数字孪生、视频孪生与空间语义大模型的演进关系探讨
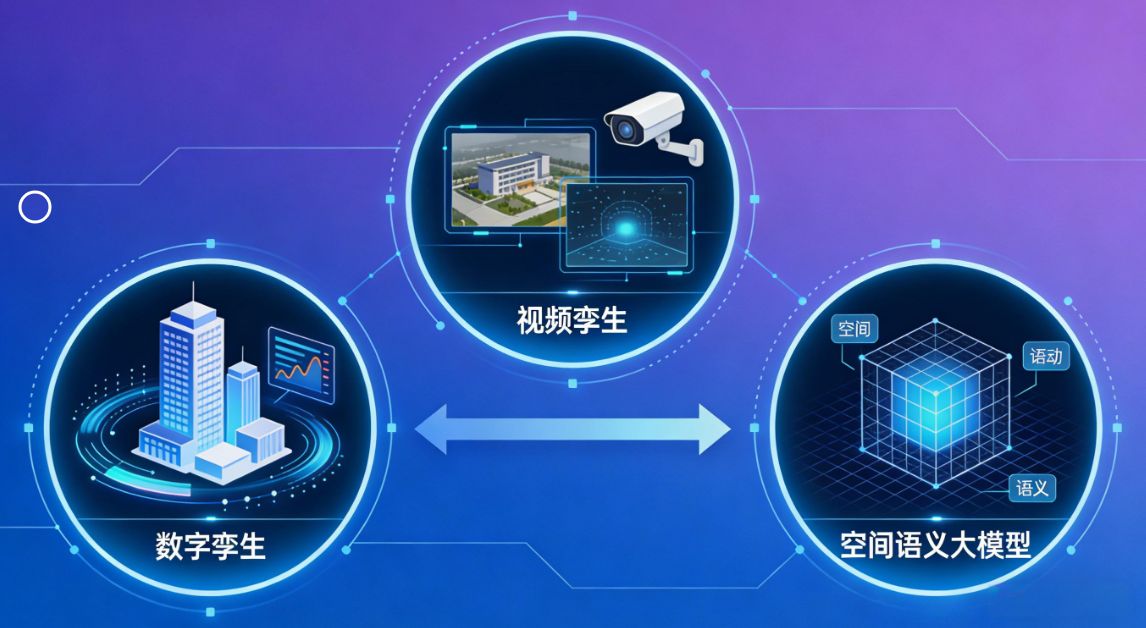
数字孪生是指利用传感器、物联网、大数据等技术,构建物理实体在数字世界中的实时动态镜像。这种镜像不仅仅是三维模型,更是与真实物理对象同步生长、实时交互的虚拟副本。它通过数字线程实现了现实与虚拟的双向映射与交互,是现代工业化和智慧城市的基础设施。数字孪生、视频孪生与空间语义大模型之间的关系,从"几何复制"到"实时感知",再到"空间认知"。犹如人类从诞生到成长的过程:数字孪生是我们诞生的身体,视频孪生
随着信息技术的飞速发展,数字孪生技术正经历着从“数字复制”向“数字认知”的深刻转型。在这一过程中,“视频孪生”与“空间语义大模型”作为两项关键技术,分别承担了感知“眼睛”和赋予“大脑”的角色。以下将系统阐述这三者之间的关系
一、概念溯源与定义
1. 数字孪生(Digital Twin)
数字孪生是指利用传感器、物联网、大数据等技术,构建物理实体在数字世界中的实时动态镜像。这种镜像不仅仅是三维模型,更是与真实物理对象同步生长、实时交互的虚拟副本。它通过数字线程实现了现实与虚拟的双向映射与交互,是现代工业化和智慧城市的基础设施。
2. 视频孪生(Video Twin)
面对传统数字孪生的动态感知盲区,智汇云舟于业内首次提出了"视频孪生"(Video Twin)概念,实现了数字孪生技术的创新性升级。视频孪生并非简单的"视频+数字孪生"的物理叠加,而是一场关于空间感知维度的技术革命。
视频孪生的关键在于"视空映射"技术——通过将2D监控视频的每一帧像素,基于经度、纬度、海拔等时空统一基准,精准地"贴合"在三维GIS场景的对应位置。这一过程实现了:
-
像素级的空间坐标赋予:视频画面中的每一个车辆、行人,不再是屏幕上的RGB颜色值,而是可被换算为(X, Y, Z, 航向, 速度)的空间对象;
-
实时动态注入:静态的数字孪生场景被赋予了连续的、实时的"视觉"能力,实现了从"死模型"到"活世界"的跃迁;
-
多源数据融合:整合监控视频、IoT传感器、业务系统数据,构建全域感知的数字底座。
3. 空间语义大模型(Spatial Semantic Large Model)
空间语义大模型是智汇云舟在视频孪生技术积累基础上,自主研发的新一代空间智能核心技术。它不同于传统的计算机视觉模型或自然语言大模型,而是专门面向三维空间理解的认知智能体。它通过AI算法赋予数字空间“认知”能力,使机器不仅能看到“是什么”,更能理解“发生了什么”。它解决了传统数字孪生系统“知道坐标点有移动目标”却“不理解行为动机”的痛点,实现了对场景中物体属性、功能、关系及规则的深度认知。
二、技术演进的“从眼到脑”路径
1. 数字孪生:构建“骨架”
数字孪生首先解决了物理世界与数字世界之间的映射问题。它通过三维建模和数据集成,构建了一个精准的虚拟空间。然而,这个空间最初只能像一张静态的白纸,这种"静态镜像"特性使得传统数字孪生在应对瞬息万变的现实场景时,缺乏对实时动态的感知能力。
2. 视频孪生:赋予数字孪生"视觉神经"
为了克服数字孪生的“静态”局限,视频孪生应运而生。它利用视频流和时空位置智能,将现实世界的实时画面投射到数字空间。通过“视空映射”技术,视频孪生打通了2D视频与3D空间的鸿沟,实现了对物体的精准空间定位。此时的数字孪生虽然看到了画面,但大多仍停留在“目击”层面,缺乏理解能力。
视频孪生的应用价值在于打破了"数据孤岛",实现了全时空回溯与透视能力。视频孪生解决了数字孪生的第一个核心难题——"看见"。工作人员在大屏上看到的不仅是精致的三维模型,更是实时流动的车流、人流,以及与之联动的统计图表和预警事件。
3. 空间语义大模型:从"看见"到"懂得"的认知革命
正如智汇云舟所描述的那样,视频孪生解决了“眼睛”的问题,而空间语义大模型解决了“大脑”的思考问题。它通过将视频AI识别的结果反向投影到三维空间(3DGS技术),为每一个空间坐标点赋予语义标签。这样,系统不仅能识别出“人”和“车”,还能理解“人正在闯入危险区域”或“设备正在发生异常”。空间语义大模型实现了数字孪生从“空间镜像”向“空间主体”的认知跃迁。
结语
数字孪生、视频孪生与空间语义大模型之间的关系,勾勒出一条清晰的技术发展脉络:从"几何复制"到"实时感知",再到"空间认知"。犹如人类从诞生到成长的过程:数字孪生是我们诞生的身体,视频孪生是我们长出眼睛感知世界的过程,而空间语义大模型则是我们长出大脑,拥有了思考和判断能力的标志。
“空间语义大模型”这一概念及其核心技术创新,突破了传统数字孪生的“镜像”局限,为行业定义了新的认知标杆,标志着数字孪生技术正从“看见”走向“懂得”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)