OpenClaw大模型学习指南:小白程序员轻松入门,收藏必备!
OpenClaw 是一个通过Gateway,连接即时通讯平台(Channel, 如 Telegram、Discord、Slack 等)与本地AI Agent ,能24×7 运行的个人助手。它不仅仅是一个简单的消息转发器,而是一个具备完整。
本文深入剖析OpenClaw的核心运行流程,从消息接入到Agent设计,详细讲解其架构原理。涵盖队列与并发控制、会话管理、记忆系统以及工具技能等方面,帮助读者理解并学习大模型设计,适合小白和程序员参考学习。
地址:
https://zhuanlan.zhihu.com/p/2004505448938767308
OpenClaw的爆火激发了我的学习热情,周末花了几天时间阅读文档、调试源码、测试功能,手搓了一张图帮助我理解核心运行流程。本文将围绕这张图,将我对OpenClaw的理解完整介绍给大家,让大家也感受到Agent设计的魅力。
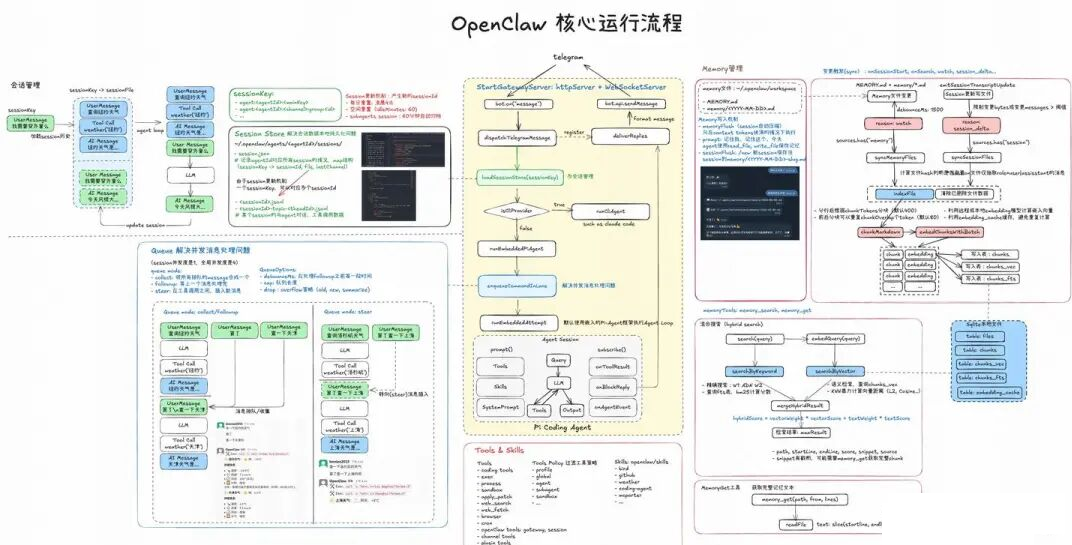
OpenClaw核心运行流程
1、概述
OpenClaw 是一个通过Gateway,连接即时通讯平台(Channel, 如 Telegram、Discord、Slack 等)与本地AI Agent ,能24×7 运行的个人助手。它不仅仅是一个简单的消息转发器,而是一个具备完整会话管理、并发控制、记忆检索以及丰富工具支持的复杂 Agent 运行时环境。
个人评价:OpenClaw的完成度非常高,尽管因为各种安全问题被质疑,但其产品思想和围绕这个核心思想设计的各种代码组件和交互,值得开发者反复学习。
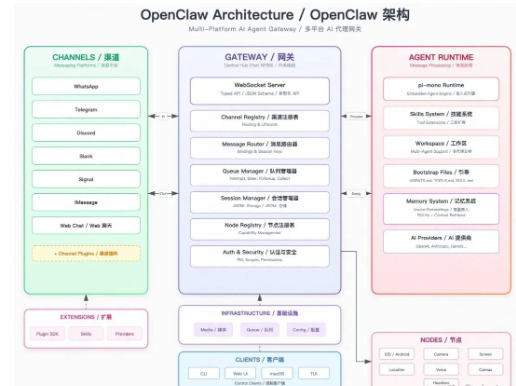
OpenClaw架构图
本文档将深入剖析 OpenClaw 的核心运行流程,结合实际代码和流程图讲解其底层设计原理。并重点介绍OpenClaw的Agent设计。
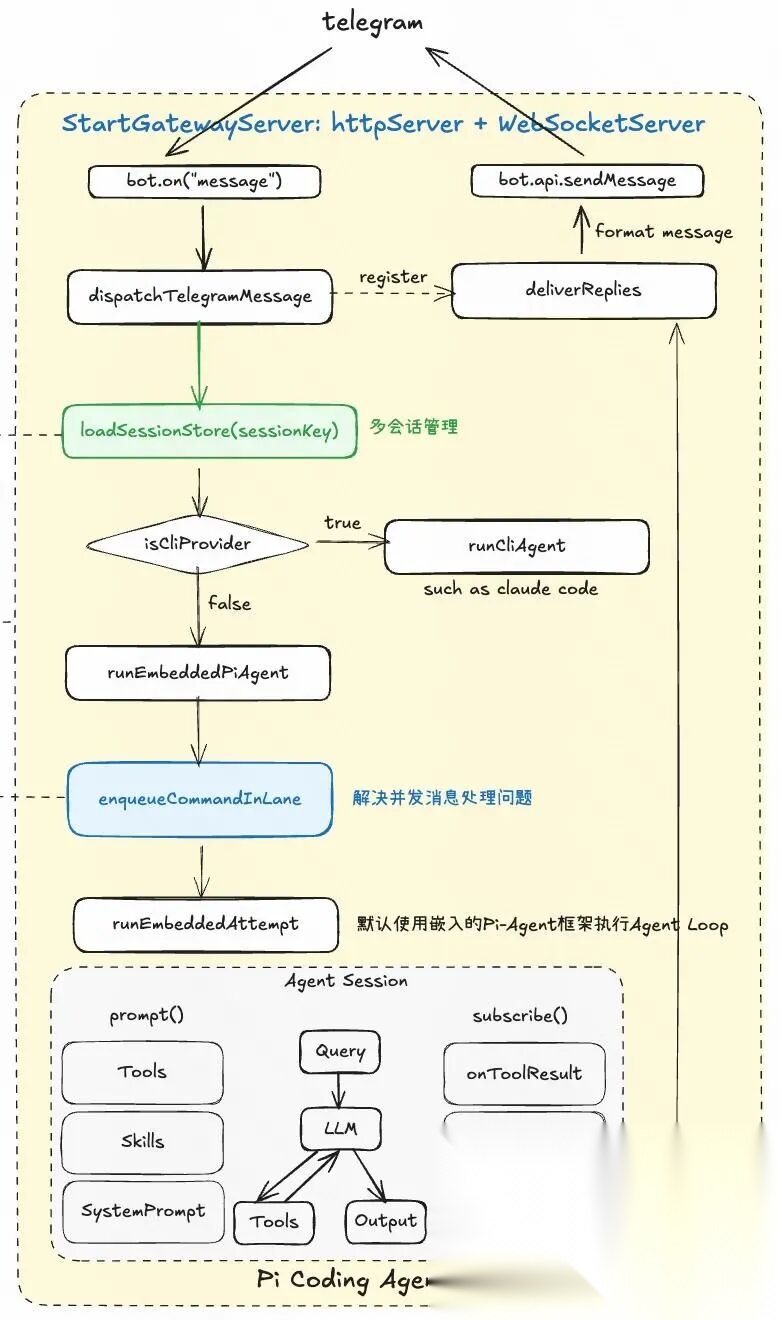
2、核心交互流程:从消息到 Agent
下图以Telegram为例,说明从收到消息,到运行Agent,最后回调发送消息的一次核心运行流程。
2.1 Gateway
如果 AI 助手需要 24×7 运行,那么必然需要一个持久运行的控制平面。这个控制平面需要:保持与所有消息渠道的长连接、管理会话状态、响应客户端请求、处理定时任务。Gateway 就是这个控制平面。
Gateway核心就是一个HTTP和WebSocket服务。其启动时与注册的Channel(比如Telegram机器人)建立WebSocket连接,随时准备接收消息。
// src/gateway/server.impl.ts
// 简化版 Gateway 启动流程
export async function startGatewayServer(
port=18789,
opts:GatewayServerOptions={},
):Promise<GatewayServer>{
// 1. 设置端口环境变量
process.env.OPENCLAW_GATEWAY_PORT=String(port);
// 2. 加载并验证配置
let configSnapshot=awaitreadConfigFileSnapshot();
// 3. 创建 WebSocket 服务器
const wsServer=newWebSocket.Server({port,host});
// 4. 注册核心处理器
const channelManager = createChannelManager (configSnapshot.config);
const agentEventHandler = createAgentEventHandler (configSnapshot.config);
const cronService = buildGatewayCronService (configSnapshot.config);
// 5. 启动通道连接(WhatsApp、Telegram 等)
awaitchannelManager.startAll();
// 6. 返回 close 方法用于优雅关闭
return{
close:(opts)=>shutdownGateway(opts),
};
}
Gateway 通过系统服务管理保持 24×7 运行:
