处是实现简单,相比每步重算注意力有很大的速度提升。
代价也很明显,内存占用按max_seq_len x batch_size线性增长而非跟随实际序列长度;大多数请求远短于最大长度,造成严重的内部碎片;并发batch大小因此受限,请求之间也无法共享内存。
性能分析的数据很直白:在这些系统中已分配的KV cache内存只有20–38%真正存储了有用的token状态,其余全部浪费在填充和碎片上。
Era 2:PagedAttention(2023年)
PagedAttention是真正改变规则的技术,UC Berkeley的vLLM团队从操作系统借来了一个基本思路:带分页的虚拟内存。
做法是把KV cache切分为固定大小的页(block),随着序列增长按需分配,而非一次性为每个请求开辟一大块连续内存。一个block table将逻辑页映射到物理内存,原理和操作系统页表将虚拟地址映射到物理RAM完全一致。
vLLM论文给出的数据相当惊人:吞吐量比FasterTransformer和Orca提升2–4倍;碎片率降到4%以下(之前是60–80%)内存浪费接近于零;并发请求数从几十跃升到数百乃至数千。
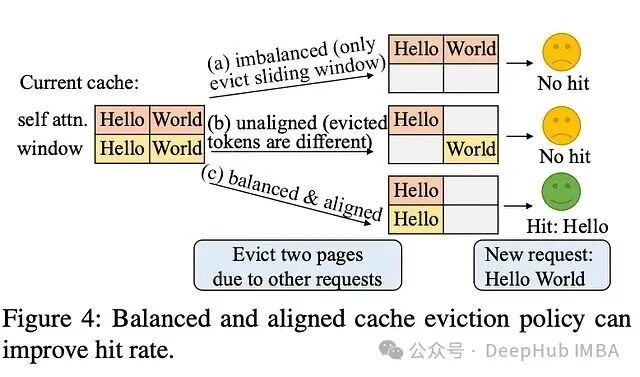
PagedAttention还打开了前缀缓存的大门:SGLang的RadixAttention正是基于此。多个请求如果共享同一前缀(系统提示词、共享文档等)对应的KV cache页可以直接复用而非重新计算。对多轮对话和RAG场景而言,这是一个巨大的吞吐量倍增器。
不过PagedAttention并非没有取舍:注意力kernel因为非连续内存访问变得更复杂,block大小需要调优,而且它默认假设KV cache是同构的:每层大小一致。
这些局限并不妨碍它成为事实标准。今天vLLM、SGLang、TensorRT-LLM全部以PagedAttention为底层基础。
实践比较:vLLM vs SGLang前缀缓存
两个框架都支持前缀缓存,实现路径不同。vLLM在block级别做基于哈希的前缀匹配;SGLang则用RadixAttention树在基数树结构中维护KV block的LRU缓存,支持跨多次生成调用的自动复用。
从实际部署看,SGLang的方案在复杂多调用场景(agent、思维树)中缓存命中率更高,vLLM的方案更简洁标准聊天场景下表现良好。
Era 3:异构KV Cache(2024年)
2024年模型架构和优化技术快速分化,推理系统需要管理形状、生命周期、访问模式各异的多种缓存状态。"KV cache"这个术语的外延已经远超原始定义。
投机解码用一个小型草稿模型一次提出多个候选token,再由大型目标模型批量验证,草稿模型和目标模型各自维护独立的KV cache。视觉语言模型(VLM)如QwenVL、InternVL的视觉编码器会产生大型图像嵌入,这些嵌入可以跨请求缓存复用,但尺寸与文本KV cache不同。量化KV Cache用FP8等低精度格式压缩存储,需要额外维护缩放因子。滑动窗口注意力(SWA)只关注最近window_size个token,KV cache管理需要判断哪些token在窗口内、哪些已过期可以淘汰。