# macOS 启动 Gateway
launchctl load ~/Library/LaunchAgents/ai.openclaw.gateway.plist
# Linux 启动 Gateway
systemctl --user enable --now openclaw-gateway.service
2.2 消息接入与分发
Telegram使用的是grammY作为机器人框架,注册监听事件,回复普通消息。
import {Bot,webhookCallback} from "grammy";
const bot = new Bot(opts.token,client ? {client} : undefined);
const processMessage = createTelegramMessageProcessor ({bot,...});
registerTelegramHandlers ({cfg,accountId,bot,processMessage,...});
其中createTelegramMessageProcessor里使用核心分发函数 dispatchTelegramMessage 负责处理来自 Telegram 的消息,以及注册回复消息的回调函数deliverReplies。
// src/telegram/bot-message-dispatch.ts
export const dispatchTelegramMessage = async({
context,
bot,
cfg,
runtime,
// ... 更多参数
})=>{
const {msg,chatId,isGroup,historyKey,route}=context;
// 1. 分发消息
const {queuedFinal}=awaitdispatchReplyWithBufferedBlockDispatcher({
ctx:ctxPayload,
cfg,
dispatcherOptions:{
// 2. 回复消息回调
deliver:async(payload,info)=>{
const result=awaitdeliverReplies({
replies:[payload],
chatId:String(chatId),
token:opts.token,
runtime,
bot,
// ... 更多选项
});
},
onError:(err,info)=>{
runtime.error?.(`telegram reply failed: ${String(err)}`);
},
},
});
};
一些特殊消息能力,需要通过message工具来发送,而非直接通过deliverReplies来发送消息。后续工具技能会具体介绍。
2.3 Session Key机制
SessionKey 是 OpenClaw 中用于标识和路由会话的核心概念。
由于OpenClaw支持非常多的Channel账号、以及私聊、群组、Thread等各种会话形式。需要一种命名方式来唯一识别不同的会话。
// src/routing/session-key.ts
export function buildAgentMainSessionKey(params:{
agentId:string;
mainKey ?: string | undefined;
}) : string{
const agentId=normalizeAgentId(params.agentId);
const mainKey=normalizeMainKey(params.mainKey);
return `agent:${agentId}:${mainKey}`;
}
export function buildAgentPeerSessionKey(params:{
agentId:string;
mainKey ?: string | undefined;
channel:string;
accountId ?: string | null;
peerKind ?: "dm"|"group"|"channel" | null;
peerId ?: string | null;
// ...
}):string{
// 对于 DM: agent:main:channel:account:dm:peerId
// 对于群组: agent:main:channel:group:groupId
// ...
}
SessionKey 的格式示例:
- 主会话: agent:main:main
- Telegram DM: agent :main :telegram :default :dm :123456789
- Telegram 群组: agent :main :telegram :group :1001234567890
2.4 Agent Loop
OpenClaw支持调用已有的CLI Agent,比如Claude Code等;但默认情况下也嵌入了基于Pi-Agent框架 执行Agent运行时。该框架具备极高的扩展性,满足OpenClaw定制化需求(比如大模型供应商支持、Session管理、工具定制化、流式输出、消息订阅)。
如下图所示,消息进入AgentSession后,通过ReAct范式执行Agent Loop(包括工具调用),通过注册reply回调(监听message_end事件)将AI回复的消息通过机器人发送给Telegram。
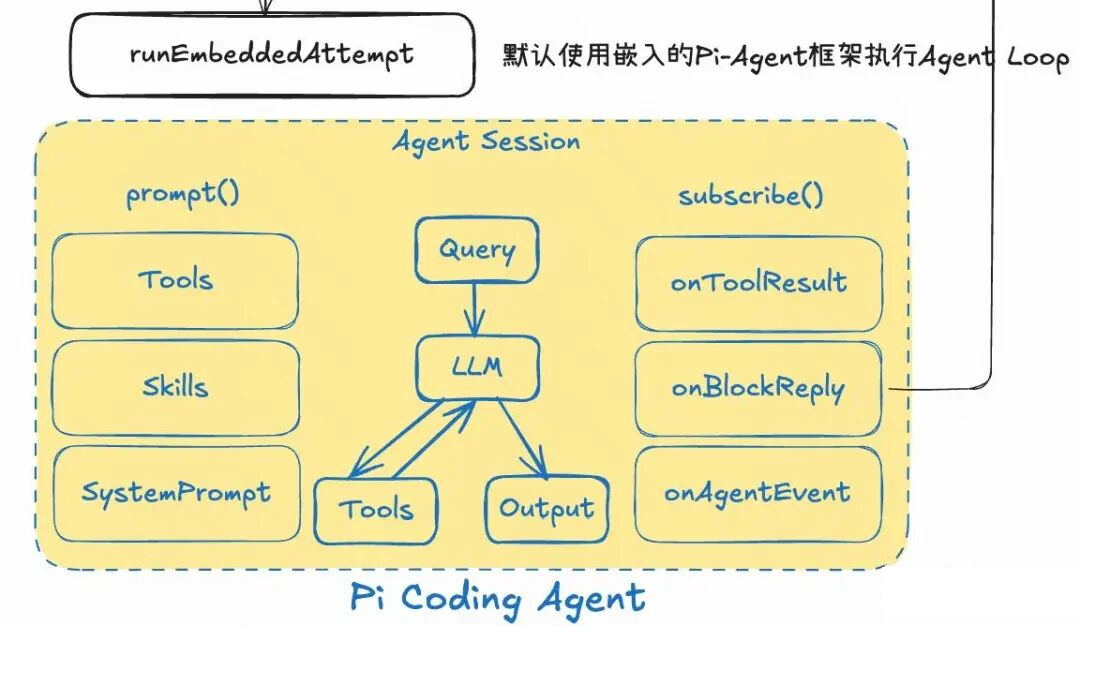
故障转移机制
为了能24 × 7 持续运行,不能因为一些异常就停止。因此OpenClaw 实现了完整的故障转移机制:
1. Auth Profile 轮换: 当一个 API Key 遇到速率限制或认证失败时,自动切换到下一个可用的 Profile
2. 上下文溢出自动压缩: 当会话过长时,自动压缩历史消息
3. 思考级别降级: 当模型不支持扩展思考模式时,自动降级到基本模式
// src/agents/pi-embedded-runner/run.ts
export async function runEmbeddedPiAgent(
params:RunEmbeddedPiAgentParams,
):Promise<EmbeddedPiRunResult>{
// 会话级别并发控制(串行处理)
const sessionLane = resolveSessionLane(params.sessionKey ?. trim() || params.sessionId);
// 全局并发控制(默认并发度 4)
const globalLane=resolveGlobalLane(params.lane);
return enqueueSession(()=>
enqueueGlobal(async()=>{
const started=Date.now();
// 模型解析和上下文窗口验证
const {model,error,authStorage,modelRegistry} = resolveModel(
provider,
modelId,
agentDir,
params.config,
);
const ctxInfo=resolveContextWindowInfo({
cfg:params.config,
provider,
modelId,
modelContextWindow:model.contextWindow,
defaultTokens:DEFAULT_CONTEXT_TOKENS,
});
// 认证配置管理和故障转移
const profileOrder=resolveAuthProfileOrder({
cfg:params.config,
store:authStore,
provider,
preferredProfile:preferredProfileId,
});
// 主执行循环,支持故障转移
while (true){
const attempt=awaitrunEmbeddedAttempt({
sessionId:params.sessionId,
sessionKey:params.sessionKey,
// ... 大量参数
});
// 处理上下文溢出,自动压缩
if (isContextOverflowError(errorText)){
if (!overflowCompactionAttempted){
const compactResult=awaitcompactEmbeddedPiSessionDirect({
sessionId:params.sessionId,
sessionKey:params.sessionKey,
// ...
});
if (compactResult.compacted){
continue;// 使用压缩后的会话重试
}
}
}
// 处理认证/速率限制故障转移
if (shouldRotate){
const rotated=awaitadvanceAuthProfile();
if (rotated) continue;
}
return {
payloads:payloads.length ? payloads :undefined,
meta:{
durationMs:Date.now()-started,
agentMeta,
aborted,
systemPromptReport:attempt.systemPromptReport,
},
};
}
}),
);
}
2.5 Agent 核心设计
OpenClaw并没有从0构造Agent核心,而是使用开源的Pi-Agent框架。但OpenClaw也定制了其中核心组件,将其打造成开箱即用的、能力丰富的本地个人助手。下面着重从**并发控制(Queue)、会话管理(Sesssion)、记忆系统(Memory)和工具技能(Tools & Skills)**几个角度介绍。
3、队列与并发控制
为了解决群组聊天或高频交互中的"消息竞争"问题,OpenClaw 参考Pi Agent设计了一套精密的 Queue 系统。
3.1 队列模式(Queue mode)
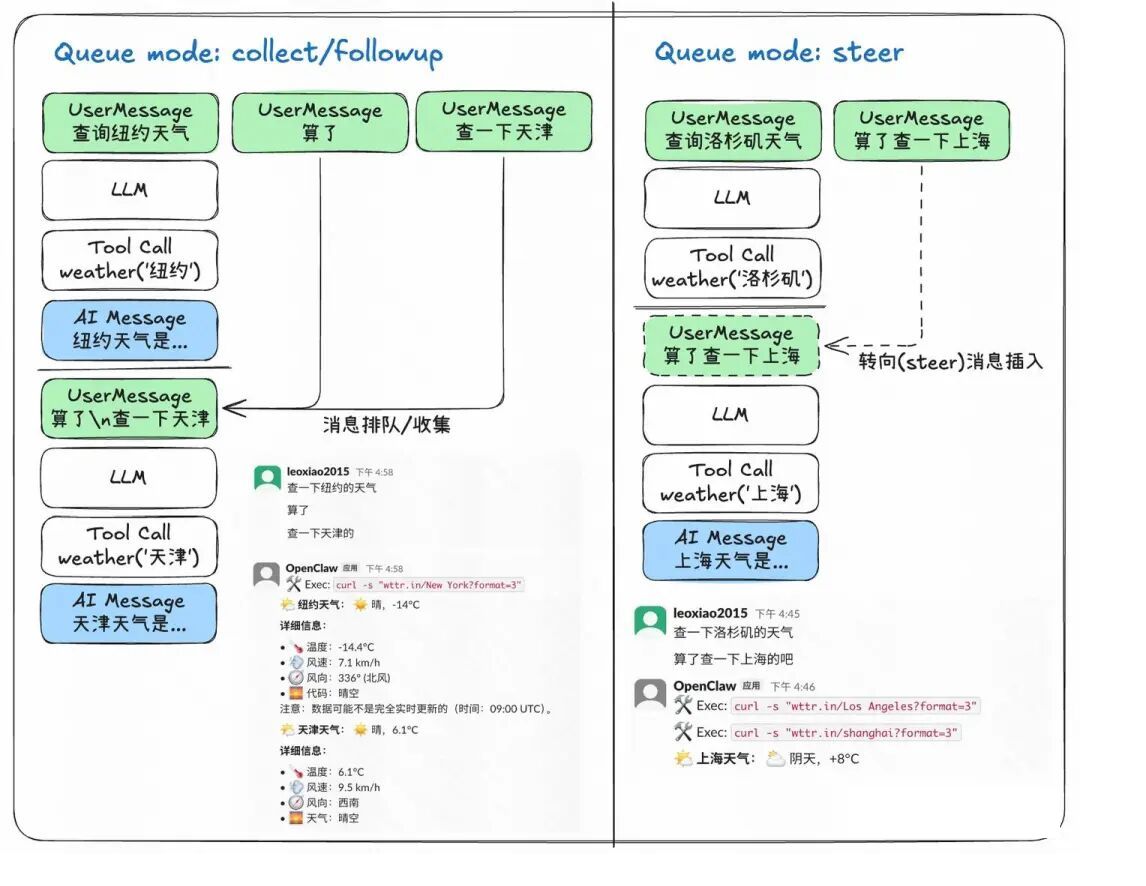
- collect - 收集模式(默认):将所有排队的消息合并成单个后续回复