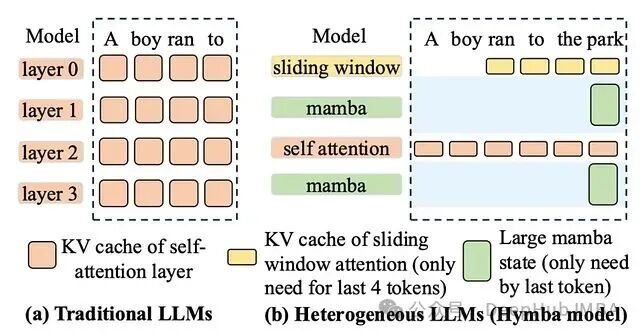
Mamba / 状态空间模型则是另外一条完全不同的路:用循环状态替代注意力,每个新token更新一个固定大小的向量。这种状态无法在token粒度上共享也不容易回滚,和KV cache在本质上就不是一回事。
混合模型则在单个模型中组合多种层类型:
-
滑动窗口 + 全注意力(Gemma 2/3、Ministral)
-
Mamba + 全注意力(Jamba、Bamba)
-
局部分块 + 全注意力(Llama 4)
Jenga论文给出了量化数据:Llama 3.2 11B Vision如果把所有层按统一方式管理,内存浪费达79.6%;Gemma-2为25%;Ministral为56.25%。
异构缓存带来的麻烦包括:多个独立缓存管理器之间的内存碎片、服务器启动时难以预测内存分配、前缀缓存按类型各自实现导致命中率下降,以及功能组合的复杂度急剧上升。
vLLM等框架在实践中走向了分离管理器的路线——普通KV cache一个管理器,视觉编码缓存一个,Mamba缓存又一个。能用,但脆弱,扩展性差。
Era 4:分布式KV Cache(2025+)
模型规模持续增长单GPU甚至单节点已不足以承载。KV cache管理正在变成一个多节点、数据中心级别的问题。
解耦推理
DistServe的核心提案是将prefill和decode阶段部署到不同的GPU实例上。prefill受计算约束,decode受内存约束,两者适合不同的硬件配置和并行策略——分开部署比混在一起更合理。
DistServe的实测数据:与共置系统相比请求处理量提升4.48倍(或在同等吞吐下收紧SLO 10.2倍)。这时候问题就变为了KV cache从prefill节点到decode节点的传输效率。
vLLM的Encoder Disaggregation将视觉编码器拆为独立可扩展服务,专门用于多模态场景,消除编码器与解码器之间的干扰后goodput提升2–2.5倍。
KV Cache感知的负载均衡
NVIDIA Dynamo引入了KV cache感知路由:请求路由器优先把请求转发到已经持有相关KV cache的实例上,在集群层面最大化前缀缓存命中率。这要求每个实例都能获取集群范围内的缓存状态视图。
分层KV Cache
Moonshot AI的Mooncake采用以KV cache为中心的解耦架构,冷KV页从GPU HBM溢出到CPU DRAM或SSD,热页留在GPU上,从而在不牺牲热数据访问速度的前提下扩展有效缓存容量。从低层级加载或写回一层KV的延迟可以和前一层的GPU计算重叠,从而被隐藏。
长上下文场景下Mooncake的吞吐量最高提升525%,同时满足SLO约束。在Kimi的真实负载中,请求处理量多出75%。
分布式时代的困难很实际:投机解码、VLM等不少优化手段和分布式推理还无法兼容;部署需要相当的专业知识和耐心;节点间网络(InfiniBand、RoCE)本身就是难题,NIXL一类的库还很不成熟;故障转移、落后者节点、硬件缺陷、自动扩缩容。每一项都在真实环境中带来额外的复杂度。
Kubernetes原生方案如NVIDIA Dynamo、vLLM Production Stack、llm-d、AIBrix正在试图收敛这些复杂度,但整体仍处于早期。