- steer - 转向模式:立即注入到当前agent回合中
- followup - 跟进模式:当前运行结束后,为下一个 agent 回合排队
- steer-backlog - 转向+积压模式:现在转向当前回合,然后保留消息用于后续回合
// src/auto-reply/reply/queue/types.ts
export typeQueueMode="steer"|"followup"|"collect"|"steer-backlog"|"interrupt"|"queue";
export typeQueueSettings={
mode:QueueMode;
debounceMs ?: number;// 防抖延迟(毫秒),默认1000ms
cap ?: number;// 队列容量上限,默认20
dropPolicy ?: "old"|"new"|"summarize";// 默认summarize
};
Collect的消息示例:
{
"id":"e1c9d464",
"message":{
"content":[
{
"text":"[Queued messages while agent was busy]\n\n---\nQueued #1\n[Slack x +1s 2026-02-09 16:58 GMT+8] 算了 [slack message id: x channel: x]\n[message_id: x]\n\n---\nQueued #2\n[Slack x +4s 2026-02-09 16:58 GMT+8] 查一下天津的 [slack message id: x channel: x]\n[message_id: x]",
"type":"text"
}
],
"role":"user",
"timestamp":1770627650797
},
"parentId":"7588527b",
"timestamp":"2026-02-09T09:00:50.802Z",
"type":"message"
}
3.2 队列处理逻辑
Steer:利用pi-agent的steer能力,在Agent loop中插入消息。
// 如果存在运行中的session,则插入消息
if (shouldSteer && isStreaming){
const handle = ACTIVE_EMBEDDED_RUNS.get(sessionId);
...
void handle.queueMessage(text);
}
// 实际:使用pi-agent框架的steer插入消息
const queueHandle:EmbeddedPiQueueHandle={
queueMessage:async(text:string)=>{
awaitactiveSession.steer(text);
}
...
};
// pi-agent的agent-loop
let pendingMessages:AgentMessage[]=(awaitconfig.getSteeringMessages?.())||[];
while (true){
...
// 如果存在待插入的消息,则直接加入到状态中
if (pendingMessages.length>0){
for (const message of pendingMessages){
currentContext.messages.push(message);
newMessages.push(message);
}
pendingMessages=[];
}
...
}
Follow Up和Collect模式:
// src/auto-reply/reply/queue/drain.ts
export function scheduleFollowupDrain(
key:string,
runFollowup:(run:FollowupRun)=>Promise<void>,
) :void {
const queue=FOLLOWUP_QUEUES.get(key);
if (! queue || queue.draining) return;
queue.draining = true;
void (async()=>{
try{
while (queue.items.length>0 || queue.droppedCount>0){
awaitwaitForQueueDebounce(queue);
if (queue.mode==="collect"){
// 批量收集模式:合并所有等待消息为一个 Prompt
const items = queue.items.splice(0,queue.items.length);
const summary = buildQueueSummaryPrompt ({state:queue,noun:"message"});
const prompt = buildCollectPrompt({
title:"[Queued messages while agent was busy]",
items,
summary,
renderItem:(item,idx)=>`---\nQueued #${idx + 1}\n${item.prompt}`.trim(),
});
awaitrunFollowup({prompt,run,enqueuedAt:Date.now()});
continue;
}
// Followup 模式:处理下一个消息
const next = queue.items.shift();
awaitrunFollowup(next);
}
}finally{
queue.draining = false;
}
})();
}
3.3 并发控制
OpenClaw 使用两层并发控制:
1. 会话级别: 同一会话内的消息串行处理,避免状态混乱
2. 全局级别: 默认并发度为 4,允许最多 4 个会话同时处理
Telegram还专门使用bot.use (sequentialize (getTelegramSequentialKey) ) 序列化所有消息。
// src/agents/pi-embedded-runner/run/lanes.ts
export function resolveSessionLane(sessionId:string):string{
return `session:${sessionId}`;
}
export function resolveGlobalLane(lane ?: string):string{
return lane || `global:default`;
}
// enqueueCommandInLane
export async function runEmbeddedPiAgent(
params:RunEmbeddedPiAgentParams,
):Promise<EmbeddedPiRunResult>{
// 全局并发度4:即保障active的会话,不超过4个
const enqueueGlobal=params.enqueue ?? ((task,opts)=>enqueueCommandInLane(globalLane,task,opts));
const enqueueSession=params.enqueue ?? ((task,opts)=>enqueueCommandInLane(sessionLane,task,opts));
return enqueueSession(()=>
enqueueGlobal(async()=>{...})
)
}
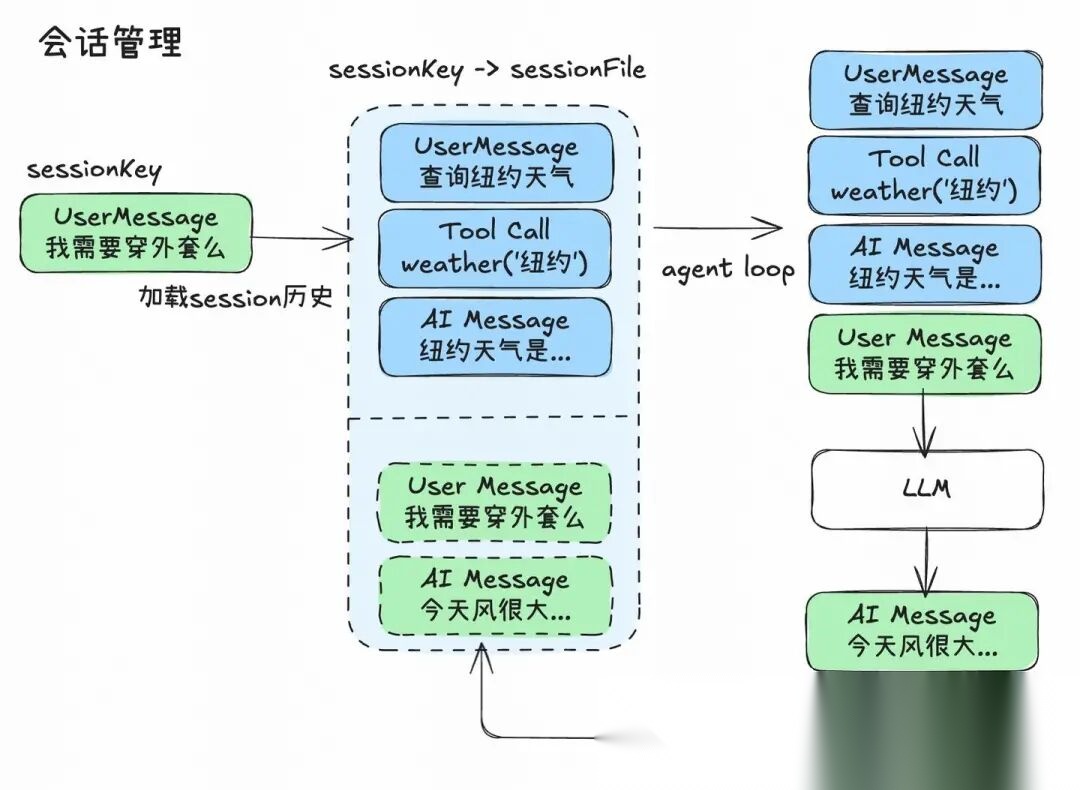
4、会话管理:Session
一般session的对话数据也被称为短期记忆
与Agent的多轮交互需要维持一次会话中历史所有消息(UserMessage, AI Message,Tool Result Message等),一般Agent会存储在内存中(简单场景)或数据库(云端场景)中。
OpenClaw 作为本地Agent,使用Pi Agent自带的Session管理工具,采用本地文件系统作为 Session存储工具,解决会话数据的持久化问题。

4.1 存储结构
物理存储路径: ~/. openclaw/ agents/ / sessions/
- session.json: 记录所有 Session 的元数据映射
- .jsonl: 存储具体的对话日志(JSON Lines 格式,便于追加写入)
4.2 生命周期管理
Agent Session并不会一直共享同一个上下文,否则上下文窗口很容易超长(虽然可以执行Session超长压缩,但总归不是一个有效率的做法)。因此OpenClaw 实现了自动化的会话生命周期管理:
- 每日重置: 每天自动生成新的 SessionId(通过检测日期变化)
- 空闲归档: 默认 60 分钟无交互后归档当前 Session
- 子 Agent 管理: 子 Agent 的 Session 同样遵循 60 分钟自动归档策略
因此**一个SessionKey,可能存在多个SessionId。**比如同样在Telegram私聊机器人,今天对话使用的上下文和昨天是完全不同的。
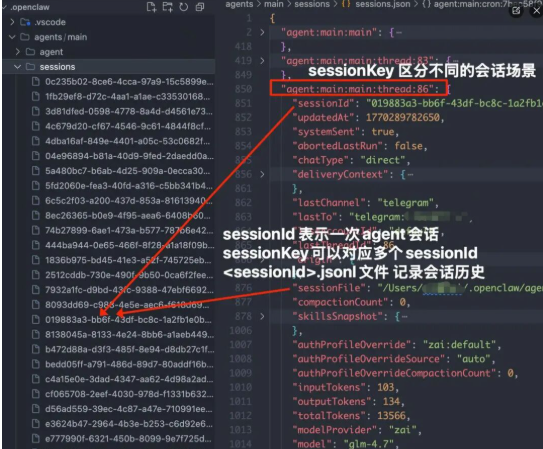
4.3 Session 加载和管理
获取Sesssion的所有配置:session.json
// src/config/sessions/store.ts
export function loadSessionStore(
storePath:string,
opts:LoadSessionStoreOptions={},
):Record<string,SessionEntry>{
// 从磁盘加载
let store:Record<string,SessionEntry>={};
try{
const raw = fs.readFileSync(storePath,"utf-8");
const parsed = JSON5.parse(raw);
if (isSessionStoreRecord(parsed)){
store=parsed;
}
} catch {
// 忽略缺失/无效的 store;我们会重新创建
}
returnstructuredClone(store);
}
根据SessionKey和对应的SessionId,获取当前会话的历史文件sessionFile: sessions/.jsonl。作为Pi Agent的SessionManager。
// 构造Session Manager,创建AgentSession
sessionManager=guardSessionManager(
// 获取当前会话的历史文件sessionFile: <sessionId>.jsonl
SessionManager.open(params.sessionFile),{
agentId:sessionAgentId,
sessionKey:params.sessionKey,
...
});
({session}=awaitcreateAgentSession({
cwd:resolvedWorkspace,
agentDir,
authStorage:params.authStorage,
modelRegistry:params.modelRegistry,
model:params.model,
thinkingLevel:mapThinkingLevel(params.thinkLevel),
tools:builtInTools,
customTools:allCustomTools,
sessionManager,
...