Era 5:统一混合KV Cache(2025+)
当前前沿工作的方向是构建统一内存系统:异构KV类型共享同一个内存池,而非各自维护独立的分配器。贯穿其中的主题是可组合性——每一项优化都应当能和其他任意优化叠加使用。
Jenga:大页 + LCM尺寸对齐
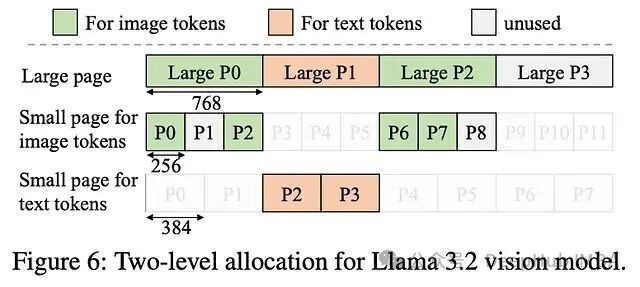
Jenga提出了两级内存分配器。核心思路是取不同嵌入尺寸的最小公倍数(LCM)作为"大页"尺寸,让不同KV形状在同一内存池中共存而不产生碎片。
举例来说,图像token的KV为256字节,文本token的KV为384字节,则取LCM(256, 384) = 768字节为大页尺寸。大页再按特定层类型细分为小页。
与原版vLLM相比,Jenga的GPU内存利用率最高改善79.6%,吞吐量最高提升4.92倍(平均1.80倍)。
SGLang:CUDA虚拟内存
SGLang则又用了另外一个方法:利用CUDA Virtual Memory API动态重映射设备内存,让KV页在虚拟地址空间中连续、物理上分散。弹性内存池可以在运行时动态调整不同池类型(如Mamba池与KV cache池)之间的分配比例。
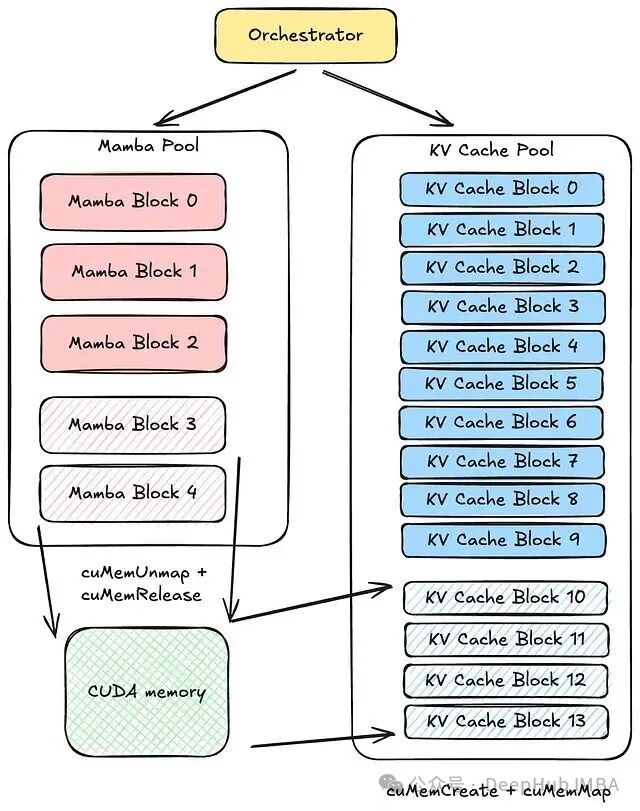
SGLang 2026年Q1路线图明确把功能可组合性列为核心目标:在解耦部署中跨多节点对混合VLM执行投机解码。要达成这一目标,需要对引擎核心组件做长周期的架构重构。
比较表:各时代一览

不同场景下的选择
结合生产部署经验给出一些判断。
标准文本LLM服务(聊天、补全):Era 2(PagedAttention)是基础,选vLLM或SGLang即可。有共享系统提示词的场景应开启前缀缓存。
多模态模型(VLM):属于Era 3的范畴,需要关注框架对视觉嵌入的处理方式。图像密集型负载占比高时,可以评估vLLM的编码器解耦(Era 4)。
混合架构(Gemma 3、Jamba、Llama 4):Era 5直接相关。SGLang的CUDA虚拟内存方案和Jenga的LCM分配器正是针对此类场景设计。
大规模高吞吐量生产:Era 4是重点。解耦prefill/decode配合KV感知路由对成本效率的改善非常可观,NVIDIA Dynamo和Mooncake是参考架构。
长上下文负载(100K+ token):分层KV cache(Era 4)配合GPU到CPU的溢出机制不可或缺,否则GPU显存根本撑不住。
总结
KV cache才是真正的瓶颈,Llama-3–70B在32个并发8K token请求下的KV cache总量超过80GB,比一整块A100的显存还大。
KV cache管理的演进轨迹和操作系统内存管理的历史惊人地相似:从连续分配到虚拟内存、分页,再到分布式共享内存。区别在于操作系统花了40年走完的路,KV cache管理在8年内走完了,背后的驱动力是LLM负载的爆发式增长。对于正在构建LLM基础设施的工程团队来说,理解这些演进阶段没有可选项:后面所有工作都建立在这个基础之上。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)