}))
会话新增消息,加锁后存入文件。
export async function updateSessionStore<T>(
storePath:string,
mutator:(store:Record<string,SessionEntry>)=>Promise<T>|T,
):Promise<T>{
return awaitwithSessionStoreLock(storePath,async()=>{
// 在锁内重新读取以避免覆盖并发写入
const store = loadSessionStore(storePath,{skipCache : true});
const result = awaitmutator(store);
awaitsaveSessionStoreUnlocked(storePath,store);
return result;
});
}
5、记忆系统:Memory
OpenClaw 拥有一个完善的记忆系统,通过对记忆相关的Markdown文件的实时索引和混合检索来实现长期记忆。下图将介绍记忆存储、记忆索引、记忆检索的流程:
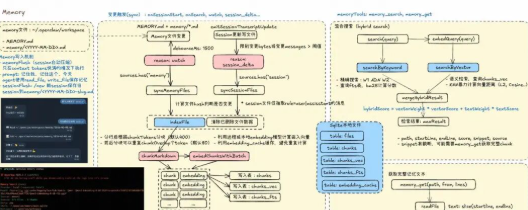
5.1 记忆存储
除了Agent固定加载的一些相关文件(比如AGENTS.md,USER.md, IDENTITY.md等)之外,我们还需要agent记住其他类型的事情 或 特定日期发生的事情,这些记忆存储在 ~/.openclaw/workspace 下:
MEMORY.md或memory.md: 全局长期记忆memory/\*.md: 目录中的所有 Markdown 文件- 额外路径: 通过
memorySearch.extraPaths配置
// src/memory/internal.ts
export async function listMemoryFiles(
workspaceDir:string,
extraPaths ?: string[],
):Promise<string[]>{
const result : string[]=[];
const memoryFile=path.join(workspaceDir,"MEMORY.md");
const altMemoryFile=path.join(workspaceDir,"memory.md");
const memoryDir=path.join(workspaceDir,"memory");
// 添加主记忆文件
awaitaddMarkdownFile(memoryFile);
awaitaddMarkdownFile(altMemoryFile);
// 递归遍历 memory 目录
try{
const dirStat=awaitfs.lstat(memoryDir);
if (! dirStat.isSymbolicLink() && dirStat.isDirectory()){
awaitwalkDir(memoryDir,result);
}
}catch{}
// 处理额外路径
const normalizedExtraPaths = normalizeExtraMemoryPaths(workspaceDir,extraPaths);
for (const inputPath of normalizedExtraPaths){
const stat = awaitfs.lstat(inputPath);
if (stat.isDirectory()){
awaitwalkDir(inputPath,result);
}else if(stat.isFile() && inputPath.endsWith(".md")){
result.push(inputPath);
}
}
// 去重
return deduped;
}
Memory写入机制:
- memoryFlush(session自动压缩) 只在context tokens快满的情况下执行
- prompt: 使用类似“记住我”、“记住这个”、“今天”等,agent会保存记忆到本地文件。
- sessionFlush: /new 新session保存旧 session到memory/-slug.md
配置使用sources: [“memory”, “sessions”] 后也会将session文件纳入到记忆检索范围中。
5.2 混合检索
通过给Agent提供memory_search和memory_get工具,允许其在合适的时候通过query检索历史记忆中相关的文本片段(RAG范式)。
在OpenClaw中,使用了典型的混合检索方案,即同时通过关键词精确搜索 + 向量语义检索,对候选结果计算加权得分,给agent展示最相关的几条。
基于本地个人Agent的定位,OpenClaw的精确检索和向量检索都默认使用Sqlite作为数据库存储(结果是一个agents.sqlite文件)。
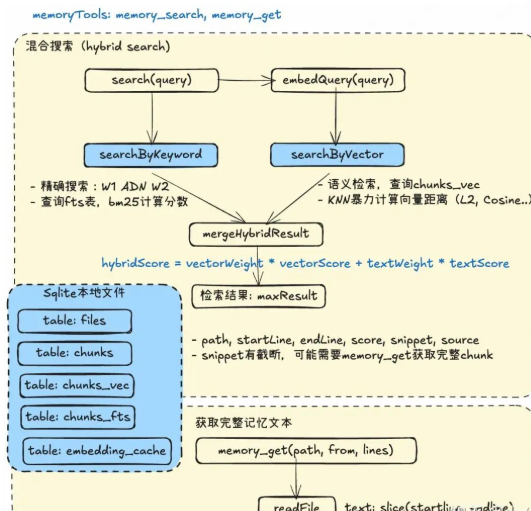
Memory检索工具:
// src/agents/tools/memory-tool.ts
export functioncreateMemorySearchTool(options:{
config ?: OpenClawConfig;
agentSessionKey ?: string;
}) : AnyAgentTool | null{
return{
label:"Memory Search",
name:"memory_search",
description:
"Mandatory recall step: semantically search MEMORY.md + memory/*.md " +
"(and optional session transcripts) before answering questions about " +
"prior work, decisions, dates, people, preferences, or todos; " +
"returns top snippets with path + lines.",
parameters : MemorySearchSchema,
execute : async(_toolCallId,params)=>{
const query=readStringParam(params,"query",{required:true});
const maxResults=readNumberParam(params,"maxResults");
const minScore=readNumberParam(params,"minScore");
const {manager,error} = awaitgetMemorySearchManager({cfg,agentId});
if (!manager){
return jsonResult({results:[],disabled : true,error});
}
const results=awaitmanager.search(query,{
maxResults,
minScore,
sessionKey:options.agentSessionKey,
});
return jsonResult ({results,provider:status.provider, model:status.model});
},
};
}
MemoryManager执行混合检索:
// src/agents/tools/memory-tool.ts
export functioncreateMemorySearchTool(options:{
config ?: OpenClawConfig;
agentSessionKey ?: string;
}) : AnyAgentTool | null{
return{
label:"Memory Search",
name:"memory_search",
description:
"Mandatory recall step: semantically search MEMORY.md + memory/*.md " +
"(and optional session transcripts) before answering questions about " +
"prior work, decisions, dates, people, preferences, or todos; " +
"returns top snippets with path + lines.",
parameters : MemorySearchSchema,
execute : async(_toolCallId,params)=>{
const query=readStringParam(params,"query",{required:true});
const maxResults=readNumberParam(params,"maxResults");
const minScore=readNumberParam(params,"minScore");
const {manager,error} = awaitgetMemorySearchManager({cfg,agentId});
if (!manager){
return jsonResult({results:[],disabled : true,error});
}
const results=awaitmanager.search(query,{
maxResults,
minScore,
sessionKey:options.agentSessionKey,
});
return jsonResult ({results,provider:status.provider, model:status.model});
},
};
}
下面简单示例如何使用Sqlite-vec执行KNN向量检索:
db.exec(`CREATE VIRTUAL TABLE vec_items USING vec0(embedding float[4])`);
// 插入
const insert=db.prepare(
`INSERT INTO vec_items(rowid, embedding) VALUES (?, ?)`
);
const data=[[1,[0.1,0.1,0.1,0.1]],[2,[0.2,0.2,0.2,0.2]]];
for (const [id,vec] of data){
insert.run(BigInt(id) , newFloat32Array(vec));
}
// KNN 搜索
const query = new Float32Array([0.15,0.15,0.15,0.15]);
const rows = db.prepare(`
SELECT rowid, distance FROM vec_items
WHERE embedding MATCH ? ORDER BY distance LIMIT 3
`).all(query);
5.3 索引写入
记忆检索依赖的本地sqlite数据库,是在特定时机触发索引写入的。比如,在监听到Memory文件变更后,会将其同步索引到本地数据库中,方便后续进行记忆检索。如果开启了session来源,也会在session更新文件后,执行索引写入。
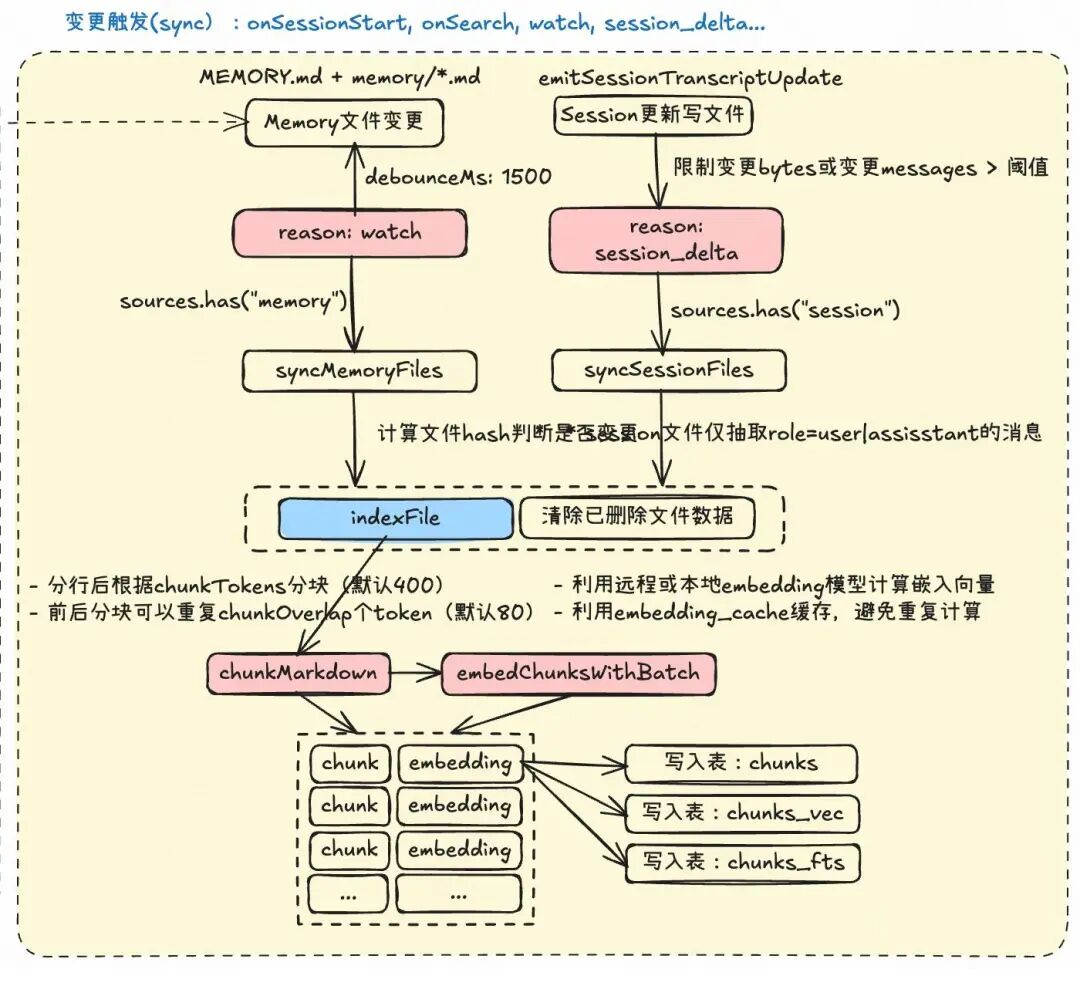
单个文件的索引写入可以分为三个部分:
- 文件分块:先将文件根据chunkTokens配置分为固定大小的块,为了增强前后文的感知,允许一定token的分块重叠。
- Embedding计算和缓存:利用配置的远程或本地embedding模型计算chunk的语义向量。同时由于经常多次索引,因此可以利用embedding缓存来避免重复计算。
- 写入本地数据库:写入索引检索依赖chunks_vec和chunks_fts两种表。
6、工具技能 (Tools & Skills)
OpenClaw提供了极其丰富且开箱即用的工具技能,这也是其能大火的原因之一。除了通用CLI Agent都有的文件系统访问、Shell命令执行、webSearch工具外,还有获取Gateway、Session等运行状态的自感知能力,以及内置的多个实用的插件工具(比如bird,message,browser,天气等)。
限于篇幅和时间,这部分更详细的内容放在后续的文章中介绍。下面介绍几个典型的工具,来说明其运作原理。
6.1 工具示例:message
工具集成本身是agent的通用能力,因此下面介绍OpenClaw比较独特的message工具。与特定Channel集成,能够达到丝滑的交互效果:
- 发送多条消息:AI 可以在最终回复用户之前或之后,先发送一张图片、一个文件或者另一条补充消息。(主动式Agent的基础)
- 富文本与复杂交互:显式设置 buttons(内联按钮)、card(卡片)、poll(投票)等高级功能。
- 引用与回复:精准控制 replyTo(回复特定消息 ID),而不仅仅是回复当前最后一条。
// message工具调用
{
"action": "send",
"buttons": "[[{\"text\":\"A. 下午好\", \"callback_data\":\"n5_quiz_wrong\"}, {\"text\":\"B. 再见\", \"callback_data\":\"n5_quiz_correct\"}], [{\"text\":\"C. 谢谢\", \"callback_data\":\"n5_quiz_wrong\"}, {\"text\":\"D. 早上好\", \"callback_data\":\"n5_quiz_wrong\"}]]",
"channel": "telegram",
"message": "📚 **日语N5练习题**\n\n**さようなら** 的中文意思是什么?",
"target": "123456"
}
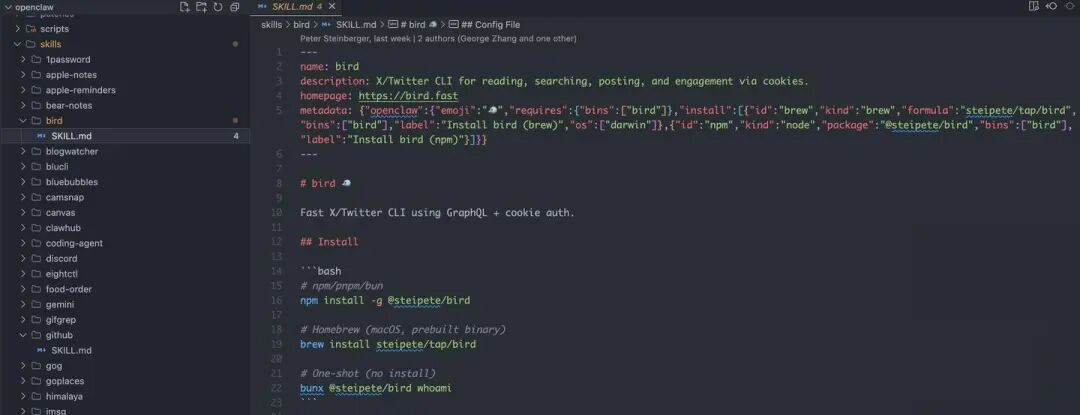
6.2 Skills示例:bird
复习一下Skills的工作原理,通过文件系统+渐进式披露,标准化和模块化技能提示词。
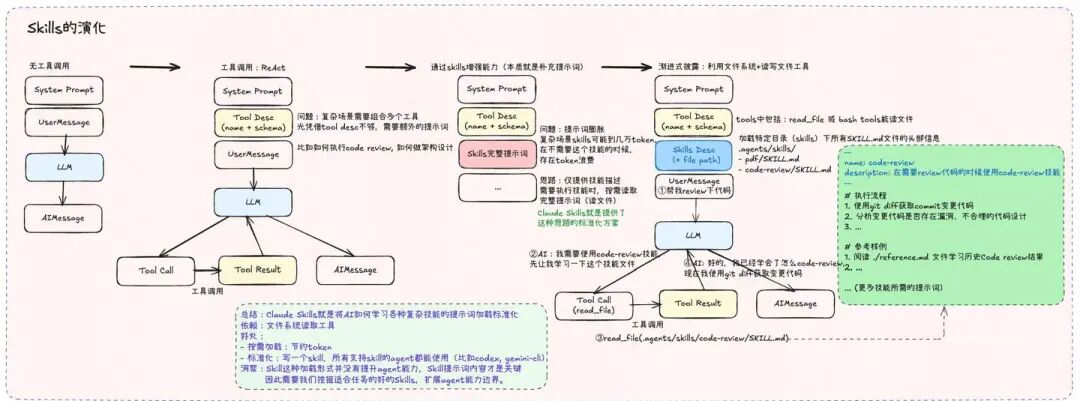
Skills 将从三个位置加载:
1. 内置 Skills:随安装包一起发布(npm 包或 OpenClaw.app),比如bird,github等
2. 托管/本地 Skills:~/.openclaw/skills
3. 工作区 Skills:/skills
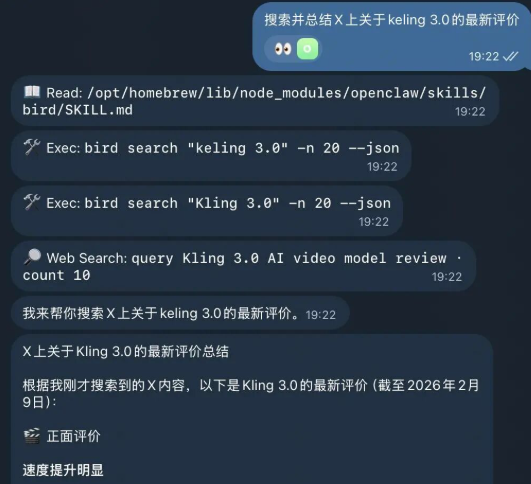
下面以bird skills介绍,如何搜索和总结Twitter(X)上的内容。
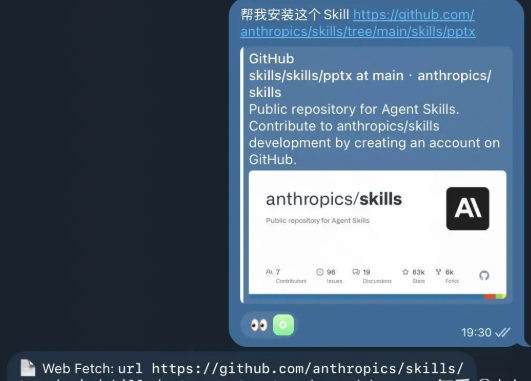
6.3 自定义工具和技能
OpenClaw还允许用户自定义加入工具和技能。当然官方推荐使用clawhub命令安装https://clawhub.ai/里的技能 或通过plugin命令安装插件。
# 技能安装,以artifacts-builder为例
npm i -g clawhub
clawhub install artifacts-builder
# 插件安装
openclaw plugins list
openclaw plugins install @openclaw/voice-call
你也可以直接让openclaw帮你安装;或者直接将skills添加到目录.openclaw/workspace/skills/
6.4 工具策略
翻看OpenClaw 的代码,其实最让我震惊的是其灵活的配置能力。以工具策略为例,OpenClaw支持多个层级的工具配置策略,即特定的场景可以配置不同的工具组合可见性。
1. 全局策略: config.tools
2. 全局按提供商策略: config .tools. byProvider [providerOrModelId]
3. Agent 策略: config .agents .[agentId] .tools
4. Agent 按提供商策略: config .agents .[agentId] .tools .byProvider [providerOrModelId]
5. 群组策略: config .groups .[groupId] .tools (针对特定群组)
总结
其实整体来看OpenClaw在Agent核心层面没有特别多新颖的地方,但作为一个完成度特别高的产品:24×7运行的本地个人助手,其架构设计思想和扩展集成值得我们反复学习。
本文从核心交互流程出发,了解消息接入和分发链路,以及SessionKey的机制,一步一步深入Agent核心设计。了解到Queue如何解决复杂的并发消息问题,以及OpenClaw如何管理session文件解决短期记忆的持久化问题,如何通过记忆文件保存和检索长期记忆。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。我们整理出这套 AI 大模型突围资料包:
- ✅ 从零到一的 AI 学习路径图
- ✅ 大模型调优实战手册(附医疗/金融等大厂真实案例)
- ✅ 百度/阿里专家闭门录播课
- ✅ 大模型当下最新行业报告
- ✅ 真实大厂面试真题
- ✅ 2026 最新岗位需求图谱
所有资料 ⚡️ ,朋友们如果有需要 《AI大模型入门+进阶学习资源包》,下方扫码获取~
① 全套AI大模型应用开发视频教程
(包含提示工程、RAG、LangChain、Agent、模型微调与部署、DeepSeek等技术点)
② 大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。这里我给大家准备了一份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!
③ 大模型学习书籍&文档
学习AI大模型离不开书籍文档,我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
④ AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。
⑤ 大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。
⑥ 大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

以上资料如何领取?

为什么大家都在学大模型?
最近科技巨头英特尔宣布裁员2万人,传统岗位不断缩减,但AI相关技术岗疯狂扩招,有3-5年经验,大厂薪资就能给到50K*20薪!

不出1年,“有AI项目经验”将成为投递简历的门槛。
风口之下,与其像“温水煮青蛙”一样坐等被行业淘汰,不如先人一步,掌握AI大模型原理+应用技术+项目实操经验,“顺风”翻盘!

这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

以上全套大模型资料如何领取?


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献668条内容
已为社区贡献668条内容

所有评论(0)